
Programma
Nozioni di base sull'intelligenza artificiale nel mondo degli affari
12 h
Usare i large language model (LLM) sui sistemi locali è sempre più diffuso grazie a maggiore privacy, controllo e affidabilità. A volte, questi modelli possono essere persino più accurati e veloci di ChatGPT.
Ti mostreremo sette modi per eseguire LLM in locale con accelerazione GPU su Windows 11, ma i metodi che trattiamo funzionano anche su macOS e Linux.
Se vuoi imparare gli LLM da zero, un buon punto di partenza è questo corso su Large Learning Models (LLMs).
Iniziamo esplorando il primo framework LLM.
Ollama è l'ecosistema dominante per eseguire in locale LLM come Llama 4, Mistral 3 e Gemma 3.
Inoltre, molte applicazioni supportano l'integrazione con Ollama, il che lo rende uno strumento eccellente per un accesso più rapido e semplice ai modelli linguistici sul nostro computer locale.
Ollama ora offre piena compatibilità con l'API di OpenAI, rendendolo un sostituto plug-and-play del servizio cloud di OpenAI. Le funzionalità recenti includono function calling, output JSON strutturato, Flash Attention per i modelli di visione e inferenza più veloce del 30% su Apple Silicon e GPU AMD.
Possiamo scaricare Ollama dalla pagina di download.
Una volta installato (usando le impostazioni predefinite), il logo di Ollama apparirà nell'area di notifica.
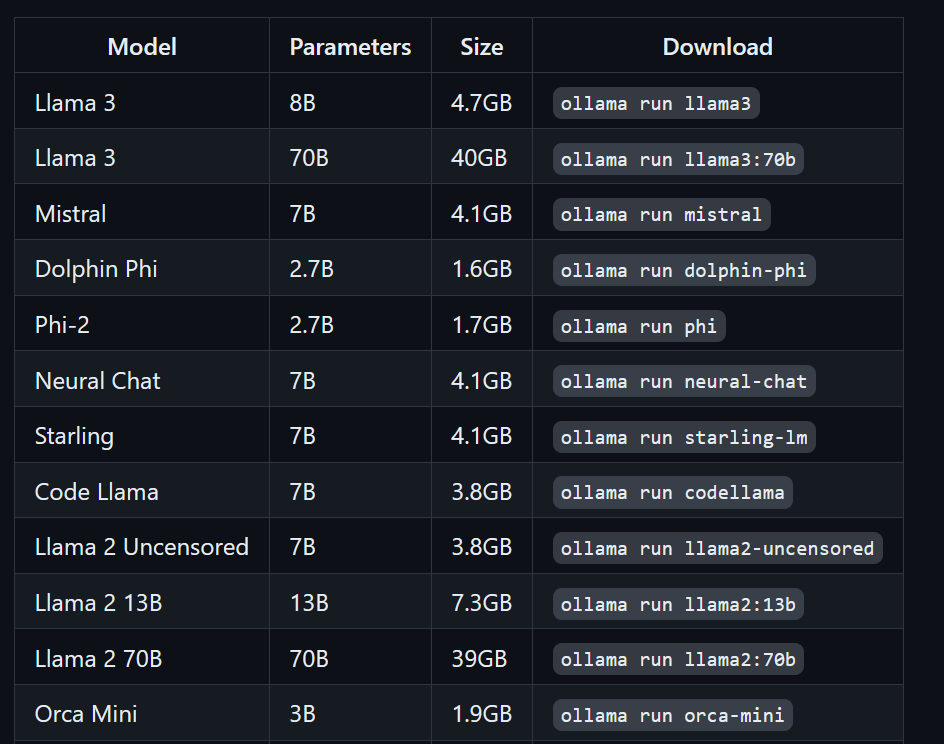
Possiamo scaricare il modello Llama 3 digitando il seguente comando nel terminale:
$ ollama run llama3Llama 3 è pronto all'uso! Qui sotto trovi un elenco di comandi da usare se vuoi provare altri LLM:
Per accedere ai modelli già scaricati e disponibili nella cartella di llama.cpp, dobbiamo:
cd.$ cd C:/Repository/GitHub/llama.cppModelfile e aggiungere la riga "FROM ./Nous-Hermes-2-Mistral-7B-DPO.Q4_0.gguf".$ echo "FROM ./Nous-Hermes-2-Mistral-7B-DPO.Q4_0.gguf" > Modelfile$ ollama create NHM-7b -f Modelfile
$ ollama run NHM-7bCon questo metodo, possiamo scaricare qualsiasi LLM da Hugging Face con estensione .gguf e usarlo nel terminale. Se vuoi saperne di più, dai un'occhiata a questo corso su Working with Hugging Face.
LM Studio è una postazione tutto-in-uno per eseguire LLM in locale e offre il fine-tuning in modo nativo. Inoltre, supporta modelli concorrenti multipli, speculative decoding (token 1,5x-3x più veloci) e integrazione RAG per documenti.
Possiamo scaricare il programma di installazione dalla home page di LM Studio.
Una volta completato il download, installiamo l'app con le opzioni predefinite.
Infine, avviamo LM Studio!
Possiamo scaricare qualsiasi modello da Hugging Face usando la funzione di ricerca.
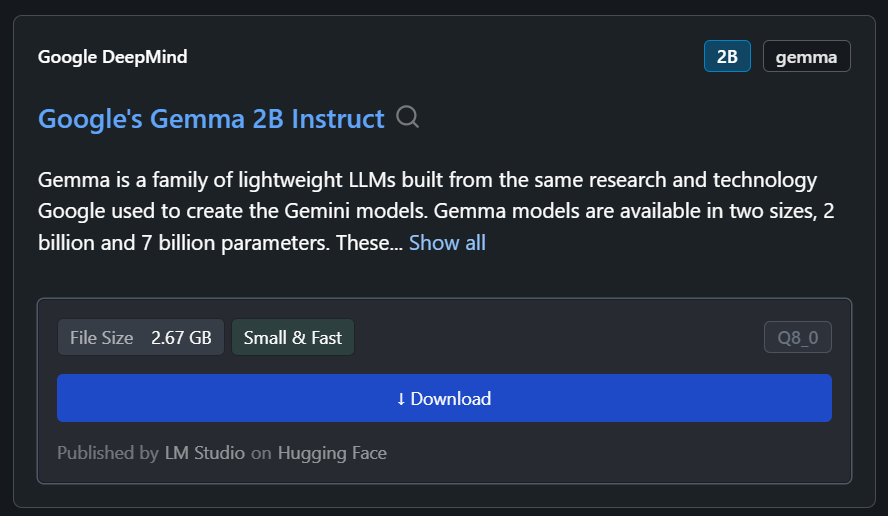
Nel nostro caso, scaricheremo il modello più piccolo, Gemma 2B Instruct di Google.
Possiamo selezionare il modello scaricato dal menu a discesa in alto e chattare come di consueto. LM Studio offre più opzioni di personalizzazione rispetto a GPT4All.
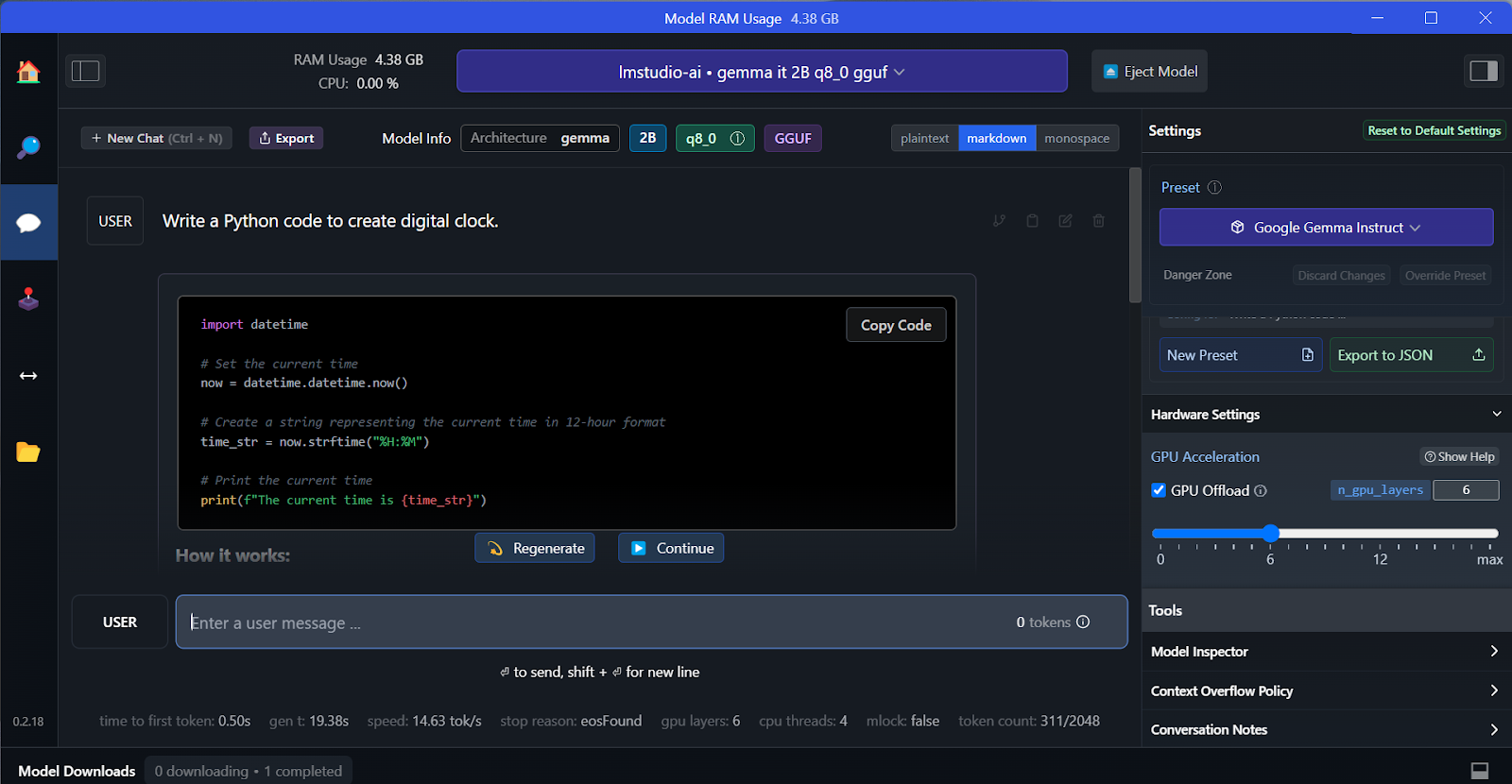
Come GPT4All, possiamo personalizzare il modello e avviare il server API con un clic. Per accedere al modello, possiamo usare il pacchetto Python dell'API OpenAI, CURL o integrarlo direttamente con qualsiasi applicazione.
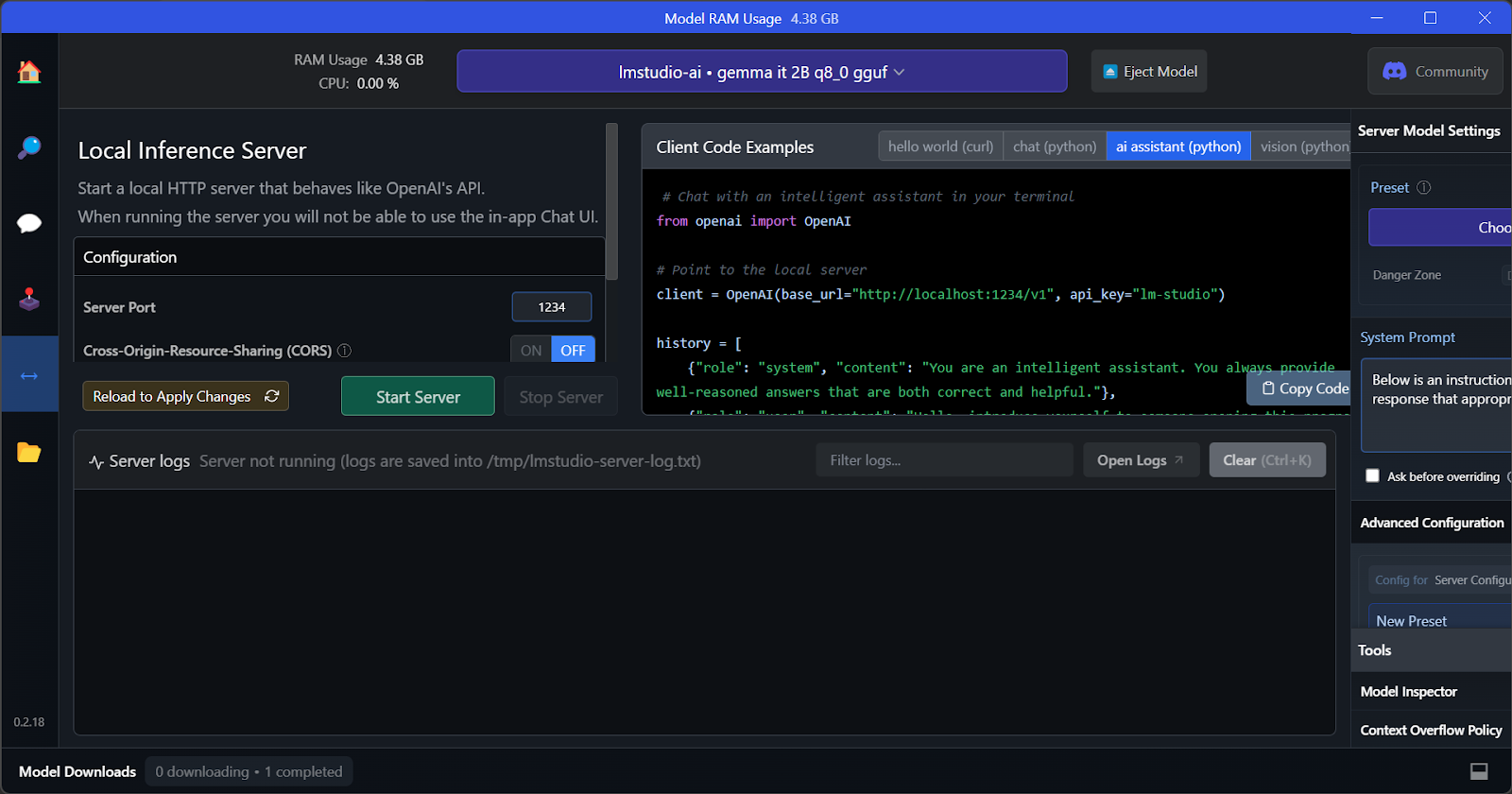
La caratteristica chiave di LM Studio è che offre l'opzione di eseguire e servire più modelli contemporaneamente. Questo consente di confrontare i risultati di modelli diversi e usarli per più applicazioni. Per eseguire più sessioni di modelli, è necessaria un'elevata VRAM della GPU.
Il fine-tuning è un altro modo per generare risposte contestuali e personalizzate. Puoi imparare a fare fine-tuning del tuo modello Google Gemma seguendo il tutorial Fine Tuning Google Gemma: Enhancing LLMs with Customized Instructions. Imparerai a eseguire l'inferenza su GPU/TPU e a fare fine-tuning dell'ultimo modello Gemma 7b-it su un dataset di role-play.
vLLM è un motore di inferenza open source per eseguire LLM in produzione su larga scala. A differenza di Ollama o LM Studio, vLLM dà priorità a throughput e latenza per scenari multiutente.
La sua innovazione principale è PagedAttention, che gestisce la memoria GPU come la memoria virtuale, riutilizzando piccole pagine invece di riservare blocchi massicci, combinata con batching continuo. Benchmark reali mostrano vLLM che eroga 793 token al secondo su Llama 70B contro i 41 token al secondo di Ollama sotto carico concorrente.
vLLM supporta anche il parallelismo tensoriale tra GPU, il prefix caching e il batching multi-LoRA per servire contemporaneamente varianti fine-tunate.
Su Mac e Linux, vLLM può essere installato facilmente usando pip.
Su Linux con CUDA 11.8+:
pip install vllmSu macOS con Apple Silicon:
python3.11 -m venv vllm_env
source vllm_env/bin/activate
pip install vllmAl momento non esiste un supporto ufficiale per Windows. Tuttavia, sono disponibili workaround tramite WSL2 o Docker.
Avvia il server compatibile con OpenAI:
vllm serve meta-llama/Llama-2-7b-hf --port 8000 --gpu-memory-utilization 0.9Per modelli 70B su più GPU:
vllm serve meta-llama/Llama-2-70b-hf --tensor-parallel-size 2 --port 8000Per l'elaborazione in batch in Python:
from vllm import LLM, SamplingParams
llm = LLM(model="meta-llama/Llama-2-7b-hf", dtype="bfloat16")
sampling_params = SamplingParams(temperature=0.8, max_tokens=256)
outputs = llm.generate(["Write hello world", "Explain AI"], sampling_params)Per interrogare, usa l'SDK OpenAI:
from openai import OpenAI
client = OpenAI(base_url='http://localhost:8000/v1', api_key='any')
response = client.chat.completions.create(
model='meta-llama/Llama-2-7b-hf',
messages=[{'role': 'user', 'content': 'What is ML?'}],
max_tokens=200
)
print(response.choices[0].message.content)Un'altra opzione è eseguirlo tramite cURL:
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{"model": "meta-llama/Llama-2-7b-hf", "messages": [{"role": "user", "content": "Hello"}]}'Scegli vLLM per API di produzione che servono centinaia di utenti contemporanei; usa Ollama per lo sviluppo locale.
Una delle applicazioni LLM locali più popolari e meglio progettate è Jan. È un'alternativa privacy-first a ChatGPT.
Possiamo scaricare il programma di installazione da Jan.ai.
Una volta installata l'app Jan con le impostazioni predefinite, siamo pronti ad avviare l'applicazione.
Quando abbiamo trattato GPT4All e LM Studio, abbiamo già scaricato due modelli. Invece di scaricarne un altro, importeremo quelli che abbiamo già andando nella pagina del modello e cliccando sul pulsante Import Model.
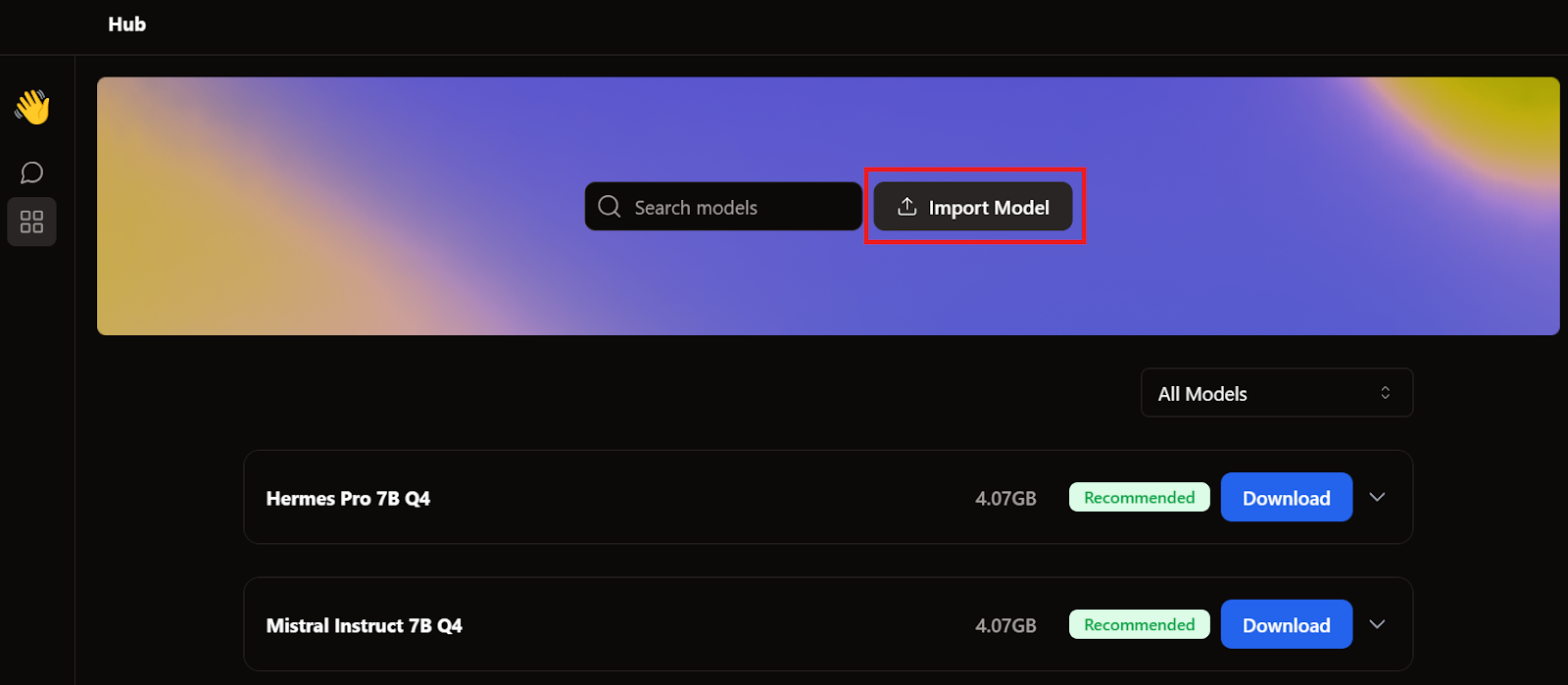
Poi andiamo nella directory delle applicazioni, selezioniamo i modelli di GPT4All e LM Studio e importiamo ciascuno di essi.
Per accedere ai modelli locali, andiamo all'interfaccia utente della chat e apriamo la sezione dei modelli nel pannello di destra.
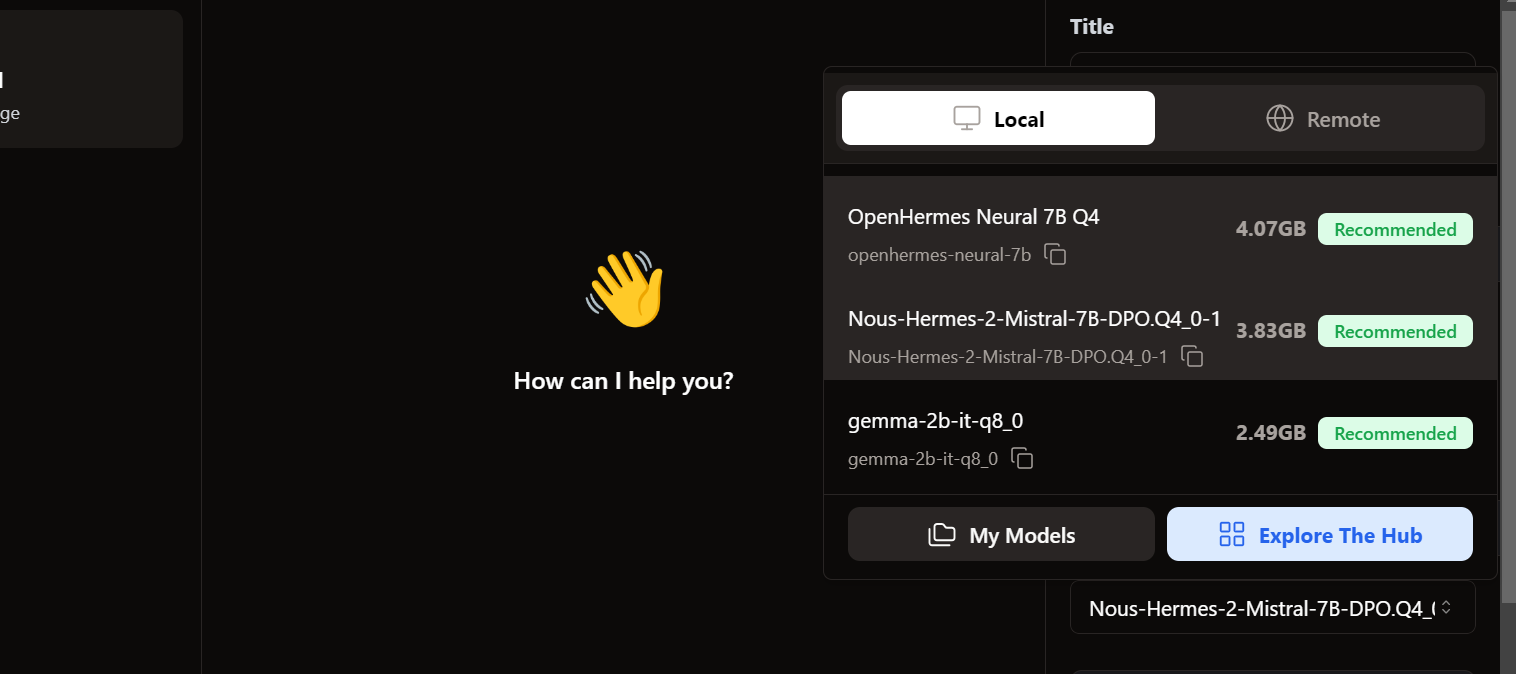
Vediamo che i modelli importati sono già lì. Possiamo selezionare quello che vogliamo e iniziare a usarlo subito!
La generazione della risposta è molto rapida. L'interfaccia utente è naturale, simile a ChatGPT, e non rallenta il tuo laptop o PC.
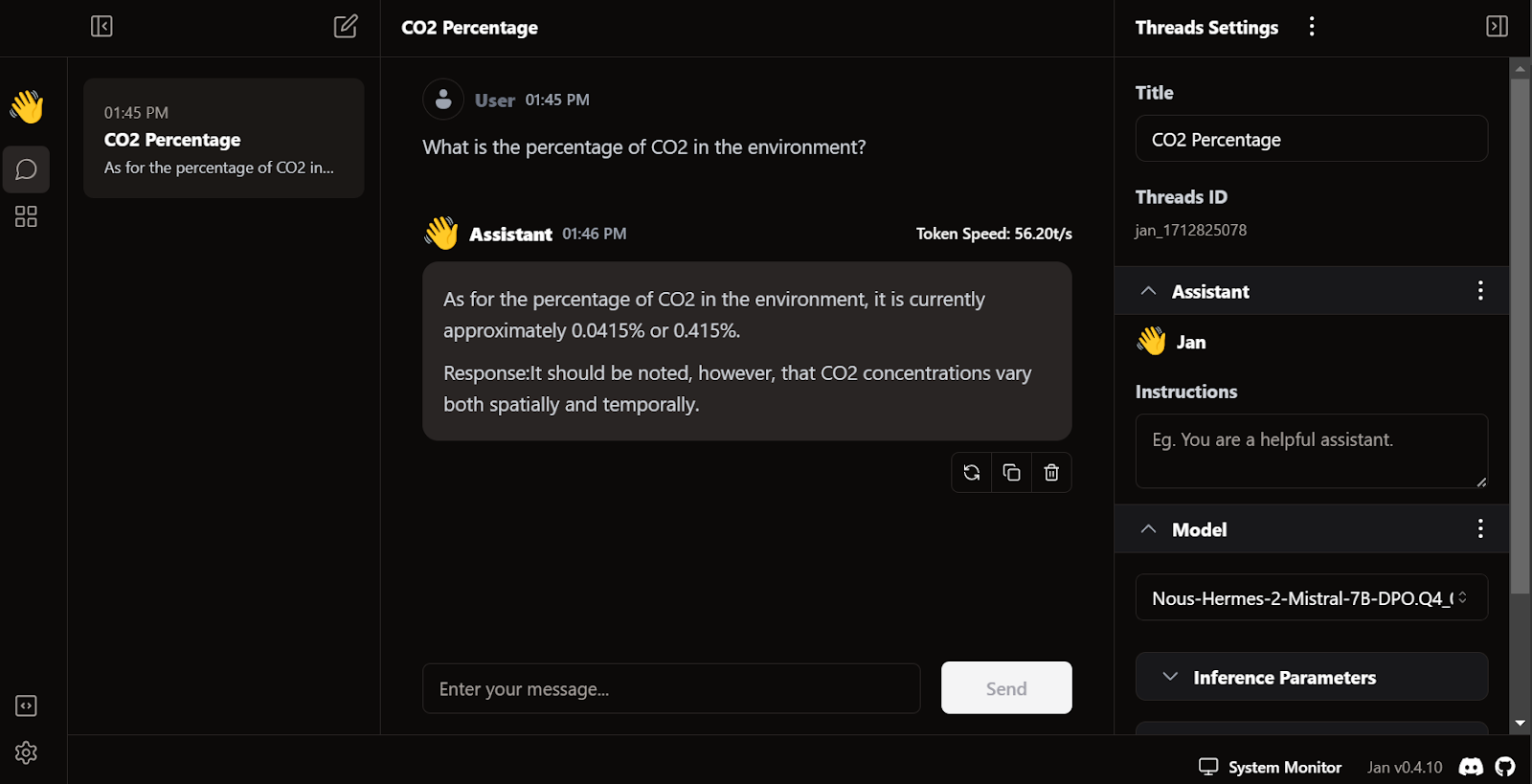
La caratteristica unica di Jan è che ci permette di installare estensioni e usare modelli proprietari di OpenAI, MistralAI, Groq, TensorRT e Triton RT.
Come LM Studio, possiamo usare Jan anche come server API locale. Offre più funzionalità di logging e controllo sulla risposta dell'LLM e integra OpenAI, Mistral AI, Groq, Claude e DeepSeek tramite una semplice configurazione della chiave API nelle impostazioni.
Un altro framework LLM open source molto popolare è llama.cpp. È scritto interamente in C/C++, il che lo rende veloce ed efficiente.
Molte applicazioni di AI locali e web si basano su llama.cpp. Quindi, imparare a usarlo in locale ti darà un vantaggio nel capire come funzionano dietro le quinte le altre applicazioni LLM.
Per prima cosa, dobbiamo andare nella directory del progetto usando il comando cd nella shell—puoi saperne di più sul terminale in questo corso di Introduction to Shell.
Quindi cloneremo tutti i file dal server GitHub usando il comando seguente:
$ git clone --depth 1 https://github.com/ggerganov/llama.cpp.gitLo strumento da riga di comando make è disponibile per impostazione predefinita in Linux e macOS. Su Windows, invece, dobbiamo seguire questi passaggi:
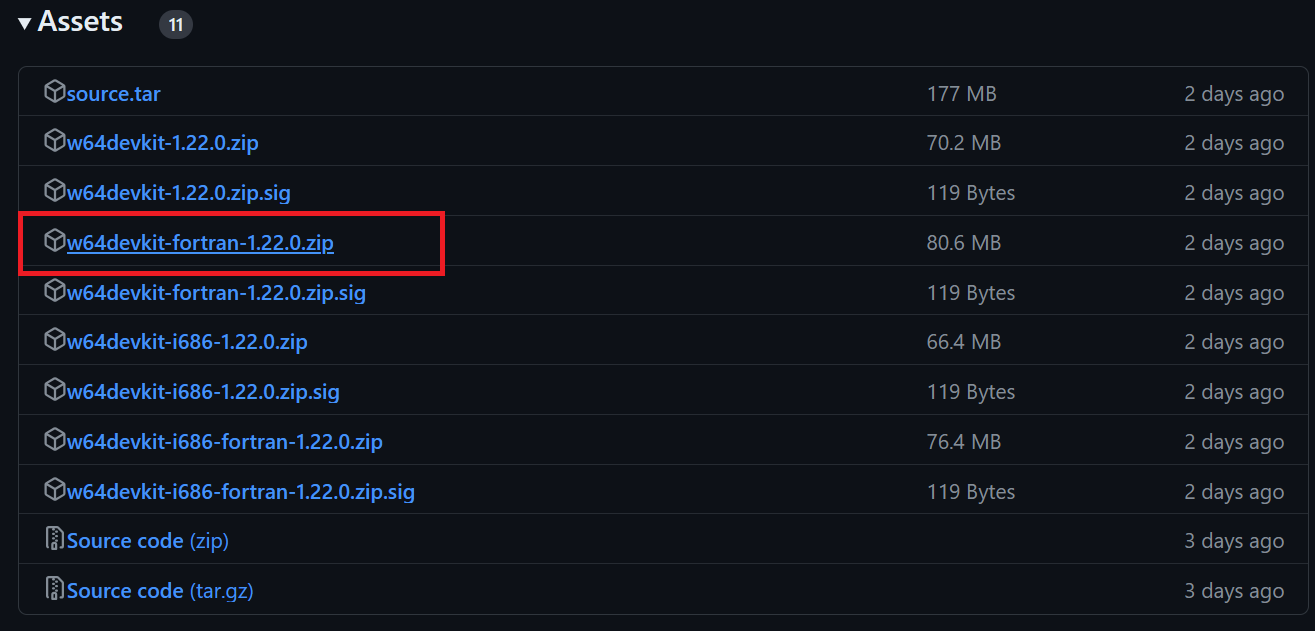
$ cd C:/Repository/GitHub/llama.cpp per accedere alla cartella di llama.cpp.$ make e premere Invio per installare llama.cpp.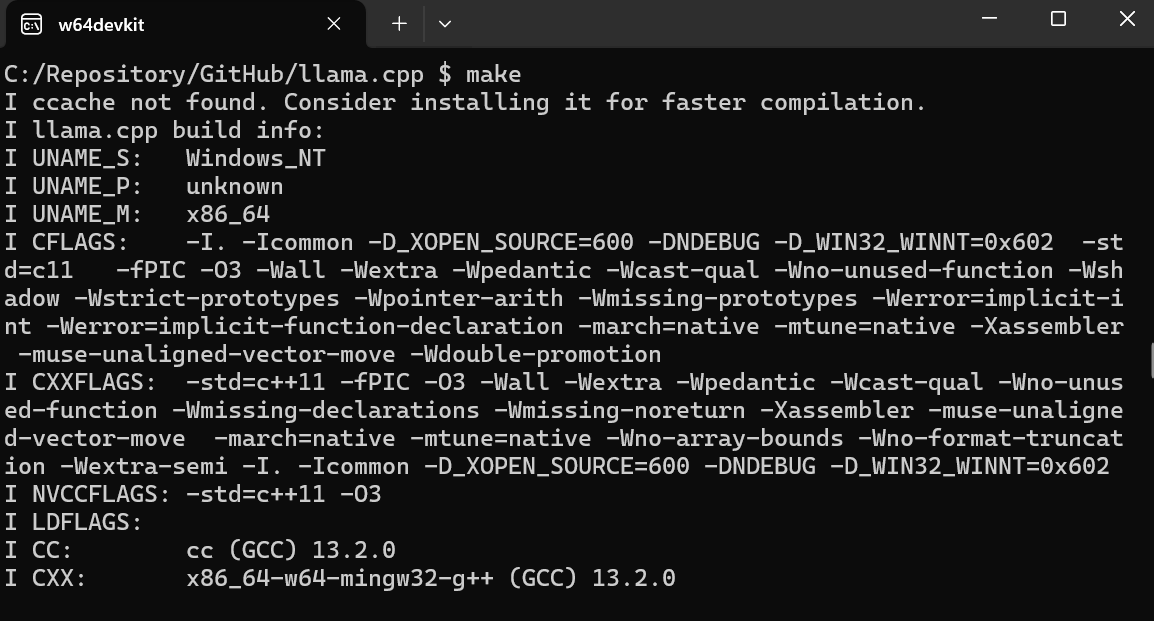
Dopo aver completato l'installazione, eseguiamo il server dell'interfaccia web di llama.cpp digitando il comando seguente. (Nota: abbiamo copiato il file del modello dalla cartella di GPT4All a quella di llama.cpp per poter accedere facilmente al modello).
$ ./server -m Nous-Hermes-2-Mistral-7B-DPO.Q4_0.gguf -ngl 27 -c 2048 --port 6589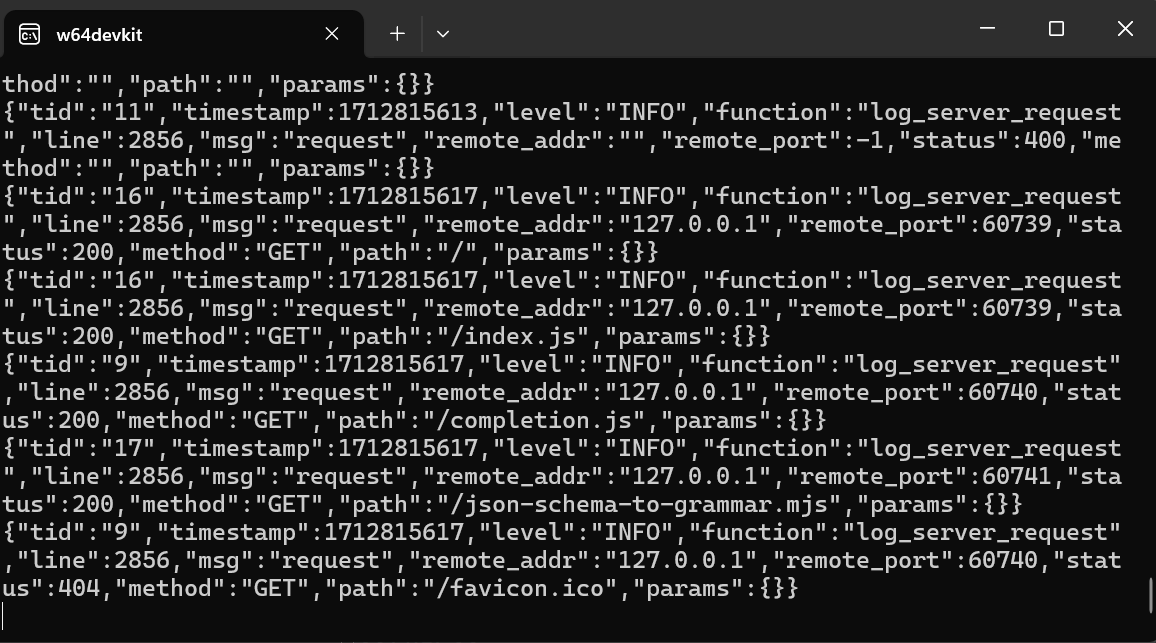
Il server web è in esecuzione su http://127.0.0.1:6589/. Puoi copiare questo URL e incollarlo nel browser per accedere all'interfaccia web di llama.cpp.
Prima di interagire con il chatbot, dovremmo modificare le impostazioni e i parametri del modello.
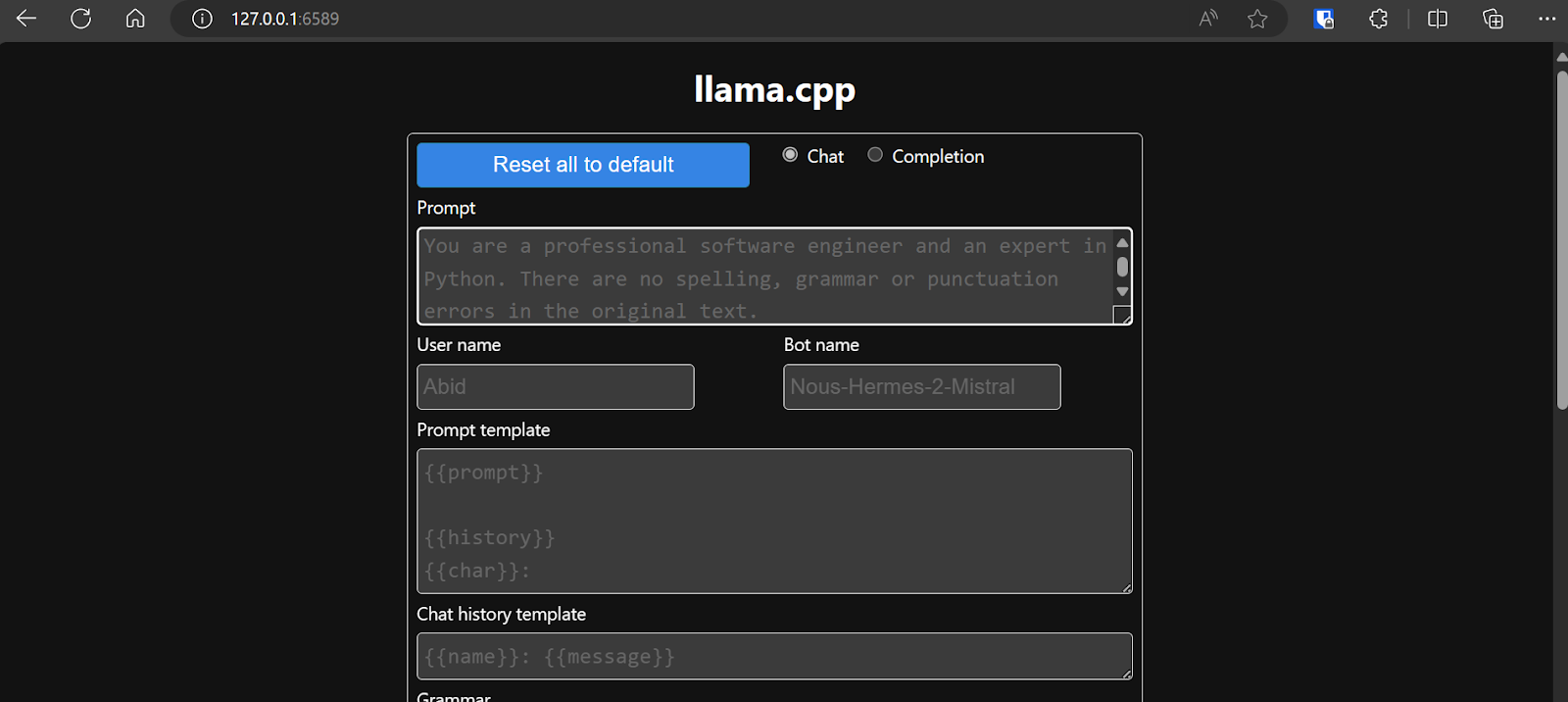 Dai un'occhiata a questo tutorial su llama.cpp se vuoi saperne di più!
Dai un'occhiata a questo tutorial su llama.cpp se vuoi saperne di più!
La generazione delle risposte è lenta perché lo eseguiamo su CPU, non su GPU. Dobbiamo installare una versione diversa di llama.cpp per eseguirlo su GPU.
$ make LLAMA_CUDA=1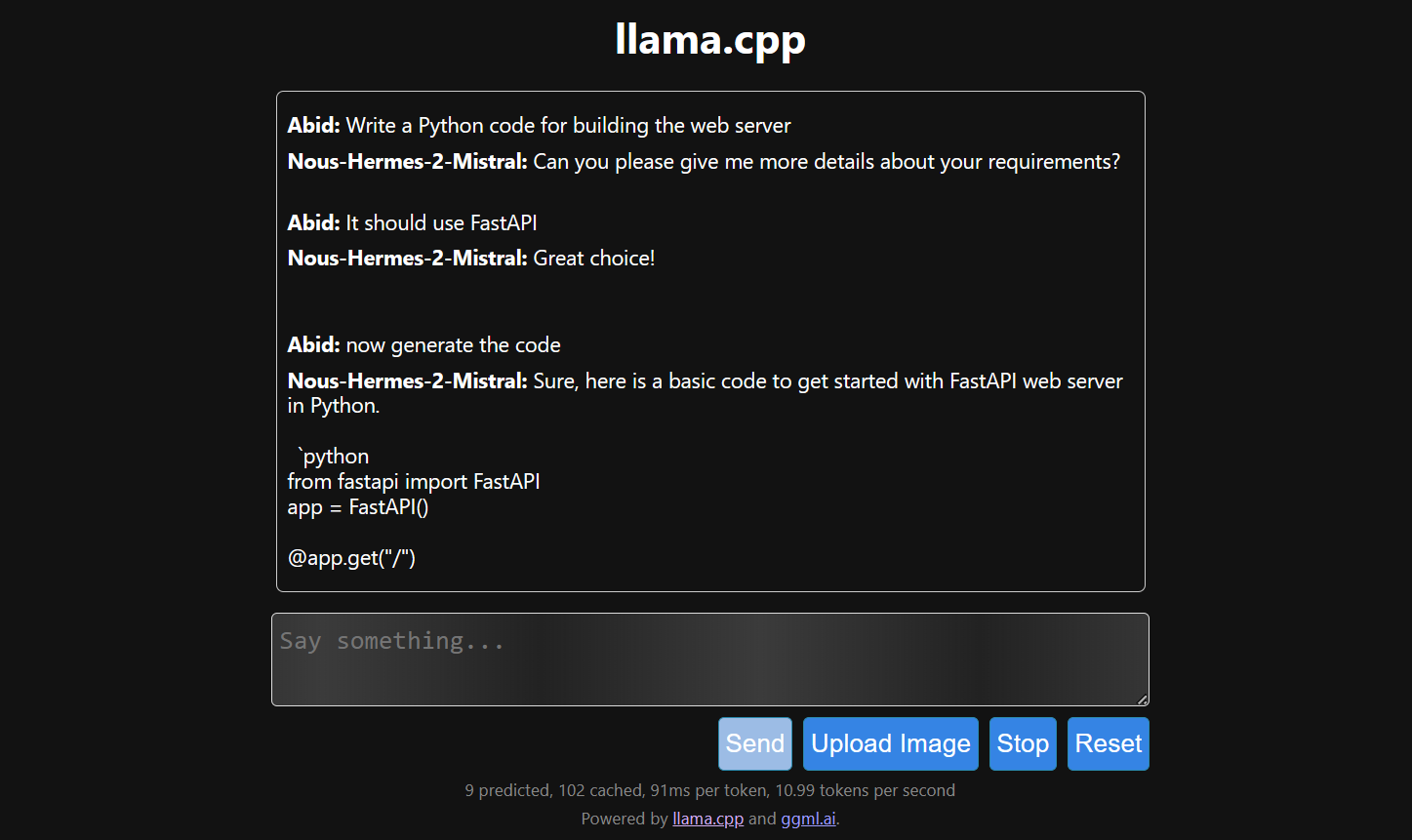
Se trovi llama.cpp un po' troppo complesso, prova llamafile. Questo framework semplifica gli LLM sia per gli sviluppatori sia per gli utenti finali combinando llama.cpp con Cosmopolitan Libc in un eseguibile in un unico file. Rimuove tutte le complessità associate agli LLM, rendendoli più accessibili.
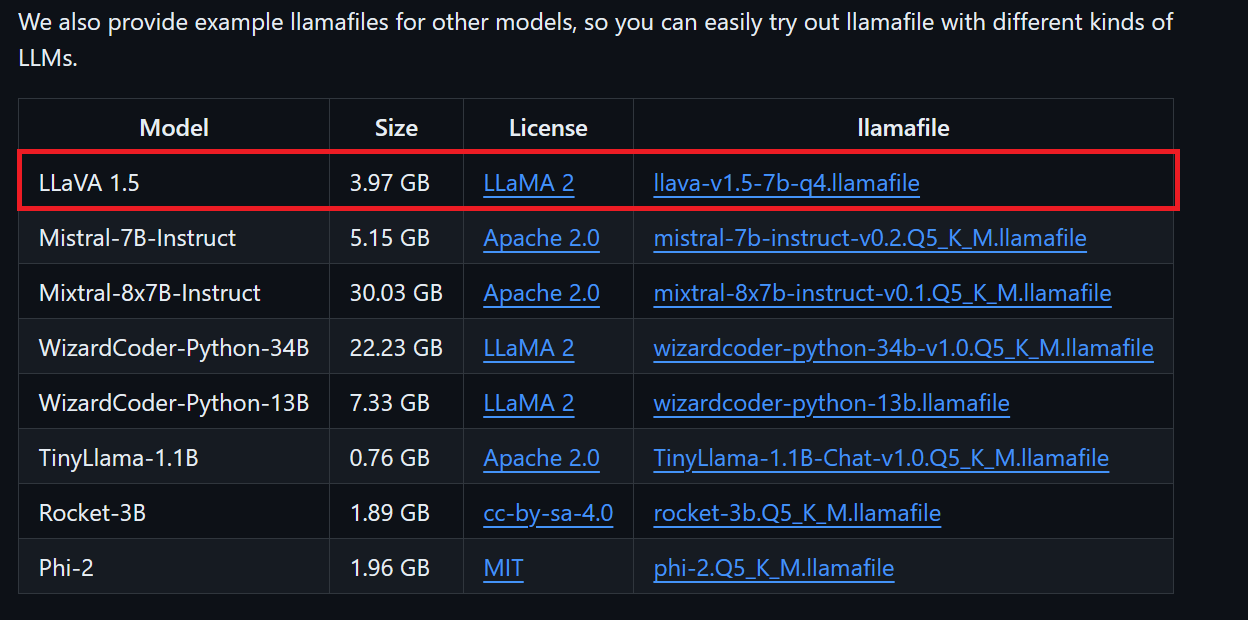
Possiamo scaricare il file del modello desiderato dal repository GitHub di llamafile.
Scaricheremo LLaVA 1.5 perché può anche comprendere le immagini.
Gli utenti Windows devono aggiungere .exe ai nomi dei file nel terminale. Per farlo, fai clic con il tasto destro sul file scaricato e seleziona Rinomina.

Per prima cosa andiamo nella directory di llamafile usando il comando cd nel terminale. Poi eseguiamo il comando seguente per avviare il server web di llama.cpp.
$ ./llava-v1.5-7b-q4.llamafile -ngl 9999Il server web utilizza la GPU senza richiedere installazioni o configurazioni.
Avvierà anche automaticamente il browser web predefinito con l'applicazione web di llama.cpp in esecuzione. Se non lo fa, possiamo usare l'URL http://127.0.0.1:8080/ per accedervi direttamente.
Dopo aver definito la configurazione del modello, possiamo iniziare a usare l'applicazione web.
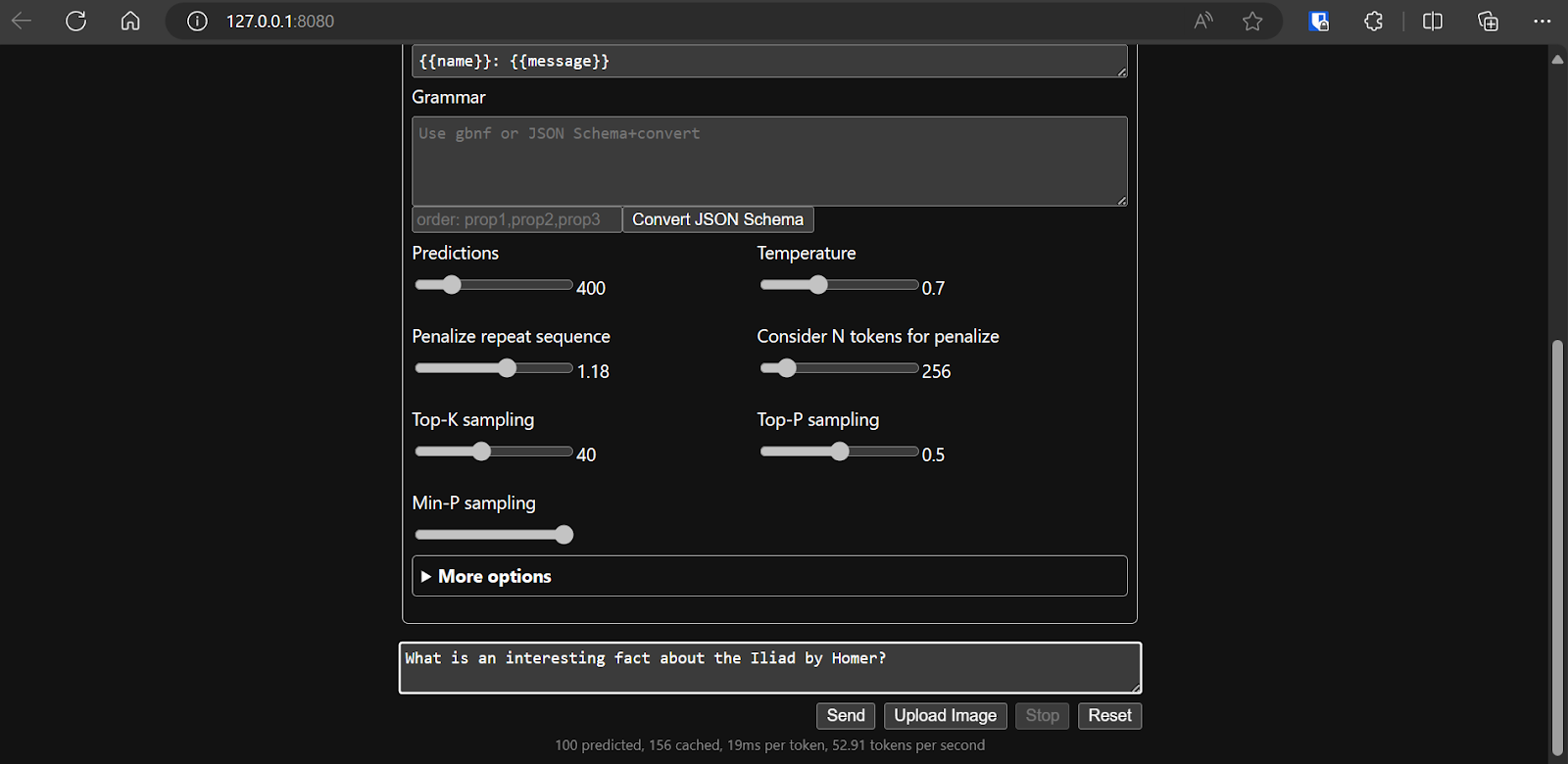
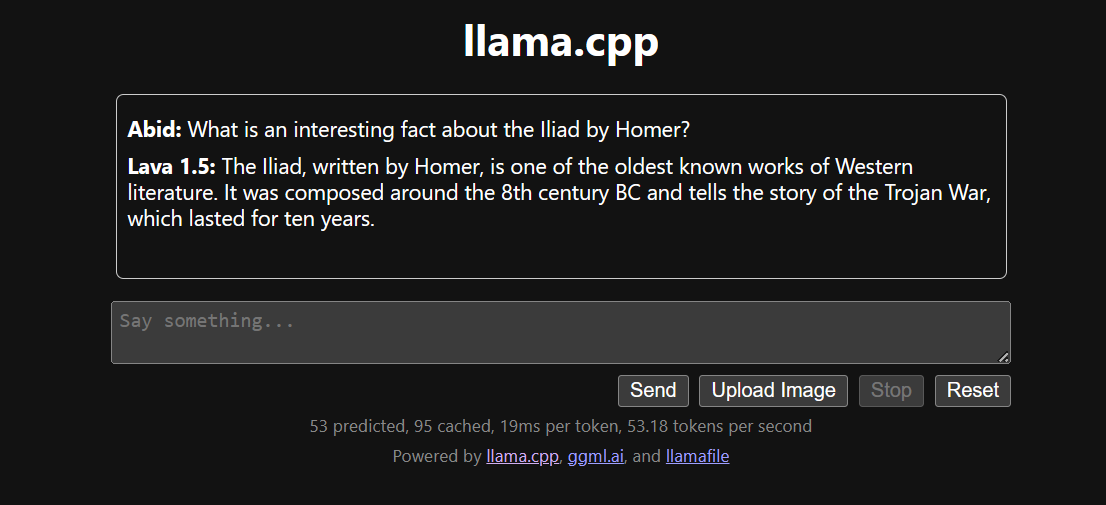
Eseguire llama.cpp tramite llamafile è più semplice ed efficiente. Abbiamo generato la risposta a 53,18 token/sec (senza llamafile, la velocità era 10,99 token/sec).
Installare e usare gli LLM in locale può essere un'esperienza divertente ed entusiasmante. Possiamo sperimentare in autonomia gli ultimi modelli open source, godendo di privacy, controllo e un'esperienza di chat migliore.
Usare gli LLM in locale ha anche applicazioni pratiche, come l'integrazione con altre applicazioni tramite server API e il collegamento di cartelle locali per fornire risposte contestuali. In alcuni casi, è essenziale usare LLM in locale, soprattutto quando privacy e sicurezza sono fattori critici.
Puoi saperne di più sugli LLM e sulla creazione di applicazioni di intelligenza artificiale seguendo queste risorse:
Costruisci la tua carriera nell'AI con DataCamp!
Programma
Corso
Corso
blog
Abid Ali Awan
15 min
blog
Abid Ali Awan
10 min
blog
Tim Lu
12 min

