
Lernpfad
KI-Grundlagen für Unternehmen
12 Std.
Die Nutzung von großen Sprachmodellen (LLMs) auf lokalen Systemen wird immer beliebter, weil sie mehr Privatsphäre, Kontrolle und Zuverlässigkeit bieten. Manchmal können diese Modelle sogar genauer und schneller sein als chatGPT.
Wir zeigen dir sieben Möglichkeiten, wie du LLMs lokal mit GPU-Beschleunigung unter Windows 11 ausführen kannst, aber die von uns vorgestellten Methoden funktionieren auch unter macOS und Linux.
Wenn du dich von Grund auf über LLMs informieren möchtest, ist dieser Kurs über Large Learning Models (LLMs) ein guter Einstieg.
Fangen wir damit an, unser erstes LLM-Framework zu checken.
Ollama ist das wichtigste System zum Ausführen von LLMs wie Llama 4, Mistral 3und Gemma 3 vor Ort.
Außerdem können viele Programme mit Ollama zusammenarbeiten, was es zu einem super Tool macht, um schneller und einfacher auf Sprachmodelle auf unserem lokalen Rechner zuzugreifen.
Ollama ist jetzt voll kompatibel mit der OpenAI-API und kann so direkt als Ersatz für den Cloud-Dienst von OpenAI eingesetzt werden. Zu den neuesten Features gehören Funktionsaufrufe, strukturierte JSON-Ausgabe, Flash Attention für Vision-Modelle und eine um 30 % schnellere Inferenz auf Apple Silicon und AMD-GPUs.
Wir können Ollama von der Download-Seite runterladen.
Sobald wir es installiert haben (mit den Standardeinstellungen), erscheint das Ollama-Logo in der Taskleiste.
Wir können das Llama 3-Modell runterladen, indem wir den folgenden Terminalbefehl eingeben:
$ ollama run llama3Llama 3 ist jetzt einsatzbereit! Unten findest du eine Liste mit Befehlen, die wir brauchen, wenn wir andere LLMs verwenden wollen:
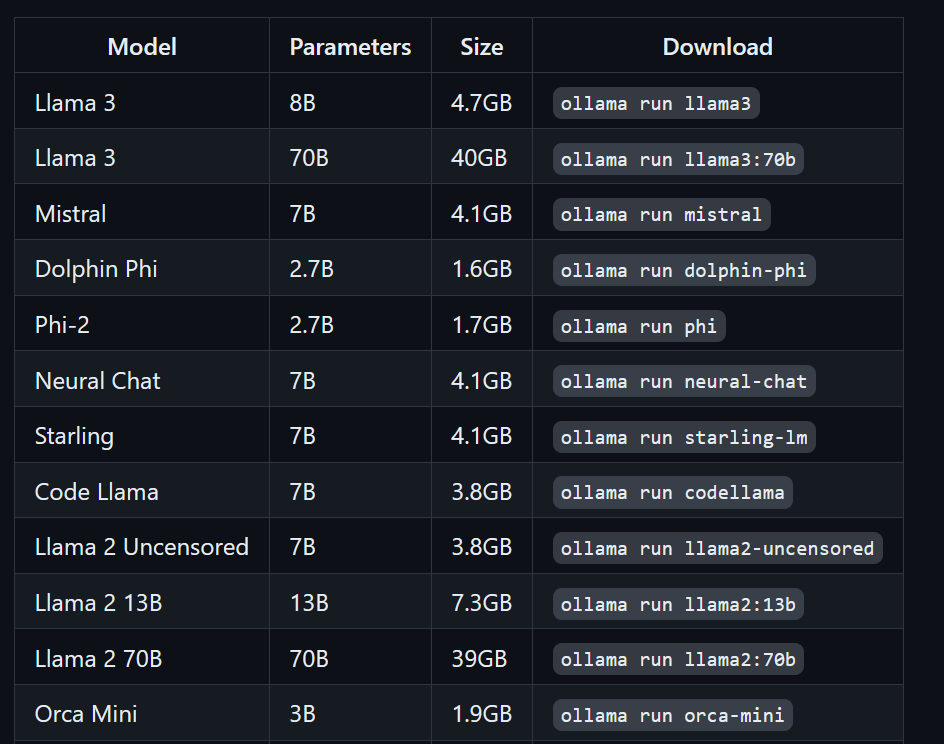
Um auf Modelle zuzugreifen, die schon runtergeladen wurden und im Ordner llama.cpp verfügbar sind, müssen wir:
cd “ zum Ordner „llama.cpp“.$ cd C:/Repository/GitHub/llama.cppModelfile “ und füge die Zeile „ "FROM ./Nous-Hermes-2-Mistral-7B-DPO.Q4_0.gguf" “ hinzu.$ echo "FROM ./Nous-Hermes-2-Mistral-7B-DPO.Q4_0.gguf" > Modelfile$ ollama create NHM-7b -f Modelfile
$ ollama run NHM-7bMit dieser Methode können wir jedes LLM von Hugging Face mit der Erweiterung .gguf runterladen und im Terminal nutzen. Wenn du mehr erfahren möchtest, schau dir diesen Kurs zum Thema „Arbeiten mit Hugging Face“ an.
LM Studio ist eine All-in-One-Workbench zum lokalen Ausführen von LLMs und bietet native Feinabstimmung. Außerdem unterstützt mehrere gleichzeitige Modelle, spekulative Dekodierung (1,5- bis 3-mal schnellere Token) und die Integration von Dokument-RAG.
Wir können das Installationsprogramm von der Homepage von LM Studiorunterladen.
Sobald der Download fertig ist, installieren wir die App mit den Standardoptionen.
Endlich starten wir LM Studio!
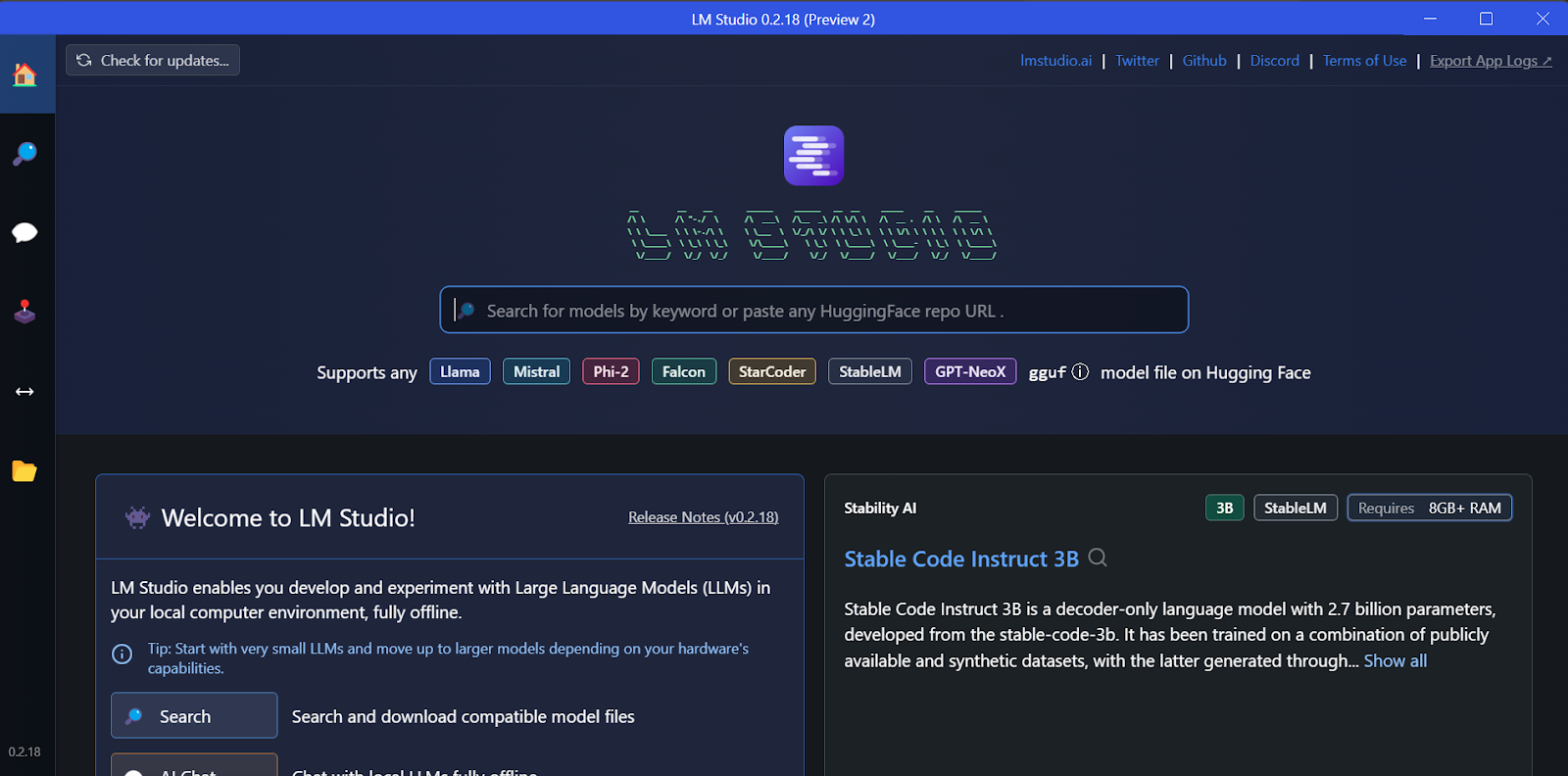
Wir können jedes Modell von Hugging Face über die Suchfunktion runterladen.
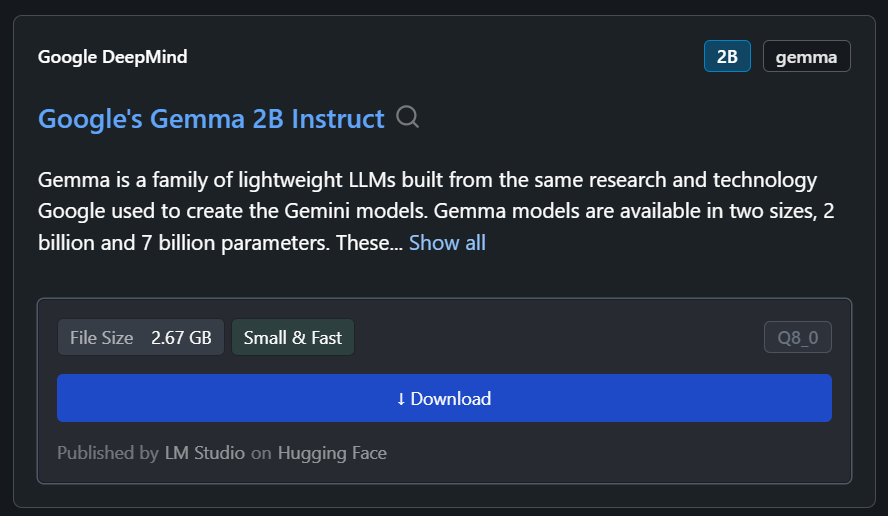
In unserem Fall laden wir das kleinste Modell runter, Googles Gemma 2B Instruct.
Wir können das heruntergeladene Modell aus dem Dropdown-Menü oben auswählen und wie gewohnt mit ihm chatten. LM Studio hat mehr Anpassungsmöglichkeiten als GPT4All.
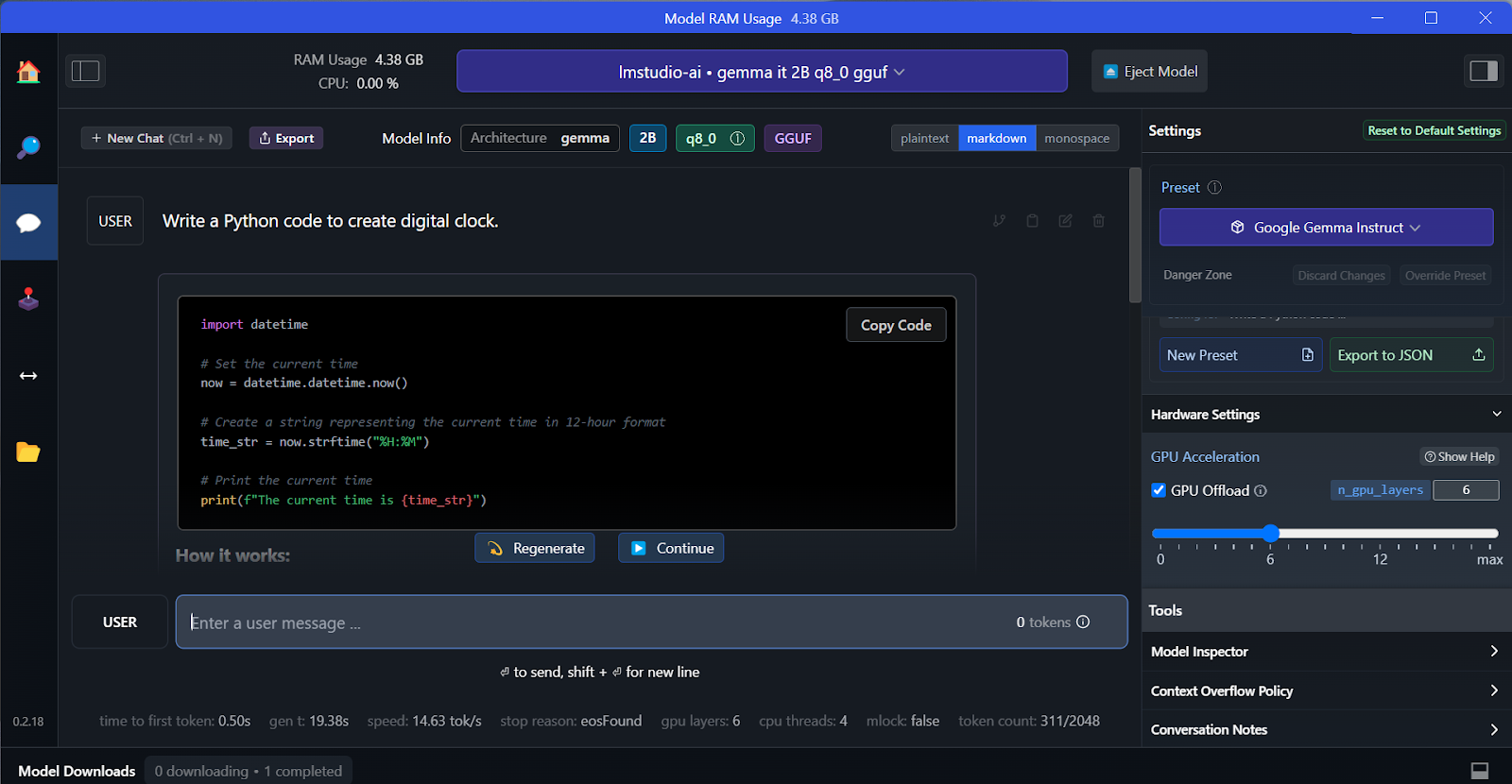
Genau wie bei GPT4All können wir das Modell anpassen und den API-Server mit einem Klick starten. Um auf das Modell zuzugreifen, können wir das Python-Paket der OpenAI-API, CURL, nutzen oder es direkt in jede beliebige Anwendung einbinden.
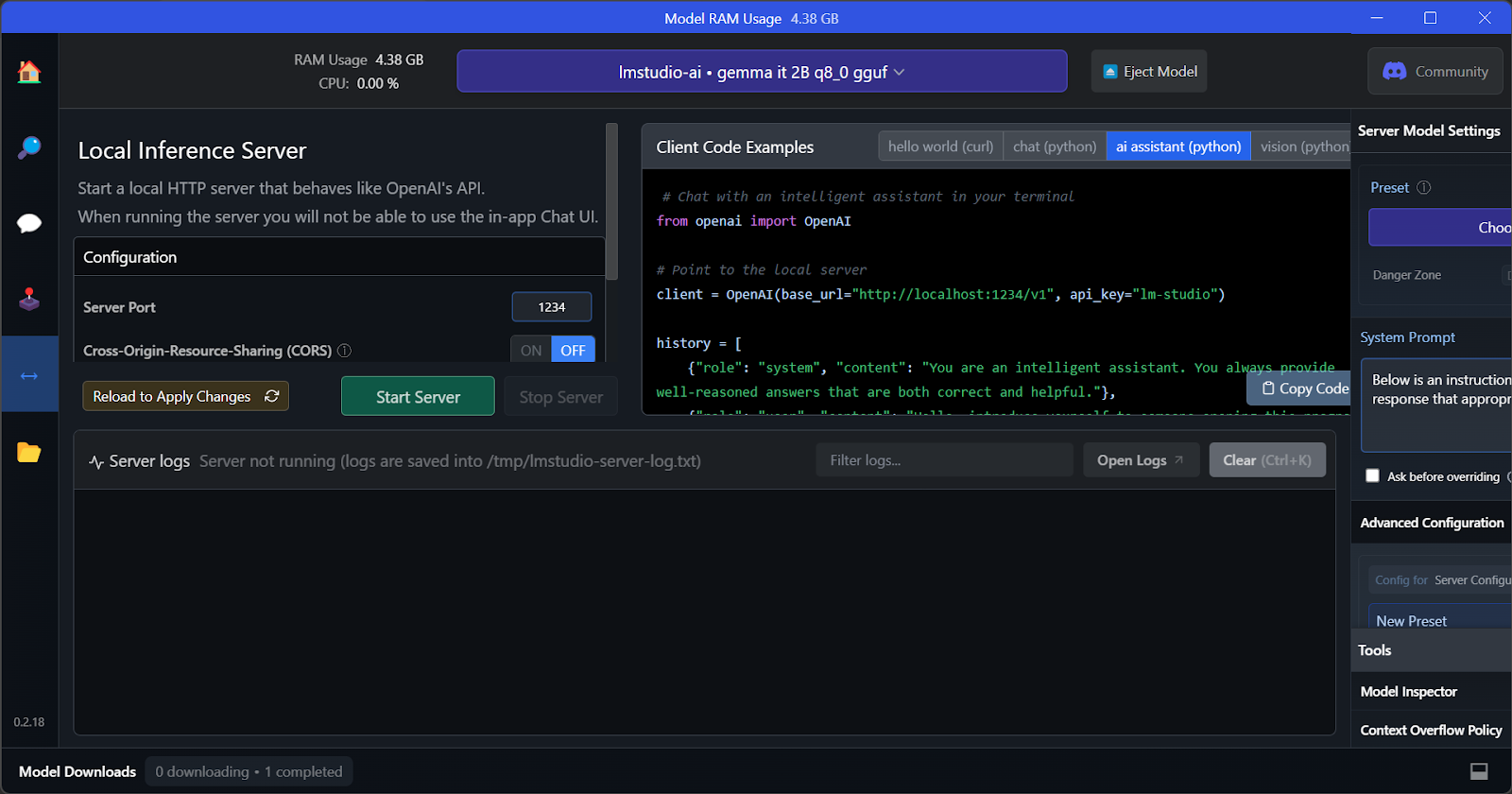
Das Beste an LM Studio ist, dass man mehrere Modelle gleichzeitig ausführen und bedienen kann. So können Leute verschiedene Modellergebnisse vergleichen und für verschiedene Sachen nutzen. Um mehrere Modell-Sessions laufen zu lassen, brauchen wir viel GPU-VRAM.
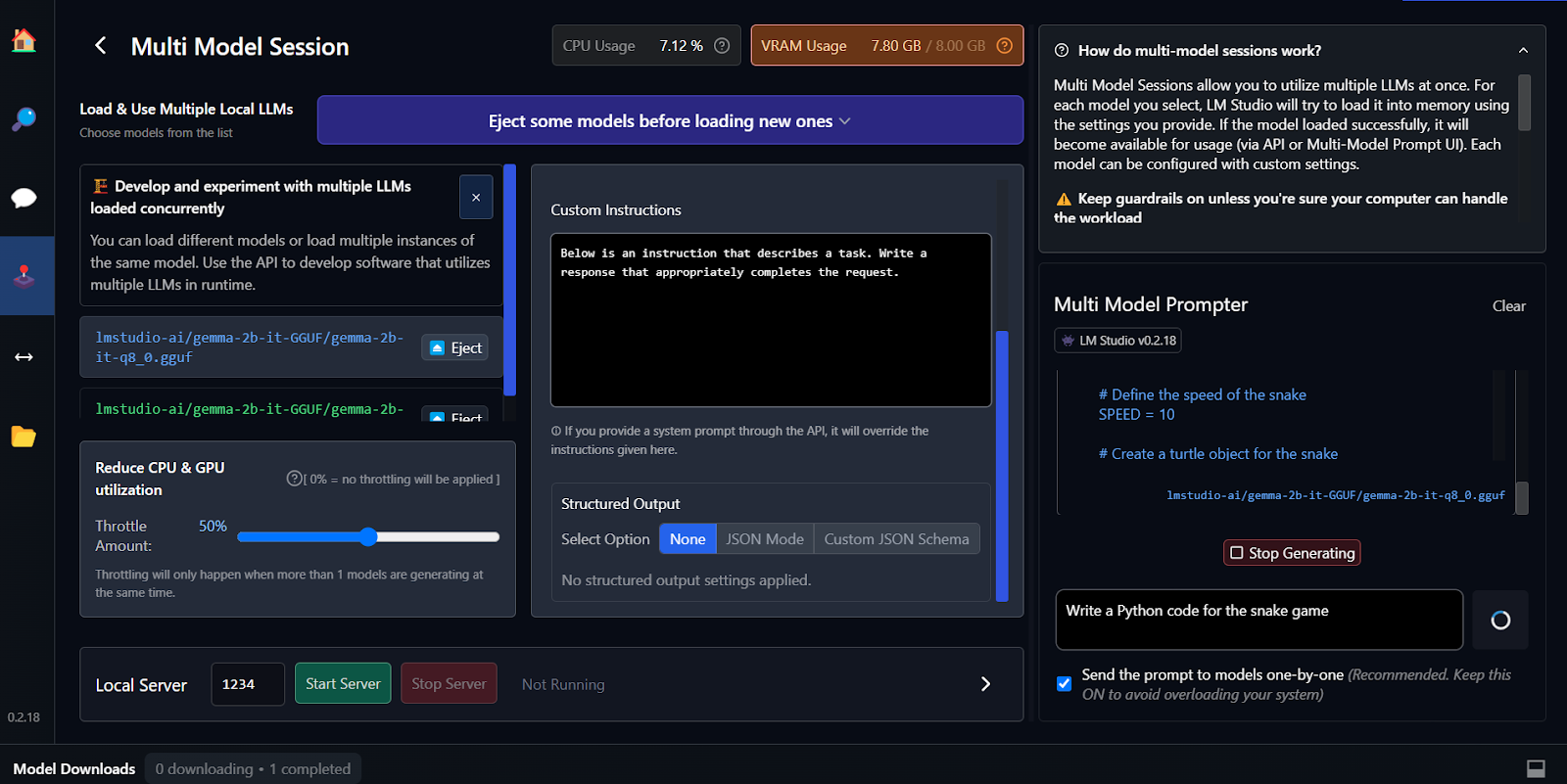
Feinabstimmung ist eine andere Möglichkeit, kontextbezogene und maßgeschneiderte Antworten zu generieren. Du kannst lernen, dein Google Gemma-Modell zu optimieren, indem du dem Tutorial „ Fine Tuning Google Gemma” folgst: Verbesserung von LLMs mit maßgeschneiderten Anweisungen. Du lernst, wie du Inferenz auf GPUs/TPUs durchführst und das neueste Gemma 7b-it-Modell anhand eines Rollenspiel-Datensatzes optimierst.
vLLM ist eine Open-Source-Inferenz-Engine, mit der man LLMs in der Produktion nutzen kann. Im Gegensatz zu Ollama oder LM Studio legt vLLM bei Szenarien mit mehreren Nutzern den Fokus auf Durchsatz und Latenz.
Die wichtigste Neuerung ist PagedAttention, das den GPU-Speicher wie virtuellen Speicher verwaltet, indem es kleine Seiten wiederverwendet, anstatt riesige Blöcke zu reservieren, und das zusammen mit kontinuierlichem Batching. Echte Benchmarks zeigen, dass vLLM bei gleichzeitiger Belastung 793 Token pro Sekunde auf Llama 70B liefert, während Ollama nur 41 Token pro Sekunde schafft.
vLLM kann auch Tensor-Parallelität über GPUs, Präfix-Caching und Multi-LoRA-Batching, um fein abgestimmte Varianten gleichzeitig zu bedienen.
Auf Mac und Linux kannst du vLLM ganz einfach mit „ pip “ installieren.
Unter Linux mit CUDA 11.8+:
pip install vllmAuf macOS mit Apple Silicon:
python3.11 -m venv vllm_env
source vllm_env/bin/activate
pip install vllmIm Moment gibt's keine offizielle Unterstützung für Windows. Es gibt aber Alternativen über WSL2 oder Docker.
Starte den OpenAI-kompatiblen Server:
vllm serve meta-llama/Llama-2-7b-hf --port 8000 --gpu-memory-utilization 0.9Für 70B-Modelle auf mehreren GPUs:
vllm serve meta-llama/Llama-2-70b-hf --tensor-parallel-size 2 --port 8000Für die Stapelverarbeitung in Python:
from vllm import LLM, SamplingParams
llm = LLM(model="meta-llama/Llama-2-7b-hf", dtype="bfloat16")
sampling_params = SamplingParams(temperature=0.8, max_tokens=256)
outputs = llm.generate(["Write hello world", "Explain AI"], sampling_params)Für Abfragen das OpenAI SDK verwenden:
from openai import OpenAI
client = OpenAI(base_url='http://localhost:8000/v1', api_key='any')
response = client.chat.completions.create(
model='meta-llama/Llama-2-7b-hf',
messages=[{'role': 'user', 'content': 'What is ML?'}],
max_tokens=200
)
print(response.choices[0].message.content)Eine andere Möglichkeit ist, es über cURL laufen zu lassen:
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{"model": "meta-llama/Llama-2-7b-hf", "messages": [{"role": "user", "content": "Hello"}]}'Nimm vLLM für Produktions-APIs, die Hunderte von Nutzern gleichzeitig bedienen; nutze Ollama für die lokale Entwicklung.
Eine der beliebtesten und coolsten lokalen LLM-Apps ist Jan. Es ist eine Alternative zu chatGPT, bei der Datenschutz an erster Stelle steht.
Wir können das Installationsprogramm von Jan.ai runterladen.
Sobald wir die Jan-App mit den Standardeinstellungen installiert haben, können wir sie starten.
Als wir über GPT4All und LM Studio berichtet haben, haben wir schon zwei Modelle runtergeladen. Anstatt ein neues Modell runterzuladen, importieren wir einfach die Modelle, die wir schon haben. Dazu gehen wir auf die Modellseite und klicken auf den Button „Modell importieren “.
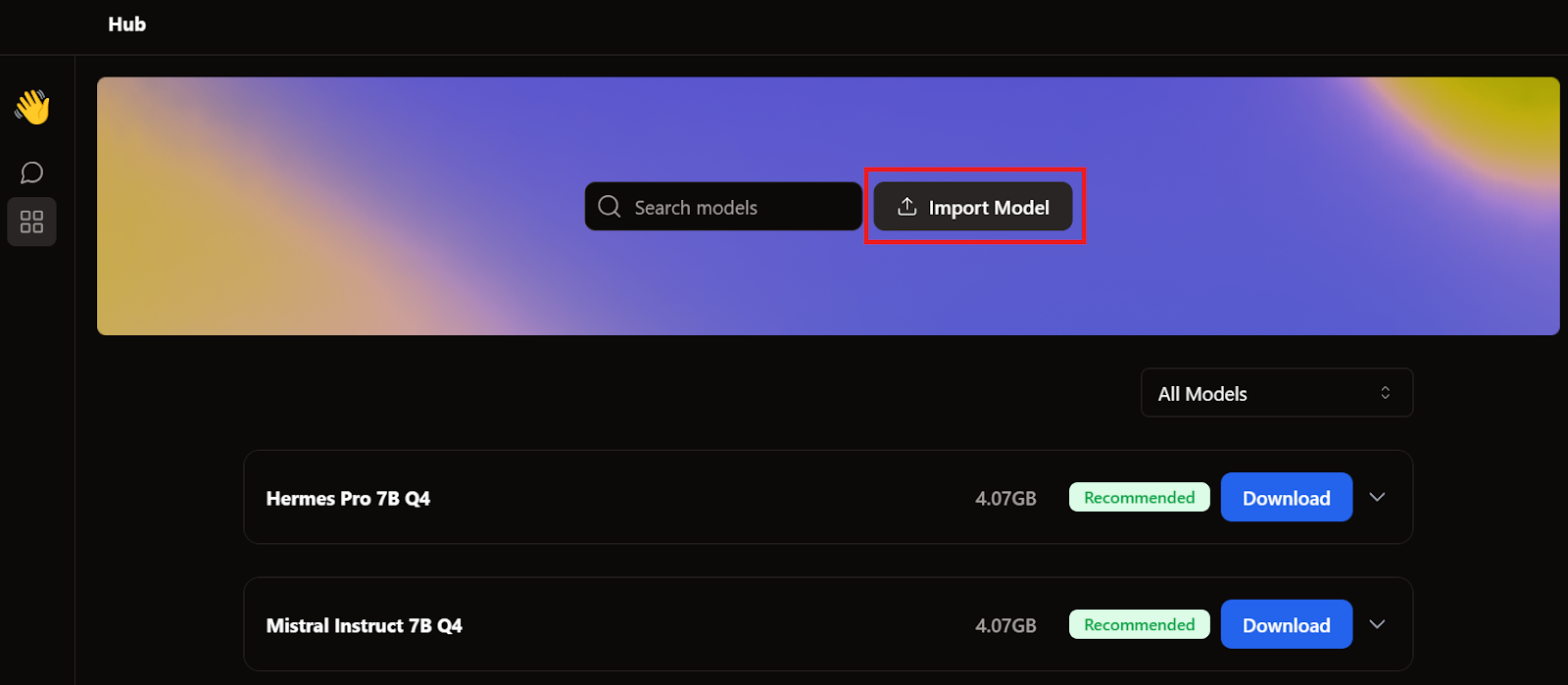
Dann gehen wir zum Anwendungsverzeichnis, wählen die Modelle GPT4All und LM Studio aus und importieren sie.
Um auf die lokalen Modelle zuzugreifen, gehen wir zur Chat-Benutzeroberfläche und öffnen den Modellbereich im rechten Fensterbereich.
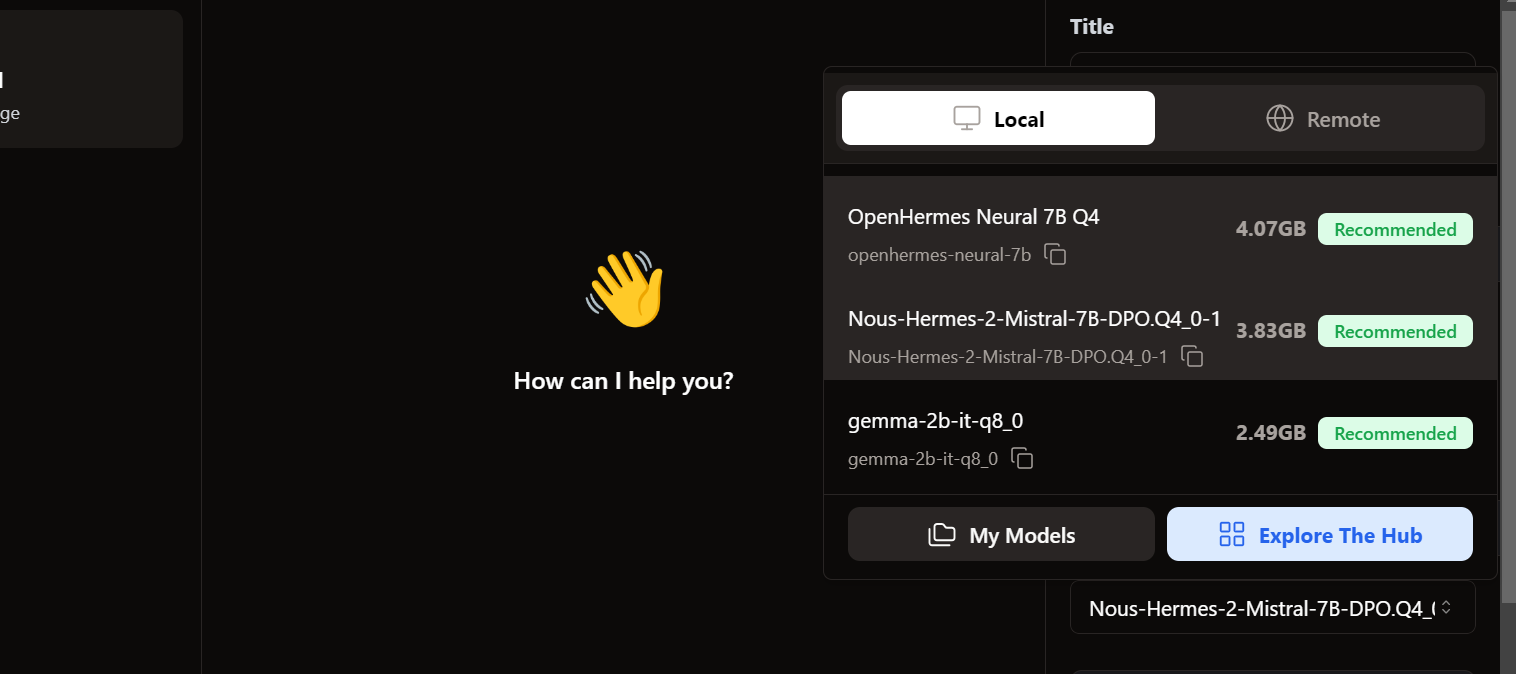
Wir sehen, dass unsere importierten Modelle schon da sind. Wir können das gewünschte Produkt auswählen und sofort loslegen!
Die Antwort kommt echt schnell. Die Benutzeroberfläche fühlt sich natürlich an, ähnlich wie chatGPT, und macht deinen Laptop oder PC nicht langsamer.
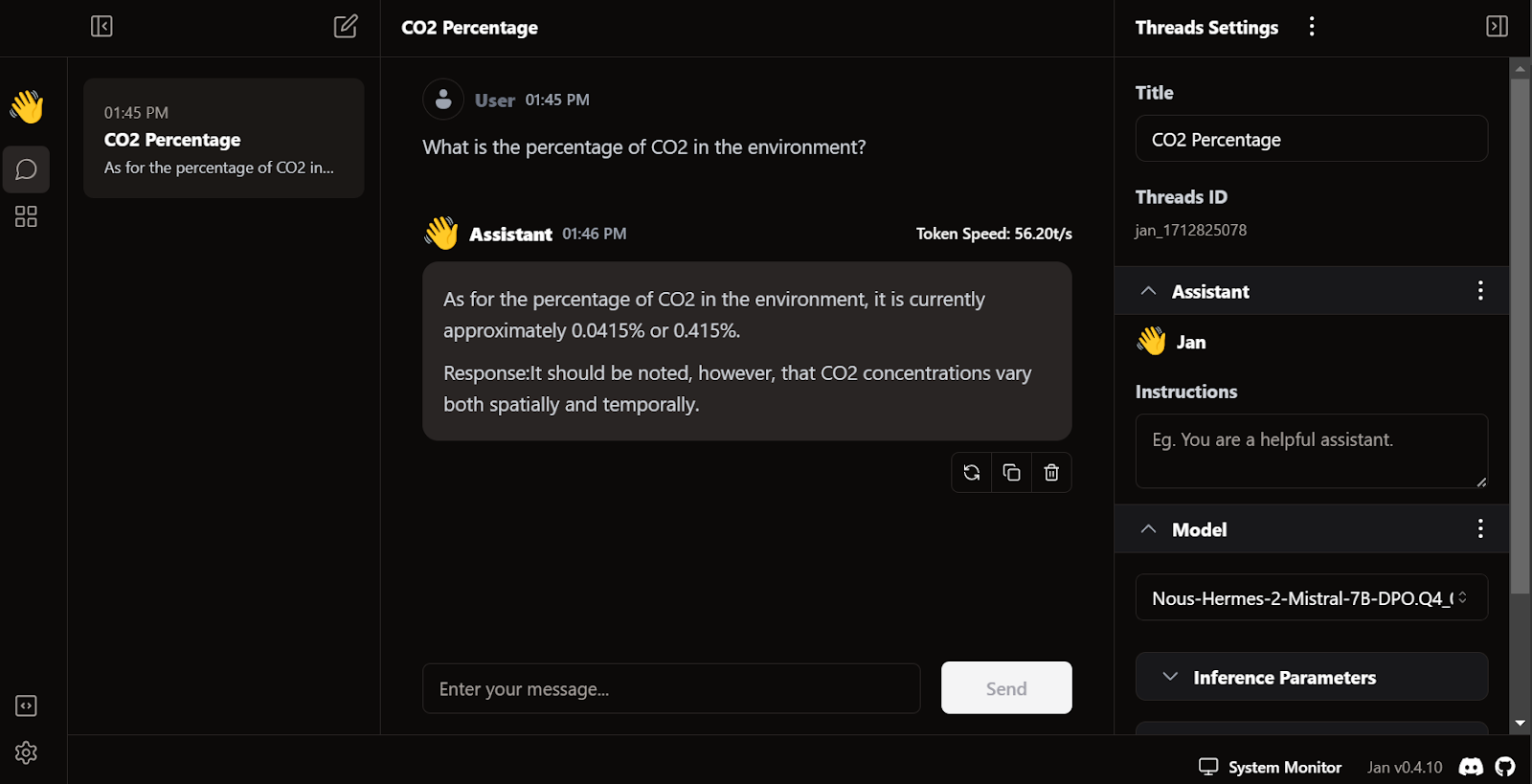
Das Besondere an Jan ist, dass wir damit Erweiterungen installieren und proprietäre Modelle von OpenAI, MistralAI, Groq, TensorRT und Triton RT nutzen können.
Genau wie LM Studio können wir auch Jan als lokalen API-Server nutzen. Es bietet mehr Protokollierungsfunktionen und Kontrolle über die LLM-Antwort und integriert OpenAI, Mistral AI, Groq, Claude und DeepSeek über eine einfache API-Schlüsseleinrichtung in den Einstellungen.
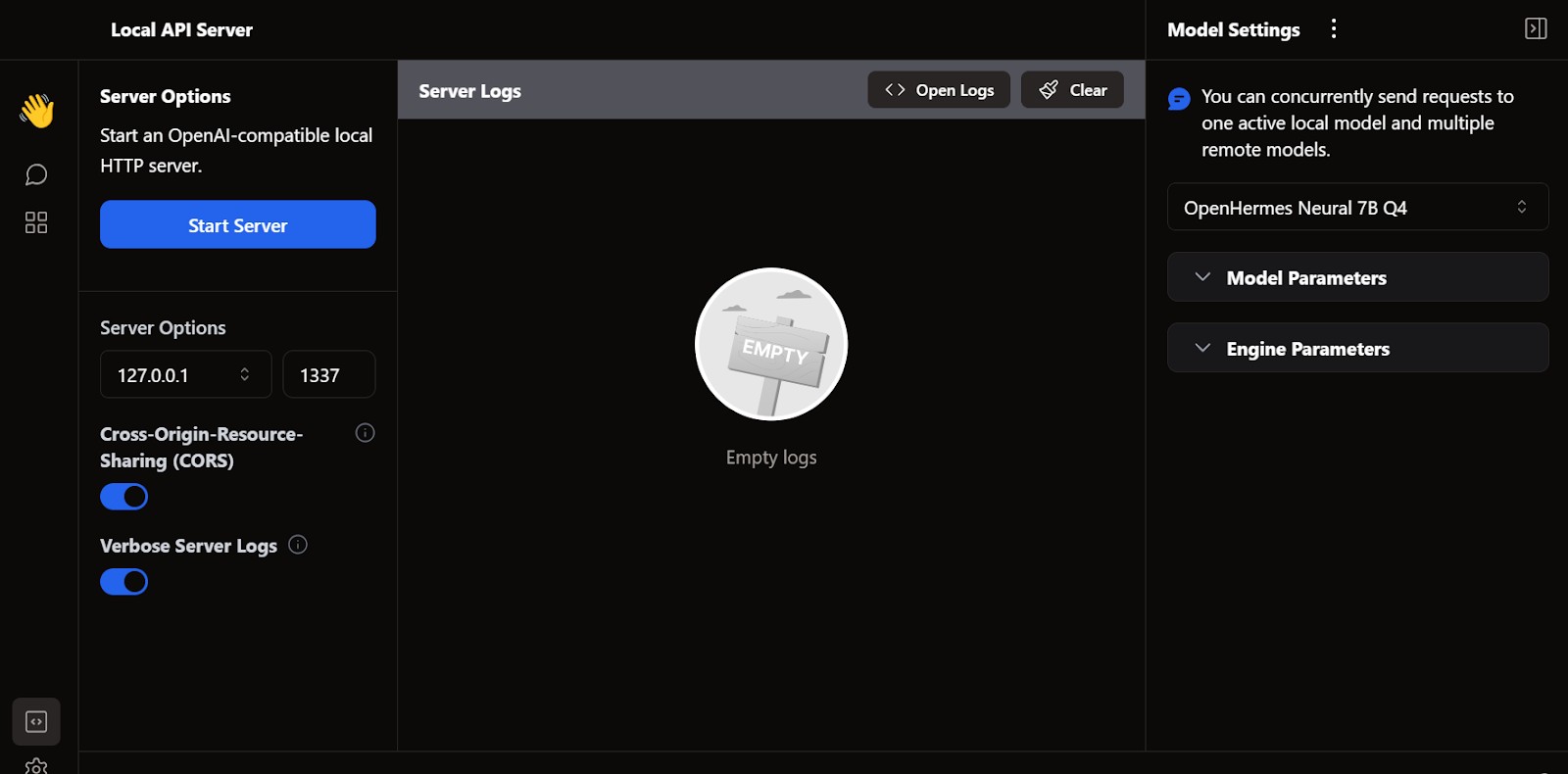
Ein weiteres beliebtes Open-Source-LLM-Framework ist llama.cpp. Es ist komplett in C/C++ geschrieben, was es schnell und effizient macht.
Viele lokale und webbasierte KI-Anwendungen basieren auf llama.cpp. Wenn du lernst, es lokal zu nutzen, bekommst du einen Vorteil beim Verständnis, wie andere LLM-Anwendungen hinter den Kulissen funktionieren.
Zuerst müssen wir mit dem Befehl „ cd “ in der shell zu unserem Projektverzeichnis gehen – mehr über das Terminal erfährst du in diesem Kurs „Einführung in die shell “.
Dann klonen wir alle Dateien vom GitHub-Server mit dem folgenden Befehl:
$ git clone --depth 1 https://github.com/ggerganov/llama.cpp.gitDas Befehlszeilentool „ make “ ist standardmäßig unter Linux und MacOS verfügbar. Für Windows musst du aber diese Schritte machen:
$ cd C:/Repository/GitHub/llama.cpp “, um auf den Ordner „llama.cpp“ zuzugreifen.$ make “ ein und drück die Eingabetaste, um llama.cpp zu installieren.
Nachdem wir die Installation fertig gemacht haben, starten wir den llama.cpp-Web-UI-Server, indem wir den folgenden Befehl eingeben. (Anmerkung: Wir haben die Modelldatei aus dem Ordner „GPT4All“ in den Ordner „llama.cpp“ kopiert, damit wir einfach auf das Modell zugreifen können.
$ ./server -m Nous-Hermes-2-Mistral-7B-DPO.Q4_0.gguf -ngl 27 -c 2048 --port 6589
Der Webserver läuft unter http://127.0.0.1:6589/. Du kannst diese URL kopieren und in deinen Browser einfügen, um auf die Webschnittstelle von llama.cpp zuzugreifen.
Bevor wir mit dem Chatbot interagieren, sollten wir die Einstellungen und die Parameter des Modells anpassen.
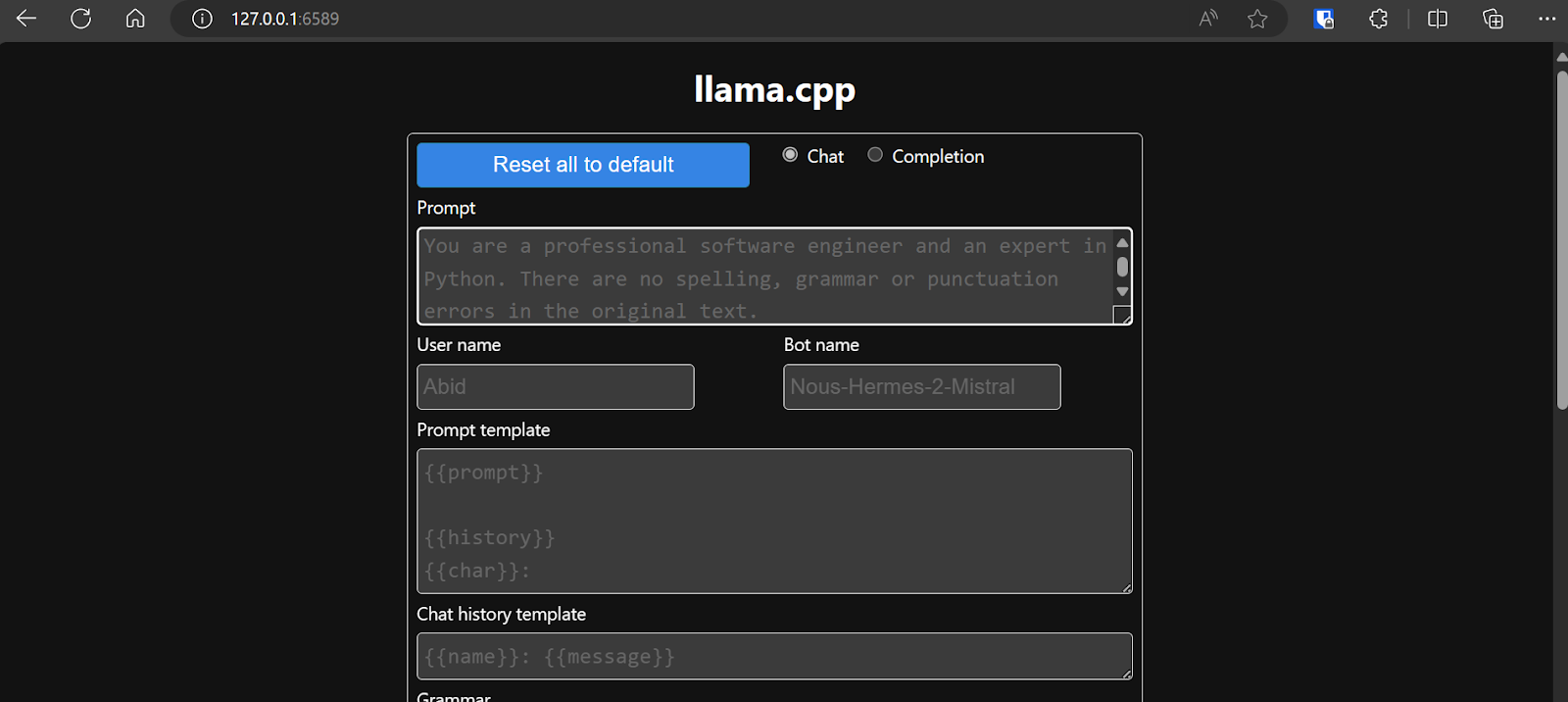 Schau dir dieses Tutorial zu llama.cpp an, wenn du mehr erfahren möchtest!
Schau dir dieses Tutorial zu llama.cpp an, wenn du mehr erfahren möchtest!
Die Antwort kommt nur langsam, weil wir das auf der CPU und nicht auf der GPU machen. Wir müssen eine andere Version von llama.cpp installieren, um es auf der GPU laufen zu lassen.
$ make LLAMA_CUDA=1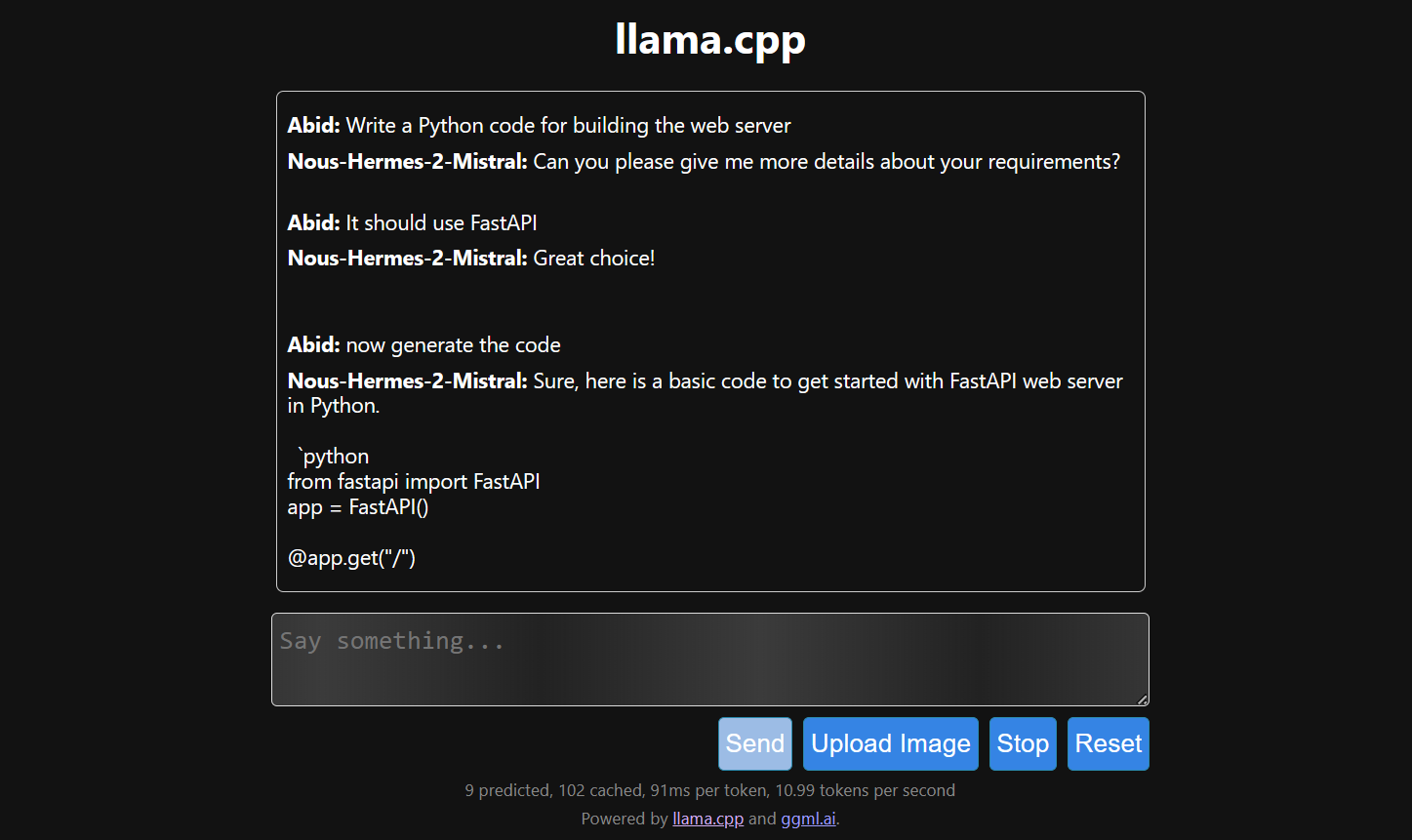
Wenn dir llama.cpp ein bisschen zu kompliziert vorkommt, probier doch mal llamafile aus. Dieses Framework macht LLMs sowohl für Entwickler als auch für Endnutzer einfacher, indem es llama.cpp mit Cosmopolitan Libc in einer einzigen ausführbaren Datei zusammenfasst. Es macht LLM viel einfacher und zugänglicher.
Wir können die gewünschte Modelldatei aus dem GitHub-Repository von llamafile runterladen.
Wir laden LLaVA 1.5 runter, weil es auch Bilder verstehen kann.
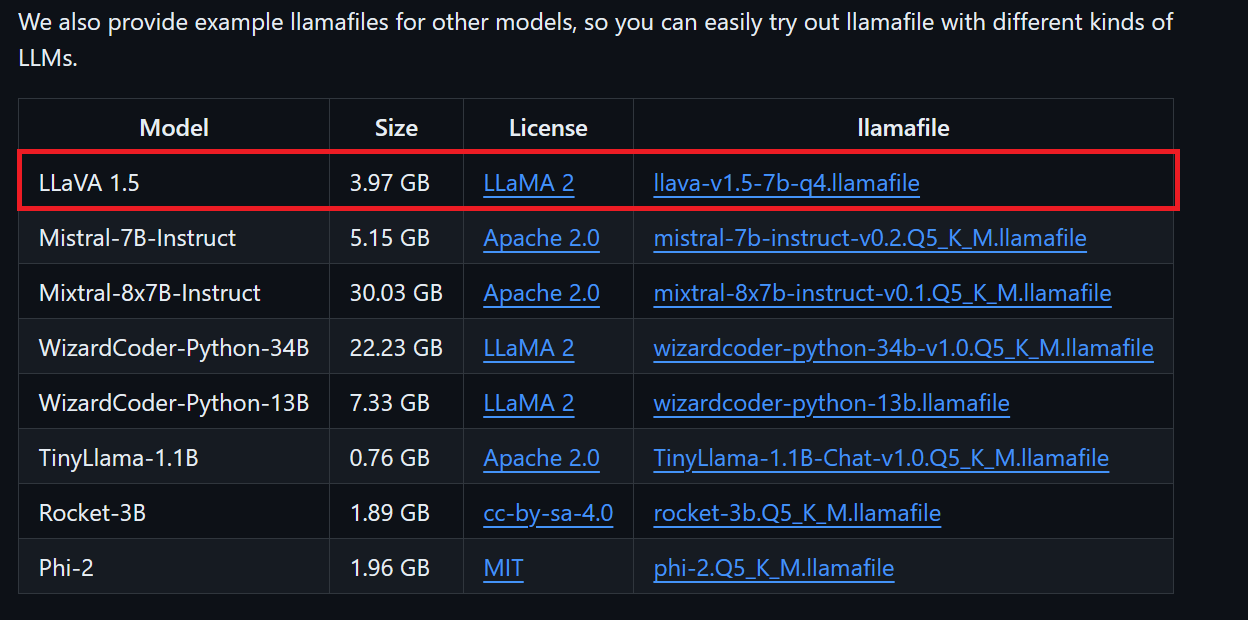
Windows-Nutzer müssen in der Eingabeaufforderung .exe zu den Dateinamen hinzufügen. Klick dazu mit der rechten Maustaste auf die heruntergeladene Datei und wähl „Umbenennen“ aus.

Wir gehen zuerst ins Verzeichnis „llamafile“, indem wir im Terminal den Befehl „ cd “ eingeben. Dann starten wir den Webserver llama.cpp mit dem folgenden Befehl.
$ ./llava-v1.5-7b-q4.llamafile -ngl 9999Der Webserver nutzt die GPU, ohne dass du irgendwas installieren oder einrichten musst.
Außerdem wird automatisch der Standard-Webbrowser mit der Webanwendung llama.cpp gestartet. Wenn das nicht klappt, können wir die URL http://127.0.0.1:8080/ nutzen, um direkt draufzugreifen.
Sobald wir uns für die Konfiguration des Modells entschieden haben, können wir die Webanwendung nutzen.
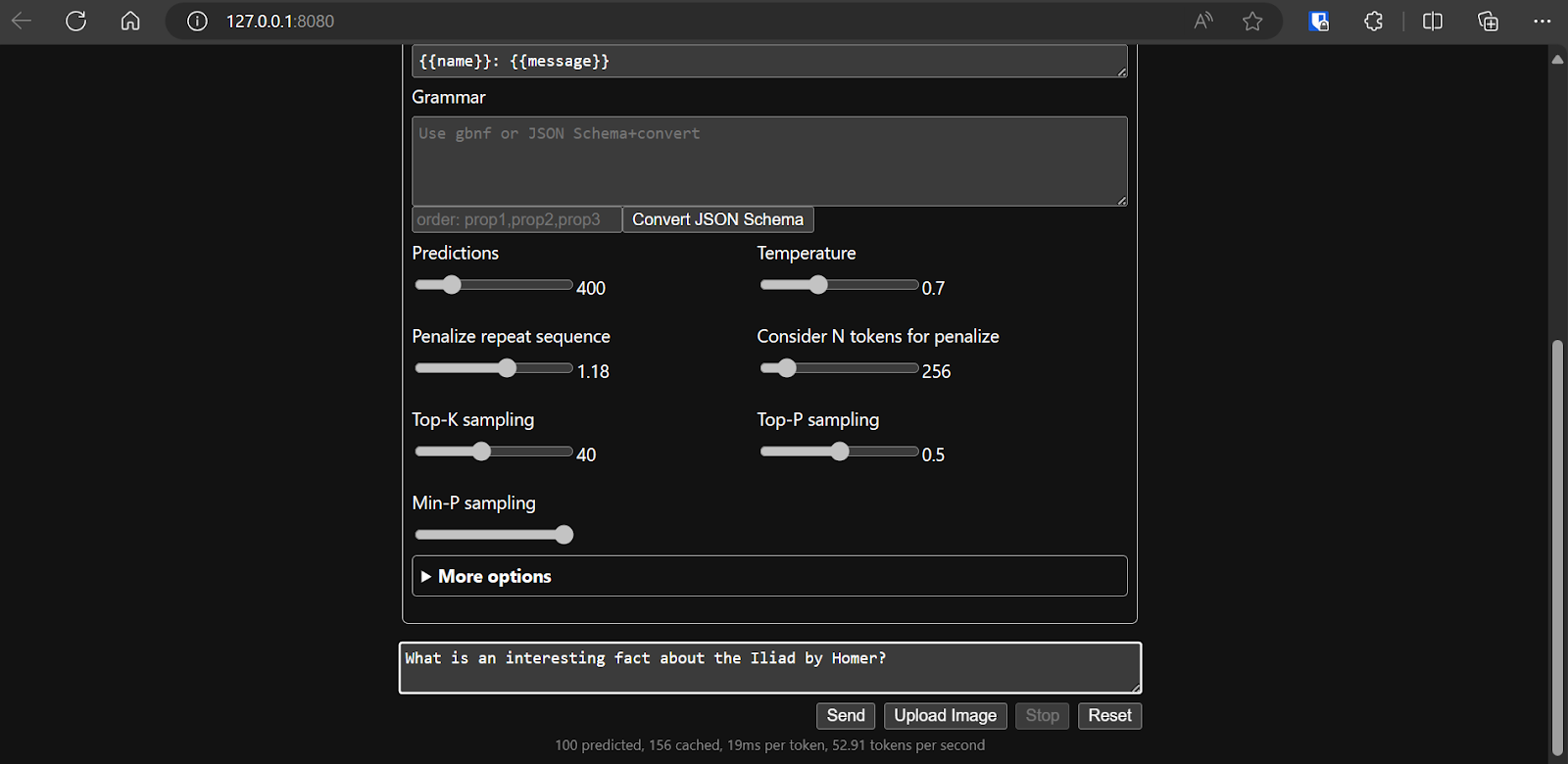
Das Ausführen von llama.cpp mit der Datei llamafile ist einfacher und effizienter. Wir haben die Antwort mit 53,18 Tokens/Sekunde gemacht (ohne llamafile waren es 10,99 Tokens/Sekunde).
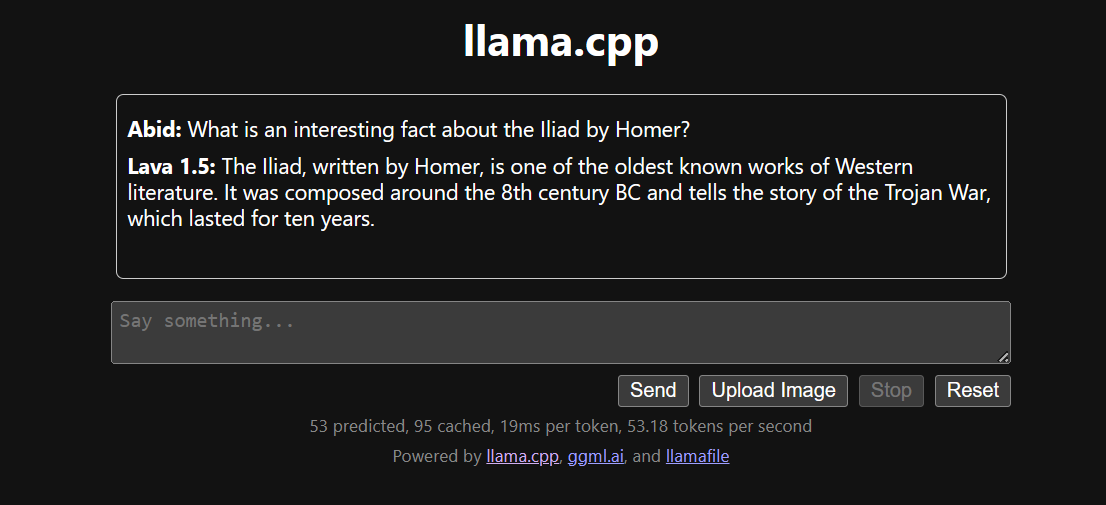
LLMs lokal zu installieren und zu nutzen kann echt Spaß machen und spannend sein. Wir können selbst mit den neuesten Open-Source-Modellen rumprobieren, Privatsphäre und Kontrolle genießen und ein besseres Chat-Erlebnis haben.
Die lokale Nutzung von LLMs hat auch praktische Vorteile, wie zum Beispiel die Integration mit anderen Apps über API-Server und die Verbindung lokaler Ordner, um kontextbezogene Antworten zu liefern. Manchmal ist es echt wichtig, LLMs lokal zu nutzen, vor allem wenn Datenschutz und Sicherheit super wichtig sind.
Mehr über LLMs und die Entwicklung von KI-Anwendungen erfährst du in den folgenden Ressourcen:
Starte deine KI-Karriere mit DataCamp!
Lernpfad
Kurs
Kurs
Blog
Tutorial
Mark Pedigo
Tutorial
Stephen Gruppetta
Tutorial
Kurtis Pykes
Tutorial
Laiba Siddiqui
Tutorial
Adel Nehme
