
Programa
Fundamentos do Negócio de IA
12 h
Usar grandes modelos de linguagem (LLMs) em sistemas locais está ficando cada vez mais popular por causa da melhoria na privacidade, controle e confiabilidade. Às vezes, esses modelos podem ser ainda mais precisos e rápidos do que o chatGPT.
Vamos mostrar sete maneiras de rodar LLMs localmente com aceleração de GPU no Windows 11, mas os métodos que abordamos também funcionam no macOS e no Linux.
Se você quer aprender sobre LLMs do zero, um bom lugar para começar é este curso sobre Modelos de Aprendizagem de Grande Porte (LLMs).
Vamos começar explorando nossa primeira estrutura LLM.
O Ollama é o ecossistema dominante para executar LLMs, como o Llama 4, Mistral 3e Gemma 3 localmente.
Além disso, vários aplicativos aceitam a integração com o Ollama, o que o torna uma ferramenta excelente para acessar modelos de linguagem de forma mais rápida e fácil na nossa máquina local.
O Ollama agora é totalmente compatível com a API OpenAI, o que faz dele um substituto direto para o serviço em nuvem da OpenAI. Recursos recentes incluem chamada de função, saída JSON estruturada, Flash Attention para modelos de visão e inferência 30% mais rápida em Apple Silicon e GPUs AMD.
A gente pode baixar o Ollama na página de downloads.
Depois de instalarmos (usando as configurações padrão), o logotipo do Ollama vai aparecer na bandeja do sistema.
A gente pode baixar o modelo Llama 3 digitando o seguinte comando no terminal:
$ ollama run llama3O Llama 3 já está pronto para ser usado! Abaixo, vemos uma lista de comandos que precisamos usar se quisermos usar outros LLMs:
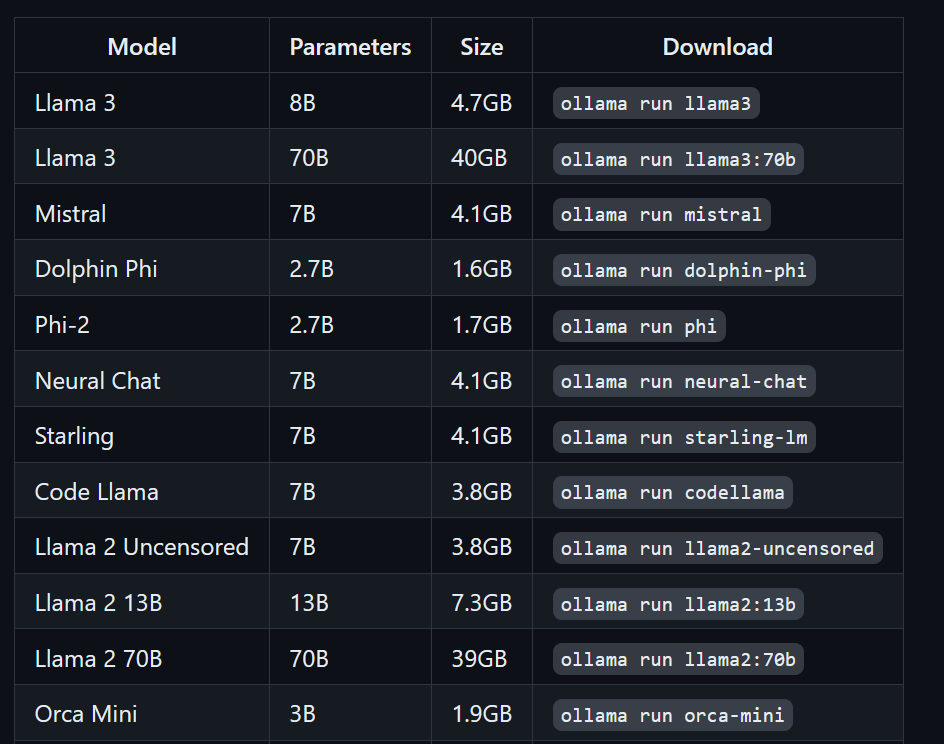
Pra acessar os modelos que já foram baixados e estão disponíveis na pasta llama.cpp, a gente precisa:
cd.$ cd C:/Repository/GitHub/llama.cppModelfile e adicione a linha "FROM ./Nous-Hermes-2-Mistral-7B-DPO.Q4_0.gguf".$ echo "FROM ./Nous-Hermes-2-Mistral-7B-DPO.Q4_0.gguf" > Modelfile$ ollama create NHM-7b -f Modelfile
$ ollama run NHM-7bCom esse método, a gente pode baixar qualquer LLM do Hugging Face com a extensão .gguf e usar no terminal. Se você quiser saber mais, dá uma olhada nesse curso sobre como trabalhar com o Hugging Face.
O LM Studio é uma plataforma completa pra rodar LLMs localmente e oferece ajuste fino nativo. Além disso, ele suporta vários modelos simultâneos, decodificação especulativa (tokens 1,5x-3x mais rápidos) e integração de RAG de documentos.
A gente pode baixar o instalador na página inicial do LM Studio.
Quando o download terminar, a gente instala o aplicativo com as opções padrão.
Finalmente, lançamos o LM Studio!
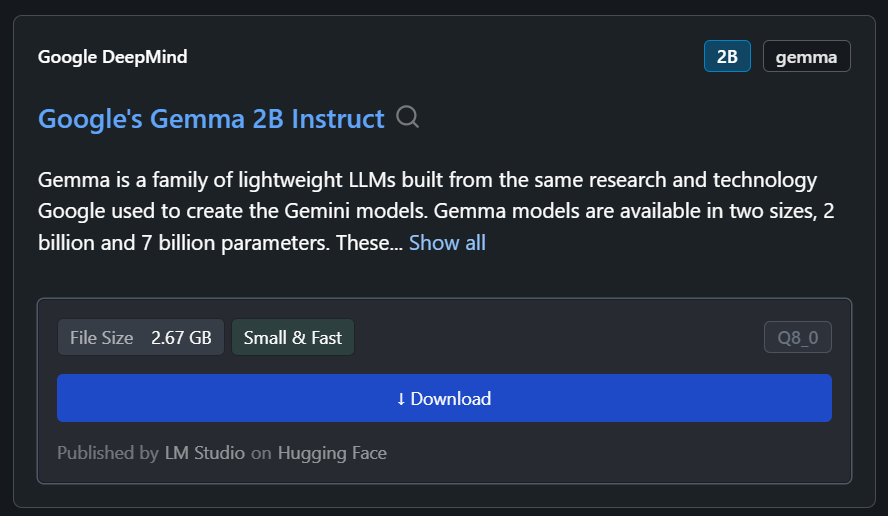
A gente pode baixar qualquer modelo do Hugging Face usando a função de pesquisa.
No nosso caso, vamos baixar o modelo menor, o Gemma 2B Instruct do Google.
A gente pode escolher o modelo baixado no menu suspenso na parte de cima e bater um papo com ele como sempre. O LM Studio tem mais opções de personalização do que o GPT4All.
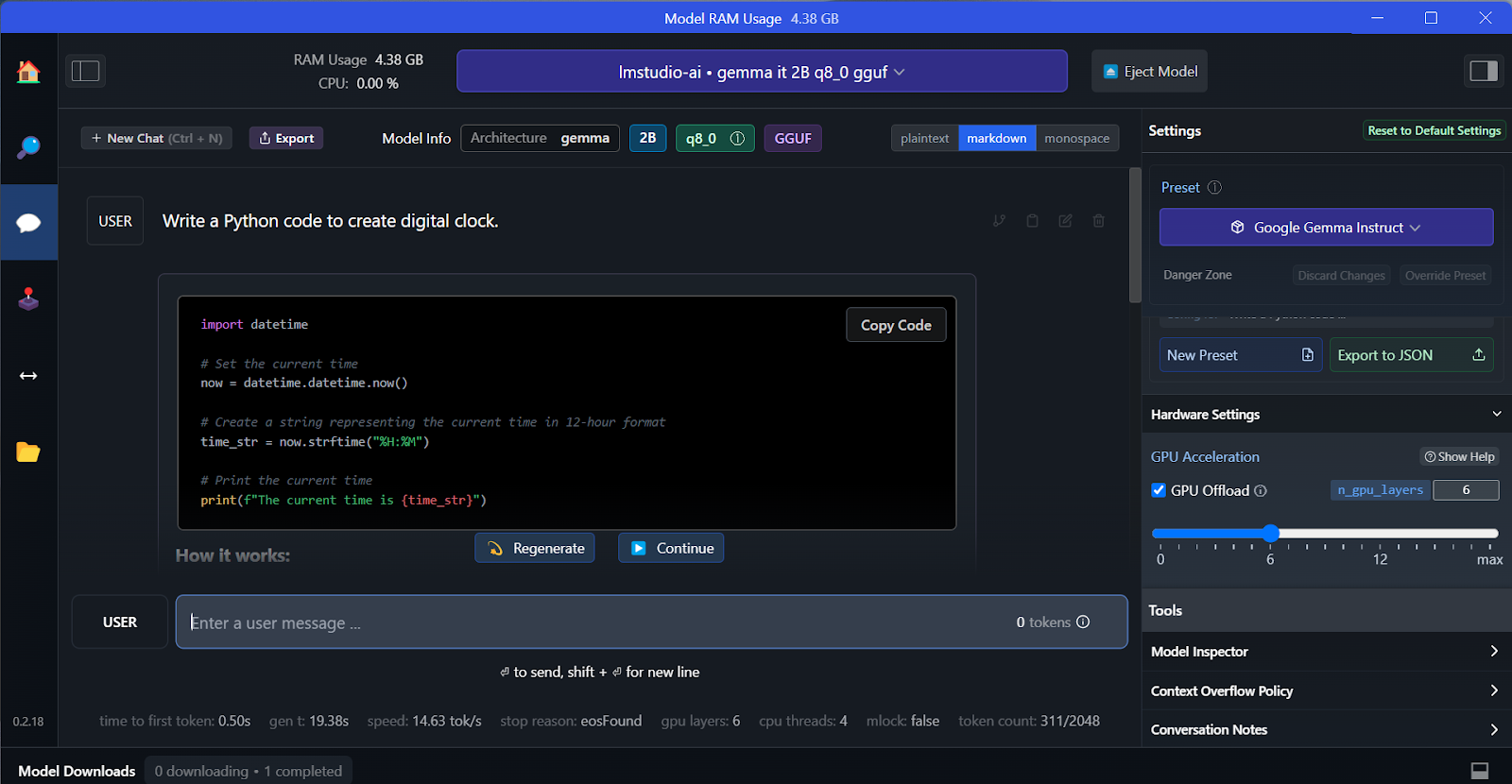
Assim como o GPT4All, dá pra personalizar o modelo e ativar o servidor API com um clique. Pra acessar o modelo, a gente pode usar o pacote Python da API OpenAI, CURL, ou integrar diretamente com qualquer aplicativo.
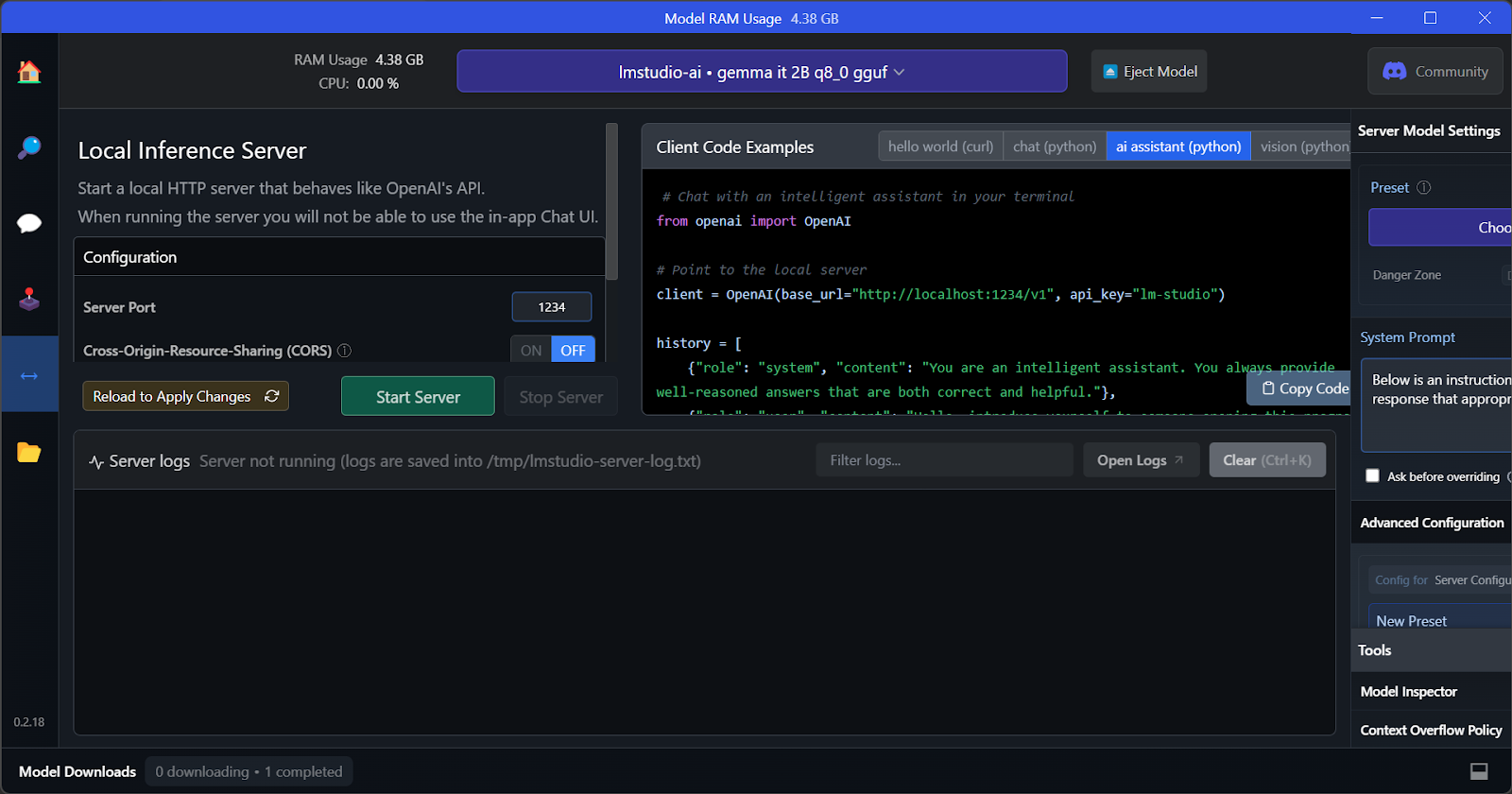
A principal característica do LM Studio é que ele oferece a opção de executar e servir vários modelos ao mesmo tempo. Isso permite que os usuários comparem resultados de diferentes modelos e os utilizem para várias aplicações. Pra rodar várias sessões de modelo, a gente precisa de uma VRAM de GPU alta.
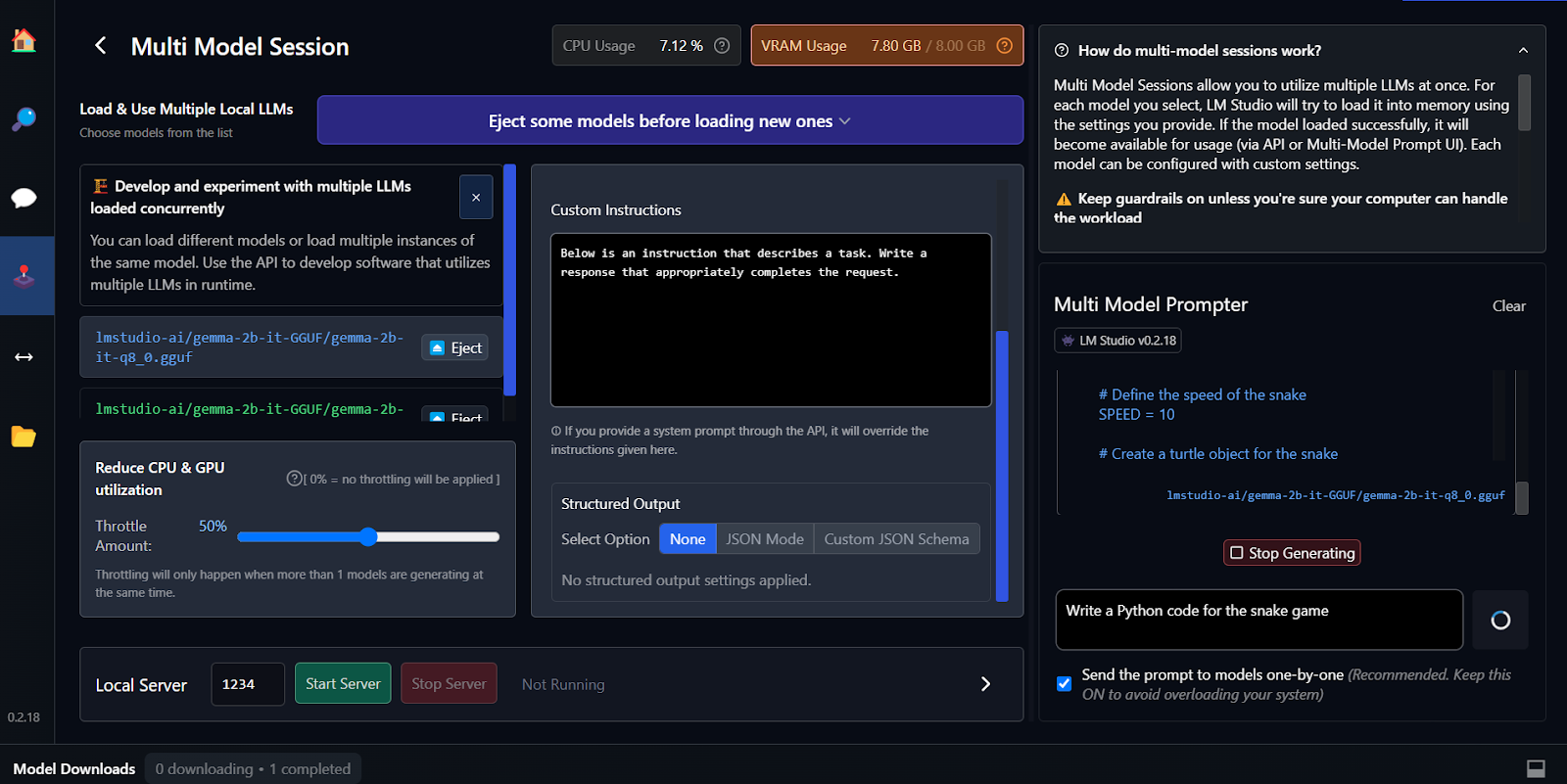
O ajuste fino é outra maneira de criar respostas personalizadas e que entendem o contexto. Você pode aprender a ajustar seu modelo Google Gemma seguindo o tutorial Ajustando o Google Gemma: Aprimorando LLMs com instruções personalizadas. Você vai aprender a fazer inferência em GPUs/TPUs e ajustar o modelo Gemma 7b-it mais recente em um conjunto de dados de role-play.
O vLLM é um mecanismo de inferência de código aberto para rodar LLMs em escala de produção. Diferente do Ollama ou do LM Studio, o vLLM prioriza a taxa de transferência e a latência para cenários com vários usuários.
A principal inovação é o PagedAttention, que gerencia a memória da GPU como se fosse memória virtual, reutilizando pequenas páginas em vez de reservar blocos enormes, junto com o processamento contínuo em lotes. Os benchmarks reais mostram que o vLLM entrega 793 tokens por segundo no Llama 70B, contra os 41 tokens por segundo do Ollama sob carga simultânea.
O vLLM também suporta paralelismo tensorial entre GPUs, cache de prefixos e processamento em lote multi-LoRA para servir variantes ajustadas simultaneamente.
No Mac e no Linux, o vLLM pode ser instalado facilmente usando o pip.
No Linux com CUDA 11.8+:
pip install vllmNo macOS com Apple Silicon:
python3.11 -m venv vllm_env
source vllm_env/bin/activate
pip install vllmNo momento, não tem suporte oficial para Windows. Mas tem jeitos alternativos usando WSL2 ou Docker.
Inicie o servidor compatível com OpenAI:
vllm serve meta-llama/Llama-2-7b-hf --port 8000 --gpu-memory-utilization 0.9Para modelos 70B em várias GPUs:
vllm serve meta-llama/Llama-2-70b-hf --tensor-parallel-size 2 --port 8000Para processamento em lote no Python:
from vllm import LLM, SamplingParams
llm = LLM(model="meta-llama/Llama-2-7b-hf", dtype="bfloat16")
sampling_params = SamplingParams(temperature=0.8, max_tokens=256)
outputs = llm.generate(["Write hello world", "Explain AI"], sampling_params)Para fazer uma consulta, use o SDK da OpenAI:
from openai import OpenAI
client = OpenAI(base_url='http://localhost:8000/v1', api_key='any')
response = client.chat.completions.create(
model='meta-llama/Llama-2-7b-hf',
messages=[{'role': 'user', 'content': 'What is ML?'}],
max_tokens=200
)
print(response.choices[0].message.content)Outra opção é executá-lo via cURL:
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{"model": "meta-llama/Llama-2-7b-hf", "messages": [{"role": "user", "content": "Hello"}]}'Escolha o vLLM para APIs de produção que atendem centenas de usuários ao mesmo tempo; use o Ollama para desenvolvimento local.
Um dos aplicativos LLM locais mais populares e bonitos é o Jan. É uma alternativa ao chatGPT que prioriza a privacidade.
A gente pode baixar o instalador no site Jan.ai.
Depois de instalar o aplicativo Jan com as configurações padrão, estamos prontos para iniciá-lo.
Quando falamos sobre o GPT4All e o LM Studio, já baixamos dois modelos. Em vez de baixar outro, vamos importar os que já temos indo até a página do modelo e clicando no botão Importar Modelo.
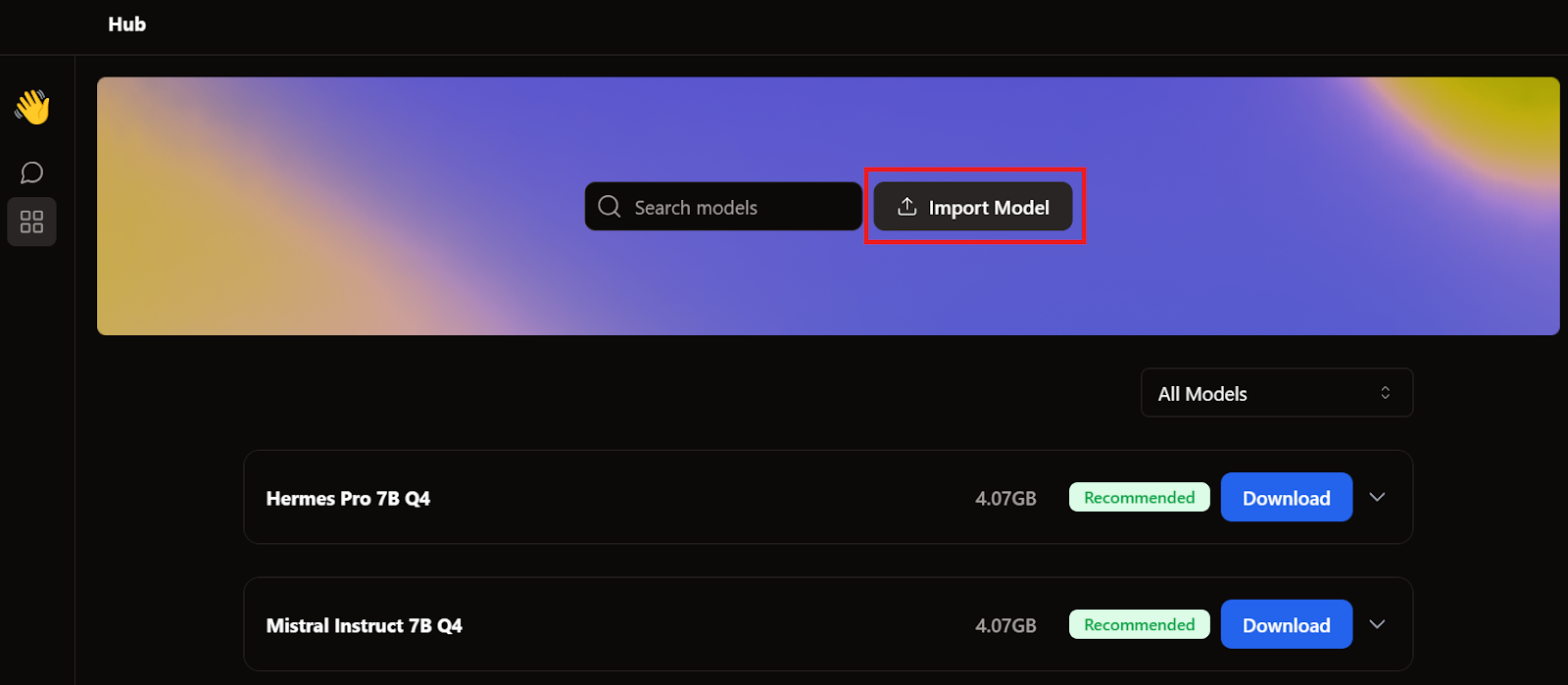
Depois, vamos para o diretório de aplicativos, escolhemos os modelos GPT4All e LM Studio e importamos cada um deles.
Pra acessar os modelos locais, vamos até a interface do usuário do chat e abrimos a seção de modelos no painel direito.
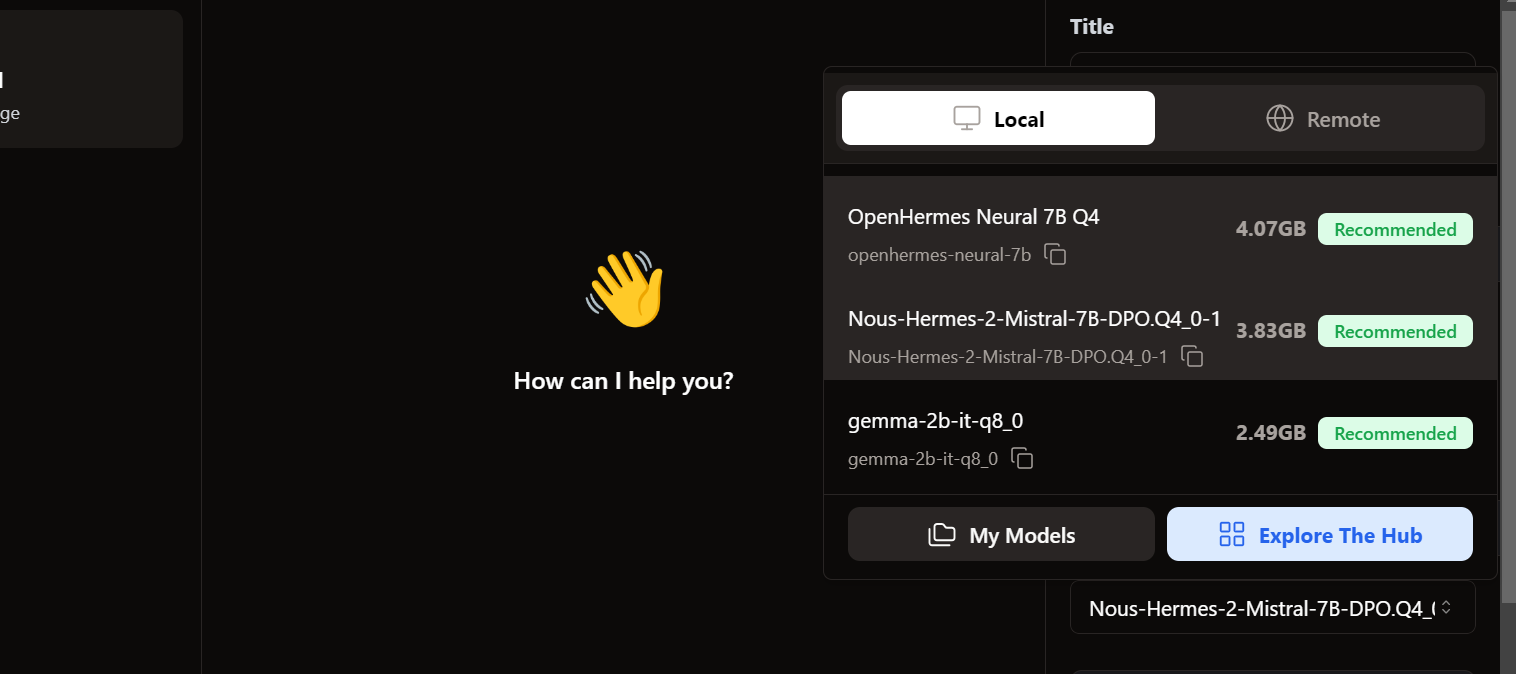
Vemos que nossos modelos importados já estão lá. Podemos escolher o que quisermos e começar a usar na hora!
A geração de respostas é super rápida. A interface do usuário parece natural, parecida com o chatGPT, e não deixa seu laptop ou PC lento.
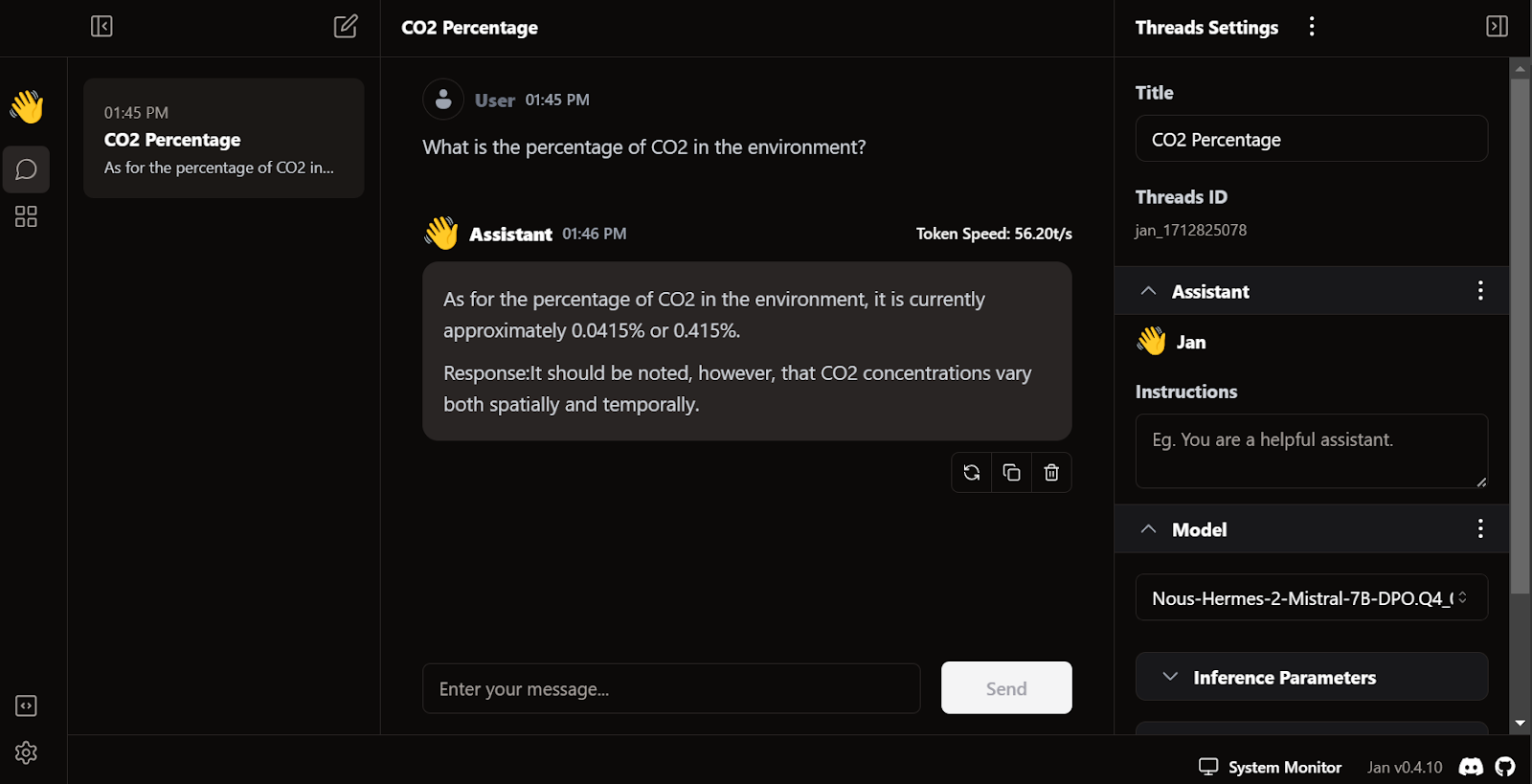
O diferencial do Jan é que ele permite instalar extensões e usar modelos proprietários da OpenAI, MistralAI, Groq, TensorRT e Triton RT.
Assim como o LM Studio, também podemos usar o Jan como um servidor API local. Ele oferece mais recursos de registro e controle sobre a resposta do LLM, além de integra OpenAI, Mistral AI, Groq, Claude e DeepSeek por meio de uma configuração simples de chave API nas configurações.
Outra estrutura LLM de código aberto bem popular é a llama.cpp. É escrito só em C/C++, o que o torna rápido e eficiente.
Muitos aplicativos de IA locais e baseados na web são feitos com o llama.cpp. Então, aprender a usar isso localmente vai te dar uma vantagem pra entender como outras aplicações LLM funcionam nos bastidores.
Primeiro, precisamos ir para o diretório do nosso projeto usando o comando ` cd ` no shell — você pode aprender mais sobre o terminal neste curso Introdução ao Shell.
Depois, a gente clona todos os arquivos do servidor GitHub usando o comando abaixo:
$ git clone --depth 1 https://github.com/ggerganov/llama.cpp.gitA ferramenta de linha de comando ` make ` já vem por padrão no Linux e no MacOS. Mas, no Windows, a gente precisa fazer o seguinte:
$ cd C:/Repository/GitHub/llama.cpp ` para acessar a pasta `llama.cpp`.$ make e aperte Enter para instalar o llama.cpp.
Depois de terminar a instalação, vamos rodar o servidor de interface do usuário web llama.cpp digitando o comando abaixo. (Observação: Copiamos o arquivo do modelo da pasta GPT4All para a pasta llama.cpp, pra gente poder acessar o modelo facilmente.
$ ./server -m Nous-Hermes-2-Mistral-7B-DPO.Q4_0.gguf -ngl 27 -c 2048 --port 6589
O servidor web está funcionando em http://127.0.0.1:6589/. Você pode copiar este URL e colá-lo no seu navegador para acessar a interface web llama.cpp.
Antes de interagir com o chatbot, a gente deve ajustar as configurações e os parâmetros do modelo.
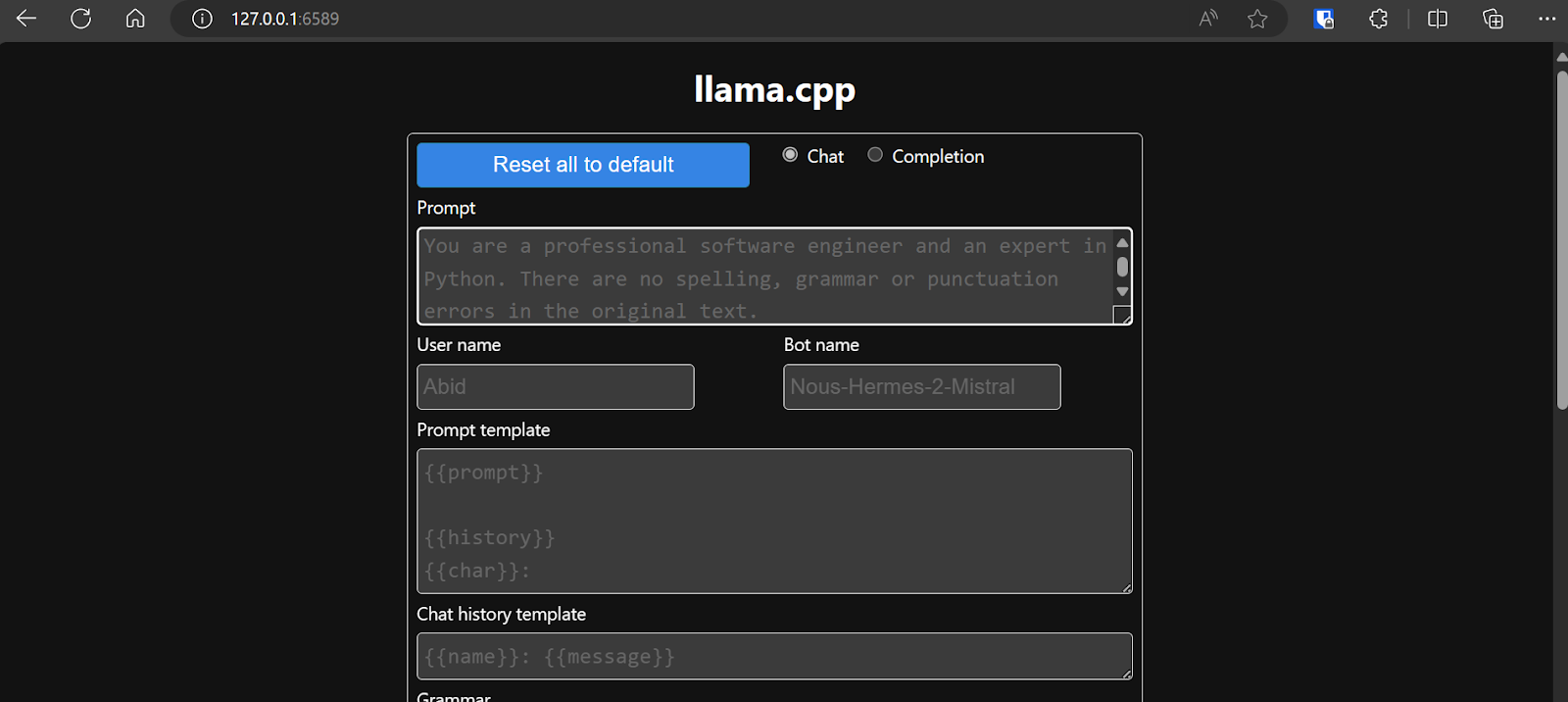 Dá uma olhada neste tutorial llama.cpp se quiser saber mais!
Dá uma olhada neste tutorial llama.cpp se quiser saber mais!
A geração de respostas é lenta porque a gente a executa na CPU, e não na GPU. Precisamos instalar uma versão diferente do llama.cpp para rodar na GPU.
$ make LLAMA_CUDA=1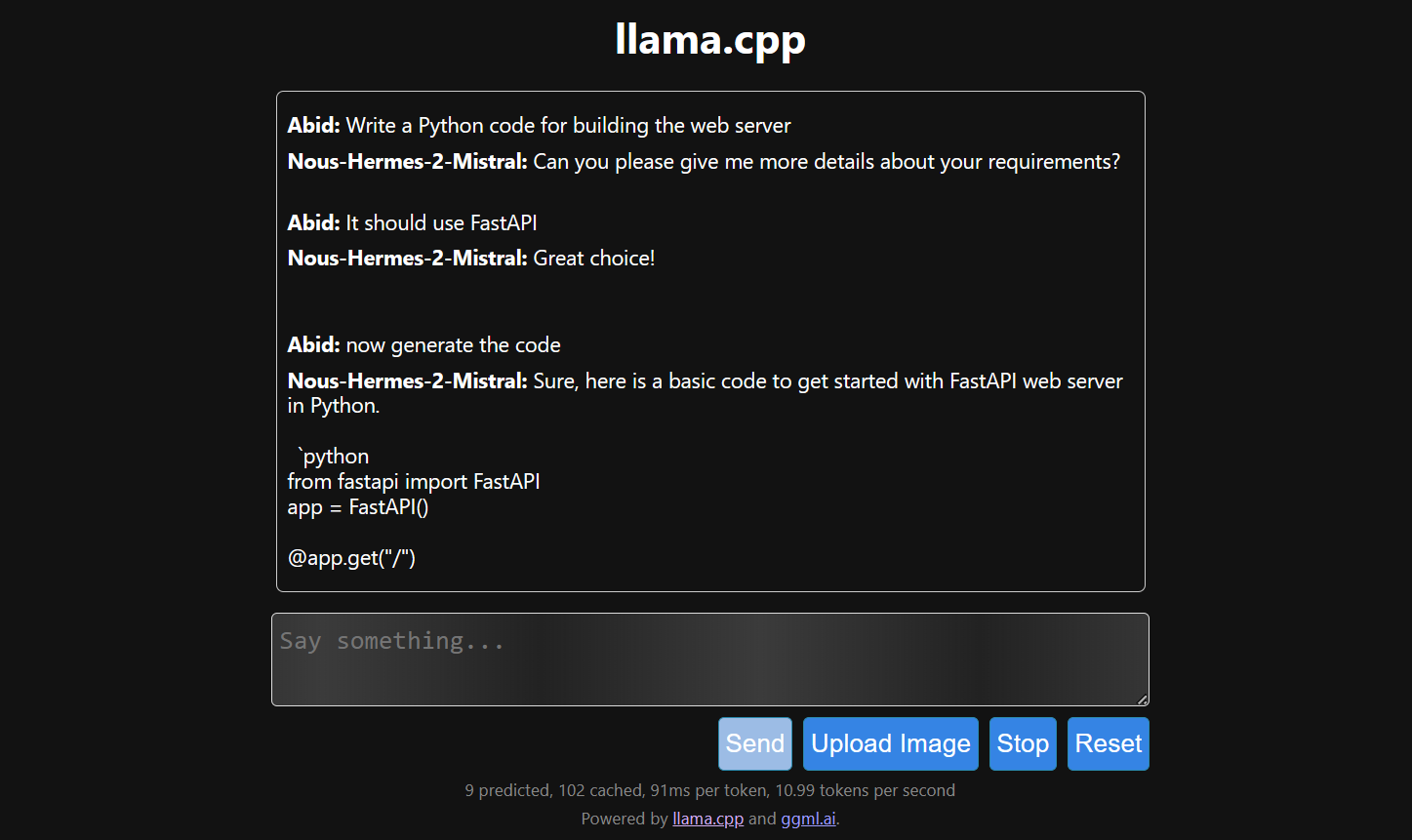
Se você achar o llama.cpp um pouco complicado, dá uma olhada no llamafile. Essa estrutura simplifica os LLMs tanto para desenvolvedores quanto para usuários finais, combinando llama.cpp com Cosmopolitan Libc em um único arquivo executável. Isso tira toda a complexidade dos LLMs, deixando-os mais acessíveis.
A gente pode baixar o arquivo do modelo que a gente quiser do repositório GitHub do llamafile.
Vamos baixar o LLaVA 1.5 porque ele também consegue entender imagens.
Os usuários do Windows precisam adicionar .exe aos nomes dos arquivos no terminal. Para fazer isso, clique com o botão direito do mouse no arquivo baixado e selecione Renomear.

Primeiro, vamos para o diretório llamafile usando o comando ` cd ` no terminal. Depois, a gente executa o comando abaixo para iniciar o servidor web llama.cpp.
$ ./llava-v1.5-7b-q4.llamafile -ngl 9999O servidor web usa a GPU sem que você precise instalar ou configurar nada.
Ele também vai abrir automaticamente o navegador padrão com o aplicativo web llama.cpp rodando. Se não funcionar, dá pra usar o URL http://127.0.0.1:8080/ pra acessar direto.
Depois de decidirmos a configuração do modelo, podemos começar a usar o aplicativo web.
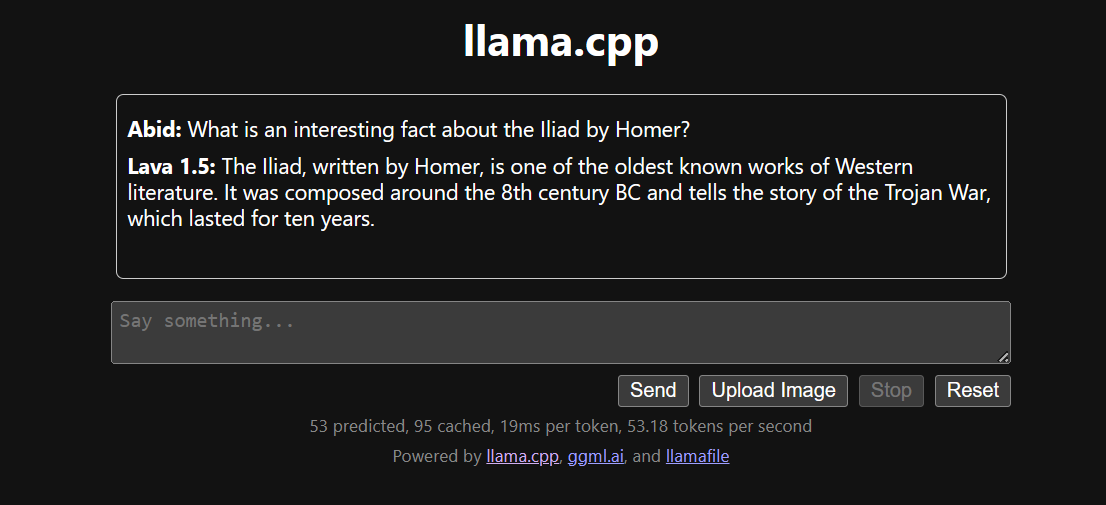
Executar o llama.cpp usando o llamafile é mais fácil e eficiente. Geramos a resposta com 53,18 tokens/segundo (sem o llamafile, a taxa era de 10,99 tokens/segundo).
Instalar e usar LLMs localmente pode ser uma experiência divertida e emocionante. Podemos experimentar os modelos de código aberto mais recentes por conta própria, curtir privacidade, controle e uma experiência de bate-papo melhorada.
Usar LLMs localmente também tem aplicações práticas, como integrá-los com outros aplicativos usando servidores API e conectar pastas locais para fornecer respostas sensíveis ao contexto. Em alguns casos, é essencial usar LLMs localmente, especialmente quando a privacidade e a segurança são fatores críticos.
Você pode aprender mais sobre LLMs e como criar aplicativos de IA conferindo esses recursos:
Comece sua carreira em IA com o DataCamp!
Programa
Curso
Curso
blog
Abid Ali Awan
8 min
blog
Abid Ali Awan
10 min
blog
Abid Ali Awan
13 min
Tutorial
Zoumana Keita
Tutorial
Abid Ali Awan
Tutorial
Moez Ali



