Cursus
Agentic Systems ontwerpen met LangChain
3 Hr
12.1K
Qwen3.5 is Alibaba’s nieuwste Qwen-modellenreeks en bouwt voort op de sterke prestaties van eerdere Qwen-modellen bij redeneren, coderen en multimodale taken.
Onafhankelijke benchmarkevaluaties laten zien dat het Qwen3.5-397B-A17B-model hoge scores behaalt op veelgebruikte tests zoals LiveCodeBench en AIME26. Het presteert vaak beter dan toonaangevende modellen zoals GPT-5.2 en Claude Opus 4.5 in een meerderheid van de beoordeelde categorieën, en levert een aanzienlijk hogere doorvoer dan eerdere Qwen-generaties.
Bron: Qwen/Qwen3.5-397B-A17B · Hugging Face
In deze tutorial gaan we:
Voordat je Qwen3.5 lokaal draait, moet je controleren of je setup voldoet aan de hardware- en softwarevereisten voor soepele inferentie. In deze tutorial gebruiken we een NVIDIA H200 GPU met 141GB VRAM, gecombineerd met 240GB RAM, wat ruim voldoende geheugen biedt om de MXFP4_MOE-versie van Qwen3.5 efficiënt te draaien met MoE-offloading.
Ter referentie: de Unsloth 4-bit dynamische quant UD-Q4_K_XL gebruikt ongeveer 214GB schijfruimte. Deze past direct op een 256GB M3 Ultra en draait ook goed op een enkele 24GB GPU met 256GB RAM, met 25+ tokens per seconde dankzij MoE-offloading. Kleinere 3-bit quants passen binnen 192GB RAM, terwijl versies met hogere precisie van 8-bit tot wel 512GB gecombineerd RAM en VRAM kunnen vereisen.
In het algemeen geldt: voor de beste prestaties zou je VRAM + RAM samen ongeveer gelijk moeten zijn aan de grootte van het gequantizeerde model dat je downloadt. Zo niet, dan kan llama.cpp offloaden naar SSD-opslag, maar de inferentie wordt dan langzamer.
Aan de softwarekant moet je de nieuwste NVIDIA GPU-drivers geïnstalleerd hebben, samen met een recente CUDA Toolkit, om volledige compatibiliteit met llama.cpp en CUDA-versnelde inferentie te garanderen.
Nu de vereisten op orde zijn, lopen we stap voor stap door hoe je Qwen 3.5 lokaal gebruikt:
Om Qwen3.5 lokaal te draaien, heb je toegang nodig tot een krachtige GPU-machine. Omdat de meeste laptops en desktops niet genoeg VRAM of geheugen hebben voor modellen van dit formaat, gebruiken we in plaats daarvan een GPU-VM in de cloud.
In deze tutorial gebruiken we Hyperbolic om het model privé te draaien. Je kunt ook andere aanbieders gebruiken, zoals RunPod, Vast.ai of elk GPU-VM-platform dat je verkiest. We kozen voor Hyperbolic omdat het momenteel enkele van de meest kostenefficiënte GPU-instances biedt.
Start met het lanceren van een nieuwe instance met een enkele H200 GPU.
Zodra de machine is opgestart, zie je het publieke IP-adres en het SSH-commando dat nodig is om vanaf je lokale terminal te verbinden.
Controleer vóór het verbinden of je lokaal SSH hebt ingesteld en dat je je publieke SSH-sleutel hebt toegevoegd bij het aanmaken van de virtuele machine.
Wanneer de instance klaar is, maak je verbinding via SSH met port forwarding. Dit is belangrijk, omdat we de llama.cpp-inferenceserver lokaal willen benaderen via poort 8080:
ssh -L 8080:localhost:8080 root@129.212.191.53De eerste keer dat je verbindt, typ je yes om te bevestigen, en daarna authenticeren met je SSH-sleutel.
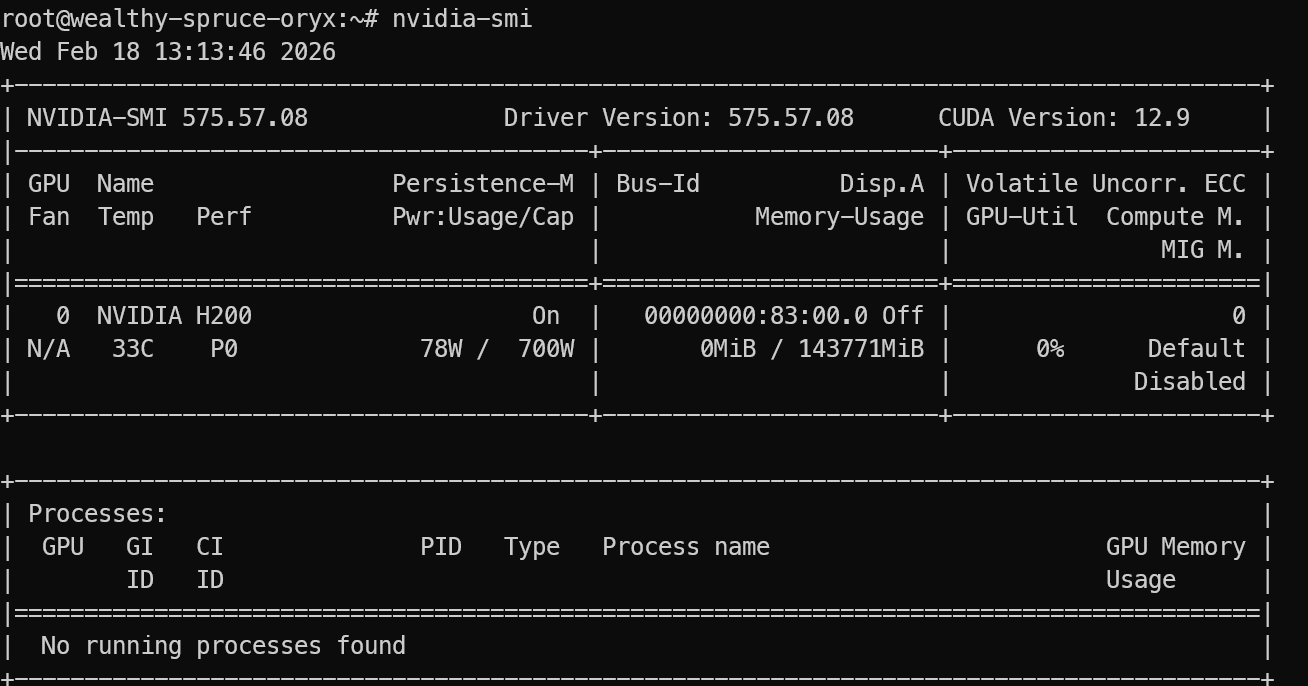
Controleer na het inloggen of de GPU correct wordt gedetecteerd:
nvidia-smi Je zou de NVIDIA H200 in de output moeten zien staan.
Installeer tot slot de vereiste Linux-pakketten om llama.cpp te downloaden, te bouwen en te draaien:
sudo apt update
sudo apt install pciutils build-essential cmake curl libcurl4-openssl-dev -yZodra dit klaar is, is je omgeving gereed om llama.cpp te installeren en Qwen3.5 lokaal te draaien.
llama.cpp is een open-source C- en C++-inference-engine waarmee je grote taalmodellen lokaal kunt draaien met minimale setup, en ondersteunt zowel CPU- als GPU-versnelling.
Kloon eerst de llama.cpp-repository:
git clone https://github.com/ggml-org/llama.cppConfigureer vervolgens een CUDA-ingeschakelde build met CMake. We schakelen CUDA in met -DGGML_CUDA=ON en stellen de CUDA-architectuur in op 90a omdat we een NVIDIA H200 (Hopper-klasse) gebruiken. Dit helpt de build om GPU-code te genereren die is geoptimaliseerd voor Hopper-features.
cmake llama.cpp -B llama.cpp/build \
-DGGML_CUDA=ON \
-DCMAKE_BUILD_TYPE=Release \
-DCMAKE_CUDA_ARCHITECTURES="90a"
Compileer nu de serverbinary. llama-server is de ingebouwde REST-server waarmee je llama.cpp als een API-endpoint kunt aanbieden:
cmake --build llama.cpp/build --config Release -j --clean-first --target llama-server
Kopieer ten slotte de gecompileerde binaries naar de hoofdmap zodat ze makkelijk te draaien zijn:
cp llama.cpp/build/bin/llama-* llama.cppNu llama.cpp is geïnstalleerd, is de volgende stap het downloaden van de daadwerkelijke Qwen3.5 modelgewichten in GGUF-formaat. Deze bestanden zijn groot, dus de Hugging Face CLI is de meest betrouwbare manier om ze direct op je GPU-machine binnen te halen.
We installeren eerst Python omdat de downloadtools en authenticatiehulpprogramma’s van Hugging Face als Python-pakketten worden verspreid. Hoewel llama.cpp zelf in C++ is geschreven, maakt Python het veel eenvoudiger om modeldownloads en -overdrachten te beheren.
Begin met het installeren van pip:
sudo apt install python3-pipInstalleer vervolgens de Hugging Face Hub-client samen met performance-helpers. hf_transfer en hf-xet versnellen downloads aanzienlijk, wat belangrijk is bij het binnenhalen van honderden gigabytes aan modelfiles:
pip -q install -U huggingface_hub hf-xet
pip -q install -U hf_transferDownload nu het Qwen3.5-model van Hugging Face. In deze tutorial halen we alleen de MXFP4_MOE-variant op, die is geoptimaliseerd voor efficiënte MoE-inferentie:
hf download unsloth/Qwen3.5-397B-A17B-GGUF \
--local-dir models/Qwen3.5 \
--include "*MXFP4_MOE*"
Na het downloaden staan de modelbestanden in models/Qwen3.5, klaar om in llama.cpp te worden geladen voor lokale inferentie.
Nu kunnen we Qwen3.5 starten met llama-server. Dit geeft ons een OpenAI-compatibele API-endpoint die we vanuit lokale tools en apps kunnen aanroepen.
We hebben de server geoptimaliseerd voor een single-GPU-setup met drie belangrijke dingen. Ten eerste schakelen we --fit on in zodat llama.cpp het model automatisch balanceert over GPU-VRAM en systeem-RAM, in plaats van te falen wanneer het model niet volledig in VRAM past.
Ten tweede gebruiken we een grotere contextwindow met --ctx-size 16384 zodat de server langere prompts aankan. Ten derde schakelen we --jinja in en geven we --chat-template-kwargs mee om de chatopmaak te sturen en thinking-modus uit te zetten voor snellere, directere reacties.
Start de server met:
./llama.cpp/llama-server \
--model models/Qwen3.5/MXFP4_MOE/Qwen3.5-397B-A17B-MXFP4_MOE-00001-of-00006.gguf \
--alias "Qwen3.5" \
--host 0.0.0.0 \
--port 8080 \
--fit on \
--jinja \
--ctx-size 16384 \
--temp 0.7 \
--top-p 0.8 \
--top-k 20 \
--min-p 0.00 \
--chat-template-kwargs "{\"enable_thinking\": false}"Tijdens het laden van het model zie je dat het zowel GPU-VRAM als systeemgeheugen gebruikt. Dat is te verwachten bij een groot MoE-model.

Zodra het laden is voltooid, is de server bereikbaar op:
0.0.0.0:8080 op de VMhttp://127.0.0.1:8080 op je lokale machine na SSH-portforwarding
Laat de server draaien. Open op je lokale pc een nieuwe terminal en maak opnieuw verbinding met SSH-portforwarding:
ssh -L 8080:localhost:8080 root@129.212.191.53Test de server vervolgens door beschikbare modellen op te vragen:
curl -s http://127.0.0.1:8080/v1/modelsAls je Qwen3.5 in de response ziet, draait je server correct en ben je klaar om hem aan te roepen vanuit de OpenAI SDK en je lokale apps.

Nu de Qwen3.5-inferenceserver draait, is de volgende stap verifiëren dat hij correct werkt met echte clientapplicaties. Een van de grootste voordelen van llama.cpp is dat llama-server een OpenAI-compatibele API aanbiedt, wat betekent dat je de officiële OpenAI SDK kunt gebruiken zonder je codestructuur te wijzigen.
Installeer eerst het OpenAI Python-pakket op je lokale machine (of binnen de VM als je dat liever hebt):
pip install openai Voer nu een eenvoudig testscript uit. Dit maakt verbinding met je lokaal doorgestuurde endpoint op http://127.0.0.1:8080/v1 in plaats van met de cloudservers van OpenAI.
python3 - <<'PY'
from openai import OpenAI
client = OpenAI(
base_url="http://127.0.0.1:8080/v1",
api_key="sk-no-key-required"
)
response = client.chat.completions.create(
model="Qwen3.5",
messages=[
{"role": "user", "content": "Write one sentence about AI agents."}
]
)
print(response.choices[0].message.content)
PYEen paar belangrijke details om hier te begrijpen:
base_url verwijst naar je lokale Qwen3.5-server, niet naar de API van OpenAI.api_key is nog steeds vereist door de SDK, maar llama.cpp handhaaft geen authenticatie, dus elke placeholderwaarde werkt.model="Qwen3.5" komt overeen met het alias dat we instelden bij het starten van de server.Als alles correct is geconfigureerd, krijg je een snelle, heldere reactie van het model.
Dit bevestigt dat:
Vanaf dit punt kun je Qwen3.5 integreren in elke lokale tool, agent-workflow of applicatie die al het OpenAI API-formaat ondersteunt.
llama.cpp bevat een ingebouwde, ChatGPT-achtige WebUI waarmee je direct in je browser met het model kunt chatten. Dit is handig voor snel testen, prompt-iteraties en code genereren zonder eerst clientscripts te hoeven schrijven.
Omdat we al SSH-portforwarding hebben ingesteld, kun je de WebUI op je lokale machine openen, en gedraagt die zich alsof de server op je laptop draait.
Standaard is de WebUI beschikbaar op:
http://127.0.0.1:8080Als deze pagina laadt, bevestigt dat twee dingen. Je SSH-tunnel werkt correct, en de Qwen3.5-server is lokaal bereikbaar terwijl hij toch privé op de GPU-VM draait.
Zodra je in de WebUI bent, plak je deze prompt. Het doel is dat het model zowel de Python-code als een korte gebruiksgids genereert.
Binnen enkele seconden zou Qwen3.5 een app.py-bestand moeten genereren en meestal een korte uitleg over hoe je het draait.
Schakel nu over naar je lokale terminal (je laptop). Installeer de afhankelijkheden die de gegenereerde app nodig heeft:
pip install rich yfinanceDit installeert:
rich voor de TUI-layout, tabellen, prompts en voortgangsindicatorenyfinance om gratis, openbare beursstatistieken op te halenMaak een bestand met de naam app.py, plak de code die het model heeft gegenereerd en voer uit:
python3 app.pyZodra je het script draait, zou de TUI correct in je terminal moeten starten. De app vraagt je om de tickers in te voeren die je wilt analyseren, samen met je voorkeursmodus en risiconiveau.
Wij testten het bijvoorbeeld met drie populaire aandelen.
Na een korte laadfase geeft de tool een volledige tabel met beursstatistieken terug, markeert de resultaten op basis van de scoringsregels en slaat alles op in een results.csv-bestand.
Dit is een goed voorbeeld van hoe Qwen3.5 in één keer een complete werkende applicatie kan genereren, met alleen een 4-bit gequantizeerde modelendpoint en een eenvoudige prompt.
Qwen3.5 lokaal draaien is een krachtige manier om toegang te krijgen tot een model op frontier-schaal, terwijl je alles privé en volledig onder controle houdt. In deze tutorial draaide het model op een enkele H200 GPU-VM, veilig benaderd vanaf een lokale machine via SSH-portforwarding, en geserveerd via een geoptimaliseerde llama.cpp OpenAI-compatibele endpoint.
Toch zijn er een paar praktische beperkingen om rekening mee te houden. Omdat alles afhankelijk is van een actieve SSH-tunnel, moet de verbinding stabiel blijven. Als je internet uitvalt of de sessie verbreekt, verlies je de toegang tot de lokale poort en moet je vaak opnieuw verbinden en delen van de workflow herstarten.
Een ander veelvoorkomend probleem is het correct bouwen van llama.cpp. Als je niet de juiste CUDA-architectuurvlag voor je GPU opgeeft, kan de compilatie veel langer duren en mogelijk niet volledig voor de hardware optimaliseren. De juiste architectuur vooraf instellen maakt een merkbaar verschil in buildtijd en prestaties.
Ten slotte, hoewel de 4-bit MXFP4_MOE-quant uitstekend is om grote modellen efficiënt te draaien, is die niet altijd ideaal voor agentische codeworkflows. Bij tests met tools zoals Qwen Code CLI, Kilo Code CLI en OpenCode had het model moeite met diepere redenering en faalde het vaak tijdens langere generatie-loops, soms zelfs met GPU-instabiliteit tot gevolg.
Quants met hogere precisie of kleinere, op redeneren gerichte modellen werken mogelijk beter voor betrouwbare agentgebaseerde coding.
Wil je meer leren over agentische coding? Bekijk dan onze AI-Assisted Coding for Developers-cursus. Ik raad ook onze gids aan over het lokaal draaien van GLM-5 voor agentische coding.
Topcursussen op DataCamp
Cursus
Cursus
Cursus
blog
Adel Nehme
15 min
