Curso
Projetando Sistemas Agentes com LangChain
3 h
12.4K
Qwen3.5 é a série mais recente de modelos da Alibaba e amplia o forte desempenho das versões anteriores do Qwen em tarefas de raciocínio, código e multimodais.
Avaliações independentes mostram que o modelo Qwen3.5-397B-A17B atinge notas altas em testes amplamente usados como LiveCodeBench e AIME26, muitas vezes superando modelos líderes como GPT-5.2 e Claude Opus 4.5 na maioria das categorias avaliadas, além de entregar uma vazão significativamente maior do que as gerações anteriores do Qwen.
Fonte: Qwen/Qwen3.5-397B-A17B · Hugging Face
Neste tutorial, você vai:
Antes de rodar o Qwen3.5 localmente, garanta que seu ambiente atende aos requisitos de hardware e software para uma inferência suave. Neste tutorial, usamos uma GPU NVIDIA H200 com 141 GB de VRAM, emparelhada com 240 GB de RAM, o que nos dá memória de sobra para rodar a versão MXFP4_MOE do Qwen3.5 com eficiência usando offloading de MoE.
Como referência, a quantização dinâmica de 4 bits da Unsloth UD-Q4_K_XL usa cerca de 214 GB de espaço em disco. Ela cabe diretamente em um M3 Ultra de 256 GB e também roda bem em uma única GPU de 24 GB com 256 GB de RAM, atingindo 25+ tokens por segundo com offloading de MoE. Quantizações menores de 3 bits podem caber em 192 GB de RAM, enquanto versões de 8 bits, com maior precisão, podem exigir até 512 GB de RAM e VRAM combinadas.
De modo geral, para obter o melhor desempenho, o somatório de VRAM + RAM deve ser aproximadamente do tamanho do modelo quantizado que você baixar. Caso contrário, o llama.cpp pode fazer offload para o SSD, mas a inferência ficará mais lenta.
No lado de software, você deve ter os drivers NVIDIA mais recentes instalados, além de um CUDA Toolkit recente, para garantir total compatibilidade com o llama.cpp e a aceleração por CUDA.
Agora que você já tem os pré-requisitos, vamos passar por um passo a passo de como usar o Qwen 3.5 localmente:
Para rodar o Qwen3.5 localmente, você precisa de acesso a uma máquina com GPU potente. Como a maioria dos laptops e desktops não tem VRAM ou memória suficiente para lidar com modelos desse tamanho, vamos usar uma máquina virtual com GPU na nuvem.
Neste tutorial, usamos a Hyperbolic para rodar o modelo de forma privada. Você também pode usar outros provedores como RunPod, Vast.ai ou qualquer plataforma de VM com GPU de sua preferência. Escolhemos a Hyperbolic porque ela atualmente oferece algumas das instâncias de GPU com melhor custo-benefício.
Comece iniciando uma nova instância com uma única GPU H200.
Depois que a máquina iniciar, você verá o endereço IP público e o comando SSH necessário para conectar a partir do seu terminal local.
Antes de conectar, certifique-se de que o SSH está configurado localmente e de que você adicionou sua chave pública SSH ao criar a máquina virtual.
Quando a instância estiver pronta, conecte-se via SSH com redirecionamento de porta. Isso é importante porque queremos acessar o servidor de inferência do llama.cpp localmente pela porta 8080:
ssh -L 8080:localhost:8080 root@129.212.191.53Na primeira conexão, digite yes para confirmar e, em seguida, autentique-se usando sua chave SSH.
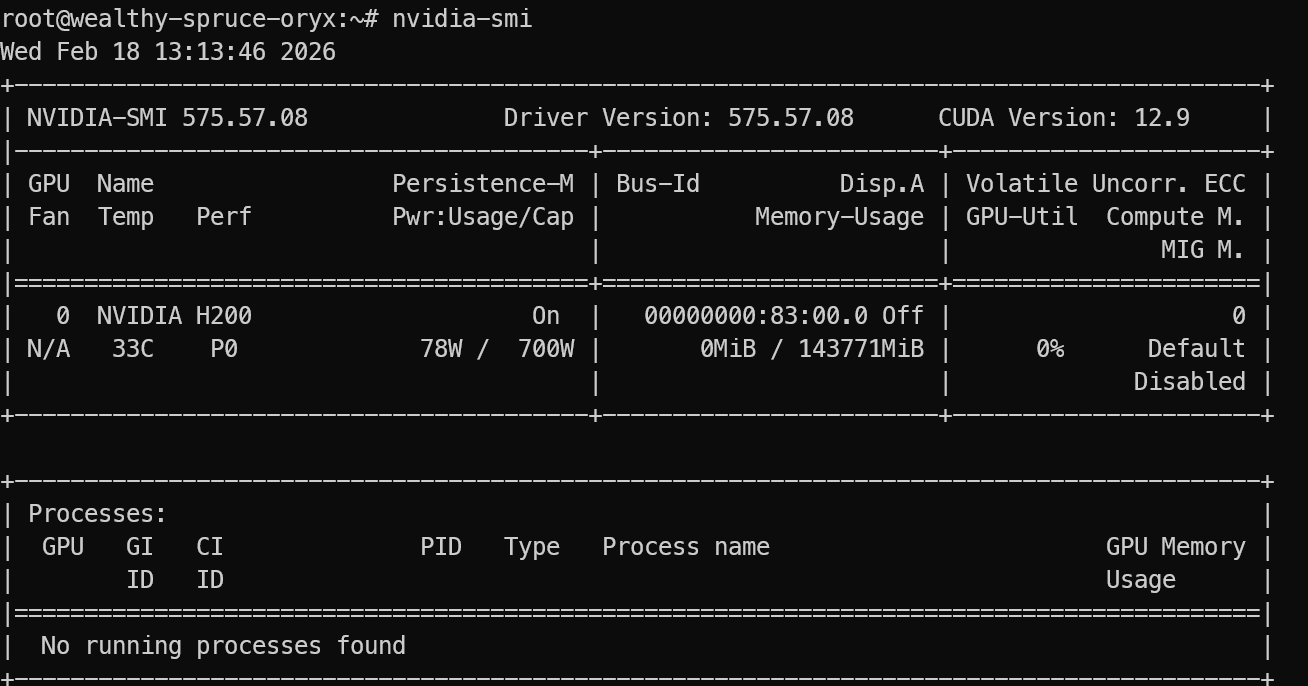
Após o login, verifique se a GPU foi detectada corretamente:
nvidia-smi Você deve ver a NVIDIA H200 listada na saída.
Por fim, instale os pacotes Linux necessários para baixar, compilar e executar o llama.cpp:
sudo apt update
sudo apt install pciutils build-essential cmake curl libcurl4-openssl-dev -yConcluída essa etapa, seu ambiente está pronto para instalar o llama.cpp e rodar o Qwen3.5 localmente.
llama.cpp é um engine de inferência open source em C e C++ que permite rodar modelos de linguagem grandes localmente com configuração mínima, com suporte a aceleração em CPU e GPU.
Primeiro, clone o repositório do llama.cpp:
git clone https://github.com/ggml-org/llama.cppEm seguida, configure uma build com CUDA via CMake. Ativamos o CUDA com -DGGML_CUDA=ON e definimos a arquitetura CUDA como 90a porque estamos usando uma NVIDIA H200 (classe Hopper). Isso ajuda a gerar código de GPU otimizado para recursos do Hopper.
cmake llama.cpp -B llama.cpp/build \
-DGGML_CUDA=ON \
-DCMAKE_BUILD_TYPE=Release \
-DCMAKE_CUDA_ARCHITECTURES="90a"
Agora compile o binário do servidor. O llama-server é o servidor REST embutido que permite expor o llama.cpp como um endpoint de API:
cmake --build llama.cpp/build --config Release -j --clean-first --target llama-server
Por fim, copie os binários compilados para a pasta principal para facilitar a execução:
cp llama.cpp/build/bin/llama-* llama.cppCom o llama.cpp instalado, o próximo passo é baixar os pesos do modelo Qwen3.5 no formato GGUF. Esses arquivos são grandes, então usar o CLI do Hugging Face é a forma mais confiável de buscá-los direto na sua máquina com GPU.
Instalamos o Python primeiro porque as ferramentas de download e autenticação do Hugging Face são distribuídas como pacotes Python. Embora o llama.cpp seja escrito em C++, o Python facilita bastante o gerenciamento de downloads e transferências de modelos.
Comece instalando o pip:
sudo apt install python3-pipDepois, instale o cliente Hugging Face Hub com utilitários de performance. hf_transfer e hf-xet aceleram bastante os downloads, o que é importante ao baixar centenas de gigabytes de arquivos de modelo:
pip -q install -U huggingface_hub hf-xet
pip -q install -U hf_transferAgora baixe o modelo Qwen3.5 do Hugging Face. Neste tutorial, buscamos apenas a variante MXFP4_MOE, otimizada para inferência eficiente com MoE:
hf download unsloth/Qwen3.5-397B-A17B-GGUF \
--local-dir models/Qwen3.5 \
--include "*MXFP4_MOE*"
Quando o download terminar, os arquivos do modelo estarão em models/Qwen3.5, prontos para serem carregados no llama.cpp para inferência local.
Agora podemos iniciar o Qwen3.5 usando o llama-server. Isso nos dá um endpoint de API compatível com OpenAI, que pode ser chamado de ferramentas e apps locais.
Otimizamos o servidor para uma configuração com GPU única com três medidas principais. Primeiro, ativamos --fit on para que o llama.cpp balanceie automaticamente o modelo entre a VRAM da GPU e a RAM do sistema, em vez de falhar quando o modelo não cabe totalmente na VRAM.
Segundo, usamos uma janela de contexto maior com --ctx-size 16384 para aceitar prompts mais longos. Terceiro, ativamos --jinja e passamos --chat-template-kwargs para controlar a formatação do chat e desativar o modo de "thinking" para respostas mais rápidas e diretas.
Execute o servidor com:
./llama.cpp/llama-server \
--model models/Qwen3.5/MXFP4_MOE/Qwen3.5-397B-A17B-MXFP4_MOE-00001-of-00006.gguf \
--alias "Qwen3.5" \
--host 0.0.0.0 \
--port 8080 \
--fit on \
--jinja \
--ctx-size 16384 \
--temp 0.7 \
--top-p 0.8 \
--top-k 20 \
--min-p 0.00 \
--chat-template-kwargs "{\"enable_thinking\": false}"Enquanto o modelo carrega, você notará o uso de VRAM da GPU e memória do sistema, o que é esperado para um modelo MoE grande.

Depois do carregamento, o servidor ficará acessível em:
0.0.0.0:8080 na VMhttp://127.0.0.1:8080 no seu computador local após o redirecionamento de porta via SSH
Mantenha o servidor rodando. No seu PC local, abra um novo terminal e reconecte com redirecionamento de porta via SSH:
ssh -L 8080:localhost:8080 root@129.212.191.53Depois, teste o servidor listando os modelos disponíveis:
curl -s http://127.0.0.1:8080/v1/modelsSe você vir Qwen3.5 na resposta, seu servidor está rodando corretamente e você já pode chamá-lo a partir do SDK da OpenAI e dos seus apps locais.

Com o servidor de inferência do Qwen3.5 em execução, o próximo passo é verificar se ele funciona corretamente com aplicações clientes reais. Uma das maiores vantagens do llama.cpp é que o llama-server expõe uma API compatível com OpenAI, o que significa que você pode usar o SDK oficial da OpenAI sem mudar a estrutura do seu código.
Primeiro, instale o pacote OpenAI para Python na sua máquina local (ou dentro da VM, se preferir):
pip install openai Agora rode um script simples de teste. Ele se conecta ao endpoint encaminhado localmente em http://127.0.0.1:8080/v1 em vez dos servidores em nuvem da OpenAI.
python3 - <<'PY'
from openai import OpenAI
client = OpenAI(
base_url="http://127.0.0.1:8080/v1",
api_key="sk-no-key-required"
)
response = client.chat.completions.create(
model="Qwen3.5",
messages=[
{"role": "user", "content": "Write one sentence about AI agents."}
]
)
print(response.choices[0].message.content)
PYAlguns pontos importantes aqui:
base_url aponta para o seu servidor local do Qwen3.5, não para a API da OpenAI.api_key ainda é exigida pelo SDK, mas o llama.cpp não aplica autenticação, então qualquer valor fictício funciona.model="Qwen3.5" corresponde ao alias que definimos ao iniciar o servidor.Se tudo estiver configurado corretamente, você receberá uma resposta rápida e direta do modelo.
Isso confirma que:
A partir daqui, você pode integrar o Qwen3.5 a qualquer ferramenta local, workflow de agentes ou aplicação que já suporte o formato da API da OpenAI.
O llama.cpp inclui uma WebUI no estilo ChatGPT para você conversar com o modelo direto no navegador. É útil para testes rápidos, iteração de prompts e geração de código sem precisar escrever scripts cliente primeiro.
Como já configuramos o redirecionamento de porta via SSH, você pode abrir a WebUI na sua máquina local, e ela vai se comportar como se o servidor estivesse rodando no seu laptop.
Por padrão, a WebUI está disponível em:
http://127.0.0.1:8080Se essa página abrir, duas coisas ficam confirmadas: o túnel SSH está funcionando e o servidor Qwen3.5 está acessível localmente, embora continue rodando de forma privada na VM com GPU.
Quando estiver na WebUI, cole este prompt. A ideia é fazer o modelo gerar tanto o código em Python quanto um guia rápido de uso.
Em poucos segundos, o Qwen3.5 deve gerar um arquivo app.py e normalmente uma explicação rápida de como executá-lo.
Agora, vá para o seu terminal local (seu laptop). Instale as dependências necessárias para o app gerado:
pip install rich yfinanceIsso instala:
rich para layout da TUI, tabelas, prompts e indicadores de progressoyfinance para obter métricas públicas e gratuitas de açõesCrie um arquivo chamado app.py, cole o código gerado pelo modelo e execute:
python3 app.pyAo rodar o script, a TUI deve abrir corretamente no terminal. O app vai pedir para você informar os tickers que deseja analisar, além do modo de triagem e do nível de risco preferidos.
Por exemplo, testamos com três ações populares.
Após uma breve fase de carregamento, a ferramenta retorna uma tabela completa de métricas, destaca os resultados com base nas regras de pontuação e salva tudo em um arquivo results.csv.
Este é um ótimo exemplo de como o Qwen3.5 consegue gerar um aplicativo completo e funcional de uma só vez, usando apenas um endpoint quantizado de 4 bits e um prompt simples.
Rodar o Qwen3.5 localmente é uma forma poderosa de acessar um modelo de fronteira mantendo tudo privado e sob seu controle. Neste tutorial, o modelo foi hospedado em uma única VM com GPU H200, acessado com segurança a partir de uma máquina local via redirecionamento de porta SSH e servido por um endpoint otimizado do llama.cpp compatível com OpenAI.
Ainda assim, vale lembrar algumas limitações práticas. Como tudo depende de um túnel SSH ativo, a conexão precisa se manter estável. Se sua internet cair ou a sessão desconectar, você perde o acesso à porta local e muitas vezes precisa reconectar e reiniciar partes do fluxo.
Outro problema comum é compilar corretamente o llama.cpp. Se você não especificar a flag de arquitetura CUDA adequada para sua GPU, a compilação pode demorar muito mais e pode não ficar totalmente otimizada para o hardware. Definir a arquitetura certa desde o início faz diferença perceptível no tempo de build e no desempenho.
Por fim, embora a quantização de 4 bits MXFP4_MOE seja excelente para rodar modelos grandes com eficiência, ela nem sempre é ideal para workflows de codificação com agentes. Em testes com ferramentas como Qwen Code CLI, Kilo Code CLI e OpenCode, o modelo teve dificuldades com raciocínios mais profundos e frequentemente falhou em loops de geração mais longos, às vezes até causando instabilidade na GPU.
Quantizações de maior precisão ou modelos menores focados em raciocínio podem funcionar melhor para uma codificação com agentes mais confiável.
Para saber mais sobre codificação com agentes, confira nosso curso AI-Assisted Coding for Developers. Também recomendo nosso guia sobre rodar o GLM-5 localmente para codificação com agentes.
Principais cursos da DataCamp
Curso
Curso
Curso
blog
Abid Ali Awan
9 min
Tutorial
Tutorial
Ryan Ong
Tutorial
Moez Ali
Tutorial
Zoumana Keita
Tutorial
Zoumana Keita



