Cours
Concevoir des systèmes agentiques avec LangChain
3 h
12.4K
Qwen3.5 est la dernière série de modèles d’Alibaba et s’appuie sur les solides performances des versions précédentes de Qwen en raisonnement, code et tâches multimodales.
Des évaluations indépendantes montrent que le modèle Qwen3.5-397B-A17B obtient des scores élevés sur des benchmarks largement utilisés comme LiveCodeBench et AIME26, dépassant souvent des modèles leaders tels que GPT-5.2 et Claude Opus 4.5 dans la majorité des catégories évaluées, tout en offrant un débit nettement supérieur aux générations Qwen précédentes.
Source : Qwen/Qwen3.5-397B-A17B · Hugging Face
Dans ce tutoriel, nous allons :
Avant d’exécuter Qwen3.5 en local, assurez-vous que votre configuration satisfait aux exigences matérielles et logicielles pour une inférence fluide. Dans ce tutoriel, nous utilisons un GPU NVIDIA H200 avec 141 Go de VRAM associé à 240 Go de RAM système, ce qui nous donne largement assez de mémoire pour exécuter efficacement la version MXFP4_MOE de Qwen3.5 avec offloading MoE.
À titre indicatif, la quantification dynamique Unsloth en 4 bits UD-Q4_K_XL occupe environ 214 Go d’espace disque. Elle tient directement sur un M3 Ultra 256 Go et s’exécute aussi très bien sur un seul GPU 24 Go avec 256 Go de RAM, atteignant 25 + tokens par seconde avec offloading MoE. Des quants plus petits en 3 bits peuvent tenir dans 192 Go de RAM, tandis que des versions 8 bits plus précises peuvent nécessiter jusqu’à 512 Go de RAM + VRAM combinées.
De manière générale, pour de meilleures performances, la somme VRAM + RAM devrait à peu près correspondre à la taille du modèle quantifié que vous téléchargez. Sinon, llama.cpp peut déporter sur le SSD, mais l’inférence sera plus lente.
Côté logiciel, vous devez disposer des derniers pilotes GPU NVIDIA ainsi qu’un CUDA Toolkit récent pour garantir la compatibilité totale avec llama.cpp et l’inférence accélérée par CUDA.
Maintenant que les prérequis sont en place, suivons pas à pas comment utiliser Qwen 3.5 en local :
Pour exécuter Qwen3.5 en local, vous avez besoin d’un poste avec un GPU puissant. La plupart des ordinateurs portables et PC de bureau manquent de VRAM ou de mémoire suffisante pour des modèles de cette taille, nous utiliserons donc une machine virtuelle GPU dans le cloud.
Dans ce tutoriel, nous utilisons Hyperbolic pour exécuter le modèle en privé. Vous pouvez aussi recourir à d’autres fournisseurs comme RunPod, Vast.ai ou toute autre plateforme de VM GPU de votre choix. Nous avons choisi Hyperbolic car elle propose actuellement certaines des instances GPU les plus économiques.
Commencez par lancer une nouvelle instance avec un seul GPU H200.
Après le démarrage, vous verrez l’adresse IP publique et la commande SSH nécessaire pour vous connecter depuis votre terminal local.
Avant de vous connecter, vérifiez que SSH est configuré localement et que vous avez ajouté votre clé publique SSH lors de la création de la VM.
Une fois l’instance prête, connectez-vous en SSH avec redirection de port. C’est important car nous voulons accéder au serveur d’inférence llama.cpp en local via le port 8080 :
ssh -L 8080:localhost:8080 root@129.212.191.53Lors de la première connexion, tapez yes pour confirmer, puis authentifiez-vous avec votre clé SSH.
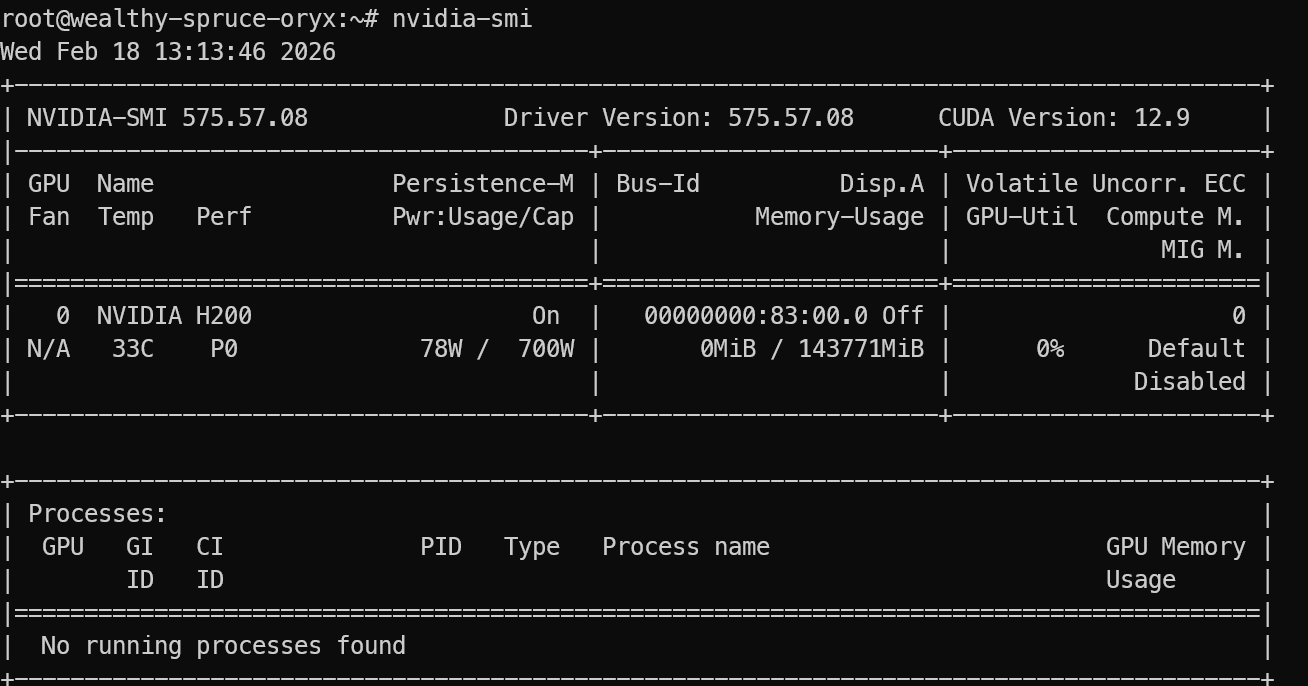
Après connexion, vérifiez que le GPU est bien détecté :
nvidia-smi Vous devez voir le NVIDIA H200 apparaître dans la sortie.
Enfin, installez les paquets Linux requis pour télécharger, compiler et exécuter llama.cpp :
sudo apt update
sudo apt install pciutils build-essential cmake curl libcurl4-openssl-dev -yUne fois terminé, votre environnement est prêt pour installer llama.cpp et exécuter Qwen3.5 en local.
llama.cpp est un moteur d’inférence open source en C/C++ qui permet d’exécuter des modèles de langage en local avec un minimum de configuration, en tirant parti de l’accélération CPU et GPU.
Commencez par cloner le dépôt llama.cpp :
git clone https://github.com/ggml-org/llama.cppEnsuite, configurez une compilation avec CUDA via CMake. Nous activons CUDA avec -DGGML_CUDA=ON et fixons l’architecture CUDA à 90a car nous utilisons un NVIDIA H200 (génération Hopper). Cela permet de générer du code GPU optimisé pour Hopper.
cmake llama.cpp -B llama.cpp/build \
-DGGML_CUDA=ON \
-DCMAKE_BUILD_TYPE=Release \
-DCMAKE_CUDA_ARCHITECTURES="90a"
Compilez maintenant le binaire serveur. llama-server est le serveur REST intégré qui expose llama.cpp en tant qu’endpoint API :
cmake --build llama.cpp/build --config Release -j --clean-first --target llama-server
Enfin, copiez les binaires compilés dans le dossier principal pour les exécuter facilement :
cp llama.cpp/build/bin/llama-* llama.cppMaintenant que llama.cpp est installé, l’étape suivante consiste à télécharger les poids du modèle Qwen3.5 au format GGUF. Ces fichiers sont volumineux : l’outil en ligne de commande Hugging Face est le moyen le plus fiable pour les récupérer directement sur votre machine GPU.
Nous installons d’abord Python car les outils de téléchargement et d’authentification Hugging Face sont distribués sous forme de packages Python. Même si llama.cpp est écrit en C++, Python facilite grandement la gestion des téléchargements et transferts de modèles.
Commencez par installer pip :
sudo apt install python3-pipInstallez ensuite le client Hugging Face Hub avec des accélérateurs de performance. hf_transfer et hf-xet accélèrent fortement les téléchargements, essentiel quand on récupère des centaines de gigaoctets de fichiers modèle :
pip -q install -U huggingface_hub hf-xet
pip -q install -U hf_transferTéléchargez maintenant le modèle Qwen3.5 depuis Hugging Face. Dans ce tutoriel, nous ne récupérons que la variante MXFP4_MOE, optimisée pour une inférence MoE efficace :
hf download unsloth/Qwen3.5-397B-A17B-GGUF \
--local-dir models/Qwen3.5 \
--include "*MXFP4_MOE*"
Une fois le téléchargement terminé, les fichiers du modèle seront stockés dans models/Qwen3.5, prêts à être chargés dans llama.cpp pour l’inférence locale.
Nous pouvons maintenant démarrer Qwen3.5 avec llama-server. Cela nous fournit un endpoint API compatible OpenAI, appelable depuis vos outils et applications locaux.
Nous avons optimisé le serveur pour une configuration à un seul GPU en appliquant trois points clés. D’abord, nous activons --fit on pour que llama.cpp répartisse automatiquement le modèle entre la VRAM du GPU et la RAM système, au lieu d’échouer si le modèle ne tient pas entièrement en VRAM.
Ensuite, nous utilisons une fenêtre de contexte plus grande avec --ctx-size 16384 pour gérer des prompts plus longs. Enfin, nous activons --jinja et passons --chat-template-kwargs afin de contrôler le formatage des chats et de désactiver le mode thinking pour des réponses plus directes et rapides.
Lancez le serveur avec :
./llama.cpp/llama-server \
--model models/Qwen3.5/MXFP4_MOE/Qwen3.5-397B-A17B-MXFP4_MOE-00001-of-00006.gguf \
--alias "Qwen3.5" \
--host 0.0.0.0 \
--port 8080 \
--fit on \
--jinja \
--ctx-size 16384 \
--temp 0.7 \
--top-p 0.8 \
--top-k 20 \
--min-p 0.00 \
--chat-template-kwargs "{\"enable_thinking\": false}"Pendant le chargement du modèle, vous remarquerez qu’il utilise à la fois la VRAM GPU et la mémoire système, ce qui est normal pour un grand modèle MoE.

Une fois le chargement terminé, le serveur sera accessible sur :
0.0.0.0:8080 sur la VMhttp://127.0.0.1:8080 sur votre machine locale après redirection de port SSH
Laissez le serveur actif. Sur votre PC local, ouvrez un nouveau terminal et reconnectez-vous avec la redirection de port SSH :
ssh -L 8080:localhost:8080 root@129.212.191.53Testez ensuite le serveur en listant les modèles disponibles :
curl -s http://127.0.0.1:8080/v1/modelsSi vous voyez Qwen3.5 dans la réponse, votre serveur fonctionne correctement et vous pouvez l’appeler depuis le SDK OpenAI et vos applications locales.

Maintenant que le serveur d’inférence Qwen3.5 tourne, vérifions qu’il fonctionne correctement avec de vraies applications clientes. L’un des grands avantages de llama.cpp est que llama-server expose une API compatible OpenAI, ce qui vous permet d’utiliser le SDK officiel OpenAI sans changer l’architecture de votre code.
Installez d’abord le package Python OpenAI sur votre machine locale (ou dans la VM si vous préférez) :
pip install openai Exécutez maintenant un script de test simple. Il se connecte à votre endpoint redirigé en local sur http://127.0.0.1:8080/v1 au lieu des serveurs cloud d’OpenAI.
python3 - <<'PY'
from openai import OpenAI
client = OpenAI(
base_url="http://127.0.0.1:8080/v1",
api_key="sk-no-key-required"
)
response = client.chat.completions.create(
model="Qwen3.5",
messages=[
{"role": "user", "content": "Write one sentence about AI agents."}
]
)
print(response.choices[0].message.content)
PYQuelques points importants à noter :
base_url pointe vers votre serveur Qwen3.5 local, et non l’API d’OpenAI.api_key reste exigée par le SDK, mais llama.cpp n’applique pas d’authentification, donc n’importe quelle valeur factice convient.model="Qwen3.5" correspond à l’alias défini au démarrage du serveur.Si tout est correctement configuré, vous obtiendrez une réponse rapide et propre du modèle.
Cela confirme que :
À ce stade, vous pouvez intégrer Qwen3.5 à tout outil local, workflow d’agent ou application déjà compatible avec l’API OpenAI.
llama.cpp inclut une interface Web intégrée, de type ChatGPT, pour dialoguer avec le modèle directement depuis votre navigateur. Pratique pour tester rapidement, itérer sur les prompts et générer du code sans écrire de scripts client au préalable.
Puisque la redirection de port SSH est déjà en place, vous pouvez ouvrir le WebUI sur votre machine locale, comme si le serveur tournait sur votre ordinateur portable.
Par défaut, le WebUI est disponible à :
http://127.0.0.1:8080Si la page se charge, cela confirme deux choses : votre tunnel SSH fonctionne, et le serveur Qwen3.5 est accessible en local tout en s’exécutant en privé sur la VM GPU.
Une fois dans le WebUI, collez ce prompt. L’objectif est que le modèle génère à la fois le code Python et un court guide d’utilisation.
En quelques secondes, Qwen3.5 devrait générer un fichier app.py ainsi qu’une brève explication pour l’exécuter.
Basculez maintenant sur votre terminal local (votre ordinateur portable). Installez les dépendances nécessaires à l’application générée :
pip install rich yfinanceCela installe :
rich pour la TUI, les tableaux, les invites et les indicateurs de progressionyfinance pour récupérer des métriques boursières publiques et gratuitesCréez un fichier nommé app.py, collez le code généré par le modèle, puis exécutez :
python3 app.pyAu lancement, la TUI doit s’afficher correctement dans votre terminal. L’application vous demandera les tickers à analyser, ainsi que le mode de filtrage et le niveau de risque souhaités.
Par exemple, nous l’avons testée avec trois actions populaires.
Après une courte phase de chargement, l’outil renvoie un tableau complet de métriques, met en avant les résultats selon les règles de scoring et enregistre tout dans un fichier results.csv.
C’est un excellent exemple de la capacité de Qwen3.5 à générer une application complète en une seule fois, en s’appuyant uniquement sur un endpoint quantifié en 4 bits et un prompt simple.
Exécuter Qwen3.5 en local est un moyen puissant d’accéder à un modèle de pointe tout en gardant vos données privées et sous contrôle. Dans ce tutoriel, le modèle a été hébergé sur une VM avec un seul GPU H200, accessible en toute sécurité depuis une machine locale via la redirection de port SSH, et servi via un endpoint llama.cpp optimisé et compatible OpenAI.
Cela dit, gardez à l’esprit quelques limites pratiques. Comme tout dépend d’un tunnel SSH actif, la connexion doit rester stable. Si votre connexion Internet tombe ou si la session se déconnecte, vous perdez l’accès au port local et devrez souvent vous reconnecter et relancer certaines étapes.
Autre écueil fréquent : bien compiler llama.cpp. Si vous ne précisez pas le bon indicateur d’architecture CUDA pour votre GPU, la compilation peut durer bien plus longtemps et ne pas tirer pleinement parti du matériel. Définir l’architecture correcte dès le départ améliore sensiblement le temps de build et les performances.
Enfin, si la quantification 4 bits MXFP4_MOE est excellente pour exécuter de grands modèles efficacement, elle n’est pas toujours idéale pour des workflows de code agentique. Lors de tests avec des outils comme Qwen Code CLI, Kilo Code CLI et OpenCode, le modèle a eu du mal sur des raisonnements plus profonds et a souvent échoué lors de boucles de génération prolongées, allant parfois jusqu’à déclencher une instabilité GPU.
Des quants de précision supérieure ou des modèles plus petits axés sur le raisonnement peuvent mieux convenir pour un codage agentique fiable.
Pour en savoir plus sur le codage agentique, découvrez notre cours AI-Assisted Coding for Developers. Je vous recommande également notre guide sur l’exécution de GLM-5 en local pour le codage agentique.
Meilleurs cours DataCamp
Cours
Cours
Cours
blog
Kurtis Pykes
9 min
blog
Zoumana Keita
15 min
blog
Lynn Heidmann
blog
Tutoriel
Tutoriel
Adel Nehme

