Corso
Progettare sistemi agentici con LangChain
3 h
12.9K
Qwen3.5 è l'ultima serie di modelli Qwen di Alibaba e si basa sull'ottima performance delle versioni precedenti di Qwen in compiti di ragionamento, coding e multimodali.
Valutazioni indipendenti mostrano che il modello Qwen3.5-397B-A17B ottiene punteggi elevati in test ampiamente utilizzati come LiveCodeBench e AIME26, spesso superando modelli di punta come GPT-5.2 e Claude Opus 4.5 nella maggior parte delle categorie valutate, e offrendo un throughput significativamente superiore rispetto alle generazioni precedenti di Qwen.
Fonte: Qwen/Qwen3.5-397B-A17B · Hugging Face
In questo tutorial, faremo:
Prima di eseguire Qwen3.5 in locale, assicurati che la tua configurazione soddisfi i requisiti hardware e software per un'inferenza fluida. In questo tutorial, usiamo una GPU NVIDIA H200 con 141GB di VRAM, abbinata a 240GB di RAM di sistema, che ci fornisce memoria più che sufficiente per eseguire in modo efficiente la versione MXFP4_MOE di Qwen3.5 con offloading MoE.
Come riferimento, la quantizzazione dinamica a 4 bit di Unsloth UD-Q4_K_XL utilizza circa 214GB di spazio su disco. Può stare direttamente su un Mac Studio M3 Ultra da 256GB, e funziona bene anche su una singola GPU da 24GB con 256GB di RAM, raggiungendo oltre 25 token al secondo con offloading MoE. Quantizzazioni più piccole a 3 bit possono rientrare in 192GB di RAM, mentre versioni a precisione più alta a 8 bit possono richiedere fino a 512GB tra RAM e VRAM combinate.
In generale, per ottenere le migliori prestazioni, la somma di VRAM + RAM dovrebbe approssimativamente corrispondere alla dimensione del modello quantizzato che scarichi. In caso contrario, llama.cpp può effettuare offloading su storage SSD, ma l'inferenza sarà più lenta.
Dal lato software, dovresti avere i driver GPU NVIDIA più recenti installati, insieme a una CUDA Toolkit recente, per garantire la piena compatibilità con llama.cpp e con l'inferenza accelerata da CUDA.
Ora che hai predisposto i prerequisiti, vediamo passo dopo passo come usare Qwen 3.5 in locale:
Per eseguire Qwen3.5 in locale, ti serve accesso a una macchina con GPU potente. Poiché la maggior parte dei laptop e dei PC desktop non dispone di abbastanza VRAM o memoria per gestire modelli di queste dimensioni, useremo invece una macchina virtuale GPU nel cloud.
In questo tutorial, usiamo Hyperbolic per eseguire il modello in privato. Puoi anche usare altri provider come RunPod, Vast.ai o qualsiasi piattaforma di VM GPU tu preferisca. Abbiamo scelto Hyperbolic perché al momento offre alcune delle istanze GPU più convenienti in termini di costo.
Inizia avviando una nuova istanza con una singola GPU H200.
Dopo l'avvio della macchina, vedrai l'indirizzo IP pubblico e il comando SSH necessario per connetterti dal tuo terminale locale.
Prima di connetterti, assicurati di avere SSH configurato in locale e di aver aggiunto la tua chiave pubblica SSH durante la creazione della macchina virtuale.
Quando l'istanza è pronta, connettiti tramite SSH con port forwarding. Questo è importante perché vogliamo accedere al server di inferenza llama.cpp in locale tramite la porta 8080:
ssh -L 8080:localhost:8080 root@129.212.191.53Al primo accesso, digita yes per confermare e poi autenticati usando la tua chiave SSH.
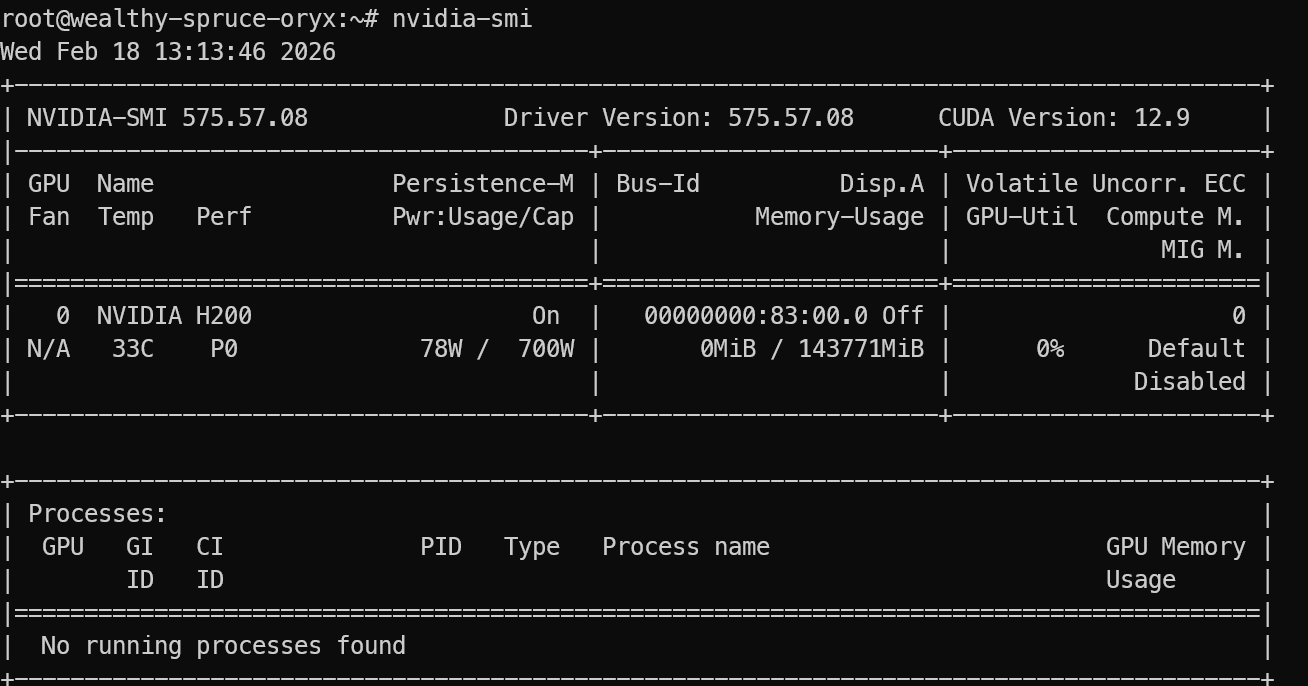
Dopo il login, verifica che la GPU sia rilevata correttamente:
nvidia-smi Dovresti vedere la NVIDIA H200 elencata nell'output.
Infine, installa i pacchetti Linux necessari per scaricare, compilare ed eseguire llama.cpp:
sudo apt update
sudo apt install pciutils build-essential cmake curl libcurl4-openssl-dev -yUna volta terminato, il tuo ambiente è pronto per installare llama.cpp ed eseguire Qwen3.5 in locale.
llama.cpp è un motore di inferenza open-source in C e C++ che ti permette di eseguire modelli linguistici di grandi dimensioni in locale con una configurazione minima, e supporta sia l'accelerazione CPU che GPU.
Per prima cosa, clona il repository di llama.cpp:
git clone https://github.com/ggml-org/llama.cppPoi configura una build con CUDA abilitata tramite CMake. Abilitiamo CUDA con -DGGML_CUDA=ON e impostiamo l'architettura CUDA a 90a perché stiamo usando una NVIDIA H200 (classe Hopper). Questo aiuta la build a generare codice GPU ottimizzato per le funzionalità di Hopper.
cmake llama.cpp -B llama.cpp/build \
-DGGML_CUDA=ON \
-DCMAKE_BUILD_TYPE=Release \
-DCMAKE_CUDA_ARCHITECTURES="90a"
Ora compila il binario del server. llama-server è il server REST integrato che ti permette di esporre llama.cpp come endpoint API:
cmake --build llama.cpp/build --config Release -j --clean-first --target llama-server
Infine, copia i binari compilati nella cartella principale per eseguirli più facilmente:
cp llama.cpp/build/bin/llama-* llama.cppOra che llama.cpp è installato, il passo successivo è scaricare i pesi del modello Qwen3.5 in formato GGUF. Questi file sono molto grandi, quindi usare la CLI di Hugging Face è il modo più affidabile per recuperarli direttamente sulla tua macchina GPU.
Installiamo prima Python perché gli strumenti di download e le utility di autenticazione di Hugging Face sono distribuiti come pacchetti Python. Anche se llama.cpp è scritto in C++, Python rende molto più semplice gestire i download e i trasferimenti dei modelli.
Inizia installando pip:
sudo apt install python3-pipPoi installa il client Hugging Face Hub insieme agli helper per le performance. hf_transfer e hf-xet velocizzano notevolmente i download, cosa importante quando devi scaricare centinaia di gigabyte di file del modello:
pip -q install -U huggingface_hub hf-xet
pip -q install -U hf_transferOra scarica il modello Qwen3.5 da Hugging Face. In questo tutorial recuperiamo solo la variante MXFP4_MOE, ottimizzata per un'inferenza MoE efficiente:
hf download unsloth/Qwen3.5-397B-A17B-GGUF \
--local-dir models/Qwen3.5 \
--include "*MXFP4_MOE*"
Al termine del download, i file del modello saranno archiviati in models/Qwen3.5, pronti per essere caricati in llama.cpp per l'inferenza locale.
Ora possiamo avviare Qwen3.5 usando llama-server. Questo ci fornisce un endpoint API compatibile con OpenAI che possiamo chiamare da strumenti e app locali.
Abbiamo ottimizzato il server per una configurazione a singola GPU in tre modi chiave. Primo, abilitiamo --fit on così llama.cpp bilancia automaticamente il modello tra VRAM della GPU e RAM di sistema, invece di fallire quando il modello non entra completamente in VRAM.
Secondo, usiamo una finestra di contesto più grande con --ctx-size 16384 in modo che il server possa gestire prompt più lunghi. Terzo, abilitiamo --jinja e passiamo --chat-template-kwargs per controllare il formato della chat e disabilitare la modalità thinking per risposte più rapide e dirette.
Avvia il server con:
./llama.cpp/llama-server \
--model models/Qwen3.5/MXFP4_MOE/Qwen3.5-397B-A17B-MXFP4_MOE-00001-of-00006.gguf \
--alias "Qwen3.5" \
--host 0.0.0.0 \
--port 8080 \
--fit on \
--jinja \
--ctx-size 16384 \
--temp 0.7 \
--top-p 0.8 \
--top-k 20 \
--min-p 0.00 \
--chat-template-kwargs "{\"enable_thinking\": false}"Durante il caricamento del modello, noterai che utilizza sia la VRAM della GPU sia la memoria di sistema, cosa attesa per un grande modello MoE.

Una volta completato il caricamento, il server sarà raggiungibile su:
0.0.0.0:8080 sulla VMhttp://127.0.0.1:8080 sulla tua macchina locale dopo il port forwarding SSH
Lascia il server in esecuzione. Sul tuo PC locale, apri un nuovo terminale e riconnettiti con il port forwarding SSH:
ssh -L 8080:localhost:8080 root@129.212.191.53Quindi testa il server elencando i modelli disponibili:
curl -s http://127.0.0.1:8080/v1/modelsSe vedi Qwen3.5 nella risposta, il tuo server è in esecuzione correttamente e sei pronto per chiamarlo dall'SDK OpenAI e dalle tue app locali.

Ora che il server di inferenza Qwen3.5 è attivo, il passo successivo è verificare che funzioni correttamente con applicazioni client reali. Uno dei maggiori vantaggi di llama.cpp è che llama-server espone un'API compatibile con OpenAI, il che significa che puoi usare l'SDK ufficiale OpenAI senza cambiare la struttura del tuo codice.
Per prima cosa, installa il pacchetto OpenAI per Python sulla tua macchina locale (o dentro la VM se preferisci):
pip install openai Ora esegui un semplice script di test. Questo si connette al tuo endpoint inoltrato in locale su http://127.0.0.1:8080/v1 invece dei server cloud di OpenAI.
python3 - <<'PY'
from openai import OpenAI
client = OpenAI(
base_url="http://127.0.0.1:8080/v1",
api_key="sk-no-key-required"
)
response = client.chat.completions.create(
model="Qwen3.5",
messages=[
{"role": "user", "content": "Write one sentence about AI agents."}
]
)
print(response.choices[0].message.content)
PYAlcuni dettagli importanti da capire qui:
base_url punta al tuo server Qwen3.5 locale, non all'API di OpenAI.api_key è comunque richiesta dall'SDK, ma llama.cpp non applica l'autenticazione, quindi qualsiasi valore segnaposto va bene.model="Qwen3.5" corrisponde all'alias che abbiamo impostato all'avvio del server.Se tutto è configurato correttamente, otterrai una risposta rapida e pulita dal modello.
Questo conferma che:
A questo punto, puoi integrare Qwen3.5 in qualsiasi strumento locale, workflow di agenti o applicazione che già supporta il formato dell'API OpenAI.
llama.cpp include una WebUI in stile ChatGPT integrata che puoi usare per chattare con il modello direttamente dal browser. È utile per test rapidi, iterazione sui prompt e generazione di codice senza dover scrivere prima script client.
Dato che abbiamo già configurato il port forwarding SSH, puoi aprire la WebUI sulla tua macchina locale e si comporterà come se il server fosse in esecuzione sul tuo laptop.
Per impostazione predefinita, la WebUI è disponibile su:
http://127.0.0.1:8080Se questa pagina si carica, conferma due cose: il tuo tunnel SSH funziona correttamente e il server Qwen3.5 è raggiungibile in locale pur rimanendo in esecuzione in privato sulla VM GPU.
Una volta nella WebUI, incolla questo prompt. L'obiettivo è far generare al modello sia il codice Python sia una breve guida all'uso.
Nel giro di pochi secondi, Qwen3.5 dovrebbe generare un file app.py e di solito una breve spiegazione su come eseguirlo.
Ora passa al tuo terminale locale (il tuo laptop). Installa le dipendenze necessarie all'app generata:
pip install rich yfinanceQuesto installa:
rich per layout TUI, tabelle, prompt e indicatori di avanzamentoyfinance per recuperare metriche azionarie pubbliche e gratuiteCrea un file chiamato app.py, incolla il codice generato dal modello ed esegui:
python3 app.pyUna volta avviato lo script, dovresti vedere la TUI avviarsi correttamente nel tuo terminale. L'app ti chiederà di inserire i ticker che vuoi analizzare, insieme alla modalità di screening preferita e al livello di rischio.
Per esempio, noi l'abbiamo testata con tre titoli popolari.
Dopo una breve fase di caricamento, lo strumento restituisce una tabella completa di metriche azionarie, evidenzia i risultati in base alle regole di punteggio e salva tutto in un file results.csv.
Questo è un ottimo esempio di come Qwen3.5 possa generare un'applicazione completa e funzionante in un colpo solo, utilizzando solo un endpoint del modello quantizzato a 4 bit e un semplice prompt.
Eseguire Qwen3.5 in locale è un modo potente per accedere a un modello di frontiera mantenendo tutto privato e completamente sotto il tuo controllo. In questo tutorial, il modello è stato ospitato su una singola VM con GPU H200, accessibile in modo sicuro da una macchina locale tramite port forwarding SSH e servito attraverso un endpoint ottimizzato di llama.cpp compatibile con OpenAI.
Detto questo, ci sono alcune limitazioni pratiche da tenere a mente. Poiché tutto dipende da un tunnel SSH attivo, la connessione deve rimanere stabile. Se la tua connessione internet cade o la sessione si disconnette, perdi l'accesso alla porta locale e spesso devi riconnetterti e riavviare parti del workflow.
Un altro problema comune è compilare correttamente llama.cpp. Se non specifichi il flag di architettura CUDA giusto per la tua GPU, la compilazione può richiedere molto più tempo e potrebbe non ottimizzare completamente l'hardware. Impostare l'architettura corretta fin dall'inizio fa una differenza evidente nel tempo di build e nelle prestazioni.
Infine, sebbene la quantizzazione a 4 bit MXFP4_MOE sia eccellente per eseguire modelli grandi in modo efficiente, non è sempre ideale per workflow di coding basati su agenti. Nei test con strumenti come Qwen Code CLI, Kilo Code CLI e OpenCode, il modello ha faticato con ragionamenti più profondi e spesso è andato in errore durante cicli di generazione più lunghi, a volte causando persino instabilità della GPU.
Quantizzazioni a precisione più alta o modelli più piccoli focalizzati sul ragionamento possono funzionare meglio per un coding affidabile basato su agenti.
Per saperne di più sul coding basato su agenti, dai un'occhiata al nostro corso AI-Assisted Coding for Developers. Ti consigliamo anche la nostra guida per eseguire GLM-5 in locale per il coding agentico.
I migliori corsi DataCamp
Corso
Corso
Corso
blog
Abid Ali Awan
15 min
blog
Abid Ali Awan
10 min
blog
Tim Lu
12 min

