Kurs
LangChain ile Aracı Sistemler Tasarlama
3 sa
12.1K
Qwen3.5, Alibaba’nın en yeni Qwen model serisidir ve önceki Qwen modellerinin akıl yürütme, kodlama ve çok kipli görevlerdeki güçlü performansını daha da ileri taşır.
Bağımsız kıyaslama değerlendirmeleri, Qwen3.5-397B-A17B modelinin LiveCodeBench ve AIME26 gibi yaygın testlerde yüksek puanlar aldığını, değerlendirilen kategorilerin çoğunda GPT-5.2 ve Claude Opus 4.5 gibi önde gelen modelleri sıklıkla geride bıraktığını ve önceki Qwen nesillerine göre anlamlı ölçüde daha yüksek işleme hızına ulaştığını gösteriyor.
Kaynak: Qwen/Qwen3.5-397B-A17B · Hugging Face
Bu eğitimde şunları yapacağız:
Qwen3.5’i yerelde çalıştırmadan önce, kurulumunuzun sorunsuz çıkarım için hem donanım hem de yazılım gereksinimlerini karşıladığından emin olmalısınız. Bu eğitimde, 141 GB VRAM’li NVIDIA H200 GPU’yu, 240 GB sistem RAM’i ile eşleştirerek kullanıyoruz; bu da Qwen3.5’in MXFP4_MOE sürümünü MoE offloading ile verimli şekilde çalıştırmak için fazlasıyla yeterli bellek sağlar.
Referans olarak, Unsloth 4-bit dinamik quant UD-Q4_K_XL yaklaşık 214 GB disk alanı kullanır. Doğrudan 256 GB M3 Ultra’ya sığar ve ayrıca 256 GB RAM’li tek bir 24 GB GPU üzerinde de MoE offloading ile saniyede 25+ token hızına ulaşarak iyi çalışır. Daha küçük 3-bit quant’lar 192 GB RAM içine sığabilirken, daha yüksek hassasiyetli 8-bit sürümler toplamda 512 GB birleşik RAM ve VRAM gerektirebilir.
Genel olarak, en iyi performans için VRAM + RAM toplamınız, indirdiğiniz quantize modelin boyutuyla yaklaşık olarak eşleşmelidir. Aksi halde, llama.cpp SSD depolamaya offload edebilir; ancak çıkarım daha yavaş olacaktır.
Yazılım tarafında ise, en güncel NVIDIA GPU sürücülerinin yanı sıra güncel bir CUDA Toolkit kurulu olmalıdır; böylece llama.cpp ile tam uyumluluk ve CUDA hızlandırmalı çıkarım sağlanır.
Artık önkoşullar hazır olduğuna göre, Qwen 3.5’i yerelde nasıl kullanacağınızı adım adım inceleyelim:
Qwen3.5’i yerelde çalıştırmak için güçlü bir GPU makinesine erişmeniz gerekir. Çoğu dizüstü ve masaüstü bilgisayarda bu boyuttaki modelleri çalıştıracak kadar VRAM veya bellek bulunmadığından, bunun yerine bulut GPU sanal makinesi kullanacağız.
Bu eğitimde, modeli özel olarak çalıştırmak için Hyperbolic kullanıyoruz. RunPod, Vast.ai gibi diğer sağlayıcıları veya tercih ettiğiniz herhangi bir GPU VM platformunu da kullanabilirsiniz. Hyperbolic’i seçtik çünkü şu anda en hesaplı GPU örneklerinden bazılarını sunuyor.
Öncelikle tek bir H200 GPU ile yeni bir örnek başlatın.
Makine açıldıktan sonra, genel IP adresini ve yerel terminalinizden bağlanmak için gereken SSH komutunu göreceksiniz.
Bağlanmadan önce, yerelde SSH yapılandırdığınızdan ve sanal makineyi oluştururken genel SSH anahtarınızı eklediğinizden emin olun.
Örnek hazır olduğunda, port yönlendirme ile SSH üzerinden bağlanın. Bu önemlidir çünkü llama.cpp çıkarım sunucusuna yerelde 8080 portu üzerinden erişmek istiyoruz:
ssh -L 8080:localhost:8080 root@129.212.191.53İlk kez bağlandığınızda onaylamak için yes yazın ve ardından SSH anahtarınızı kullanarak kimlik doğrulayın.
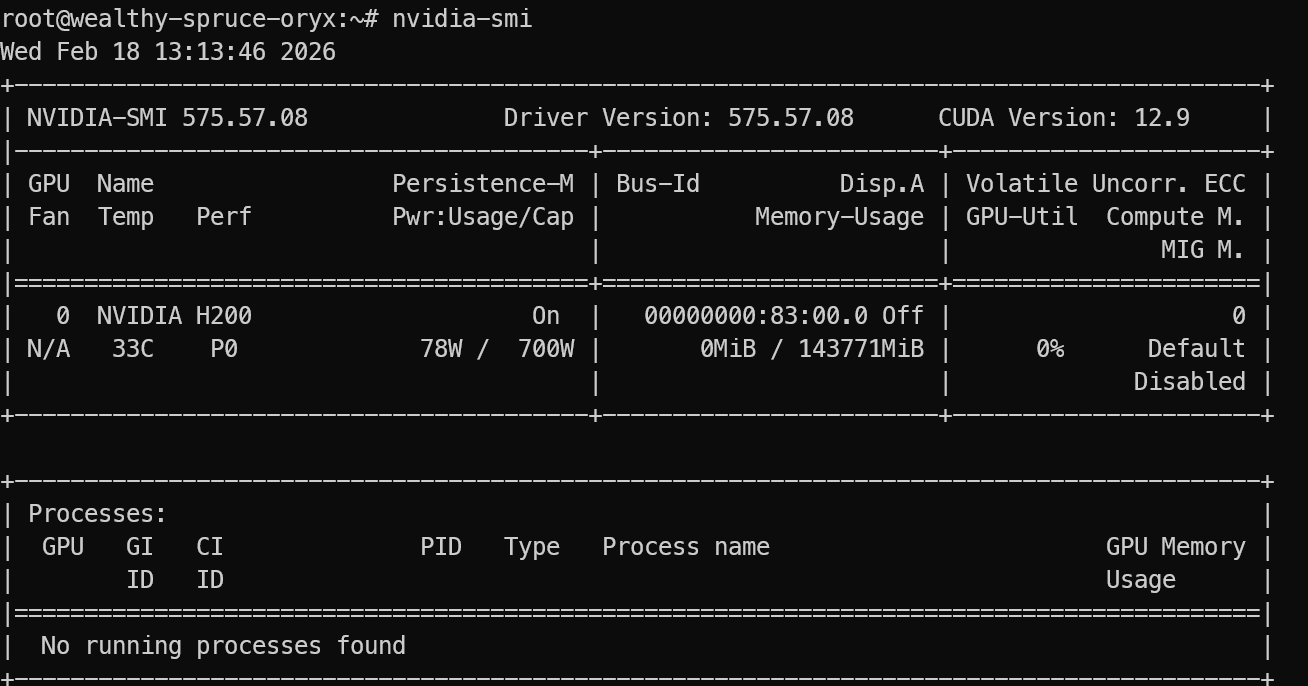
Oturum açtıktan sonra, GPU’nun doğru algılandığını doğrulayın:
nvidia-smi Çıktıda NVIDIA H200’ü görmelisiniz.
Son olarak, llama.cpp’yi indirmek, derlemek ve çalıştırmak için gereken Linux paketlerini kurun:
sudo apt update
sudo apt install pciutils build-essential cmake curl libcurl4-openssl-dev -yBu tamamlandığında, ortamınız llama.cpp’yi kurup Qwen3.5’i yerelde çalıştırmaya hazırdır.
llama.cpp, büyük dil modellerini en az kurulumla yerelde çalıştırmanıza izin veren ve hem CPU hem de GPU hızlandırmasını destekleyen, açık kaynaklı bir C ve C++ çıkarım motorudur.
Önce, llama.cpp deposunu klonlayın:
git clone https://github.com/ggml-org/llama.cppArdından, CMake ile CUDA etkin bir derleme yapılandırın. CUDA’yı -DGGML_CUDA=ON ile etkinleştiriyoruz ve NVIDIA H200 (Hopper sınıfı) kullandığımız için CUDA mimarisini 90a olarak ayarlıyoruz. Bu, derlemenin Hopper özellikleri için optimize edilmiş GPU kodu üretmesine yardımcı olur.
cmake llama.cpp -B llama.cpp/build \
-DGGML_CUDA=ON \
-DCMAKE_BUILD_TYPE=Release \
-DCMAKE_CUDA_ARCHITECTURES="90a"
Şimdi sunucu ikilisini derleyin. llama-server, llama.cpp’yi bir API uç noktası olarak sunmanıza olanak tanıyan yerleşik REST sunucusudur:
cmake --build llama.cpp/build --config Release -j --clean-first --target llama-server
Son olarak, çalıştırmayı kolaylaştırmak için derlenen ikilileri ana klasöre kopyalayın:
cp llama.cpp/build/bin/llama-* llama.cppArtık llama.cpp kurulduğuna göre sıradaki adım, Qwen3.5 model ağırlıklarını GGUF formatında indirmektir. Bu dosyalar büyüktür; bu nedenle bunları doğrudan GPU makinenize çekmenin en güvenilir yolu Hugging Face CLI’ını kullanmaktır.
Önce Python’u kuruyoruz çünkü Hugging Face indirme araçları ve kimlik doğrulama yardımcıları Python paketleri olarak dağıtılır. llama.cpp C++ ile yazılmış olsa da model indirmelerini ve aktarımlarını yönetmek Python ile çok daha kolaydır.
pip’i kurarak başlayın:
sudo apt install python3-pipSonra, Hugging Face Hub istemcisini performans yardımcılarıyla birlikte kurun. hf_transfer ve hf-xet indirmeleri önemli ölçüde hızlandırır; bu da yüzlerce gigabaytlık model dosyalarını çekerken kritiktir:
pip -q install -U huggingface_hub hf-xet
pip -q install -U hf_transferŞimdi Qwen3.5 modelini Hugging Face’ten indirin. Bu eğitimde yalnızca, verimli MoE çıkarımı için optimize edilmiş MXFP4_MOE varyantını çekiyoruz:
hf download unsloth/Qwen3.5-397B-A17B-GGUF \
--local-dir models/Qwen3.5 \
--include "*MXFP4_MOE*"
İndirme tamamlandığında, model dosyaları models/Qwen3.5 klasörünün içinde saklanır ve llama.cpp’ye yerel çıkarım için yüklenmeye hazırdır.
Şimdi Qwen3.5’i llama-server kullanarak başlatabiliriz. Bu, yerel araç ve uygulamalardan çağırabileceğimiz OpenAI ile uyumlu bir API uç noktası sağlar.
Sunucuyu tek GPU kurulumuna göre üç kritik ayarla optimize ettik. İlk olarak, model tamamen VRAM’e sığmadığında hata vermek yerine llama.cpp’nin modeli GPU VRAM ve sistem RAM’i arasında otomatik olarak dengelemesi için --fit on etkinleştirildi.
İkinci olarak, sunucunun daha uzun istemleri kaldırabilmesi için --ctx-size 16384 ile daha büyük bir bağlam penceresi kullanıyoruz. Üçüncü olarak, --jinja etkinleştiriliyor ve daha hızlı, daha doğrudan yanıtlar için düşünme modunu devre dışı bırakacak şekilde sohbet biçimlendirmesini kontrol etmek amacıyla --chat-template-kwargs geçiriliyor.
Sunucuyu şu komutla çalıştırın:
./llama.cpp/llama-server \
--model models/Qwen3.5/MXFP4_MOE/Qwen3.5-397B-A17B-MXFP4_MOE-00001-of-00006.gguf \
--alias "Qwen3.5" \
--host 0.0.0.0 \
--port 8080 \
--fit on \
--jinja \
--ctx-size 16384 \
--temp 0.7 \
--top-p 0.8 \
--top-k 20 \
--min-p 0.00 \
--chat-template-kwargs "{\"enable_thinking\": false}"Model yüklenirken hem GPU VRAM’in hem de sistem belleğinin kullanıldığını fark edeceksiniz; bu, büyük bir MoE modelinde beklenen bir durumdur.

Yükleme tamamlandığında, sunucu şu adreslerden erişilebilir olacaktır:
0.0.0.0:8080 VM üzerindehttp://127.0.0.1:8080 SSH port yönlendirmesi sonrası yerel makinenizde
Sunucuyu çalışır durumda bırakın. Yerel PC’nizde yeni bir terminal açın ve port yönlendirme ile SSH üzerinden tekrar bağlanın:
ssh -L 8080:localhost:8080 root@129.212.191.53Ardından, mevcut modelleri listeleyerek sunucuyu test edin:
curl -s http://127.0.0.1:8080/v1/modelsYanıtta Qwen3.5 görürseniz, sunucunuz doğru şekilde çalışıyor demektir ve OpenAI SDK ve yerel uygulamalarınızdan çağırmaya hazırsınız.

Qwen3.5 çıkarım sunucusu çalıştığına göre, sonraki adım gerçek istemci uygulamalarıyla doğru çalıştığını doğrulamaktır. llama.cpp’nin en büyük avantajlarından biri, llama-server’ın OpenAI ile uyumlu bir API sunmasıdır; bu da resmi OpenAI SDK’sını kod yapınızı değiştirmeden kullanabileceğiniz anlamına gelir.
Önce, yerel makinenize (veya tercih ederseniz VM içine) OpenAI Python paketini kurun:
pip install openai Şimdi basit bir test betiği çalıştırın. Bu, OpenAI’nin bulut sunucuları yerine http://127.0.0.1:8080/v1 adresindeki yerelde yönlendirilen uç noktanıza bağlanır.
python3 - <<'PY'
from openai import OpenAI
client = OpenAI(
base_url="http://127.0.0.1:8080/v1",
api_key="sk-no-key-required"
)
response = client.chat.completions.create(
model="Qwen3.5",
messages=[
{"role": "user", "content": "Write one sentence about AI agents."}
]
)
print(response.choices[0].message.content)
PYBurada anlaşılması gereken birkaç önemli ayrıntı:
base_url, yerel Qwen3.5 sunucunuzu işaret eder; OpenAI’nin API’sini değil.api_key yine SDK tarafından gereklidir; ancak llama.cpp kimlik doğrulamayı zorunlu kılmaz, bu nedenle herhangi bir yer tutucu değer işe yarar.model="Qwen3.5" adı, sunucuyu başlatırken belirlediğimiz takma adla eşleşir.Her şey doğru yapılandırıldıysa, modelden hızlı ve temiz bir yanıt alacaksınız.
Bu, şunları doğrular:
Bu noktada, Qwen3.5’i OpenAI API formatını zaten destekleyen herhangi bir yerel araca, aracı iş akışına veya uygulamaya entegre edebilirsiniz.
llama.cpp, modeli doğrudan tarayıcınızda kullanarak sohbet edebileceğiniz, ChatGPT tarzı yerleşik bir WebUI içerir. Bu, hızlı testler, komut yinelemeleri ve herhangi bir istemci betiği yazmadan önce kod üretimi için faydalıdır.
SSH port yönlendirmesini zaten kurduğumuz için, WebUI’yı yerel makinenizde açabilirsiniz ve sunucu dizüstü bilgisayarınızda çalışıyormuş gibi davranacaktır.
Varsayılan olarak WebUI şu adreste mevcuttur:
http://127.0.0.1:8080Bu sayfa yüklenirse iki şeyi doğrular. SSH tüneliniz düzgün çalışıyor ve Qwen3.5 sunucusuna, GPU VM üzerinde özel olarak çalışmaya devam ederken yerelden erişilebiliyor.
WebUI içindeyken, bu istemi yapıştırın. Amaç, modelin hem Python kodunu hem de kısa bir kullanım kılavuzunu üretmesidir.
Birkaç saniye içinde Qwen3.5 bir app.py dosyası ve genellikle nasıl çalıştırılacağına dair hızlı bir açıklama üretmelidir.
Şimdi yerel terminalinize (dizüstü bilgisayarınız) geçin. Üretilen uygulamanın ihtiyaç duyduğu bağımlılıkları kurun:
pip install rich yfinanceBu kurulum şunları içerir:
rich — TUI düzeni, tablolar, istemler ve ilerleme göstergeleri içinyfinance — Ücretsiz, herkese açık hisse senedi metriklerini çekmek içinBir app.py dosyası oluşturun, modelin ürettiği kodu yapıştırın ve çalıştırın:
python3 app.pyBetik çalıştığında, TUI’nin terminalinizde doğru şekilde açıldığını görmelisiniz. Uygulama, analiz etmek istediğiniz hisse senedi sembollerini, tercih ettiğiniz tarama modunu ve risk seviyesini girmenizi isteyecektir.
Örneğin, biz üç popüler hisseyle test ettik.
Kısa bir yükleme aşamasının ardından araç, hisse senedi metriklerinin tam bir tablosunu döndürür, puanlama kurallarına göre sonuçları vurgular ve her şeyi bir results.csv dosyasına kaydeder.
Bu, yalnızca 4-bit quantize bir model uç noktası ve basit bir istem kullanarak Qwen3.5’in tek seferde eksiksiz bir çalışan uygulama üretebileceğine güzel bir örnektir.
Qwen3.5’i yerelde çalıştırmak, her şeyi özel ve tamamen kontrolünüz altında tutarken sınır ölçeğinde bir modele erişmenin güçlü bir yoludur. Bu eğitimde, model tek bir H200 GPU VM üzerinde barındırıldı, yerel makineden SSH port yönlendirme ile güvenli şekilde erişildi ve optimize edilmiş, OpenAI ile uyumlu bir llama.cpp uç noktası üzerinden sunuldu.
Bununla birlikte, akılda tutulması gereken bazı pratik sınırlamalar var. Her şey etkin bir SSH tüneline bağlı olduğundan bağlantının istikrarlı kalması gerekir. İnternetiniz kesilirse veya oturum kapanırsa, yerel bağlantı noktasına erişimi kaybedersiniz ve genellikle iş akışının bazı bölümlerine yeniden bağlanıp yeniden başlamanız gerekir.
Bir diğer yaygın sorun da llama.cpp’nin doğru şekilde derlenmesidir. GPU’nuz için doğru CUDA mimarisi bayrağını belirtmezseniz, derleme çok daha uzun sürebilir ve donanım için tam optimize olmayabilir. Doğru mimariyi baştan ayarlamak, derleme süresi ve performansta fark edilir bir iyileşme sağlar.
Son olarak, 4-bit MXFP4_MOE quant büyük modelleri verimli şekilde çalıştırmak için mükemmel olsa da her zaman ajansal kodlama iş akışları için ideal değildir. Qwen Code CLI, Kilo Code CLI ve OpenCode gibi araçlarla yapılan testlerde model, daha derin akıl yürütmede zorlandı ve uzun üretim döngülerinde sıklıkla başarısız oldu; bazen GPU kararsızlığını dahi tetikledi.
Daha yüksek hassasiyetli quant’lar veya daha küçük, akıl yürütme odaklı modeller, güvenilir aracı tabanlı kodlama için daha iyi çalışabilir.
Ajansal kodlama hakkında daha fazla bilgi edinmek için Geliştiriciler için Yapay Zekâ Destekli Kodlama kursumuza göz atın. Ayrıca, ajansal kodlama için GLM-5’i yerelde çalıştırma rehberimizi de öneririm.
Öne Çıkan DataCamp Kursları
Kurs
Kurs
Kurs
blog
Abid Ali Awan
14 dk.
blog
Dario Radečić
15 dk.
Eğitim
Kurtis Pykes
Eğitim
Adel Nehme
