Kurs
Agentische Systeme mit LangChain entwerfen
3 Std.
12.4K
Qwen3.5 ist Alibabas neueste Qwen-Modellreihe und baut auf der starken Performance früherer Qwen-Modelle bei Reasoning-, Coding- und multimodalen Aufgaben auf.
Unabhängige Benchmarks zeigen, dass das Modell Qwen3.5-397B-A17B auf gängigen Tests wie LiveCodeBench und AIME26 hohe Werte erzielt, in vielen Kategorien führende Modelle wie GPT-5.2 und Claude Opus 4.5 übertrifft und dabei deutlich höheren Durchsatz liefert als frühere Qwen-Generationen.
Quelle: Qwen/Qwen3.5-397B-A17B · Hugging Face
In diesem Tutorial werden wir:
Bevor du Qwen3.5 lokal ausführst, stell sicher, dass deine Umgebung die Hardware- und Softwareanforderungen für reibungslose Inferenz erfüllt. In diesem Tutorial nutzen wir eine NVIDIA H200 GPU mit 141 GB VRAM in Kombination mit 240 GB System-RAM. Das bietet mehr als genügend Speicher, um die MXFP4_MOE-Variante von Qwen3.5 mit MoE-Offloading effizient zu betreiben.
Zum Vergleich: Die Unsloth 4-Bit Dynamic Quant UD-Q4_K_XL belegt rund 214 GB Speicherplatz. Sie passt direkt auf ein 256 GB M3 Ultra und läuft auch gut auf einer einzelnen 24-GB-GPU mit 256 GB RAM. So werden 25+ Tokens pro Sekunde mit MoE-Offloading erreicht. Kleinere 3-Bit-Quants kommen mit 192 GB RAM aus, während hochpräzise 8-Bit-Versionen bis zu 512 GB aus RAM und VRAM kombiniert benötigen können.
Grundsätzlich gilt: Für beste Performance sollte die Summe aus VRAM und RAM ungefähr der Größe des quantisierten Modells entsprechen, das du herunterlädst. Andernfalls kann llama.cpp auf SSD-Speicher auslagern, was die Inferenz jedoch verlangsamt.
Auf der Softwareseite solltest du die neuesten NVIDIA-GPU-Treiber sowie ein aktuelles CUDA Toolkit installiert haben, um volle Kompatibilität mit llama.cpp und CUDA-beschleunigter Inferenz sicherzustellen.
Wenn die Voraussetzungen stehen, gehen wir die Schritte durch, um Qwen 3.5 lokal zu nutzen:
Um Qwen3.5 lokal auszuführen, brauchst du Zugriff auf eine leistungsfähige GPU-Maschine. Da die meisten Laptops und Desktops nicht genug VRAM oder RAM für Modelle dieser Größe haben, verwenden wir stattdessen eine GPU-VM in der Cloud.
In diesem Tutorial nutzen wir Hyperbolic, um das Modell privat zu betreiben. Du kannst auch andere Anbieter wie RunPod, Vast.ai oder jede GPU-VM-Plattform deiner Wahl verwenden. Wir haben Hyperbolic gewählt, weil dort aktuell einige der kostengünstigsten GPU-Instanzen verfügbar sind.
Starte eine neue Instanz mit einer einzigen H200-GPU.
Sobald die Maschine hochgefahren ist, siehst du die öffentliche IP-Adresse und den SSH-Befehl, um dich von deinem lokalen Terminal zu verbinden.
Bevor du dich verbindest, stelle sicher, dass SSH lokal eingerichtet ist und dass du deinen öffentlichen SSH-Schlüssel bei der Erstellung der VM hinterlegt hast.
Wenn die Instanz bereit ist, verbinde dich per SSH mit Portweiterleitung. Das ist wichtig, weil wir den llama.cpp-Inferenzserver lokal über Port 8080 erreichen wollen:
ssh -L 8080:localhost:8080 root@129.212.191.53Beim ersten Verbindungsaufbau gib yes zur Bestätigung ein und authentifiziere dich dann mit deinem SSH-Schlüssel.
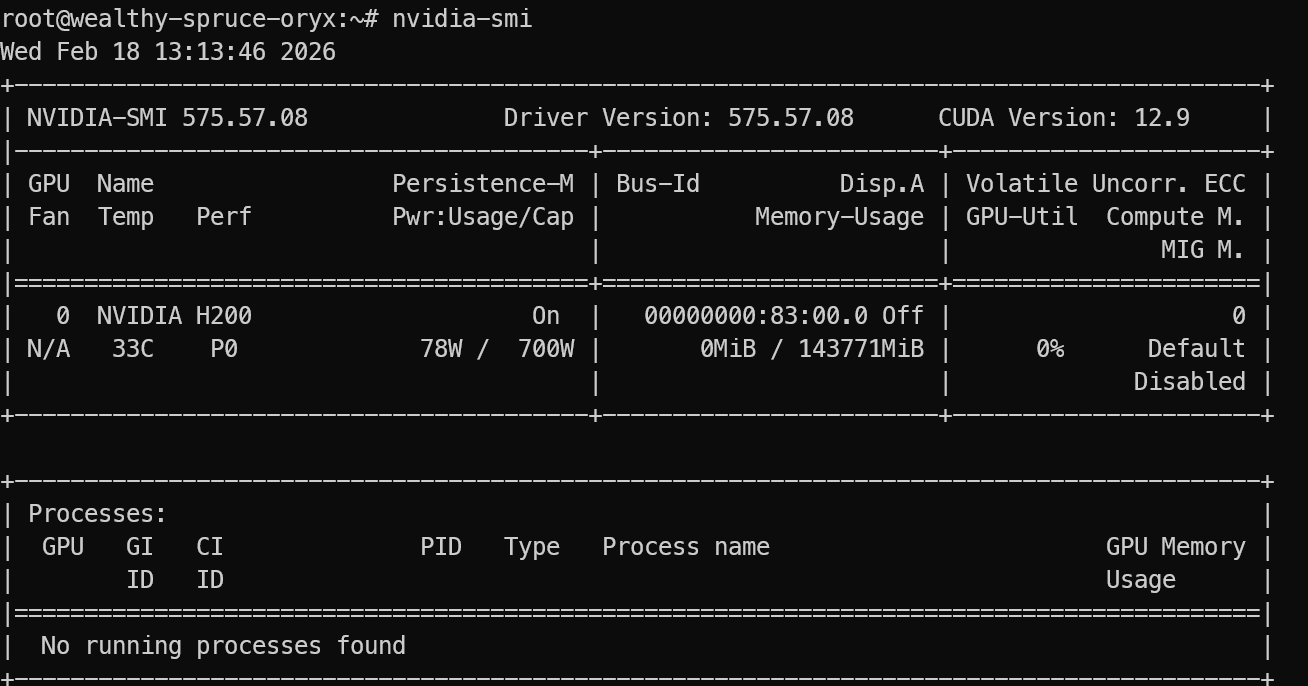
Nach dem Login prüfe, ob die GPU korrekt erkannt wird:
nvidia-smi In der Ausgabe sollte die NVIDIA H200 aufgeführt sein.
Installiere anschließend die benötigten Linux-Pakete, um llama.cpp herunterzuladen, zu bauen und auszuführen:
sudo apt update
sudo apt install pciutils build-essential cmake curl libcurl4-openssl-dev -yDanach ist deine Umgebung bereit, um llama.cpp zu installieren und Qwen3.5 lokal zu starten.
llama.cpp ist eine Open-Source-Inferenzengine in C/C++, mit der du große Sprachmodelle lokal mit minimalem Setup ausführen kannst. Sie unterstützt CPU- und GPU-Beschleunigung.
Klonen wir zuerst das llama.cpp-Repository:
git clone https://github.com/ggml-org/llama.cppAls Nächstes konfigurieren wir mit CMake einen CUDA-fähigen Build. Wir aktivieren CUDA mit -DGGML_CUDA=ON und setzen die CUDA-Architektur auf 90a, da wir eine NVIDIA H200 (Hopper-Klasse) nutzen. So wird GPU-Code erzeugt, der für Hopper-Features optimiert ist.
cmake llama.cpp -B llama.cpp/build \
-DGGML_CUDA=ON \
-DCMAKE_BUILD_TYPE=Release \
-DCMAKE_CUDA_ARCHITECTURES="90a"
Kompiliere nun das Server-Binary. llama-server ist der integrierte REST-Server, über den du llama.cpp als API-Endpunkt bereitstellst:
cmake --build llama.cpp/build --config Release -j --clean-first --target llama-server
Kopiere zum Schluss die kompilierten Binaries in den Hauptordner, damit sie leicht aufrufbar sind:
cp llama.cpp/build/bin/llama-* llama.cppNachdem llama.cpp installiert ist, laden wir die eigentlichen Qwen3.5-Gewichte im GGUF-Format herunter. Diese Dateien sind groß, daher ist die Hugging Face CLI der zuverlässigste Weg, sie direkt auf deine GPU-VM zu laden.
Wir installieren zuerst Python, da die Hugging Face Download-Tools und Authentifizierungs-Helfer als Python-Pakete bereitgestellt werden. Auch wenn llama.cpp in C++ geschrieben ist, erleichtert Python das Management großer Modelldownloads erheblich.
Installiere zunächst pip:
sudo apt install python3-pipInstalliere anschließend den Hugging Face Hub Client samt Performance-Tools. hf_transfer und hf-xet beschleunigen Downloads deutlich – wichtig beim Abruf hunderter Gigabyte an Modelldateien:
pip -q install -U huggingface_hub hf-xet
pip -q install -U hf_transferLade nun das Qwen3.5-Modell von Hugging Face. In diesem Tutorial ziehen wir nur die Variante MXFP4_MOE, die für effiziente MoE-Inferenz optimiert ist:
hf download unsloth/Qwen3.5-397B-A17B-GGUF \
--local-dir models/Qwen3.5 \
--include "*MXFP4_MOE*"
Nach Abschluss des Downloads liegen die Modelldateien unter models/Qwen3.5 bereit und können in llama.cpp für lokale Inferenz geladen werden.
Jetzt starten wir Qwen3.5 mit llama-server. Dadurch erhalten wir einen OpenAI-kompatiblen API-Endpunkt, den wir aus lokalen Tools und Apps aufrufen können.
Wir haben den Server für eine Single-GPU-Umgebung mit drei Maßnahmen optimiert. Erstens aktivieren wir --fit on, damit llama.cpp das Modell automatisch zwischen GPU-VRAM und System-RAM balanciert, anstatt zu scheitern, wenn es nicht vollständig in den VRAM passt.
Zweitens nutzen wir ein größeres Kontextfenster mit --ctx-size 16384 für längere Prompts. Drittens aktivieren wir --jinja und übergeben --chat-template-kwargs, um die Chatformatierung zu steuern und den Thinking-Mode zu deaktivieren – für schnellere, direktere Antworten.
Starte den Server mit:
./llama.cpp/llama-server \
--model models/Qwen3.5/MXFP4_MOE/Qwen3.5-397B-A17B-MXFP4_MOE-00001-of-00006.gguf \
--alias "Qwen3.5" \
--host 0.0.0.0 \
--port 8080 \
--fit on \
--jinja \
--ctx-size 16384 \
--temp 0.7 \
--top-p 0.8 \
--top-k 20 \
--min-p 0.00 \
--chat-template-kwargs "{\"enable_thinking\": false}"Während das Modell lädt, siehst du, dass sowohl GPU-VRAM als auch System-RAM genutzt werden – das ist bei einem großen MoE-Modell zu erwarten.

Nach dem Laden ist der Server erreichbar unter:
0.0.0.0:8080 auf der VMhttp://127.0.0.1:8080 auf deinem lokalen Rechner nach SSH-Portweiterleitung
Lass den Server laufen. Öffne auf deinem lokalen PC ein neues Terminal und verbinde dich erneut mit SSH-Portweiterleitung:
ssh -L 8080:localhost:8080 root@129.212.191.53Teste den Server dann, indem du die verfügbaren Modelle auflistest:
curl -s http://127.0.0.1:8080/v1/modelsWenn in der Antwort Qwen3.5 erscheint, läuft dein Server korrekt und du kannst ihn mit dem OpenAI SDK und deinen lokalen Apps ansprechen.

Da der Qwen3.5-Inferenzserver läuft, prüfen wir nun die Funktionsfähigkeit mit echten Clients. Einer der größten Vorteile von llama.cpp ist, dass llama-server eine OpenAI-kompatible API bereitstellt. Du kannst also das offizielle OpenAI SDK nutzen, ohne deine Code-Struktur zu ändern.
Installiere zunächst das OpenAI-Python-Paket lokal (oder in der VM, wenn du willst):
pip install openai Führe nun ein kurzes Testskript aus. Es verbindet sich mit deinem lokal weitergeleiteten Endpunkt unter http://127.0.0.1:8080/v1 statt mit den Cloud-Servern von OpenAI.
python3 - <<'PY'
from openai import OpenAI
client = OpenAI(
base_url="http://127.0.0.1:8080/v1",
api_key="sk-no-key-required"
)
response = client.chat.completions.create(
model="Qwen3.5",
messages=[
{"role": "user", "content": "Write one sentence about AI agents."}
]
)
print(response.choices[0].message.content)
PYWichtige Details dazu:
base_url verweist auf deinen lokalen Qwen3.5-Server, nicht auf die OpenAI-API.api_key ist im SDK weiterhin erforderlich, aber llama.cpp erzwingt keine Authentifizierung, daher funktioniert jeder Platzhalterwert.model="Qwen3.5" entspricht dem Alias, den wir beim Serverstart gesetzt haben.Wenn alles korrekt konfiguriert ist, erhältst du eine schnelle, saubere Antwort vom Modell.
Damit ist bestätigt, dass:
Ab jetzt kannst du Qwen3.5 in jedes lokale Tool, Agent-Workflow oder jede App integrieren, die bereits das OpenAI-API-Format unterstützt.
llama.cpp enthält eine integrierte, ChatGPT-ähnliche WebUI, mit der du direkt im Browser mit dem Modell chatten kannst. Ideal für schnelle Tests, Prompt-Iterationen und Codegenerierung – ganz ohne eigene Client-Skripte.
Da wir bereits SSH-Portweiterleitung eingerichtet haben, kannst du die WebUI lokal öffnen – sie verhält sich so, als liefe der Server auf deinem Laptop.
Standardmäßig ist die WebUI hier erreichbar:
http://127.0.0.1:8080Wenn die Seite lädt, bestätigt das zweierlei: Dein SSH-Tunnel funktioniert korrekt und der Qwen3.5-Server ist lokal erreichbar, während er privat auf der GPU-VM läuft.
Sobald du in der WebUI bist, füge diesen Prompt ein. Ziel ist, dass das Modell sowohl den Python-Code als auch eine kurze Anleitung generiert.
Nach wenigen Sekunden sollte Qwen3.5 eine Datei app.py erzeugen – meist inklusive einer kurzen Anleitung zur Ausführung.
Wechsle nun in dein lokales Terminal (Laptop). Installiere die Abhängigkeiten, die die generierte App benötigt:
pip install rich yfinanceDas installiert:
rich für TUI-Layout, Tabellen, Prompts und Ladeanzeigenyfinance zum Abrufen frei verfügbarer, öffentlicher AktienkennzahlenErstelle eine Datei namens app.py, füge den generierten Code ein und starte:
python3 app.pyNach dem Start sollte die TUI korrekt in deinem Terminal erscheinen. Die App fordert dich auf, die gewünschten Tickern einzugeben, außerdem den Screening-Modus und die Risikostufe.
Wir haben das zum Beispiel mit drei populären Aktien getestet.
Nach kurzer Ladephase liefert das Tool eine vollständige Tabelle mit Kennzahlen, hebt Ergebnisse nach den Scoring-Regeln hervor und speichert alles in einer Datei results.csv.
Das zeigt eindrucksvoll, wie Qwen3.5 mit nur einem 4-Bit-quantisierten Endpunkt und einem einfachen Prompt eine komplette, lauffähige Anwendung erzeugen kann.
Qwen3.5 lokal auszuführen ist ein starker Weg, ein Modell auf Frontier-Niveau zu nutzen – privat und vollständig unter deiner Kontrolle. In diesem Tutorial lief das Modell auf einer einzelnen H200-GPU-VM, wurde per SSH-Portweiterleitung sicher vom lokalen Rechner erreicht und über einen optimierten, OpenAI-kompatiblen llama.cpp-Endpunkt bereitgestellt.
Es gibt allerdings ein paar praktische Einschränkungen. Weil alles von einem aktiven SSH-Tunnel abhängt, muss die Verbindung stabil bleiben. Bricht das Internet ab oder die Session trennt sich, verlierst du den Zugriff auf den lokalen Port und musst oft Teile des Workflows neu starten und die Verbindung wiederherstellen.
Ein weiterer häufiger Stolperstein ist der korrekte Build von llama.cpp. Wenn du die richtige CUDA-Architektur für deine GPU nicht angibst, kann die Kompilierung deutlich länger dauern und die Hardware nicht optimal nutzen. Die korrekte Architektur von Anfang an zu setzen, macht sich bei Build-Zeit und Performance klar bemerkbar.
Schließlich ist der 4-Bit-MXFP4_MOE-Quant zwar hervorragend, um große Modelle effizient zu betreiben, aber nicht immer ideal für agentisches Coding. In Tests mit Tools wie Qwen Code CLI, Kilo Code CLI und OpenCode tat sich das Modell bei tieferem Reasoning schwer und scheiterte in längeren Generierungsschleifen – teils bis hin zu GPU-Instabilitäten.
Höherpräzise Quants oder kleinere, auf Reasoning fokussierte Modelle funktionieren für verlässliches agentenbasiertes Coding oft besser.
Wenn du mehr über agentisches Coding erfahren willst, schau dir unseren Kurs AI-Assisted Coding for Developers an. Empfehlenswert ist außerdem unser Guide zum lokalen Einsatz von GLM-5 für agentisches Coding.
Top-DataCamp-Kurse
Kurs
Kurs
Kurs
Blog
Hesam Sheikh Hassani
15 Min.
Blog
Blog
Zoumana Keita
15 Min.
Tutorial
Allan Ouko
Tutorial
Matt Crabtree
Tutorial
Mark Pedigo
