
Kursus
Inferensi untuk Regresi Linear di R
4 Hr
16K
Setiap kisah punya awal, dan bagi analis data atau data scientist, awal kisah itu sering kali adalah regresi linear sederhana. Memang, regresi linear sederhana barangkali merupakan model yang paling mendasar. Jadi, jika Anda serius ingin menjadi analis data atau data scientist, regresi linear sederhana (dan regresi pada umumnya) adalah hal yang wajib dipahami.
Alasan mempelajari regresi bukan hanya karena teknik ini sangat berharga untuk menjawab pertanyaan mendesak di hampir setiap bidang, tetapi juga karena regresi membuka pintu untuk pemahaman yang lebih dalam tentang berbagai hal lain, seperti uji hipotesis, inferensi kausal, dan peramalan. Jadi, ambil kursus Introduction to Regression in R dan kursus Introduction to Regression with statsmodels in Python kami hari ini.
Regresi linear sederhana adalah regresi linear dengan satu variabel independen, juga disebut variabel penjelas, dan satu variabel dependen, juga disebut variabel respons. Pada regresi linear sederhana, variabel dependen bersifat kontinu.
Cara paling umum melakukan regresi linear sederhana adalah melalui estimasi ordinary least squares (OLS). Karena OLS adalah metode yang paling umum, bagian “ordinary least squares” sering kali sudah tersirat saat kita membicarakan regresi linear sederhana.
Ordinary least squares bekerja dengan meminimalkan jumlah kuadrat selisih antara nilai teramati (titik data aktual) dan nilai yang diprediksi dari garis regresi. Selisih ini disebut residual, dan menguadratkan residual memastikan residual positif dan negatif diperlakukan sama.
Regresi linear sederhana membantu membuat prediksi dan memahami hubungan antara satu variabel independen dan satu variabel dependen. Misalnya, Anda mungkin ingin mengetahui bagaimana tinggi pohon (variabel independen) memengaruhi jumlah daunnya (variabel dependen). Dengan mengumpulkan data dan memasang model regresi linear sederhana, Anda dapat memprediksi jumlah daun berdasarkan tinggi pohon. Inilah bagian ‘membuat prediksi’. Namun pendekatan ini juga mengungkapkan seberapa besar perubahan rata-rata jumlah daun saat pohon tumbuh lebih tinggi, yang menunjukkan bagaimana regresi linear sederhana juga digunakan untuk memahami hubungan.
Mari kita lihat persamaan regresi linear sederhana. Kita dapat mulai dengan bentuk gradien–titik potong (slope-intercept) dari garis lurus menggunakan notasi yang umum dalam buku geometri atau aljabar. Artinya, kita akan mulai dari awal.
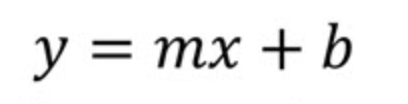
Di sini
Dalam konteks data science, Anda lebih mungkin melihat persamaan ini sebagai gantinya:
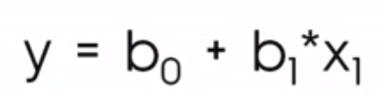
Di mana
Notasi yang melibatkan b0 dan b1 membantu kita memahami bahwa kita sedang melihat situasi di mana kita membuat prediksi atas y, itulah mengapa kita menyebutnya ŷ, atau y-hat, karena kita tidak berharap garis regresi benar-benar melewati semua titik.
Visualisasi berikut menunjukkan perbedaan konseptual antara bentuk gradien–titik potong, di sebelah kiri, dan persamaan regresi, di sebelah kanan. Dalam bahasa aljabar linear, kita akan mengatakan bahwa sistem persamaan linear tersebut overdetermined, artinya ada lebih banyak persamaan (sekitar tiga puluh) daripada jumlah peubah tak dikenal (dua), sehingga kita tidak berharap menemukan solusi.
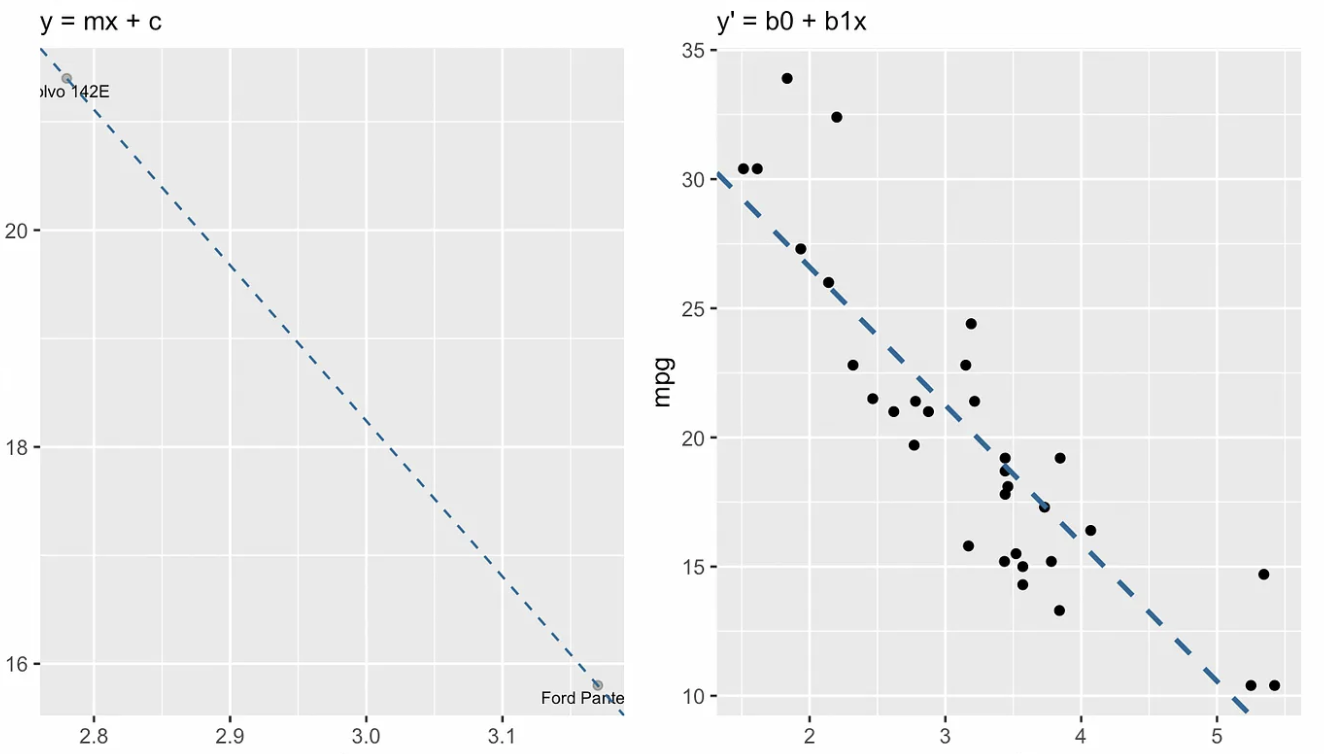 Bentuk gradien–titik potong vs. persamaan regresi linear sederhana. Gambar oleh Penulis
Bentuk gradien–titik potong vs. persamaan regresi linear sederhana. Gambar oleh Penulis
Jika kita hanya menggunakan persamaan gradien–titik potong, kita akan menemukan nilai m (gradien) dan b (titik potong pada sumbu-y) dengan terlebih dahulu menghitung gradien sebagai ‘kenaikan per langkah’ (rise over run), yaitu mengukur perubahan pada y terhadap perubahan pada x antara dua titik pada garis. Lalu, setelah menemukan gradien, kita akan menemukan titik potong sumbu-y b dengan mensubstitusikan koordinat salah satu titik pada garis ke dalam persamaan dan menyelesaikan untuk b. Langkah akhir ini memberi Anda titik di mana garis memotong sumbu-y.
Ini tidak bekerja dalam regresi karena tidak ada garis yang melewati semua titik, itulah sebabnya kita mencari garis terbaik (line of best fit). Untungnya, ada persamaan bentuk tertutup yang rapi untuk menemukan gradien dan titik potong.
Gradien dapat dihitung dengan mengalikan korelasi r dengan hasil bagi simpangan baku y atas simpangan baku x. Ini masuk akal secara intuitif karena pada dasarnya kita mengonversi kembali koefisien korelasi ke dalam satuan variabel asal. Pada persamaan di bawah, a merujuk pada gradien dan sy dan sx merujuk pada simpangan baku y dan simpangan baku x, masing-masing.
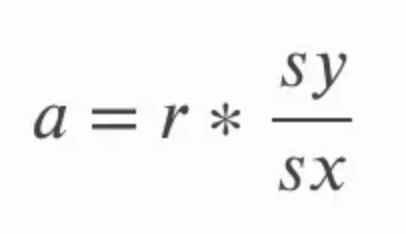
Titik potong garis terbaik untuk regresi linear sederhana dapat dihitung setelah kita menghitung gradien. Kita melakukannya dengan mengurangkan hasil kali gradien dan mean x dari mean y. Pada persamaan di bawah, i merujuk pada titik potong sumbu-y dan garis di atas nilai x dan y adalah cara untuk merujuk pada mean x dan mean y masing-masing; kita menyebut istilah ini sebagai x-bar dan y-bar.
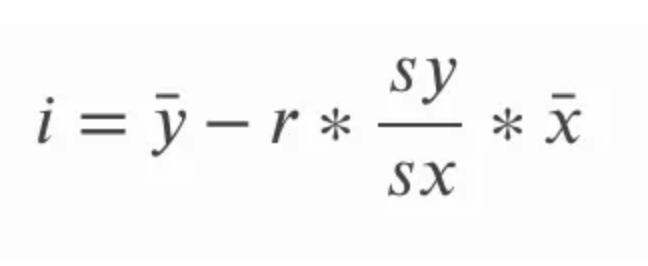
Demi kelengkapan, kita dapat mengeksplorasi cara alternatif untuk menulis persamaan ini. Ingat bahwa simpangan baku sama dengan akar kuadrat dari varians, jadi alih-alih merujuk pada simpangan baku y dan simpangan baku x, kita juga bisa merujuk pada akar kuadrat varians y dan akar kuadrat varians x. Varians itu sendiri, kita ingat, adalah rata-rata dari jumlah kuadrat.
Pada persamaan di atas untuk gradien, a, kita juga bisa menulis sy dan sx dalam bentuk simpangan baku, dan kita juga bisa menuliskan bentuk panjang persamaan untuk korelasi r. Kita kemudian dapat mengalikan silang dan menyederhanakan persamaan dengan menghilangkan suku-suku yang sama dan mendapatkan set persamaan berikut untuk gradien dan titik potong. Poinnya di sini bukan untuk menunjukkan bagaimana satu persamaan berubah menjadi yang lain, tetapi untuk menekankan bahwa kedua persamaan tersebut sama karena Anda mungkin melihat salah satunya.
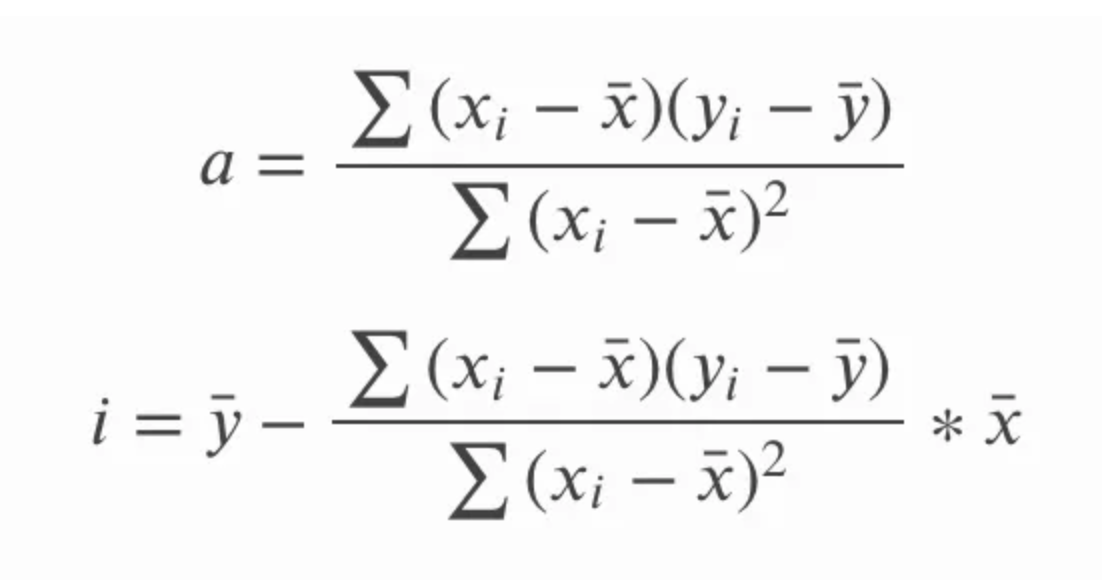
Konsekuensi menarik lainnya adalah bahwa garis regresi linear sederhana akan melewati titik pusat, yaitu mean dari x dan mean dari y. Dengan kata lain, regresi linear sederhana berpotongan pada nilai rata-rata kedua variabel independen dan dependen, terlepas dari sebaran titik data, yang membantu memberikan sifat semacam ‘menyeimbangkan’ pada regresi linear sederhana.
Kita telah melihat cara menemukan koefisien model regresi linear sederhana menggunakan persamaan yang rapi. Di sini, kita akan melihat lebih rinci beberapa metode lain yang melibatkan aljabar linear dan kalkulus. Lingkungan pemrograman, khususnya, menyelesaikan dengan teknik yang lebih maju karena teknik ini lebih cepat dan lebih presisi (hal tentang menguadratkan untuk mencari varians dapat mengurangi presisi).
Sekarang mari kita lihat asumsi utama model regresi linear sederhana. Jika asumsi-asumsi ini dilanggar, kita mungkin ingin mempertimbangkan pendekatan lain. Tiga yang pertama, khususnya, merupakan asumsi kuat dan tidak boleh diabaikan.
Misalkan kita telah membuat model regresi linear sederhana. Bagaimana kita tahu apakah model tersebut sesuai dengan baik? Untuk menjawabnya, kita dapat melihat plot diagnostik dan statistik model.
Plot diagnostik membantu kita melihat apakah model regresi linear sederhana cocok dengan baik dan tidak melanggar asumsi. Pola atau deviasi apa pun dalam plot ini menunjukkan masalah model yang perlu diperhatikan atau informasi yang tidak tertangkap. Salah satu plot diagnostik yang unik untuk regresi linear sederhana adalah plot nilai x versus residual, seperti yang dapat Anda lihat di bawah. Plot tambahan mencakup Q-Q plot, plot skala–lokasi, nomor observasi vs. jarak cook, dan lainnya.
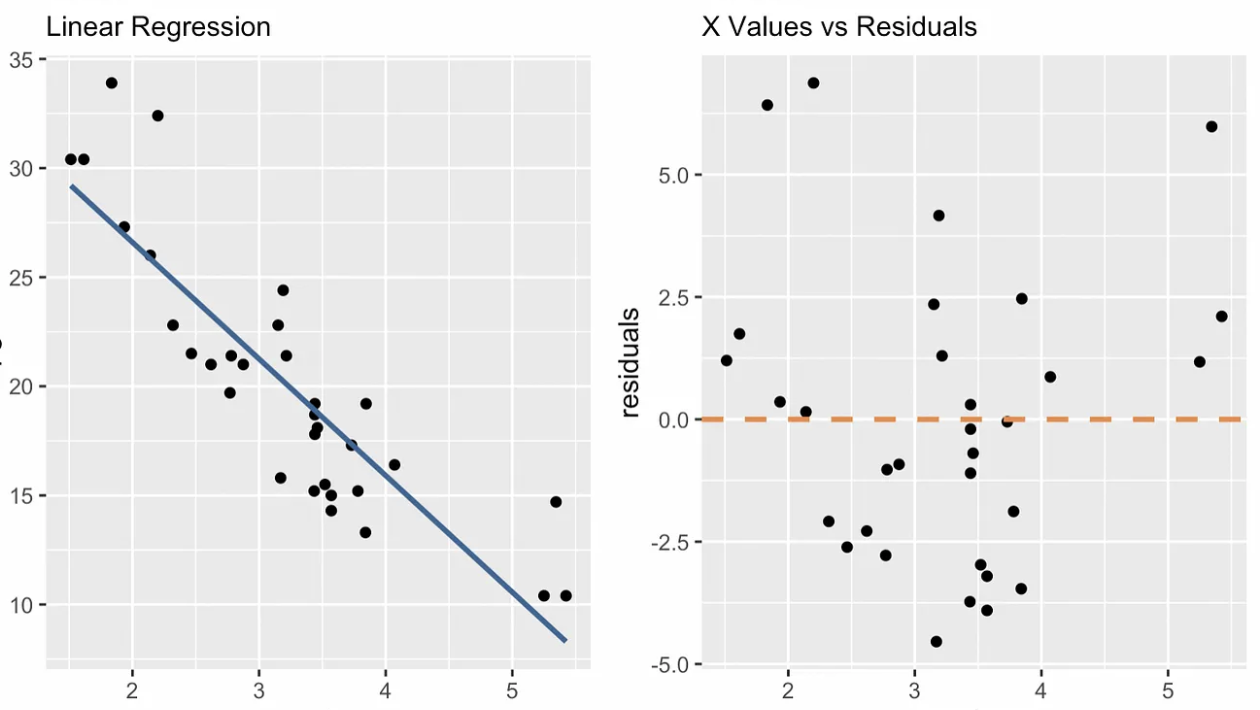 Plot diagnostik nilai x vs. residual. Gambar oleh Penulis
Plot diagnostik nilai x vs. residual. Gambar oleh Penulis
Statistik model seperti R-squared dan Adjusted R-squared mengukur seberapa baik variabel independen menjelaskan varians pada variabel dependen. F-statistic menguji signifikansi keseluruhan model, dan p-value untuk koefisien memberi tahu kita tentang dampak prediktor individual.
Saat menafsirkan hasil regresi linear sederhana, kita harus berhati-hati untuk tepat dalam cara kita membicarakan hubungan antara variabel independen dan variabel dependen.
Secara khusus, kita harus berhati-hati saat membicarakan dua komponen kunci: gradien dan titik potong.
Satu hal penting untuk dipertimbangkan adalah bahwa korelasi tidak sama dengan kausalitas. Analis yang akrab dengan konsep ini masih bisa keliru saat menafsirkan regresi linear sederhana karena kurang terbiasa dengan diksi yang tepat. Anda tidak akan mengatakan bahwa tinggi pohon menyebabkan lebih banyak daun, melainkan Anda bisa mengatakan bahwa peningkatan satu satuan tinggi pohon berkaitan dengan peningkatan sejumlah daun tertentu.
Pertimbangan penting lainnya adalah bahwa mengekstrapolasi di luar rentang data mungkin tidak menghasilkan prediksi yang andal. Model regresi linear sederhana yang memprediksi jumlah daun dari tinggi pohon mungkin tidak terlalu akurat untuk pohon yang sangat pendek atau sangat tinggi, terutama jika pohon pendek atau tinggi tidak dipertimbangkan dalam pembuatan model kita.
Model linear disebut model linear karena linear dalam bentuk fungsionalnya. Secara khusus, dalam regresi linear sederhana, hubungan antara variabel respons y dan variabel prediktor x dimodelkan sebagai kombinasi linear dari prediktor dan konstanta. Meski begitu, Anda mungkin akan terkejut dengan apa yang bisa dilakukan dengan regresi linear sederhana. Walaupun model mengasumsikan hubungan garis lurus antarvariabel, Anda dapat memperkenalkan transformasi untuk menangkap hubungan non-linear.
Sebagai contoh, pertimbangkan hubungan non-linear yang merepresentasikan pertumbuhan jumlah leluhur per generasi di mana jumlah leluhur tampak tumbuh secara eksponensial setiap generasi: dua orang tua, empat kakek-nenek, delapan buyut, dan seterusnya. Anda tidak akan berharap model linear menangkap pertumbuhan eksponensial, tetapi dengan memprediksi log(y) alih-alih y, Anda melineariskan hubungan tersebut.
Namun, berpikir lebih jauh, Anda menyadari bahwa tidak ada pertumbuhan eksponensial jumlah leluhur karena sesuatu yang disebut pedigree collapse, yaitu laju pertumbuhan melambat drastis dari waktu ke waktu karena leluhur jauh muncul di beberapa tempat pada silsilah keluarga. Karena alasan ini, mengambil log(y) mungkin telah terlalu memperkuat model kita. Kini, untuk melunakkannya, kita dapat membuat variabel baru berupa transformasi akar kuadrat pada x dan menggunakannya sebagai prediktor. Sekarang, saya tidak bilang model ini benar, atau mencoba menafsirkannya sepenuhnya, tetapi saya ingin menunjukkan bagaimana log(y) dan akar kuadrat dari x adalah transformasi non-linear yang masuk ke dalam persamaan secara linear terhadap koefisien, jadi kita tetap memiliki regresi linear sederhana.
Mari pertimbangkan regresi linear sederhana di R dan Python.
R adalah salah satu opsi yang sangat baik untuk regresi linear sederhana.
Kita dapat menemukan koefisien sendiri dengan menghitung mean dan simpangan baku variabel kita.
# Manually calculate the slope and intercept in R
# Sample data
X <- c(1, 2, 3, 4, 5)
y <- c(2, 4, 5, 4, 5)
# Calculate means
mean_X <- mean(X)
mean_y <- mean(y)
# Calculate standard deviations
sd_X <- sd(X)
sd_y <- sd(y)
# Calculate correlation
correlation <- cor(X, y)
# Calculate slope (b1) using the formula: b1 = (correlation * sd_y) / sd_X
slope <- (correlation * sd_y) / sd_X
# Calculate intercept (b0) using the formula: b0 = mean_y - slope * mean_X
intercept <- mean_y - slope * mean_X
# Print the slope and intercept
cat("Slope (b1):", slope, "\n")
cat("Intercept (b0):", intercept, "\n")
# Use the manually calculated coefficients to predict y values
y_pred <- intercept + slope * X
cat("Predicted values:", y_pred, "\n")Di R, kita dapat membuat regresi menggunakan fungsi lm(), yang dapat kita akses tanpa perlu menggunakan pustaka apa pun.
# Fit the model
model <- lm(y ~ X)
# Print the summary of the regression
summary(model)Python adalah opsi hebat lainnya untuk regresi linear sederhana.
Di sini kita mencari mean dan simpangan baku untuk setiap variabel.
import numpy as np
# Sample data
X = np.array([1, 2, 3, 4, 5])
y = np.array([2, 4, 5, 4, 5])
# Calculate means
mean_X = np.mean(X)
mean_y = np.mean(y)
# Calculate standard deviations
sd_X = np.std(X, ddof=1)
sd_y = np.std(y, ddof=1)
# Calculate correlation
correlation = np.corrcoef(X, y)[0, 1]
# Calculate slope (b1) using the formula: b1 = (correlation * sd_y) / sd_X
slope = (correlation * sd_y) / sd_X
# Calculate intercept (b0) using the formula: b0 = mean_y - slope * mean_X
intercept = mean_y - slope * mean_X
# Print the slope and intercept
print(f"Slope (b1): {slope}")
print(f"Intercept (b0): {intercept}")
# Use the manually calculated coefficients to predict y values
y_pred = intercept + slope * X
print(f"Predicted values: {y_pred}")statsmodels adalah salah satu opsi untuk regresi linear sederhana.
import statsmodels.api as sm
# Adding a constant for the intercept
X = sm.add_constant(X)
# Fit the model
model = sm.OLS(y, X)
results = model.fit()
# Print the summary of the regression
print(results.summary())Regresi linear sederhana digunakan dalam pengujian hipotesis dan menjadi inti dalam uji t serta analysis of variance (ANOVA).
Sebuah uji t sering digunakan untuk menentukan apakah gradien garis regresi berbeda secara signifikan dari nol. Uji ini membantu kita memahami apakah variabel independen memiliki efek yang signifikan secara statistik. Intinya, kita merumuskan hipotesis nol yang menyatakan bahwa gradien garis regresi sama dengan nol, yang berarti tidak ada hubungan linear, dan uji t mengevaluasi hal ini. Regresi linear sederhana terkait di sini karena regresi linear sederhana dengan variabel independen biner sama dengan perbedaan mean, seperti yang kita lihat dalam uji t.
Analysis of variance (ANOVA) adalah metode statistik yang digunakan untuk menilai kesesuaian keseluruhan model dan untuk menentukan apakah variabel independen menjelaskan porsi varians yang signifikan pada variabel dependen. Yang kita lakukan adalah mempartisi total varians variabel dependen menjadi dua komponen: varians yang dijelaskan oleh model regresi (antar kelompok) dan varians karena residual atau galat (dalam kelompok). Uji F pada ANOVA pada dasarnya menguji apakah model regresi, secara keseluruhan, lebih cocok dengan data daripada model tanpa prediktor. Misalnya, dalam contoh tinggi pohon dan jumlah daun, ANOVA akan membantu menentukan apakah memasukkan tinggi pohon secara signifikan meningkatkan kemampuan kita untuk memprediksi jumlah daun.
Kita mengatakan bahwa ordinary least squares adalah estimator yang sejauh ini paling umum dalam regresi linear sederhana, dan kita telah berfokus pada OLS dalam artikel ini. Namun, kita perlu mempertimbangkan bahwa estimator ordinary least squares sensitif terhadap, atau tidak robust terhadap, pencilan. Jadi menambahkan titik data yang sangat berpengaruh atau berkekuatan ungkit tinggi dapat secara drastis mengubah gradien dan titik potong garis.
Karena alasan ini, opsi non-parametrik tersedia. Visualisasi berikut menunjukkan ordinary least squares dengan tiga alternatif non-parametrik: median absolute deviation (MAD), least median squares (LMS), dan Theil–Sen. Perhatikan bahwa gradien dan titik potong berbeda untuk setiap estimator. Jika kita menambahkan titik yang sangat berpengaruh pada, katakanlah, koordinat x = 7 dan y = 70, maka garis regresi ordinary least squares akan berubah paling banyak.
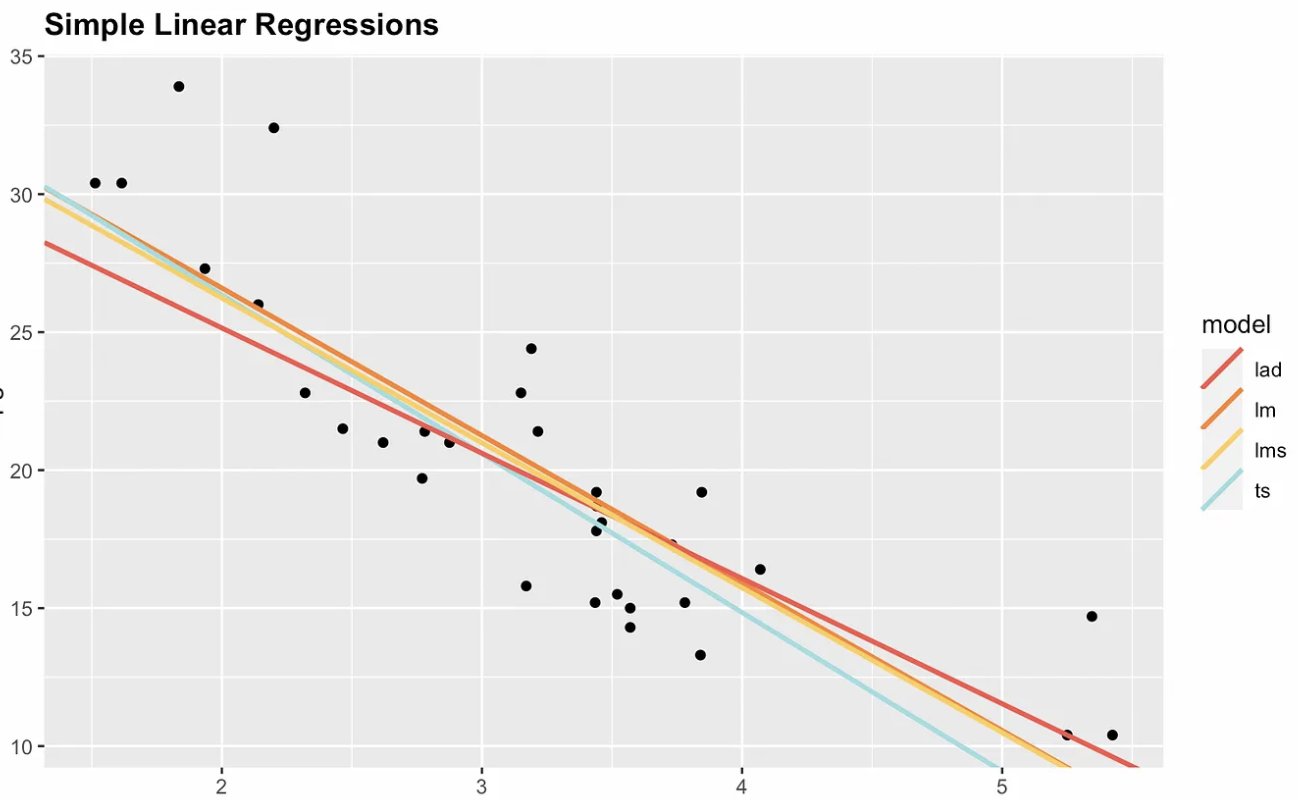 Empat opsi regresi linear sederhana. Gambar oleh Penulis
Empat opsi regresi linear sederhana. Gambar oleh Penulis
Regresi linear sederhana adalah titik awal untuk memahami hubungan yang lebih kompleks dalam data. Untuk membantu, DataCamp menawarkan tutorial agar Anda dapat terus berlatih, termasuk tutorial Essentials of Linear Regression in Python, tutorial How to Do Linear Regression in R, dan tutorial Linear Regression in Excel: A Comprehensive Guide For Beginners.
Sumber daya ini akan memandu Anda menggunakan berbagai alat untuk melakukan regresi linear dan memahami penerapannya. Terakhir, jika Anda siap mengembangkan keterampilan, lihat Multiple Linear Regression in R: Tutorial With Examples, yang membahas model yang lebih kompleks dengan banyak prediktor. Anda juga dapat menonton video YouTube kami Regression in Excel Made Easy untuk panduan ramah pemula yang khusus Excel.
Pelajari Regresi Linear Sederhana bersama DataCamp
Kursus
Kursus
Kursus
blogs
David Woods
13 mnt
blogs
Hugo Bowne-Anderson
13 mnt
blogs
Dario Radečić
15 mnt
blogs
Javier Canales Luna
14 mnt
