
Cursus
Inference for Linear Regression in R
4 Hr
16K
Elk verhaal begint ergens, en voor de data-analist of data scientist begint het verhaal vaak bij eenvoudige lineaire regressie. Eenvoudige lineaire regressie is misschien wel het meest fundamentele model van allemaal. Dus als je serieus aan de slag wilt als data-analist of data scientist, dan is eenvoudige lineaire regressie (en regressie in het algemeen) absoluut basiskennis.
Regressie is het leren waard, niet alleen omdat het een onmisbare techniek is om prangende vragen te beantwoorden in vrijwel elk vakgebied, maar ook omdat het de deur opent naar een dieper begrip van heel veel andere onderwerpen, zoals hypothesetoetsing, causale inferentie en forecasting. Volg daarom vandaag nog onze cursussen Introduction to Regression in R en Introduction to Regression with statsmodels in Python.
Eenvoudige lineaire regressie is een lineaire regressie met één onafhankelijke variabele, ook wel de verklarende variabele, en één afhankelijke variabele, ook wel de responsvariabele. Bij eenvoudige lineaire regressie is de afhankelijke variabele continu.
De meest gangbare manier om eenvoudige lineaire regressie uit te voeren is met gewone kleinste kwadraten (ordinary least squares, OLS). Omdat OLS veruit de meest gebruikte methode is, wordt het deel “ordinary least squares” vaak impliciet bedoeld wanneer we over eenvoudige lineaire regressie spreken.
Ordinary least squares werkt door de som van de gekwadrateerde verschillen te minimaliseren tussen de geobserveerde waarden (de werkelijke datapunten) en de voorspelde waarden van de regressielijn. Deze verschillen heten residuen, en door ze te kwadrateren worden positieve en negatieve residuen gelijk behandeld.
Eenvoudige lineaire regressie helpt om voorspellingen te doen en relaties te begrijpen tussen één onafhankelijke variabele en één afhankelijke variabele. Je wilt bijvoorbeeld weten hoe de hoogte van een boom (onafhankelijke variabele) het aantal bladeren (afhankelijke variabele) beïnvloedt. Door data te verzamelen en een eenvoudig lineair regressiemodel te fitten, kun je het aantal bladeren voorspellen op basis van de boomhoogte. Dat is het deel ‘voorspellingen doen’. Maar deze aanpak laat ook zien hoeveel het aantal bladeren gemiddeld verandert naarmate de boom hoger wordt, en zo gebruiken we eenvoudige lineaire regressie ook om relaties te begrijpen.
Laten we de vergelijking voor eenvoudige lineaire regressie bekijken. We kunnen beginnen met de richtingscoëfficiënt-vorm van een rechte lijn, in notatie die je vaak in meetkunde- of algebraboeken ziet. We beginnen dus echt bij het begin.
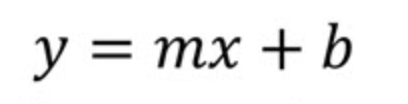
Hierbij
In de context van data science zie je echter vaker deze vergelijking:
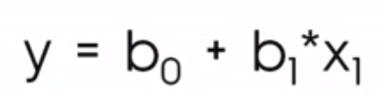
Waarbij
De notatie met b0 en b1 maakt duidelijk dat we een voorspelling doen voor y, daarom noteren we dit als ŷ, of y-hat, omdat we niet verwachten dat onze regressielijn daadwerkelijk door alle punten loopt.
De volgende visualisatie laat het conceptuele verschil zien tussen de richtingscoëfficiënt-vorm van de lijn, links, en de regressievergelijking, rechts. In de taal van lineaire algebra zouden we zeggen dat het stelsel lineaire vergelijkingen overbepaald is: er zijn meer vergelijkingen (een dertigtal) dan onbekenden (twee), dus we verwachten geen exacte oplossing te vinden.
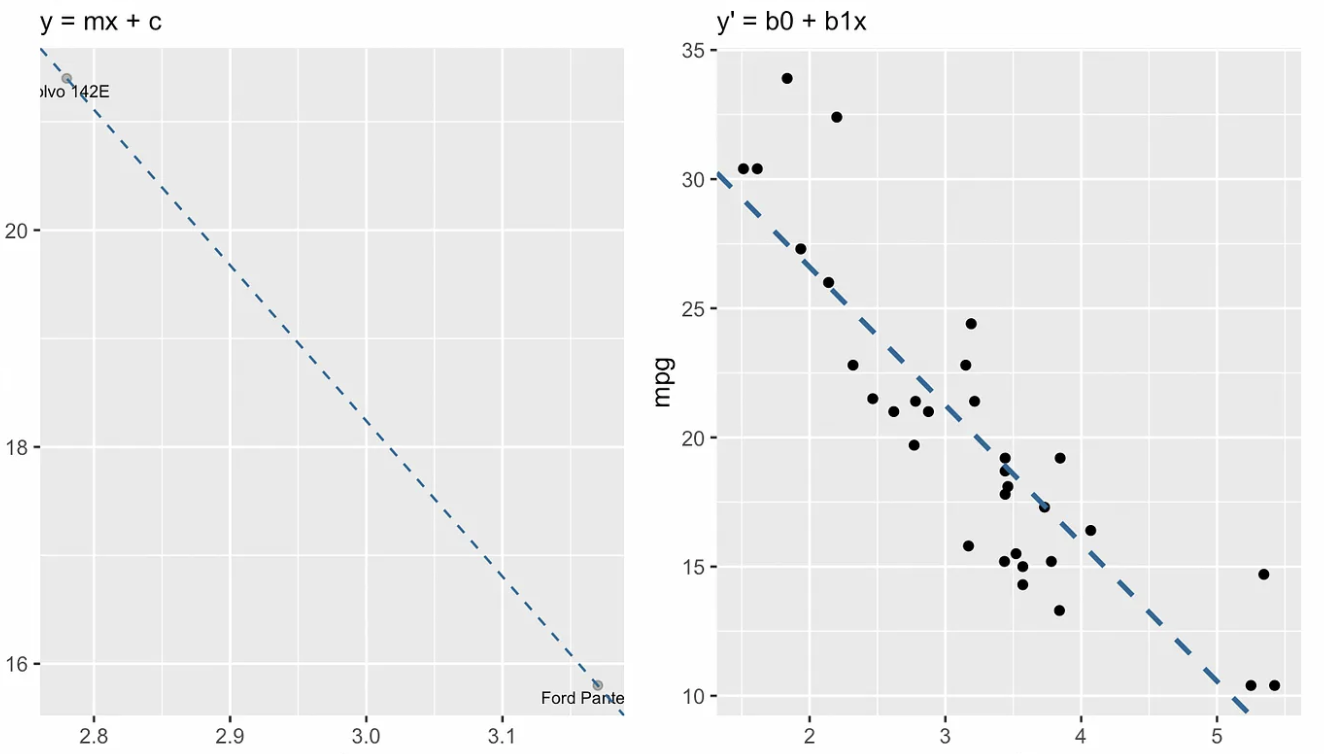 Richtingscoëfficiënt-vorm vs. vergelijking voor eenvoudige lineaire regressie. Afbeelding door de auteur
Richtingscoëfficiënt-vorm vs. vergelijking voor eenvoudige lineaire regressie. Afbeelding door de auteur
Als we alleen de richtingscoëfficiënt-vorm zouden gebruiken, zouden we de waarden van m (helling) en b (snijpunt met de y-as) vinden door eerst de helling te berekenen als ‘rijs over run’, oftewel de verandering in y over de verandering in x tussen twee punten op de lijn. Zodra we de helling hebben, vinden we het snijpunt met de y-as b door de coördinaten van één punt op de lijn in te vullen in de vergelijking en op te lossen naar b. Deze laatste stap geeft het punt waar de lijn de y-as kruist.
Dit werkt niet bij regressie omdat er geen lijn is die door alle punten gaat. Daarom zoeken we de best passende lijn. Gelukkig bestaan er nette, gesloten-formule vergelijkingen om de helling en het snijpunt te vinden.
De helling kun je berekenen door de correlatie r te vermenigvuldigen met de quotient van de standaarddeviatie van y over de standaarddeviatie van x. Dit is intuïtief logisch omdat we de correlatiecoëfficiënt in feite terugvertalen naar de eenheden van de oorspronkelijke variabelen. In de onderstaande vergelijking verwijst a naar de helling en verwijzen sy en sx respectievelijk naar de standaarddeviatie van y en de standaarddeviatie van x.
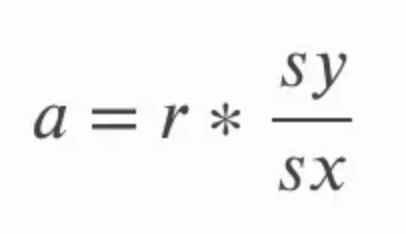
Het snijpunt van de best passende lijn voor eenvoudige lineaire regressie kunnen we berekenen nadat we de helling hebben berekend. Dit doen we door het product van de helling en het gemiddelde van x af te trekken van het gemiddelde van y. In de onderstaande vergelijking verwijst i naar het snijpunt met de y-as en verwijzen de streepjes boven de x- en y-waarden naar het gemiddelde van respectievelijk x en y; we noemen deze termen x-bar en y-bar.
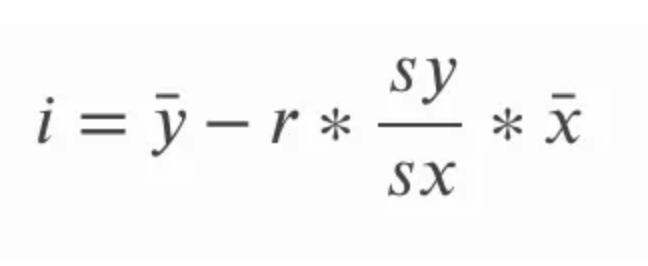
Om volledig te zijn, kunnen we alternatieve schrijfwijzen van deze vergelijkingen verkennen. Onthoud dat de standaarddeviatie gelijk is aan de wortel uit de variantie, dus in plaats van te verwijzen naar de standaarddeviatie van y en de standaarddeviatie van x, kunnen we ook verwijzen naar de wortel uit de variantie van y en de wortel uit de variantie van x. De variantie zelf, herinneren we ons, is het gemiddelde van de som van kwadraten.
In de bovenstaande vergelijking voor de helling, a, zouden we sy en sx ook in termen van de standaarddeviatie kunnen schrijven, en we zouden de langere vorm van de vergelijking voor de correlatie r kunnen uitschrijven. We zouden dan kruislings kunnen vermenigvuldigen en de vergelijking vereenvoudigen door gemeenschappelijke termen te schrappen, en zo op de volgende set vergelijkingen voor helling en snijpunt uitkomen. Het punt hier is minder om te laten zien hoe de ene vergelijking in de andere overgaat en meer om te benadrukken dat beide vergelijkingen hetzelfde zijn, omdat je beide varianten kunt tegenkomen.
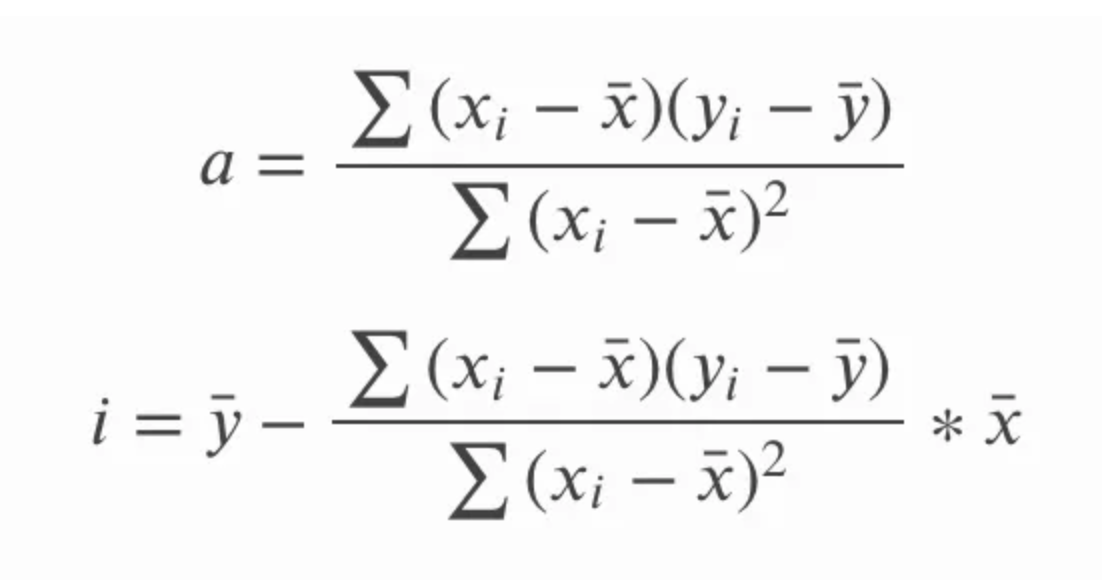
Een andere interessante consequentie is dat de lijn van de eenvoudige lineaire regressie door het centrale punt gaat, namelijk het gemiddelde van x en het gemiddelde van y. Met andere woorden: de eenvoudige lineaire regressie snijdt bij de gemiddelden van zowel de onafhankelijke als de afhankelijke variabele, ongeacht de verdeling van de datapunten. Dit geeft de eenvoudige lineaire regressie haar ‘balancerende’ eigenschap.
We zagen hoe we de modelcoëfficiënten van eenvoudige lineaire regressie kunnen vinden met nette vergelijkingen. Hier bekijken we in meer detail enkele andere methoden uit de lineaire algebra en de calculus. Programmeeromgevingen lossen dit met name op via meer geavanceerde technieken omdat die sneller en preciezer zijn (het kwadrateren om de variantie te vinden kan de precisie verminderen).
Laten we nu de belangrijkste aannames van het model voor eenvoudige lineaire regressie bekijken. Als deze aannames geschonden worden, kun je beter een andere aanpak overwegen. Vooral de eerste drie zijn sterke aannames en mogen niet genegeerd worden.
Stel, we hebben een eenvoudig lineair regressiemodel gemaakt. Hoe weten we of het een goede fit is? Hiervoor kunnen we kijken naar diagnostische plots en modelstatistieken.
Diagnostische plots helpen ons te zien of een eenvoudig lineair regressiemodel goed past en onze aannames niet schendt. Patronen of afwijkingen in deze plots duiden op modelproblemen die aandacht vragen of op informatie die niet is vastgelegd. Een diagnostische plot die uniek is voor eenvoudige lineaire regressie is de plot van x-waarden tegen residuen, zoals je hieronder ziet. Extra plots zijn de Q-Q-plot, de schaal-locatie-plot, observatienummer vs. Cook’s distance, en andere.
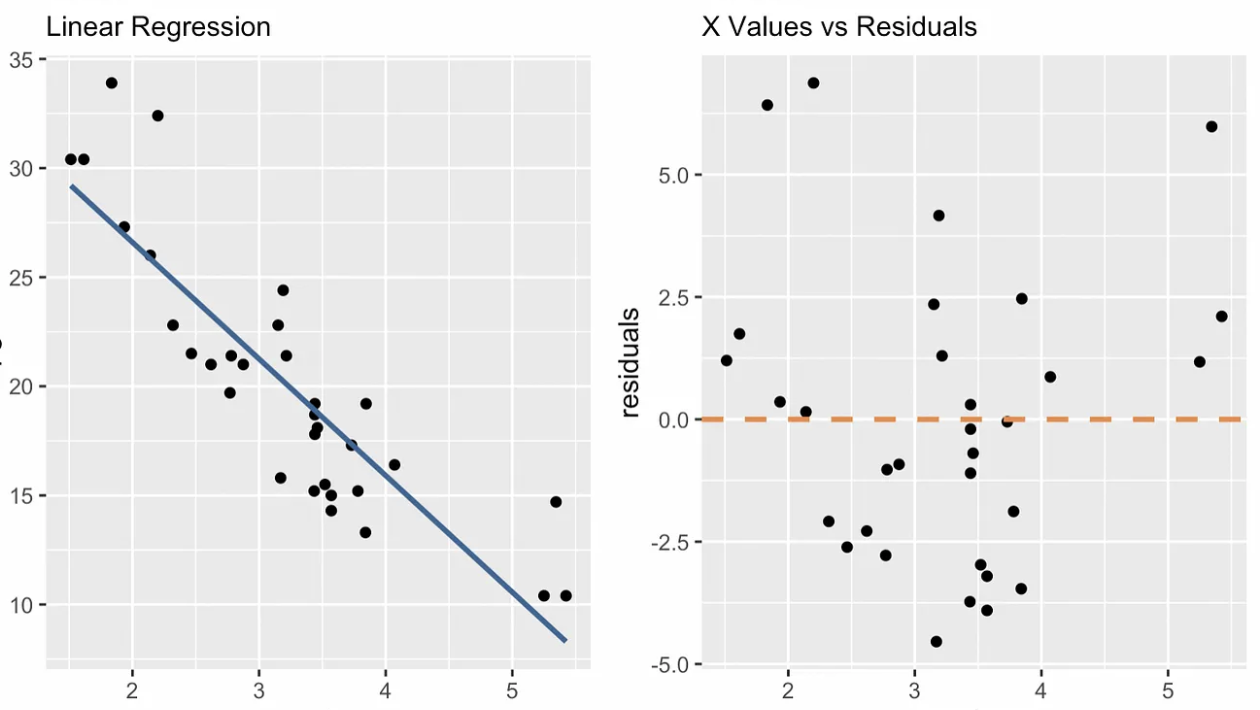 x-waarden vs. residuen diagnostische plot. Afbeelding door de auteur
x-waarden vs. residuen diagnostische plot. Afbeelding door de auteur
Modelstatistieken zoals R-kwadraat en aangepast R-kwadraat kwantificeren hoe goed de onafhankelijke variabele de variantie in de afhankelijke variabele verklaart. De F-statistiek test de algehele significantie van het model, en p-waarden voor coëfficiënten vertellen ons iets over de impact van individuele voorspellers.
Bij het interpreteren van de resultaten van eenvoudige lineaire regressie moeten we precies zijn in hoe we de relatie tussen de onafhankelijke en de afhankelijke variabele beschrijven.
We moeten vooral zorgvuldig zijn bij de twee kernonderdelen: de helling en het snijpunt.
Eén belangrijk aandachtspunt is dat correlatie niet gelijkstaat aan causaliteit. Analisten die met dit concept bekend zijn, kunnen nog steeds de fout ingaan bij het interpreteren van eenvoudige lineaire regressie omdat ze niet geoefend zijn in de juiste bewoording. Je zou niet zeggen dat boomhoogte meer bladeren veroorzaakt, maar je kunt wel zeggen dat een toename van één eenheid in boomhoogte geassocieerd is met een toename van een bepaald aantal bladeren.
Een andere belangrijke overweging is dat extrapoleren buiten het bereik van de data mogelijk geen betrouwbare voorspellingen oplevert. Een eenvoudig lineair regressiemodel dat het aantal bladeren voorspelt op basis van de boomhoogte is wellicht niet erg nauwkeurig voor heel kleine of heel grote bomen, zeker als zulke bomen niet zijn meegenomen bij het opstellen van ons model.
Lineaire modellen heten lineair omdat ze lineair zijn in hun functionele vorm. Concreet wordt bij eenvoudige lineaire regressie de relatie tussen de responsvariabele y en de voorspeller x gemodelleerd als een lineaire combinatie van de voorspeller en een constante. Toch zul je verrast zijn door wat je met een eenvoudige lineaire regressie kunt doen. Hoewel het model een rechte-lijnrelatie tussen variabelen aanneemt, kun je transformaties introduceren om niet-lineaire relaties te vangen.
Neem bijvoorbeeld de niet-lineaire relatie die de groei van voorouders per generatie weergeeft, waarbij het aantal voorouders met elke generatie exponentieel lijkt te groeien: twee ouders, vier grootouders, acht overgrootouders, enzovoort. Je zou niet verwachten dat een lineair model exponentiële groei vangt, maar door log(y) te voorspellen in plaats van y, lineariseer je de relatie.
Als je verder nadenkt, realiseer je je echter dat er geen exponentiële groei in voorouders is door iets dat pedigree collapse heet: de groeisnelheid vertraagt sterk in de tijd omdat verre voorouders op meerdere plekken in de stamboom voorkomen. Daarom kan het nemen van de log(y) onze modelvorming te sterk hebben aangezet. Om dit te verzachten, kunnen we een nieuwe variabele maken die een worteltransformatie op x is en die als voorspeller gebruiken. Ik zeg niet dat dit model klopt of dat ik het volledig probeer te interpreteren, maar ik wil laten zien hoe log(y) en de wortel van x niet-lineaire transformaties zijn die lineair in de vergelijking binnenkomen ten opzichte van de coëfficiënten, zodat we nog steeds een eenvoudige lineaire regressie hebben.
Laten we eenvoudige lineaire regressie in R en Python bekijken.
R is een uitstekende optie voor eenvoudige lineaire regressie.
We kunnen de coëfficiënten zelf vinden door het gemiddelde en de standaarddeviatie van onze variabelen te berekenen.
# Manually calculate the slope and intercept in R
# Sample data
X <- c(1, 2, 3, 4, 5)
y <- c(2, 4, 5, 4, 5)
# Calculate means
mean_X <- mean(X)
mean_y <- mean(y)
# Calculate standard deviations
sd_X <- sd(X)
sd_y <- sd(y)
# Calculate correlation
correlation <- cor(X, y)
# Calculate slope (b1) using the formula: b1 = (correlation * sd_y) / sd_X
slope <- (correlation * sd_y) / sd_X
# Calculate intercept (b0) using the formula: b0 = mean_y - slope * mean_X
intercept <- mean_y - slope * mean_X
# Print the slope and intercept
cat("Slope (b1):", slope, "\n")
cat("Intercept (b0):", intercept, "\n")
# Use the manually calculated coefficients to predict y values
y_pred <- intercept + slope * X
cat("Predicted values:", y_pred, "\n")In R kunnen we een regressie maken met de functie lm(), die beschikbaar is zonder extra libraries te laden.
# Fit the model
model <- lm(y ~ X)
# Print the summary of the regression
summary(model)Python is een andere uitstekende optie voor eenvoudige lineaire regressie.
Hier berekenen we het gemiddelde en de standaarddeviatie voor elke variabele.
import numpy as np
# Sample data
X = np.array([1, 2, 3, 4, 5])
y = np.array([2, 4, 5, 4, 5])
# Calculate means
mean_X = np.mean(X)
mean_y = np.mean(y)
# Calculate standard deviations
sd_X = np.std(X, ddof=1)
sd_y = np.std(y, ddof=1)
# Calculate correlation
correlation = np.corrcoef(X, y)[0, 1]
# Calculate slope (b1) using the formula: b1 = (correlation * sd_y) / sd_X
slope = (correlation * sd_y) / sd_X
# Calculate intercept (b0) using the formula: b0 = mean_y - slope * mean_X
intercept = mean_y - slope * mean_X
# Print the slope and intercept
print(f"Slope (b1): {slope}")
print(f"Intercept (b0): {intercept}")
# Use the manually calculated coefficients to predict y values
y_pred = intercept + slope * X
print(f"Predicted values: {y_pred}")statsmodels is een optie voor eenvoudige lineaire regressie.
import statsmodels.api as sm
# Adding a constant for the intercept
X = sm.add_constant(X)
# Fit the model
model = sm.OLS(y, X)
results = model.fit()
# Print the summary of the regression
print(results.summary())Eenvoudige lineaire regressie wordt gebruikt bij hypothesetoetsing en staat centraal in t-toetsen en variantieanalyse (ANOVA).
Een t-toets wordt vaak gebruikt om te bepalen of de helling van de regressielijn significant verschilt van nul. Deze toets helpt ons te begrijpen of de onafhankelijke variabele een statistisch significant effect heeft. In feite formuleren we een nulhypothese die stelt dat de helling van de regressielijn gelijk is aan nul, wat betekent dat er geen lineaire relatie is, en de t-toets beoordeelt dit. Eenvoudige lineaire regressie sluit hierop aan omdat een eenvoudige lineaire regressie met een binaire onafhankelijke variabele gelijkstaat aan een verschil in gemiddelden, zoals we in een t-toets zien.
Variantieanalyse (ANOVA) is een statistische methode om de algehele fit van het model te beoordelen en te bepalen of de onafhankelijke variabele een significant deel van de variantie in de afhankelijke variabele verklaart. We splitsen de totale variantie van de afhankelijke variabele op in twee componenten: de door het regressiemodel verklaarde variantie (tussen groepen) en de variantie door residuen of fout (binnen groepen). De F-toets in ANOVA test in wezen of het regressiemodel als geheel de data beter verklaart dan een model zonder voorspellers. In ons voorbeeld met boomhoogte en aantal bladeren helpt ANOVA bijvoorbeeld te bepalen of het meenemen van boomhoogte onze voorspellingen van het aantal bladeren significant verbetert.
We zeiden dat ordinary least squares veruit de meest gebruikte schatter is bij eenvoudige lineaire regressie, en we hebben ons in dit artikel op OLS gericht. Toch moeten we beseffen dat de OLS-schatting gevoelig is voor, of niet robuust tegen, uitschieters. Het toevoegen van een zeer invloedrijk of high-leverage datapunt kan de helling en het snijpunt van de lijn drastisch veranderen.
Daarom bestaan er niet-parametrische opties. De volgende visualisatie toont ordinary least squares met drie niet-parametrische alternatieven: median absolute deviation (MAD), least median squares (LMS) en Theil-Sen. Let op dat de helling en het snijpunt voor elke schatter anders zijn. Als we een zeer invloedrijk punt zouden toevoegen op bijvoorbeeld de coördinaten x = 7 en y = 70, dan zou de OLS-regressielijn het meest veranderen.
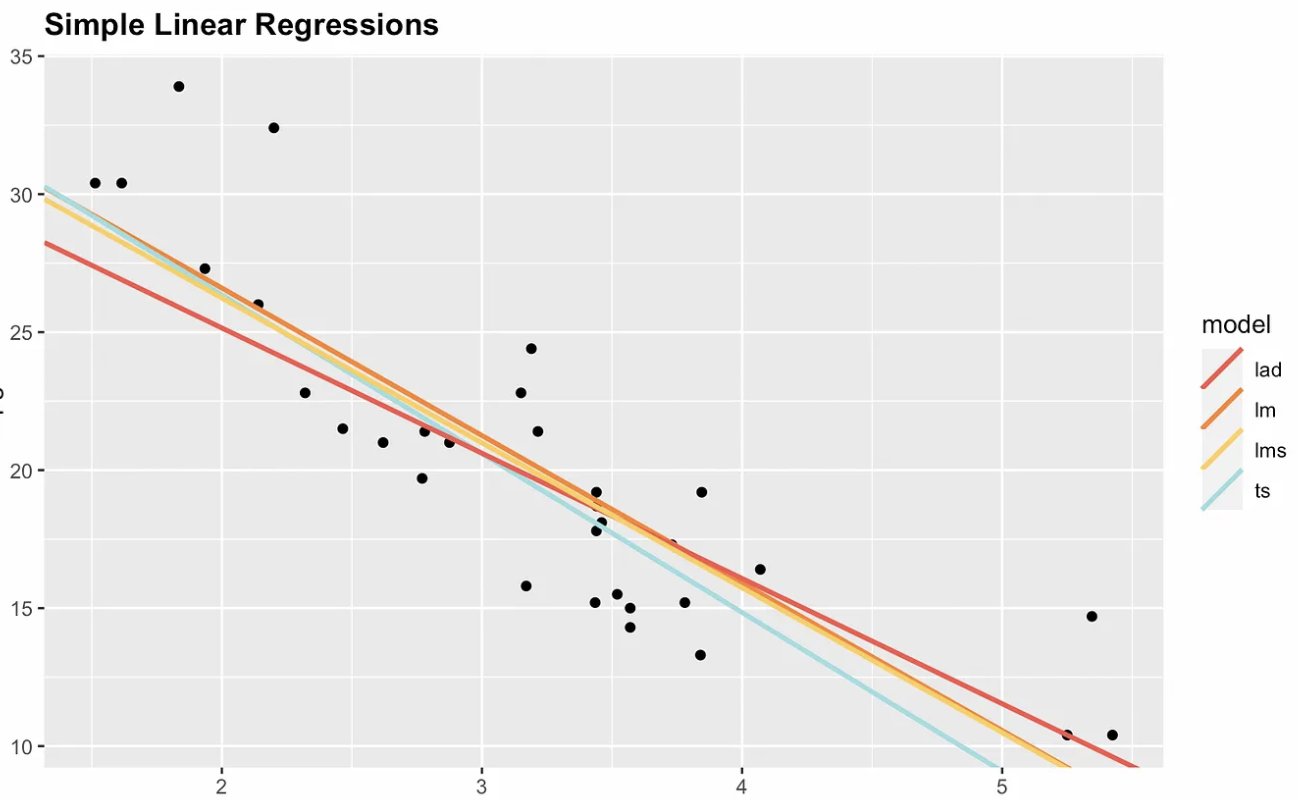 Vier opties voor eenvoudige lineaire regressie. Afbeelding door de auteur
Vier opties voor eenvoudige lineaire regressie. Afbeelding door de auteur
Eenvoudige lineaire regressie is het startpunt om complexere relaties in data te begrijpen. Om je te helpen biedt DataCamp tutorials zodat je kunt blijven oefenen, waaronder onze tutorial Essentials of Linear Regression in Python, de tutorial How to Do Linear Regression in R en de tutorial Linear Regression in Excel: A Comprehensive Guide For Beginners.
Deze bronnen begeleiden je bij het gebruik van verschillende tools om lineaire regressie uit te voeren en de toepassingen ervan te begrijpen. Als je klaar bent om je vaardigheden uit te breiden, bekijk dan onze Multiple Linear Regression in R: Tutorial With Examples, die complexere modellen met meerdere voorspellers behandelt. Je kunt ook onze Regression in Excel Made Easy-video op YouTube bekijken voor een toegankelijke, Excel-specifieke walkthrough.
Leer eenvoudige lineaire regressie met DataCamp
Cursus
Cursus
Cursus
blog
Adel Nehme
15 min
