
Corso
Inferenza per la regressione lineare in R
4 h
16K
Ogni storia inizia da qualche parte e, per l’analista o lo scienziato dei dati, spesso l’inizio è la regressione lineare semplice. Di fatto, la regressione lineare semplice è forse il modello più fondamentale di tutti. Quindi, se vuoi davvero diventare data analyst o data scientist, la regressione lineare semplice (e le regressioni in generale) è qualcosa che devi assolutamente conoscere.
La regressione vale la pena di essere imparata non solo perché è una tecnica preziosissima per rispondere a domande pressanti in praticamente ogni campo, ma anche perché apre la porta a una comprensione più profonda di una grande varietà di altri argomenti, come il test d’ipotesi, l’inferenza causale e la previsione. Dai un’occhiata oggi stesso ai nostri corsi Introduction to Regression in R e Introduction to Regression with statsmodels in Python.
La regressione lineare semplice è una regressione lineare con una variabile indipendente, detta anche variabile esplicativa, e una variabile dipendente, detta anche variabile di risposta. Nella regressione lineare semplice, la variabile dipendente è continua.
Il modo più comune per fare una regressione lineare semplice è tramite la stima a minimi quadrati ordinari (OLS). Poiché l’OLS è di gran lunga il metodo più usato, la parte “minimi quadrati ordinari” è spesso sottintesa quando si parla di regressione lineare semplice.
I minimi quadrati ordinari funzionano minimizzando la somma delle differenze al quadrato tra i valori osservati (i dati reali) e i valori predetti dalla retta di regressione. Queste differenze sono chiamate residui e, elevandole al quadrato, ci si assicura che residui positivi e negativi siano trattati allo stesso modo.
La regressione lineare semplice aiuta a fare previsioni e a capire le relazioni tra una variabile indipendente e una dipendente. Per esempio, potresti voler sapere come l’altezza di un albero (variabile indipendente) influisce sul numero di foglie che ha (variabile dipendente). Raccogliendo dati e adattando un modello di regressione lineare semplice, potresti predire il numero di foglie in base all’altezza dell’albero. Questa è la parte del “fare previsioni”. Ma questo approccio rivela anche di quanto cambia, in media, il numero di foglie man mano che l’albero cresce in altezza, ed è così che la regressione lineare semplice viene usata anche per comprendere le relazioni.
Diamo un’occhiata all’equazione della regressione lineare semplice. Possiamo iniziare guardando la forma esplicita della retta, usando la notazione comune nei libri di geometria o algebra. Cioè, partiamo dall’inizio.
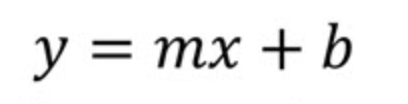
Qui
Nel contesto della data science, è più probabile vedere invece questa equazione:
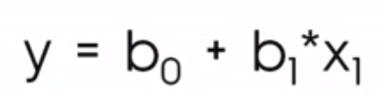
Dove
La notazione con b0 e b1 ci aiuta a capire che stiamo facendo una previsione su y, motivo per cui la chiamiamo ŷ, o y-cappello, dato che non ci aspettiamo che la retta di regressione passi davvero per tutti i punti.
La seguente visualizzazione mostra la differenza concettuale tra la forma esplicita della retta, a sinistra, e l’equazione di regressione, a destra. Nel linguaggio dell’algebra lineare, diremmo che il sistema di equazioni lineari è sovradeterminato, cioè ci sono più equazioni (una trentina) che incognite (due), quindi non ci aspettiamo di trovare una soluzione.
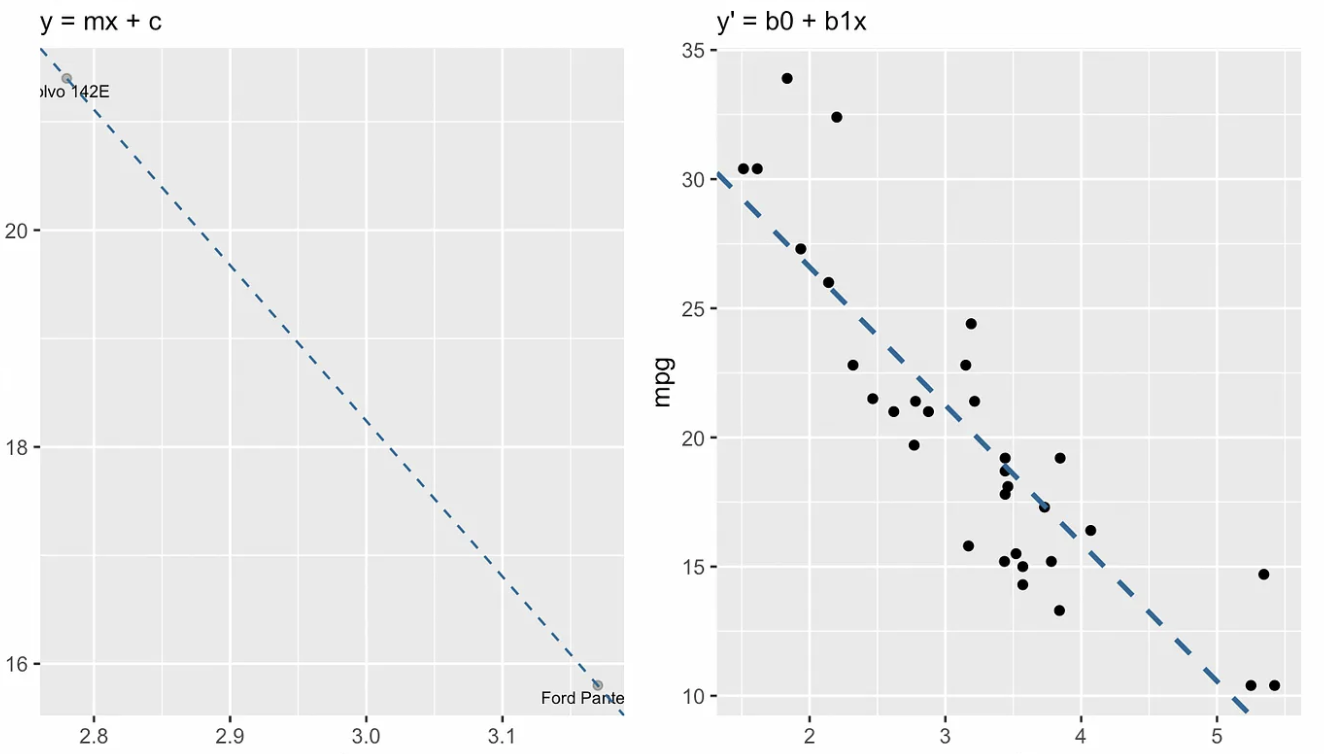 Forma esplicita vs. equazione della regressione lineare semplice. Immagine dell’autore
Forma esplicita vs. equazione della regressione lineare semplice. Immagine dell’autore
Se usassimo soltanto l’equazione della retta, troveremmo i valori di m (pendenza) e b (intercetta) calcolando prima la pendenza come “salita su corsa” (rise over run), cioè misurando la variazione di y sulla variazione di x tra due punti della retta. Poi, una volta trovata la pendenza, troveremmo l’intercetta b sostituendo le coordinate di un punto della retta nell’equazione e risolvendo per b. Questo passaggio finale ti dà il punto in cui la retta incrocia l’asse y.
Questo non funziona nella regressione perché non esiste una retta che passi per tutti i punti, ed è per questo che cerchiamo invece la retta di miglior adattamento. Fortunatamente, esistono equazioni pulite in forma chiusa per trovare pendenza e intercetta.
La pendenza si può calcolare moltiplicando la correlazione r per il rapporto tra la deviazione standard di y e la deviazione standard di x. Questo ha senso intuitivamente perché stiamo sostanzialmente riconvertendo il coefficiente di correlazione nelle unità delle variabili originali. Nell’equazione qui sotto, a indica la pendenza e sy e sx si riferiscono rispettivamente alla deviazione standard di y e alla deviazione standard di x.
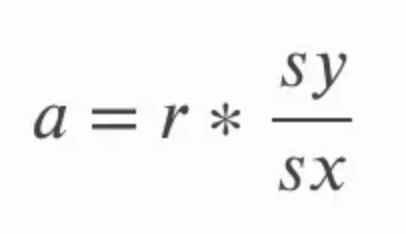
L’intercetta della retta di miglior adattamento per la regressione lineare semplice può essere calcolata dopo aver calcolato la pendenza. Lo facciamo sottraendo dal valore medio di y il prodotto tra la pendenza e il valore medio di x. Nell’equazione seguente, i indica l’intercetta e la lineetta sopra i valori di x e y è un modo per riferirsi alla media di x e alla media di y rispettivamente; ci riferiamo a questi termini come x-barra e y-barra.
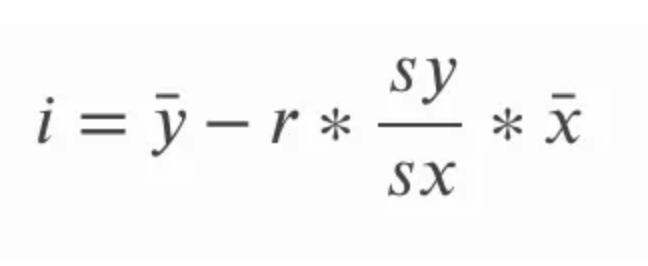
Per completezza, possiamo esplorare modi alternativi di scrivere queste equazioni. Ricorda che la deviazione standard è la radice quadrata della varianza, quindi invece di riferirci alla deviazione standard di y e di x, potremmo anche riferirci alla radice quadrata della varianza di y e alla radice quadrata della varianza di x. La varianza, ricordiamo, è la media della somma dei quadrati.
Nell’equazione della pendenza, a, potremmo anche esprimere sy e sx in termini di deviazione standard, e potremmo anche scrivere la forma estesa della correlazione r. Potremmo quindi moltiplicare in croce e semplificare l’equazione rimuovendo i termini comuni e ottenere il seguente insieme di equazioni per pendenza e intercetta. Il punto qui non è tanto mostrare come un’equazione diventi l’altra, quanto sottolineare che entrambe sono equivalenti, dato che potresti imbatterti nell’una o nell’altra.
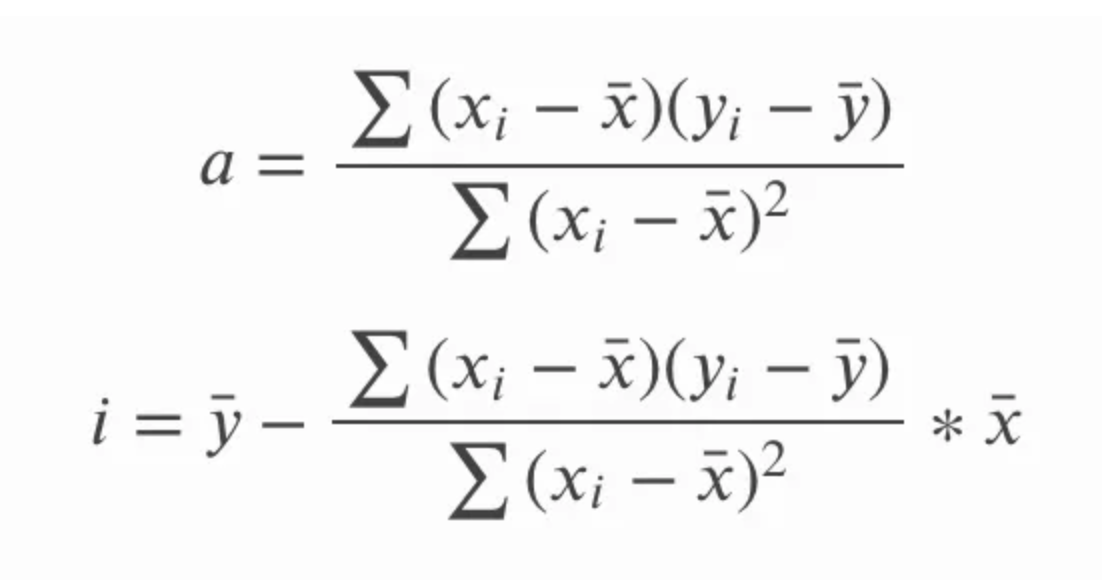
Un’altra conseguenza interessante è che la retta di regressione lineare semplice passerà per il punto centrale, cioè la media di x e la media di y. In altre parole, la regressione lineare semplice interseca la media sia della variabile indipendente sia di quella dipendente, indipendentemente dalla distribuzione dei punti, il che conferisce alla regressione semplice una sorta di proprietà di “bilanciamento”.
Abbiamo visto come trovare i coefficienti del modello di regressione lineare semplice usando comode equazioni. Qui guardiamo più in dettaglio altri metodi che coinvolgono algebra lineare e calcolo. Gli ambienti di programmazione, in particolare, risolvono con tecniche più avanzate perché più rapide e precise (il discorso dell’elevamento al quadrato per trovare la varianza può ridurre la precisione).
Vediamo ora le principali assunzioni del modello di regressione lineare semplice. Se queste assunzioni vengono violate, potremmo voler considerare un approccio diverso. Le prime tre, in particolare, sono assunzioni forti e non andrebbero ignorate.
Supponiamo di aver creato un modello di regressione lineare semplice. Come facciamo a sapere se si adatta bene? Per rispondere, possiamo guardare i grafici diagnostici e le statistiche del modello.
I grafici diagnostici ci aiutano a vedere se un modello di regressione lineare semplice si adatta bene e non viola le nostre assunzioni. Qualsiasi schema o deviazione in questi grafici suggerisce problemi di modello da affrontare o informazioni non catturate. Un grafico diagnostico specifico per la regressione semplice è quello dei valori di x contro i residui, come puoi vedere sotto. Altri grafici includono il Q-Q plot, lo scale-location plot, il numero dell’osservazione vs. distanza di Cook e altri.
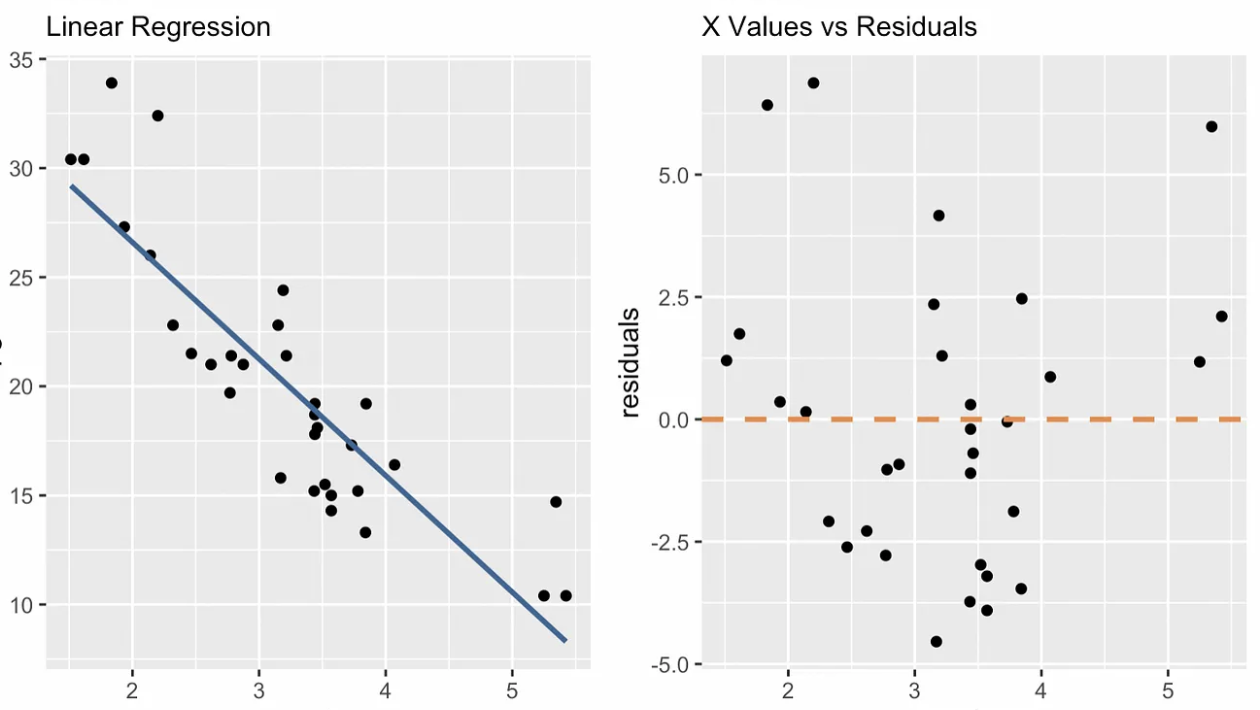 Grafico diagnostico valori di x vs. residui. Immagine dell’autore
Grafico diagnostico valori di x vs. residui. Immagine dell’autore
Statistiche come R-quadro e R-quadro aggiustato quantificano quanto bene la variabile indipendente spiega la varianza della variabile dipendente. L’F-statistic testa la significatività complessiva del modello e i p-value dei coefficienti ci dicono l’impatto dei singoli predittori.
Quando interpreti i risultati della regressione lineare semplice, è bene essere precisi nel modo in cui si parla della relazione tra variabile indipendente e variabile dipendente.
In particolare, bisogna fare attenzione a come si parla dei due elementi chiave: la pendenza e l’intercetta.
Una cosa importante da considerare è che correlazione non implica causalità. Anche gli analisti che conoscono questo concetto possono comunque sbagliare nell’interpretare una regressione semplice perché non hanno molta dimestichezza con le parole da usare. Non diresti che l’altezza dell’albero causa più foglie, ma piuttosto potresti dire che un aumento di un’unità dell’altezza è associato a un aumento di un certo numero di foglie.
Un’altra considerazione importante è che l’extrapolazione oltre l’intervallo dei dati potrebbe non fornire previsioni affidabili. Un modello che predice il numero di foglie dall’altezza dell’albero potrebbe non essere molto accurato per alberi molto bassi o molto alti, soprattutto se alberi così bassi o alti non sono stati considerati nella creazione del modello.
I modelli lineari si chiamano così perché sono lineari nella loro forma funzionale. In particolare, nella regressione lineare semplice, la relazione tra la variabile risposta y e la variabile predittiva x è modellata come una combinazione lineare del predittore e di una costante. Detto questo, potresti sorprenderti da quanto si possa fare con una semplice regressione. Anche se il modello assume una relazione lineare tra le variabili, puoi introdurre trasformazioni per catturare relazioni non lineari.
Per esempio, considera la relazione non lineare che rappresenta la crescita degli antenati per generazione, dove il numero di antenati sembra crescere esponenzialmente a ogni generazione: due genitori, quattro nonni, otto bisnonni e così via. Non ti aspetteresti che un modello lineare catturi una crescita esponenziale, ma predicendo il log(y) invece di y, linearizzi la relazione.
Pensandoci meglio, tuttavia, ti rendi conto che la crescita degli antenati non è esponenziale a causa di qualcosa chiamato “collasso dell’albero genealogico”, in cui il tasso di crescita rallenta drasticamente nel tempo perché antenati lontani compaiono in più punti dell’albero. Per questo motivo, prendere il log(y) potrebbe aver amplificato eccessivamente il nostro modello. Ora, per attenuare questo effetto, possiamo creare una nuova variabile come trasformazione radice quadrata su x e usarla come predittore. Non sto dicendo che questo modello sia corretto, né sto cercando di interpretarlo pienamente, ma voglio mostrare come log(y) e la radice quadrata di x siano trasformazioni non lineari che entrano nell’equazione in modo lineare rispetto ai coefficienti, quindi abbiamo comunque una regressione lineare semplice.
Consideriamo la regressione lineare semplice in R e Python.
R è un’ottima opzione per la regressione lineare semplice.
Possiamo trovare noi stessi i coefficienti calcolando media e deviazione standard delle nostre variabili.
# Manually calculate the slope and intercept in R
# Sample data
X <- c(1, 2, 3, 4, 5)
y <- c(2, 4, 5, 4, 5)
# Calculate means
mean_X <- mean(X)
mean_y <- mean(y)
# Calculate standard deviations
sd_X <- sd(X)
sd_y <- sd(y)
# Calculate correlation
correlation <- cor(X, y)
# Calculate slope (b1) using the formula: b1 = (correlation * sd_y) / sd_X
slope <- (correlation * sd_y) / sd_X
# Calculate intercept (b0) using the formula: b0 = mean_y - slope * mean_X
intercept <- mean_y - slope * mean_X
# Print the slope and intercept
cat("Slope (b1):", slope, "\n")
cat("Intercept (b0):", intercept, "\n")
# Use the manually calculated coefficients to predict y values
y_pred <- intercept + slope * X
cat("Predicted values:", y_pred, "\n")In R, possiamo creare una regressione usando la funzione lm(), accessibile senza dover usare librerie.
# Fit the model
model <- lm(y ~ X)
# Print the summary of the regression
summary(model)Anche Python è un’ottima opzione per la regressione lineare semplice.
Qui troviamo media e deviazione standard per ciascuna variabile.
import numpy as np
# Sample data
X = np.array([1, 2, 3, 4, 5])
y = np.array([2, 4, 5, 4, 5])
# Calculate means
mean_X = np.mean(X)
mean_y = np.mean(y)
# Calculate standard deviations
sd_X = np.std(X, ddof=1)
sd_y = np.std(y, ddof=1)
# Calculate correlation
correlation = np.corrcoef(X, y)[0, 1]
# Calculate slope (b1) using the formula: b1 = (correlation * sd_y) / sd_X
slope = (correlation * sd_y) / sd_X
# Calculate intercept (b0) using the formula: b0 = mean_y - slope * mean_X
intercept = mean_y - slope * mean_X
# Print the slope and intercept
print(f"Slope (b1): {slope}")
print(f"Intercept (b0): {intercept}")
# Use the manually calculated coefficients to predict y values
y_pred = intercept + slope * X
print(f"Predicted values: {y_pred}")statsmodels è un’opzione per la regressione lineare semplice.
import statsmodels.api as sm
# Adding a constant for the intercept
X = sm.add_constant(X)
# Fit the model
model = sm.OLS(y, X)
results = model.fit()
# Print the summary of the regression
print(results.summary())La regressione lineare semplice è usata nel test d’ipotesi ed è centrale nei t-test e nell’analisi della varianza (ANOVA).
Il t-test è spesso usato per determinare se la pendenza della retta di regressione è significativamente diversa da zero. Questo test ci aiuta a capire se la variabile indipendente ha un effetto statisticamente significativo. In pratica, formuliamo un’ipotesi nulla che afferma che la pendenza della retta è uguale a zero, cioè non c’è relazione lineare, e il t-test valuta questa ipotesi. La regressione semplice si collega qui perché una regressione semplice con variabile indipendente binaria equivale a una differenza di medie, come nel t-test.
L’analisi della varianza (ANOVA) è un metodo statistico usato per valutare l’adattamento complessivo del modello e determinare se la variabile indipendente spiega una quota significativa della varianza della variabile dipendente. Ciò che facciamo è suddividere la varianza totale della variabile dipendente in due componenti: la varianza spiegata dal modello di regressione (tra i gruppi) e la varianza dovuta ai residui o errore (all’interno dei gruppi). Il test F in ANOVA verifica essenzialmente se il modello di regressione, nel suo complesso, si adatta ai dati meglio di un modello senza predittori. Per esempio, nel nostro caso di altezza dell’albero e numero di foglie, l’ANOVA aiuterebbe a determinare se includere l’altezza migliora significativamente la capacità di predire il numero di foglie.
Abbiamo detto che i minimi quadrati ordinari sono di gran lunga lo stimatore più comune nella regressione semplice, e in questo articolo ci siamo concentrati sull’OLS. Tuttavia, dovremmo considerare che lo stimatore OLS è sensibile, o non robusto, agli outlier. Quindi aggiungere un punto dati altamente influente o ad alta leva potrebbe cambiare drasticamente pendenza e intercetta della retta.
Per questo motivo, esistono opzioni non parametriche. La visualizzazione seguente mostra i minimi quadrati ordinari insieme a tre alternative non parametriche: deviazione assoluta mediana (MAD), minimi quadrati mediani (LMS) e Theil-Sen. Nota che pendenza e intercetta sono diverse per ciascuno stimatore. Se aggiungessimo un punto altamente influente, per esempio con coordinate x = 7 e y = 70, la retta OLS cambierebbe di più.
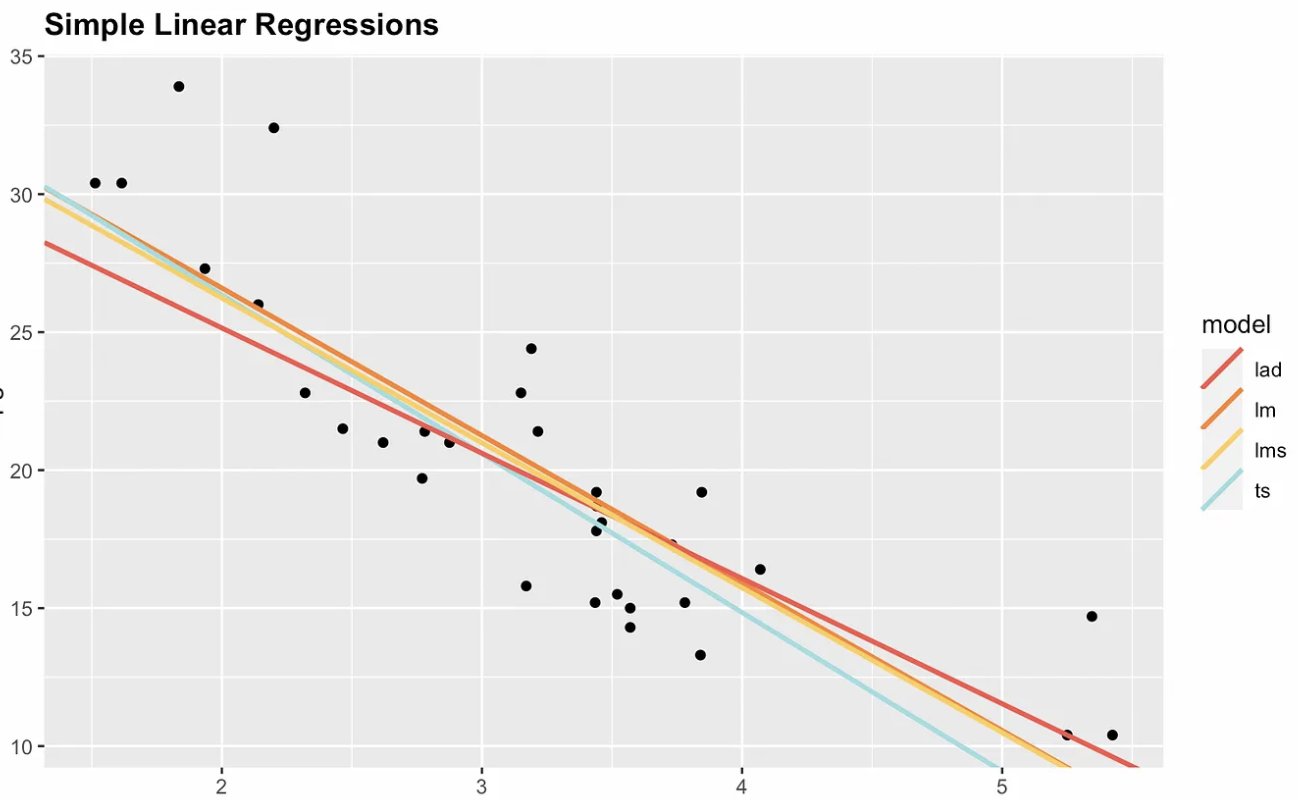 Quattro opzioni di regressione lineare semplice. Immagine dell’autore
Quattro opzioni di regressione lineare semplice. Immagine dell’autore
La regressione lineare semplice è il punto di partenza per comprendere relazioni più complesse nei dati. Per aiutarti, DataCamp offre tutorial con cui continuare a fare pratica, tra cui il nostro tutorial Essentials of Linear Regression in Python, il tutorial How to Do Linear Regression in R e il tutorial Linear Regression in Excel: A Comprehensive Guide For Beginners.
Queste risorse ti guideranno nell’uso di diversi strumenti per eseguire la regressione lineare e capirne le applicazioni. Infine, se sei pronto ad ampliare le tue competenze, dai un’occhiata al nostro Multiple Linear Regression in R: Tutorial With Examples, che copre modelli più complessi con predittori multipli. Puoi anche guardare il nostro video su YouTube Regression in Excel Made Easy per una guida pratica, adatta ai principianti e specifica per Excel.
Impara la regressione lineare semplice con DataCamp
Corso
Corso
Corso
blog
Tim Lu
12 min
blog
Abid Ali Awan
10 min
blog
Abid Ali Awan
15 min

