
Cours
Inférence pour la régression linéaire en R
4 h
15.9K
Chaque histoire a un point de départ, et pour l’analyste ou le data scientist, ce point de départ est souvent la régression linéaire simple. En effet, la régression linéaire simple est sans doute le modèle le plus fondamental. Si vous souhaitez sérieusement devenir analyste de données ou data scientist, la régression linéaire simple (et les régressions en général) est un incontournable.
Si la régression mérite d’être apprise, ce n’est pas seulement parce qu’elle est précieuse pour répondre à des questions essentielles dans pratiquement tous les domaines, mais aussi parce qu’elle ouvre la voie à une compréhension plus fine d’une multitude de sujets : tests d’hypothèses, inférence causale, prévision, etc. Suivez dès aujourd’hui notre cours Introduction to Regression in R et notre cours Introduction to Regression with statsmodels in Python.
La régression linéaire simple est une régression linéaire avec une variable indépendante, aussi appelée variable explicative, et une variable dépendante, aussi appelée variable réponse. Dans la régression linéaire simple, la variable dépendante est continue.
La façon la plus courante de réaliser une régression linéaire simple est l’estimation par les moindres carrés ordinaires (MCO, OLS en anglais). Comme OLS est de loin la méthode la plus utilisée, la mention « moindres carrés ordinaires » est souvent implicite quand on parle de régression linéaire simple.
Les moindres carrés ordinaires consistent à minimiser la somme des carrés des écarts entre les valeurs observées (les points de données réels) et les valeurs prédites par la droite de régression. Ces écarts sont appelés résidus, et les mettre au carré garantit que les résidus positifs et négatifs sont traités de la même manière.
La régression linéaire simple aide à faire des prédictions et à comprendre les relations entre une variable indépendante et une variable dépendante. Par exemple, vous pourriez vouloir savoir comment la hauteur d’un arbre (variable indépendante) influe sur son nombre de feuilles (variable dépendante). En collectant des données et en ajustant un modèle de régression linéaire simple, vous pourriez prédire le nombre de feuilles en fonction de la hauteur de l’arbre. C’est la partie « prédiction ». Mais cette approche révèle aussi de combien le nombre de feuilles varie, en moyenne, lorsque l’arbre grandit, ce qui illustre l’usage de la régression linéaire simple pour comprendre les relations.
Regardons l’équation de la régression linéaire simple. Commençons par la forme pente–ordonnée à l’origine d’une droite, telle qu’on la voit en géométrie ou en algèbre. Autrement dit, revenons au point de départ.
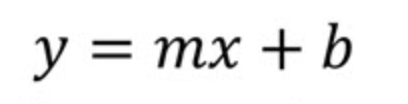
Ici
Dans le contexte de la data science, vous verrez plus souvent cette équation :
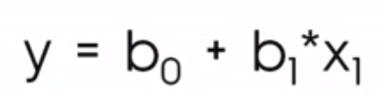
Où
La notation avec b0 et b1 indique que nous sommes dans une situation de prédiction de y, d’où l’écriture ŷ, ou y-chapeau, puisque nous ne nous attendons pas à ce que la droite de régression passe par tous les points.
La visualisation suivante montre la différence conceptuelle entre la forme pente–ordonnée à l’origine à gauche et l’équation de régression à droite. En algèbre linéaire, on dirait que le système d’équations linéaires est surdéterminé : il y a plus d’équations (une trentaine) que d’inconnues (deux), on ne s’attend donc pas à trouver une solution exacte.
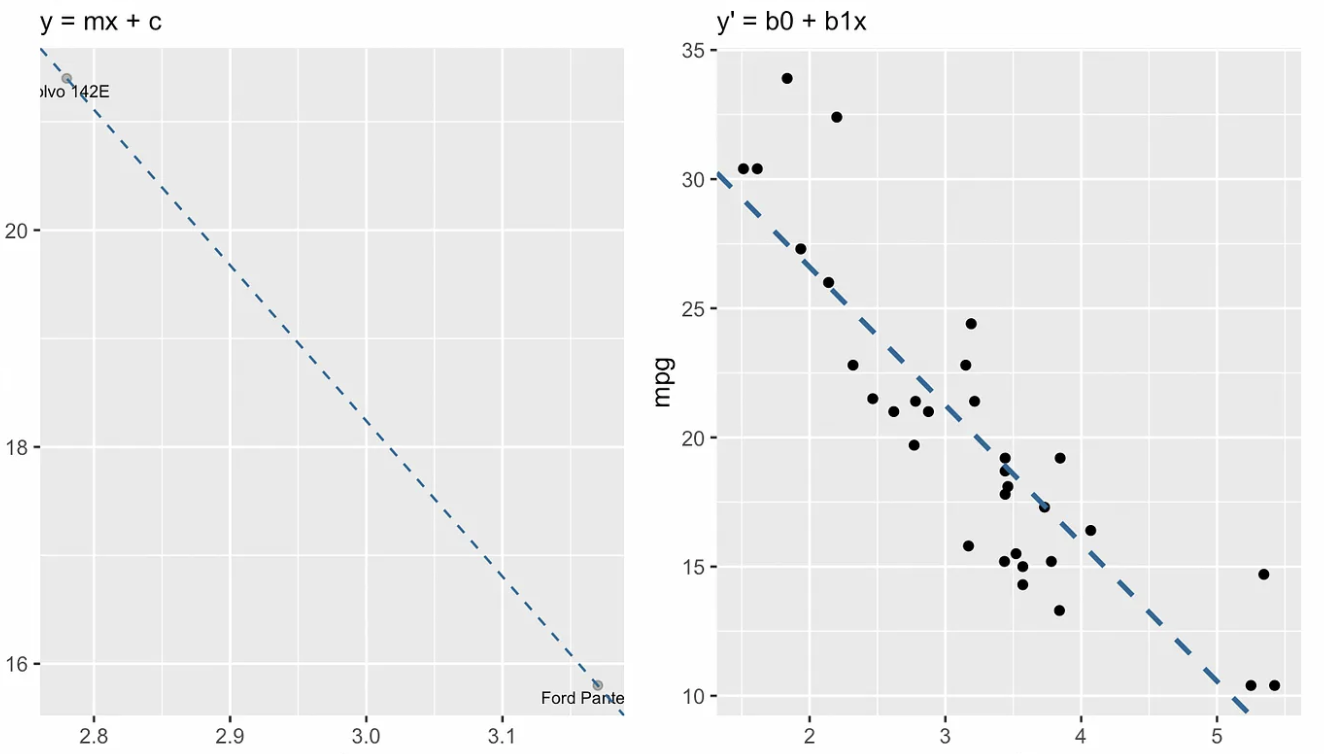 Forme pente–ordonnée à l’origine vs. équation de régression linéaire simple. Image de l’auteur
Forme pente–ordonnée à l’origine vs. équation de régression linéaire simple. Image de l’auteur
Si nous utilisions uniquement l’équation pente–ordonnée à l’origine, nous trouverions les valeurs de m (pente) et b (ordonnée à l’origine) en calculant d’abord la pente comme « élévation sur course » (rise over run), c’est-à-dire la variation de y sur la variation de x entre deux points de la droite. Ensuite, une fois la pente trouvée, nous obtiendrions l’ordonnée à l’origine b en substituant les coordonnées d’un point de la droite dans l’équation et en résolvant en b. Cette dernière étape donne le point où la droite coupe l’axe des ordonnées.
Cela ne fonctionne pas en régression, car aucune droite ne passe par tous les points ; c’est pour cela que nous cherchons plutôt la meilleure droite d’ajustement. Heureusement, il existe des formules fermées élégantes pour trouver la pente et l’ordonnée à l’origine.
On peut calculer la pente en multipliant la corrélation r par le quotient de l’écart-type de y sur l’écart-type de x. Cela a du sens intuitivement, car on reconvertit en quelque sorte le coefficient de corrélation dans l’unité des variables d’origine. Dans l’équation ci-dessous, a désigne la pente, et sy et sx renvoient respectivement aux écarts-types de y et de x.
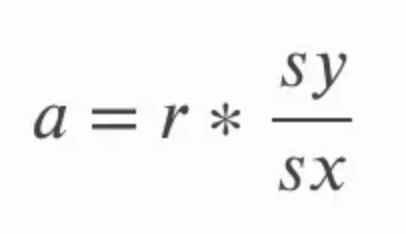
L’ordonnée à l’origine de la meilleure droite d’ajustement en régression linéaire simple se calcule une fois la pente connue. On soustrait le produit de la pente et de la moyenne de x à la moyenne de y. Dans l’équation ci-dessous, i désigne l’ordonnée à l’origine, et la barre au-dessus des valeurs x et y renvoie à leur moyenne ; on parle souvent de x-barre et y-barre.
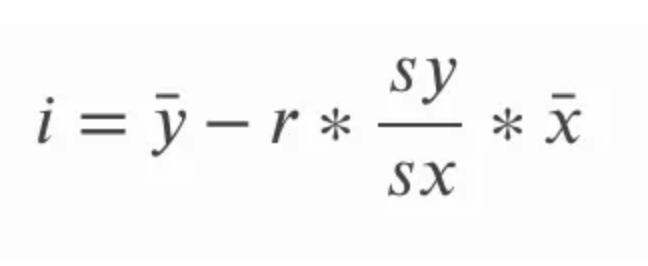
Pour être complet, examinons des écritures alternatives de ces équations. Rappelez-vous que l’écart-type est la racine carrée de la variance ; au lieu de parler de l’écart-type de y et de x, on pourrait parler de la racine carrée de la variance de y et de x. La variance, rappelons-le, est la moyenne de la somme des carrés.
Dans l’équation de la pente ci-dessus, a, on pourrait aussi écrire sy et sx en termes d’écarts-types, et développer la formule longue de la corrélation r. On pourrait alors effectuer des multiplications en croix, simplifier en supprimant des termes communs, et aboutir à l’ensemble d’équations suivant pour la pente et l’ordonnée à l’origine. L’objectif n’est pas tant de montrer comment on passe de l’une à l’autre, mais de souligner qu’elles sont équivalentes, car vous pouvez rencontrer l’une ou l’autre.
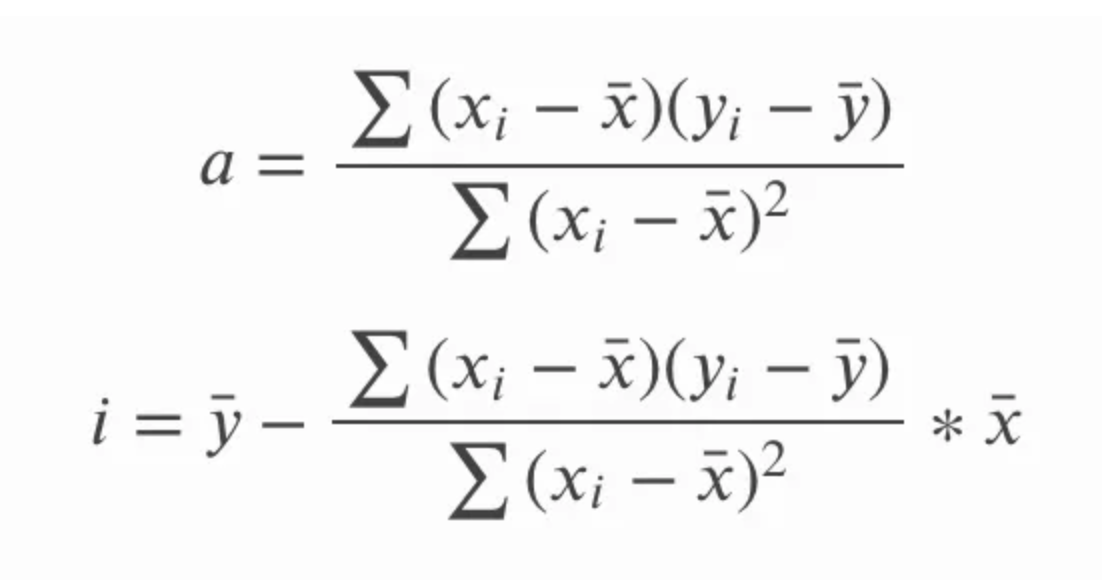
Autre conséquence intéressante : la droite de régression linéaire simple passe par le point central, c’est-à-dire la moyenne de x et la moyenne de y. Autrement dit, la régression linéaire simple coupe au niveau des moyennes de la variable indépendante et de la variable dépendante, quelle que soit la distribution des points, ce qui lui confère une sorte de propriété d’« équilibre ».
Nous avons vu comment obtenir les coefficients de la régression linéaire simple via des équations élégantes. Examinons maintenant d’autres méthodes impliquant l’algèbre linéaire et le calcul différentiel. Les environnements de programmation privilégient ces techniques plus avancées car elles sont plus rapides et plus précises (le fait d’élever au carré pour calculer la variance peut réduire la précision).
Passons en revue les principales hypothèses du modèle de régression linéaire simple. Si elles sont violées, il peut être pertinent d’envisager une autre approche. Les trois premières, en particulier, sont fortes et ne doivent pas être ignorées.
Supposons que nous ayons créé un modèle de régression linéaire simple. Comment savoir s’il s’ajuste bien ? Pour répondre, examinons des graphiques de diagnostic et des statistiques du modèle.
Les graphiques de diagnostic aident à vérifier l’adéquation du modèle et le respect des hypothèses. Tout motif ou écart suggère des problèmes d’ajustement ou une information non capturée. Un graphique de diagnostic propre à la régression linéaire simple est le nuage des valeurs de x contre les résidus, comme ci-dessous. D’autres graphiques utiles : Q-Q plot, échelle–localisation, numéro d’observation vs distance de Cook, etc.
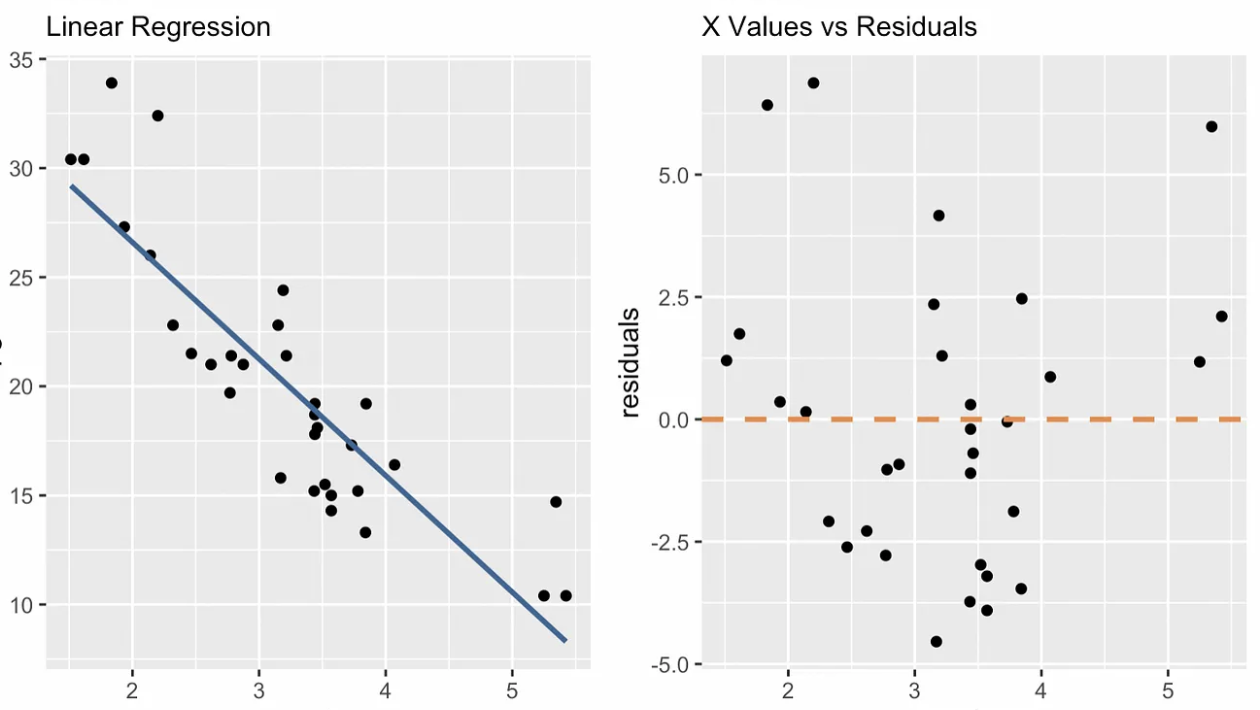 Valeurs de x vs résidus. Image de l’auteur
Valeurs de x vs résidus. Image de l’auteur
Des statistiques comme R-carré et R-carré ajusté quantifient la part de variance de la variable dépendante expliquée par la variable indépendante. La statistique F teste la significativité globale du modèle, et les p-valeurs des coefficients renseignent sur l’impact des prédicteurs pris individuellement.
Lors de l’interprétation des résultats d’une régression linéaire simple, il faut être précis dans la façon de décrire la relation entre la variable indépendante et la variable dépendante.
En particulier, soyez attentif à la formulation concernant les deux éléments clés : la pente et l’ordonnée à l’origine.
Un point essentiel : corrélation n’est pas causalité. Même des analystes au fait de ce principe peuvent trébucher sur les mots en interprétant une régression linéaire simple. On ne dira pas que la hauteur d’un arbre cause un plus grand nombre de feuilles, mais plutôt qu’une augmentation d’une unité de la hauteur est associée à une augmentation d’un certain nombre de feuilles.
Autre point d’attention : extrapoler au-delà de l’intervalle des données peut donner des prédictions peu fiables. Un modèle qui prédit le nombre de feuilles selon la hauteur peut être peu précis pour des arbres très petits ou très grands, surtout si ces cas n’ont pas été pris en compte lors de la construction du modèle.
On parle de « modèles linéaires » car ils sont linéaires dans leur forme fonctionnelle. Plus précisément, en régression linéaire simple, la relation entre la variable réponse y et la variable prédictive x est modélisée comme une combinaison linéaire du prédicteur et d’une constante. Cela dit, vous seriez surpris de ce que l’on peut faire avec une simple régression linéaire. Bien que le modèle suppose une relation en ligne droite, on peut introduire des transformations pour capturer des relations non linéaires.
Par exemple, considérez la croissance du nombre d’ancêtres par génération, qui semble exponentielle : deux parents, quatre grands-parents, huit arrière-grands-parents, etc. On ne s’attend pas à ce qu’un modèle linéaire capture une croissance exponentielle, mais en prédisant log(y) plutôt que y, on linéarise la relation.
En y réfléchissant, il n’y a toutefois pas de croissance exponentielle illimitée à cause du « pedigree collapse » : le taux de croissance ralentit fortement car des ancêtres éloignés apparaissent à plusieurs endroits de l’arbre généalogique. Ainsi, prendre log(y) peut surestimer notre modèle. Pour atténuer cet effet, on peut créer une nouvelle variable via une transformation racine carrée de x et l’utiliser comme prédicteur. Je ne dis pas que ce modèle est correct ni ne cherche à l’interpréter complètement ; je veux montrer que log(y) et la racine carrée de x sont des transformations non linéaires qui entrent linéairement dans l’équation par rapport aux coefficients ; on reste donc dans une régression linéaire simple.
Voyons la régression linéaire simple en R et en Python.
R est une excellente option pour la régression linéaire simple.
Nous pouvons calculer nous-mêmes les coefficients en utilisant la moyenne et l’écart-type de nos variables.
# Manually calculate the slope and intercept in R
# Sample data
X <- c(1, 2, 3, 4, 5)
y <- c(2, 4, 5, 4, 5)
# Calculate means
mean_X <- mean(X)
mean_y <- mean(y)
# Calculate standard deviations
sd_X <- sd(X)
sd_y <- sd(y)
# Calculate correlation
correlation <- cor(X, y)
# Calculate slope (b1) using the formula: b1 = (correlation * sd_y) / sd_X
slope <- (correlation * sd_y) / sd_X
# Calculate intercept (b0) using the formula: b0 = mean_y - slope * mean_X
intercept <- mean_y - slope * mean_X
# Print the slope and intercept
cat("Slope (b1):", slope, "\n")
cat("Intercept (b0):", intercept, "\n")
# Use the manually calculated coefficients to predict y values
y_pred <- intercept + slope * X
cat("Predicted values:", y_pred, "\n")En R, on peut créer une régression avec la fonction lm(), accessible sans bibliothèque additionnelle.
# Fit the model
model <- lm(y ~ X)
# Print the summary of the regression
summary(model)Python est une autre excellente option pour la régression linéaire simple.
Ici, nous calculons la moyenne et l’écart-type pour chaque variable.
import numpy as np
# Sample data
X = np.array([1, 2, 3, 4, 5])
y = np.array([2, 4, 5, 4, 5])
# Calculate means
mean_X = np.mean(X)
mean_y = np.mean(y)
# Calculate standard deviations
sd_X = np.std(X, ddof=1)
sd_y = np.std(y, ddof=1)
# Calculate correlation
correlation = np.corrcoef(X, y)[0, 1]
# Calculate slope (b1) using the formula: b1 = (correlation * sd_y) / sd_X
slope = (correlation * sd_y) / sd_X
# Calculate intercept (b0) using the formula: b0 = mean_y - slope * mean_X
intercept = mean_y - slope * mean_X
# Print the slope and intercept
print(f"Slope (b1): {slope}")
print(f"Intercept (b0): {intercept}")
# Use the manually calculated coefficients to predict y values
y_pred = intercept + slope * X
print(f"Predicted values: {y_pred}")statsmodels est une option pour réaliser une régression linéaire simple.
import statsmodels.api as sm
# Adding a constant for the intercept
X = sm.add_constant(X)
# Fit the model
model = sm.OLS(y, X)
results = model.fit()
# Print the summary of the regression
print(results.summary())La régression linéaire simple est utilisée dans les tests d’hypothèses et occupe une place centrale dans les tests t et l’analyse de la variance (ANOVA).
Un test t sert souvent à déterminer si la pente de la droite de régression est significativement différente de zéro. Ce test permet de savoir si la variable indépendante a un effet statistiquement significatif. Concrètement, on formule une hypothèse nulle indiquant que la pente est égale à zéro (pas de relation linéaire), et le test t l’évalue. La régression linéaire simple intervient ici car une régression simple avec une variable indépendante binaire équivaut à une différence de moyennes, comme dans un test t.
L’analyse de la variance (ANOVA) est une méthode statistique utilisée pour évaluer l’adéquation globale du modèle et déterminer si la variable indépendante explique une part significative de la variance de la variable dépendante. On partitionne la variance totale de la variable dépendante en deux composantes : la variance expliquée par le modèle (entre groupes) et la variance due aux résidus/erreurs (intra-groupes). Le test F de l’ANOVA évalue si le modèle de régression, pris dans son ensemble, s’ajuste mieux aux données qu’un modèle sans prédicteurs. Dans notre exemple de hauteur d’arbre et de nombre de feuilles, l’ANOVA indiquerait si intégrer la hauteur améliore significativement notre capacité à prédire le nombre de feuilles.
Nous avons indiqué que les moindres carrés ordinaires sont l’estimateur le plus courant en régression linéaire simple, et nous nous y sommes concentrés dans cet article. Toutefois, l’estimateur OLS est sensible aux valeurs aberrantes et manque de robustesse. Ajouter un point très influent ou à fort levier peut modifier fortement la pente et l’ordonnée de la droite.
Pour cette raison, il existe des options non paramétriques. La visualisation suivante montre OLS avec trois alternatives non paramétriques : l’écart absolu médian (MAD), les moindres carrés médians (LMS) et Theil–Sen. Observez que la pente et l’ordonnée diffèrent selon l’estimateur. Si l’on ajoutait un point très influent, par exemple x = 7 et y = 70, la droite de régression OLS changerait le plus.
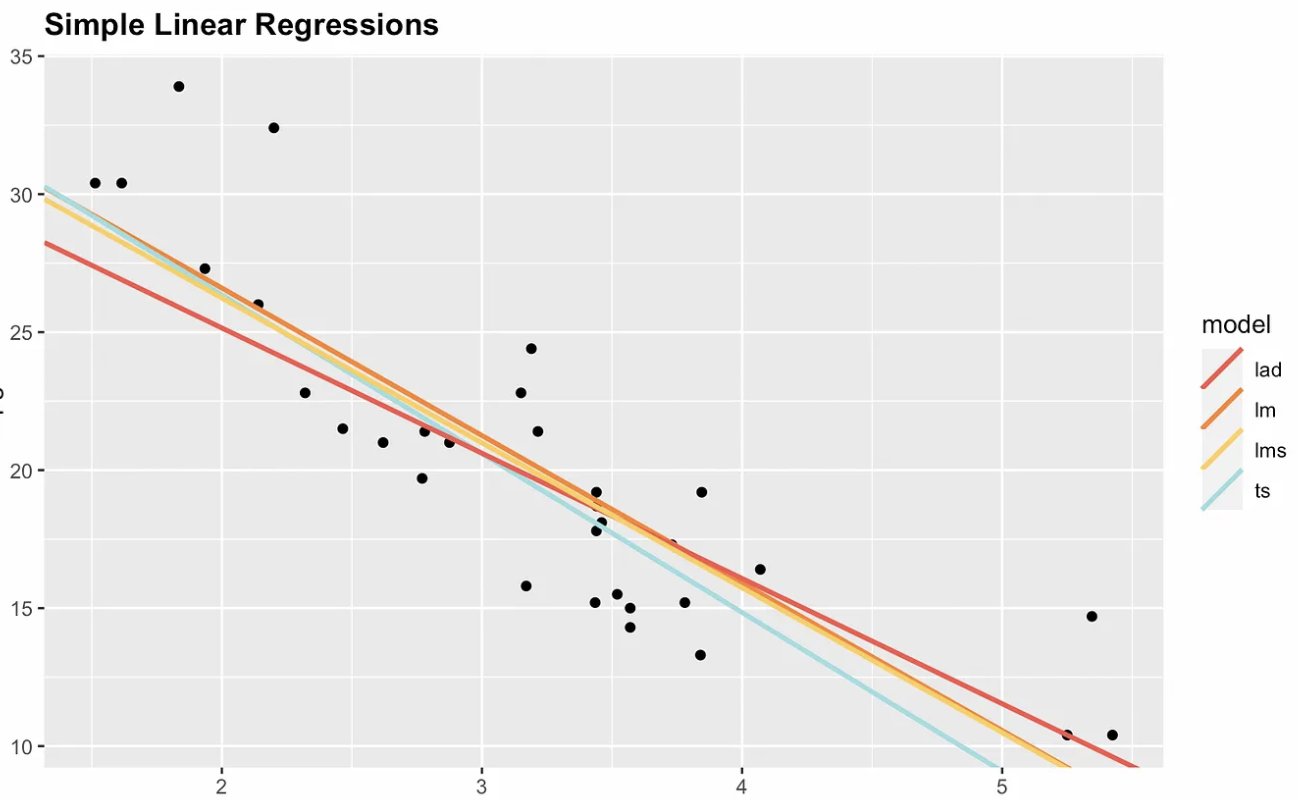 Quatre options de régression linéaire simple. Image de l’auteur
Quatre options de régression linéaire simple. Image de l’auteur
La régression linéaire simple est le point de départ pour comprendre des relations plus complexes dans les données. Pour vous accompagner, DataCamp propose des tutoriels pour continuer à pratiquer, notamment notre tutoriel Essentials of Linear Regression in Python, notre tutoriel How to Do Linear Regression in R, ainsi que Linear Regression in Excel: A Comprehensive Guide For Beginners.
Ces ressources vous guideront dans l’utilisation de différents outils pour réaliser une régression linéaire et en comprendre les applications. Enfin, si vous êtes prêt à développer vos compétences, consultez notre Multiple Linear Regression in R: Tutorial With Examples, qui couvre des modèles plus complexes avec plusieurs prédicteurs. Vous pouvez aussi regarder notre vidéo YouTube Regression in Excel Made Easy pour un parcours pas à pas, accessible aux débutants et dédié à Excel.
Apprenez la régression linéaire simple avec DataCamp
Cours
Cours
Cours
blog
Kurtis Pykes
15 min
Tutoriel
Samuel Shaibu
Tutoriel
Laiba Siddiqui
Tutoriel
Matt Crabtree
Tutoriel
Mark Pedigo
Tutoriel
Sejal Jaiswal

