
Curso
Inferencia para la regresión lineal en R
4 h
15.9K
Toda historia empieza en algún sitio, y para el analista de datos o el científico de datos, el inicio de la historia suele ser una simple regresión lineal. De hecho, la regresión lineal simple es quizá el modelo más fundacional de todos. Por tanto, si quieres convertirte en analista de datos o científico de datos, la regresión lineal simple (y las regresiones en general) son conocimientos imprescindibles.
La razón por la que merece la pena aprender regresión no es sólo porque es una técnica inestimable para responder a preguntas apremiantes en prácticamente todos los campos, sino que también abre la puerta a una comprensión más profunda de una enorme variedad de otras cosas, como la comprobación de hipótesis, la inferencia causal y la previsión. Así que sigue hoy mismo nuestro curso Introducción a la regresión en R y nuestro curso Introducción a la regresión con modelos estadísticos en Python.
La regresión lineal simple es una regresión lineal con una variable independiente, también llamada variable explicativa, y una variable dependiente, también llamada variable de respuesta. En la regresión lineal simple, la variable dependiente es continua.
La forma más habitual de hacer una regresión lineal simple es mediante la estimación por mínimos cuadrados ordinarios (MCO). Como los MCO son, con mucho, el método más común, la parte de "mínimos cuadrados ordinarios" suele estar implícita cuando hablamos de regresión lineal simple.
Los mínimos cuadrados ordinarios funcionan minimizando la suma de las diferencias al cuadrado entre los valores observados (los puntos de datos reales) y los valores predichos a partir de la recta de regresión. Estas diferencias se llaman residuos, y elevarlas al cuadrado garantiza que tanto los residuos positivos como los negativos reciban el mismo trato.
La regresión lineal simple ayuda a hacer predicciones y a comprender las relaciones entre una variable independiente y una variable dependiente. Por ejemplo, podrías querer saber cómo afecta la altura de un árbol (variable independiente) al número de hojas que tiene (variable dependiente). Recopilando datos y ajustando un sencillo modelo de regresión lineal, podrías predecir el número de hojas en función de la altura del árbol. Esta es la parte de "hacer predicciones". Pero este enfoque también revela cuánto cambia, por término medio, el número de hojas a medida que el árbol crece en altura, que es como también se utiliza la regresión lineal simple para comprender las relaciones.
Veamos la ecuación de regresión lineal simple. Podemos empezar examinando primero la forma pendiente-intersección de una recta utilizando la notación habitual en los libros de texto de geometría o álgebra. Es decir, empezaremos por el principio.
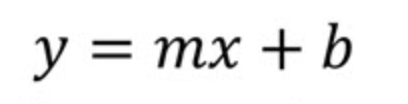
Aquí
En el contexto de la ciencia de datos, es más probable que veas esta ecuación en su lugar:
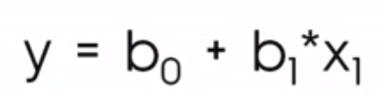
Dónde
La notación que implica b0 y b1 nos ayuda a comprender que estamos ante una situación en la que hacemos una predicción sobre ypor eso la llamamos ŷo y, ya que no esperamos que nuestra recta de regresión pase realmente por todos los puntos.
La siguiente visualización muestra la diferencia conceptual entre la forma pendiente-intersección de la recta, a la izquierda, y la ecuación de regresión, a la derecha. En el lenguaje del álgebra lineal, diríamos que el sistema de ecuaciones lineales está sobredeterminado, lo que significa que hay más ecuaciones (unas treinta) que incógnitas (dos), por lo que no esperamos encontrar una solución.
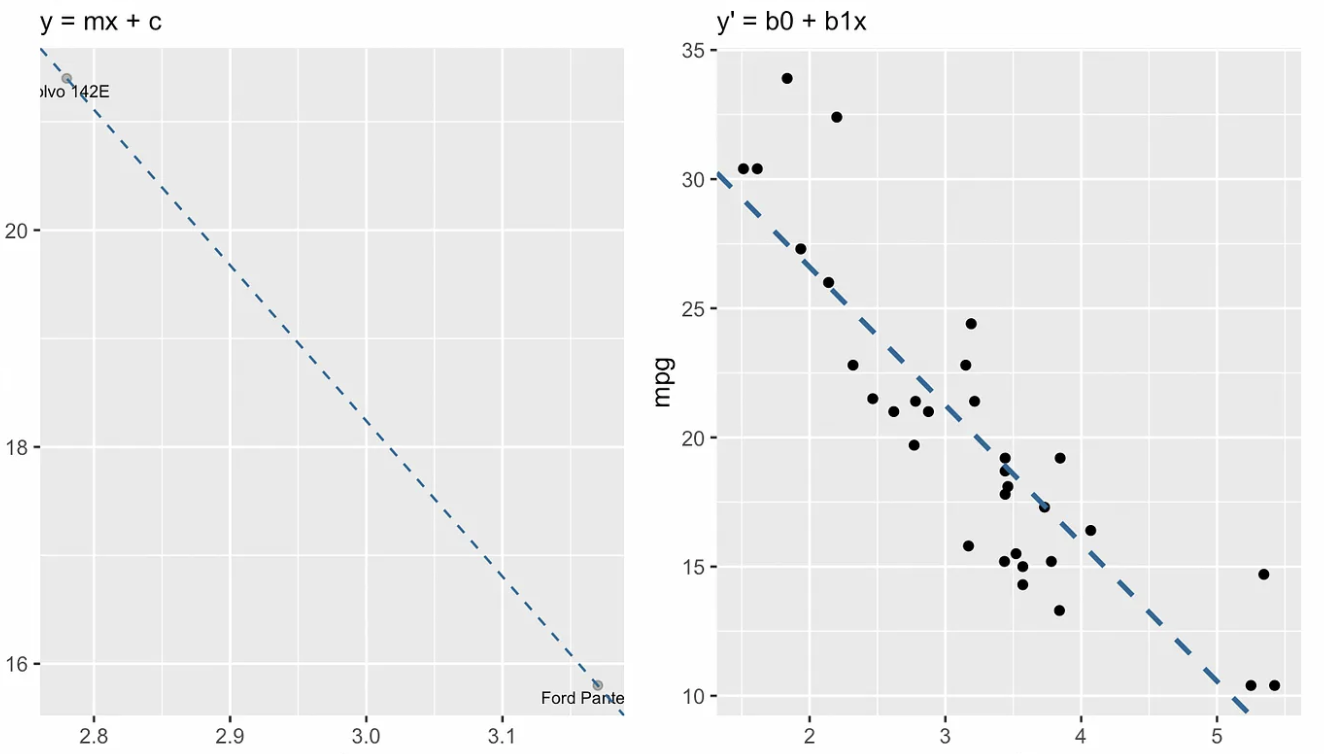 forma pendiente-intercepto vs. al Forma pendiente-intercepto vs. ecuación de regresión lineal simple. Imagen del autor
forma pendiente-intercepto vs. al Forma pendiente-intercepto vs. ecuación de regresión lineal simple. Imagen del autor
Si sólo utilizáramos la ecuación pendiente-intersección, hallaríamos los valores de m (pendiente) y b (intersección y) calculando primero la pendiente como "subida sobre recorrido", es decir, midiendo el cambio en y sobre el cambio en x entre dos puntos de la recta. Entonces, una vez hallada la pendiente, hallaríamos la intersección y b sustituyendo las coordenadas de un punto de la recta en la ecuación y resolviendo b. Este último paso te da el punto en el que la recta cruza el eje y.
Esto no funciona en la regresión porque no hay ninguna recta que pase por todos los puntos, por eso buscamos en su lugar la recta de mejor ajuste. Afortunadamente, existen ecuaciones claras y cerradas para hallar la pendiente y el intercepto.
La pendiente puede calcularse multiplicando la correlación r por el cociente de la desviación típica de y sobre la desviación típica de x. Esto tiene un sentido intuitivo, porque en esencia estamos volviendo a convertir el coeficiente de correlación en unidades de las variables originales. En la ecuación siguiente, a se refiere a la pendiente y sy y sx se refieren a la desviación típica de y y a la desviación típica de x, respectivamente.
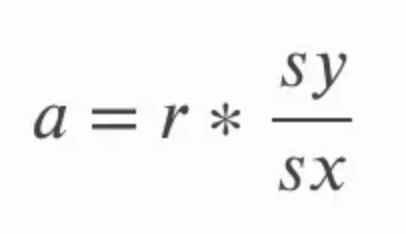
El intercepto de la recta de mejor ajuste de la regresión lineal simple puede calcularse después de calcular la pendiente. Para ello, restamos el producto de la pendiente y la media de x de la media de y. En la ecuación siguiente i se refiere a la intersección y y la línea recta sobre la intersección x y y es una forma de referirse a la media de x y y respectivamente; nos referimos a estos términos como barra x y barra y.
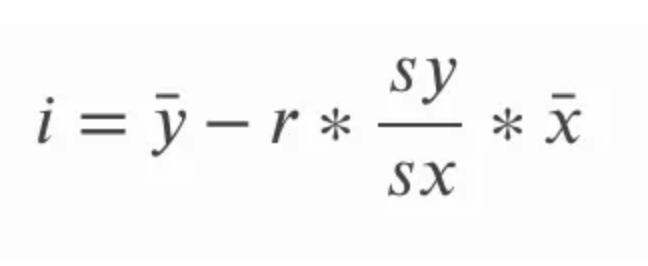
Para ser minuciosos, podemos explorar formas alternativas de escribir estas ecuaciones. Recuerda que la desviación típica es lo mismo que la raíz cuadrada de la varianza, así que en lugar de referirnos a la desviación típica de y y a la desviación típica de x, también podríamos referirnos a la raíz cuadrada de la varianza de y y a la raíz cuadrada de la varianza de x. La varianza propiamente dicha, recordemos, es la media de la suma de cuadrados.
En la ecuación anterior para la pendiente, a, también podríamos escribir sy y sx en términos de la desviación típica, y también podríamos escribir la ecuación de forma más larga para la correlación r. A continuación, podríamos multiplicar en cruz y simplificar la ecuación eliminando los términos comunes y acabar con el siguiente conjunto de ecuaciones para la pendiente y el intercepto. No se trata tanto de mostrar cómo una ecuación se convierte en la otra como de subrayar que ambas ecuaciones son la misma, ya que puedes ver una u otra.
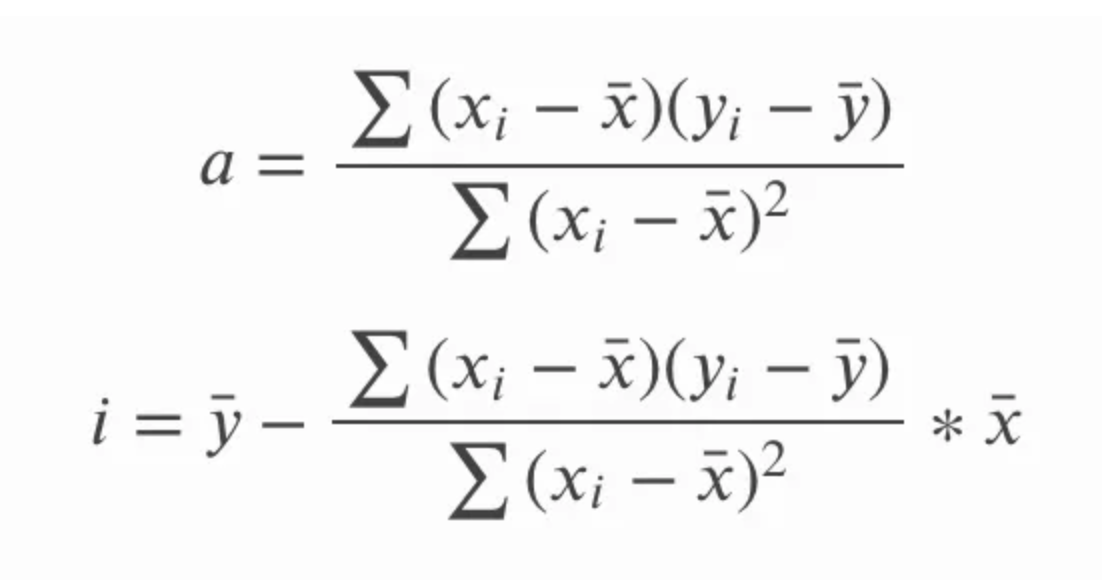
Otra consecuencia interesante es que la recta de regresión lineal simple pasará por el punto central, que es la media de x y la media de y. En otras palabras, la regresión lineal simple se cruza en la media de las variables independiente y dependiente, independientemente de la distribución de los puntos de datos, lo que contribuye a dar a la regresión lineal simple una especie de propiedad de "equilibrio".
Hemos visto cómo hallar los coeficientes del modelo de regresión lineal simple mediante ecuaciones ordenadas. Aquí veremos con más detalle otros métodos que implican álgebra lineal y cálculo. Los entornos de programación, en particular, resuelven mediante técnicas más avanzadas porque estas técnicas son más rápidas y precisas (lo de elevar al cuadrado para hallar la varianza puede reducir la precisión).
Veamos ahora los principales supuestos del modelo de regresión lineal simple. Si se incumplen estos supuestos, quizá debamos plantearnos un enfoque diferente. Los tres primeros, en particular, son fuertes suposiciones y no deben ignorarse.
Supongamos que hemos creado un modelo de regresión lineal simple. ¿Cómo sabemos si era una buena opción? Para responder a esto, podemos fijarnos en los gráficos de diagnóstico y en las estadísticas del modelo.
Los gráficos de diagnóstico nos ayudan a ver si un modelo de regresión lineal simple se ajusta bien y no viola nuestros supuestos. Cualquier patrón o desviación en estos gráficos sugiere problemas del modelo que requieren atención o información que no se captó. Un gráfico de diagnóstico exclusivo de la regresión lineal simple es el gráfico de valores x frente a residuos, como puedes ver a continuación. Otros gráficos son el gráfico Q-Q, el gráfico escala-localización, el número de observaciones frente a la distancia del cocinero y otros.
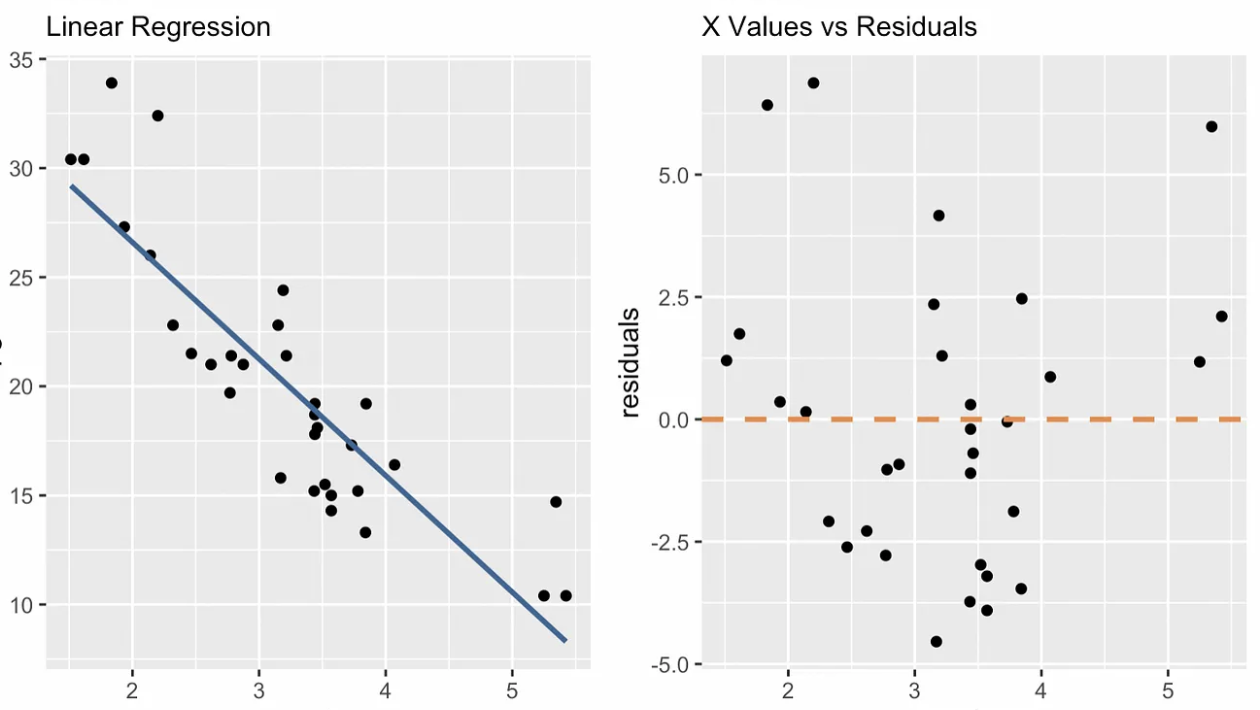 valores x vs. diagrama de diagnóstico de residuos. Imagen del autor
valores x vs. diagrama de diagnóstico de residuos. Imagen del autor
Los estadísticos del modelo, como R-cuadrado y R-cuadrado ajustado, cuantifican lo bien que la variable independiente explica la varianza de la variable dependiente. El estadístico F comprueba la significación global del modelo, y los valores p de los coeficientes nos informan sobre el impacto de los predictores individuales.
Al interpretar los resultados de la regresión lineal simple, debemos tener cuidado de ser exactos al hablar de la relación entre la variable independiente y la variable dependiente.
En particular, debemos tener cuidado al hablar de los dos componentes clave: la pendiente y el intercepto.
Una cosa importante que hay que tener en cuenta es que correlación no equivale a causalidad. Los analistas familiarizados con este concepto pueden meter la pata al interpretar una simple regresión lineal porque no tienen práctica con las palabras que deben utilizar. No dirías que la altura del árbol provoca más hojas, sino que podrías decir que un aumento de una unidad en la altura del árbol está asociado a un aumento de un determinado número de hojas.
Otra consideración importante es que extrapolar más allá del rango de los datos podría no dar lugar a predicciones fiables. Un simple modelo de regresión lineal que predijera el número de hojas a partir de la altura del árbol podría no ser muy preciso para árboles muy cortos o muy altos, sobre todo si no se tuvieron en cuenta los árboles cortos o altos en la creación de nuestro modelo.
Los modelos lineales se llaman modelos lineales porque son lineales en su forma funcional. En concreto, en la regresión lineal simple, la relación entre la variable de respuesta y y la variable predictora x se modela como una combinación lineal del predictor y una constante. Dicho esto, quizá te sorprenda lo que puedes hacer con una simple regresión lineal. Aunque el modelo supone una relación rectilínea entre las variables, puedes introducir transformaciones para captar las relaciones no lineales.
Por ejemplo, considera la relación no lineal que representa el crecimiento de los antepasados por generación, en la que el número de antepasados parece crecer exponencialmente con cada generación: dos padres, cuatro abuelos, ocho bisabuelos, etc. No esperarías que un modelo lineal captara el crecimiento exponencial, pero al predecir el log(y) en lugar de y, linealizas la relación .
Sin embargo, si piensas un poco más, te das cuenta de que no hay un crecimiento exponencial de los antepasados debido a algo llamado colapso del pedigrí, que es cuando la tasa de crecimiento se ralentiza drásticamente con el tiempo porque los antepasados lejanos aparecen en varios lugares del árbol genealógico. Por este motivo, tomar el log(y) puede haber sobreamplificado nuestro modelo. Ahora, para suavizar esto, podemos crear una nueva variable que sea una transformación de raíz cuadrada en x y utilizarla como nuestro predictor en su lugar. Ahora bien, no estoy diciendo que nada de este modelo sea correcto, ni intento interpretarlo completamente, sino que intento mostrar cómo log(y) y raíz cuadrada de x son transformaciones no lineales que entran en la ecuación linealmente con respecto a los coeficientes, por lo que seguimos teniendo una regresión lineal simple.
Consideremos la regresión lineal simple en R y Python.
R es una gran opción para la regresión lineal simple.
Podemos encontrar los coeficientes nosotros mismos calculando la media y la desviación típica de nuestras variables.
# Manually calculate the slope and intercept in R
# Sample data
X <- c(1, 2, 3, 4, 5)
y <- c(2, 4, 5, 4, 5)
# Calculate means
mean_X <- mean(X)
mean_y <- mean(y)
# Calculate standard deviations
sd_X <- sd(X)
sd_y <- sd(y)
# Calculate correlation
correlation <- cor(X, y)
# Calculate slope (b1) using the formula: b1 = (correlation * sd_y) / sd_X
slope <- (correlation * sd_y) / sd_X
# Calculate intercept (b0) using the formula: b0 = mean_y - slope * mean_X
intercept <- mean_y - slope * mean_X
# Print the slope and intercept
cat("Slope (b1):", slope, "\n")
cat("Intercept (b0):", intercept, "\n")
# Use the manually calculated coefficients to predict y values
y_pred <- intercept + slope * X
cat("Predicted values:", y_pred, "\n")En R, podemos crear una regresión utilizando la función lm(), a la que podemos acceder sin necesidad de utilizar ninguna biblioteca.
# Fit the model
model <- lm(y ~ X)
# Print the summary of the regression
summary(model)Python es otra gran opción para la regresión lineal simple.
Aquí hallamos la media y la desviación típica de cada variable.
import numpy as np
# Sample data
X = np.array([1, 2, 3, 4, 5])
y = np.array([2, 4, 5, 4, 5])
# Calculate means
mean_X = np.mean(X)
mean_y = np.mean(y)
# Calculate standard deviations
sd_X = np.std(X, ddof=1)
sd_y = np.std(y, ddof=1)
# Calculate correlation
correlation = np.corrcoef(X, y)[0, 1]
# Calculate slope (b1) using the formula: b1 = (correlation * sd_y) / sd_X
slope = (correlation * sd_y) / sd_X
# Calculate intercept (b0) using the formula: b0 = mean_y - slope * mean_X
intercept = mean_y - slope * mean_X
# Print the slope and intercept
print(f"Slope (b1): {slope}")
print(f"Intercept (b0): {intercept}")
# Use the manually calculated coefficients to predict y values
y_pred = intercept + slope * X
print(f"Predicted values: {y_pred}")statsmodels es una opción para la regresión lineal simple.
import statsmodels.api as sm
# Adding a constant for the intercept
X = sm.add_constant(X)
# Fit the model
model = sm.OLS(y, X)
results = model.fit()
# Print the summary of the regression
print(results.summary())La regresión lineal simple se utiliza en la comprobación de hipótesis y es fundamental en las pruebas t y en el análisis de la varianza (ANOVA).
A menudo se utiliza una prueba t para determinar si la pendiente de la recta de regresión es significativamente diferente de cero. Esta prueba nos ayuda a comprender si la variable independiente tiene un efecto estadísticamente significativo. Básicamente, formulamos una hipótesis nula según la cual la pendiente de la recta de regresión es igual a cero, lo que significa que no hay relación lineal, y la prueba t lo evalúa. La regresión lineal simple se relaciona aquí porque una regresión lineal simple con una variable independiente binaria es lo mismo que una diferencia de medias, como vemos en una prueba t.
El análisis de la varianza (ANOVA) es un método estadístico utilizado para evaluar el ajuste global del modelo y determinar si la variable independiente explica una parte significativa de la varianza de la variable dependiente. Lo que hacemos es dividir la varianza total de la variable dependiente en dos componentes: la varianza explicada por el modelo de regresión (entre grupos) y la varianza debida a los residuos o al error (dentro de los grupos). La prueba F del ANOVA básicamente comprueba si el modelo de regresión, en su conjunto, se ajusta mejor a los datos que un modelo sin predictores. Por ejemplo, en nuestro ejemplo de la altura del árbol y el recuento de hojas, el ANOVA ayudaría a determinar si la incorporación de la altura del árbol mejora significativamente nuestra capacidad de predecir el número de hojas.
Hemos dicho que los mínimos cuadrados ordinarios son, con diferencia, el estimador más habitual en la regresión lineal simple, y nos hemos centrado en los MCO en este artículo. Sin embargo, debemos tener en cuenta que el estimador de mínimos cuadrados ordinarios es sensible a los valores atípicos, o no es robusto frente a ellos. Así que añadir un punto de datos muy influyente o de gran influencia podría cambiar drásticamente la pendiente y el intercepto de la línea.
Por esta razón, existen opciones no paramétricas. La siguiente visualización muestra mínimos cuadrados ordinarios con tres alternativas no paramétricas: desviación absoluta mediana (MAD), mínimos cuadrados medianos (LMS) y Theil-Sen. Observa que la pendiente y el intercepto son diferentes para cada estimador. Si añadiéramos un punto muy influyente en, por ejemplo, las coordenadas x = 7 y y = 70, la línea de regresión por mínimos cuadrados ordinarios sería la que más cambiaría.
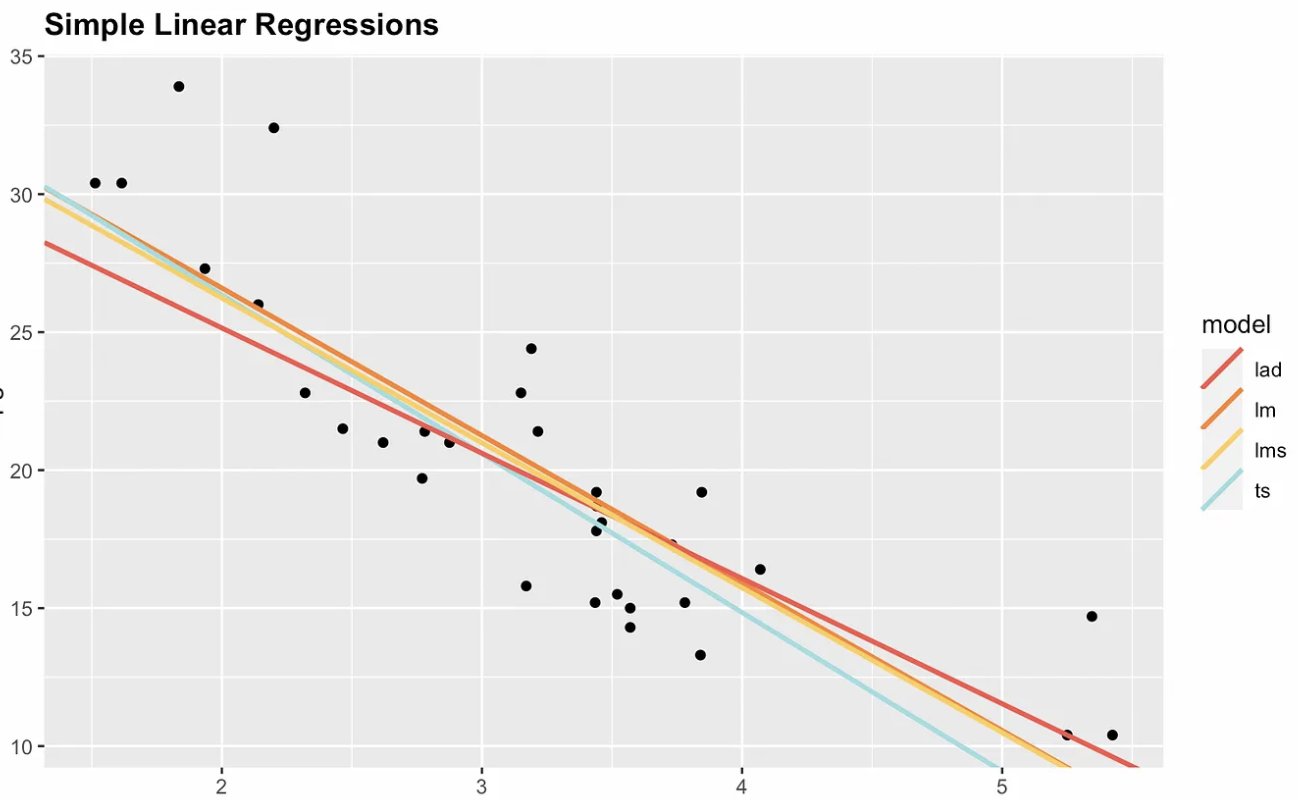 regresión lineal simpleCuatro opciones de regresión lineal simple. Imagen del autor
regresión lineal simpleCuatro opciones de regresión lineal simple. Imagen del autor
La regresión lineal simple es el punto de partida para comprender relaciones más complejas en los datos. Para ayudarte, DataCamp ofrece tutoriales para que puedas seguir practicando, como nuestro tutorial Fundamentos de la regresión lineal en Python, el tutorial Cómo hacer regresión lineal en R y el Regresión lineal en Excel: Guía completa para principiantes tutorial. Estos recursos te guiarán en el uso de diferentes herramientas para realizar la regresión lineal y comprender sus aplicaciones. Por último, si estás preparado para ampliar tus conocimientos, consulta nuestra página Regresión lineal múltiple en R: Tutorial con ejemplos, que cubre modelos más complejos con múltiples predictores.
Aprende Regresión Lineal Simple con DataCamp
Curso
Curso
Curso
Tutorial
Eladio Montero Porras
Tutorial
Kurtis Pykes
Tutorial
Zoumana Keita
Tutorial
Natassha Selvaraj
Tutorial
Vidhi Chugh
Tutorial
DataCamp Team
