Kursus
Extreme Gradient Boosting dengan XGBoost
4 Hr
61.1K
XGBoost adalah salah satu framework machine learning paling populer di kalangan data scientist. Menurut State of Data Science Survey 2021 dari Kaggle, hampir 50% responden mengatakan mereka menggunakan XGBoost, berada tepat di bawah TensorFlow dan Sklearn.
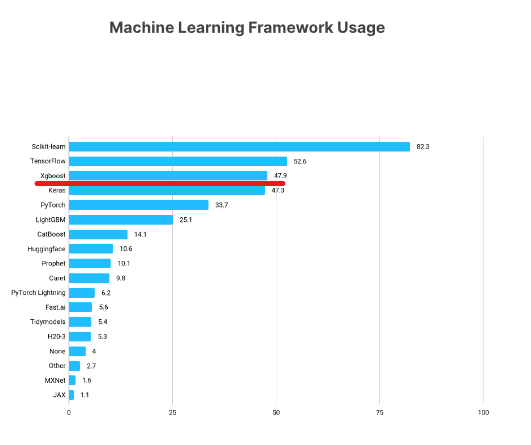
https://www.kaggle.com/kaggle-survey-2021
Tutorial XGBoost ini akan memperkenalkan aspek-aspek kunci dari framework Python populer ini, mengeksplorasi bagaimana Anda dapat menggunakannya untuk proyek machine learning Anda sendiri.
Tonton dan pelajari lebih lanjut tentang penggunaan XGBoost di Python dalam video dari kursus kami.
Sepanjang tutorial ini, kita akan membahas aspek-aspek kunci XGBoost, termasuk:
Mari mulai!
Jalankan dan edit kode dari tutorial ini secara online.
Jalankan kodeAnda dapat menginstal XGBoost seperti pustaka lainnya melalui pip. Metode instalasi ini juga akan menyertakan dukungan untuk GPU NVIDIA pada mesin Anda. Jika Anda ingin menginstal versi khusus CPU, Anda dapat menggunakan conda-forge:
$ pip install --user xgboost
# CPU only
$ conda install -c conda-forge py-xgboost-cpu
# Use NVIDIA GPU
$ conda install -c conda-forge py-xgboost-gpuDisarankan untuk menginstal XGBoost di lingkungan virtual agar tidak mencemari lingkungan dasar Anda.
Kami merekomendasikan menjalankan contoh-contoh dalam tutorial ini dengan mesin yang mendukung GPU. Jika Anda tidak memilikinya, Anda dapat melihat alternatif seperti DataLab atau Google Colab.
Jika Anda memilih Colab, ia memiliki versi XGBoost lama yang terpasang, jadi Anda harus menjalankan pip install --upgrade xgboost untuk mendapatkan versi terbaru.
Kita akan menggunakan dataset Diamonds sepanjang tutorial. Dataset ini sudah ada di pustaka Seaborn, atau sebagai alternatif, Anda juga dapat mengunduhnya dari Kaggle. Dataset ini memiliki kombinasi fitur numerik dan kategorikal yang baik serta lebih dari 50 ribu observasi sehingga kita dapat menampilkan semua keunggulan XGBoost dengan nyaman.
import seaborn as sns
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings("ignore")
diamonds = sns.load_dataset("diamonds")
diamonds.head()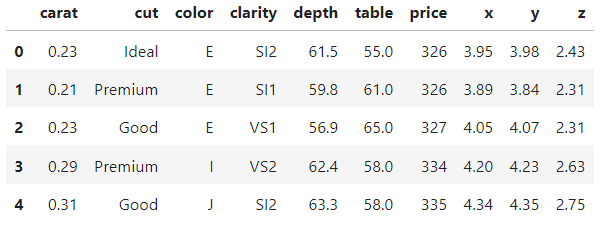
>>> diamonds.shape
(53940, 10)Dalam proyek dunia nyata, Anda biasanya akan menghabiskan lebih banyak waktu mengeksplorasi dataset dan memvisualisasikan fiturnya. Namun karena data ini sudah menjadi bagian dari Seaborn, datanya relatif bersih.
Jadi, kita hanya akan melihat ringkasan 5-angka dari fitur numerik dan kategorikal lalu lanjut. Luangkan sedikit waktu untuk membiasakan diri dengan dataset ini.
diamonds.describe()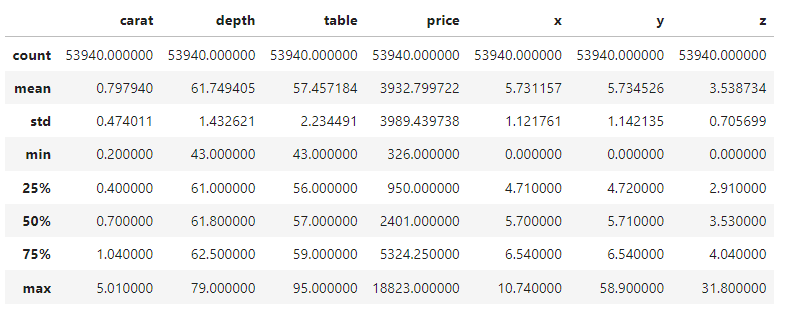
diamonds.describe(exclude=np.number)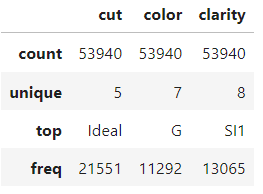
Setelah selesai eksplorasi, langkah pertama dalam proyek apa pun adalah membingkai masalah machine learning dan mengekstrak array fitur dan target berdasarkan dataset.
Dalam tutorial ini, kita terlebih dahulu akan mencoba memprediksi harga berlian menggunakan pengukuran fisiknya, jadi target kita adalah kolom price.
Jadi, kita memisahkan fitur ke X dan target ke y:
from sklearn.model_selection import train_test_split
# Extract feature and target arrays
X, y = diamonds.drop('price', axis=1), diamonds[['price']]Dataset memiliki tiga kolom kategorikal. Biasanya, Anda akan mengenkodenya dengan ordinal atau one-hot encoding, tetapi XGBoost dapat menangani fitur kategorikal secara internal.
Cara mengaktifkan fitur ini adalah dengan mengonversi kolom kategorikal menjadi tipe data category Pandas (secara default, kolom tersebut dianggap sebagai teks):
# Extract text features
cats = X.select_dtypes(exclude=np.number).columns.tolist()
# Convert to Pandas category
for col in cats:
X[col] = X[col].astype('category')Sekarang, ketika Anda mencetak atribut dtypes, Anda akan melihat bahwa kita memiliki tiga fitur category:
>>> X.dtypes
carat float64
cut category
color category
clarity category
depth float64
table float64
x float64
y float64
z float64
dtype: objectMari kita bagi data menjadi train dan test set (ukuran test 0,25):
# Split the data
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=1)Sekarang, bagian penting: XGBoost hadir dengan kelasnya sendiri untuk menyimpan dataset bernama DMatrix. Ini adalah kelas yang sangat dioptimalkan untuk memori dan kecepatan. Itulah mengapa mengonversi dataset ke format ini menjadi persyaratan untuk API native XGBoost:
import xgboost as xgb
# Create regression matrices
dtrain_reg = xgb.DMatrix(X_train, y_train, enable_categorical=True)
dtest_reg = xgb.DMatrix(X_test, y_test, enable_categorical=True)Kelas ini menerima fitur pelatihan dan label sekaligus. Untuk mengaktifkan pengkodean otomatis kolom kategori Pandas, kita juga menetapkan enable_categorical ke True.
Catatan:
Mengapa kita menggunakan API native XGBoost, bukan API Scikit-learn? Walau awalnya mungkin lebih nyaman menggunakan API Sklearn, nantinya Anda akan menyadari bahwa API native XGBoost memiliki sejumlah fitur hebat yang tidak didukung oleh yang pertama. Jadi, lebih baik membiasakannya sejak awal. Namun, ada bagian di akhir yang menunjukkan cara beralih antar API hanya dengan satu baris kode bahkan setelah Anda melatih model.
Setelah membangun DMatrix, Anda harus memilih nilai untuk parameter objective. Parameter ini memberi tahu XGBoost masalah machine learning yang Anda coba selesaikan dan metrik atau fungsi loss apa yang akan digunakan untuk menyelesaikan masalah tersebut.
Misalnya, untuk memprediksi harga berlian, yang merupakan masalah regresi, Anda dapat menggunakan objective umum reg:squarederror. Biasanya, nama objective juga memuat nama fungsi loss untuk masalah tersebut. Untuk regresi, umum digunakan Root Mean Squared Error, yang meminimalkan akar kuadrat dari jumlah kuadrat selisih antara nilai aktual dan prediksi. Berikut contoh implementasi metrik tersebut di NumPy:
import numpy as np
mse = np.mean((actual - predicted) ** 2)
rmse = np.sqrt(mse)Kita akan mempelajari objective untuk klasifikasi nanti di tutorial.
Sedikit catatan tentang perbedaan antara fungsi loss dan metrik kinerja: Fungsi loss digunakan oleh model machine learning untuk meminimalkan perbedaan antara nilai aktual (ground truth) dan prediksi model. Di sisi lain, metrik dipilih oleh engineer machine learning untuk mengukur kesamaan antara ground truth dan prediksi model.
Singkatnya, fungsi loss harus diminimalkan sementara metrik harus dimaksimalkan. Fungsi loss digunakan selama pelatihan untuk membimbing model di mana harus memperbaiki. Metrik digunakan selama evaluasi untuk mengukur kinerja keseluruhan.
Fungsi objective yang dipilih dan hyperparameter XGBoost lainnya harus ditentukan dalam sebuah dictionary, yang secara konvensi dinamai params:
# Define hyperparameters
params = {"objective": "reg:squarederror", "tree_method": "gpu_hist"}Di dalam params awal ini, kita juga menyetel tree_method ke gpu_hist, yang mengaktifkan akselerasi GPU. Jika Anda tidak memiliki GPU, Anda dapat menghilangkan parameter ini atau mengaturnya ke hist.
Sekarang, kita menetapkan parameter lain bernama num_boost_round, yang berarti jumlah putaran boosting. Secara internal, XGBoost meminimalkan fungsi loss RMSE dalam putaran kecil yang bertahap (lebih lanjut tentang ini nanti). Parameter ini menentukan jumlah putaran tersebut.
Jumlah putaran ideal ditemukan melalui hyperparameter tuning. Untuk saat ini, kita tetapkan saja ke 100:
# Define hyperparameters
params = {"objective": "reg:squarederror", "tree_method": "gpu_hist"}
n = 100
model = xgb.train(
params=params,
dtrain=dtrain_reg,
num_boost_round=n,
)Ketika XGBoost berjalan di GPU, kecepatannya sangat tinggi. Jika Anda tidak menerima error dari kode di atas, pelatihan berhasil!
Selama putaran boosting, objek model telah mempelajari semua pola dari training set sebisanya. Sekarang, kita harus mengukur kinerjanya dengan mengujinya pada data yang belum pernah dilihat. Di sinilah DMatrix dtest_reg kita berperan:
from sklearn.metrics import mean_squared_error
preds = model.predict(dtest_reg)Langkah ini disebut evaluasi model (atau inferensi). Setelah Anda menghasilkan prediksi dengan predict, Anda memasukkannya ke dalam fungsi mean_squared_error dari Sklearn untuk dibandingkan dengan y_test:
rmse = mean_squared_error(y_test, preds, squared=False)
print(f"RMSE of the base model: {rmse:.3f}")
RMSE of the base model: 543.203Kita mendapatkan skor dasar ~543$, yang merupakan kinerja model dasar dengan parameter default. Ada dua cara untuk meningkatkannya—dengan melakukan cross-validation dan hyperparameter tuning. Namun sebelum itu, mari lihat cara yang lebih cepat untuk mengevaluasi model XGBoost.
Melatih model machine learning seperti meluncurkan roket ke luar angkasa. Anda bisa mengendalikan semuanya tentang model hingga peluncuran, tetapi setelah itu, yang bisa Anda lakukan hanyalah menunggu hingga selesai.
Namun masalah dengan proses pelatihan kita saat ini adalah kita bahkan tidak bisa melihat ke mana model melaju. Untuk mengatasinya, kita akan menggunakan array evaluasi yang memungkinkan kita melihat kinerja model saat meningkat secara bertahap di seluruh putaran boosting.
Pertama, mari atur kembali parameternya:
params = {"objective": "reg:squarederror", "tree_method": "gpu_hist"}
n = 100Berikutnya, kita membuat daftar dua tuple yang masing-masing berisi dua elemen. Elemen pertama adalah array yang akan dievaluasi model, dan yang kedua adalah nama array tersebut.
evals = [(dtrain_reg, "train"), (dtest_reg, "validation")]Saat kita meneruskan array ini ke parameter evals dari xgb.train, kita akan melihat kinerja model setelah setiap putaran boosting:
evals = [(dtrain_reg, "train"), (dtest_reg, "validation")]
model = xgb.train(
params=params,
dtrain=dtrain_reg,
num_boost_round=n,
evals=evals,
)Anda akan mendapat output serupa dengan di bawah (dipersingkat menjadi 10 baris). Anda dapat melihat bagaimana model meminimalkan skor dari ~3931$ menjadi hanya 543$.
Yang terbaik adalah kita dapat melihat kinerja model pada training dan validation set. Biasanya, loss pada training akan lebih rendah daripada validation karena model sudah melihat yang pertama.
[0] train-rmse:3985.18329 validation-rmse:3930.52457
[1] train-rmse:2849.72257 validation-rmse:2813.20828
[2] train-rmse:2059.86648 validation-rmse:2036.66330
[3] train-rmse:1519.32314 validation-rmse:1510.02762
[4] train-rmse:1153.68171 validation-rmse:1153.91223
...
[95] train-rmse:381.93902 validation-rmse:543.56526
[96] train-rmse:380.97024 validation-rmse:543.51413
[97] train-rmse:380.75330 validation-rmse:543.36855
[98] train-rmse:379.65918 validation-rmse:543.42558
[99] train-rmse:378.30590 validation-rmse:543.20278Dalam proyek dunia nyata, Anda biasanya melatih hingga ribuan putaran boosting, yang berarti sangat banyak baris output. Untuk menguranginya, Anda dapat menggunakan parameter verbose_eval, yang memaksa XGBoost mencetak pembaruan kinerja setiap vebose_eval putaran:
params = {"objective": "reg:squarederror", "tree_method": "gpu_hist"}
n = 100
evals = [(dtest_reg, "validation"), (dtrain_reg, "train")]
model = xgb.train(
params=params,
dtrain=dtrain_reg,
num_boost_round=n,
evals=evals,
verbose_eval=10 # Every ten rounds
)
[OUT]:
[0] train-rmse:3985.18329 validation-rmse:3930.52457
[10] train-rmse:550.08330 validation-rmse:590.15023
[20] train-rmse:488.51248 validation-rmse:551.73431
[30] train-rmse:463.13288 validation-rmse:547.87843
[40] train-rmse:447.69788 validation-rmse:546.57096
[50] train-rmse:432.91655 validation-rmse:546.22557
[60] train-rmse:421.24046 validation-rmse:546.28601
[70] train-rmse:408.64125 validation-rmse:546.78238
[80] train-rmse:396.41125 validation-rmse:544.69846
[90] train-rmse:386.87996 validation-rmse:543.82192
[99] train-rmse:378.30590 validation-rmse:543.20278Sampai sekarang, Anda pasti menyadari betapa pentingnya putaran boosting. Secara umum, semakin banyak putaran, semakin XGBoost berusaha meminimalkan loss. Namun, ini tidak berarti loss akan selalu turun. Mari coba dengan 5000 putaran boosting dengan verbosity 500:
params = {"objective": "reg:squarederror", "tree_method": "gpu_hist"}
n = 5000
evals = [(dtest_reg, "validation"), (dtrain_reg, "train")]
model = xgb.train(
params=params,
dtrain=dtrain_reg,
num_boost_round=n,
evals=evals,
verbose_eval=250
)
[OUT]:
[0] train-rmse:3985.18329 validation-rmse:3930.52457
[500] train-rmse:195.89184 validation-rmse:555.90367
[1000] train-rmse:122.10746 validation-rmse:563.44888
[1500] train-rmse:84.18238 validation-rmse:567.16974
[2000] train-rmse:61.66682 validation-rmse:569.52584
[2500] train-rmse:46.34923 validation-rmse:571.07632
[3000] train-rmse:37.04591 validation-rmse:571.76912
[3500] train-rmse:29.43356 validation-rmse:572.43196
[4000] train-rmse:24.00607 validation-rmse:572.81287
[4500] train-rmse:20.45021 validation-rmse:572.89062
[4999] train-rmse:17.44305 validation-rmse:573.13200
Kita mendapatkan loss terendah sebelum putaran ke-500. Setelah itu, meskipun training loss terus turun, validation loss (yang kita pedulikan) terus meningkat.
Ketika diberi jumlah putaran boosting yang tidak perlu, XGBoost mulai overfit dan menghafal dataset. Hal ini pada gilirannya menyebabkan penurunan kinerja validasi karena model menghafal alih-alih melakukan generalisasi.
Ingat, kita menginginkan titik tengah emas: model yang mempelajari pola yang cukup saat pelatihan sehingga memberikan kinerja tertinggi pada validation set. Jadi, bagaimana kita menemukan jumlah putaran boosting yang tepat?
Kita akan menggunakan teknik yang disebut early stopping. Early stopping memaksa XGBoost untuk memantau validation loss, dan jika tidak membaik selama jumlah putaran tertentu, pelatihan otomatis dihentikan.
Ini berarti kita dapat menetapkan jumlah putaran boosting yang tinggi selama kita menetapkan jumlah putaran early stopping yang masuk akal.
Misalnya, mari gunakan 10000 putaran boosting dan set parameter early_stopping_rounds ke 50. Dengan cara ini, XGBoost akan otomatis menghentikan pelatihan jika validation loss tidak membaik selama 50 putaran berturut-turut.
n = 10000
model = xgb.train(
params=params,
dtrain=dtrain_reg,
num_boost_round=n,
evals=evals,
verbose_eval=50,
# Activate early stopping
early_stopping_rounds=50
)
[OUT]:
[0] train-rmse:3985.18329 validation-rmse:3930.52457
[50] train-rmse:432.91655 validation-rmse:546.22557
[100] train-rmse:377.66173 validation-rmse:542.92457
[150] train-rmse:334.27548 validation-rmse:542.79733
[167] train-rmse:321.04059 validation-rmse:543.35679Seperti yang Anda lihat, pelatihan berhenti setelah putaran ke-167 karena loss berhenti membaik selama 50 putaran sebelumnya.
Di awal tutorial, kita menyisihkan 25% dataset untuk pengujian. Test set memungkinkan kita meniru kondisi model di produksi, di mana ia harus menghasilkan prediksi untuk data yang belum pernah dilihat.
Namun, hanya satu test set tidak cukup untuk mengukur secara akurat bagaimana model akan tampil di produksi. Misalnya, jika kita melakukan hyperparameter tuning hanya dengan satu training set dan satu test set, pengetahuan tentang test set masih akan “bocor”. Bagaimana?
Karena kita mencoba menemukan nilai terbaik dari hyperparameter dengan membandingkan kinerja validasi model pada test set, kita akan berakhir dengan model yang dikonfigurasi untuk tampil baik hanya pada test set tersebut. Sebaliknya, kita menginginkan model yang tampil baik secara umum—pada test set mana pun yang kita berikan.
Salah satu solusi adalah membagi data menjadi tiga set. Model dilatih pada set pertama, set kedua digunakan untuk evaluasi dan hyperparameter tuning, dan set ketiga adalah yang terakhir kita uji sebelum produksi.
Namun ketika data terbatas, membagi data menjadi tiga set akan membuat training set menjadi tipis, yang merugikan kinerja model.
Solusi untuk semua masalah ini adalah cross-validation. Dalam cross-validation, kita tetap memiliki dua set: training dan testing.
Sementara test set menunggu di pojok, kita membagi training menjadi 3, 5, 7, atau k split atau fold. Lalu, kita melatih model sebanyak k kali. Setiap kali, kita menggunakan k-1 bagian untuk pelatihan dan bagian ke-k untuk validasi. Proses ini disebut k-fold cross-validation:
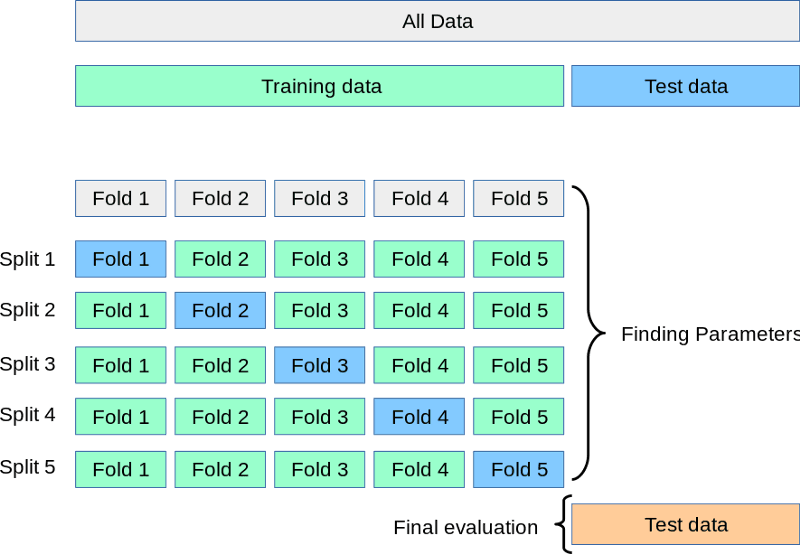
Sumber: https://scikit-learn.org/stable/modules/cross_validation.html
Di atas adalah gambaran visual 5-fold cross-validation. Setelah semua fold selesai, kita dapat mengambil rata-rata skor sebagai kinerja akhir model yang paling realistis.
Mari lakukan proses ini dalam kode menggunakan fungsi cv dari XGB:
params = {"objective": "reg:squarederror", "tree_method": "gpu_hist"}
n = 1000
results = xgb.cv(
params, dtrain_reg,
num_boost_round=n,
nfold=5,
early_stopping_rounds=20
)Satu-satunya perbedaan dengan fungsi train adalah menambahkan parameter nfold untuk menentukan jumlah split. Objek results sekarang adalah DataFrame yang berisi hasil setiap fold:
results.head()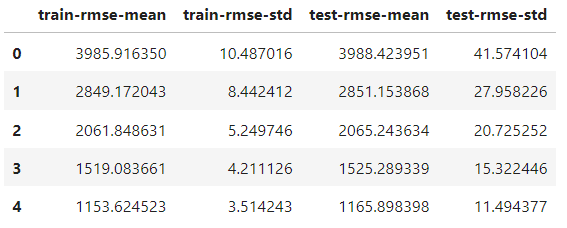
Jumlah barisnya sama dengan jumlah putaran boosting. Setiap baris adalah rata-rata dari semua split untuk putaran tersebut. Jadi, untuk menemukan skor terbaik, kita ambil nilai minimum dari kolom test-rmse-mean:
best_rmse = results['test-rmse-mean'].min()
best_rmse
550.8959336674216Perlu dicatat bahwa metode cross-validation ini digunakan untuk melihat kinerja sejati model. Setelah puas dengan skornya, Anda harus melatih ulang pada data penuh sebelum deployment.
Membangun XGBoost classifier semudah mengubah fungsi objective; sisanya bisa tetap sama.
Dua objective klasifikasi paling populer adalah:
binary:logistic - klasifikasi biner (target hanya berisi dua kelas, misalnya kucing atau anjing)multi:softprob - klasifikasi multi-kelas (lebih dari dua kelas pada target, misalnya apel/jeruk/pisang)Melakukan klasifikasi biner dan multi-kelas di XGBoost hampir identik, jadi kita akan memilih yang terakhir. Mari siapkan data untuk tugas ini terlebih dahulu.
Kita ingin memprediksi kualitas potongan (cut) berlian berdasarkan harganya dan pengukuran fisiknya. Jadi, kita akan membangun array fitur/target sesuai itu:
from sklearn.preprocessing import OrdinalEncoder
X, y = diamonds.drop("cut", axis=1), diamonds[['cut']]
# Encode y to numeric
y_encoded = OrdinalEncoder().fit_transform(y)
# Extract text features
cats = X.select_dtypes(exclude=np.number).columns.tolist()
# Convert to pd.Categorical
for col in cats:
X[col] = X[col].astype('category')
# Split the data
X_train, X_test, y_train, y_test = train_test_split(X, y_encoded, random_state=1, stratify=y_encoded)Satu-satunya perbedaan adalah karena XGBoost hanya menerima angka pada target, kita mengenkode kelas teks pada target dengan OrdinalEncoder dari Sklearn.
Sekarang, kita bangun DMatrix…
# Create classification matrices
dtrain_clf = xgb.DMatrix(X_train, y_train, enable_categorical=True)
dtest_clf = xgb.DMatrix(X_test, y_test, enable_categorical=True)…dan set objective menjadi multi:softprob. Objective ini juga memerlukan jumlah kelas untuk ditentukan oleh kita:
params = {"objective": "multi:softprob", "tree_method": "gpu_hist", "num_class": 5}
n = 1000
results = xgb.cv(
params, dtrain_clf,
num_boost_round=n,
nfold=5,
metrics=["mlogloss", "auc", "merror"],
)Selama cross-validation, kita meminta XGBoost memantau tiga metrik klasifikasi yang melaporkan kinerja model dari tiga sudut berbeda. Berikut hasilnya:
results.keys()
Index(['train-mlogloss-mean', 'train-mlogloss-std', 'train-auc-mean',
'train-auc-std', 'train-merror-mean', 'train-merror-std',
'test-mlogloss-mean', 'test-mlogloss-std', 'test-auc-mean',
'test-auc-std', 'test-merror-mean', 'test-merror-std'],
dtype='object')Untuk melihat skor AUC terbaik, kita ambil nilai maksimum dari kolom test-auc-mean:
>>> results['test-auc-mean'].max()
0.9402233623451636Bahkan konfigurasi default memberi kita kinerja 94%, yang sangat bagus.
Sejauh ini, kita menggunakan API native XGBoost, tetapi API Sklearn juga cukup populer.
Sklearn adalah framework luas dengan banyak algoritme dan utilitas machine learning serta memiliki sintaks API yang disukai hampir semua orang. Oleh karena itu, XGBoost juga menawarkan kelas XGBClassifier dan XGBRegressor agar dapat diintegrasikan ke dalam ekosistem Sklearn (dengan kehilangan sebagian fungsionalitas).
Jika Anda ingin hanya menggunakan API Scikit-learn bila memungkinkan dan hanya beralih ke native saat membutuhkan fungsionalitas ekstra, ada caranya.
Setelah melatih XGBoost classifier atau regressor, Anda dapat mengonversinya menggunakan metode get_booster:
import xgboost as xgb
# Train a model using the scikit-learn API
xgb_classifier = xgb.XGBClassifier(n_estimators=100, objective='binary:logistic', tree_method='hist', eta=0.1, max_depth=3, enable_categorical=True)
xgb_classifier.fit(X_train, y_train)
# Convert the model to a native API model
model = xgb_classifier.get_booster()Objek model akan berperilaku persis seperti yang telah kita lihat sepanjang tutorial ini.
Kita telah membahas banyak topik penting dalam tutorial XGBoost ini, tetapi masih banyak hal yang bisa dipelajari.
Anda dapat melihat halaman parameter XGBoost, yang mengajarkan cara mengonfigurasi parameter untuk memeras setiap tetes kinerja dari model Anda.
Jika Anda mencari sumber yang komprehensif dan all-in-one untuk mempelajari pustaka ini, lihat kursus Extreme Gradient Boosting With XGBoost kami.
Pelajari lebih lanjut tentang Python dan XGBoost
Kursus
Kursus
Kursus
blogs
David Woods
13 mnt
blogs
Hugo Bowne-Anderson
13 mnt
blogs
Javier Canales Luna
14 mnt
blogs
Dario Radečić
15 mnt
