Kurs
Extreme Gradient Boosting mit XGBoost
4 Std.
60.7K
XGBoost ist eines der beliebtesten Frameworks für maschinelles Lernen unter Datenwissenschaftlern. Laut der Kaggle State of Data Science Survey 2021 gaben fast 50 % der Befragten an, dass sie XGBoost verwenden, womit es nur noch hinter TensorFlow und Sklearn liegt.
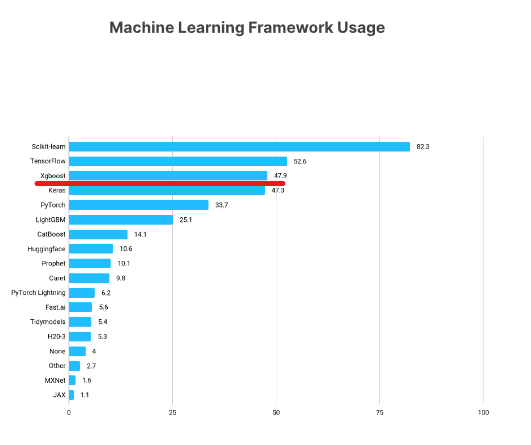
https://www.kaggle.com/kaggle-survey-2021
Dieses XGBoost-Tutorial stellt die wichtigsten Aspekte dieses beliebten Python-Frameworks vor und zeigt dir, wie du es für deine eigenen Machine-Learning-Projekte nutzen kannst.
In diesem Video aus unserem Kurs erfährst du mehr über die Verwendung von XGBoost in Python.
In diesem Lernprogramm werden wir die wichtigsten Aspekte von XGBoost behandeln, darunter:
Lass uns loslegen!
Code aus diesem Tutorial online ausführen und bearbeiten
Code ausführenDu kannst XGBoost wie jede andere Bibliothek über pip installieren. Bei dieser Installationsmethode wird auch die NVIDIA-GPU deines Computers unterstützt. Wenn du die reine CPU-Version installieren willst, kannst du conda-forge verwenden:
$ pip install --user xgboost
# CPU only
$ conda install -c conda-forge py-xgboost-cpu
# Use NVIDIA GPU
$ conda install -c conda-forge py-xgboost-gpuEs wird empfohlen, XGBoost in einer virtuellen Umgebung zu installieren, um deine Basisumgebung nicht zu belasten.
Wir empfehlen, die Beispiele im Tutorial mit einem GPU-fähigen Rechner durchzugehen. Wenn du keins hast, kannst du dir Alternativen wie DataLab oder Google Colab ansehen.
Wenn du dich für Colab entscheidest, ist dort die alte Version von XGBoost installiert. Du solltest also pip install --upgrade xgboost anrufen, um die neueste Version zu erhalten.
Wir werden während des gesamten Tutorials mit dem Diamonds-Datensatz arbeiten. Sie ist in die Seaborn-Bibliothek integriert. Alternativ kannst du sie auch bei Kaggle herunterladen. Mit einer schönen Kombination aus numerischen und kategorialen Merkmalen und über 50k Beobachtungen können wir alle Vorteile von XGBoost bequem präsentieren.
import seaborn as sns
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings("ignore")
diamonds = sns.load_dataset("diamonds")
diamonds.head()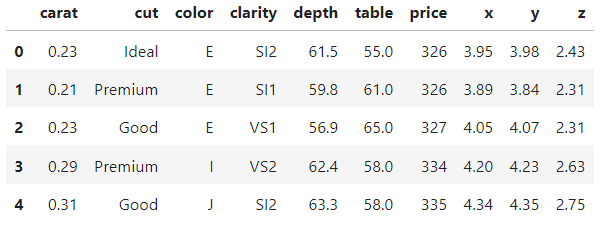
>>> diamonds.shape
(53940, 10)In einem typischen Projekt würdest du viel mehr Zeit damit verbringen wollen, den Datensatz zu erforschen und seine Merkmale zu visualisieren. Aber da diese Daten in Seaborn integriert sind, sind sie relativ sauber.
Wir schauen uns also nur die 5-stellige Zusammenfassung der numerischen und kategorialen Merkmale an und legen los. Du kannst dir ein paar Minuten Zeit nehmen, um dich mit dem Datensatz vertraut zu machen.
diamonds.describe()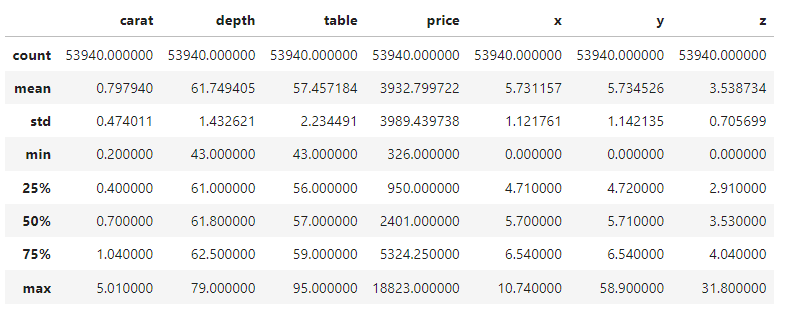
diamonds.describe(exclude=np.number)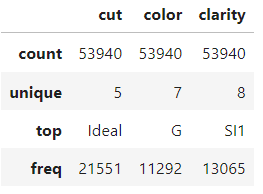
Nachdem du mit der Erkundung fertig bist, besteht der erste Schritt in jedem Projekt darin, das Problem des maschinellen Lernens zu formulieren und die Merkmale und Zielfelder auf der Grundlage des Datensatzes zu extrahieren.
In diesem Lernprogramm werden wir zunächst versuchen, die Preise von Diamanten anhand ihrer physikalischen Maße vorherzusagen, unser Ziel ist also die Preisspalte.
Wir isolieren also die Merkmale in X und das Ziel in y:
from sklearn.model_selection import train_test_split
# Extract feature and target arrays
X, y = diamonds.drop('price', axis=1), diamonds[['price']]Der Datensatz hat drei kategoriale Spalten. Normalerweise würdest du sie mit Ordinal- oder One-Hot-Codierung kodieren, aber XGBoost kann intern auch mit kategorialen Werten umgehen.
Um diese Funktion zu aktivieren, musst du die kategorischen Spalten in den Pandas category Datentyp umwandeln (standardmäßig werden sie als Textspalten behandelt):
# Extract text features
cats = X.select_dtypes(exclude=np.number).columns.tolist()
# Convert to Pandas category
for col in cats:
X[col] = X[col].astype('category')Wenn du jetzt das Attribut dtypes ausdruckst, siehst du, dass wir drei category Merkmale haben:
>>> X.dtypes
carat float64
cut category
color category
clarity category
depth float64
table float64
x float64
y float64
z float64
dtype: objectTeilen wir die Daten in Trainings- und Testmengen auf (0,25 Testgröße):
# Split the data
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=1)Jetzt kommt der wichtige Teil: XGBoost verfügt über eine eigene Klasse zum Speichern von Datensätzen namens DMatrix. Es ist eine hochoptimierte Klasse für Speicher und Geschwindigkeit. Deshalb ist die Konvertierung von Datensätzen in dieses Format eine Voraussetzung für die native XGBoost-API:
import xgboost as xgb
# Create regression matrices
dtrain_reg = xgb.DMatrix(X_train, y_train, enable_categorical=True)
dtest_reg = xgb.DMatrix(X_test, y_test, enable_categorical=True)Die Klasse akzeptiert sowohl die Trainingsmerkmale als auch die Labels. Um die automatische Kodierung der Pandas-Kategoriespalten zu aktivieren, setzen wir auch enable_categorical auf True.
Hinweis:
Warum verwenden wir die native API von XGBoost und nicht die Scikit-learn-API? Auch wenn es anfangs vielleicht bequemer ist, die Sklearn-API zu verwenden, wirst du später feststellen, dass die native API von XGBoost einige hervorragende Funktionen enthält, die die erstere nicht unterstützt. Gewöhn dich also besser von Anfang an daran. In einem Abschnitt am Ende zeigen wir jedoch, wie du mit einer einzigen Codezeile zwischen den APIs wechseln kannst, auch nachdem du Modelle trainiert hast.
Nachdem du die DMatrizen erstellt hast, solltest du einen Wert für den Parameter objective wählen. Sie teilt XGBoost mit, welches maschinelle Lernproblem du zu lösen versuchst und welche Metriken oder Verlustfunktionen zur Lösung dieses Problems verwendet werden sollen.
Für die Vorhersage von Diamantenpreisen, die ein Regressionsproblem ist, kannst du zum Beispiel das gemeinsame Ziel reg:squarederror verwenden. In der Regel enthält der Name des Ziels auch den Namen der Verlustfunktion für das Problem. Bei der Regression wird üblicherweise der mittlere quadratische Fehler (Root Mean Squared Error) verwendet, der die Quadratwurzel aus der Summe der Unterschiede zwischen den tatsächlichen und den vorhergesagten Werten minimiert. Hier siehst du, wie die Metrik aussehen würde, wenn sie in NumPy implementiert wäre:
import numpy as np
mse = np.mean((actual - predicted) ** 2)
rmse = np.sqrt(mse)Wir werden die Klassifizierungsziele später im Lernprogramm kennenlernen.
Ein Hinweis auf den Unterschied zwischen einer Verlustfunktion und einer Leistungsmetrik: Eine Verlustfunktion wird von maschinellen Lernmodellen verwendet, um die Unterschiede zwischen den tatsächlichen Werten (Ground Truth) und den Modellvorhersagen zu minimieren. Auf der anderen Seite wählt der Ingenieur für maschinelles Lernen eine Metrik (oder mehrere Metriken), um die Ähnlichkeit zwischen der Grundwahrheit und den Modellvorhersagen zu messen.
Kurz gesagt: Eine Verlustfunktion sollte minimiert werden, während eine Metrik maximiert werden sollte. Beim Training wird eine Verlustfunktion verwendet, um dem Modell zu zeigen, wo es sich verbessern muss. Bei der Bewertung wird eine Metrik verwendet, um die Gesamtleistung zu messen.
Die gewählte Zielfunktion und alle anderen Hyperparameter von XGBoost sollten in einem Wörterbuch angegeben werden, das vereinbarungsgemäß params genannt wird:
# Define hyperparameters
params = {"objective": "reg:squarederror", "tree_method": "gpu_hist"}In diesem anfänglichen params setzen wir auch tree_method auf gpu_hist, was die GPU-Beschleunigung aktiviert. Wenn du keinen Grafikprozessor hast, kannst du den Parameter weglassen oder ihn auf hist setzen.
Jetzt setzen wir einen weiteren Parameter namens num_boost_round, der für die Anzahl der Boosting-Runden steht. Intern minimiert XGBoost die Verlustfunktion RMSE in kleinen inkrementellen Runden (mehr dazu später). Dieser Parameter gibt die Anzahl dieser Runden an.
Die ideale Anzahl von Runden wird durch die Abstimmung der Hyperparameter gefunden. Für den Moment setzen wir ihn einfach auf 100:
# Define hyperparameters
params = {"objective": "reg:squarederror", "tree_method": "gpu_hist"}
n = 100
model = xgb.train(
params=params,
dtrain=dtrain_reg,
num_boost_round=n,
)Wenn XGBoost auf einer GPU läuft, ist es rasend schnell. Wenn du mit dem obigen Code keine Fehlermeldung erhalten hast, war das Training erfolgreich!
Während der Boosting-Runden hat das Modellobjekt alle Muster der Trainingsmenge gelernt, die es lernen kann. Jetzt müssen wir seine Leistung messen, indem wir ihn an ungesehenen Daten testen. Hier kommt unsere dtest_reg DMatrix ins Spiel:
from sklearn.metrics import mean_squared_error
preds = model.predict(dtest_reg)Dieser Schritt des Prozesses wird als Modellbewertung (oder Inferenz) bezeichnet. Sobald du mit Predict Vorhersagen erstellt hast, übergibst du sie in der Funktion mean_squared_error von Sklearn, um sie mit y_test zu vergleichen:
rmse = mean_squared_error(y_test, preds, squared=False)
print(f"RMSE of the base model: {rmse:.3f}")
RMSE of the base model: 543.203Wir haben einen Basiswert von ~543$, was der Leistung eines Basismodells mit Standardparametern entspricht. Es gibt zwei Möglichkeiten, sie zu verbessern - durch Kreuzvalidierung und Hyperparameter-Tuning. Aber vorher wollen wir uns noch eine schnellere Methode ansehen, um die XGBoost-Modelle zu bewerten.
Das Training eines maschinellen Lernmodells ist wie der Start einer Rakete ins All. Bis zum Start kannst du alles über das Modell steuern, aber sobald es startet, kannst du nur noch abwarten, bis es fertig ist.
Aber das Problem mit unserem derzeitigen Trainingsverfahren ist, dass wir nicht einmal beobachten können, wohin das Modell geht. Um dieses Problem zu lösen, werden wir Evaluierungsarrays verwenden, die es uns ermöglichen, die Leistung des Modells zu sehen, wie sie über die Boosting-Runden hinweg schrittweise verbessert wird.
Lass uns zunächst die Parameter neu einstellen:
params = {"objective": "reg:squarederror", "tree_method": "gpu_hist"}
n = 100Als nächstes erstellen wir eine Liste mit zwei Tupeln, die jeweils zwei Elemente enthalten. Das erste Element ist das Array für das auszuwertende Modell und das zweite ist der Name des Arrays.
evals = [(dtrain_reg, "train"), (dtest_reg, "validation")]Wenn wir dieses Array an den evals Parameter von xgb.train übergeben, sehen wir die Modellleistung nach jeder Boosting-Runde:
evals = [(dtrain_reg, "train"), (dtest_reg, "validation")]
model = xgb.train(
params=params,
dtrain=dtrain_reg,
num_boost_round=n,
evals=evals,
)Du solltest eine ähnliche Ausgabe wie die folgende erhalten (hier auf 10 Zeilen gekürzt). Du kannst sehen, wie das Modell die Punktzahl von ~3931$ auf nur 543$ minimiert.
Das Beste ist, dass wir die Leistung des Modells sowohl auf unseren Trainings- als auch auf unseren Validierungssätzen sehen können. In der Regel ist der Trainingsverlust niedriger als der Validierungsverlust, da das Modell das erste bereits gesehen hat.
[0] train-rmse:3985.18329 validation-rmse:3930.52457
[1] train-rmse:2849.72257 validation-rmse:2813.20828
[2] train-rmse:2059.86648 validation-rmse:2036.66330
[3] train-rmse:1519.32314 validation-rmse:1510.02762
[4] train-rmse:1153.68171 validation-rmse:1153.91223
...
[95] train-rmse:381.93902 validation-rmse:543.56526
[96] train-rmse:380.97024 validation-rmse:543.51413
[97] train-rmse:380.75330 validation-rmse:543.36855
[98] train-rmse:379.65918 validation-rmse:543.42558
[99] train-rmse:378.30590 validation-rmse:543.20278In realen Projekten trainierst du in der Regel Tausende von Boosting-Runden, was bedeutet, dass du so viele Zeilen an Output hast. Um sie zu reduzieren, kannst du den Parameter verbose_eval verwenden, der XGBoost dazu zwingt, alle vebose_eval Runden Leistungsaktualisierungen zu drucken:
params = {"objective": "reg:squarederror", "tree_method": "gpu_hist"}
n = 100
evals = [(dtest_reg, "validation"), (dtrain_reg, "train")]
model = xgb.train(
params=params,
dtrain=dtrain_reg,
num_boost_round=n,
evals=evals,
verbose_eval=10 # Every ten rounds
)
[OUT]:
[0] train-rmse:3985.18329 validation-rmse:3930.52457
[10] train-rmse:550.08330 validation-rmse:590.15023
[20] train-rmse:488.51248 validation-rmse:551.73431
[30] train-rmse:463.13288 validation-rmse:547.87843
[40] train-rmse:447.69788 validation-rmse:546.57096
[50] train-rmse:432.91655 validation-rmse:546.22557
[60] train-rmse:421.24046 validation-rmse:546.28601
[70] train-rmse:408.64125 validation-rmse:546.78238
[80] train-rmse:396.41125 validation-rmse:544.69846
[90] train-rmse:386.87996 validation-rmse:543.82192
[99] train-rmse:378.30590 validation-rmse:543.20278Du hast sicher schon gemerkt, wie wichtig Boosting-Runden sind. Generell gilt: Je mehr Runden es gibt, desto mehr versucht XGBoost, den Verlust zu minimieren. Das bedeutet aber nicht, dass der Verlust immer geringer wird. Versuchen wir es mit 5000 Boosting-Runden mit der Ausführlichkeit von 500:
params = {"objective": "reg:squarederror", "tree_method": "gpu_hist"}
n = 5000
evals = [(dtest_reg, "validation"), (dtrain_reg, "train")]
model = xgb.train(
params=params,
dtrain=dtrain_reg,
num_boost_round=n,
evals=evals,
verbose_eval=250
)
[OUT]:
[0] train-rmse:3985.18329 validation-rmse:3930.52457
[500] train-rmse:195.89184 validation-rmse:555.90367
[1000] train-rmse:122.10746 validation-rmse:563.44888
[1500] train-rmse:84.18238 validation-rmse:567.16974
[2000] train-rmse:61.66682 validation-rmse:569.52584
[2500] train-rmse:46.34923 validation-rmse:571.07632
[3000] train-rmse:37.04591 validation-rmse:571.76912
[3500] train-rmse:29.43356 validation-rmse:572.43196
[4000] train-rmse:24.00607 validation-rmse:572.81287
[4500] train-rmse:20.45021 validation-rmse:572.89062
[4999] train-rmse:17.44305 validation-rmse:573.13200
Wir bekommen den niedrigsten Verlust vor Runde 500. Danach sinkt zwar der Ausbildungsverlust, aber der Validierungsverlust (der, der uns interessiert) steigt weiter an.
Bei einer unnötigen Anzahl von Boosting-Runden beginnt XGBoost, den Datensatz zu überarbeiten und sich zu merken. Das wiederum führt dazu, dass die Validierungsleistung sinkt, weil sich das Modell merkt, anstatt zu generalisieren.
Denke daran, wir wollen die goldene Mitte: ein Modell, das im Training gerade so viele Muster gelernt hat, dass es in der Validierungsmenge die höchste Leistung erbringt. Wie finden wir also die perfekte Anzahl von Boosting-Runden?
Wir werden eine Technik anwenden, die man Frühstopp nennt. Frühzeitiges Aufhören zwingt XGBoost dazu, den Validierungsverlust zu beobachten. Wenn er sich für eine bestimmte Anzahl von Runden nicht mehr verbessert, hört er automatisch mit dem Training auf.
Das bedeutet, dass wir eine beliebig hohe Anzahl von Boosting-Runden festlegen können, solange wir eine vernünftige Anzahl von frühen Stopp-Runden festlegen.
Nehmen wir zum Beispiel 10000 Boosting-Runden und setzen den Parameter early_stopping_rounds auf 50. Auf diese Weise bricht XGBoost das Training automatisch ab, wenn sich der Validierungsverlust in 50 aufeinanderfolgenden Runden nicht verbessert.
n = 10000
model = xgb.train(
params=params,
dtrain=dtrain_reg,
num_boost_round=n,
evals=evals,
verbose_eval=50,
# Activate early stopping
early_stopping_rounds=50
)
[OUT]:
[0] train-rmse:3985.18329 validation-rmse:3930.52457
[50] train-rmse:432.91655 validation-rmse:546.22557
[100] train-rmse:377.66173 validation-rmse:542.92457
[150] train-rmse:334.27548 validation-rmse:542.79733
[167] train-rmse:321.04059 validation-rmse:543.35679Wie du siehst, hörte das Training nach der 167. Runde auf, weil sich der Verlust schon 50 Runden vorher nicht mehr verbesserte.
Zu Beginn des Tutorials haben wir 25 % des Datensatzes zum Testen reserviert. Mit der Testmenge können wir die Bedingungen eines Modells in der Produktion simulieren, wo es Vorhersagen für ungesehene Daten erstellen muss.
Aber ein einziger Testsatz reicht nicht aus, um genau zu messen, wie ein Modell in der Produktion abschneiden würde. Wenn wir zum Beispiel die Abstimmung der Hyperparameter nur mit einer einzigen Trainings- und einer einzigen Testmenge durchführen, würde das Wissen über die Testmenge trotzdem "durchsickern". Wie?
Da wir versuchen, den besten Wert eines Hyperparameters zu finden, indem wir die Validierungsleistung des Modells auf der Testmenge vergleichen, erhalten wir am Ende ein Modell, das so konfiguriert ist, dass es nur auf dieser bestimmten Testmenge gut funktioniert. Stattdessen wollen wir ein Modell, das in allen Bereichen gut abschneidet - bei jedem Test, den wir ihm vorlegen.
Eine mögliche Abhilfe ist die Aufteilung der Daten in drei Sätze. Das Modell wird mit der ersten Menge trainiert, die zweite Menge wird für die Bewertung und die Abstimmung der Hyperparameter verwendet und die dritte Menge ist die letzte, mit der wir das Modell vor der Produktion testen.
Aber wenn die Daten begrenzt sind, führt die Aufteilung der Daten in drei Sätze dazu, dass die Trainingsmenge dünn wird, was die Leistung des Modells beeinträchtigt.
Die Lösung für all diese Probleme ist die Kreuzvalidierung. Bei der Kreuzvalidierung haben wir immer noch zwei Sets: Training und Test.
Während die Testmenge in der Ecke wartet, teilen wir das Training in 3, 5, 7 oder k Splits oder Foldings auf. Dann trainieren wir das Modell k-mal. Jedes Mal verwenden wir k-1 Teile zum Training und den letzten k-tenTeil zur Validierung. Dieser Prozess wird als k-fache Kreuzvalidierung bezeichnet:
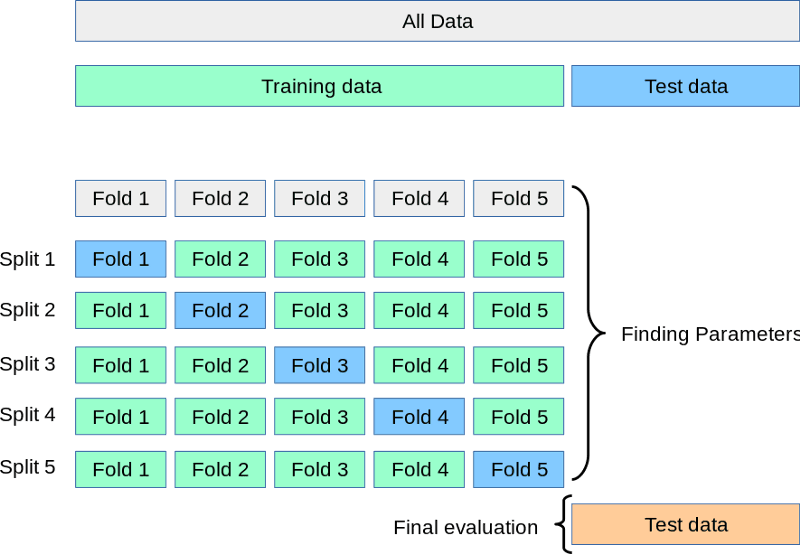
Quelle: https://scikit-learn.org/stable/modules/cross_validation.html
Oben siehst du eine visuelle Darstellung einer 5-fachen Kreuzvalidierung. Nachdem alle Faltungen durchgeführt wurden, können wir den Mittelwert der Punktzahlen als die endgültige, realistischste Leistung des Modells betrachten.
Führen wir diesen Vorgang im Code mit der Funktion cv von XGB durch:
params = {"objective": "reg:squarederror", "tree_method": "gpu_hist"}
n = 1000
results = xgb.cv(
params, dtrain_reg,
num_boost_round=n,
nfold=5,
early_stopping_rounds=20
)Der einzige Unterschied zur Zugfunktion ist das Hinzufügen des Parameters nfold, um die Anzahl der Splits anzugeben. Das Ergebnisobjekt ist jetzt ein DataFrame, der die Ergebnisse der einzelnen Falten enthält:
results.head()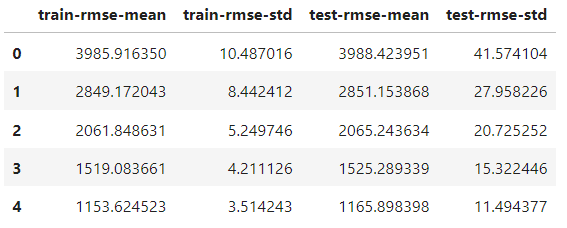
Sie hat die gleiche Anzahl an Reihen wie die Anzahl der Boosting-Runden. Jede Zeile ist der Durchschnitt aller Splits für diese Runde. Um also die beste Punktzahl zu finden, nehmen wir das Minimum der Spalte test-rmse-mean:
best_rmse = results['test-rmse-mean'].min()
best_rmse
550.8959336674216Beachte, dass diese Methode der Kreuzvalidierung verwendet wird, um die wahre Leistung des Modells zu sehen. Wenn du mit dem Ergebnis zufrieden bist, musst du es vor dem Einsatz erneut mit den vollständigen Daten trainieren.
Der Aufbau eines XGBoost-Klassifikators ist so einfach wie das Ändern der Zielfunktion; der Rest kann gleich bleiben.
Die beiden beliebtesten Klassifizierungsziele sind:
binary:logistic - Binäre Klassifizierung (das Ziel enthält nur zwei Klassen, z. B. Katze oder Hund)multi:softprob - Mehrklassen-Klassifizierung (mehr als zwei Klassen im Ziel, z. B. Apfel/Orange/Banane)Die binäre und die Mehrklassen-Klassifizierung in XGBoost sind fast identisch, also entscheiden wir uns für Letzteres. Lass uns zuerst die Daten für die Aufgabe vorbereiten.
Wir wollen die Schliffqualität von Diamanten anhand ihres Preises und ihrer physischen Maße vorhersagen. Wir werden also die Feature-/Ziel-Arrays entsprechend aufbauen:
from sklearn.preprocessing import OrdinalEncoder
X, y = diamonds.drop("cut", axis=1), diamonds[['cut']]
# Encode y to numeric
y_encoded = OrdinalEncoder().fit_transform(y)
# Extract text features
cats = X.select_dtypes(exclude=np.number).columns.tolist()
# Convert to pd.Categorical
for col in cats:
X[col] = X[col].astype('category')
# Split the data
X_train, X_test, y_train, y_test = train_test_split(X, y_encoded, random_state=1, stratify=y_encoded)Der einzige Unterschied besteht darin, dass XGBoost nur Zahlen im Ziel akzeptiert, während wir die Textklassen im Ziel mit OrdinalEncoder von Sklearn kodieren.
Jetzt erstellen wir die DMatrizen...
# Create classification matrices
dtrain_clf = xgb.DMatrix(X_train, y_train, enable_categorical=True)
dtest_clf = xgb.DMatrix(X_test, y_test, enable_categorical=True)...und setze das Ziel auf multi:softprob. Für dieses Ziel muss auch die Anzahl der Klassen von uns festgelegt werden:
params = {"objective": "multi:softprob", "tree_method": "gpu_hist", "num_class": 5}
n = 1000
results = xgb.cv(
params, dtrain_clf,
num_boost_round=n,
nfold=5,
metrics=["mlogloss", "auc", "merror"],
)Während der Kreuzvalidierung bitten wir XGBoost, drei Klassifizierungsmetriken zu beobachten, die die Leistung des Modells aus drei verschiedenen Blickwinkeln darstellen. Hier ist das Ergebnis:
results.keys()
Index(['train-mlogloss-mean', 'train-mlogloss-std', 'train-auc-mean',
'train-auc-std', 'train-merror-mean', 'train-merror-std',
'test-mlogloss-mean', 'test-mlogloss-std', 'test-auc-mean',
'test-auc-std', 'test-merror-mean', 'test-merror-std'],
dtype='object')Um den besten AUC-Wert zu ermitteln, nehmen wir das Maximum der Spalte test-auc-mean:
>>> results['test-auc-mean'].max()
0.9402233623451636Schon die Standardkonfiguration brachte uns 94% Leistung, was großartig ist.
Bisher haben wir die native XGBoost-API verwendet, aber auch die Sklearn-API ist sehr beliebt.
Sklearn ist ein umfangreiches Framework mit vielen Algorithmen und Hilfsprogrammen für maschinelles Lernen und hat eine API-Syntax, die von fast jedem geliebt wird. Deshalb bietet XGBoost auch die Klassen XGBClassifier und XGBRegressor an, damit sie in das Sklearn-Ökosystem integriert werden können (mit dem Verlust eines Teils der Funktionalität).
Wenn du nur die Scikit-learn-API verwenden möchtest, wann immer es möglich ist, und nur dann zur nativen API wechselst, wenn du Zugang zu zusätzlichen Funktionen brauchst, gibt es einen Weg.
Nachdem du den XGBoost-Klassifikator oder -Regressor trainiert hast, kannst du ihn mit der Methode get_booster umwandeln:
import xgboost as xgb
# Train a model using the scikit-learn API
xgb_classifier = xgb.XGBClassifier(n_estimators=100, objective='binary:logistic', tree_method='hist', eta=0.1, max_depth=3, enable_categorical=True)
xgb_classifier.fit(X_train, y_train)
# Convert the model to a native API model
model = xgb_classifier.get_booster()Das Modellobjekt verhält sich genau so, wie wir es in diesem Lernprogramm gesehen haben.
Wir haben in diesem XGBoost-Tutorial viele wichtige Themen behandelt, aber es gibt noch so viele Dinge zu lernen.
Auf der Seite mit den XGBoost-Parametern erfährst du, wie du die Parameter konfigurieren kannst, um das Letzte aus deinen Modellen herauszuholen.
Wenn du auf der Suche nach einer umfassenden, allumfassenden Ressource bist, um die Bibliothek zu erlernen, schau dir unseren Kurs Extreme Gradient Boosting With XGBoost an.
Erfahre mehr über Python und XGBoost
Kurs
Kurs
Kurs
Tutorial
Matt Crabtree
Tutorial
Mark Pedigo
Tutorial
Sejal Jaiswal
Tutorial
Aditya Sharma
Tutorial
DataCamp Team
Tutorial
Satyabrata Pal