Cours
Extreme Gradient Boosting avec XGBoost
4 h
60.7K
XGBoost est l'un des cadres d'apprentissage automatique les plus populaires parmi les scientifiques des données. Selon l'enquête Kaggle State of Data Science Survey 2021, près de 50 % des personnes interrogées ont déclaré utiliser XGBoost, qui se classe juste derrière TensorFlow et Sklearn.
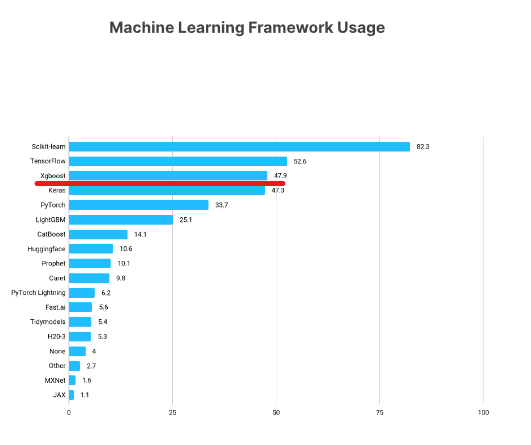
https://www.kaggle.com/kaggle-survey-2021
Ce tutoriel XGBoost présentera les aspects clés de ce framework Python populaire, en explorant comment vous pouvez l'utiliser pour vos propres projets d'apprentissage automatique.
Regardez et apprenez-en plus sur l'utilisation de XGBoost en Python dans cette vidéo de notre cours.
Tout au long de ce tutoriel, nous couvrirons les aspects clés de XGBoost, y compris :
Commençons !
Exécutez et modifiez le code de ce tutoriel en ligne
Exécuter le codeVous pouvez installer XGBoost comme n'importe quelle autre bibliothèque via pip. Cette méthode d'installation inclut également la prise en charge du GPU NVIDIA de votre machine. Si vous souhaitez installer la version CPU-only, vous pouvez utiliser conda-forge :
$ pip install --user xgboost
# CPU only
$ conda install -c conda-forge py-xgboost-cpu
# Use NVIDIA GPU
$ conda install -c conda-forge py-xgboost-gpuIl est recommandé d'installer XGBoost dans un environnement virtuel afin de ne pas polluer votre environnement de base.
Nous vous recommandons d'exécuter les exemples du didacticiel avec une machine équipée d'un GPU. Si vous n'en avez pas, vous pouvez consulter des alternatives comme DataLab ou Google Colab.
Si vous décidez d'opter pour Colab, l'ancienne version de XGBoost est installée, vous devez donc appeler pip install --upgrade xgboost pour obtenir la dernière version.
Nous travaillerons avec l'ensemble de données Diamonds tout au long de ce tutoriel. Il est intégré à la bibliothèque Seaborn, ou vous pouvez également le télécharger sur Kaggle. Il présente une belle combinaison de caractéristiques numériques et catégorielles et plus de 50 000 observations qui nous permettent de présenter confortablement tous les avantages d'XGBoost.
import seaborn as sns
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings("ignore")
diamonds = sns.load_dataset("diamonds")
diamonds.head()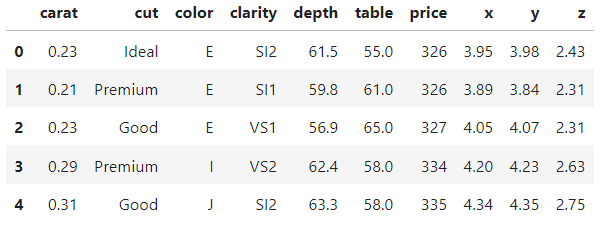
>>> diamonds.shape
(53940, 10)Dans un projet réel typique, vous souhaiteriez passer beaucoup plus de temps à explorer l'ensemble de données et à visualiser ses caractéristiques. Mais comme ces données sont intégrées à Seaborn, elles sont relativement propres.
Nous nous contenterons donc d'examiner le résumé en cinq chiffres des caractéristiques numériques et catégorielles pour commencer. Vous pouvez prendre quelques instants pour vous familiariser avec l'ensemble des données.
diamonds.describe()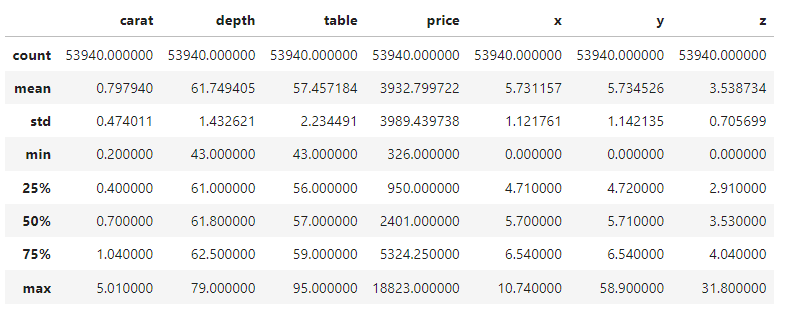
diamonds.describe(exclude=np.number)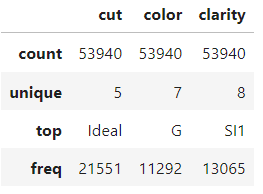
Une fois l'exploration terminée, la première étape de tout projet consiste à formuler le problème d'apprentissage automatique et à extraire les tableaux de caractéristiques et de cibles sur la base de l'ensemble de données.
Dans ce tutoriel, nous allons d'abord essayer de prédire les prix des diamants en utilisant leurs mesures physiques, notre cible sera donc la colonne des prix.
Nous isolons donc les caractéristiques dans X et la cible dans y :
from sklearn.model_selection import train_test_split
# Extract feature and target arrays
X, y = diamonds.drop('price', axis=1), diamonds[['price']]L'ensemble de données comporte trois colonnes catégorielles. Normalement, vous devriez les encoder avec un encodage ordinal ou un encodage à un point, mais XGBoost a la capacité de traiter en interne les catégories.
Pour activer cette fonctionnalité, vous devez convertir les colonnes catégorielles en type de données Pandas category (par défaut, elles sont traitées comme des colonnes de texte) :
# Extract text features
cats = X.select_dtypes(exclude=np.number).columns.tolist()
# Convert to Pandas category
for col in cats:
X[col] = X[col].astype('category')Si vous imprimez l'attribut dtypes, vous verrez que nous avons trois caractéristiques category:
>>> X.dtypes
carat float64
cut category
color category
clarity category
depth float64
table float64
x float64
y float64
z float64
dtype: objectDivisons les données en ensembles de formation et de test (taille de test de 0,25) :
# Split the data
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=1)Maintenant, la partie importante : XGBoost dispose de sa propre classe pour le stockage des ensembles de données, appelée DMatrix. Il s'agit d'une classe hautement optimisée en termes de mémoire et de vitesse. C'est pourquoi la conversion des ensembles de données dans ce format est une exigence de l'API XGBoost native :
import xgboost as xgb
# Create regression matrices
dtrain_reg = xgb.DMatrix(X_train, y_train, enable_categorical=True)
dtest_reg = xgb.DMatrix(X_test, y_test, enable_categorical=True)La classe accepte à la fois les caractéristiques d'apprentissage et les étiquettes. Pour permettre l'encodage automatique des colonnes de catégories Pandas, nous avons également défini enable_categorical sur True.
Note:
Pourquoi utiliser l'API native de XGBoost, plutôt que son API Scikit-learn ? Bien qu'il puisse être plus confortable d'utiliser l'API Sklearn au début, vous réaliserez plus tard que l'API native de XGBoost contient d'excellentes fonctionnalités que l'API Sklearn ne prend pas en charge. Il est donc préférable de s'y habituer dès le début. Cependant, une section à la fin montre comment passer d'une API à l'autre en une seule ligne de code, même après avoir formé des modèles.
Après avoir construit les DMatrices, vous devez choisir une valeur pour le paramètre objective. Il indique à XGBoost le problème d'apprentissage automatique que vous essayez de résoudre et les métriques ou fonctions de perte à utiliser pour résoudre ce problème.
Par exemple, pour prédire le prix des diamants, qui est un problème de régression, vous pouvez utiliser l'objectif commun reg:squarederror. En général, le nom de l'objectif contient également le nom de la fonction de perte pour le problème. Pour la régression, il est courant d'utiliser l'erreur quadratique moyenne, qui minimise la racine carrée de la somme des différences entre les valeurs réelles et les valeurs prédites. Voici à quoi ressemblerait la métrique si elle était implémentée dans NumPy :
import numpy as np
mse = np.mean((actual - predicted) ** 2)
rmse = np.sqrt(mse)Nous verrons les objectifs de classification plus loin dans ce tutoriel.
Note sur la différence entre une fonction de perte et une mesure de performance : Une fonction de perte est utilisée par les modèles d'apprentissage automatique pour minimiser les différences entre les valeurs réelles (vérité de terrain) et les prédictions du modèle. D'autre part, une (ou plusieurs) métrique (s) est (sont) choisie(s) par l'ingénieur en apprentissage automatique pour mesurer la similarité entre la vérité de terrain et les prédictions du modèle.
En bref, une fonction de perte doit être minimisée tandis qu'une métrique doit être maximisée. Une fonction de perte est utilisée pendant la formation pour guider le modèle sur les points à améliorer. Une métrique est utilisée lors de l'évaluation pour mesurer la performance globale.
La fonction objective choisie et tout autre hyperparamètre de XGBoost doivent être spécifiés dans un dictionnaire, appelé par convention params :
# Define hyperparameters
params = {"objective": "reg:squarederror", "tree_method": "gpu_hist"}À l'intérieur de ce site initial params, nous configurons également tree_method en gpu_hist, ce qui active l'accélération GPU. Si vous n'avez pas de GPU, vous pouvez omettre ce paramètre ou le fixer à hist.
Nous définissons maintenant un autre paramètre appelé num_boost_round, qui correspond au nombre de tours de stimulation. En interne, XGBoost minimise la fonction de perte RMSE par petites étapes incrémentales (nous y reviendrons). Ce paramètre spécifie le montant de ces rondes.
Le nombre idéal de tours est déterminé par l'ajustement des hyperparamètres. Pour l'instant, nous nous contenterons de la fixer à 100 :
# Define hyperparameters
params = {"objective": "reg:squarederror", "tree_method": "gpu_hist"}
n = 100
model = xgb.train(
params=params,
dtrain=dtrain_reg,
num_boost_round=n,
)Lorsque XGBoost fonctionne sur un GPU, il est extrêmement rapide. Si vous n'avez pas reçu d'erreur dans le code ci-dessus, la formation s'est déroulée avec succès !
Au cours des cycles de stimulation, l'objet modèle a appris tous les modèles de l'ensemble d'apprentissage qu'il est possible d'apprendre. Nous devons maintenant mesurer ses performances en le testant sur des données inédites. C'est là que notre dtest_reg DMatrix entre en jeu :
from sklearn.metrics import mean_squared_error
preds = model.predict(dtest_reg)Cette étape du processus est appelée évaluation du modèle (ou inférence). Une fois que vous avez généré des prédictions avec predict, vous les passez dans la fonction mean_squared_error de Sklearn pour les comparer à y_test:
rmse = mean_squared_error(y_test, preds, squared=False)
print(f"RMSE of the base model: {rmse:.3f}")
RMSE of the base model: 543.203Nous avons un score de base de ~543$, ce qui correspond à la performance d'un modèle de base avec les paramètres par défaut. Nous pouvons l'améliorer de deux manières : en effectuant une validation croisée et en réglant les hyperparamètres. Mais avant cela, voyons une façon plus rapide d'évaluer les modèles XGBoost.
Former un modèle d'apprentissage automatique, c'est comme lancer une fusée dans l'espace. Vous pouvez contrôler tout ce qui concerne le modèle jusqu'à son lancement, mais une fois qu'il est lancé, tout ce que vous pouvez faire, c'est attendre qu'il se termine.
Mais le problème de notre processus de formation actuel est que nous ne pouvons même pas regarder où va le modèle. Pour résoudre ce problème, nous utiliserons des tableaux d'évaluation qui nous permettront de voir les performances du modèle au fur et à mesure qu'elles sont améliorées de manière incrémentielle au cours des cycles de stimulation.
Tout d'abord, définissons à nouveau les paramètres :
params = {"objective": "reg:squarederror", "tree_method": "gpu_hist"}
n = 100Ensuite, nous créons une liste de deux tuples contenant chacun deux éléments. Le premier élément est le tableau du modèle à évaluer, et le second est le nom du tableau.
evals = [(dtrain_reg, "train"), (dtest_reg, "validation")]Lorsque nous passons ce tableau au paramètre evals de xgb.train, nous voyons la performance du modèle après chaque cycle de boosting :
evals = [(dtrain_reg, "train"), (dtest_reg, "validation")]
model = xgb.train(
params=params,
dtrain=dtrain_reg,
num_boost_round=n,
evals=evals,
)Vous devriez obtenir un résultat similaire à celui ci-dessous (raccourci ici à seulement 10 lignes). Vous pouvez voir comment le modèle minimise le score de ~3931$ à seulement 543$.
Le plus intéressant, c'est que nous pouvons voir les performances du modèle sur nos ensembles d'entraînement et de validation. En général, la perte d'entraînement est inférieure à la perte de validation, car le modèle a déjà vu le premier.
[0] train-rmse:3985.18329 validation-rmse:3930.52457
[1] train-rmse:2849.72257 validation-rmse:2813.20828
[2] train-rmse:2059.86648 validation-rmse:2036.66330
[3] train-rmse:1519.32314 validation-rmse:1510.02762
[4] train-rmse:1153.68171 validation-rmse:1153.91223
...
[95] train-rmse:381.93902 validation-rmse:543.56526
[96] train-rmse:380.97024 validation-rmse:543.51413
[97] train-rmse:380.75330 validation-rmse:543.36855
[98] train-rmse:379.65918 validation-rmse:543.42558
[99] train-rmse:378.30590 validation-rmse:543.20278Dans les projets réels, vous vous entraînez généralement pour des milliers de cycles de stimulation, ce qui signifie de nombreuses lignes de résultats. Pour les réduire, vous pouvez utiliser le paramètre verbose_eval, qui force XGBoost à imprimer des mises à jour de performance tous les vebose_eval rounds :
params = {"objective": "reg:squarederror", "tree_method": "gpu_hist"}
n = 100
evals = [(dtest_reg, "validation"), (dtrain_reg, "train")]
model = xgb.train(
params=params,
dtrain=dtrain_reg,
num_boost_round=n,
evals=evals,
verbose_eval=10 # Every ten rounds
)
[OUT]:
[0] train-rmse:3985.18329 validation-rmse:3930.52457
[10] train-rmse:550.08330 validation-rmse:590.15023
[20] train-rmse:488.51248 validation-rmse:551.73431
[30] train-rmse:463.13288 validation-rmse:547.87843
[40] train-rmse:447.69788 validation-rmse:546.57096
[50] train-rmse:432.91655 validation-rmse:546.22557
[60] train-rmse:421.24046 validation-rmse:546.28601
[70] train-rmse:408.64125 validation-rmse:546.78238
[80] train-rmse:396.41125 validation-rmse:544.69846
[90] train-rmse:386.87996 validation-rmse:543.82192
[99] train-rmse:378.30590 validation-rmse:543.20278Vous devez maintenant avoir compris l'importance des rondes de stimulation. En général, plus il y a de tours, plus XGBoost essaie de minimiser la perte. Mais cela ne signifie pas que la perte diminuera toujours. Essayons avec 5000 tours de stimulation avec une verbosité de 500 :
params = {"objective": "reg:squarederror", "tree_method": "gpu_hist"}
n = 5000
evals = [(dtest_reg, "validation"), (dtrain_reg, "train")]
model = xgb.train(
params=params,
dtrain=dtrain_reg,
num_boost_round=n,
evals=evals,
verbose_eval=250
)
[OUT]:
[0] train-rmse:3985.18329 validation-rmse:3930.52457
[500] train-rmse:195.89184 validation-rmse:555.90367
[1000] train-rmse:122.10746 validation-rmse:563.44888
[1500] train-rmse:84.18238 validation-rmse:567.16974
[2000] train-rmse:61.66682 validation-rmse:569.52584
[2500] train-rmse:46.34923 validation-rmse:571.07632
[3000] train-rmse:37.04591 validation-rmse:571.76912
[3500] train-rmse:29.43356 validation-rmse:572.43196
[4000] train-rmse:24.00607 validation-rmse:572.81287
[4500] train-rmse:20.45021 validation-rmse:572.89062
[4999] train-rmse:17.44305 validation-rmse:573.13200
Nous obtenons la perte la plus faible avant le tour 500. Ensuite, même si la perte d'entraînement continue à diminuer, la perte de validation (celle qui nous intéresse) continue à augmenter.
Lorsqu'on lui donne un nombre inutile de tours de boosting, XGBoost commence à suradapter et à mémoriser l'ensemble de données. Cela entraîne une baisse des performances de validation, car le modèle mémorise au lieu de généraliser.
Rappelez-vous que nous recherchons le juste milieu: un modèle qui a appris juste assez de modèles lors de la formation pour obtenir les meilleures performances sur l'ensemble de validation. Alors, comment trouver le nombre parfait de tours de stimulation ?
Nous utiliserons une technique appelée arrêt anticipé. L'arrêt précoce oblige XGBoost à surveiller la perte de validation, et s'il cesse de s'améliorer pendant un nombre spécifié de tours, il arrête automatiquement la formation.
Cela signifie que nous pouvons fixer un nombre de tours de stimulation aussi élevé que possible, à condition de fixer un nombre raisonnable de tours d'arrêt précoces.
Par exemple, utilisons 10000 tours de boosting et fixons le paramètre early_stopping_rounds à 50. De cette façon, XGBoost arrêtera automatiquement la formation si la perte de validation ne s'améliore pas pendant 50 cycles consécutifs.
n = 10000
model = xgb.train(
params=params,
dtrain=dtrain_reg,
num_boost_round=n,
evals=evals,
verbose_eval=50,
# Activate early stopping
early_stopping_rounds=50
)
[OUT]:
[0] train-rmse:3985.18329 validation-rmse:3930.52457
[50] train-rmse:432.91655 validation-rmse:546.22557
[100] train-rmse:377.66173 validation-rmse:542.92457
[150] train-rmse:334.27548 validation-rmse:542.79733
[167] train-rmse:321.04059 validation-rmse:543.35679Comme vous pouvez le constater, l'entraînement s'est arrêté après le 167e round, car la perte a cessé de s'améliorer pendant les 50 rounds précédents.
Au début du didacticiel, nous avons mis de côté 25 % de l'ensemble de données pour les tests. L'ensemble de test nous permettrait de simuler les conditions d'un modèle en production, où il doit générer des prédictions pour des données inédites.
Mais une seule série de tests ne suffirait pas à mesurer avec précision les performances d'un modèle en production. Par exemple, si nous procédons à l'ajustement des hyperparamètres en n'utilisant qu'un seul ensemble d'apprentissage et un seul ensemble de test, les connaissances relatives à l'ensemble de test continueront à "fuir". Comment ?
Étant donné que nous essayons de trouver la meilleure valeur d'un hyperparamètre en comparant les performances de validation du modèle sur l'ensemble de test, nous obtiendrons un modèle configuré pour être performant uniquement sur cet ensemble de test particulier. Nous voulons au contraire un modèle qui donne de bons résultats dans tous les domaines, quel que soit l'ensemble de tests que nous lui soumettons.
Une solution possible consiste à diviser les données en trois ensembles. Le modèle s'entraîne sur le premier ensemble, le deuxième est utilisé pour l'évaluation et le réglage des hyperparamètres, et le troisième est le dernier pour tester le modèle avant la production.
Mais lorsque les données sont limitées, la division des données en trois ensembles rendra l'ensemble d'apprentissage peu dense, ce qui nuira à la performance du modèle.
La solution à tous ces problèmes est la validation croisée. En validation croisée, nous disposons toujours de deux ensembles : l'entraînement et le test.
Pendant que l'ensemble de test attend dans un coin, nous divisons la formation en 3, 5, 7 ou k divisions ou plis. Ensuite, nous entraînons le modèle k fois. Chaque fois, nous utilisons k-1 parties pour la formation et la kièmepartie finale pour la validation. Ce processus est appelé validation croisée k-fold :
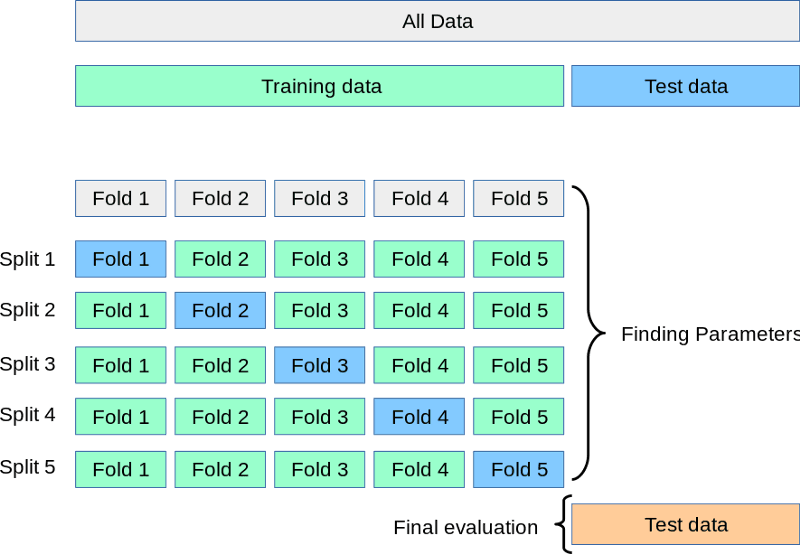
Source : https://scikit-learn.org/stable/modules/cross_validation.html
Vous trouverez ci-dessus une représentation visuelle d'une validation croisée 5 fois. Une fois tous les plis effectués, nous pouvons considérer la moyenne des scores comme la performance finale, la plus réaliste, du modèle.
Exécutons ce processus dans le code en utilisant la fonction cv de XGB :
params = {"objective": "reg:squarederror", "tree_method": "gpu_hist"}
n = 1000
results = xgb.cv(
params, dtrain_reg,
num_boost_round=n,
nfold=5,
early_stopping_rounds=20
)La seule différence avec la fonction train est l'ajout du paramètre nfold pour spécifier le nombre de fractionnements. L'objet résultats est maintenant un DataFrame contenant les résultats de chaque pli :
results.head()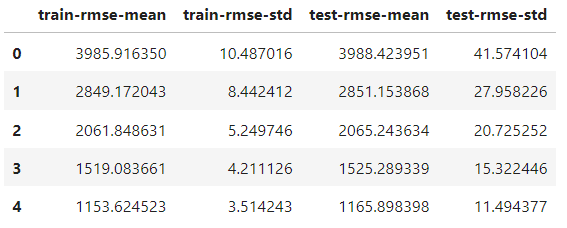
Il comporte le même nombre de lignes que le nombre de tours de stimulation. Chaque ligne correspond à la moyenne de tous les fractionnements pour ce tour. Ainsi, pour trouver le meilleur score, nous prenons le minimum de la colonne test-rmse-mean:
best_rmse = results['test-rmse-mean'].min()
best_rmse
550.8959336674216Notez que cette méthode de validation croisée est utilisée pour voir la véritable performance du modèle. Une fois satisfait de son score, vous devez le réentraîner sur l'ensemble des données avant de le déployer.
Pour construire un classificateur XGBoost, il suffit de modifier la fonction objective ; le reste peut rester inchangé.
Les deux objectifs de classification les plus courants sont les suivants :
binary:logistic - classification binaire (la cible ne contient que deux classes, à savoir chat ou chien)multi:softprob - classification multi-classes (plus de deux classes dans la cible, par exemple, pomme/orange/banane)La classification binaire et multi-classe dans XGBoost est presque identique, nous opterons donc pour cette dernière. Préparons d'abord les données pour la tâche.
Nous voulons prédire la qualité de la taille des diamants en fonction de leur prix et de leurs mesures physiques. Nous construirons donc les tableaux caractéristiques/cibles en conséquence :
from sklearn.preprocessing import OrdinalEncoder
X, y = diamonds.drop("cut", axis=1), diamonds[['cut']]
# Encode y to numeric
y_encoded = OrdinalEncoder().fit_transform(y)
# Extract text features
cats = X.select_dtypes(exclude=np.number).columns.tolist()
# Convert to pd.Categorical
for col in cats:
X[col] = X[col].astype('category')
# Split the data
X_train, X_test, y_train, y_test = train_test_split(X, y_encoded, random_state=1, stratify=y_encoded)La seule différence est que, puisque XGBoost n'accepte que des nombres dans la cible, nous encodons les classes de texte dans la cible avec OrdinalEncoder de Sklearn.
Maintenant, nous construisons les DMatrices...
# Create classification matrices
dtrain_clf = xgb.DMatrix(X_train, y_train, enable_categorical=True)
dtest_clf = xgb.DMatrix(X_test, y_test, enable_categorical=True)...et fixez l'objectif à multi:softprob. Cet objectif exige également que le nombre de classes soit fixé par nous :
params = {"objective": "multi:softprob", "tree_method": "gpu_hist", "num_class": 5}
n = 1000
results = xgb.cv(
params, dtrain_clf,
num_boost_round=n,
nfold=5,
metrics=["mlogloss", "auc", "merror"],
)Lors de la validation croisée, nous demandons à XGBoost d'observer trois mesures de classification qui rendent compte des performances du modèle sous trois angles différents. Voici le résultat :
results.keys()
Index(['train-mlogloss-mean', 'train-mlogloss-std', 'train-auc-mean',
'train-auc-std', 'train-merror-mean', 'train-merror-std',
'test-mlogloss-mean', 'test-mlogloss-std', 'test-auc-mean',
'test-auc-std', 'test-merror-mean', 'test-merror-std'],
dtype='object')Pour obtenir le meilleur score AUC, nous prenons le maximum de la colonne test-auc-moyenne :
>>> results['test-auc-mean'].max()
0.9402233623451636Même la configuration par défaut nous a permis d'atteindre une performance de 94 %, ce qui est excellent.
Jusqu'à présent, nous avons utilisé l'API native de XGBoost, mais son API Sklearn est également très populaire.
Sklearn est un vaste cadre de travail comprenant de nombreux algorithmes et utilitaires d'apprentissage automatique et disposant d'une syntaxe d'API appréciée par presque tout le monde. C'est pourquoi XGBoost propose également les classes XGBClassifier et XGBRegressor afin qu'elles puissent être intégrées dans l'écosystème Sklearn (au détriment de certaines fonctionnalités).
Si vous souhaitez utiliser l'API Scikit-learn dans la mesure du possible et ne passer à la version native que lorsque vous avez besoin d'accéder à des fonctionnalités supplémentaires, il existe une solution.
Après avoir formé le classificateur ou le régresseur XGBoost, vous pouvez le convertir à l'aide de la méthode get_booster:
import xgboost as xgb
# Train a model using the scikit-learn API
xgb_classifier = xgb.XGBClassifier(n_estimators=100, objective='binary:logistic', tree_method='hist', eta=0.1, max_depth=3, enable_categorical=True)
xgb_classifier.fit(X_train, y_train)
# Convert the model to a native API model
model = xgb_classifier.get_booster()L'objet modèle se comportera exactement de la même manière que nous l'avons vu tout au long de ce tutoriel.
Nous avons abordé de nombreux sujets importants dans ce tutoriel XGBoost, mais il reste encore beaucoup de choses à apprendre.
Vous pouvez consulter la page des paramètres XGBoost, qui vous apprend à configurer les paramètres pour tirer le meilleur parti de vos modèles.
Si vous êtes à la recherche d'une ressource complète, tout-en-un, pour apprendre la bibliothèque, consultez notre cours Extreme Gradient Boosting With XGBoost.
En savoir plus sur Python et XGBoost
Cours
Cours
Cours
Tutoriel
Aditya Sharma
Tutoriel
Satyabrata Pal
Tutoriel
Aditya Sharma
Tutoriel
DataCamp Team
Tutoriel
Sejal Jaiswal
Tutoriel
Mark Pedigo