Curso
Extreme Gradient Boosting com XGBoost
4 h
60.7K
O XGBoost é uma das estruturas de aprendizado de máquina mais populares entre os cientistas de dados. De acordo com a pesquisa Kaggle State of Data Science Survey 2021, quase 50% dos entrevistados disseram que usaram o XGBoost, ficando abaixo apenas do TensorFlow e do Sklearn.
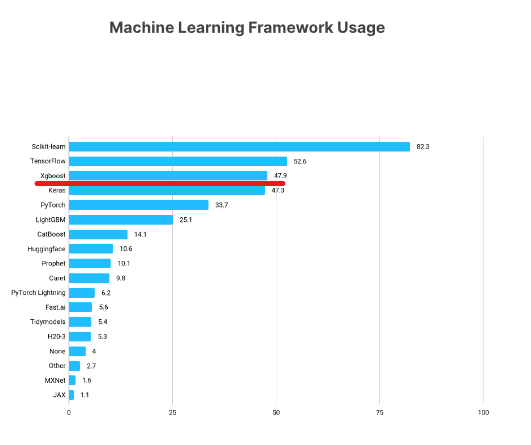
https://www.kaggle.com/kaggle-survey-2021
Este tutorial do XGBoost apresentará os principais aspectos dessa popular estrutura Python, explorando como você pode usá-la em seus próprios projetos de aprendizado de máquina.
Assista e saiba mais sobre o uso do XGBoost em Python neste vídeo do nosso curso.
Ao longo deste tutorial, abordaremos os principais aspectos do XGBoost, inclusive:
Vamos começar!
Execute e edite o código deste tutorial online
Executar códigoVocê pode instalar o XGBoost como qualquer outra biblioteca por meio do pip. Esse método de instalação também incluirá suporte para a GPU NVIDIA do seu computador. Se quiser instalar a versão somente para CPU, você pode usar o conda-forge:
$ pip install --user xgboost
# CPU only
$ conda install -c conda-forge py-xgboost-cpu
# Use NVIDIA GPU
$ conda install -c conda-forge py-xgboost-gpuRecomenda-se que você instale o XGBoost em um ambiente virtual para não poluir o seu ambiente básico.
Recomendamos que você execute os exemplos do tutorial com uma máquina habilitada para GPU. Se não tiver um, você pode verificar alternativas como o DataLab ou o Google Colab.
Se você optar pelo Colab, ele tem a versão antiga do XGBoost instalada, portanto, você deve ligar para pip install --upgrade xgboost para obter a versão mais recente.
Trabalharemos com o conjunto de dados Diamonds durante todo o tutorial. Ele está integrado à biblioteca do Seaborn ou, como alternativa, você também pode baixá-lo do Kaggle. Ele tem uma boa combinação de recursos numéricos e categóricos e mais de 50 mil observações, o que nos permite mostrar confortavelmente todas as vantagens do XGBoost.
import seaborn as sns
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings("ignore")
diamonds = sns.load_dataset("diamonds")
diamonds.head()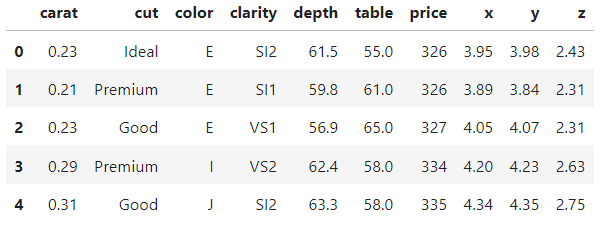
>>> diamonds.shape
(53940, 10)Em um projeto típico do mundo real, você gostaria de passar muito mais tempo explorando o conjunto de dados e visualizando seus recursos. Mas como esses dados são incorporados ao Seaborn, eles são relativamente limpos.
Portanto, vamos dar uma olhada no resumo de cinco números dos recursos numéricos e categóricos e continuar. Você pode dedicar alguns momentos para se familiarizar com o conjunto de dados.
diamonds.describe()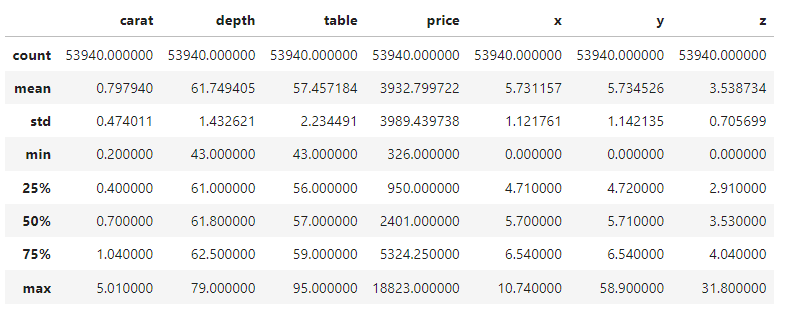
diamonds.describe(exclude=np.number)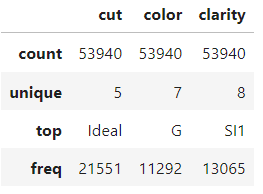
Depois que você terminar a exploração, a primeira etapa de qualquer projeto é enquadrar o problema de aprendizado de máquina e extrair os conjuntos de recursos e alvos com base no conjunto de dados.
Neste tutorial, primeiro tentaremos prever os preços dos diamantes usando suas medidas físicas, portanto, nosso alvo será a coluna de preços.
Portanto, estamos isolando os recursos em X e o alvo em y:
from sklearn.model_selection import train_test_split
# Extract feature and target arrays
X, y = diamonds.drop('price', axis=1), diamonds[['price']]O conjunto de dados tem três colunas categóricas. Normalmente, você os codificaria com a codificação ordinal ou de um único ponto, mas o XGBoost tem a capacidade de lidar internamente com categóricos.
A maneira de ativar esse recurso é converter as colunas categóricas no tipo de dados do Pandas category (por padrão, elas são tratadas como colunas de texto):
# Extract text features
cats = X.select_dtypes(exclude=np.number).columns.tolist()
# Convert to Pandas category
for col in cats:
X[col] = X[col].astype('category')Agora, ao imprimir o atributo dtypes, você verá que temos três recursos category:
>>> X.dtypes
carat float64
cut category
color category
clarity category
depth float64
table float64
x float64
y float64
z float64
dtype: objectVamos dividir os dados em conjuntos de treinamento e teste (tamanho de teste de 0,25):
# Split the data
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=1)Agora, a parte importante: O XGBoost vem com sua própria classe para armazenar conjuntos de dados, chamada DMatrix. É uma classe altamente otimizada para memória e velocidade. É por isso que a conversão de conjuntos de dados nesse formato é um requisito para a API nativa do XGBoost:
import xgboost as xgb
# Create regression matrices
dtrain_reg = xgb.DMatrix(X_train, y_train, enable_categorical=True)
dtest_reg = xgb.DMatrix(X_test, y_test, enable_categorical=True)A classe aceita tanto os recursos de treinamento quanto os rótulos. Para ativar a codificação automática das colunas de categoria do Pandas, também definimos enable_categorical como True.
Observação:
Por que estamos usando a API nativa do XGBoost, em vez da API do Scikit-learn? Embora possa ser mais confortável usar a API do Sklearn no início, mais tarde você perceberá que a API nativa do XGBoost contém alguns recursos excelentes que não são suportados pela primeira. Portanto, é melhor você se acostumar com isso desde o início. No entanto, há uma seção no final em que mostramos como alternar entre APIs em uma única linha de código, mesmo depois de você ter treinado os modelos.
Depois de criar as DMatrices, você deve escolher um valor para o parâmetro objective. Ele informa ao XGBoost o problema de aprendizado de máquina que você está tentando resolver e quais métricas ou funções de perda devem ser usadas para resolver esse problema.
Por exemplo, para prever os preços dos diamantes, que é um problema de regressão, você pode usar o objetivo comum reg:squarederror. Normalmente, o nome do objetivo também contém o nome da função de perda para o problema. Para regressão, é comum usar a raiz do erro quadrático médio, que minimiza a raiz quadrada da soma quadrada das diferenças entre os valores reais e previstos. Aqui está a aparência da métrica quando implementada no NumPy:
import numpy as np
mse = np.mean((actual - predicted) ** 2)
rmse = np.sqrt(mse)Aprenderemos os objetivos de classificação mais adiante no tutorial.
Uma observação sobre a diferença entre uma função de perda e uma métrica de desempenho: Uma função de perda é usada por modelos de aprendizado de máquina para minimizar as diferenças entre os valores reais (verdade terrestre) e as previsões do modelo. Por outro lado, uma métrica (ou métricas) é escolhida pelo engenheiro de aprendizado de máquina para medir a semelhança entre a verdade básica e as previsões do modelo.
Em resumo, uma função de perda deve ser minimizada, enquanto uma métrica deve ser maximizada. Uma função de perda é usada durante o treinamento para orientar o modelo sobre onde melhorar. Uma métrica é usada durante a avaliação para medir o desempenho geral.
A função objetiva escolhida e quaisquer outros hiperparâmetros do XGBoost devem ser especificados em um dicionário, que, por convenção, deve ser chamado de params:
# Define hyperparameters
params = {"objective": "reg:squarederror", "tree_method": "gpu_hist"}Dentro desse params inicial, também estamos configurando tree_method para gpu_hist, o que permite a aceleração da GPU. Se você não tiver uma GPU, poderá omitir o parâmetro ou defini-lo como hist.
Agora, definimos outro parâmetro chamado num_boost_round, que representa o número de rodadas de reforço. Internamente, o XGBoost minimiza a função de perda RMSE em pequenas rodadas incrementais (mais sobre isso adiante). Esse parâmetro especifica a quantidade dessas rodadas.
O número ideal de rodadas é encontrado por meio do ajuste de hiperparâmetros. Por enquanto, vamos definir esse valor como 100:
# Define hyperparameters
params = {"objective": "reg:squarederror", "tree_method": "gpu_hist"}
n = 100
model = xgb.train(
params=params,
dtrain=dtrain_reg,
num_boost_round=n,
)Quando o XGBoost é executado em uma GPU, ele é extremamente rápido. Se você não recebeu nenhum erro do código acima, o treinamento foi bem-sucedido!
Durante as rodadas de reforço, o objeto modelo aprendeu todos os padrões do conjunto de treinamento possíveis. Agora, precisamos medir seu desempenho testando-o em dados não vistos. É aí que o nosso dtest_reg DMatrix entra em ação:
from sklearn.metrics import mean_squared_error
preds = model.predict(dtest_reg)Essa etapa do processo é chamada de avaliação (ou inferência) do modelo. Depois de gerar previsões com o predict, você as passa para a função mean_squared_error do Sklearn para comparar com y_test:
rmse = mean_squared_error(y_test, preds, squared=False)
print(f"RMSE of the base model: {rmse:.3f}")
RMSE of the base model: 543.203Temos uma pontuação básica de ~543$, que foi o desempenho de um modelo básico com parâmetros padrão. Há duas maneiras de aprimorá-lo: realizando a validação cruzada e o ajuste do hiperparâmetro. Mas antes disso, vamos ver uma maneira mais rápida de avaliar os modelos XGBoost.
Treinar um modelo de aprendizado de máquina é como lançar um foguete no espaço. Você pode controlar tudo sobre o modelo até o lançamento, mas, uma vez lançado, tudo o que você pode fazer é aguardar e esperar que ele termine.
Mas o problema com nosso processo de treinamento atual é que não podemos nem mesmo observar para onde o modelo está indo. Para resolver esse problema, usaremos matrizes de avaliação que nos permitem ver o desempenho do modelo à medida que ele é aprimorado de forma incremental nas rodadas de reforço.
Primeiro, vamos configurar os parâmetros novamente:
params = {"objective": "reg:squarederror", "tree_method": "gpu_hist"}
n = 100Em seguida, criamos uma lista de duas tuplas que contêm dois elementos cada. O primeiro elemento é a matriz para o modelo a ser avaliado, e o segundo é o nome da matriz.
evals = [(dtrain_reg, "train"), (dtest_reg, "validation")]Quando passarmos essa matriz para o parâmetro evals de xgb.train, você verá o desempenho do modelo após cada rodada de aumento:
evals = [(dtrain_reg, "train"), (dtest_reg, "validation")]
model = xgb.train(
params=params,
dtrain=dtrain_reg,
num_boost_round=n,
evals=evals,
)Você deve obter um resultado semelhante ao abaixo (reduzido aqui para apenas 10 linhas). Você pode ver como o modelo minimiza a pontuação de incríveis ~3931$ para apenas 543$.
O melhor é que podemos ver o desempenho do modelo em nossos conjuntos de treinamento e validação. Normalmente, a perda de treinamento será menor do que a validação, pois o modelo já viu a primeira.
[0] train-rmse:3985.18329 validation-rmse:3930.52457
[1] train-rmse:2849.72257 validation-rmse:2813.20828
[2] train-rmse:2059.86648 validation-rmse:2036.66330
[3] train-rmse:1519.32314 validation-rmse:1510.02762
[4] train-rmse:1153.68171 validation-rmse:1153.91223
...
[95] train-rmse:381.93902 validation-rmse:543.56526
[96] train-rmse:380.97024 validation-rmse:543.51413
[97] train-rmse:380.75330 validation-rmse:543.36855
[98] train-rmse:379.65918 validation-rmse:543.42558
[99] train-rmse:378.30590 validation-rmse:543.20278Em projetos do mundo real, você geralmente treina milhares de rodadas de reforço, o que significa muitas linhas de saída. Para reduzi-los, você pode usar o parâmetro verbose_eval, que força o XGBoost a imprimir atualizações de desempenho a cada vebose_eval rodadas:
params = {"objective": "reg:squarederror", "tree_method": "gpu_hist"}
n = 100
evals = [(dtest_reg, "validation"), (dtrain_reg, "train")]
model = xgb.train(
params=params,
dtrain=dtrain_reg,
num_boost_round=n,
evals=evals,
verbose_eval=10 # Every ten rounds
)
[OUT]:
[0] train-rmse:3985.18329 validation-rmse:3930.52457
[10] train-rmse:550.08330 validation-rmse:590.15023
[20] train-rmse:488.51248 validation-rmse:551.73431
[30] train-rmse:463.13288 validation-rmse:547.87843
[40] train-rmse:447.69788 validation-rmse:546.57096
[50] train-rmse:432.91655 validation-rmse:546.22557
[60] train-rmse:421.24046 validation-rmse:546.28601
[70] train-rmse:408.64125 validation-rmse:546.78238
[80] train-rmse:396.41125 validation-rmse:544.69846
[90] train-rmse:386.87996 validation-rmse:543.82192
[99] train-rmse:378.30590 validation-rmse:543.20278A esta altura, você já deve ter percebido a importância das rodadas de reforço. Em geral, quanto mais rodadas houver, mais o XGBoost tentará minimizar a perda. Mas isso não significa que a perda sempre diminuirá. Vamos tentar com 5.000 rodadas de aumento com a verbosidade de 500:
params = {"objective": "reg:squarederror", "tree_method": "gpu_hist"}
n = 5000
evals = [(dtest_reg, "validation"), (dtrain_reg, "train")]
model = xgb.train(
params=params,
dtrain=dtrain_reg,
num_boost_round=n,
evals=evals,
verbose_eval=250
)
[OUT]:
[0] train-rmse:3985.18329 validation-rmse:3930.52457
[500] train-rmse:195.89184 validation-rmse:555.90367
[1000] train-rmse:122.10746 validation-rmse:563.44888
[1500] train-rmse:84.18238 validation-rmse:567.16974
[2000] train-rmse:61.66682 validation-rmse:569.52584
[2500] train-rmse:46.34923 validation-rmse:571.07632
[3000] train-rmse:37.04591 validation-rmse:571.76912
[3500] train-rmse:29.43356 validation-rmse:572.43196
[4000] train-rmse:24.00607 validation-rmse:572.81287
[4500] train-rmse:20.45021 validation-rmse:572.89062
[4999] train-rmse:17.44305 validation-rmse:573.13200
Obtemos a menor perda antes da rodada 500. Depois disso, embora a perda de treinamento continue diminuindo, a perda de validação (a que nos interessa) continua aumentando.
Quando você recebe um número desnecessário de rodadas de reforço, o XGBoost começa a se ajustar demais e a memorizar o conjunto de dados. Isso, por sua vez, leva a uma queda no desempenho da validação porque o modelo está memorizando em vez de generalizar.
Lembre-se de que queremos o meio-termo: um modelo que tenha aprendido padrões suficientes no treinamento para proporcionar o melhor desempenho no conjunto de validação. Então, como podemos encontrar o número perfeito de rodadas de reforço?
Usaremos uma técnica chamada parada antecipada. A interrupção antecipada força o XGBoost a observar a perda de validação e, se parar de melhorar em um número especificado de rodadas, ele interrompe automaticamente o treinamento.
Isso significa que podemos definir um número tão alto de rodadas de aumento, desde que definamos um número razoável de rodadas de parada antecipada.
Por exemplo, vamos usar 10000 rodadas de aumento e definir o parâmetro early_stopping_rounds como 50. Dessa forma, o XGBoost interromperá automaticamente o treinamento se a perda de validação não melhorar por 50 rodadas consecutivas.
n = 10000
model = xgb.train(
params=params,
dtrain=dtrain_reg,
num_boost_round=n,
evals=evals,
verbose_eval=50,
# Activate early stopping
early_stopping_rounds=50
)
[OUT]:
[0] train-rmse:3985.18329 validation-rmse:3930.52457
[50] train-rmse:432.91655 validation-rmse:546.22557
[100] train-rmse:377.66173 validation-rmse:542.92457
[150] train-rmse:334.27548 validation-rmse:542.79733
[167] train-rmse:321.04059 validation-rmse:543.35679Como você pode ver, o treinamento parou após a 167ª rodada porque a perda parou de melhorar por 50 rodadas antes disso.
No início do tutorial, reservamos 25% do conjunto de dados para testes. O conjunto de testes nos permitiria simular as condições de um modelo em produção, onde ele deve gerar previsões para dados não vistos.
Mas apenas um único conjunto de testes não seria suficiente para medir com precisão o desempenho de um modelo na produção. Por exemplo, se realizarmos o ajuste do hiperparâmetro usando apenas um único conjunto de treinamento e um único conjunto de teste, o conhecimento sobre o conjunto de teste ainda "vazaria". Como?
Como tentamos encontrar o melhor valor de um hiperparâmetro comparando o desempenho de validação do modelo no conjunto de teste, acabaremos com um modelo configurado para ter um bom desempenho somente nesse conjunto de teste específico. Em vez disso, queremos um modelo que tenha um bom desempenho em todas as áreas, em qualquer conjunto de testes que você fizer.
Uma possível solução alternativa é dividir os dados em três conjuntos. O modelo é treinado no primeiro conjunto, o segundo conjunto é usado para avaliação e ajuste de hiperparâmetros, e o terceiro é o último conjunto em que testamos o modelo antes da produção.
Porém, quando os dados são limitados, a divisão dos dados em três conjuntos tornará o conjunto de treinamento esparso, o que prejudica o desempenho do modelo.
A solução para todos esses problemas é a validação cruzada. Na validação cruzada, ainda temos dois conjuntos: treinamento e teste.
Enquanto o conjunto de teste aguarda no canto, dividimos o treinamento em 3, 5, 7 ou k divisões ou dobras. Em seguida, treinamos o modelo k vezes. A cada vez, usamos k-1 partes para treinamento e a k-ésimaparte final para validação. Esse processo é chamado de validação cruzada k-fold:
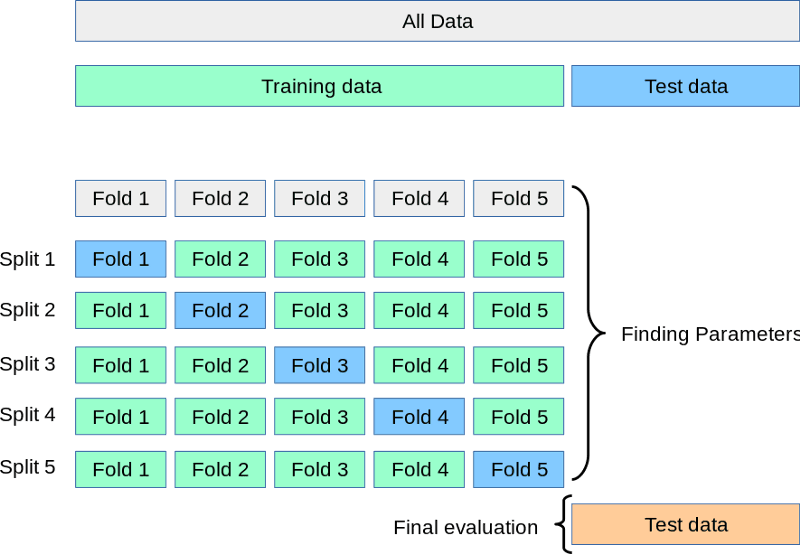
Fonte: https://scikit-learn.org/stable/modules/cross_validation.html
Acima, você tem uma representação visual de uma validação cruzada de 5 vezes. Depois que todas as dobras forem feitas, podemos considerar a média das pontuações como o desempenho final e mais realista do modelo.
Vamos executar esse processo no código usando a função cv do XGB:
params = {"objective": "reg:squarederror", "tree_method": "gpu_hist"}
n = 1000
results = xgb.cv(
params, dtrain_reg,
num_boost_round=n,
nfold=5,
early_stopping_rounds=20
)A única diferença em relação à função train é adicionar o parâmetro nfold para especificar o número de divisões. O objeto de resultados agora é um DataFrame que contém os resultados de cada pasta:
results.head()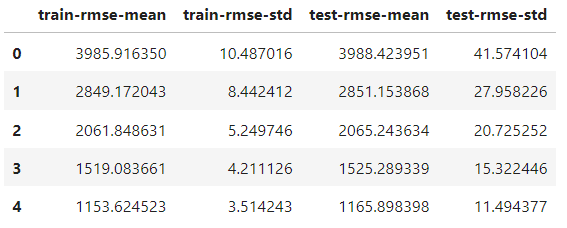
Ele tem o mesmo número de linhas que o número de rodadas de reforço. Cada linha é a média de todas as divisões para aquela rodada. Portanto, para encontrar a melhor pontuação, pegamos o mínimo da coluna test-rmse-mean:
best_rmse = results['test-rmse-mean'].min()
best_rmse
550.8959336674216Observe que esse método de validação cruzada é usado para ver o desempenho real do modelo. Quando estiver satisfeito com a pontuação, você deverá treiná-lo novamente com os dados completos antes da implementação.
Criar um classificador XGBoost é tão fácil quanto alterar a função objetiva; o restante pode permanecer o mesmo.
Os dois objetivos de classificação mais populares são:
binary:logistic - classificação binária (o alvo contém apenas duas classes, ou seja, gato ou cachorro)multi:softprob - classificação multiclasse (mais de duas classes no alvo, ou seja, maçã/laranja/banana)A execução da classificação binária e multiclasse no XGBoost é quase idêntica, portanto, optaremos pela última. Primeiro, vamos preparar os dados para a tarefa.
Queremos prever a qualidade da lapidação dos diamantes com base em seu preço e em suas medidas físicas. Portanto, criaremos as matrizes de recurso/alvo de acordo com isso:
from sklearn.preprocessing import OrdinalEncoder
X, y = diamonds.drop("cut", axis=1), diamonds[['cut']]
# Encode y to numeric
y_encoded = OrdinalEncoder().fit_transform(y)
# Extract text features
cats = X.select_dtypes(exclude=np.number).columns.tolist()
# Convert to pd.Categorical
for col in cats:
X[col] = X[col].astype('category')
# Split the data
X_train, X_test, y_train, y_test = train_test_split(X, y_encoded, random_state=1, stratify=y_encoded)A única diferença é que, como o XGBoost só aceita números no destino, estamos codificando as classes de texto no destino com OrdinalEncoder do Sklearn.
Agora, criamos as DMatrices...
# Create classification matrices
dtrain_clf = xgb.DMatrix(X_train, y_train, enable_categorical=True)
dtest_clf = xgb.DMatrix(X_test, y_test, enable_categorical=True)...e defina o objetivo para multi:softprob. Esse objetivo também exige que o número de classes seja definido por nós:
params = {"objective": "multi:softprob", "tree_method": "gpu_hist", "num_class": 5}
n = 1000
results = xgb.cv(
params, dtrain_clf,
num_boost_round=n,
nfold=5,
metrics=["mlogloss", "auc", "merror"],
)Durante a validação cruzada, pedimos ao XGBoost que observe três métricas de classificação que informam o desempenho do modelo de três ângulos diferentes. Aqui está o resultado:
results.keys()
Index(['train-mlogloss-mean', 'train-mlogloss-std', 'train-auc-mean',
'train-auc-std', 'train-merror-mean', 'train-merror-std',
'test-mlogloss-mean', 'test-mlogloss-std', 'test-auc-mean',
'test-auc-std', 'test-merror-mean', 'test-merror-std'],
dtype='object')Para ver a melhor pontuação AUC, pegamos o máximo da coluna test-auc-mean:
>>> results['test-auc-mean'].max()
0.9402233623451636Mesmo a configuração padrão nos proporcionou 94% de desempenho, o que é ótimo.
Até o momento, usamos a API nativa do XGBoost, mas a API do Sklearn também é bastante popular.
O Sklearn é uma estrutura ampla com muitos algoritmos e utilitários de aprendizado de máquina e tem uma sintaxe de API adorada por quase todo mundo. Portanto, o XGBoost também oferece as classes XGBClassifier e XGBRegressor para que possam ser integradas ao ecossistema do Sklearn (com a perda de parte da funcionalidade).
Se você quiser usar apenas a API do Scikit-learn sempre que possível e só mudar para a versão nativa quando precisar de acesso a funcionalidades extras, há uma maneira.
Depois de treinar o classificador ou regressor XGBoost, você pode convertê-lo usando o método get_booster:
import xgboost as xgb
# Train a model using the scikit-learn API
xgb_classifier = xgb.XGBClassifier(n_estimators=100, objective='binary:logistic', tree_method='hist', eta=0.1, max_depth=3, enable_categorical=True)
xgb_classifier.fit(X_train, y_train)
# Convert the model to a native API model
model = xgb_classifier.get_booster()O objeto modelo se comportará exatamente da mesma forma que vimos ao longo deste tutorial.
Abordamos muitos tópicos importantes neste tutorial do XGBoost, mas ainda há muitas coisas que você precisa aprender.
Você pode conferir a página de parâmetros do XGBoost, que ensina como configurar os parâmetros para extrair o máximo de desempenho dos seus modelos.
Se você estiver procurando um recurso abrangente e completo para aprender a biblioteca, confira nosso curso Extreme Gradient Boosting With XGBoost.
Saiba mais sobre Python e XGBoost
Curso
Curso
Curso
Tutorial
Moez Ali
Tutorial
Abid Ali Awan
Tutorial
DataCamp Team
Tutorial
Avinash Navlani
Tutorial
Joleen Bothma
Tutorial
Kevin Babitz

