Courses
Gradient Boosting Cực Mạnh với XGBoost
4 giờ
61.1K
XGBoost là một trong những framework machine learning phổ biến nhất với các nhà khoa học dữ liệu. Theo Khảo sát State of Data Science 2021 của Kaggle, gần 50% người trả lời cho biết họ sử dụng XGBoost, chỉ xếp sau TensorFlow và Sklearn.
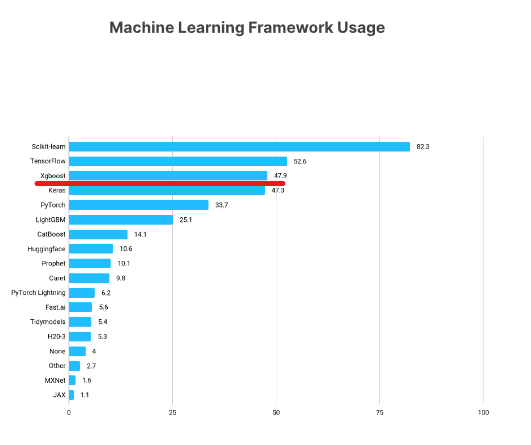
https://www.kaggle.com/kaggle-survey-2021
Hướng dẫn XGBoost này sẽ giới thiệu các khía cạnh chính của framework Python phổ biến này, khám phá cách bạn có thể sử dụng nó cho các dự án machine learning của riêng mình.
Xem và tìm hiểu thêm về cách dùng XGBoost trong Python trong video từ khóa học của chúng tôi.
Xuyên suốt hướng dẫn, chúng ta sẽ đề cập đến các khía cạnh chính của XGBoost, bao gồm:
Hãy bắt đầu thôi!
Chạy và chỉnh sửa mã từ hướng dẫn trực tuyến này.
Chạy mãBạn có thể cài đặt XGBoost như bất kỳ thư viện nào khác qua pip. Cách cài đặt này cũng bao gồm hỗ trợ GPU NVIDIA của máy bạn. Nếu muốn cài bản chỉ dùng CPU, bạn có thể dùng conda-forge:
$ pip install --user xgboost
# CPU only
$ conda install -c conda-forge py-xgboost-cpu
# Use NVIDIA GPU
$ conda install -c conda-forge py-xgboost-gpuKhuyến nghị cài đặt XGBoost trong môi trường ảo để tránh làm lộn xộn môi trường gốc của bạn.
Chúng tôi khuyên bạn nên chạy các ví dụ trong hướng dẫn trên máy có hỗ trợ GPU. Nếu bạn không có, có thể xem các lựa chọn như DataLab hoặc Google Colab.
Nếu bạn chọn dùng Colab, ở đó có sẵn phiên bản XGBoost cũ, vì vậy bạn nên gọi pip install --upgrade xgboost để cài bản mới nhất.
Trong toàn bộ hướng dẫn, chúng ta sẽ làm việc với bộ dữ liệu Diamonds. Nó được tích hợp trong thư viện Seaborn, hoặc bạn cũng có thể tải từ Kaggle. Bộ dữ liệu này có sự kết hợp tốt giữa đặc trưng số và phân loại cùng hơn 50 nghìn quan sát, cho phép chúng ta trình diễn thoải mái mọi ưu điểm của XGBoost.
import seaborn as sns
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings("ignore")
diamonds = sns.load_dataset("diamonds")
diamonds.head()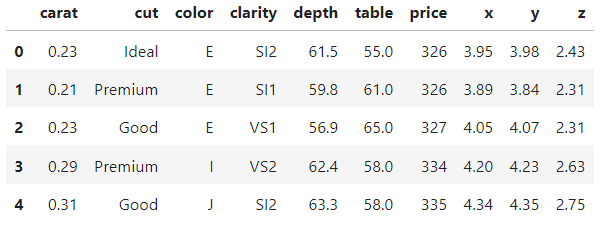
>>> diamonds.shape
(53940, 10)Trong một dự án thực tế điển hình, bạn sẽ muốn dành nhiều thời gian hơn để khám phá bộ dữ liệu và trực quan hóa các đặc trưng. Nhưng vì dữ liệu này được tích hợp sẵn trong Seaborn, nó tương đối sạch.
Vì vậy, chúng ta sẽ chỉ xem tóm tắt 5 số của các đặc trưng số và phân loại rồi bắt tay vào làm. Bạn có thể dành vài phút để làm quen với bộ dữ liệu.
diamonds.describe()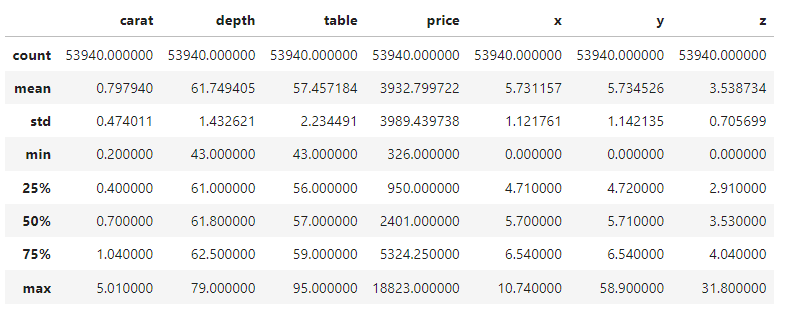
diamonds.describe(exclude=np.number)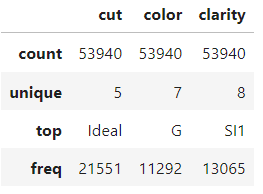
Sau khi khám phá xong, bước đầu tiên trong mọi dự án là xác định bài toán machine learning và trích xuất mảng đặc trưng và đích dựa trên bộ dữ liệu.
Trong hướng dẫn này, trước tiên chúng ta sẽ thử dự đoán giá kim cương dựa trên các kích thước vật lý của chúng, vì vậy biến đích của chúng ta sẽ là cột price.
Như vậy, chúng ta tách đặc trưng vào X và đích vào y:
from sklearn.model_selection import train_test_split
# Extract feature and target arrays
X, y = diamonds.drop('price', axis=1), diamonds[['price']]Bộ dữ liệu có ba cột phân loại. Thông thường, bạn sẽ mã hóa chúng bằng ordinal hoặc one-hot, nhưng XGBoost có khả năng xử lý nội bộ các biến phân loại.
Cách bật tính năng này là ép kiểu các cột phân loại sang kiểu dữ liệu category của Pandas (mặc định chúng được coi là cột văn bản):
# Extract text features
cats = X.select_dtypes(exclude=np.number).columns.tolist()
# Convert to Pandas category
for col in cats:
X[col] = X[col].astype('category')Bây giờ, khi bạn in thuộc tính dtypes, bạn sẽ thấy chúng ta có ba đặc trưng category:
>>> X.dtypes
carat float64
cut category
color category
clarity category
depth float64
table float64
x float64
y float64
z float64
dtype: objectHãy chia dữ liệu thành tập huấn luyện và kiểm tra (kích thước kiểm tra 0,25):
# Split the data
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=1)Bây giờ là phần quan trọng: XGBoost đi kèm lớp riêng để lưu trữ bộ dữ liệu gọi là DMatrix. Đây là một lớp được tối ưu hóa cao cho bộ nhớ và tốc độ. Đó là lý do tại sao chuyển đổi bộ dữ liệu sang định dạng này là yêu cầu đối với API gốc của XGBoost:
import xgboost as xgb
# Create regression matrices
dtrain_reg = xgb.DMatrix(X_train, y_train, enable_categorical=True)
dtest_reg = xgb.DMatrix(X_test, y_test, enable_categorical=True)Lớp này nhận cả đặc trưng huấn luyện và nhãn. Để bật mã hóa tự động các cột category của Pandas, chúng ta cũng đặt enable_categorical thành True.
Lưu ý:
Tại sao chúng ta dùng API gốc của XGBoost thay vì API Scikit-learn? Mặc dù ban đầu dùng API Sklearn có thể thoải mái hơn, sau này bạn sẽ nhận ra API gốc của XGBoost có một số tính năng tuyệt vời mà API kia không hỗ trợ. Vì vậy, tốt hơn là làm quen từ đầu. Tuy nhiên, có một phần ở cuối nơi chúng tôi cho thấy cách chuyển đổi giữa các API chỉ bằng một dòng mã ngay cả sau khi bạn đã huấn luyện mô hình.
Sau khi xây dựng các DMatrix, bạn nên chọn giá trị cho tham số objective. Nó cho XGBoost biết bài toán machine learning bạn đang cố giải quyết và nên dùng những metric hay hàm mất mát nào để giải quyết.
Ví dụ, để dự đoán giá kim cương, vốn là bài toán hồi quy, bạn có thể dùng objective phổ biến reg:squarederror. Thường thì tên của objective cũng bao gồm tên hàm mất mát cho bài toán. Với hồi quy, thường dùng Sai số Bình phương Trung bình Căn (RMSE), tối thiểu hóa căn bậc hai của tổng bình phương chênh lệch giữa giá trị thực và dự đoán. Đây là cách metric trông như khi hiện thực bằng NumPy:
import numpy as np
mse = np.mean((actual - predicted) ** 2)
rmse = np.sqrt(mse)Chúng ta sẽ học các objective phân loại sau trong hướng dẫn.
Một lưu ý về khác biệt giữa hàm mất mát và metric đánh giá: Hàm mất mát được mô hình machine learning dùng để tối thiểu hóa khác biệt giữa giá trị thực (ground truth) và dự đoán của mô hình. Mặt khác, metric được kỹ sư machine learning chọn để đo mức độ giống nhau giữa ground truth và dự đoán của mô hình.
Tóm lại, hàm mất mát cần được tối thiểu hóa trong khi metric cần được tối đa hóa. Hàm mất mát được dùng trong huấn luyện để dẫn dắt mô hình biết cần cải thiện ở đâu. Metric được dùng trong đánh giá để đo hiệu năng tổng thể.
Hàm mục tiêu đã chọn và mọi siêu tham số khác của XGBoost nên được chỉ định trong một dictionary, theo quy ước là params:
# Define hyperparameters
params = {"objective": "reg:squarederror", "tree_method": "gpu_hist"}Bên trong params ban đầu này, chúng ta cũng đặt tree_method là gpu_hist, giúp bật tăng tốc GPU. Nếu bạn không có GPU, có thể bỏ tham số này hoặc đặt thành hist.
Bây giờ, chúng ta đặt tham số khác gọi là num_boost_round, viết tắt của number of boosting rounds (số vòng boosting). Bên trong, XGBoost tối thiểu hóa hàm mất mát RMSE theo các vòng tăng dần nhỏ (sẽ nói thêm sau). Tham số này quy định số lượng các vòng đó.
Số vòng lý tưởng được tìm qua tinh chỉnh siêu tham số. Trước mắt, chúng ta chỉ đặt là 100:
# Define hyperparameters
params = {"objective": "reg:squarederror", "tree_method": "gpu_hist"}
n = 100
model = xgb.train(
params=params,
dtrain=dtrain_reg,
num_boost_round=n,
)Khi XGBoost chạy trên GPU, nó rất nhanh. Nếu bạn không gặp lỗi nào từ đoạn mã trên, việc huấn luyện đã thành công!
Trong các vòng boosting, đối tượng mô hình đã học tất cả các mẫu từ tập huấn luyện có thể học được. Bây giờ, chúng ta phải đo lường hiệu năng bằng cách kiểm tra trên dữ liệu chưa từng thấy. Đó là lúc DMatrix dtest_reg của chúng ta phát huy tác dụng:
from sklearn.metrics import mean_squared_error
preds = model.predict(dtest_reg)Bước này được gọi là đánh giá mô hình (hoặc suy luận). Khi bạn tạo dự đoán với predict, bạn truyền chúng vào hàm mean_squared_error của Sklearn để so sánh với y_test:
rmse = mean_squared_error(y_test, preds, squared=False)
print(f"RMSE of the base model: {rmse:.3f}")
RMSE of the base model: 543.203Chúng ta có điểm cơ sở khoảng ~543$, đây là hiệu năng của mô hình cơ sở với tham số mặc định. Có hai cách để cải thiện — thực hiện cross-validation và tinh chỉnh siêu tham số. Nhưng trước đó, hãy xem một cách đánh giá nhanh hơn cho các mô hình XGBoost.
Huấn luyện mô hình machine learning giống như phóng một tên lửa vào không gian. Bạn có thể kiểm soát mọi thứ về mô hình cho đến lúc phóng, nhưng khi đã phóng rồi, tất cả những gì bạn có thể làm là đứng nhìn và chờ nó hoàn tất.
Vấn đề với quy trình huấn luyện hiện tại là chúng ta thậm chí không thể theo dõi mô hình đang đi đến đâu. Để giải quyết, chúng ta sẽ dùng mảng đánh giá cho phép xem hiệu năng mô hình khi nó được cải thiện dần qua các vòng boosting.
Trước tiên, hãy thiết lập lại tham số:
params = {"objective": "reg:squarederror", "tree_method": "gpu_hist"}
n = 100Tiếp theo, chúng ta tạo một danh sách gồm hai bộ tuple, mỗi tuple chứa hai phần tử. Phần tử đầu là mảng để mô hình đánh giá, phần thứ hai là tên của mảng.
evals = [(dtrain_reg, "train"), (dtest_reg, "validation")]Khi truyền mảng này vào tham số evals của xgb.train, chúng ta sẽ thấy hiệu năng mô hình sau mỗi vòng boosting:
evals = [(dtrain_reg, "train"), (dtest_reg, "validation")]
model = xgb.train(
params=params,
dtrain=dtrain_reg,
num_boost_round=n,
evals=evals,
)Bạn sẽ nhận được kết quả tương tự như bên dưới (rút gọn chỉ còn 10 dòng). Bạn có thể thấy mô hình giảm điểm số từ khoảng ~3931$ xuống chỉ còn 543$.
Điều hay nhất là chúng ta có thể thấy hiệu năng mô hình trên cả tập huấn luyện và tập validation. Thông thường, loss trên tập huấn luyện sẽ thấp hơn validation vì mô hình đã thấy dữ liệu huấn luyện.
[0] train-rmse:3985.18329 validation-rmse:3930.52457
[1] train-rmse:2849.72257 validation-rmse:2813.20828
[2] train-rmse:2059.86648 validation-rmse:2036.66330
[3] train-rmse:1519.32314 validation-rmse:1510.02762
[4] train-rmse:1153.68171 validation-rmse:1153.91223
...
[95] train-rmse:381.93902 validation-rmse:543.56526
[96] train-rmse:380.97024 validation-rmse:543.51413
[97] train-rmse:380.75330 validation-rmse:543.36855
[98] train-rmse:379.65918 validation-rmse:543.42558
[99] train-rmse:378.30590 validation-rmse:543.20278Trong các dự án thực tế, bạn thường huấn luyện hàng nghìn vòng boosting, tức là rất nhiều dòng đầu ra. Để giảm bớt, bạn có thể dùng tham số verbose_eval, buộc XGBoost in cập nhật hiệu năng sau mỗi vebose_eval vòng:
params = {"objective": "reg:squarederror", "tree_method": "gpu_hist"}
n = 100
evals = [(dtest_reg, "validation"), (dtrain_reg, "train")]
model = xgb.train(
params=params,
dtrain=dtrain_reg,
num_boost_round=n,
evals=evals,
verbose_eval=10 # Every ten rounds
)
[OUT]:
[0] train-rmse:3985.18329 validation-rmse:3930.52457
[10] train-rmse:550.08330 validation-rmse:590.15023
[20] train-rmse:488.51248 validation-rmse:551.73431
[30] train-rmse:463.13288 validation-rmse:547.87843
[40] train-rmse:447.69788 validation-rmse:546.57096
[50] train-rmse:432.91655 validation-rmse:546.22557
[60] train-rmse:421.24046 validation-rmse:546.28601
[70] train-rmse:408.64125 validation-rmse:546.78238
[80] train-rmse:396.41125 validation-rmse:544.69846
[90] train-rmse:386.87996 validation-rmse:543.82192
[99] train-rmse:378.30590 validation-rmse:543.20278Đến giờ, hẳn bạn đã nhận ra các vòng boosting quan trọng thế nào. Nói chung, càng nhiều vòng, XGBoost càng cố gắng tối thiểu hóa loss. Nhưng điều đó không có nghĩa là loss sẽ luôn giảm. Hãy thử với 5000 vòng boosting với độ chi tiết 500:
params = {"objective": "reg:squarederror", "tree_method": "gpu_hist"}
n = 5000
evals = [(dtest_reg, "validation"), (dtrain_reg, "train")]
model = xgb.train(
params=params,
dtrain=dtrain_reg,
num_boost_round=n,
evals=evals,
verbose_eval=250
)
[OUT]:
[0] train-rmse:3985.18329 validation-rmse:3930.52457
[500] train-rmse:195.89184 validation-rmse:555.90367
[1000] train-rmse:122.10746 validation-rmse:563.44888
[1500] train-rmse:84.18238 validation-rmse:567.16974
[2000] train-rmse:61.66682 validation-rmse:569.52584
[2500] train-rmse:46.34923 validation-rmse:571.07632
[3000] train-rmse:37.04591 validation-rmse:571.76912
[3500] train-rmse:29.43356 validation-rmse:572.43196
[4000] train-rmse:24.00607 validation-rmse:572.81287
[4500] train-rmse:20.45021 validation-rmse:572.89062
[4999] train-rmse:17.44305 validation-rmse:573.13200
Chúng ta đạt loss thấp nhất trước vòng 500. Sau đó, mặc dù loss huấn luyện tiếp tục giảm, loss validation (cái chúng ta quan tâm) lại tăng.
Khi được cho số vòng boosting quá mức cần thiết, XGBoost bắt đầu overfit và ghi nhớ bộ dữ liệu. Điều này khiến hiệu năng validation giảm vì mô hình đang ghi nhớ thay vì khái quát hóa.
Hãy nhớ, chúng ta muốn điểm cân bằng vàng: một mô hình học vừa đủ các mẫu trong huấn luyện để đạt hiệu năng cao nhất trên tập validation. Vậy làm sao để tìm số vòng boosting “chuẩn”?
Chúng ta sẽ dùng kỹ thuật early stopping. Early stopping buộc XGBoost quan sát loss validation, và nếu nó không cải thiện trong số vòng chỉ định, quá trình huấn luyện sẽ tự động dừng.
Điều này có nghĩa chúng ta có thể đặt số vòng boosting cao miễn là đặt số vòng early stopping hợp lý.
Ví dụ, hãy dùng 10000 vòng boosting và đặt tham số early_stopping_rounds là 50. Cách này khiến XGBoost tự động dừng huấn luyện nếu loss validation không cải thiện trong 50 vòng liên tiếp.
n = 10000
model = xgb.train(
params=params,
dtrain=dtrain_reg,
num_boost_round=n,
evals=evals,
verbose_eval=50,
# Activate early stopping
early_stopping_rounds=50
)
[OUT]:
[0] train-rmse:3985.18329 validation-rmse:3930.52457
[50] train-rmse:432.91655 validation-rmse:546.22557
[100] train-rmse:377.66173 validation-rmse:542.92457
[150] train-rmse:334.27548 validation-rmse:542.79733
[167] train-rmse:321.04059 validation-rmse:543.35679Như bạn thấy, việc huấn luyện dừng sau vòng 167 vì loss đã ngừng cải thiện trong 50 vòng trước đó.
Đầu hướng dẫn, chúng ta đã trích 25% bộ dữ liệu để kiểm thử. Tập kiểm thử cho phép mô phỏng điều kiện mô hình ở môi trường production, nơi nó phải tạo dự đoán cho dữ liệu chưa thấy.
Nhưng chỉ một tập kiểm thử sẽ không đủ để đo chính xác mô hình sẽ hoạt động thế nào trong production. Ví dụ, nếu chúng ta tinh chỉnh siêu tham số chỉ dùng một tập huấn luyện và một tập kiểm thử, kiến thức về tập kiểm thử vẫn sẽ “rò rỉ”. Bằng cách nào?
Vì chúng ta cố tìm giá trị tốt nhất của siêu tham số bằng cách so sánh hiệu năng validation của mô hình trên tập kiểm thử, rốt cuộc chúng ta sẽ có một mô hình được cấu hình để hoạt động tốt chỉ trên tập kiểm thử đó. Thay vào đó, chúng ta muốn một mô hình hoạt động tốt trên diện rộng — trên bất kỳ tập kiểm thử nào được đưa ra.
Một cách khắc phục là chia dữ liệu thành ba tập. Mô hình huấn luyện trên tập thứ nhất, tập thứ hai dùng để đánh giá và tinh chỉnh siêu tham số, và tập thứ ba là tập cuối cùng chúng ta kiểm thử mô hình trước khi đưa vào production.
Nhưng khi dữ liệu hạn chế, chia thành ba tập sẽ làm tập huấn luyện loãng, gây hại hiệu năng mô hình.
Giải pháp cho tất cả các vấn đề này là cross-validation. Trong cross-validation, chúng ta vẫn có hai tập: huấn luyện và kiểm thử.
Trong khi tập kiểm thử “đứng ngoài”, chúng ta chia tập huấn luyện thành 3, 5, 7, hoặc k phần (fold). Sau đó, chúng ta huấn luyện mô hình k lần. Mỗi lần, dùng k-1 phần để huấn luyện và phần thứ k để validation. Quy trình này được gọi là k-fold cross-validation:
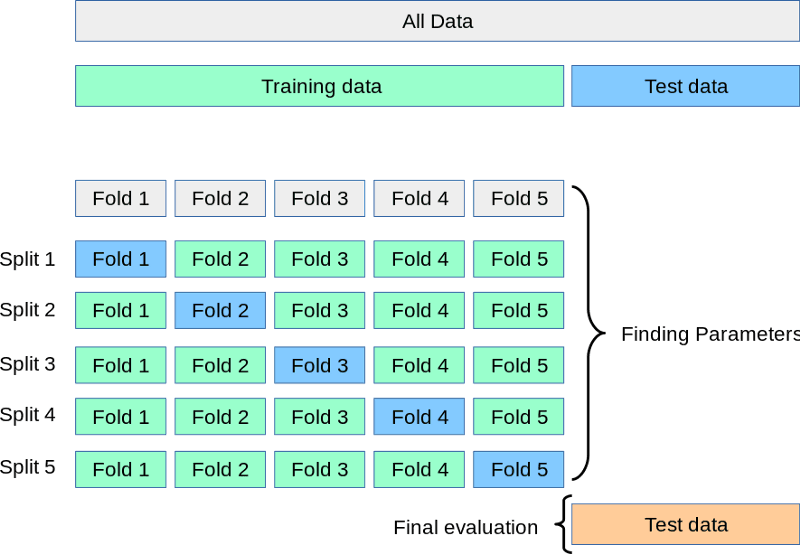
Nguồn: https://scikit-learn.org/stable/modules/cross_validation.html
Trên đây là minh họa trực quan của 5-fold cross-validation. Sau khi hoàn tất tất cả các fold, chúng ta có thể lấy trung bình các điểm số làm hiệu năng cuối cùng, thực tế nhất của mô hình.
Hãy thực hiện quy trình này trong mã bằng hàm cv của XGB:
params = {"objective": "reg:squarederror", "tree_method": "gpu_hist"}
n = 1000
results = xgb.cv(
params, dtrain_reg,
num_boost_round=n,
nfold=5,
early_stopping_rounds=20
)Điểm khác biệt duy nhất với hàm train là thêm tham số nfold để chỉ định số lần chia. Đối tượng results giờ là một DataFrame chứa kết quả của từng fold:
results.head()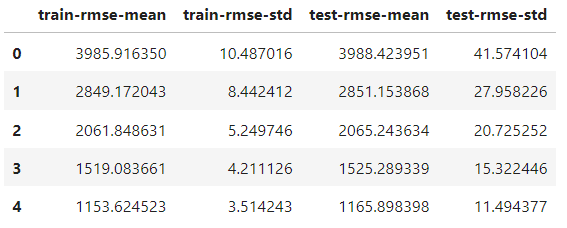
Nó có số dòng bằng số vòng boosting. Mỗi dòng là giá trị trung bình của tất cả các lần chia cho vòng đó. Vì vậy, để tìm điểm tốt nhất, chúng ta lấy giá trị nhỏ nhất của cột test-rmse-mean:
best_rmse = results['test-rmse-mean'].min()
best_rmse
550.8959336674216Lưu ý rằng phương pháp cross-validation này dùng để xem hiệu năng thực sự của mô hình. Khi đã hài lòng với điểm số, bạn phải huấn luyện lại trên toàn bộ dữ liệu trước khi triển khai.
Xây dựng một bộ phân loại XGBoost đơn giản như việc đổi hàm mục tiêu; phần còn lại có thể giữ nguyên.
Hai objective phân loại phổ biến nhất là:
binary:logistic - phân loại nhị phân (biến đích chỉ có hai lớp, ví dụ: mèo hoặc chó)multi:softprob - phân loại đa lớp (nhiều hơn hai lớp trong đích, ví dụ: táo/cam/chuối)Thực hiện phân loại nhị phân và đa lớp trong XGBoost hầu như giống nhau, vì vậy chúng ta sẽ chọn trường hợp sau. Trước tiên, hãy chuẩn bị dữ liệu cho tác vụ.
Chúng ta muốn dự đoán chất lượng cắt (cut) của kim cương dựa trên giá và kích thước vật lý. Vì vậy, chúng ta sẽ xây dựng mảng đặc trưng/đích tương ứng:
from sklearn.preprocessing import OrdinalEncoder
X, y = diamonds.drop("cut", axis=1), diamonds[['cut']]
# Encode y to numeric
y_encoded = OrdinalEncoder().fit_transform(y)
# Extract text features
cats = X.select_dtypes(exclude=np.number).columns.tolist()
# Convert to pd.Categorical
for col in cats:
X[col] = X[col].astype('category')
# Split the data
X_train, X_test, y_train, y_test = train_test_split(X, y_encoded, random_state=1, stratify=y_encoded)Khác biệt duy nhất là vì XGBoost chỉ chấp nhận số ở biến đích, chúng ta mã hóa các lớp văn bản trong đích bằng OrdinalEncoder của Sklearn.
Bây giờ, chúng ta xây dựng các DMatrix…
# Create classification matrices
dtrain_clf = xgb.DMatrix(X_train, y_train, enable_categorical=True)
dtest_clf = xgb.DMatrix(X_test, y_test, enable_categorical=True)…và đặt objective thành multi:softprob. Objective này cũng yêu cầu chúng ta đặt số lượng lớp:
params = {"objective": "multi:softprob", "tree_method": "gpu_hist", "num_class": 5}
n = 1000
results = xgb.cv(
params, dtrain_clf,
num_boost_round=n,
nfold=5,
metrics=["mlogloss", "auc", "merror"],
)Trong cross-validation, chúng ta yêu cầu XGBoost theo dõi ba metric phân loại, báo cáo hiệu năng mô hình từ ba góc độ khác nhau. Kết quả như sau:
results.keys()
Index(['train-mlogloss-mean', 'train-mlogloss-std', 'train-auc-mean',
'train-auc-std', 'train-merror-mean', 'train-merror-std',
'test-mlogloss-mean', 'test-mlogloss-std', 'test-auc-mean',
'test-auc-std', 'test-merror-mean', 'test-merror-std'],
dtype='object')Để xem điểm AUC tốt nhất, chúng ta lấy giá trị lớn nhất của cột test-auc-mean:
>>> results['test-auc-mean'].max()
0.9402233623451636Ngay cả cấu hình mặc định cũng mang lại hiệu năng 94%, thật tuyệt.
Đến giờ, chúng ta đã sử dụng API gốc của XGBoost, nhưng API Sklearn của nó cũng khá phổ biến.
Sklearn là một framework lớn với nhiều thuật toán và tiện ích machine learning và có cú pháp API được hầu như ai cũng yêu thích. Do đó, XGBoost cũng cung cấp các lớp XGBClassifier và XGBRegressor để có thể tích hợp vào hệ sinh thái Sklearn (đổi lại là mất một số chức năng).
Nếu bạn muốn chỉ dùng API Scikit-learn khi có thể và chỉ chuyển sang API gốc khi cần truy cập tính năng bổ sung, có một cách.
Sau khi huấn luyện bộ phân loại hoặc bộ hồi quy XGBoost, bạn có thể chuyển đổi nó bằng phương thức get_booster:
import xgboost as xgb
# Train a model using the scikit-learn API
xgb_classifier = xgb.XGBClassifier(n_estimators=100, objective='binary:logistic', tree_method='hist', eta=0.1, max_depth=3, enable_categorical=True)
xgb_classifier.fit(X_train, y_train)
# Convert the model to a native API model
model = xgb_classifier.get_booster()Đối tượng model sẽ hoạt động y hệt như những gì chúng ta đã thấy trong suốt hướng dẫn này.
Chúng ta đã bao quát nhiều chủ đề quan trọng trong hướng dẫn XGBoost này, nhưng vẫn còn rất nhiều điều để học.
Bạn có thể xem trang tham số của XGBoost, nơi chỉ cho bạn cách cấu hình tham số để khai thác tối đa hiệu năng từ các mô hình.
Nếu bạn đang tìm một tài nguyên toàn diện, tất cả trong một để học thư viện này, hãy xem khóa học Extreme Gradient Boosting With XGBoost của chúng tôi.
Tìm hiểu thêm về Python và XGBoost
Courses
Courses
Courses