Corso
Extreme Gradient Boosting con XGBoost
4 h
61.1K
XGBoost è uno dei framework di machine learning più popolari tra i data scientist. Secondo il State of Data Science Survey 2021 di Kaggle, quasi il 50% degli intervistati ha dichiarato di utilizzare XGBoost, piazzandolo subito sotto TensorFlow e Sklearn.
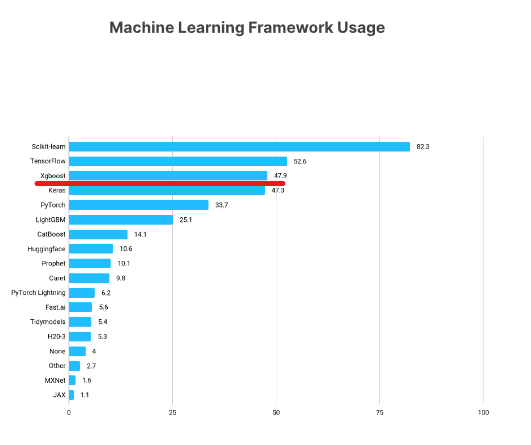
https://www.kaggle.com/kaggle-survey-2021
Questo tutorial su XGBoost ti introdurrà agli aspetti chiave di questo popolare framework Python, mostrando come usarlo nei tuoi progetti di machine learning.
Guarda e scopri di più sull’uso di XGBoost in Python in questo video tratto dal nostro corso.
Nel corso del tutorial, tratteremo gli aspetti fondamentali di XGBoost, tra cui:
Iniziamo!
Esegui e modifica il codice da questo tutorial online
Esegui codicePuoi installare XGBoost come qualsiasi altra libreria tramite pip. Questo metodo di installazione includerà anche il supporto per la GPU NVIDIA della tua macchina. Se vuoi installare la versione solo CPU, puoi usare conda-forge:
$ pip install --user xgboost
# CPU only
$ conda install -c conda-forge py-xgboost-cpu
# Use NVIDIA GPU
$ conda install -c conda-forge py-xgboost-gpuSi consiglia di installare XGBoost in un ambiente virtuale per non inquinare l’ambiente base.
Ti consigliamo di seguire gli esempi del tutorial con una macchina dotata di GPU. Se non ne hai una, puoi valutare alternative come DataLab o Google Colab.
Se decidi di usare Colab, include una versione vecchia di XGBoost, quindi dovresti eseguire pip install --upgrade xgboost per ottenere l’ultima versione.
Nel tutorial useremo il dataset Diamonds. È incluso nella libreria Seaborn oppure, in alternativa, puoi anche scaricarlo da Kaggle. Ha una buona combinazione di feature numeriche e categoriche e oltre 50k osservazioni, che ci permettono di mostrare comodamente tutti i vantaggi di XGBoost.
import seaborn as sns
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings("ignore")
diamonds = sns.load_dataset("diamonds")
diamonds.head()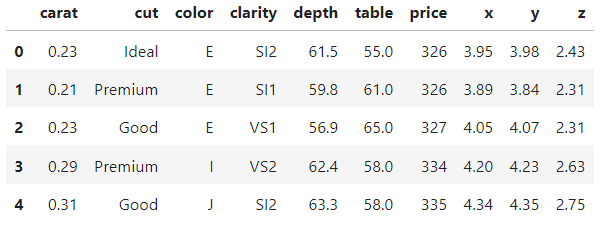
>>> diamonds.shape
(53940, 10)In un tipico progetto reale, vorresti dedicare molto più tempo all’esplorazione del dataset e alla visualizzazione delle sue feature. Ma poiché questi dati sono integrati in Seaborn, sono relativamente puliti.
Quindi ci limiteremo a guardare il riepilogo a 5 numeri delle feature numeriche e categoriche e a procedere. Puoi prenderti qualche istante per familiarizzare con il dataset.
diamonds.describe()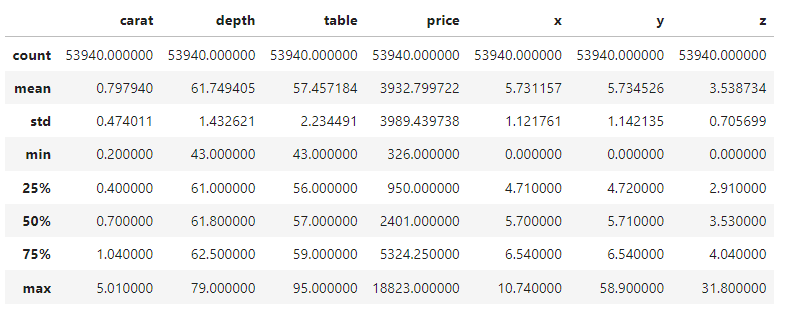
diamonds.describe(exclude=np.number)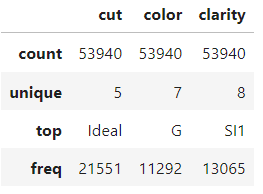
Terminata l’esplorazione, il primo passo in qualsiasi progetto è inquadrare il problema di machine learning ed estrarre gli array di feature e target in base al dataset.
In questo tutorial, proveremo prima a prevedere il prezzo dei diamanti usando le loro misure fisiche, quindi il nostro target sarà la colonna price.
Perciò isoliamo le feature in X e il target in y:
from sklearn.model_selection import train_test_split
# Extract feature and target arrays
X, y = diamonds.drop('price', axis=1), diamonds[['price']]Il dataset ha tre colonne categoriche. Normalmente le codificheresti con encoding ordinale o one-hot, ma XGBoost ha la capacità di gestire internamente le categoriche.
Per abilitare questa funzione, bisogna convertire le colonne categoriche nel tipo di dato category di Pandas (per impostazione predefinita sono trattate come colonne di testo):
# Extract text features
cats = X.select_dtypes(exclude=np.number).columns.tolist()
# Convert to Pandas category
for col in cats:
X[col] = X[col].astype('category')Ora, se stampi l’attributo dtypes, vedrai che abbiamo tre feature di tipo category:
>>> X.dtypes
carat float64
cut category
color category
clarity category
depth float64
table float64
x float64
y float64
z float64
dtype: objectDividiamo i dati in train e test set (dimensione test 0,25):
# Split the data
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=1)Ora, la parte importante: XGBoost fornisce una propria classe per memorizzare i dataset chiamata DMatrix. È una classe altamente ottimizzata per memoria e velocità. Per questo la conversione dei dataset in questo formato è un requisito per l’API nativa di XGBoost:
import xgboost as xgb
# Create regression matrices
dtrain_reg = xgb.DMatrix(X_train, y_train, enable_categorical=True)
dtest_reg = xgb.DMatrix(X_test, y_test, enable_categorical=True)La classe accetta sia le feature di training sia le etichette. Per abilitare l’encoding automatico delle colonne category di Pandas, impostiamo anche enable_categorical su True.
Nota:
Perché usare l’API nativa di XGBoost invece della sua API Scikit-learn? Anche se all’inizio può essere più comoda l’API Sklearn, più avanti ti accorgerai che l’API nativa di XGBoost contiene ottime funzionalità non supportate dalla prima. Quindi è meglio farci l’abitudine fin dall’inizio. C’è comunque una sezione finale in cui mostriamo come passare tra le API con una sola riga di codice anche dopo aver addestrato i modelli.
Dopo aver costruito le DMatrix, dovresti scegliere un valore per il parametro objective. Indica a XGBoost il problema di machine learning che stai cercando di risolvere e quali metriche o funzioni di loss usare per farlo.
Per esempio, per prevedere i prezzi dei diamanti, che è un problema di regressione, puoi usare l’obiettivo comune reg:squarederror. Di solito il nome dell’obiettivo include anche il nome della funzione di loss per il problema. Per la regressione è comune usare la Root Mean Squared Error, che minimizza la radice quadrata della somma dei quadrati delle differenze tra valori reali e previsti. Ecco come apparirebbe la metrica implementata in NumPy:
import numpy as np
mse = np.mean((actual - predicted) ** 2)
rmse = np.sqrt(mse)Più avanti nel tutorial impareremo gli obiettivi per la classificazione.
Una nota sulla differenza tra funzione di loss e metrica di performance: una funzione di loss è usata dai modelli di machine learning per minimizzare le differenze tra i valori reali (ground truth) e le predizioni del modello. Dall’altro lato, una metrica (o più metriche) è scelta dall’ingegnere di machine learning per misurare la somiglianza tra ground truth e predizioni del modello.
In breve, una funzione di loss va minimizzata mentre una metrica va massimizzata. Una funzione di loss viene usata durante il training per guidare il modello su dove migliorare. Una metrica è usata durante la valutazione per misurare la performance complessiva.
La funzione obiettivo scelta e qualsiasi altro iperparametro di XGBoost vanno specificati in un dizionario, che per convenzione chiamiamo params:
# Define hyperparameters
params = {"objective": "reg:squarederror", "tree_method": "gpu_hist"}All’interno di questo params iniziale impostiamo anche tree_method su gpu_hist, che abilita l’accelerazione GPU. Se non hai una GPU, puoi omettere il parametro o impostarlo su hist.
Ora impostiamo un altro parametro chiamato num_boost_round, che sta per numero di round di boosting. Internamente, XGBoost minimizza la loss RMSE in piccoli round incrementali (ne parleremo più avanti). Questo parametro specifica quanti siano tali round.
Il numero ideale di round si trova tramite tuning degli iperparametri. Per ora lo impostiamo a 100:
# Define hyperparameters
params = {"objective": "reg:squarederror", "tree_method": "gpu_hist"}
n = 100
model = xgb.train(
params=params,
dtrain=dtrain_reg,
num_boost_round=n,
)Quando XGBoost gira su GPU, è velocissimo. Se non hai ricevuto errori dal codice qui sopra, l’addestramento è andato a buon fine!
Durante i round di boosting, l’oggetto modello ha imparato tutti i pattern del training set che poteva. Ora dobbiamo misurarne la performance testandolo su dati mai visti. È qui che entra in gioco la nostra DMatrix dtest_reg:
from sklearn.metrics import mean_squared_error
preds = model.predict(dtest_reg)Questa fase è chiamata valutazione del modello (o inferenza). Una volta generate le predizioni con predict, le passi alla funzione mean_squared_error di Sklearn per confrontarle con y_test:
rmse = mean_squared_error(y_test, preds, squared=False)
print(f"RMSE of the base model: {rmse:.3f}")
RMSE of the base model: 543.203Abbiamo ottenuto un punteggio base di circa 543$, che è la performance di un modello base con parametri di default. Ci sono due modi per migliorarlo: effettuare cross-validation e tuning degli iperparametri. Ma prima, vediamo un modo più rapido per valutare i modelli XGBoost.
Addestrare un modello di machine learning è come lanciare un razzo nello spazio. Puoi controllare tutto del modello fino al lancio, ma una volta partito, non puoi far altro che aspettare che finisca.
Il problema con il nostro processo di training attuale è che non possiamo nemmeno osservare dove sta andando il modello. Per risolverlo, useremo degli array di valutazione che ci permettono di vedere la performance del modello mentre migliora in modo incrementale nei round di boosting.
Per prima cosa, reimpostiamo i parametri:
params = {"objective": "reg:squarederror", "tree_method": "gpu_hist"}
n = 100Poi creiamo una lista di due tuple che contengono due elementi ciascuna. Il primo elemento è l’array su cui il modello deve valutare, il secondo è il nome dell’array.
evals = [(dtrain_reg, "train"), (dtest_reg, "validation")]Quando passiamo questo array al parametro evals di xgb.train, vedremo la performance del modello dopo ogni round di boosting:
evals = [(dtrain_reg, "train"), (dtest_reg, "validation")]
model = xgb.train(
params=params,
dtrain=dtrain_reg,
num_boost_round=n,
evals=evals,
)Dovresti ottenere un output simile a quello sotto (qui accorciato a 10 righe). Puoi vedere come il modello minimizza il punteggio da ~3931$ fino a 543$.
La cosa migliore è che possiamo vedere la performance del modello sia sul training set sia sul validation set. Di solito la loss di training è più bassa di quella di validazione perché il modello ha già visto i primi.
[0] train-rmse:3985.18329 validation-rmse:3930.52457
[1] train-rmse:2849.72257 validation-rmse:2813.20828
[2] train-rmse:2059.86648 validation-rmse:2036.66330
[3] train-rmse:1519.32314 validation-rmse:1510.02762
[4] train-rmse:1153.68171 validation-rmse:1153.91223
...
[95] train-rmse:381.93902 validation-rmse:543.56526
[96] train-rmse:380.97024 validation-rmse:543.51413
[97] train-rmse:380.75330 validation-rmse:543.36855
[98] train-rmse:379.65918 validation-rmse:543.42558
[99] train-rmse:378.30590 validation-rmse:543.20278Nei progetti reali, di solito si addestra per migliaia di round di boosting, il che significa molte righe di output. Per ridurle, puoi usare il parametro verbose_eval, che forza XGBoost a stampare gli aggiornamenti delle performance ogni vebose_eval round:
params = {"objective": "reg:squarederror", "tree_method": "gpu_hist"}
n = 100
evals = [(dtest_reg, "validation"), (dtrain_reg, "train")]
model = xgb.train(
params=params,
dtrain=dtrain_reg,
num_boost_round=n,
evals=evals,
verbose_eval=10 # Every ten rounds
)
[OUT]:
[0] train-rmse:3985.18329 validation-rmse:3930.52457
[10] train-rmse:550.08330 validation-rmse:590.15023
[20] train-rmse:488.51248 validation-rmse:551.73431
[30] train-rmse:463.13288 validation-rmse:547.87843
[40] train-rmse:447.69788 validation-rmse:546.57096
[50] train-rmse:432.91655 validation-rmse:546.22557
[60] train-rmse:421.24046 validation-rmse:546.28601
[70] train-rmse:408.64125 validation-rmse:546.78238
[80] train-rmse:396.41125 validation-rmse:544.69846
[90] train-rmse:386.87996 validation-rmse:543.82192
[99] train-rmse:378.30590 validation-rmse:543.20278A questo punto avrai capito quanto siano importanti i round di boosting. In generale, più round ci sono, più XGBoost cerca di minimizzare la loss. Ma ciò non significa che la loss scenderà sempre. Proviamo con 5000 round di boosting con una verbosità di 500:
params = {"objective": "reg:squarederror", "tree_method": "gpu_hist"}
n = 5000
evals = [(dtest_reg, "validation"), (dtrain_reg, "train")]
model = xgb.train(
params=params,
dtrain=dtrain_reg,
num_boost_round=n,
evals=evals,
verbose_eval=250
)
[OUT]:
[0] train-rmse:3985.18329 validation-rmse:3930.52457
[500] train-rmse:195.89184 validation-rmse:555.90367
[1000] train-rmse:122.10746 validation-rmse:563.44888
[1500] train-rmse:84.18238 validation-rmse:567.16974
[2000] train-rmse:61.66682 validation-rmse:569.52584
[2500] train-rmse:46.34923 validation-rmse:571.07632
[3000] train-rmse:37.04591 validation-rmse:571.76912
[3500] train-rmse:29.43356 validation-rmse:572.43196
[4000] train-rmse:24.00607 validation-rmse:572.81287
[4500] train-rmse:20.45021 validation-rmse:572.89062
[4999] train-rmse:17.44305 validation-rmse:573.13200
Otteniamo la loss più bassa prima del round 500. Dopo, anche se la loss di training continua a scendere, quella di validazione (quella che ci interessa) continua ad aumentare.
Quando viene dato un numero di round di boosting eccessivo, XGBoost inizia a overfittare e a memorizzare il dataset. Questo porta a un calo della performance in validazione perché il modello memorizza invece di generalizzare.
Ricorda, vogliamo la via di mezzo: un modello che abbia imparato abbastanza pattern in training da fornire la massima performance sul validation set. Come troviamo allora il numero perfetto di round di boosting?
Useremo una tecnica chiamata early stopping. L’early stopping forza XGBoost a tenere d’occhio la loss di validazione e, se smette di migliorare per un numero specificato di round, interrompe automaticamente il training.
Questo significa che possiamo impostare anche un numero alto di round di boosting purché fissiamo un numero sensato di round di early stopping.
Per esempio, usiamo 10000 round di boosting e impostiamo il parametro early_stopping_rounds a 50. In questo modo, XGBoost interromperà automaticamente il training se la loss di validazione non migliora per 50 round consecutivi.
n = 10000
model = xgb.train(
params=params,
dtrain=dtrain_reg,
num_boost_round=n,
evals=evals,
verbose_eval=50,
# Activate early stopping
early_stopping_rounds=50
)
[OUT]:
[0] train-rmse:3985.18329 validation-rmse:3930.52457
[50] train-rmse:432.91655 validation-rmse:546.22557
[100] train-rmse:377.66173 validation-rmse:542.92457
[150] train-rmse:334.27548 validation-rmse:542.79733
[167] train-rmse:321.04059 validation-rmse:543.35679Come vedi, l’addestramento si è fermato dopo il 167° round perché la loss aveva smesso di migliorare per 50 round prima.
All’inizio del tutorial, abbiamo messo da parte il 25% del dataset per il test. Il test set ci consente di simulare le condizioni di un modello in produzione, dove deve generare predizioni su dati mai visti.
Ma un solo test set non basta per misurare accuratamente come si comporterebbe un modello in produzione. Per esempio, se facciamo tuning degli iperparametri usando un solo training e un solo test set, alcune informazioni sul test set “trapeleranno”. Come?
Poiché cerchiamo i migliori valori degli iperparametri confrontando la performance di validazione del modello sul test set, finiremo con un modello configurato per andare bene solo su quel particolare test set. Invece vogliamo un modello che vada bene in generale — su qualunque test set gli sottoponiamo.
Un possibile workaround è dividere i dati in tre set. Il modello si addestra sul primo set, il secondo viene usato per valutazione e tuning degli iperparametri, e il terzo è quello finale su cui testiamo il modello prima della produzione.
Ma quando i dati sono limitati, dividere in tre set rende il training set scarno, il che danneggia la performance del modello.
La soluzione a tutti questi problemi è la cross-validation. Nella cross-validation abbiamo comunque due set: training e test.
Mentre il test set resta da parte, dividiamo il training in 3, 5, 7 o k split o fold. Poi addestriamo il modello k volte. Ogni volta usiamo k-1 parti per il training e la k-esima parte per la validazione. Questo processo è chiamato k-fold cross-validation:
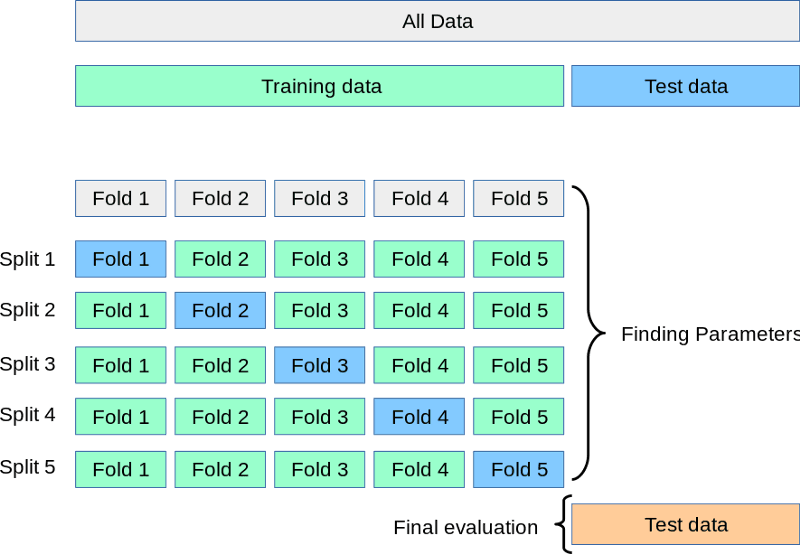
Fonte: https://scikit-learn.org/stable/modules/cross_validation.html
Sopra c’è una rappresentazione visiva di una cross-validation a 5 fold. Dopo tutti i fold, possiamo fare la media dei punteggi come performance finale e più realistica del modello.
Eseguiamo questo processo in codice usando la funzione cv di XGB:
params = {"objective": "reg:squarederror", "tree_method": "gpu_hist"}
n = 1000
results = xgb.cv(
params, dtrain_reg,
num_boost_round=n,
nfold=5,
early_stopping_rounds=20
)L’unica differenza rispetto alla funzione train è l’aggiunta del parametro nfold per specificare il numero di split. L’oggetto results è ora un DataFrame che contiene i risultati di ciascun fold:
results.head()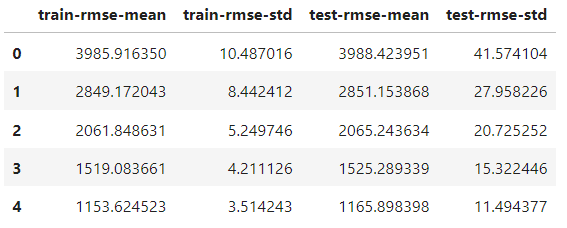
Ha lo stesso numero di righe dei round di boosting. Ogni riga è la media di tutti gli split per quel round. Quindi, per trovare il punteggio migliore, prendiamo il minimo della colonna test-rmse-mean:
best_rmse = results['test-rmse-mean'].min()
best_rmse
550.8959336674216Nota che questo metodo di cross-validation serve per vedere la vera performance del modello. Una volta soddisfatto del punteggio, devi riaddestrarlo su tutti i dati prima del deploy.
Costruire un classificatore XGBoost è semplice quanto cambiare la funzione obiettivo; il resto può rimanere uguale.
Le due funzioni obiettivo per classificazione più popolari sono:
binary:logistic - classificazione binaria (il target contiene solo due classi, ad es. gatto o cane)multi:softprob - classificazione multi-classe (più di due classi nel target, ad es. mela/arancia/banana)Eseguire classificazione binaria e multi-classe in XGBoost è quasi identico, quindi useremo la seconda. Prepariamo prima i dati per il task.
Vogliamo prevedere la qualità del taglio dei diamanti dato il loro prezzo e le loro misure fisiche. Quindi costruiremo gli array di feature/target di conseguenza:
from sklearn.preprocessing import OrdinalEncoder
X, y = diamonds.drop("cut", axis=1), diamonds[['cut']]
# Encode y to numeric
y_encoded = OrdinalEncoder().fit_transform(y)
# Extract text features
cats = X.select_dtypes(exclude=np.number).columns.tolist()
# Convert to pd.Categorical
for col in cats:
X[col] = X[col].astype('category')
# Split the data
X_train, X_test, y_train, y_test = train_test_split(X, y_encoded, random_state=1, stratify=y_encoded)L’unica differenza è che, poiché XGBoost accetta solo numeri nel target, codifichiamo le classi testuali nel target con OrdinalEncoder di Sklearn.
Ora costruiamo le DMatrix…
# Create classification matrices
dtrain_clf = xgb.DMatrix(X_train, y_train, enable_categorical=True)
dtest_clf = xgb.DMatrix(X_test, y_test, enable_categorical=True)…e impostiamo l’obiettivo su multi:softprob. Questo obiettivo richiede anche che impostiamo il numero di classi:
params = {"objective": "multi:softprob", "tree_method": "gpu_hist", "num_class": 5}
n = 1000
results = xgb.cv(
params, dtrain_clf,
num_boost_round=n,
nfold=5,
metrics=["mlogloss", "auc", "merror"],
)Durante la cross-validation, chiediamo a XGBoost di monitorare tre metriche di classificazione che riportano la performance del modello da tre angolazioni diverse. Ecco il risultato:
results.keys()
Index(['train-mlogloss-mean', 'train-mlogloss-std', 'train-auc-mean',
'train-auc-std', 'train-merror-mean', 'train-merror-std',
'test-mlogloss-mean', 'test-mlogloss-std', 'test-auc-mean',
'test-auc-std', 'test-merror-mean', 'test-merror-std'],
dtype='object')Per vedere il miglior punteggio AUC, prendiamo il massimo della colonna test-auc-mean:
>>> results['test-auc-mean'].max()
0.9402233623451636Anche la configurazione di default ci ha dato una performance del 94%, ottimo.
Finora abbiamo usato l’API nativa di XGBoost, ma anche la sua API Sklearn è piuttosto popolare.
Sklearn è un framework vasto con molti algoritmi e utility di machine learning e ha una sintassi API amata quasi da tutti. Perciò XGBoost offre anche le classi XGBClassifier e XGBRegressor, così da integrarsi nell’ecosistema Sklearn (con la perdita di alcune funzionalità).
Se vuoi usare l’API Scikit-learn quando possibile e passare a quella nativa solo quando ti serve l’accesso a funzionalità extra, c’è un modo.
Dopo aver addestrato il classificatore o il regressore XGBoost, puoi convertirlo usando il metodo get_booster:
import xgboost as xgb
# Train a model using the scikit-learn API
xgb_classifier = xgb.XGBClassifier(n_estimators=100, objective='binary:logistic', tree_method='hist', eta=0.1, max_depth=3, enable_categorical=True)
xgb_classifier.fit(X_train, y_train)
# Convert the model to a native API model
model = xgb_classifier.get_booster()L’oggetto modello si comporterà esattamente come abbiamo visto in tutto il tutorial.
Abbiamo coperto molti argomenti importanti in questo tutorial su XGBoost, ma c’è ancora tanto da imparare.
Puoi consultare la pagina dei parametri di XGBoost, che spiega come configurare i parametri per spremere fino all’ultimo punto di performance dai tuoi modelli.
Se cerchi una risorsa completa e all-in-one per imparare la libreria, dai un’occhiata al nostro corso Extreme Gradient Boosting With XGBoost.
Scopri di più su Python e XGBoost
Corso
Corso
Corso
blog
Abid Ali Awan
10 min
blog
Tim Lu
12 min
blog
Abid Ali Awan
15 min

