courses
MLOps 개념
2
42.6K
머신러닝 모델은 과거 데이터로 학습되지만, 실제 환경에서 사용되면 드리프트라는 현상으로 시간이 지나며 구식이 되어 정확도가 떨어질 수 있습니다. 드리프트는 머신러닝 모델을 학습시킨 데이터의 통계적 특성이 시간에 따라 변하는 것을 의미합니다. 이로 인해 모델이 덜 정확해지거나 설계 의도와 다르게 동작할 수 있습니다.
즉, "드리프트"는 모델이 사용되는 환경의 변화로 인해 정확한 예측을 할 수 있는 능력이 감소하는 현상입니다.
머신러닝 모델이 시간이 지남에 따라 드리프트하는 데에는 여러 이유가 있습니다.
가장 흔한 이유는 모델이 학습한 데이터가 시대에 뒤처지거나 현재 조건을 더 이상 대표하지 못하게 되는 경우입니다.
예를 들어, 과거 데이터를 기반으로 기업의 주가를 예측하도록 학습된 모델을 생각해 보세요. 안정적인 시장의 데이터로 학습했다면 처음에는 잘 작동할 수 있습니다. 그러나 시간이 지나 시장이 더 변동성이 커지면 데이터의 통계적 특성이 바뀌기 때문에 모델이 더 이상 주가를 정확히 예측하지 못할 수 있습니다.
또 다른 이유는 모델이 데이터의 변화를 처리하도록 설계되지 않았기 때문입니다. 일부 머신러닝 모델은 다른 모델보다 데이터 변화에 더 강인하지만, 어떤 모델도 드리프트를 완전히 피할 수는 없습니다.
고려해야 할 두 가지 드리프트 유형을 살펴보겠습니다.
컨셉 드리프트(모델 드리프트라고도 함)는 모델이 수행하도록 설계된 작업이 시간이 지나며 변할 때 발생합니다. 예를 들어, 이메일 내용에 기반해 스팸 메일을 탐지하도록 학습된 모델이 있다고 합시다. 사람들이 받는 스팸 메일의 유형이 크게 바뀌면 모델은 더 이상 스팸을 정확히 탐지하지 못할 수 있습니다.
컨셉 드리프트는 네 가지 범주로 더 나눌 수 있습니다(Concept Drift 하에서의 학습: 리뷰, Jie Lu 외):
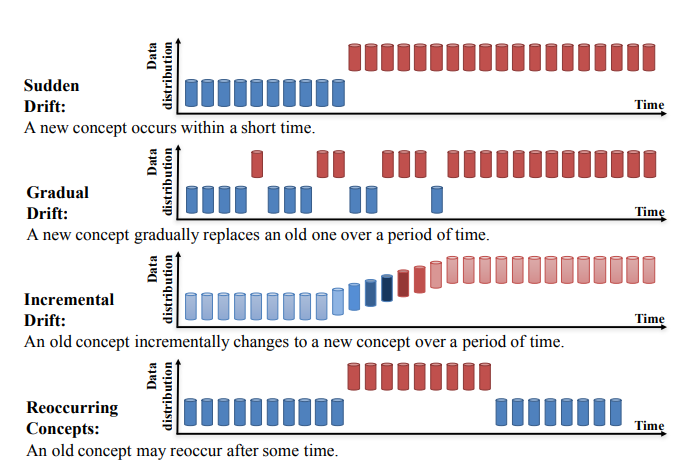
출처: https://arxiv.org/pdf/2004.05785.pdf
데이터 드리프트(공변량 이동이라고도 함)는 입력 데이터의 분포가 시간이 지나며 바뀌는 경우 발생합니다. 예를 들어, 고객의 나이와 소득을 바탕으로 구매 가능성을 예측하도록 학습된 모델이 있다고 합시다. 시간이 지나 고객의 나이와 소득 분포가 크게 변하면 모델은 더 이상 구매 가능성을 정확히 예측하지 못할 수 있습니다.
컨셉 드리프트와 데이터 드리프트 모두를 인지하고, 이를 방지하거나 영향을 완화하기 위한 조치를 취하는 것이 중요합니다. 모델의 성능을 지속적으로 모니터링하고 평가하기, 새로운 데이터로 모델을 업데이트하기, 드리프트에 더 강인한 머신러닝 모델 사용하기 등이 이에 해당합니다.
드리프트와 같은 배포 이후 데이터 사이언스에 대해서는 DataFramed 팟캐스트 에피소드에서 더 알아보실 수 있습니다.
LLM은 위의 방법들이 설계되지 않은 새로운 유형의 드리프트를 가져옵니다. 데이터는 테이블의 행이 아니라 자유 형식의 텍스트이며, 시간이 지나며 변하는 것은 대개 사용자가 묻는 내용의 의미입니다. 현재는 모니터링해야 할 LLM 드리프트가 세 가지 형태로 알려져 있습니다.
임베딩 드리프트는 사용자가 모델에 보내는 텍스트의 의미가 달라졌지만, 표면적인 텍스트는 비슷해 보일 때 발생합니다. LLM은 텍스트를 임베딩이라 부르는 긴 숫자 목록으로 변환하며, 드리프트는 일반적으로 측정하던 지표에는 드러나지 않고 이 숫자들에서 나타날 수 있습니다.
예를 들어, 고객지원 챗봇이 처음에는 주로 설정 및 온보딩 질문을 처리했다고 합시다. 6개월 후 메시지 수와 평균 길이는 변하지 않았지만, 이제 사용자는 주로 청구와 해지에 대해 묻습니다. 텍스트 통계는 안정적으로 보이지만, 임베딩 분포는 이동했습니다. 이를 감지하려면 팀은 최근 임베딩 배치를 기준 배치와 비교하여 통계적 거리 측정치를 사용합니다.
프롬프트 드리프트는 임베딩 드리프트와 같은 아이디어이지만 한 단계 위에서 추적합니다. 원시 임베딩을 비교하는 대신, 들어오는 질의를 분류기나 또 다른 LLM을 사용해 카테고리로 묶고, 구성 비율의 변화를 관찰합니다.
예를 들어, 백엔드 엔지니어를 위해 출시된 내부 코딩 어시스턴트가 점차 데이터 과학자들의 pandas 관련 질문을 받기 시작할 수 있습니다. 어시스턴트가 여전히 능숙히 답하더라도, 이제 서비스 대상 집단은 테스트 당시와 달라졌고, 시스템 프롬프트나 검색 인덱스가 시간이 지나며 더 이상 최적이 아닐 수 있습니다.
루브릭 드리프트는 자동 평가자가 모델 출력에 부여하는 품질 점수가 시간에 따라 변하는 현상입니다. 현재 많은 운영 팀이 LLM을 심판으로 사용해 각 응답을 유용성, 정확성, 톤 등으로 채점합니다. 동일한 유형의 입력에서 이러한 점수가 하향 추세를 보이기 시작하면, 보통 무언가가 바뀐 것입니다 — API 뒤의 모델, 검색되는 문서, 혹은 사용자 구성 등.
루브릭 드리프트의 특히 유용한 점은 생성형 출력에 대해 실시간으로 이용 가능한 정답 라벨이 거의 없는 상황에서도 품질 신호를 제공한다는 것입니다.
드리프트를 감지하는 방법은 두 가지입니다.
1. 머신러닝 모델 기반 접근: 유입되는 입력 데이터에 드리프트가 발생했는지 모델을 통해 감지하는 방법.
2. 통계적 검정: 데이터 드리프트를 감지하는 통계적 검정이 많이 있습니다. 크게 세 가지 범주로 나눌 수 있습니다.
시간 분포 기반 방법은 두 확률분포 간의 차이를 계산하는 통계적 기법을 사용해 드리프트를 감지합니다. 여기에는 Population Stability Index, KL Divergence, JS Divergence, KS Test, Wasserstein Metric 등이 포함됩니다.
Kolmogorov-Smirnov (K-S) 검정은 두 데이터 집합이 동일한 분포에서 나왔는지 판단하는 비모수 통계 검정입니다. 특정 표본이 어떤 모집단에서 왔는지 검정하거나, 두 표본이 같은 모집단에서 왔는지 비교할 때 자주 사용됩니다.
이 검정의 귀무가설은 두 분포가 동일하다는 것입니다. 이 가설이 기각되면 모델에 드리프트가 있음을 시사합니다.
K-S 검정은 데이터셋을 비교하고 동일한 분포에서 왔는지 판단하는 유용한 도구입니다.
Population Stability Index(PSI)는 두 개의 서로 다른 데이터셋에서 범주형 변수의 분포를 비교하는 통계적 지표입니다.
PSI는 두 표본 간 또는 시간 경과에 따라 변수의 분포가 얼마나 변했는지를 측정하는 도구입니다. 인구 특성의 변화를 모니터링하고 머신러닝 모델 성능의 잠재적 문제를 식별하는 데 일반적으로 사용됩니다.
PSI는 원래 리스크 스코어카드에서 점수 분포의 변화를 모니터링하기 위해 개발되었지만, 현재는 종속변수와 독립변수를 포함한 모든 모델 관련 속성의 분포 이동을 확인하는 데 사용됩니다.
PSI 값이 높다는 것은 두 데이터셋에서 해당 변수의 분포가 크게 다르다는 의미이며, 이는 모델에 드리프트가 있음을 시사할 수 있습니다.
변수의 분포가 크게 변했거나 여러 변수가 어느 정도 변화했다면, 성능 개선을 위해 모델을 재보정하거나 재구축해야 할 수 있습니다.
Page-Hinkley 방법은 시간에 따라 데이터 시리즈의 평균 변화(변화점)를 감지하는 통계적 방법입니다. 머신러닝 모델의 성능을 모니터링하고 모델 드리프트를 시사할 수 있는 데이터 분포 변화를 감지하는 데 일반적으로 사용됩니다.
Page-Hinkley 방법을 사용하려면 먼저 임계값과 의사결정 함수를 정의합니다. 임계값은 평균 변화가 유의미하다고 간주되는 기준이며, 의사결정 함수는 변화가 감지되면 1, 감지되지 않으면 0을 반환합니다.
그다음 각 시점에서 데이터 시리즈의 평균을 계산하고, 변화가 발생했는지 판단하기 위해 의사결정 함수를 적용합니다. 의사결정 함수가 1을 반환하면 변화가 감지되었음을 의미하며, 모델이 드리프트하고 있을 수 있습니다.
Page-Hinkley 방법은 시간에 따른 평균 변화를 감지하는 간단하고 효과적인 방법입니다. 눈으로는 즉시 드러나지 않는 작은 평균 변화 감지에 특히 유용합니다. 다만, 데이터의 변화를 민감하게 감지하되 오경보를 줄일 수 있도록 임계값과 의사결정 함수를 신중히 선택하는 것이 중요합니다.
이 섹션에서는 Evidently를 사용해 드리프트를 감지합니다. Evidently는 머신러닝을 다루는 데이터 사이언티스트와 엔지니어를 위해 만들어진 오픈 소스 Python 라이브러리로, 검증부터 운영까지 모델의 성능을 테스트, 평가, 추적하는 데 도움을 줍니다.
import pandas as pd
import numpy as np
from sklearn import datasets
from evidently import Report
from evidently.presets import DataDriftPreset# create ref and cur dataset for drift detection
adult_data = datasets.fetch_openml(name='adult', version=2, as_frame=True)
adult = adult_data.frame
adult_ref = adult[~adult.education.isin(['Some-college', 'HS-grad', 'Bachelors'])].copy()
adult_cur = adult[adult.education.isin(['Some-college', 'HS-grad', 'Bachelors'])].copy()
adult_cur.iloc[:2000, 3:5] = np.nan#dataset-level metrics
report = Report([DataDriftPreset()], include_tests=True)
my_eval = report.run(current_data=adult_cur, reference_data=adult_ref)
my_eval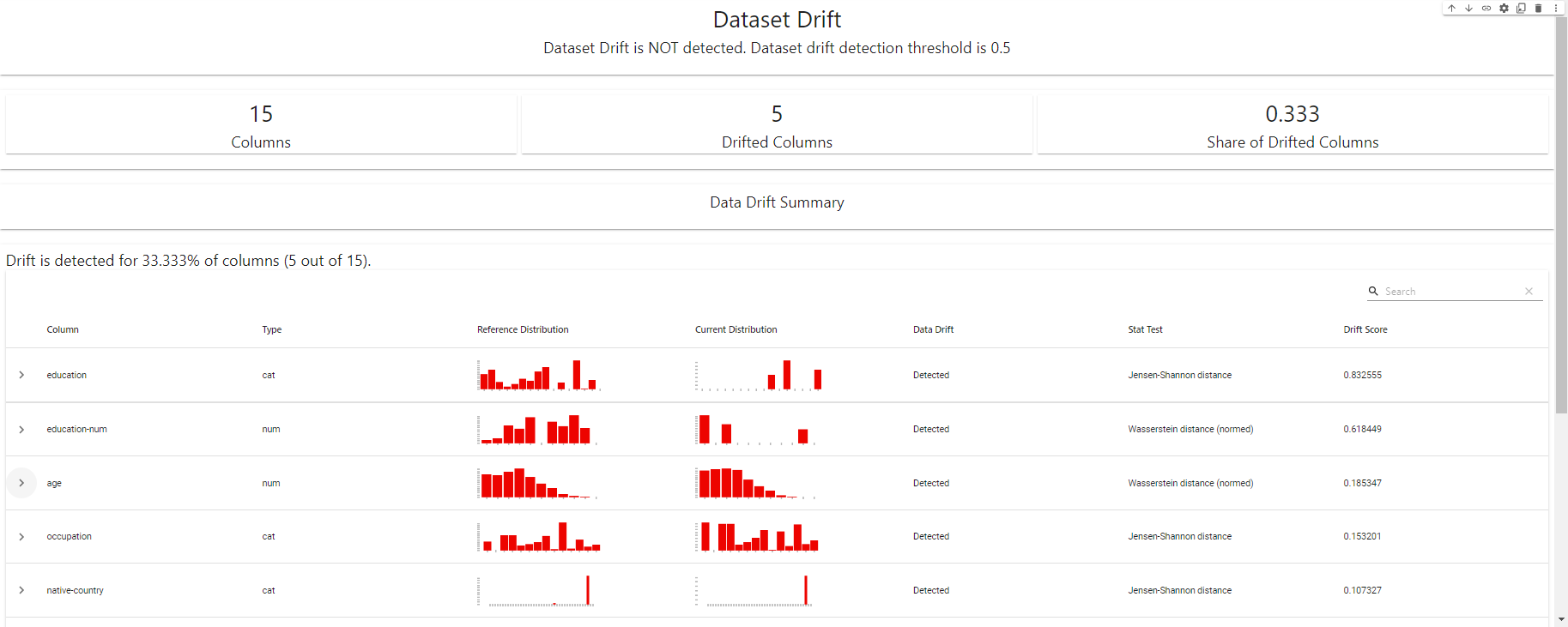
EvidentlyAI로 생성한 드리프트 감지 대시보드
#report in a JSON format
my_eval.json()
전체 Datacamp 노트북은 여기에서 확인하세요.
데이터 및 모델 드리프트는 운영 환경의 머신러닝 시스템에 상당한 도전 과제가 될 수 있습니다. 드리프트의 원인과 영향을 이해하고 효과적인 모니터링 실천을 구현하면, 머신러닝 모델이 시간이 지나도 정확하고 신뢰할 수 있도록 유지할 수 있습니다.
모델 성능 모니터링, 드리프트 감지 모델 활용, 최신 데이터로의 정기적 재학습은 드리프트 위험을 완화하기 위한 몇 가지 모범 사례입니다. 드리프트 모니터링에 선제적으로 대응하면 머신러닝 시스템이 조직에 지속적인 가치를 제공하도록 보장할 수 있습니다.
머신러닝 모델의 드리프트 모니터링은 MLOps라는 더 넓은 분야의 한 부분에 불과합니다. MLOps 개념을 이해하는 것은 데이터 사이언티스트, 엔지니어, 리더가 로컬 노트북의 모델을 운영 환경의 실제 모델로 전환하는 데 필수적입니다.
경력에 도움이 되는 MLOps를 깊이 있게 이해하고 싶다면 MLOps Concepts 과정을 확인하세요. 여기서 MLOps가 무엇인지, MLOps 프로세스의 다양한 단계, 그리고 MLOps 성숙도의 여러 수준을 배우게 됩니다. 핵심 MLOps 개념을 학습한 후에는 머신러닝을 지속적이고 신뢰성 있으며 효율적으로 구현하는 여정을 시작할 준비가 될 것입니다.
MLOps 강의
courses
courses
courses