
Cours
Concepts MLOps
2 h
42.6K
Les modèles de machine learning sont entraînés sur des données historiques, mais une fois déployés dans le monde réel, ils peuvent devenir obsolètes et perdre en précision avec le temps : c’est le phénomène de dérive. La dérive correspond à l’évolution, au fil du temps, des propriétés statistiques des données ayant servi à entraîner un modèle. Elle peut rendre le modèle moins précis ou le faire se comporter différemment de ce qui était prévu.
En d’autres termes, la « dérive » est la baisse de la capacité d’un modèle à produire des prédictions justes en raison de changements dans l’environnement dans lequel il est utilisé.
Plusieurs raisons expliquent la dérive des modèles au fil du temps.
La plus courante tient simplement au fait que les données d’entraînement deviennent obsolètes ou ne reflètent plus les conditions actuelles.
Par exemple, prenons un modèle entraîné à prédire le cours d’une action à partir de données historiques. S’il a été entraîné sur une période de marché stable, il peut bien fonctionner au départ. Mais si le marché devient plus volatil avec le temps, le modèle risque de ne plus prédire correctement le cours, car les propriétés statistiques des données ont changé.
Autre cause : le modèle n’a pas été conçu pour gérer les évolutions des données. Certains modèles gèrent mieux ces changements que d’autres, mais aucun n’est totalement immunisé contre la dérive.
Examinons deux types de dérive à prendre en compte :
La dérive de concept, aussi appelée dérive du modèle, survient lorsque la tâche pour laquelle le modèle a été conçu évolue. Par exemple, un modèle entraîné à détecter les spams à partir du contenu des e-mails peut perdre en efficacité si les types de spams reçus changent significativement.
La dérive de concept peut être subdivisée en quatre catégories (Learning under Concept Drift: A Review, Jie Lu et al.) :
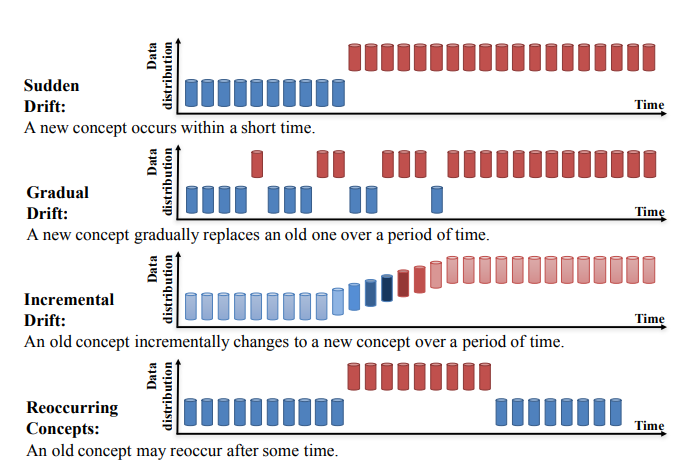
Source : https://arxiv.org/pdf/2004.05785.pdf
La dérive des données, aussi appelée covariate shift, se produit lorsque la distribution des données d’entrée évolue. Par exemple, pour un modèle prédisant la probabilité d’achat d’un client en fonction de son âge et de son revenu, une modification notable de la distribution des âges et des revenus au fil du temps peut dégrader la précision des prédictions.
Il est essentiel d’être attentif à la dérive de concept comme à la dérive des données, et de mettre en place des actions préventives ou correctives. Parmi les stratégies possibles : surveiller et évaluer en continu les performances, actualiser le modèle avec de nouvelles données, et privilégier des approches plus robustes à la dérive.
Pour en savoir plus sur la data science post-déploiement, notamment la dérive, écoutez notre épisode du podcast DataFramed.
Les LLM introduisent une forme de dérive pour laquelle les méthodes ci-dessus n’ont pas été pensées. Les données ne sont pas des lignes dans un tableau : c’est du texte libre, et ce qui évolue généralement, c’est le sens des requêtes des utilisateurs. On distingue aujourd’hui trois formes de dérive des LLM à surveiller.
La dérive des embeddings survient quand le sens du texte envoyé au modèle change, même si le texte en surface paraît similaire. Les LLM convertissent le texte en longues listes de nombres, appelées embeddings ; la dérive peut apparaître dans ces nombres sans se voir dans les indicateurs habituels.
Imaginez un chatbot support client d’abord consacré aux questions d’installation et d’onboarding. Six mois plus tard, le volume et la longueur moyenne des messages sont inchangés, mais les utilisateurs posent surtout des questions de facturation et de résiliation. Les statistiques textuelles semblent stables, mais la distribution des embeddings a dérivé. Pour le détecter, on compare des lots d’embeddings récents à un lot de référence via une mesure de distance statistique.
C’est la même idée que la dérive des embeddings, observée un cran plus haut. Plutôt que de comparer les embeddings bruts, on regroupe les requêtes entrantes par catégories — à l’aide d’un classificateur ou d’un autre LLM — et on surveille l’évolution du mix.
Par exemple, un assistant de code interne lancé pour des ingénieurs back-end peut progressivement capter des demandes de data scientists sur pandas. L’assistant répond encore correctement, mais la population servie n’est plus celle du périmètre de test, et le system prompt ou l’index de retrieval peut, avec le temps, devenir moins pertinent.
La rubric drift désigne une évolution dans le temps des scores de qualité attribués par un évaluateur automatique aux sorties du modèle. De nombreuses équipes de production utilisent désormais un LLM comme juge, notant chaque réponse sur l’utilité, la précision ou le ton. Quand ces scores baissent pour des entrées similaires, quelque chose a changé — le modèle derrière l’API, les documents récupérés, ou le mix d’utilisateurs.
L’intérêt majeur de la rubric drift est de fournir un signal qualité sans vérité terrain immédiate, rarement disponible en temps réel pour des sorties génératives.
Deux approches permettent de détecter la dérive :
1. Approche basée sur un modèle de machine learning : utiliser un modèle pour déterminer si les nouvelles données d’entrée ont dérivé.
2. Tests statistiques : de nombreux tests existent pour détecter la dérive des données. Ils se répartissent principalement en trois catégories :
Les méthodes fondées sur la comparaison de distributions utilisent des techniques statistiques pour mesurer l’écart entre deux distributions de probabilité afin de détecter la dérive. Parmi elles : le Population Stability Index, la divergence de Kullback-Leibler (KL), la divergence de Jensen-Shannon (JS), le test de Kolmogorov-Smirnov (KS) et la métrique de Wasserstein.
Le test de Kolmogorov-Smirnov (K-S) est un test statistique non paramétrique permettant de déterminer si deux jeux de données proviennent de la même distribution. On l’utilise souvent pour vérifier si un échantillon suit une distribution donnée, ou pour comparer deux échantillons et évaluer s’ils appartiennent à la même population.
L’hypothèse nulle du test stipule que les distributions sont identiques. Si elle est rejetée, cela suggère une dérive dans le modèle.
Le test K-S est un outil utile pour comparer des jeux de données et déterminer s’ils partagent la même distribution.
Le Population Stability Index (PSI) est une mesure statistique utilisée pour comparer la distribution d’une variable (souvent catégorielle, mais pas uniquement) entre deux jeux de données.
Le PSI sert à quantifier à quel point la distribution d’une variable a changé entre deux échantillons ou au cours du temps. Il est couramment employé pour surveiller l’évolution des caractéristiques d’une population et identifier d’éventuels problèmes de performance d’un modèle de machine learning.
Initialement conçu pour suivre l’évolution d’un score dans des scorecards de risque, le PSI est désormais utilisé pour analyser les décalages de distribution de tous les attributs liés aux modèles, variables dépendantes comme indépendantes.
Une valeur de PSI élevée indique une différence significative entre les distributions de la variable dans les deux jeux de données, pouvant signaler une dérive du modèle.
Si la distribution d’une variable a fortement changé, ou si plusieurs variables ont évolué, il peut être nécessaire de recalibrer ou de reconstruire le modèle pour restaurer ses performances.
La méthode de Page-Hinkley est une technique statistique utilisée pour détecter les changements de moyenne d’une série temporelle. Elle sert couramment à surveiller les performances des modèles de machine learning et à repérer des évolutions de distribution pouvant indiquer une dérive.
Pour l’utiliser, on définit d’abord une valeur seuil et une fonction de décision. Le seuil détermine à partir de quand un changement de moyenne est jugé significatif, et la fonction de décision renvoie 1 si un changement est détecté, 0 sinon.
Ensuite, on calcule la moyenne à chaque pas de temps et on applique la fonction de décision pour déterminer s’il y a eu changement. Si la fonction renvoie 1, un changement est détecté et le modèle peut être en dérive.
La méthode de Page-Hinkley est simple et efficace pour repérer des variations de moyenne, notamment de faibles changements qui ne sautent pas aux yeux. Il est toutefois crucial de bien choisir le seuil et la fonction de décision pour concilier sensibilité et limitation des fausses alertes.
Dans cette section, nous allons utiliser Evidently pour détecter la dérive. Evidently est une bibliothèque Python open source destinée aux data scientists et ingénieurs ML. Elle facilite les tests, l’évaluation et le suivi des performances des modèles, de la validation à la production.
import pandas as pd
import numpy as np
from sklearn import datasets
from evidently import Report
from evidently.presets import DataDriftPreset# create ref and cur dataset for drift detection
adult_data = datasets.fetch_openml(name='adult', version=2, as_frame=True)
adult = adult_data.frame
adult_ref = adult[~adult.education.isin(['Some-college', 'HS-grad', 'Bachelors'])].copy()
adult_cur = adult[adult.education.isin(['Some-college', 'HS-grad', 'Bachelors'])].copy()
adult_cur.iloc[:2000, 3:5] = np.nan#dataset-level metrics
report = Report([DataDriftPreset()], include_tests=True)
my_eval = report.run(current_data=adult_cur, reference_data=adult_ref)
my_eval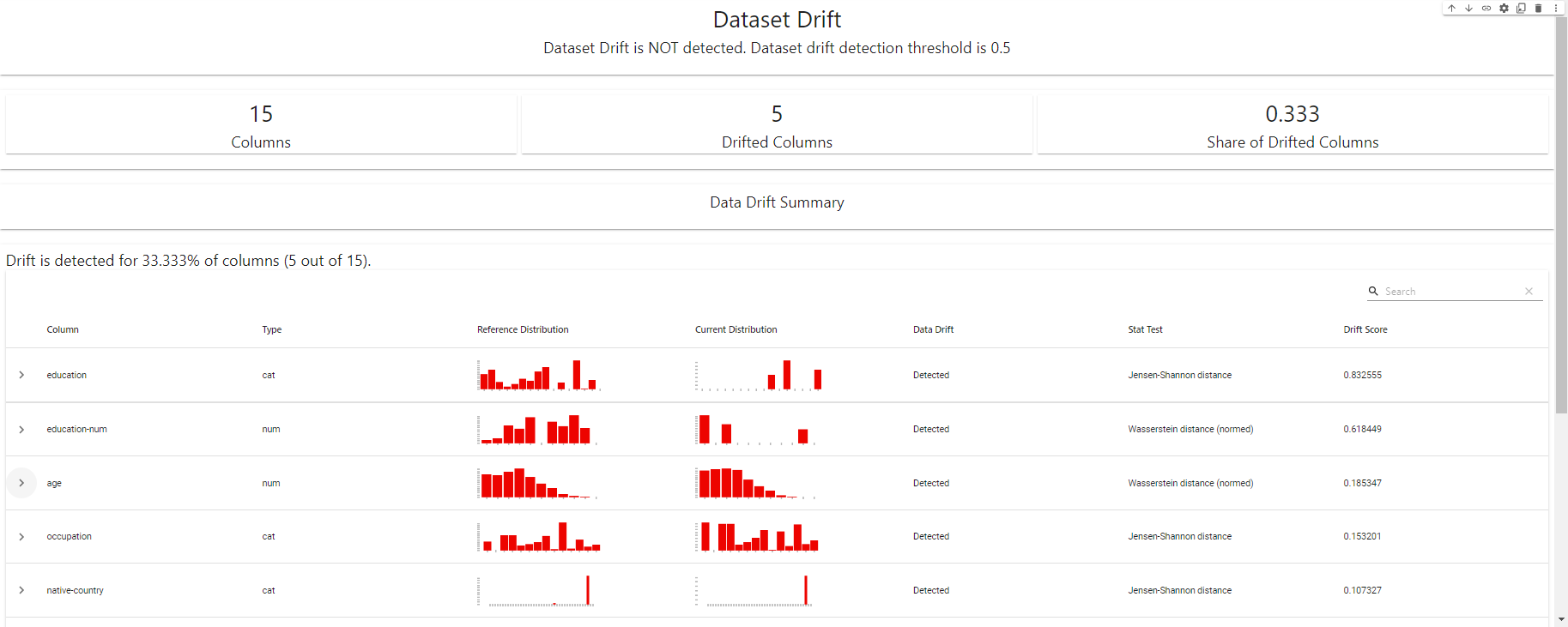
Tableau de bord de détection de dérive - créé avec EvidentlyAI
#report in a JSON format
my_eval.json()
Consultez le Notebook Datacamp complet ici.
La dérive des données et des modèles peut sérieusement mettre à mal les systèmes de machine learning en production. En comprenant ses causes et ses effets, et en mettant en place une surveillance efficace, vous pouvez maintenir des modèles précis et fiables dans la durée.
Surveiller les performances, utiliser un modèle de détection de dérive et réentraîner régulièrement sur des données mises à jour font partie des bonnes pratiques pour limiter les risques. En adoptant une démarche proactive, vous garantissez que votre système de machine learning continue de créer de la valeur pour votre organisation.
La surveillance de la dérive n’est qu’un volet d’un domaine plus large : le MLOps. Maîtriser les concepts MLOps est essentiel pour tout data scientist, ingénieur ou décideur souhaitant faire passer des modèles d’un notebook local à une mise en production opérationnelle.
Pour approfondir le MLOps et en tirer parti dans votre carrière, découvrez notre cours MLOps Concepts. Vous y verrez ce qu’est le MLOps, les différentes phases des processus MLOps et les niveaux de maturité. Une fois ces fondamentaux acquis, vous serez prêt à déployer le machine learning de façon continue, fiable et efficace.
Cours MLOps
Cours
Cours
Cours
Tutoriel
Sejal Jaiswal
Tutoriel
Moez Ali
Tutoriel
Satyabrata Pal
Tutoriel
Laiba Siddiqui
Tutoriel
Aditya Sharma
Tutoriel
Matt Crabtree
