course
MLOps Concepts
2 घंटा
42.7K
मशीन लर्निंग मॉडल ऐतिहासिक डेटा पर प्रशिक्षित किए जाते हैं, लेकिन वास्तविक दुनिया में उपयोग होने पर वे समय के साथ पुराने पड़ सकते हैं और उनकी सटीकता घट सकती है—इसे ही ड्रिफ्ट कहते हैं। ड्रिफ्ट उस डेटा के सांख्यिकीय गुणों में समय के साथ होने वाला परिवर्तन है, जिस पर मॉडल को प्रशिक्षित किया गया था। इससे मॉडल कम सटीक हो सकता है या अपेक्षित तरीके से अलग प्रदर्शन कर सकता है।
दूसरे शब्दों में, "ड्रिफ्ट" वह गिरावट है जो उस परिवेश में बदलाव के कारण होती है जिसमें मॉडल का उपयोग किया जा रहा है, और इससे उसकी सही भविष्यवाणी करने की क्षमता घटती है।
कई कारणों से मशीन लर्निंग मॉडल समय के साथ ड्रिफ्ट कर सकते हैं।
एक सामान्य कारण यह है कि जिस डेटा पर मॉडल को प्रशिक्षित किया गया था, वह पुराना हो जाता है या अब वर्तमान परिस्थितियों का प्रतिनिधित्व नहीं करता।
उदाहरण के लिए, किसी कंपनी के स्टॉक प्राइस की भविष्यवाणी के लिए ऐतिहासिक डेटा पर प्रशिक्षित मॉडल प्रारंभ में ठीक काम कर सकता है। लेकिन यदि समय के साथ बाजार अधिक अस्थिर हो जाए, तो डेटा के सांख्यिकीय गुण बदल जाने के कारण मॉडल अब सही अनुमान नहीं लगा पाएगा।
ड्रिफ्ट का एक और कारण यह है कि मॉडल डेटा में होने वाले बदलावों को संभालने के लिए डिजाइन नहीं किया गया था। कुछ मॉडल ऐसे बदलावों के प्रति अधिक सक्षम होते हैं, लेकिन कोई भी मॉडल ड्रिफ्ट से पूरी तरह बच नहीं सकता।
आइए ड्रिफ्ट के दो अलग-अलग प्रकारों को समझें:
कॉन्सेप्ट ड्रिफ्ट, जिसे मॉडल ड्रिफ्ट भी कहा जाता है, तब होता है जब समय के साथ वह कार्य बदल जाता है जिसके लिए मॉडल को डिजाइन किया गया था। उदाहरण के लिए, यदि स्पैम ईमेल का पता लगाने के लिए किसी मॉडल को ईमेल की सामग्री के आधार पर प्रशिक्षित किया गया है, तो समय के साथ स्पैम ईमेल के प्रकार बदल जाने पर मॉडल स्पैम को सटीकता से पहचान नहीं पाएगा।
कॉन्सेप्ट ड्रिफ्ट को आगे चार श्रेणियों में बाँटा जा सकता है (Learning under Concept Drift: A Review, Jie Lu et al.):
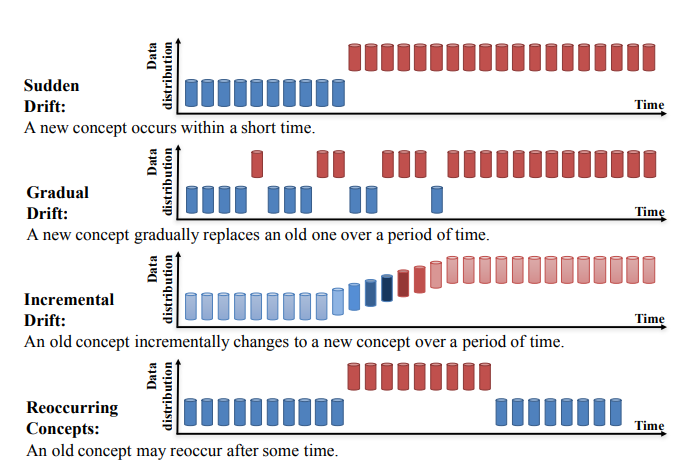
Source: https://arxiv.org/pdf/2004.05785.pdf
डेटा ड्रिफ्ट, जिसे कोवेरिएट शिफ्ट भी कहा जाता है, तब होता है जब इनपुट डेटा का वितरण समय के साथ बदल जाता है। उदाहरण के लिए, आयु और आय के आधार पर किसी ग्राहक के उत्पाद खरीदने की संभावना का अनुमान लगाने के लिए प्रशिक्षित मॉडल, यदि समय के साथ ग्राहकों की आयु और आय का वितरण काफी बदल जाए, तो सटीक भविष्यवाणी नहीं कर पाएगा।
कॉन्सेप्ट ड्रिफ्ट और डेटा ड्रिफ्ट—दोनों से अवगत रहना और उनके प्रभाव को रोकने या कम करने के उपाय करना महत्वपूर्ण है। कुछ रणनीतियों में मॉडल के प्रदर्शन की निरंतर निगरानी और मूल्यांकन, नए डेटा के साथ मॉडल को अपडेट करना, और ऐसे मॉडल्स चुनना शामिल हैं जो ड्रिफ्ट के प्रति अधिक सक्षम हों।
आप हमारे DataFramed पॉडकास्ट एपिसोड में पोस्ट-डिप्लॉयमेंट डेटा साइंस जैसे ड्रिफ्ट के बारे में और जान सकते हैं।
LLMs एक ऐसी ड्रिफ्ट पेश करते हैं जिसके लिए ऊपर बताई गई विधियाँ बनी नहीं थीं। यहाँ डेटा टेबल की पंक्तियाँ नहीं, बल्कि मुक्त-रूप पाठ होता है—और समय के साथ जो बदलता है, वह अक्सर यह होता है कि उपयोगकर्ता क्या पूछ रहे हैं उसका अर्थ। अब माना जाता है कि LLM ड्रिफ्ट की निगरानी के तीन रूप हैं।
एम्बेडिंग ड्रिफ्ट तब होती है जब उपयोगकर्ताओं के भेजे गए पाठ का अर्थ बदल जाता है, भले ही सतही पाठ एक जैसा दिखे। LLMs पाठ को संख्याओं की लंबी सूचियों—एम्बेडिंग्स—में बदलते हैं, और ड्रिफ्ट उन संख्याओं में दिख सकती है, बिना उन सामान्य आँकड़ों में दिखे जिन्हें आप सामान्यतः मापते हैं।
कल्पना करें कि एक कस्टमर सपोर्ट चैटबॉट शुरुआत में सेटअप और ऑनबोर्डिंग से जुड़े प्रश्नों को अधिकतर संभाल रहा था। छह माह बाद संदेशों की संख्या और औसत लंबाई समान रहती है, लेकिन अब उपयोगकर्ता ज्यादातर बिलिंग और कैंसलेशन पर पूछ रहे हैं। टेक्स्ट के आँकड़े स्थिर दिखते हैं, पर एम्बेडिंग वितरण बदल गया है। इसे पहचानने के लिए टीमें हालिया एम्बेडिंग बैचों को किसी संदर्भ बैच से किसी सांख्यिक दूरी माप से तुलना करती हैं।
प्रॉम्प्ट ड्रिफ्ट का विचार एम्बेडिंग ड्रिफ्ट जैसा ही है, बस एक स्तर ऊपर ट्रैक किया जाता है। कच्ची एम्बेडिंग्स की तुलना करने के बजाय, आप आने वाली क्वेरीज़ को वर्गों में बाँटते हैं—किसी क्लासिफायर या किसी अन्य LLM का उपयोग करके—और मिश्रण में होने वाले बदलावों पर नज़र रखते हैं।
मान लें कि बैकएंड इंजीनियरों के लिए शुरू किया गया एक आंतरिक कोडिंग असिस्टेंट धीरे-धीरे डेटा साइंटिस्ट्स से pandas संबंधित प्रश्न लेने लगता है। असिस्टेंट शायद सक्षम उत्तर देता रहे, लेकिन जिन उपयोगकर्ताओं की वह सेवा कर रहा है, वे अब वे नहीं हैं जिन पर इसे टेस्ट किया गया था, और सिस्टम प्रॉम्प्ट या रिट्रीवल इंडेक्स समय के साथ उपयुक्त न रह जाए।
रूब्रिक ड्रिफ्ट वह परिवर्तन है जो समय के साथ किसी स्वचालित मूल्यांकनकर्ता द्वारा मॉडल के आउटपुट्स को दिए जाने वाले गुणवत्ता स्कोर में आता है। कई प्रोडक्शन टीमें अब एक LLM को जज के रूप में इस्तेमाल करती हैं, जो प्रत्येक उत्तर को उपयोगिता, सटीकता या टोन जैसे पहलुओं पर स्कोर करती हैं। जब समान प्रकार के इनपुट्स के लिए ये स्कोर नीचे जाने लगते हैं, तो आमतौर पर कुछ बदल गया होता है—किसी API के पीछे का मॉडल, रिट्रीव की जा रही डॉक्युमेंट्स, या उपयोगकर्ता मिश्रण।
रूब्रिक ड्रिफ्ट खास उपयोगी इसलिए है क्योंकि यह ग्राउंड ट्रुथ लेबल्स के बिना गुणवत्ता संकेत देता है, जो जेनरेटिव आउटपुट्स के लिए वास्तविक समय में शायद ही उपलब्ध होते हैं।
ड्रिफ्ट का पता लगाने के दो तरीके हैं:
1. मशीन लर्निंग मॉडल-आधारित दृष्टिकोण: मॉडल-आधारित तरीका यह पहचानने के लिए कि आने वाला इनपुट डेटा ड्रिफ्ट हुआ है या नहीं।
2. सांख्यिकीय परीक्षण: डेटा ड्रिफ्ट का पता लगाने के लिए कई सांख्यिकीय परीक्षण होते हैं। इन्हें मुख्यतः तीन श्रेणियों में बाँटा जाता है:
टाइम-डिस्ट्रिब्यूशन आधारित विधियाँ ड्रिफ्ट पहचानने के लिए दो प्रायिकता वितरणों के बीच अंतर को मापने हेतु सांख्यिकीय तरीकों का उपयोग करती हैं। इनमें Population Stability Index, KL Divergence, JS Divergence, KS Test, और Wasserstein Metric शामिल हैं।
Kolmogorov-Smirnov (K-S) टेस्ट एक नॉन-पैरामेट्रिक सांख्यिकीय परीक्षण है, जिसका उपयोग यह निर्धारित करने के लिए किया जाता है कि क्या दो डेटा सेट एक ही वितरण से आते हैं। यह अक्सर यह जाँचने के लिए उपयोग होता है कि कोई सैंपल किसी विशिष्ट आबादी से आता है या नहीं, या दो सैंपल्स की तुलना करने के लिए कि वे एक ही आबादी से हैं या नहीं।
इस परीक्षण में शून्य परिकल्पना यह होती है कि वितरण समान हैं। यदि यह परिकल्पना अस्वीकृत होती है, तो यह मॉडल में ड्रिफ्ट का संकेत देती है।
K-S टेस्ट डेटासेट्स की तुलना करने और यह निर्धारित करने के लिए एक उपयोगी उपकरण है कि वे एक ही वितरण से आते हैं या नहीं।
Population Stability Index (PSI) एक सांख्यिकीय माप है जिसका उपयोग दो अलग-अलग डेटासेट्स में किसी वर्गीकृत चर के वितरण की तुलना करने के लिए किया जाता है।
Population Stability Index (PSI) का उपयोग यह मापने के लिए किया जाता है कि दो सैंपल्स के बीच या समय के साथ किसी चर के वितरण में कितना परिवर्तन हुआ है। इसे आमतौर पर किसी आबादी की विशेषताओं में बदलाव की निगरानी करने और मशीन लर्निंग मॉडल के प्रदर्शन में संभावित समस्याओं की पहचान करने के लिए उपयोग किया जाता है।
PSI मूल रूप से जोखिम स्कोरकार्ड्स में स्कोर के वितरण में होने वाले बदलावों की निगरानी के लिए विकसित किया गया था, लेकिन अब इसे मॉडल-संबंधित सभी विशेषताओं—निर्भर और स्वतंत्र चर—में वितरणीय बदलावों की जाँच के लिए उपयोग किया जाता है।
उच्च PSI मान यह संकेत देता है कि दोनों डेटासेट्स में उस चर के वितरण में महत्वपूर्ण अंतर है, जो मॉडल में ड्रिफ्ट का सुझाव दे सकता है।
यदि किसी चर का वितरण काफी बदल गया है, या कई चर कुछ हद तक बदल गए हैं, तो मॉडल के प्रदर्शन में सुधार के लिए उसे पुन:कैलिब्रेट या फिर से बनाना आवश्यक हो सकता है।
Page-Hinkley विधि एक सांख्यिकीय तरीका है जो समय के साथ किसी डेटा श्रेणी के औसत में होने वाले बदलावों का पता लगाने के लिए उपयोग होता है। इसे आमतौर पर मशीन लर्निंग मॉडल्स के प्रदर्शन की निगरानी और डेटा वितरण में होने वाले उन परिवर्तनों का पता लगाने के लिए उपयोग किया जाता है जो मॉडल ड्रिफ्ट का संकेत दे सकते हैं।
Page-Hinkley विधि उपयोग करने के लिए, पहले एक थ्रेशहोल्ड मान और एक निर्णय फ़ंक्शन परिभाषित किया जाता है। थ्रेशहोल्ड वह मान है जिसके ऊपर औसत में बदलाव को महत्वपूर्ण माना जाता है, और निर्णय फ़ंक्शन वह फ़ंक्शन है जो बदलाव पाए जाने पर 1 और बदलाव न पाए जाने पर 0 लौटाता है।
इसके बाद, प्रत्येक समय चरण पर डेटा श्रेणी का औसत निकाला जाता है, और यह जाँचने के लिए निर्णय फ़ंक्शन लागू किया जाता है कि क्या कोई बदलाव हुआ है। यदि निर्णय फ़ंक्शन 1 लौटाता है, तो यह संकेत होता है कि बदलाव का पता चल गया है और मॉडल ड्रिफ्ट कर सकता है।
Page-Hinkley विधि समय के साथ किसी डेटा श्रेणी के औसत में होने वाले बदलावों का पता लगाने का एक सरल और प्रभावी तरीका है। यह विशेष रूप से छोटे बदलावों का पता लगाने में उपयोगी है जो डेटा को देखकर तुरंत स्पष्ट नहीं होते। हालाँकि, थ्रेशहोल्ड मान और निर्णय फ़ंक्शन का सावधानीपूर्वक चयन करना महत्वपूर्ण है ताकि विधि परिवर्तन के प्रति पर्याप्त संवेदनशील रहे, लेकिन इतनी नहीं कि झूठे अलार्म उत्पन्न करे।
इस सेक्शन में, हम ड्रिफ्ट का पता लगाने के लिए Evidently का उपयोग करेंगे। Evidently डेटा वैज्ञानिकों और इंजीनियरों के लिए बनाया गया एक ओपन-सोर्स Python लाइब्रेरी है, जो उन्हें वैलिडेशन से लेकर प्रोडक्शन तक अपने मॉडलों का परीक्षण, मूल्यांकन और ट्रैक करने में मदद करती है।
import pandas as pd
import numpy as np
from sklearn import datasets
from evidently import Report
from evidently.presets import DataDriftPreset# create ref and cur dataset for drift detection
adult_data = datasets.fetch_openml(name='adult', version=2, as_frame=True)
adult = adult_data.frame
adult_ref = adult[~adult.education.isin(['Some-college', 'HS-grad', 'Bachelors'])].copy()
adult_cur = adult[adult.education.isin(['Some-college', 'HS-grad', 'Bachelors'])].copy()
adult_cur.iloc[:2000, 3:5] = np.nan#dataset-level metrics
report = Report([DataDriftPreset()], include_tests=True)
my_eval = report.run(current_data=adult_cur, reference_data=adult_ref)
my_eval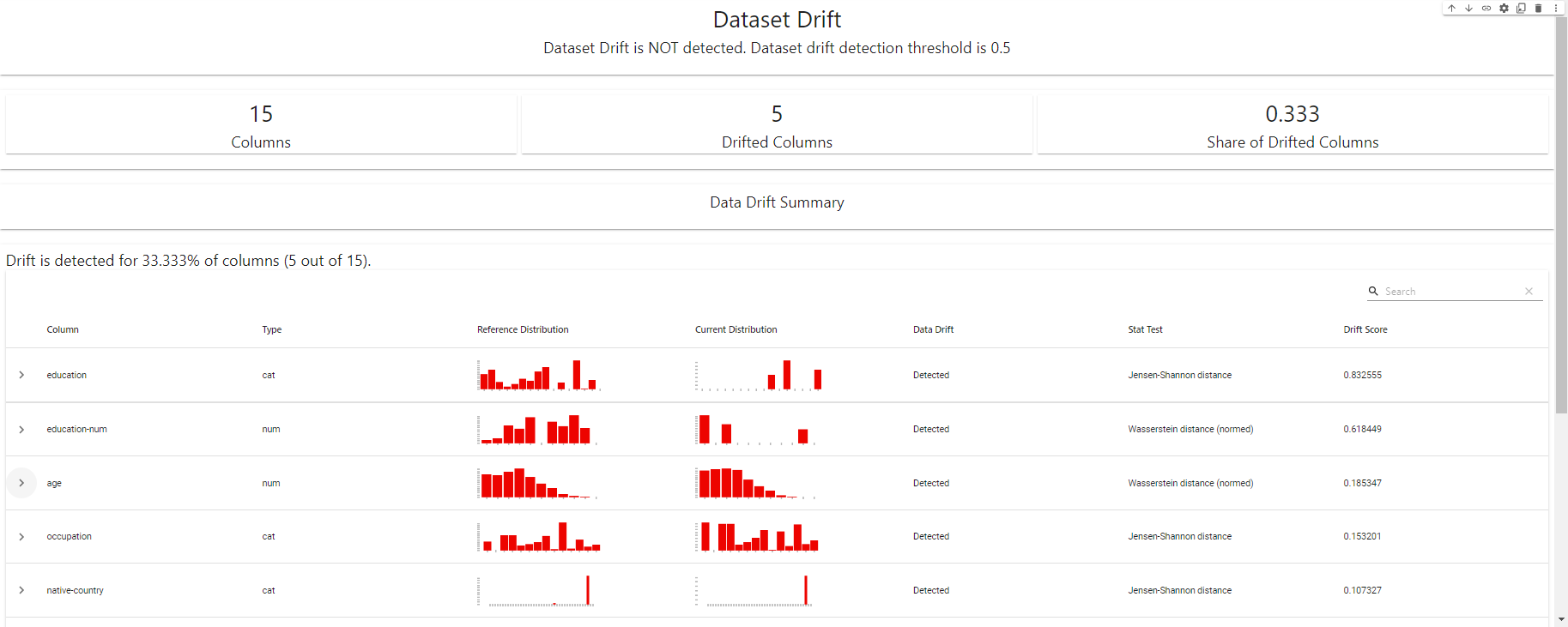
ड्रिफ्ट डिटेक्शन डैशबोर्ड - EvidentlyAI से बनाया गया
#report in a JSON format
my_eval.json()
पूरा Datacamp नोटबुक यहाँ देखें।
डेटा और मॉडल ड्रिफ्ट, प्रोडक्शन में मशीन लर्निंग सिस्टम्स के लिए गंभीर चुनौतियाँ पैदा कर सकते हैं। ड्रिफ्ट के कारणों और प्रभावों को समझकर, और प्रभावी ड्रिफ्ट मॉनिटरिंग प्रक्रियाएँ लागू करके, आप सुनिश्चित कर सकते हैं कि आपके मॉडल समय के साथ सटीक और विश्वसनीय बने रहें।
अपने मॉडलों के प्रदर्शन की निगरानी करना, ड्रिफ्ट डिटेक्शन मॉडल का उपयोग करना, और अपडेटेड डेटा पर नियमित रूप से पुन:प्रशिक्षण करना—ये कुछ सर्वोत्तम प्रथाएँ हैं जिनसे आप ड्रिफ्ट के जोखिम को कम कर सकते हैं। ड्रिफ्ट मॉनिटरिंग के प्रति सक्रिय रहकर, आप सुनिश्चित कर सकते हैं कि आपका मशीन लर्निंग सिस्टम आपकी संस्था को लगातार मूल्य देता रहे।
ड्रिफ्ट के लिए मशीन लर्निंग मॉडल की निगरानी करना, MLOps नामक व्यापक क्षेत्र का एक पहलू मात्र है। MLOps की अवधारणाओं को समझना किसी भी डेटा वैज्ञानिक, इंजीनियर, या लीडर के लिए आवश्यक है ताकि वे स्थानीय नोटबुक से प्रोडक्शन में चलने वाले मॉडल तक पहुँच सकें।
यदि आप MLOps को गहराई से समझना चाहते हैं और यह जानना चाहते हैं कि यह आपके करियर में कैसे सहायक हो सकता है, तो हमारा MLOps Concepts कोर्स देखें। यहाँ आप जानेंगे कि MLOps क्या है, MLOps प्रक्रियाओं के अलग-अलग चरणों को समझेंगे, और MLOps की परिपक्वता के विभिन्न स्तरों की पहचान करेंगे। आवश्यक MLOps अवधारणाएँ सीखने के बाद, आप मशीन लर्निंग को निरंतर, विश्वसनीय और कुशलतापूर्वक लागू करने की अपनी यात्रा के लिए अच्छी तरह तैयार होंगे।
MLOps कोर्सेज
course
course
course