course
MLOps Concepts
2 timmar
42.6K
Maskininlärningsmodeller tränas på historisk data, men när de används i verkligheten kan de bli inaktuella och tappa noggrannhet över tid på grund av ett fenomen som kallas drift. Drift är förändringen över tid i de statistiska egenskaperna hos den data som användes för att träna en maskininlärningsmodell. Det kan göra att modellen blir mindre träffsäker eller beter sig annorlunda än den var avsedd att göra.
Med andra ord är ”drift” en minskning av en modells förmåga att göra korrekta förutsägelser på grund av förändringar i den miljö där den används.
Det finns flera skäl till att maskininlärningsmodeller kan driftera över tid.
Ett vanligt skäl är helt enkelt att datan som modellen tränades på blir inaktuell eller inte längre representerar rådande förhållanden.
Anta till exempel en maskininlärningsmodell som tränats för att förutsäga ett företags aktiekurs baserat på historiska data. Om vi tränar modellen på data från en stabil marknad kan den prestera bra till en början. Om marknaden däremot blir mer volatil över tid kanske modellen inte längre kan förutsäga aktiekursen korrekt eftersom de statistiska egenskaperna hos datan har förändrats.
Ett annat skäl till modelldrift är att modellen inte är utformad för att hantera förändringar i datan. Vissa maskininlärningsmodeller kan hantera förändringar bättre än andra, men ingen modell kan helt undvika drift.
Låt oss gå igenom två olika typer av drift att beakta:
Konceptdrift, även kallad modelldrift, uppstår när uppgiften som modellen var avsedd att utföra förändras över tid. Föreställ dig till exempel att en maskininlärningsmodell tränades för att upptäcka skräppost baserat på e-postens innehåll. Om typerna av skräppost som människor får förändras avsevärt kanske modellen inte längre kan identifiera skräppost korrekt.
Konceptdrift kan delas in i fyra kategorier (Learning under Concept Drift: A Review, Jie Lu et al.):
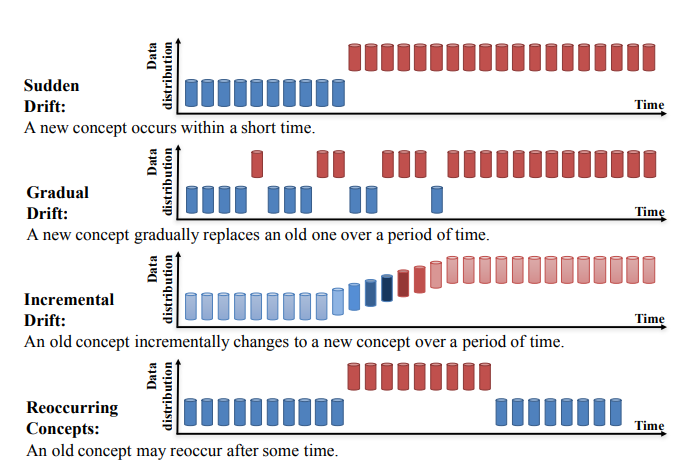
Källa: https://arxiv.org/pdf/2004.05785.pdf
Datadrift, även kallad kovariatförskjutning, uppstår när fördelningen av indata förändras över tid. Tänk till exempel på en modell som tränats för att förutsäga sannolikheten att en kund köper en produkt baserat på ålder och inkomst. Om fördelningen av åldrar och inkomster bland kunderna förändras avsevärt över tid kanske modellen inte längre kan förutsäga köpsannolikheten korrekt.
Det är viktigt att vara medveten om både konceptdrift och datadrift och vidta åtgärder för att förebygga eller mildra deras effekter. Några strategier för att hantera drift är att kontinuerligt övervaka och utvärdera en modells prestanda, uppdatera modellen med ny data samt använda modeller som är mer robusta mot drift.
Du kan lära dig mer om data science efter driftsättning, till exempel drift, i vårt DataFramed-podcastavsnitt.
LLM:er introducerar en typ av drift som metoderna ovan inte var utformade för. Datan är inte rader i en tabell — det är fri text — och det som skiftar över tid är oftast betydelsen av vad användarna frågar. Det anses nu finnas tre former av LLM-drift att övervaka.
Inbäddningsdrift uppstår när betydelsen av texten som användare skickar till en modell förändras, även om själva texten ser likadan ut på ytan. LLM:er omvandlar text till långa listor av tal som kallas inbäddningar, och drift kan synas i dessa tal utan att märkas i något du normalt skulle mäta.
Föreställ dig en kundsupportbot som från början mest hanterade frågor om installation och onboarding. Sex månader senare är både mängden meddelanden och deras genomsnittliga längd oförändrade, men nu frågar användarna mest om fakturering och uppsägningar. Textstatistiken ser stabil ut, men fördelningen av inbäddningar har skiftat. För att upptäcka detta jämför team satser av senaste inbäddningar mot en referenssats med ett statistiskt avståndsmått.
Promptdrift är samma idé som inbäddningsdrift, men spårad en nivå upp. I stället för att jämföra råa inbäddningar grupperar du inkommande frågor i kategorier — med en klassificerare eller en annan LLM — och följer skiften i blandningen.
Tänk dig en intern kodassistent lanserad för backend‑ingenjörer som gradvis börjar få trafik från data scientists med frågor om pandas. Assistenten kan fortfarande svara bra, men populationen den tjänar är inte längre den den testades på, och systemprompten eller hämtningsindexet kan med tiden sluta passa lika bra.
Rubrikdrift är en förändring över tid i de kvalitetspoäng som en automatiserad utvärderare ger modellens svar. Många produktionsteam använder nu en LLM som domare, som betygsätter varje svar på saker som hjälpsamhet, korrekthet eller ton. När dessa poäng börjar trenda nedåt för samma typer av indata har vanligtvis något förändrats — modellen bakom ett API, dokumenten som hämtas eller användarmixen.
Det som gör rubrikdrift särskilt användbart är att det ger en kvalitetsignal utan behov av facit‑etiketter, som sällan finns tillgängliga i realtid för generativa utdata.
Det finns två sätt att upptäcka drift:
1. Modellbaserad metod inom maskininlärning: En modellbaserad metod för att avgöra om inkommande indata har driftera eller inte.
2. Statistiska tester: Det finns många statistiska tester för att upptäcka datadrift. De delas i huvudsak in i tre kategorier:
Tidsfördelningsbaserade metoder använder statistiska metoder för att beräkna skillnaden mellan två sannolikhetsfördelningar för att upptäcka drift. Dessa metoder inkluderar Population Stability Index, KL-divergens, JS-divergens, KS-test och Wasserstein-måttet.
Kolmogorov–Smirnov-testet (K–S) är ett icke‑parametriskt statistiskt test som används för att avgöra om två dataset kommer från samma fördelning. Det används ofta för att testa om ett urval kommer från en specifik population eller för att jämföra två urval för att avgöra om de kommer från samma population.
Nollhypotesen i detta test är att fördelningarna är desamma. Om denna hypotes förkastas tyder det på att det finns drift i modellen.
K–S-testet är ett användbart verktyg för att jämföra dataset och avgöra om de kommer från samma fördelning.
Population Stability Index (PSI) är ett statistiskt mått som används för att jämföra fördelningen av en kategorisk variabel i två olika dataset.
Population Stability Index (PSI) är ett verktyg för att mäta hur mycket fördelningen av en variabel har förändrats mellan två urval eller över tid. Det används ofta för att övervaka förändringar i egenskaperna hos en population och för att identifiera potentiella problem med prestandan hos en maskininlärningsmodell.
PSI utvecklades ursprungligen för att övervaka förändringar i fördelningen av ett poäng i riskscorekort, men används nu för att undersöka förskjutningar i fördelningar för alla modellrelaterade attribut, inklusive både beroende och oberoende variabler.
Ett högt PSI-värde indikerar att det finns en betydande skillnad mellan variabelns fördelningar i de två datasetten, vilket kan tyda på drift i modellen.
Om fördelningen av en variabel har förändrats avsevärt, eller om flera variabler har förändrats i viss utsträckning, kan det vara nödvändigt att rekalibrera eller bygga om modellen för att förbättra dess prestanda.
Page–Hinkley-metoden är en statistisk metod som används för att upptäcka förändringar i medelvärdet hos en dataserie över tid. Den används ofta för att övervaka prestandan hos maskininlärningsmodeller och upptäcka förändringar i datans fördelning som kan indikera modelldrift.
För att använda Page–Hinkley-metoden börjar man med att definiera ett tröskelvärde och en beslutsfunktion. Tröskelvärdet är ett värde över vilket en förändring i medelvärdet anses vara signifikant, och beslutsfunktionen returnerar 1 om en förändring har upptäckts och 0 om ingen förändring har upptäckts.
Därefter beräknas medelvärdet för dataserien vid varje tidssteg, och beslutsfunktionen tillämpas på datan för att avgöra om en förändring har skett. Om beslutsfunktionen returnerar 1 indikerar det att en förändring har upptäckts och att modellen kan vara på väg att driftera.
Page–Hinkley-metoden är ett enkelt och effektivt sätt att upptäcka förändringar i medelvärdet hos en dataserie över tid. Den är särskilt användbar för att upptäcka små förändringar i medelvärdet som kanske inte är omedelbart uppenbara vid en översiktlig granskning. Det är dock viktigt att noggrant välja tröskelvärde och beslutsfunktion så att metoden är tillräckligt känslig för att upptäcka förändringar, men inte så känslig att den genererar falsklarm.
I det här avsnittet använder vi Evidently för att upptäcka drift. Evidently är ett Python-bibliotek med öppen källkod för data scientists och ingenjörer som arbetar med maskininlärning. Det hjälper dem att testa, utvärdera och följa upp hur väl deras modeller fungerar från validering till produktion.
import pandas as pd
import numpy as np
from sklearn import datasets
from evidently import Report
from evidently.presets import DataDriftPreset# create ref and cur dataset for drift detection
adult_data = datasets.fetch_openml(name='adult', version=2, as_frame=True)
adult = adult_data.frame
adult_ref = adult[~adult.education.isin(['Some-college', 'HS-grad', 'Bachelors'])].copy()
adult_cur = adult[adult.education.isin(['Some-college', 'HS-grad', 'Bachelors'])].copy()
adult_cur.iloc[:2000, 3:5] = np.nan#dataset-level metrics
report = Report([DataDriftPreset()], include_tests=True)
my_eval = report.run(current_data=adult_cur, reference_data=adult_ref)
my_eval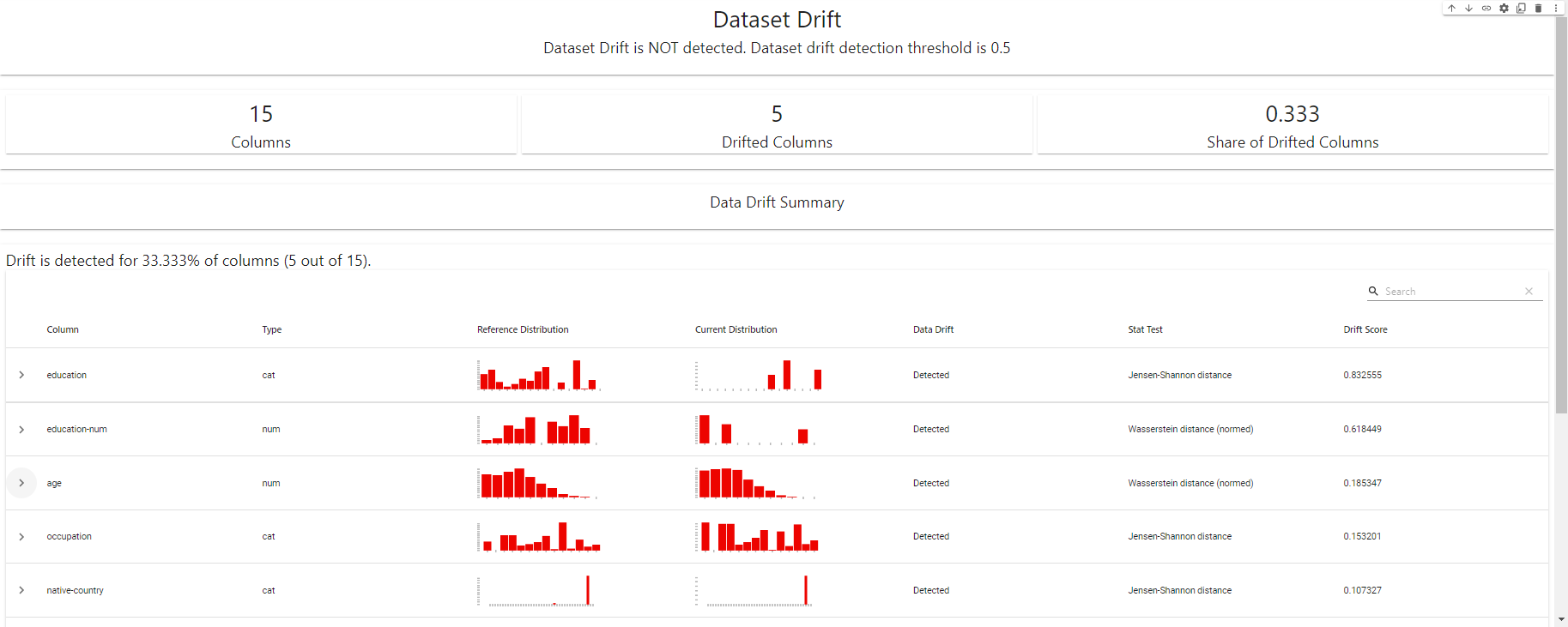
Driftdetekteringspanel – skapad med EvidentlyAI
#report in a JSON format
my_eval.json()
Kolla in hela Datacamp‑anteckningsboken här.
Data- och modelldrift kan utgöra betydande utmaningar för maskininlärningssystem i produktion. Genom att förstå orsakerna och effekterna av drift och införa effektiva metoder för driftovervakning kan du säkerställa att dina modeller förblir träffsäkra och tillförlitliga över tid.
Att övervaka modellernas prestanda, använda en driftdetekteringsmodell och regelbundet omskola på uppdaterad data är bara några av de bästa praxis du kan följa för att minska riskerna med drift. Genom att vara proaktiv med driftovervakning kan du se till att ditt maskininlärningssystem fortsätter att leverera värde till din organisation.
Att övervaka maskininlärningsmodeller för drift är bara en del av ett bredare område som kallas MLOps. Att förstå MLOps‑koncept är avgörande för varje data scientist, ingenjör eller ledare för att ta modeller från en lokal anteckningsbok till en fungerande modell i produktion.
Om du vill fördjupa dig i att förstå MLOps och hur det kan gynna din karriär, ta en titt på vår kurs MLOps Concepts. Här lär du dig vad MLOps är, förstår de olika faserna i MLOps‑processer och identifierar olika nivåer av MLOps‑mognad. Efter att ha lärt dig de grundläggande MLOps‑koncepten är du väl rustad för att implementera maskininlärning kontinuerligt, pålitligt och effektivt.
MLOps‑kurser
course
course
course