
Course
MLOps Concepts
2 hr
42.6K
Machine learning models are trained with historical data, but once they are used in the real world, they may become outdated and lose their accuracy over time due to a phenomenon called drift. Drift is the change over time in the statistical properties of the data that was used to train a machine learning model. This can cause the model to become less accurate or perform differently than it was designed to.
In other words, "drift" is the decline in a model's ability to make accurate predictions due to changes in the environment in which it is being used.
There are several reasons why machine learning models can drift over time.
One common reason is simply that the data that the model was trained on becomes outdated or no longer represents the current conditions.
For example, consider a machine learning model trained to predict the stock price of a company based on historical data. If we train the model with data from a stable market, it might do well at first. However, if the market becomes more volatile over time, the model might not be able to accurately predict the stock price anymore because the statistical properties of the data have changed.
Another reason for model drift is that the model was not designed to handle changes in the data. Some machine learning models can handle changes in the data better than others, but no model can avoid drift completely.
Let's explore the two different types of drift to consider:
Concept drift, also known as model drift, occurs when the task that the model was designed to perform changes over time. For example, imagine that a machine learning model was trained to detect spam emails based on the content of the email. If the types of spam emails that people receive change significantly, the model may no longer be able to accurately detect spam.
Concept Drift can be further divided into four categories (Learning under Concept Drift: A Review, Jie Lu et al.):
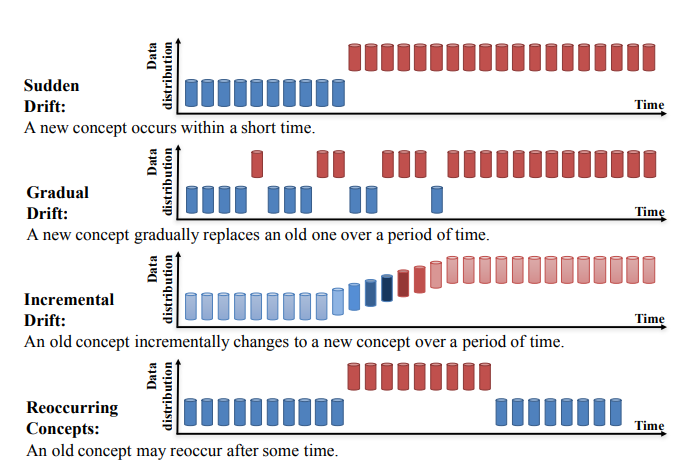
Source: https://arxiv.org/pdf/2004.05785.pdf
Data drift, also known as covariate shift, occurs when the distribution of the input data changes over time. For example, consider a machine learning model that was trained to predict the likelihood of a customer purchasing a product based on their age and income. If the distribution of ages and incomes of the customers changes significantly over time, the model may no longer be able to predict the likelihood of a purchase accurately.
It is important to be aware of both concept drift and data drift and take steps to prevent or mitigate their effects. Some strategies for addressing drift include continuously monitoring and evaluating the performance of a model, updating the model with new data, and using machine learning models that are more robust to drift.
You can learn more about post-deployment data science, such as drift, in our DataFramed podcast episode.
LLMs introduce a kind of drift that the methods above weren't designed for. The data isn't rows in a table — it's free-form text — and what shifts over time is usually the meaning of what users are asking. It is thought now there are three forms of LLM drift to monitor.
Embedding drift happens when the meaning of the text users send to a model changes, even when the surface text looks the same. LLMs convert text into long lists of numbers called embeddings, and drift can show up in those numbers without showing up in anything you'd usually be measuring.
Imagine a customer support chatbot that originally handled mostly setup and onboarding questions. Then, six months later, the volume of messages, plus their average length, are unchanged, but users are now mostly asking about billing and cancellations. The text statistics look stable, but the embedding distribution has shifted. To detect this, teams compare batches of recent embeddings against a reference batch using a statistical distance measure.
Prompt drift is the same idea as embedding drift, but tracked one level up. Instead of comparing raw embeddings, you bucket incoming queries into categories — using a classifier or another LLM — and watch for shifts in the mix.
Imagine an internal coding assistant launched for backend engineers might gradually start picking up traffic from data scientists asking pandas questions. The assistant may still answer competently, but the population it's serving is no longer the one it was tested on, and the system prompt or retrieval index may over time stop being a great fit.
Rubric drift is a change over time in the quality scores that an automated evaluator gives to a model's outputs. Many production teams now use an LLM as a judge, scoring each response on things like helpfulness, accuracy, or tone. When those scores start trending down for the same kinds of inputs, something has usually changed — the model behind an API, the documents being retrieved, or the user mix.
What makes rubric drift especially useful is that it gives you a quality signal without needing ground truth labels, which are rarely available in real time for generative outputs.
There are two ways we can detect drift:
1. Machine Learning Model-Based Approach: Model-based approach to detect whether the incoming input data has drifted or not.
2. Statistical Tests: There are many statistical tests to detect data drift. They are primarily divided into three categories:
Time distribution-based methods use statistical methods to calculate the difference between two probability distributions to detect drift. These methods include the Population Stability Index, KL Divergence, JS Divergence, KS Test, and the Wasserstein Metric.
The Kolmogorov-Smirnov (K-S) test is a nonparametric statistical test that is used to determine whether two sets of data come from the same distribution. It is often used to test whether a sample of data comes from a specific population or to compare two samples to determine if they come from the same population.
The null hypothesis in this test is that the distributions are the same. If this hypothesis is rejected, it suggests that there is a drift in the model.
The K-S test is a useful tool for comparing datasets and determining whether they come from the same distribution.
The Population Stability Index (PSI) is a statistical measure that is used to compare the distribution of a categorical variable in two different datasets.
The Population Stability Index (PSI) is a tool used to measure how much the distribution of a variable has changed between two samples or over time. It is commonly used to monitor changes in the characteristics of a population and to identify potential problems with the performance of a machine learning model.
The PSI was originally developed to monitor changes in the distribution of a score in risk scorecards, but it is now used to examine distributional shifts for all model-related attributes, including both dependent and independent variables.
A high PSI value indicates that there is a significant difference between the distributions of the variable in the two datasets, which may suggest that there is a drift in the model.
If the distribution of a variable has changed significantly, or if several variables have changed to some extent, it may be necessary to recalibrate or rebuild the model to improve its performance.
The Page-Hinkley method is a statistical method used to detect changes in the mean of a series of data over time. It is commonly used to monitor the performance of machine learning models and detect changes in the distribution of the data that may indicate model drift.
To use the Page-Hinkley method, the first step is to define a threshold value and a decision function. The threshold value is a value above which a change in the mean is considered significant, and the decision function is a function that returns a value of 1 if a change has been detected and a value of 0 if no change has been detected.
Next, the mean of the data series is calculated at each time step, and the decision function is applied to the data to determine if a change has occurred. If the decision function returns a value of 1, it indicates that a change has been detected and the model may be drifting.
The Page-Hinkley method is a simple and effective way to detect changes in the mean of a data series over time. It is particularly useful for detecting small changes in the mean that may not be immediately apparent when looking at the data. However, it is important to carefully select the threshold value and decision function to ensure that the method is sensitive enough to detect changes in the data but not so sensitive that it generates false alarms.
In this section, we will use Evidently to detect drift. Evidently is an open-source Python library made for data scientists and engineers who work with machine learning. It helps them test, evaluate, and keep track of how well their models work from validation to production.
import pandas as pd
import numpy as np
from sklearn import datasets
from evidently import Report
from evidently.presets import DataDriftPreset# create ref and cur dataset for drift detection
adult_data = datasets.fetch_openml(name='adult', version=2, as_frame=True)
adult = adult_data.frame
adult_ref = adult[~adult.education.isin(['Some-college', 'HS-grad', 'Bachelors'])].copy()
adult_cur = adult[adult.education.isin(['Some-college', 'HS-grad', 'Bachelors'])].copy()
adult_cur.iloc[:2000, 3:5] = np.nan#dataset-level metrics
report = Report([DataDriftPreset()], include_tests=True)
my_eval = report.run(current_data=adult_cur, reference_data=adult_ref)
my_eval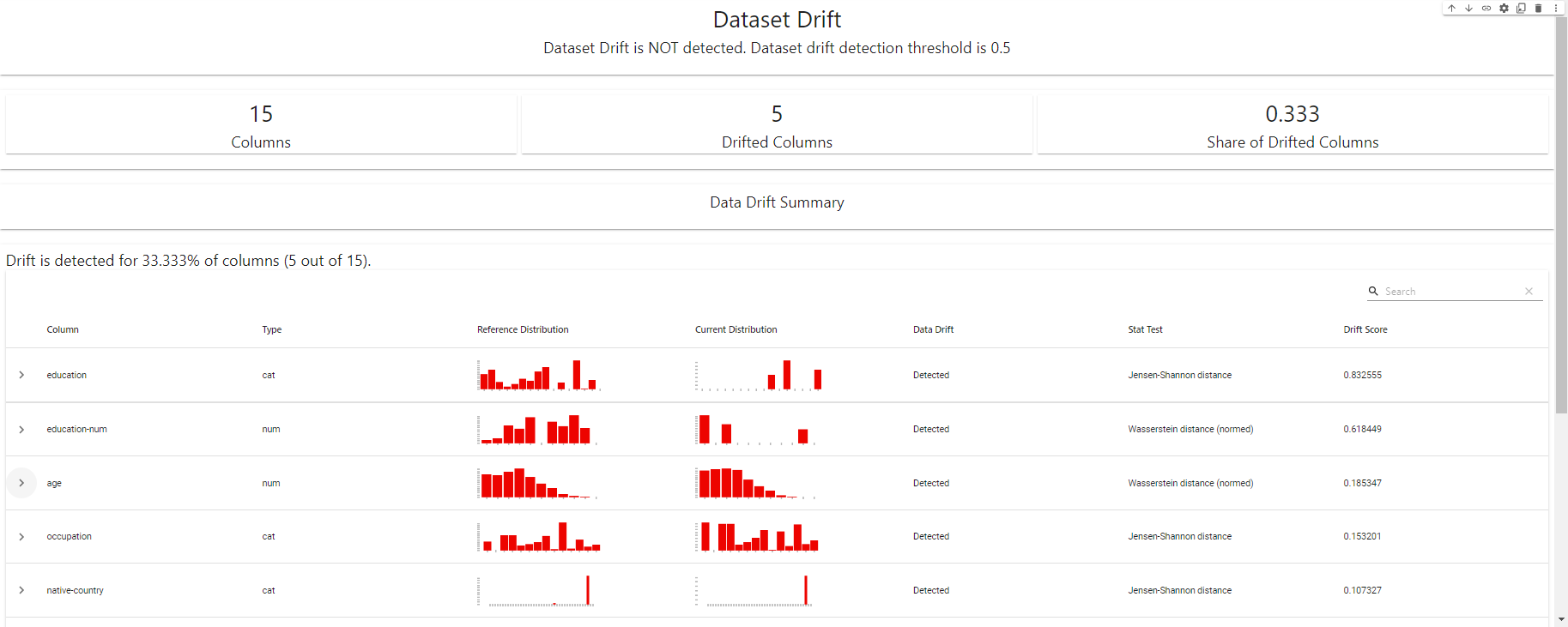
Drift Detection Dashboard - created using EvidentlyAI
#report in a JSON format
my_eval.json()
Check out the complete Datacamp Notebook here.
Data and model drift can pose significant challenges to machine learning systems in production. By understanding the causes and effects of drift, and implementing effective drift monitoring practices, you can ensure that your machine learning models remain accurate and reliable over time.
Monitoring the performance of your models, using a drift detection model, and regularly retraining on updated data are just a few of the best practices you can follow to mitigate the risks of drift. By being proactive about drift monitoring, you can ensure that your machine learning system continues to deliver value to your organization.
Monitoring machine learning models for drift is just one aspect of a broader field called MLOps. Understanding MLOps concepts is essential for any data scientist, engineer, or leader to take machine learning models from a local notebook to a functioning model in production.
If you would like to take a deep dive into understanding MLOps and how it can benefit you in your career, check out our MLOps Concepts course. Here, you’ll learn what MLOps is, understand the different phases in MLOps processes, and identify different levels of MLOps maturity. After learning about the essential MLOps concepts, you’ll be well-equipped in your journey to implement machine learning continuously, reliably, and efficiently.
MLOps Courses
Course
Course
Course
blog
Elena Kosourova
10 min
blog
Kurtis Pykes
10 min
Tutorial
Sayak Paul
code-along
Weston Bassler
code-along
George Boorman
code-along
Justin Saddlemyer



