
Kurs
MLOps Kavramları
2 sa
43.7K
Makine öğrenimi modelleri geçmiş verilerle eğitilir; ancak gerçek dünyada kullanılmaya başlandıklarında, kayma adı verilen bir olgu nedeniyle zamanla güncelliğini yitirip doğrulukları düşebilir. Kayma, bir makine öğrenimi modelinin eğitildiği verilerin istatistiksel özelliklerinin zaman içinde değişmesidir. Bu durum, modelin daha az doğru hale gelmesine veya tasarlandığından farklı davranmasına yol açabilir.
Başka bir deyişle, “kayma”, bir modelin, kullanıldığı ortamda meydana gelen değişiklikler nedeniyle doğru tahmin yapma yeteneğinin düşmesidir.
Makine öğrenimi modellerinin zamanla kaymasına neden olabilecek çeşitli etkenler vardır.
Yaygın bir neden, modelin eğitildiği verilerin eskimesi veya mevcut koşulları artık temsil etmemesidir.
Örneğin, bir şirketin hisse senedi fiyatını geçmiş verilere dayanarak tahmin etmek üzere eğitilmiş bir makine öğrenimi modelini düşünün. Modeli istikrarlı bir piyasa verisiyle eğitirsek, başlangıçta iyi performans gösterebilir. Ancak zamanla piyasa daha oynak hale gelirse, verilerin istatistiksel özellikleri değiştiğinden model artık fiyatı doğru tahmin edemeyebilir.
Model kaymasının bir diğer nedeni, modelin verideki değişiklikleri ele alacak şekilde tasarlanmamış olmasıdır. Bazı makine öğrenimi modelleri değişimlere diğerlerinden daha dayanıklıdır; ancak hiçbir model kaymayı tamamen önleyemez.
Göz önünde bulundurulması gereken iki farklı kayma türünü inceleyelim:
Model kayması olarak da bilinen kavram kayması, modelin tasarlandığı görevin zaman içinde değişmesi durumunda ortaya çıkar. Örneğin, e-posta içeriğine göre istenmeyen e-postaları tespit etmek üzere eğitilen bir makine öğrenimi modelini düşünün. İnsanların aldığı spam türleri önemli ölçüde değişirse, model artık spam’i doğru şekilde tespit edemeyebilir.
Kavram kayması dört kategoriye ayrılabilir (Learning under Concept Drift: A Review, Jie Lu ve diğ.):
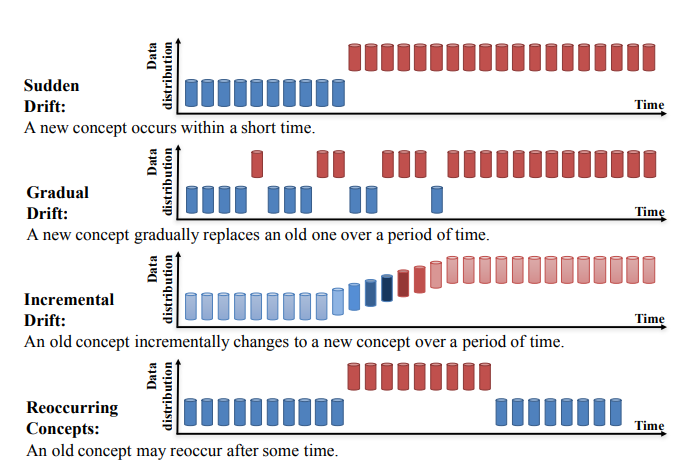
Kaynak: https://arxiv.org/pdf/2004.05785.pdf
Eş değişken kayması (covariate shift) olarak da bilinen veri kayması, girdi verilerinin dağılımının zamanla değişmesi durumunda meydana gelir. Örneğin, bir müşterinin yaşına ve gelirine göre ürün satın alma olasılığını tahmin etmek üzere eğitilen bir makine öğrenimi modelini düşünün. Müşterilerin yaş ve gelir dağılımı zaman içinde önemli ölçüde değişirse, model artık satın alma olasılığını doğru tahmin edemeyebilir.
Hem kavram kaymasının hem de veri kaymasının farkında olmak ve etkilerini önlemek veya hafifletmek için adımlar atmak önemlidir. Kaymayı ele almak için bazı stratejiler arasında bir modelin performansını sürekli izlemek ve değerlendirmek, modeli yeni verilerle güncellemek ve kaymaya daha dayanıklı makine öğrenimi modelleri kullanmak yer alır.
Kayma gibi dağıtım sonrası veri bilimi konuları hakkında daha fazla bilgiyi DataFramed podcast bölümümüzde bulabilirsiniz.
Büyük dil modelleri (BYM’ler), yukarıdaki yöntemlerin tasarlanmadığı bir tür kaymayı gündeme getirir. Veri, bir tablodaki satırlar değildir — serbest biçimli metindir — ve zamanla değişen şey genellikle kullanıcıların ne sorduğunun anlamıdır. Günümüzde izlenmesi gereken üç tür BYM kayması olduğu düşünülmektedir.
Gömme kayması, kullanıcıların modele gönderdiği metnin yüzey metni aynı görünse bile anlamının değişmesiyle ortaya çıkar. BYM’ler metni, gömme (embedding) adı verilen uzun sayı listelerine dönüştürür ve kayma, genellikle ölçtüğünüz hiçbir şeye yansımasa da bu sayılarda kendini gösterebilir.
Kurulum ve işe alıştırma sorularını ağırlıklı olarak yanıtlayan bir müşteri destek sohbet botunu hayal edin. Altı ay sonra, mesaj hacmi ve ortalama uzunluk değişmemiş olsa da kullanıcılar artık çoğunlukla faturalama ve iptaller hakkında soruyor. Metin istatistikleri sabit görünür, ancak gömme dağılımı kaymıştır. Bunu tespit etmek için ekipler, son dönem gömmelerini bir referans toplulukla istatistiksel uzaklık ölçüsü kullanarak karşılaştırır.
İstem kayması, gömme kaymasıyla aynı fikirdir ancak bir seviye yukarıdan izlenir. Ham gömmeleri karşılaştırmak yerine, gelen sorguları — bir sınıflandırıcı veya başka bir BYM kullanarak — kategorilere ayırır ve karışımdaki değişimleri izlersiniz.
Örneğin, arka uç mühendislerine yönelik bir iç kod asistanı zamanla veri bilimcilerden gelen pandas sorularını almaya başlayabilir. Asistan hâlâ yetkin yanıtlar verebilir, ancak hizmet verdiği kitle test edildiği kitle olmaktan çıkmıştır ve sistem istemi veya getirme dizini zamanla uygunluğunu yitirebilir.
Rubrik kayması, otomatik bir değerlendiricinin bir modelin çıktılarına verdiği kalite puanlarının zaman içinde değişmesidir. Birçok üretim ekibi artık bir BYM’yi hakem olarak kullanıyor; her yanıtı faydalılık, doğruluk veya üslup gibi ölçütlerde puanlıyor. Aynı tür girdiler için bu puanlar düşmeye başladığında genellikle bir şeyler değişmiştir — bir API’nin arkasındaki model, getirilen belgeler veya kullanıcı karması.
Rubrik kaymasını özellikle yararlı kılan şey, üretken çıktılar için gerçek zamanlı yer doğrularının nadiren mevcut olduğu durumlarda, yer gerçeğine ihtiyaç duymadan bir kalite sinyali sağlamasıdır.
Kaymayı tespit etmenin iki yolu vardır:
1. Makine Öğrenimi Model Tabanlı Yaklaşım: Gelen girdi verisinin kayıp kaymadığını tespit etmek için model tabanlı yaklaşım.
2. İstatistiksel Testler: Veri kaymasını tespit etmek için birçok istatistiksel test vardır. Bunlar temel olarak üç kategoriye ayrılır:
Zaman dağılımına dayalı yöntemler, kaymayı tespit etmek için iki olasılık dağılımı arasındaki farkı hesaplamak üzere istatistiksel yöntemler kullanır. Bu yöntemler arasında Nüfus Kararlılık Endeksi, KL Ayrışımı, JS Ayrışımı, KS Testi ve Wasserstein Metriği bulunur.
Kolmogorov-Smirnov (K-S) testi, iki veri kümesinin aynı dağımdan gelip gelmediğini belirlemek için kullanılan parametrik olmayan bir istatistiksel testtir. Genellikle bir veri örneğinin belirli bir popülasyondan gelip gelmediğini test etmek veya iki örneği karşılaştırarak aynı popülasyondan gelip gelmediklerini anlamak için kullanılır.
Bu testteki sıfır hipotezi dağılımların aynı olduğudur. Bu hipotez reddedilirse, modelde kayma olduğuna işaret eder.
K-S testi, veri kümelerini karşılaştırmak ve aynı dağımdan gelip gelmediklerini belirlemek için yararlı bir araçtır.
Nüfus Kararlılık Endeksi (PSI), iki farklı veri kümesinde kategorik bir değişkenin dağılımını karşılaştırmak için kullanılan bir istatistiksel ölçüdür.
Nüfus Kararlılık Endeksi (PSI), bir değişkenin iki örnek arasında veya zaman içinde dağılımının ne kadar değiştiğini ölçmek için kullanılan bir araçtır. Genellikle bir popülasyonun özelliklerindeki değişimleri izlemek ve bir makine öğrenimi modelinin performansındaki olası sorunları belirlemek için kullanılır.
PSI, başlangıçta risk skorkartlarında bir skorun dağılımındaki değişiklikleri izlemek için geliştirilmiştir; ancak günümüzde bağımlı ve bağımsız değişkenler dahil tüm modelle ilgili özniteliklerdeki dağılımsal kaymaları incelemek için de kullanılmaktadır.
Yüksek bir PSI değeri, iki veri kümesindeki değişken dağılımları arasında önemli bir fark olduğunu ve bunun da modelde kayma olduğuna işaret edebileceğini gösterir.
Bir değişkenin dağılımı önemli ölçüde değişmişse veya birkaç değişkende belirli ölçüde değişim varsa, performansı artırmak için modelin yeniden kalibre edilmesi veya yeniden oluşturulması gerekebilir.
Page-Hinkley yöntemi, bir veri serisinin ortalamasındaki zaman içindeki değişiklikleri tespit etmek için kullanılan bir istatistiksel yöntemdir. Genellikle makine öğrenimi modellerinin performansını izlemek ve model kaymasına işaret edebilecek veri dağılımı değişikliklerini tespit etmek için kullanılır.
Page-Hinkley yöntemini kullanmak için ilk adım bir eşik değeri ve bir karar fonksiyonu tanımlamaktır. Eşik değeri, ortalamadaki bir değişimin anlamlı kabul edildiği değerdir; karar fonksiyonu ise bir değişim tespit edilirse 1, tespit edilmezse 0 döndüren bir fonksiyondur.
Sonrasında, her zaman adımında serinin ortalaması hesaplanır ve bir değişim olup olmadığını belirlemek için karar fonksiyonu uygulanır. Karar fonksiyonu 1 döndürürse, bir değişim tespit edildiğini ve modelin kayıyor olabileceğini gösterir.
Page-Hinkley yöntemi, bir veri serisinin ortalamasındaki değişiklikleri zaman içinde tespit etmek için basit ve etkili bir yöntemdir. Özellikle, veriye bakıldığında hemen fark edilmeyebilecek küçük ortalama değişikliklerini tespit etmede kullanışlıdır. Ancak yöntemin, değişiklikleri yeterince algılayacak kadar duyarlı, ancak yanlış alarmlara yol açmayacak kadar da seçici olmasını sağlamak için eşik değeri ve karar fonksiyonunun dikkatle seçilmesi önemlidir.
Bu bölümde kaymayı tespit etmek için Evidently kullanacağız. Evidently, makine öğrenimi ile çalışan veri bilimciler ve mühendisler için geliştirilmiş açık kaynak bir Python kütüphanesidir. Modellerin doğrulamadan üretime kadar ne kadar iyi çalıştığını test etmeye, değerlendirmeye ve takip etmeye yardımcı olur.
import pandas as pd
import numpy as np
from sklearn import datasets
from evidently import Report
from evidently.presets import DataDriftPreset# create ref and cur dataset for drift detection
adult_data = datasets.fetch_openml(name='adult', version=2, as_frame=True)
adult = adult_data.frame
adult_ref = adult[~adult.education.isin(['Some-college', 'HS-grad', 'Bachelors'])].copy()
adult_cur = adult[adult.education.isin(['Some-college', 'HS-grad', 'Bachelors'])].copy()
adult_cur.iloc[:2000, 3:5] = np.nan#dataset-level metrics
report = Report([DataDriftPreset()], include_tests=True)
my_eval = report.run(current_data=adult_cur, reference_data=adult_ref)
my_eval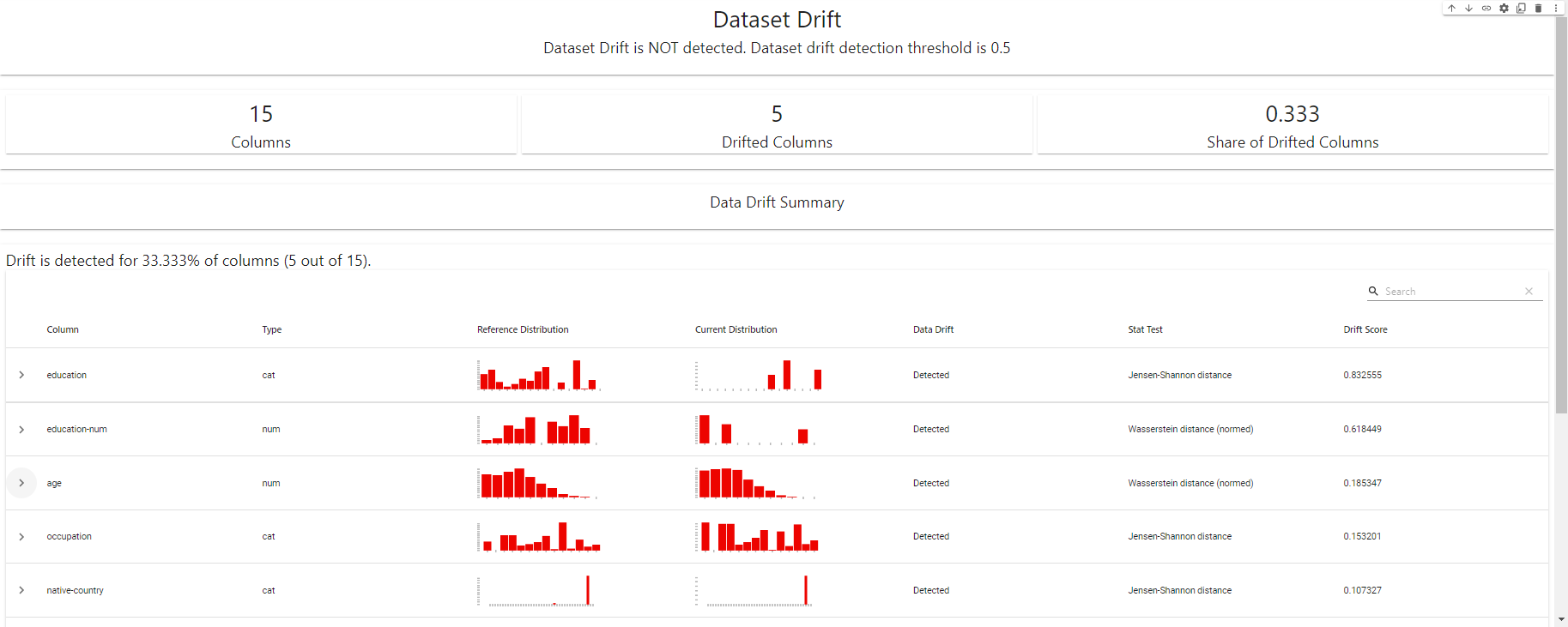
Kayma Tespiti Panosu - EvidentlyAI kullanılarak oluşturulmuştur
#report in a JSON format
my_eval.json()
Tam Datacamp Notebook’unu buradan inceleyin.
Veri ve model kayması, üretimdeki makine öğrenimi sistemleri için ciddi zorluklar oluşturabilir. Kaymanın nedenlerini ve etkilerini anlayarak ve etkili kayma izleme uygulamalarını hayata geçirerek, makine öğrenimi modellerinizin zaman içinde doğru ve güvenilir kalmasını sağlayabilirsiniz.
Modellerinizin performansını izlemek, bir kayma tespit modeli kullanmak ve güncellenmiş verilerle düzenli olarak yeniden eğitmek, kayma risklerini azaltmak için uygulayabileceğiniz en iyi yöntemlerden yalnızca birkaçıdır. Kayma izleme konusunda proaktif davranarak, makine öğrenimi sisteminizin kuruluşunuza değer sunmaya devam etmesini sağlayabilirsiniz.
Makine öğrenimi modellerini kayma açısından izlemek, MLOps olarak adlandırılan daha geniş bir alanın yalnızca bir yönüdür. MLOps kavramlarını anlamak, makine öğrenimi modellerini yerel bir defterden üretimde çalışan bir modele taşımak isteyen her veri bilimci, mühendis veya lider için temeldir.
MLOps’u ve kariyerinize nasıl fayda sağlayabileceğini derinlemesine incelemek isterseniz, MLOps Concepts kursumuza göz atın. Burada MLOps’un ne olduğunu, MLOps süreçlerindeki farklı aşamaları ve MLOps olgunluk seviyelerini öğreneceksiniz. Temel MLOps kavramlarını öğrendikten sonra, makine öğrenimini sürekli, güvenilir ve verimli bir şekilde uygulama yolculuğunuzda iyi donanımlı olacaksınız.
MLOps Kursları
Kurs
Kurs
Kurs
blog
Dario Radečić
15 dk.
blog
Abid Ali Awan
14 dk.
Eğitim
Adel Nehme
Eğitim
Kurtis Pykes
