
Kursus
Konsep MLOps
2 Hr
43.7K
Model machine learning dilatih dengan data historis, tetapi setelah digunakan di dunia nyata, model dapat menjadi usang dan kehilangan akurasi seiring waktu karena fenomena yang disebut drift. Drift adalah perubahan dari waktu ke waktu pada sifat statistik data yang digunakan untuk melatih model machine learning. Hal ini dapat menyebabkan model menjadi kurang akurat atau berkinerja berbeda dari yang dirancang.
Dengan kata lain, "drift" adalah penurunan kemampuan model untuk membuat prediksi akurat karena perubahan lingkungan tempat model digunakan.
Ada beberapa alasan mengapa model machine learning dapat mengalami drift seiring waktu.
Salah satu alasan umum adalah data yang digunakan untuk melatih model menjadi usang atau tidak lagi mewakili kondisi saat ini.
Misalnya, pertimbangkan model machine learning yang dilatih untuk memprediksi harga saham suatu perusahaan berdasarkan data historis. Jika kita melatih model dengan data dari pasar yang stabil, model mungkin berkinerja baik pada awalnya. Namun, jika pasar menjadi lebih volatil seiring waktu, model mungkin tidak lagi dapat memprediksi harga saham secara akurat karena sifat statistik datanya telah berubah.
Alasan lain model mengalami drift adalah karena model tidak dirancang untuk menangani perubahan pada data. Beberapa model machine learning dapat menangani perubahan data lebih baik daripada yang lain, tetapi tidak ada model yang dapat sepenuhnya menghindari drift.
Mari kita telusuri dua jenis drift yang perlu dipertimbangkan:
Concept drift, juga dikenal sebagai model drift, terjadi ketika tugas yang dirancang untuk dilakukan oleh model berubah seiring waktu. Misalnya, bayangkan sebuah model machine learning dilatih untuk mendeteksi email spam berdasarkan kontennya. Jika jenis email spam yang diterima orang berubah secara signifikan, model mungkin tidak lagi dapat mendeteksi spam secara akurat.
Concept Drift dapat dibagi lagi menjadi empat kategori (Learning under Concept Drift: A Review, Jie Lu dkk.):
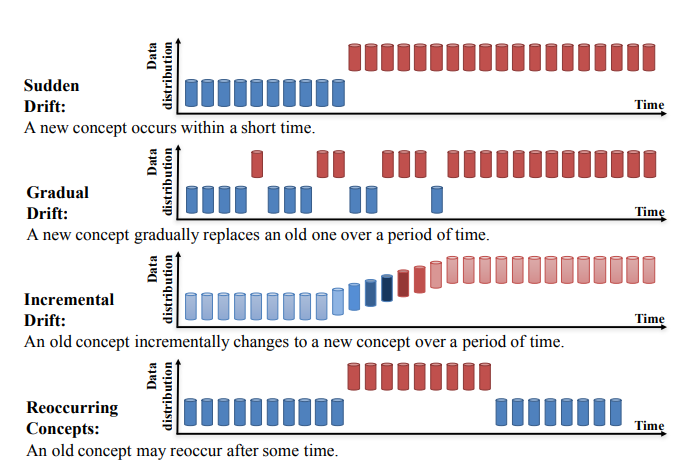
Sumber: https://arxiv.org/pdf/2004.05785.pdf
Data drift, juga dikenal sebagai covariate shift, terjadi ketika distribusi data masukan berubah seiring waktu. Misalnya, pertimbangkan model machine learning yang dilatih untuk memprediksi kemungkinan seorang pelanggan membeli produk berdasarkan usia dan pendapatan. Jika distribusi usia dan pendapatan pelanggan berubah secara signifikan seiring waktu, model mungkin tidak lagi dapat memprediksi kemungkinan pembelian dengan akurat.
Penting untuk menyadari adanya concept drift dan data drift serta mengambil langkah untuk mencegah atau mengurangi dampaknya. Beberapa strategi untuk mengatasi drift meliputi pemantauan dan evaluasi kinerja model secara berkelanjutan, memperbarui model dengan data baru, dan menggunakan model machine learning yang lebih tangguh terhadap drift.
Anda dapat mempelajari lebih lanjut tentang data science pascadeploy, seperti drift, di episode podcast DataFramed kami.
LLM memperkenalkan jenis drift yang tidak dirancang untuk ditangani oleh metode di atas. Datanya bukan baris dalam tabel — melainkan teks bebas — dan yang biasanya bergeser seiring waktu adalah makna dari apa yang ditanyakan pengguna. Saat ini diperkirakan ada tiga bentuk drift LLM yang perlu dipantau.
Embedding drift terjadi ketika makna teks yang dikirim pengguna ke model berubah, meskipun teks permukaannya terlihat sama. LLM mengonversi teks menjadi daftar panjang angka yang disebut embedding, dan drift dapat muncul pada angka-angka tersebut tanpa terlihat pada hal-hal yang biasanya Anda ukur.
Bayangkan chatbot dukungan pelanggan yang awalnya banyak menangani pertanyaan penyiapan dan onboarding. Lalu, enam bulan kemudian, volumenya serta panjang rata-rata pesan tidak berubah, tetapi pengguna kini lebih banyak menanyakan penagihan dan pembatalan. Statistik teks tampak stabil, tetapi distribusi embedding telah bergeser. Untuk mendeteksinya, tim membandingkan batch embedding terbaru dengan batch acuan menggunakan ukuran jarak statistik.
Prompt drift sama idenya dengan embedding drift, tetapi dilacak satu tingkat lebih tinggi. Alih-alih membandingkan embedding mentah, Anda mengelompokkan kueri masuk ke dalam kategori — menggunakan classifier atau LLM lain — dan memantau pergeseran komposisinya.
Bayangkan asisten coding internal yang diluncurkan untuk engineer backend perlahan mulai menerima trafik dari data scientist yang menanyakan pertanyaan pandas. Asisten tersebut mungkin masih mampu menjawab dengan baik, tetapi populasi yang dilayani bukan lagi yang digunakan saat pengujian, dan system prompt atau indeks retrieval lama-kelamaan bisa jadi kurang sesuai.
Rubric drift adalah perubahan seiring waktu pada skor kualitas yang diberikan evaluator otomatis terhadap keluaran model. Banyak tim produksi kini menggunakan LLM sebagai juri, yang memberi skor setiap respons pada aspek seperti kebermanfaatan, akurasi, atau nada. Saat skor tersebut mulai menurun untuk jenis input yang sama, biasanya ada sesuatu yang berubah — model di balik API, dokumen yang diambil, atau komposisi pengguna.
Yang membuat rubric drift sangat berguna adalah ia memberi sinyal kualitas tanpa memerlukan label kebenaran dasar, yang jarang tersedia secara real time untuk keluaran generatif.
Ada dua cara untuk mendeteksi drift:
1. Pendekatan Berbasis Model Machine Learning: Pendekatan berbasis model untuk mendeteksi apakah data masukan yang datang mengalami drift atau tidak.
2. Uji Statistik: Ada banyak uji statistik untuk mendeteksi data drift. Secara utama terbagi menjadi tiga kategori:
Metode berbasis distribusi waktu menggunakan metode statistik untuk menghitung perbedaan antara dua distribusi probabilitas guna mendeteksi drift. Metode ini mencakup Population Stability Index, KL Divergence, JS Divergence, Uji KS, dan Metrik Wasserstein.
Uji Kolmogorov-Smirnov (K-S) adalah uji statistik nonparametrik yang digunakan untuk menentukan apakah dua kumpulan data berasal dari distribusi yang sama. Uji ini sering digunakan untuk menguji apakah sebuah sampel data berasal dari populasi tertentu atau untuk membandingkan dua sampel guna menentukan apakah keduanya berasal dari populasi yang sama.
Hipotesis nol pada uji ini adalah bahwa distribusinya sama. Jika hipotesis ini ditolak, hal tersebut menyiratkan adanya drift pada model.
Uji K-S adalah alat yang berguna untuk membandingkan dataset dan menentukan apakah keduanya berasal dari distribusi yang sama.
Population Stability Index (PSI) adalah ukuran statistik yang digunakan untuk membandingkan distribusi variabel kategorikal pada dua dataset berbeda.
Population Stability Index (PSI) adalah alat untuk mengukur seberapa besar distribusi suatu variabel berubah antara dua sampel atau dari waktu ke waktu. Ini umum digunakan untuk memantau perubahan karakteristik suatu populasi dan mengidentifikasi potensi masalah pada kinerja model machine learning.
PSI awalnya dikembangkan untuk memantau perubahan distribusi skor pada risk scorecard, tetapi kini digunakan untuk menelaah pergeseran distribusi pada semua atribut terkait model, termasuk variabel dependen maupun independen.
Nilai PSI yang tinggi menunjukkan adanya perbedaan signifikan antara distribusi variabel pada dua dataset, yang mungkin mengindikasikan adanya drift pada model.
Jika distribusi suatu variabel berubah secara signifikan, atau jika beberapa variabel berubah hingga tingkat tertentu, mungkin perlu dilakukan kalibrasi ulang atau membangun ulang model untuk meningkatkan performanya.
Metode Page-Hinkley adalah metode statistik yang digunakan untuk mendeteksi perubahan rata-rata suatu deret data dari waktu ke waktu. Metode ini umum digunakan untuk memantau kinerja model machine learning dan mendeteksi perubahan pada distribusi data yang mungkin mengindikasikan model drift.
Untuk menggunakan metode Page-Hinkley, langkah pertama adalah menentukan nilai ambang batas dan fungsi keputusan. Nilai ambang batas adalah nilai di atasnya suatu perubahan pada rata-rata dianggap signifikan, dan fungsi keputusan adalah fungsi yang mengembalikan nilai 1 jika perubahan terdeteksi dan nilai 0 jika tidak ada perubahan yang terdeteksi.
Berikutnya, rata-rata deret data dihitung pada setiap langkah waktu, dan fungsi keputusan diterapkan pada data untuk menentukan apakah terjadi perubahan. Jika fungsi keputusan mengembalikan nilai 1, itu menandakan perubahan telah terdeteksi dan model mungkin mengalami drift.
Metode Page-Hinkley adalah cara yang sederhana dan efektif untuk mendeteksi perubahan rata-rata deret data dari waktu ke waktu. Metode ini sangat berguna untuk mendeteksi perubahan kecil pada rata-rata yang mungkin tidak langsung terlihat saat melihat data. Namun, penting untuk memilih nilai ambang dan fungsi keputusan dengan cermat agar metode ini cukup sensitif untuk mendeteksi perubahan pada data, tetapi tidak terlalu sensitif hingga menimbulkan alarm palsu.
Pada bagian ini, kita akan menggunakan Evidently untuk mendeteksi drift. Evidently adalah pustaka Python open-source yang dibuat untuk data scientist dan engineer yang bekerja dengan machine learning. Pustaka ini membantu mereka menguji, mengevaluasi, dan melacak performa model dari validasi hingga produksi.
import pandas as pd
import numpy as np
from sklearn import datasets
from evidently import Report
from evidently.presets import DataDriftPreset# create ref and cur dataset for drift detection
adult_data = datasets.fetch_openml(name='adult', version=2, as_frame=True)
adult = adult_data.frame
adult_ref = adult[~adult.education.isin(['Some-college', 'HS-grad', 'Bachelors'])].copy()
adult_cur = adult[adult.education.isin(['Some-college', 'HS-grad', 'Bachelors'])].copy()
adult_cur.iloc[:2000, 3:5] = np.nan#dataset-level metrics
report = Report([DataDriftPreset()], include_tests=True)
my_eval = report.run(current_data=adult_cur, reference_data=adult_ref)
my_eval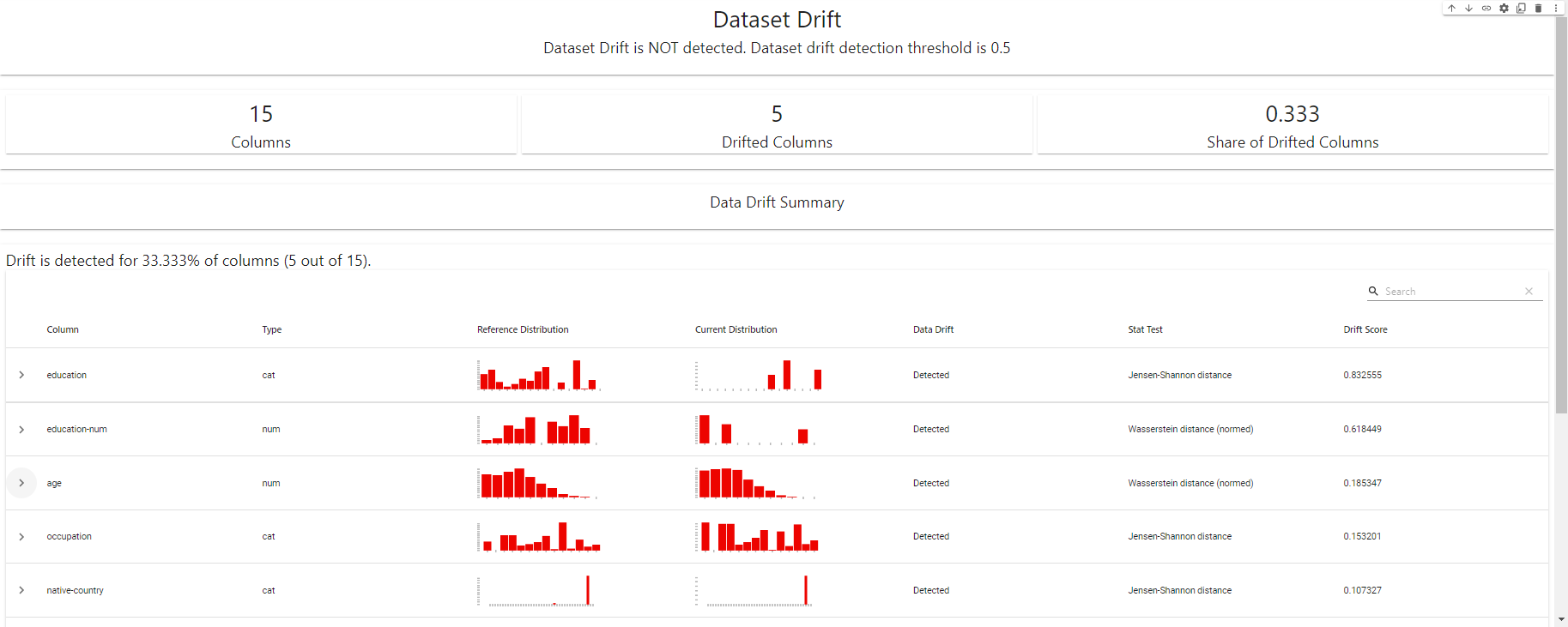
Dasbor Deteksi Drift - dibuat menggunakan EvidentlyAI
#report in a JSON format
my_eval.json()
Lihat Datacamp Notebook lengkapnya di sini.
Data dan model drift dapat menjadi tantangan signifikan bagi sistem machine learning di produksi. Dengan memahami penyebab dan dampak drift, serta menerapkan praktik pemantauan drift yang efektif, Anda dapat memastikan model machine learning tetap akurat dan andal seiring waktu.
Memantau kinerja model, menggunakan model deteksi drift, dan melatih ulang secara berkala dengan data terbaru hanyalah beberapa praktik terbaik yang dapat Anda lakukan untuk mengurangi risiko drift. Dengan bersikap proaktif dalam pemantauan drift, Anda dapat memastikan sistem machine learning terus memberikan nilai bagi organisasi Anda.
Memantau model machine learning terhadap drift hanyalah satu aspek dari bidang yang lebih luas yang disebut MLOps. Memahami konsep MLOps penting bagi setiap data scientist, engineer, atau pemimpin untuk membawa model machine learning dari notebook lokal menjadi model yang berfungsi di produksi.
Jika Anda ingin mendalami pemahaman tentang MLOps dan bagaimana hal itu dapat bermanfaat bagi karier Anda, lihat kursus MLOps Concepts kami. Di sini, Anda akan mempelajari apa itu MLOps, memahami berbagai fase dalam proses MLOps, dan mengidentifikasi berbagai tingkat kematangan MLOps. Setelah mempelajari konsep-konsep MLOps yang esensial, Anda akan siap untuk menerapkan machine learning secara berkelanjutan, andal, dan efisien.
Kursus MLOps
Kursus
Kursus
Kursus
blogs
Hugo Bowne-Anderson
13 mnt
blogs
David Woods
13 mnt
blogs
Dario Radečić
15 mnt
blogs
Javier Canales Luna
14 mnt
