Courses
แนวคิด MLOps
2 ชม.
42.7K
โมเดลแมชชีนเลิร์นนิงถูกฝึกด้วยข้อมูลในอดีต แต่เมื่อถูกนำไปใช้ในโลกจริง โมเดลอาจล้าสมัยและสูญเสียความแม่นยำเมื่อเวลาผ่านไป อันเป็นปรากฏการณ์ที่เรียกว่า drift Drift คือการเปลี่ยนแปลงตามเวลาของคุณสมบัติทางสถิติของข้อมูลที่ใช้ฝึกโมเดลแมชชีนเลิร์นนิง ซึ่งอาจทำให้โมเดลมีความแม่นยำน้อยลงหรือทำงานต่างไปจากที่ออกแบบไว้
กล่าวอีกนัยหนึ่ง "drift" คือความเสื่อมถอยของความสามารถในการพยากรณ์อย่างแม่นยำของโมเดล อันเป็นผลจากการเปลี่ยนแปลงของสภาพแวดล้อมที่โมเดลถูกใช้งาน
มีหลายสาเหตุที่ทำให้โมเดลแมชชีนเลิร์นนิงเกิด drift เมื่อเวลาผ่านไป
สาเหตุหนึ่งที่พบได้บ่อยคือข้อมูลที่โมเดลถูกฝึกนั้นล้าสมัยหรือไม่สะท้อนสภาพการณ์ปัจจุบันอีกต่อไป
ตัวอย่างเช่น โมเดลที่ถูกฝึกเพื่อพยากรณ์ราคาหุ้นจากข้อมูลในอดีต หากฝึกด้วยข้อมูลจากตลาดที่มีเสถียรภาพ ช่วงแรกอาจพยากรณ์ได้ดี อย่างไรก็ตาม หากตลาดมีความผันผวนมากขึ้นเมื่อเวลาผ่านไป โมเดลอาจไม่สามารถพยากรณ์ราคาหุ้นได้อย่างแม่นยำอีกต่อไป เพราะคุณสมบัติทางสถิติของข้อมูลได้เปลี่ยนไป
อีกสาเหตุหนึ่งคือโมเดลไม่ได้ถูกออกแบบมาเพื่อรองรับการเปลี่ยนแปลงของข้อมูล บางโมเดลรับมือกับการเปลี่ยนแปลงของข้อมูลได้ดีกว่าแบบอื่น ๆ แต่ไม่มีโมเดลใดสามารถหลีกเลี่ยง drift ได้อย่างสมบูรณ์
มาดูสองประเภทของ drift ที่ควรพิจารณา:
Concept drift หรือที่เรียกว่า model drift เกิดขึ้นเมื่อภารกิจที่โมเดลถูกออกแบบมาให้ทำมีการเปลี่ยนแปลงตามเวลา ตัวอย่างเช่น โมเดลที่ฝึกเพื่อจำแนกอีเมลสแปมจากเนื้อหา หากประเภทของอีเมลสแปมที่ผู้คนได้รับเปลี่ยนไปอย่างมีนัยสำคัญ โมเดลอาจไม่สามารถตรวจจับสแปมได้อย่างแม่นยำอีกต่อไป
Concept drift สามารถแบ่งย่อยได้เป็นสี่ประเภท (Learning under Concept Drift: A Review, Jie Lu และคณะ):
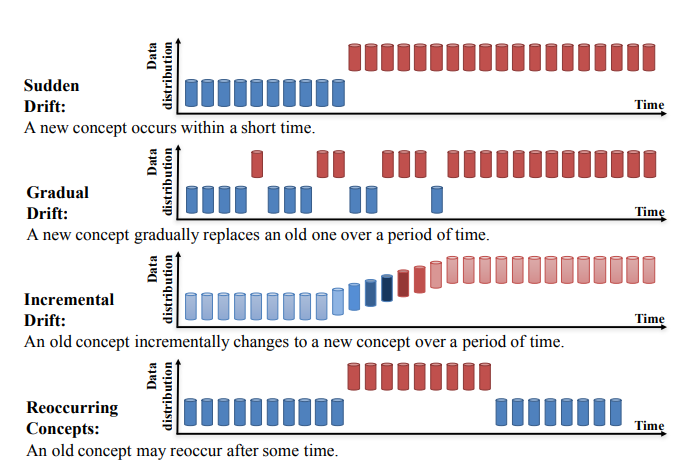
ที่มา: https://arxiv.org/pdf/2004.05785.pdf
Data drift หรือที่เรียกว่า covariate shift เกิดขึ้นเมื่อการกระจายของข้อมูลอินพุตเปลี่ยนแปลงไปตามเวลา ตัวอย่างเช่น โมเดลที่ฝึกเพื่อพยากรณ์ความน่าจะเป็นที่ลูกค้าจะซื้อสินค้าโดยอาศัยอายุและรายได้ หากการกระจายของอายุและรายได้ของลูกค้าเปลี่ยนไปอย่างมีนัยสำคัญเมื่อเวลาผ่านไป โมเดลอาจไม่สามารถพยากรณ์ความน่าจะเป็นในการซื้อได้อย่างแม่นยำ
ทั้ง concept drift และ data drift ล้วนสำคัญต่อการเฝ้าระวัง และควรมีมาตรการป้องกันหรือบรรเทาผลกระทบ วิธีการรับมือ drift อาทิ เฝ้าติดตามและประเมินประสิทธิภาพของโมเดลอย่างต่อเนื่อง อัปเดตโมเดลด้วยข้อมูลใหม่ และใช้โมเดลที่ทนทานต่อ drift มากกว่า
สามารถเรียนรู้เพิ่มเติมเกี่ยวกับ วิทยาการข้อมูลหลังการปรับใช้ เช่น drift ได้จากตอนพอดแคสต์ DataFramed ของเรา
LLM นำเสนอรูปแบบของ drift ที่วิธีการข้างต้นไม่ได้ถูกออกแบบมารองรับ ข้อมูลไม่ได้เป็นแถวในตาราง แต่เป็นข้อความอิสระ และสิ่งที่เปลี่ยนไปตามเวลามักเป็นความหมายของสิ่งที่ผู้ใช้สอบถาม ปัจจุบันมองว่ามี LLM drift อยู่สามรูปแบบหลักที่ควรเฝ้าระวัง
Embedding drift เกิดขึ้นเมื่อความหมายของข้อความที่ผู้ใช้ส่งให้โมเดลเปลี่ยน แม้ผิวเผินข้อความจะดูเหมือนเดิม LLM แปลงข้อความเป็นรายการตัวเลขยาว ๆ ที่เรียกว่า embedding และ drift อาจปรากฏในตัวเลขเหล่านั้นโดยไม่สะท้อนในสิ่งที่ปกติใช้วัด
ลองนึกถึงแชตบอทซัพพอร์ตลูกค้าที่เดิมตอบคำถามเรื่องติดตั้งและเริ่มต้นใช้งานเป็นหลัก ผ่านไปหกเดือน ปริมาณข้อความและความยาวเฉลี่ยไม่เปลี่ยน แต่ผู้ใช้หันมาถามเรื่องการเรียกเก็บเงินและการยกเลิกมากขึ้น สถิติของข้อความดูคงที่ แต่การกระจายของ embedding เปลี่ยนไป เพื่อให้ตรวจจับได้ ทีมงานจะเปรียบเทียบชุด embedding ล่าสุดกับชุดอ้างอิงโดยใช้มาตรวัดระยะทางทางสถิติ
Prompt drift มีแนวคิดเดียวกับ embedding drift แต่ติดตามในระดับที่สูงขึ้น แทนที่จะเปรียบเทียบ embedding ดิบ จะจัดกลุ่มคำถามขาเข้าเป็นหมวดหมู่ — โดยใช้ตัวจำแนกหรือ LLM อีกตัว — แล้วเฝ้าดูการเปลี่ยนแปลงของสัดส่วน
ตัวอย่างเช่น ผู้ช่วยเขียนโค้ดภายในที่เปิดให้วิศวกรแบ็กเอนด์ใช้งาน อาจค่อย ๆ ได้ทราฟฟิกจากนักวิทยาการข้อมูลที่ถามเรื่อง pandas มากขึ้น ผู้ช่วยอาจยังตอบได้ดี แต่ประชากรผู้ใช้ไม่ใช่กลุ่มเดิมที่เคยทดสอบ และ system prompt หรือดัชนีการค้นคืนอาจค่อย ๆ ไม่เหมาะสมที่สุด
Rubric drift คือการเปลี่ยนแปลงตามเวลาในคะแนนคุณภาพที่ตัวประเมินอัตโนมัติให้กับผลลัพธ์ของโมเดล หลายทีมโปรดักชันใช้ LLM เป็นผู้ตัดสิน ให้คะแนนแต่ละคำตอบในประเด็นอย่างความช่วยเหลือ ความถูกต้อง หรือโทน เมื่อคะแนนเริ่มลดลงสำหรับอินพุตชนิดเดิม มักแปลว่ามีบางอย่างเปลี่ยนไป — ไม่ว่าจะเป็นโมเดลหลัง API เอกสารที่ใช้ค้นคืน หรือสัดส่วนผู้ใช้
สิ่งที่ทำให้ rubric drift มีประโยชน์เป็นพิเศษคือให้สัญญาณด้านคุณภาพโดยไม่ต้องพึ่งป้ายกำกับ ground truth ซึ่งมักไม่มีให้แบบเรียลไทม์สำหรับผลลัพธ์แบบกำเนิด
มีสองแนวทางในการตรวจจับ drift:
1. แนวทางอิงโมเดลแมชชีนเลิร์นนิง: ใช้โมเดลเพื่อตรวจว่าข้อมูลอินพุตที่เข้ามาเกิด drift หรือไม่
2. การทดสอบทางสถิติ: มีการทดสอบทางสถิติจำนวนมากเพื่อตรวจจับ data drift โดยหลักแบ่งเป็นสามกลุ่ม:
วิธีที่อาศัยการกระจายตามเวลาใช้สถิติคำนวณความแตกต่างระหว่างการกระจายความน่าจะเป็นสองชุดเพื่อบ่งชี้ drift วิธีเหล่านี้รวมถึง Population Stability Index, KL Divergence, JS Divergence, KS Test และ Wasserstein Metric
การทดสอบ Kolmogorov-Smirnov (K-S) เป็นการทดสอบทางสถิติแบบไม่อาศัยพารามิเตอร์ ใช้เพื่อตรวจว่าข้อมูลสองชุดมาจากการกระจายเดียวกันหรือไม่ มักใช้ทดสอบว่าตัวอย่างข้อมูลมาจากประชากรที่ระบุไว้ หรือเปรียบเทียบสองตัวอย่างว่าอยู่ในประชากรเดียวกันหรือไม่
สมมติฐานศูนย์ของการทดสอบนี้คือการกระจายเหมือนกัน หากปฏิเสธสมมติฐานนี้ แสดงว่ามี drift ในโมเดล
การทดสอบ K-S เป็นเครื่องมือที่เป็นประโยชน์สำหรับการเปรียบเทียบชุดข้อมูลและตรวจว่ามาจากการกระจายเดียวกันหรือไม่
Population Stability Index (PSI) เป็นตัวชี้วัดทางสถิติที่ใช้เปรียบเทียบการกระจายของตัวแปรเชิงหมวดหมู่ระหว่างชุดข้อมูลสองชุด
PSI ใช้วัดว่าการกระจายของตัวแปรเปลี่ยนแปลงไปมากน้อยเพียงใดระหว่างสองตัวอย่างหรือเมื่อเวลาผ่านไป มักใช้เฝ้าติดตามการเปลี่ยนแปลงของลักษณะประชากร และระบุปัญหาที่อาจเกิดขึ้นกับประสิทธิภาพของโมเดลแมชชีนเลิร์นนิง
เดิม PSI ถูกพัฒนามาเพื่อเฝ้าการกระจายของคะแนนในสกอร์การ์ดความเสี่ยง แต่ปัจจุบันใช้ตรวจสอบการเปลี่ยนแปลงการกระจายสำหรับแอตทริบิวต์ที่เกี่ยวกับโมเดลทั้งหมด ทั้งตัวแปรตามและอิสระ
ค่า PSI ที่สูงบ่งชี้ว่ามีความแตกต่างอย่างมีนัยสำคัญระหว่างการกระจายของตัวแปรในสองชุดข้อมูล ซึ่งอาจเป็นสัญญาณของ drift ในโมเดล
หากการกระจายของตัวแปรเปลี่ยนอย่างมีนัยสำคัญ หรือหลายตัวแปรเปลี่ยนในระดับหนึ่ง อาจจำเป็นต้องปรับเทียบใหม่หรือสร้างโมเดลใหม่เพื่อปรับปรุงประสิทธิภาพ
วิธี Page-Hinkley เป็นวิธีทางสถิติสำหรับตรวจจับการเปลี่ยนแปลงของค่าเฉลี่ยของอนุกรมข้อมูลตามเวลา มักใช้เฝ้าติดตามประสิทธิภาพของโมเดลแมชชีนเลิร์นนิง และตรวจจับการเปลี่ยนแปลงของการกระจายข้อมูลที่อาจบ่งชี้ถึง model drift
การใช้วิธี Page-Hinkley ขั้นแรกคือกำหนดค่า threshold และฟังก์ชันตัดสินใจ ค่า threshold คือค่าที่สูงกว่าซึ่งจะถือว่าการเปลี่ยนค่าเฉลี่ยนั้นมีนัยสำคัญ และฟังก์ชันตัดสินใจจะคืนค่า 1 เมื่อพบการเปลี่ยนแปลง และ 0 เมื่อไม่พบ
จากนั้นคำนวณค่าเฉลี่ยของอนุกรมข้อมูลในแต่ละช่วงเวลา และใช้ฟังก์ชันตัดสินใจเพื่อตรวจว่ามีการเปลี่ยนแปลงเกิดขึ้นหรือไม่ หากฟังก์ชันตัดสินใจคืนค่า 1 แสดงว่าตรวจพบการเปลี่ยนแปลงและโมเดลอาจกำลังเกิด drift
วิธี Page-Hinkley ใช้ง่ายและมีประสิทธิภาพในการตรวจจับการเปลี่ยนแปลงของค่าเฉลี่ยตามเวลา โดยเฉพาะการเปลี่ยนแปลงเล็กน้อยที่อาจมองไม่เห็นจากการดูข้อมูลด้วยตา อย่างไรก็ตาม การเลือกค่า threshold และฟังก์ชันตัดสินใจต้องระมัดระวังเพื่อให้มีความไวพอที่จะตรวจจับการเปลี่ยนแปลง โดยไม่ไวเกินไปจนเกิดสัญญาณเตือนผิดพลาด
ในส่วนนี้ เราจะใช้ Evidently เพื่อตรวจจับ drift Evidently เป็นไลบรารี Python แบบโอเพ่นซอร์สสำหรับนักวิทยาการข้อมูลและวิศวกรที่ทำงานกับแมชชีนเลิร์นนิง ช่วยทดสอบ ประเมิน และติดตามประสิทธิภาพของโมเดลตั้งแต่ช่วงตรวจสอบความถูกต้องจนถึงขึ้นโปรดักชัน
import pandas as pd
import numpy as np
from sklearn import datasets
from evidently import Report
from evidently.presets import DataDriftPreset# create ref and cur dataset for drift detection
adult_data = datasets.fetch_openml(name='adult', version=2, as_frame=True)
adult = adult_data.frame
adult_ref = adult[~adult.education.isin(['Some-college', 'HS-grad', 'Bachelors'])].copy()
adult_cur = adult[adult.education.isin(['Some-college', 'HS-grad', 'Bachelors'])].copy()
adult_cur.iloc[:2000, 3:5] = np.nan#dataset-level metrics
report = Report([DataDriftPreset()], include_tests=True)
my_eval = report.run(current_data=adult_cur, reference_data=adult_ref)
my_eval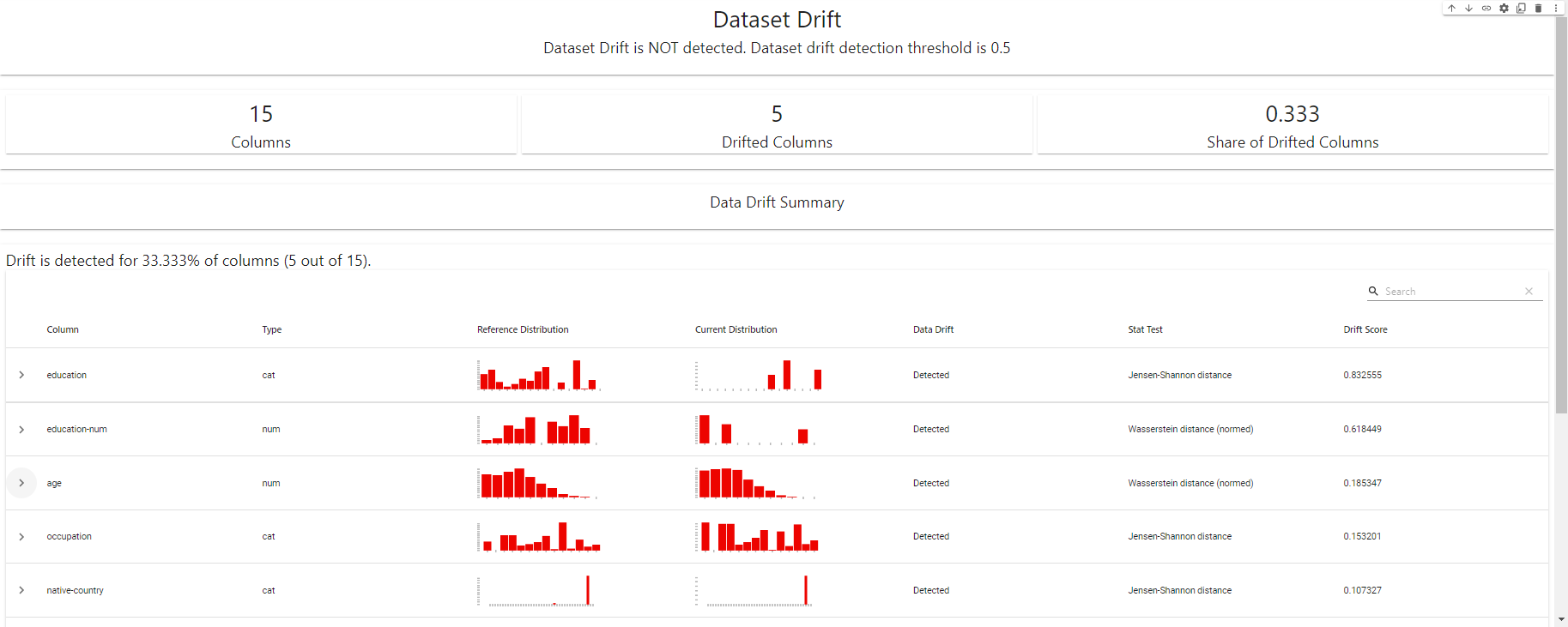
แดชบอร์ดตรวจจับ Drift - สร้างด้วย EvidentlyAI
#report in a JSON format
my_eval.json()
ชมโน้ตบุ๊ก Datacamp แบบสมบูรณ์ได้ ที่นี่
Data drift และ model drift อาจสร้างความท้าทายอย่างมากให้กับระบบแมชชีนเลิร์นนิงในโปรดักชัน ด้วยความเข้าใจสาเหตุและผลกระทบของ drift และการตั้งระบบเฝ้าระวังที่มีประสิทธิภาพ จะช่วยให้โมเดลแมชชีนเลิร์นนิงคงความแม่นยำและความน่าเชื่อถือเมื่อเวลาผ่านไป
การติดตามประสิทธิภาพของโมเดล ใช้โมเดลตรวจจับ drift และฝึกใหม่อย่างสม่ำเสมอด้วยข้อมูลที่อัปเดต เป็นแนวปฏิบัติบางส่วนที่ช่วยลดความเสี่ยงจาก drift ได้ ด้วยการเฝ้าระวังเชิงรุก จะช่วยให้ระบบแมชชีนเลิร์นนิงยังคงส่งมอบคุณค่าแก่องค์กรได้อย่างต่อเนื่อง
การเฝ้าระวังโมเดลแมชชีนเลิร์นนิงเรื่อง drift เป็นเพียงแง่มุมหนึ่งของสาขาที่กว้างกว่าอย่าง MLOps การทำความเข้าใจแนวคิด MLOps เป็นสิ่งจำเป็นสำหรับนักวิทยาการข้อมูล วิศวกร หรือผู้นำ ที่ต้องการพาโมเดลจากโน้ตบุ๊กสู่ระบบที่ทำงานจริงในโปรดักชัน
หากต้องการเจาะลึกเพื่อทำความเข้าใจ MLOps และประโยชน์ต่ออาชีพของคุณ ลองดูคอร์ส MLOps Concepts ที่นี่จะได้เรียนรู้ว่า MLOps คืออะไร ทำความเข้าใจเฟสต่าง ๆ ในกระบวนการ MLOps และระดับความพร้อมของ MLOps หลังจากเรียนรู้แนวคิดสำคัญแล้ว จะพร้อมสำหรับการนำแมชชีนเลิร์นนิงไปใช้ได้อย่างต่อเนื่อง น่าเชื่อถือ และมีประสิทธิภาพ
คอร์ส MLOps
Courses
Courses
Courses