
Curso
Conceitos de MLOps
2 h
42.6K
Modelos de machine learning são treinados com dados históricos, mas, quando entram em produção, podem ficar desatualizados e perder precisão ao longo do tempo por conta de um fenômeno chamado drift. Drift é a mudança, com o passar do tempo, nas propriedades estatísticas dos dados usados para treinar um modelo. Isso pode fazer com que o modelo fique menos preciso ou se comporte de forma diferente do planejado.
Em outras palavras, “drift” é a queda na capacidade de um modelo de fazer previsões precisas devido a mudanças no ambiente em que ele é usado.
Há várias razões pelas quais os modelos podem apresentar drift ao longo do tempo.
Um motivo comum é simplesmente o fato de que os dados usados no treinamento ficam desatualizados ou deixam de representar as condições atuais.
Por exemplo, considere um modelo treinado para prever o preço de uma ação com base em dados históricos. Se o modelo foi treinado com dados de um mercado estável, ele pode ir bem no começo. Porém, se o mercado ficar mais volátil com o tempo, o modelo pode não conseguir mais prever os preços com precisão porque as propriedades estatísticas dos dados mudaram.
Outro motivo para o model drift é o modelo não ter sido projetado para lidar com mudanças nos dados. Alguns modelos lidam melhor com mudanças do que outros, mas nenhum é completamente imune ao drift.
Vamos explorar dois tipos principais de drift:
Concept drift, também chamado de model drift, ocorre quando a tarefa para a qual o modelo foi projetado muda com o tempo. Por exemplo, imagine um modelo treinado para detectar spam com base no conteúdo do e-mail. Se os tipos de spam que as pessoas recebem mudarem significativamente, o modelo pode deixar de identificar spam com precisão.
O concept drift pode ser subdividido em quatro categorias (Learning under Concept Drift: A Review, Jie Lu et al.):
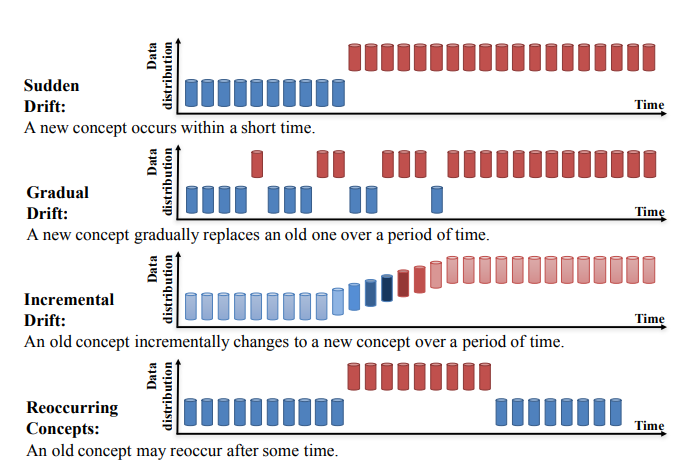
Fonte: https://arxiv.org/pdf/2004.05785.pdf
Data drift, também conhecido como covariate shift, acontece quando a distribuição dos dados de entrada muda ao longo do tempo. Por exemplo, considere um modelo treinado para prever a probabilidade de um cliente comprar um produto com base em idade e renda. Se a distribuição de idades e rendas dos clientes mudar significativamente, o modelo pode deixar de prever compras com precisão.
É importante estar atento tanto ao concept drift quanto ao data drift e adotar medidas para prevenir ou mitigar seus efeitos. Algumas estratégias incluem monitorar continuamente o desempenho do modelo, atualizá-lo com novos dados e usar modelos mais robustos a drift.
Você pode aprender mais sobre data science pós-implantação, como drift, neste episódio do podcast DataFramed.
LLMs introduzem um tipo de drift para o qual os métodos acima não foram feitos. Os dados não são linhas em uma tabela — é texto livre — e o que muda ao longo do tempo costuma ser o significado do que os usuários estão pedindo. Hoje se considera que há três formas de drift em LLMs a serem monitoradas.
Embedding drift acontece quando o significado do texto enviado ao modelo muda, mesmo que o texto na superfície pareça igual. LLMs convertem texto em longas listas de números chamadas embeddings, e o drift pode aparecer nesses números sem aparecer em nada do que você normalmente mediria.
Imagine um chatbot de suporte que, no início, recebia principalmente perguntas de setup e onboarding. Seis meses depois, o volume de mensagens e o tamanho médio continuam iguais, mas agora os usuários perguntam mais sobre cobrança e cancelamentos. As estatísticas textuais parecem estáveis, mas a distribuição dos embeddings mudou. Para detectar isso, as equipes comparam lotes recentes de embeddings com um lote de referência usando uma medida de distância estatística.
O drift de prompt segue a mesma ideia do embedding drift, mas observado um nível acima. Em vez de comparar embeddings brutos, você agrupa as consultas em categorias — com um classificador ou outro LLM — e monitora mudanças no mix.
Imagine um assistente interno de código lançado para engenheiros de backend que, aos poucos, começa a receber tráfego de cientistas de dados com dúvidas sobre pandas. O assistente pode até responder bem, mas o público atendido já não é o mesmo do teste, e o prompt do sistema ou o índice de recuperação pode deixar de ser o ideal.
Rubric drift é a mudança, ao longo do tempo, nas notas de qualidade que um avaliador automatizado atribui às respostas de um modelo. Muitos times em produção usam um LLM como juiz, pontuando cada resposta por critérios como utilidade, precisão ou tom. Quando essas notas começam a cair para os mesmos tipos de entrada, algo geralmente mudou — o modelo por trás da API, os documentos recuperados ou o perfil de usuários.
O que torna o rubric drift especialmente útil é fornecer um sinal de qualidade sem precisar de rótulos de verdade terrestre, que raramente estão disponíveis em tempo real para saídas generativas.
Existem duas formas de detectar drift:
1. Abordagem baseada em modelo de machine learning: usar um modelo para detectar se os dados de entrada recentes sofreram drift.
2. Testes estatísticos: há vários testes estatísticos para detectar data drift. Eles se dividem principalmente em três categorias:
Métodos baseados em distribuição temporal usam técnicas estatísticas para calcular a diferença entre duas distribuições de probabilidade e detectar drift. Esses métodos incluem Population Stability Index, divergência KL, divergência JS, teste KS e a métrica de Wasserstein.
O teste de Kolmogorov–Smirnov (K-S) é um teste estatístico não paramétrico usado para verificar se dois conjuntos de dados vêm da mesma distribuição. Ele é frequentemente aplicado para avaliar se uma amostra vem de uma população específica ou para comparar duas amostras e determinar se pertencem à mesma população.
A hipótese nula desse teste é que as distribuições são iguais. Se essa hipótese for rejeitada, isso sugere a presença de drift no modelo.
O teste K-S é uma ferramenta útil para comparar conjuntos de dados e determinar se eles vêm da mesma distribuição.
O Population Stability Index (PSI) é uma medida estatística usada para comparar a distribuição de uma variável em duas bases de dados diferentes.
O PSI mede o quanto a distribuição de uma variável mudou entre duas amostras ou ao longo do tempo. É comum no monitoramento de mudanças nas características de uma população e na identificação de possíveis problemas no desempenho de um modelo de machine learning.
O PSI foi criado originalmente para acompanhar mudanças na distribuição de scores em scorecards de risco, mas hoje é usado para examinar mudanças de distribuição em todos os atributos relacionados ao modelo, incluindo variáveis dependentes e independentes.
Um valor alto de PSI indica diferença significativa entre as distribuições da variável nas duas bases, o que pode sugerir drift no modelo.
Se a distribuição de uma variável mudou muito — ou se várias variáveis mudaram em algum grau — pode ser necessário recalibrar ou reconstruir o modelo para melhorar seu desempenho.
O método de Page–Hinkley é uma técnica estatística para detectar mudanças na média de uma série temporal de dados. Ele é amplamente usado para monitorar o desempenho de modelos de machine learning e identificar alterações na distribuição dos dados que possam indicar model drift.
Para usar o método de Page–Hinkley, o primeiro passo é definir um valor de limiar e uma função de decisão. O limiar é o valor acima do qual uma mudança na média é considerada significativa, e a função de decisão retorna 1 se uma mudança for detectada e 0 caso contrário.
Em seguida, calcula-se a média da série a cada instante e aplica-se a função de decisão para verificar se ocorreu uma mudança. Se a função retornar 1, isso indica que uma mudança foi detectada e que o modelo pode estar sofrendo drift.
O método de Page–Hinkley é simples e eficaz para detectar mudanças na média de uma série ao longo do tempo. Ele é especialmente útil para identificar mudanças pequenas que não seriam tão aparentes a olho nu. No entanto, é importante escolher bem o limiar e a função de decisão para garantir sensibilidade suficiente sem gerar alarmes falsos.
Nesta seção, vamos usar o Evidently para detectar drift. Evidently é uma biblioteca open source em Python feita para cientistas de dados e engenheiros que trabalham com machine learning. Ela ajuda a testar, avaliar e acompanhar o desempenho dos modelos, do período de validação até a produção.
import pandas as pd
import numpy as np
from sklearn import datasets
from evidently import Report
from evidently.presets import DataDriftPreset# create ref and cur dataset for drift detection
adult_data = datasets.fetch_openml(name='adult', version=2, as_frame=True)
adult = adult_data.frame
adult_ref = adult[~adult.education.isin(['Some-college', 'HS-grad', 'Bachelors'])].copy()
adult_cur = adult[adult.education.isin(['Some-college', 'HS-grad', 'Bachelors'])].copy()
adult_cur.iloc[:2000, 3:5] = np.nan#dataset-level metrics
report = Report([DataDriftPreset()], include_tests=True)
my_eval = report.run(current_data=adult_cur, reference_data=adult_ref)
my_eval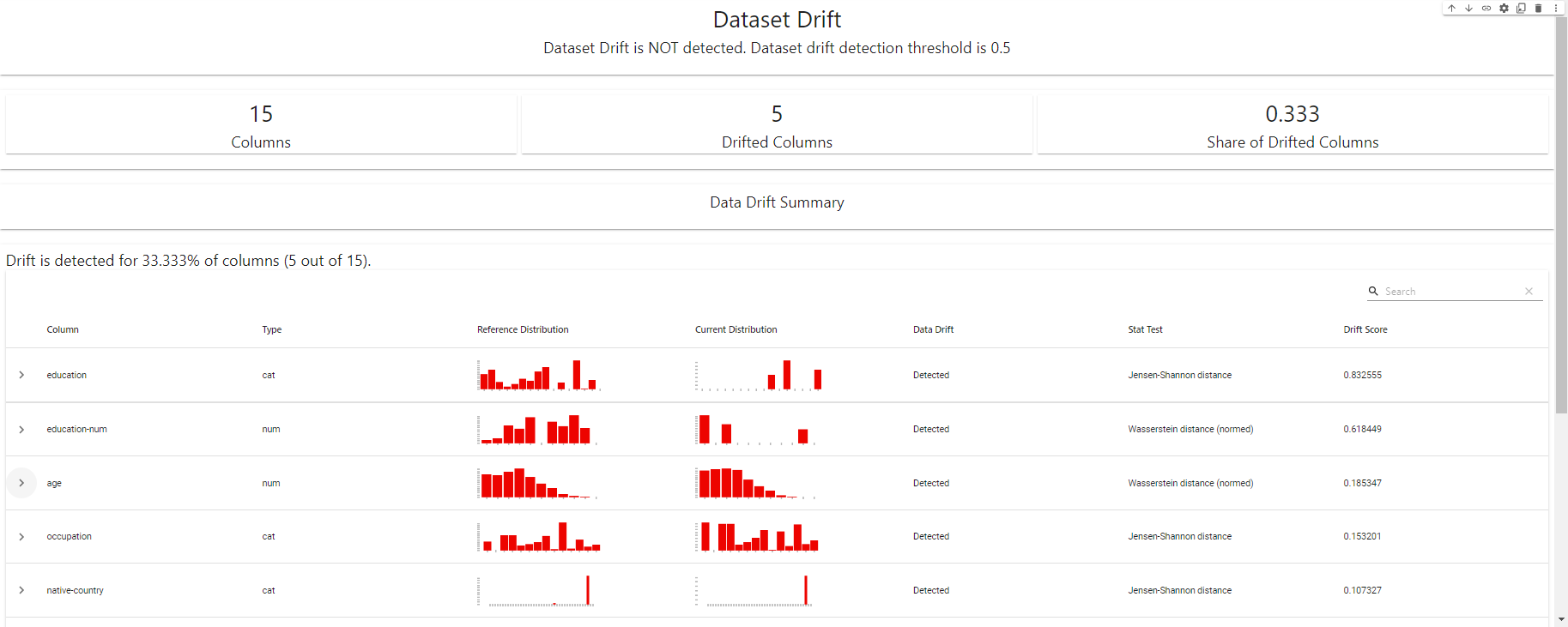
Drift Detection Dashboard - criado com EvidentlyAI
#report in a JSON format
my_eval.json()
Confira o Notebook completo da Datacamp aqui.
Data drift e model drift podem trazer desafios importantes para sistemas de machine learning em produção. Ao entender as causas e os efeitos do drift e implementar práticas eficazes de monitoramento, você garante que seus modelos continuem precisos e confiáveis ao longo do tempo.
Monitorar o desempenho, usar um modelo de detecção de drift e retreinar regularmente com dados atualizados são algumas das melhores práticas para mitigar riscos. Ao ser proativo no monitoramento de drift, você assegura que seu sistema de machine learning continue gerando valor para a sua organização.
Monitorar drift em modelos é apenas um aspecto de uma área mais ampla chamada MLOps. Entender os conceitos de MLOps é essencial para qualquer cientista de dados, engenheiro ou líder que queira levar modelos de um notebook local para produção de forma robusta.
Se quiser se aprofundar em MLOps e como isso pode impulsionar sua carreira, confira nosso curso MLOps Concepts. Nele, você vai entender o que é MLOps, conhecer as diferentes fases dos processos e identificar os níveis de maturidade em MLOps. Depois de dominar os conceitos essenciais, você estará pronto para implementar machine learning de forma contínua, confiável e eficiente.
Cursos de MLOps
Curso
Curso
Curso
Tutorial
DataCamp Team
Tutorial
Avinash Navlani
Tutorial
Moez Ali
Tutorial
Abid Ali Awan
Tutorial
Thushan Ganegedara
Tutorial
Abid Ali Awan
