
Kurs
MLOps-Konzepte
2 Std.
42.6K
Machine-Learning-Modelle werden mit historischen Daten trainiert. Im Einsatz können sie jedoch veralten und an Genauigkeit verlieren – dieses Phänomen nennt man Drift. Drift beschreibt die zeitliche Veränderung der statistischen Eigenschaften der Daten, mit denen ein Modell trainiert wurde. Dadurch wird das Modell ungenauer oder verhält sich anders als vorgesehen.
Anders gesagt: „Drift“ ist der Rückgang der Vorhersagequalität eines Modells aufgrund von Änderungen in seiner Einsatzumgebung.
Es gibt mehrere Gründe, warum ML-Modelle mit der Zeit driften.
Ein häufiger Grund: Die Trainingsdaten sind veraltet und spiegeln die aktuellen Bedingungen nicht mehr wider.
Nehmen wir ein Modell, das Aktienkurse anhand historischer Daten vorhersagt. Wurde es in einer stabilen Marktphase trainiert, funktioniert es anfangs gut. Wird der Markt später volatiler, kann das Modell möglicherweise nicht mehr zuverlässig vorhersagen, weil sich die statistischen Eigenschaften der Daten verändert haben.
Ein weiterer Grund: Das Modell ist nicht dafür ausgelegt, mit Änderungen in den Daten umzugehen. Manche Modelle sind robuster als andere – ganz vermeiden lässt sich Drift jedoch nie.
Es gibt im Wesentlichen zwei Driftarten, die du im Blick behalten solltest:
Concept Drift, auch Model Drift genannt, tritt auf, wenn sich die zu lösende Aufgabe im Zeitverlauf verändert. Beispiel: Ein Modell wurde darauf trainiert, Spam-E-Mails anhand ihres Inhalts zu erkennen. Ändern sich die Spam-Muster deutlich, erkennt das Modell Spam womöglich nicht mehr zuverlässig.
Concept Drift lässt sich weiter in vier Kategorien einteilen (Learning under Concept Drift: A Review, Jie Lu et al.):
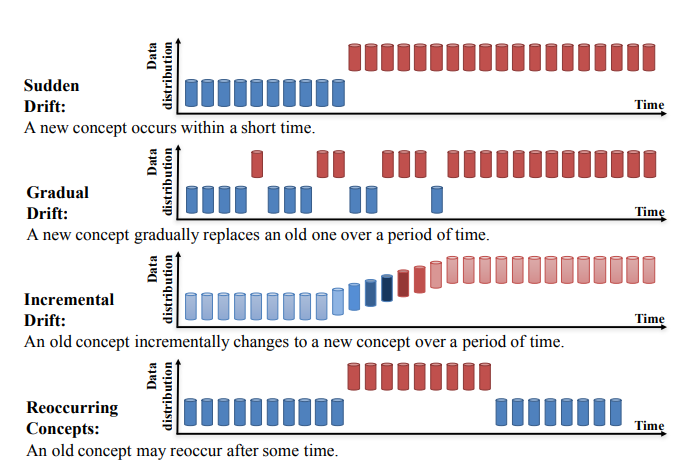
Quelle: https://arxiv.org/pdf/2004.05785.pdf
Data Drift, auch Covariate Shift, bezeichnet die Veränderung der Verteilung der Eingabedaten. Beispiel: Ein Modell sagt die Kaufwahrscheinlichkeit anhand von Alter und Einkommen voraus. Verschiebt sich die Verteilung von Alter und Einkommen der Kundschaft stark, sinkt die Genauigkeit der Vorhersagen.
Wichtig ist, sowohl Concept Drift als auch Data Drift zu kennen und Gegenmaßnahmen zu ergreifen. Strategien sind u. a.: kontinuierliches Monitoring und Evaluieren der Modellleistung, regelmäßige Updates mit neuen Daten sowie der Einsatz driftrobuster Modellansätze.
Mehr über Post-Deployment Data Science, inklusive Drift, erfährst du in unserer DataFramed-Podcastfolge.
LLMs bringen eine Driftform mit, für die die oben genannten Methoden nicht gedacht sind. Die Daten sind kein Tabellengerüst, sondern Freitext – und was sich ändert, ist meist die Bedeutung dessen, was Nutzer fragen. Inzwischen geht man von drei Formen der LLM-Drift aus, die du überwachen solltest.
Embedding-Drift entsteht, wenn sich die Bedeutung der Texte ändert, die Nutzer an ein Modell schicken – auch wenn der sichtbare Text gleich aussieht. LLMs wandeln Text in lange Zahlenvektoren, sogenannte Embeddings, um. Drift kann sich in diesen Zahlen zeigen, ohne dass sie in herkömmlichen Textmetriken sichtbar wäre.
Stell dir einen Support-Chatbot vor, der anfangs vor allem Fragen zu Setup und Onboarding beantwortet. Sechs Monate später sind Volumen und durchschnittliche Länge der Nachrichten unverändert, aber es geht nun überwiegend um Abrechnung und Kündigungen. Textstatistiken wirken stabil, doch die Embedding-Verteilung hat sich verschoben. Zur Erkennung vergleichen Teams Chargen aktueller Embeddings mit einer Referenzcharge über ein statistisches Distanzmaß.
Prompt-Drift folgt der gleichen Idee wie Embedding-Drift, nur eine Ebene höher. Statt roher Embeddings werden eingehende Anfragen in Kategorien geclustert – per Klassifikator oder einem weiteren LLM – und Verschiebungen im Mix beobachtet.
Ein interner Coding-Assistent für Backend-Engineers könnte allmählich immer mehr Anfragen von Data Scientists zu pandas erhalten. Der Assistent antwortet vielleicht weiterhin solide, aber die adressierte Zielgruppe entspricht nicht mehr der getesteten, und System-Prompt oder Retrieval-Index passen mit der Zeit nicht mehr optimal.
Rubric-Drift ist eine zeitliche Veränderung der Qualitätswerte, die ein automatischer Bewerter für Modellantworten vergibt. Viele Teams setzen inzwischen ein LLM als „Richter“ ein und bewerten Antworten nach Nützlichkeit, Genauigkeit oder Tonalität. Sinken diese Scores bei gleichartigen Inputs, hat sich meist etwas geändert – das Modell hinter einer API, die genutzten Dokumente oder der Nutzermix.
Besonders nützlich ist Rubric-Drift, weil sie ein Qualitätssignal liefert, ohne Ground-Truth-Labels zu benötigen – die es für generative Outputs in Echtzeit selten gibt.
Es gibt zwei grundlegende Ansätze zur Drifterkennung:
1. Modellbasierter ML-Ansatz: Ein separates Modell prüft, ob sich die eingehenden Eingabedaten verschoben haben.
2. Statistische Tests: Zahlreiche Tests erkennen Data Drift. Grob lassen sie sich in drei Kategorien einteilen:
Verteilungsbasierte Methoden messen statistisch den Unterschied zwischen zwei Wahrscheinlichkeitsverteilungen, um Drift zu erkennen. Dazu gehören Population Stability Index, KL-Divergenz, JS-Divergenz, KS-Test und die Wasserstein-Metrik.
Der Kolmogorov-Smirnov-(K-S)-Test ist ein nichtparametrischer Test, der prüft, ob zwei Datensätze aus derselben Verteilung stammen. Er wird häufig genutzt, um eine Stichprobe mit einer Referenzpopulation zu vergleichen oder zwei Stichproben gegeneinander zu testen.
Die Nullhypothese lautet, dass die Verteilungen identisch sind. Wird sie verworfen, deutet das auf Drift hin.
Der K-S-Test ist ein nützliches Werkzeug, um Datensätze zu vergleichen und Verteilungsunterschiede zu erkennen.
Der Population Stability Index (PSI) ist ein statistisches Maß, das die Verteilung einer Variablen zwischen zwei Datensätzen vergleicht.
Mit dem PSI misst du, wie stark sich die Verteilung einer Variablen zwischen zwei Stichproben oder im Zeitverlauf verändert hat. Häufig wird er genutzt, um Populationsänderungen zu überwachen und potenzielle Performanceprobleme eines Modells zu identifizieren.
Ursprünglich für Risikoscorecards entwickelt, wird der PSI heute breit eingesetzt, um Verteilungsverschiebungen bei allen modellrelevanten Attributen zu prüfen – abhängige wie unabhängige Variablen.
Ein hoher PSI-Wert weist auf einen signifikanten Verteilungsunterschied hin und kann auf Modelldrift hindeuten.
Haben sich einzelne Variablen stark oder viele Variablen merklich verschoben, kann eine Neukalibrierung oder ein Rebuild des Modells nötig sein.
Die Page-Hinkley-Methode erkennt Veränderungen im Mittelwert einer Datenreihe über die Zeit. Sie wird häufig genutzt, um ML-Modelle zu überwachen und Verteilungsänderungen zu identifizieren, die auf Modelldrift hindeuten.
Zunächst legst du einen Schwellwert und eine Entscheidungsfunktion fest. Überschreitet der kumulierte Unterschied den Schwellwert, signalisiert die Funktion eine Änderung.
Anschließend wird der Mittelwert je Zeitschritt berechnet und die Entscheidungsfunktion angewendet. Gibt sie 1 zurück, wurde eine Änderung erkannt und das Modell driftet möglicherweise.
Die Page-Hinkley-Methode ist einfach und wirksam, um Mittelwertänderungen über die Zeit zu entdecken – besonders kleine Verschiebungen, die im Rohverlauf nicht sofort auffallen. Wichtig ist eine sorgfältige Wahl von Schwellwert und Entscheidungsfunktion, um sensibel genug zu sein, ohne Fehlalarme zu produzieren.
In diesem Abschnitt verwenden wir Evidently zur Drifterkennung. Evidently ist eine Open-Source-Python-Bibliothek für Data Scientists und Engineers, um Modelle von der Validierung bis in die Produktion zu testen, zu evaluieren und zu überwachen.
import pandas as pd
import numpy as np
from sklearn import datasets
from evidently import Report
from evidently.presets import DataDriftPreset# create ref and cur dataset for drift detection
adult_data = datasets.fetch_openml(name='adult', version=2, as_frame=True)
adult = adult_data.frame
adult_ref = adult[~adult.education.isin(['Some-college', 'HS-grad', 'Bachelors'])].copy()
adult_cur = adult[adult.education.isin(['Some-college', 'HS-grad', 'Bachelors'])].copy()
adult_cur.iloc[:2000, 3:5] = np.nan#dataset-level metrics
report = Report([DataDriftPreset()], include_tests=True)
my_eval = report.run(current_data=adult_cur, reference_data=adult_ref)
my_eval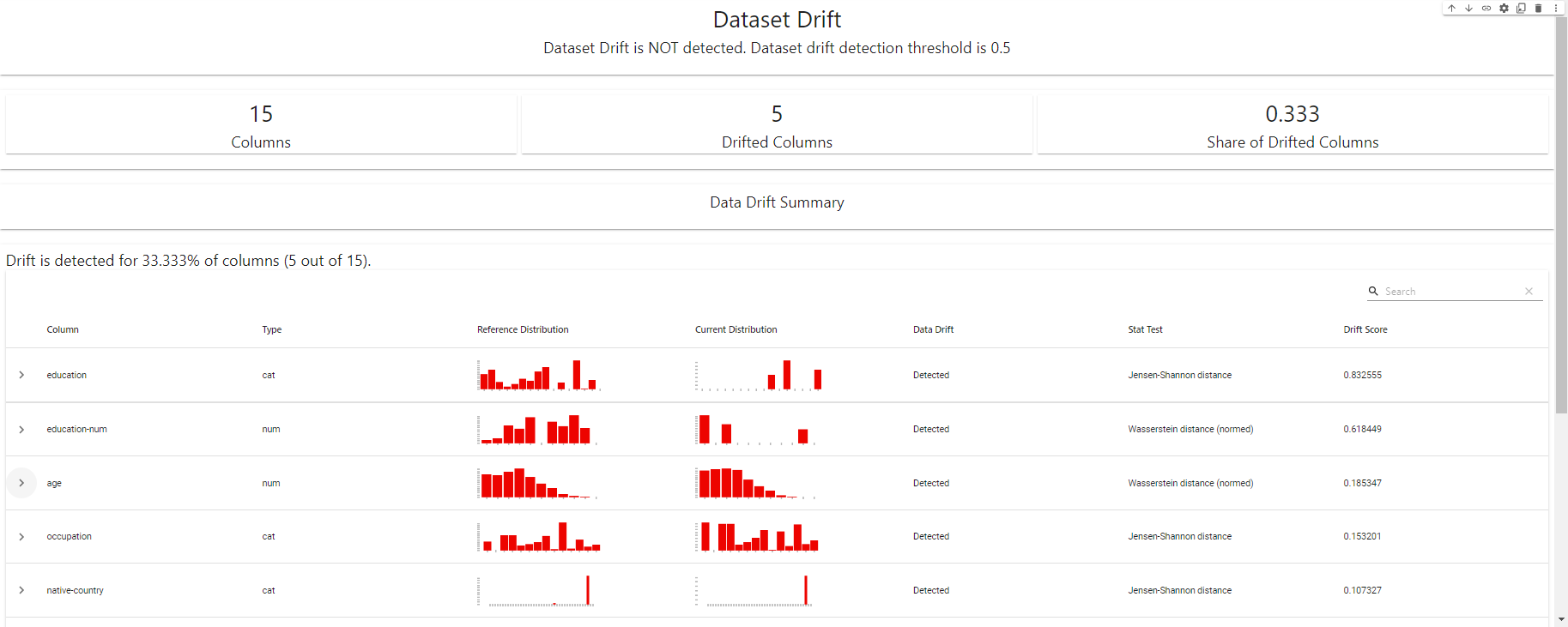
Drift Detection Dashboard – erstellt mit EvidentlyAI
#report in a JSON format
my_eval.json()
Das komplette DataCamp-Notebook findest du hier.
Data Drift und Model Drift sind ernstzunehmende Herausforderungen für ML-Systeme im Betrieb. Wenn du Ursachen und Auswirkungen verstehst und ein wirksames Drift-Monitoring etablierst, bleiben deine Modelle langfristig präzise und zuverlässig.
Beobachte die Modellleistung, nutze Drifterkennung und trainiere regelmäßig mit aktualisierten Daten – so reduzierst du Driftrisiken deutlich. Mit proaktivem Monitoring stellst du sicher, dass dein ML-System dauerhaft Mehrwert liefert.
Das Überwachen von ML-Modellen auf Drift ist Teil des größeren Themenfelds MLOps. Wer ML-Modelle aus dem Notebook in die Produktion bringen will – ob Data Scientist, Engineer oder Führungskraft – sollte MLOps-Konzepte verstehen.
Wenn du tiefer in MLOps einsteigen willst und wissen möchtest, wie es deiner Karriere hilft, schau dir unseren Kurs MLOps Concepts an. Du lernst, was MLOps ist, welche Phasen der MLOps-Prozess umfasst und welche Reifegrade es gibt. Mit diesem Fundament kannst du Machine Learning kontinuierlich, zuverlässig und effizient in die Produktion bringen.
MLOps-Kurse
Kurs
Kurs
Kurs
Tutorial
Matt Crabtree
Tutorial
Sejal Jaiswal
Tutorial
Allan Ouko
Tutorial
Sejal Jaiswal
Tutorial
Adel Nehme
Tutorial
Moez Ali

