Course
MLOps Concepts
2 ч
42.6K
Модели машинного обучения обучаются на исторических данных, но при применении в реальном мире со временем могут устаревать и терять точность из‑за явления, называемого дрейфом. Дрейф — это изменение со временем статистических свойств данных, на которых обучалась модель. Это может привести к снижению точности или изменению поведения модели относительно изначального замысла.
Иными словами, «дрейф» — это падение способности модели давать точные прогнозы из‑за изменений в среде её использования.
Существует несколько причин, по которым модели со временем дрейфуют.
Одна из распространённых — данные, на которых обучалась модель, устаревают и уже не отражают текущие условия.
Например, модель, обученная предсказывать цену акции по историческим данным. Если обучать её на данных стабильного рынка, поначалу она может работать хорошо. Но если со временем рынок станет более волатильным, модель уже не сможет точно предсказывать цены, поскольку статистические свойства данных изменились.
Ещё одна причина дрейфа — модель изначально не была спроектирована для устойчивости к изменениям данных. Одни алгоритмы переносят такие изменения лучше других, но полностью исключить дрейф не может ни одна модель.
Рассмотрим два основных типа дрейфа:
Дрейф концепции (concept drift), также известный как дрейф модели, возникает, когда со временем меняется сама задача, под которую была разработана модель. Например, модель для обнаружения спама по содержимому писем может перестать работать, если типы спам-сообщений существенно изменились.
Дрейф концепции можно разделить на четыре категории (Learning under Concept Drift: A Review, Jie Lu et al.):
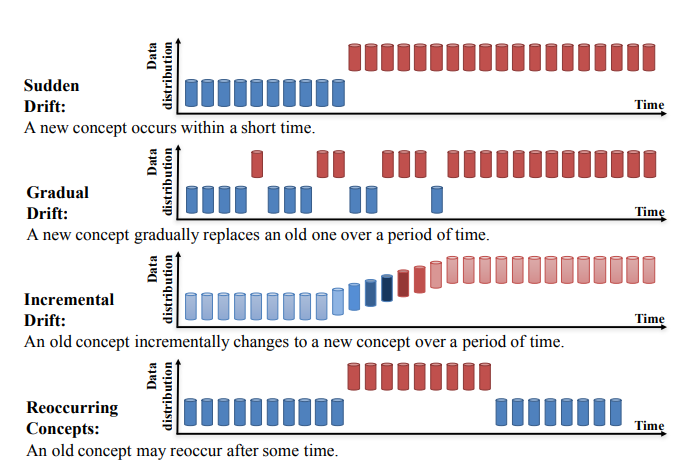
Источник: https://arxiv.org/pdf/2004.05785.pdf
Дрейф данных (covariate shift) возникает, когда со временем меняется распределение входных данных. Например, модель, предсказывающая вероятность покупки на основе возраста и дохода клиента, может перестать работать, если распределение возрастов и доходов заметно изменилось.
Важно отслеживать как дрейф концепции, так и дрейф данных и принимать меры для их предотвращения или снижения влияния. Среди стратегий — непрерывный мониторинг и оценка качества модели, обновление модели на новых данных и использование более устойчивых к дрейфу алгоритмов.
Больше о data science после внедрения, включая дрейф, слушайте в выпуске подкаста DataFramed.
Большие языковые модели (LLM) вносят тип дрейфа, под который классические методы не создавались. Данные — это не строки таблицы, а свободный текст, и чаще всего со временем меняется смысл пользовательских запросов. Сегодня выделяют три формы дрейфа LLM, которые стоит мониторить.
Дрейф эмбеддингов возникает, когда меняется смысл текстов, которые пользователи отправляют модели, даже если поверхностно тексты выглядят так же. LLM преобразуют текст в длинные списки чисел — эмбеддинги, и дрейф может проявляться в этих числах, не отражаясь в привычных метриках текста.
Представьте чат‑бот поддержки, который изначально отвечал в основном на вопросы по настройке и онбордингу. Через полгода объём и средняя длина сообщений не изменились, но теперь пользователи чаще спрашивают о биллинге и отменах. Текстовые статистики стабильны, но распределение эмбеддингов сдвинулось. Чтобы это обнаружить, команды сравнивают батчи недавних эмбеддингов с эталонным батчем с помощью статистических мер расстояния.
Дрейф промптов — та же идея, что и дрейф эмбеддингов, но на уровень выше. Вместо сравнения сырых эмбеддингов входящие запросы группируют по категориям — с помощью классификатора или другой LLM — и отслеживают сдвиги в их смеси.
Например, внутренний помощник по коду, созданный для бэкенд‑инженеров, со временем начинает получать трафик от дата‑саентистов с вопросами по pandas. Ассистент может по‑прежнему отвечать неплохо, но аудитория уже не та, на которой он тестировался, а системный промпт или индекс для поиска со временем перестают подходить.
Дрейф рубрики — это изменение со временем качественных оценок, которые автоматический оценщик выставляет ответам модели. Многие продакшен‑команды используют LLM в роли «судьи», оценивая каждую реплику по полезности, точности или тону. Если эти оценки по схожим входам начинают снижаться, обычно что‑то изменилось — модель за API, извлекаемые документы или состав пользователей.
Преимущество дрейфа рубрики в том, что он даёт сигнал качества без необходимости истинной разметки, которая для генеративных ответов редко доступна в реальном времени.
Есть два подхода к обнаружению дрейфа:
1. Модельный подход: подход на основе ML‑модели для определения, изменились ли входные данные.
2. Статистические тесты: существует множество статистических тестов для обнаружения дрейфа данных. Их обычно делят на три категории:
Методы на основе сравнения распределений используют статистические меры для оценки различия между двумя распределениями вероятностей. К ним относятся индекс стабильности популяции (PSI), дивергенция KL, дивергенция JS, критерий Колмогорова—Смирнова и метрика Васерштайна.
Критерий Колмогорова—Смирнова — непараметрический статистический тест, который используется для проверки, принадлежат ли две выборки одному распределению. Его применяют, чтобы проверить, исходит ли выборка из заданной генеральной совокупности, или сравнить две выборки на однородность.
Нулевая гипотеза теста — распределения одинаковы. Отказ от этой гипотезы указывает на наличие дрейфа.
Тест K‑S — полезный инструмент для сравнения наборов данных и проверки их на принадлежность к одному распределению.
Индекс стабильности популяции (Population Stability Index, PSI) — статистическая мера для сравнения распределения категориальной переменной в двух разных наборах данных.
PSI используют, чтобы измерять, насколько изменилось распределение признака между двумя выборками или со временем. Его часто применяют для мониторинга характеристик популяции и выявления потенциальных проблем с производительностью ML‑модели.
Изначально PSI разрабатывался для мониторинга изменения баллов в скоринговых картах риска, но теперь используется для анализа сдвигов распределений по всем атрибутам, связанным с моделью, включая зависимые и независимые переменные.
Высокое значение PSI указывает на значимые различия в распределениях признака между двумя наборами данных и может говорить о дрейфе модели.
Если распределение признака сильно изменилось, или если изменились сразу несколько признаков, может потребоваться перекалибровать или переобучить модель, чтобы улучшить её работу.
Метод Пейджа—Хинкли — статистический метод для обнаружения изменений среднего значения временного ряда. Его часто применяют для мониторинга работы ML‑моделей и выявления сдвигов в распределении данных, указывающих на дрейф.
Для применения метода сначала задают порог и решающую функцию. Порог — это значение, превышение которого трактуется как значимое изменение среднего; решающая функция возвращает 1 при обнаружении изменения и 0 — если изменений нет.
Далее на каждом шаге времени вычисляют среднее ряда и применяют решающую функцию, чтобы понять, произошло ли изменение. Возврат значения 1 указывает на обнаружение сдвига и возможный дрейф модели.
Метод Пейджа—Хинкли прост и эффективен для выявления изменений среднего во времени. Он особенно полезен для обнаружения небольших сдвигов, которые неочевидны при визуальном анализе. Однако важно аккуратно подбирать порог и решающую функцию, чтобы метод был достаточно чувствительным к реальным изменениям и при этом не давал слишком много ложных срабатываний.
В этом разделе мы используем Evidently для детекции дрейфа. Evidently — это открытая библиотека Python для дата‑саентистов и инженеров, работающих с ML. Она помогает тестировать, оценивать и отслеживать работу моделей от валидации до продакшена.
import pandas as pd
import numpy as np
from sklearn import datasets
from evidently import Report
from evidently.presets import DataDriftPreset# create ref and cur dataset for drift detection
adult_data = datasets.fetch_openml(name='adult', version=2, as_frame=True)
adult = adult_data.frame
adult_ref = adult[~adult.education.isin(['Some-college', 'HS-grad', 'Bachelors'])].copy()
adult_cur = adult[adult.education.isin(['Some-college', 'HS-grad', 'Bachelors'])].copy()
adult_cur.iloc[:2000, 3:5] = np.nan#dataset-level metrics
report = Report([DataDriftPreset()], include_tests=True)
my_eval = report.run(current_data=adult_cur, reference_data=adult_ref)
my_eval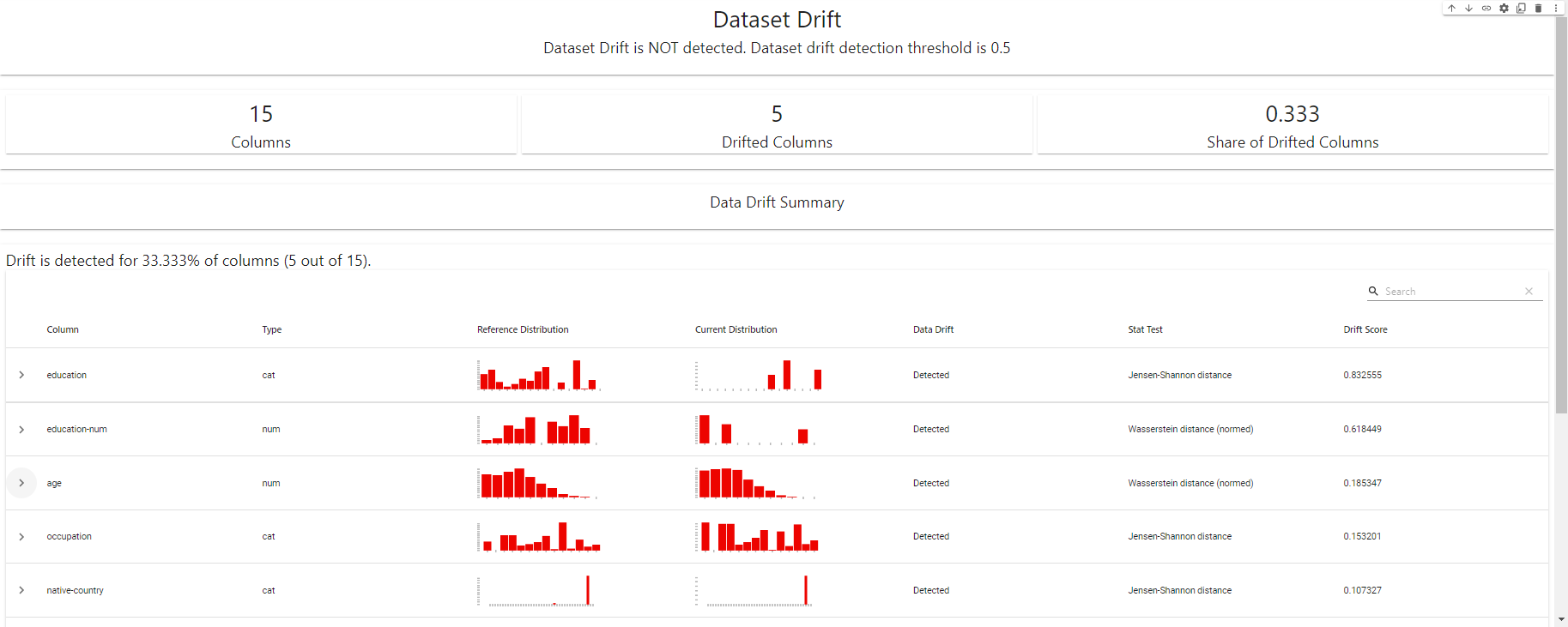
Панель обнаружения дрейфа — создано с помощью EvidentlyAI
#report in a JSON format
my_eval.json()
Полный ноутбук Datacamp смотрите здесь.
Дрейф данных и моделей — серьёзный вызов для ML‑систем в продакшене. Понимая причины и последствия дрейфа и внедряя эффективные практики его мониторинга, вы сможете поддерживать точность и надёжность своих моделей со временем.
Мониторинг качества моделей, использование методов детекции дрейфа и регулярное переобучение на обновлённых данных — лишь часть лучших практик, помогающих снизить риски дрейфа. Проактивный подход к мониторингу дрейфа обеспечивает устойчивую ценность ML‑системы для вашей организации.
Мониторинг дрейфа — лишь один аспект более широкой области MLOps. Понимание MLOps важно для дата‑саентистов, инженеров и руководителей, чтобы переводить модели из локальных ноутбуков в рабочие продакшен‑сервисы.
Если вы хотите глубже разобраться в MLOps и понять, как это поможет вашей карьере, посмотрите наш курс MLOps Concepts. Вы узнаете, что такое MLOps, разберёте этапы процессов MLOps и уровни зрелости. Освоив ключевые концепции, вы будете готовы внедрять машинное обучение непрерывно, надёжно и эффективно.
Курсы по MLOps
Course
Course
Course