course
Algebra liniowa dla data science w R
4 godz.
21K
W analizie danych nieustannie staramy się zrozumieć, jak zmienne odnoszą się do siebie. Prawdopodobnie spotkali się Państwo z dwiema miarami statystycznymi powszechnie używanymi w tym celu: kowariancją i korelacją. Brzmią podobnie i często są ze sobą mylone. Czym jednak się różnią i jak należy ich używać?
Obie opisują, jak zmienne zmieniają się wspólnie. Mimo podobieństw, kowariancja i korelacja odpowiadają na nieco inne pytania i pełnią różne role w przepływach pracy z danymi. Kowariancja uchwyca surową współzmienność cech, natomiast korelacja standaryzuje tę relację, aby ułatwić porównania.
Przyjrzyjmy się, jak ta subtelna różnica wpływa na dobór miary w różnych okolicznościach.
Kowariancja mierzy, jak dwie zmienne zmieniają się razem. Informuje, czy wzrost jednej zmiennej ma tendencję do współwystępowania ze wzrostem lub spadkiem drugiej. Wyróżniamy trzy typy kowariancji:
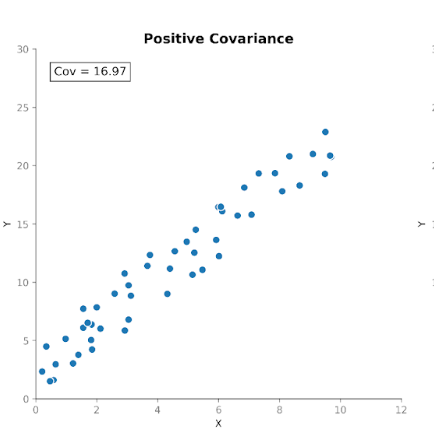
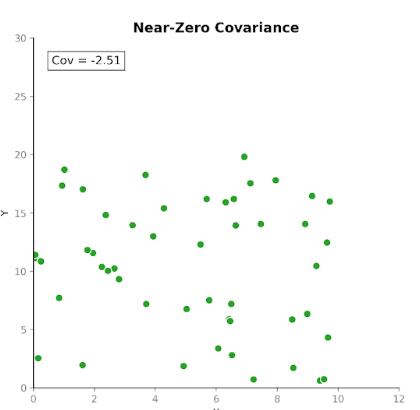
Dzięki temu kowariancja jest przydatna do wykrywania, jak zmienne współporuszają się względem siebie.
Choć kierunek zależności jest użyteczny, interpretacja wielkości kowariancji nie jest już tak prosta. Wielkość zależy od jednostek pomiaru oraz skali zmiennych. Zmiana jednostek, np. z centymetrów na metry, może drastycznie zmienić wartość kowariancji bez wpływu na samą zależność.
Z tego powodu kowariancja częściej pełni rolę wewnętrznego elementu obliczeń niż samodzielnej statystyki opisowej.
Korelacja mierzy zarówno siłę, jak i kierunek zależności między dwiema zmiennymi. Bazuje na kowariancji, standaryzując jej wielkość tak, aby jednostki nie wpływały na wynik.
Wartości korelacji mieszczą się w stałym przedziale od +1 (doskonała zależność dodatnia) do -1 (doskonała zależność ujemna). Wartość 0 oznacza brak zależności liniowej.
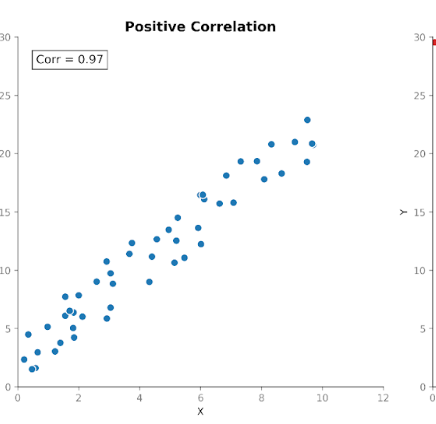
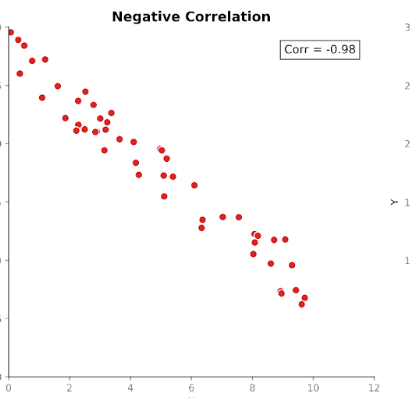
Ta standaryzowana skala sprawia, że korelacja jest łatwiejsza do interpretacji niż kowariancja. Jeśli widzimy wartość 0,8, od razu wiemy, że istnieje silna zależność między zmiennymi — niezależnie od jednostek użytych w pierwotnym pomiarze.
Standaryzacja pozwala też na sensowne porównania między zbiorami danych, cechami i dziedzinami. Dlatego korelacja jest tak częstym narzędziem w eksploracyjnej analizie danych i badaniu cech.
Kowariancja i korelacja opisują pokrewne właściwości relacji między zmiennymi, lecz służą różnym celom analitycznym.
W praktyce kowariancja odzwierciedla surową współzmienność, a korelacja — tę samą zależność w formie standaryzowanej. Zrozumienie tej różnicy pomaga dobrać właściwą miarę do konkretnego zadania analitycznego.
|
Kowariancja |
Korelacja |
|
|
Mierzy |
Zależność liniową (niestandaryzowaną) |
Zależność liniową (standaryzowaną) |
|
Wrażliwość na skalę |
Skala zależna od jednostek |
Stały zakres (−1 do +1) |
|
Jednostki |
Ma jednostki |
Bezwymiarowa |
|
Interpretowalność |
Wielkość trudna do interpretacji |
Kierunek i wielkość łatwe do interpretacji |
|
Porównywalność |
Ograniczona porównywalność między zbiorami danych |
Bezpośrednio porównywalna między zbiorami danych |
|
Typowe zastosowanie |
Modelowanie i budowa macierzy |
Eksploracja i komunikacja |
|
Zaleta |
Zachowuje oryginalną skalę |
Standaryzuje na potrzeby porównań |
Załóżmy, że zbieramy dane o dwóch zmiennych: wzroście i masie ciała. Oczekujemy zależności, ponieważ z reguły wyżsi ludzie ważą więcej. Gdy wykreślimy wzrost w centymetrach względem masy w kilogramach, widać wyraźny trend rosnący. Wraz ze wzrostem rośnie zwykle i masa.
Po obliczeniu kowariancji otrzymujemy wartość dodatnią: 48,08. Dodatni znak mówi nam, że obie zmienne poruszają się w tym samym kierunku. Gdy wzrost jest powyżej średniej, masa zwykle też jest powyżej średniej.
Teraz robi się ciekawie. Weźmy te same dane i zmieńmy jednostki. Przeliczymy wzrost z centymetrów na metry, a masę z kilogramów na funty. Ludzie się nie zmienili. Zależność się nie zmieniła. Wzór na wykresie rozrzutu wygląda tak samo. Ale po przeliczeniu kowariancji liczba jest inna: 1,06. Nadal dodatnia, lecz wielkość bardzo się różni. A jedyną zmianą były jednostki.
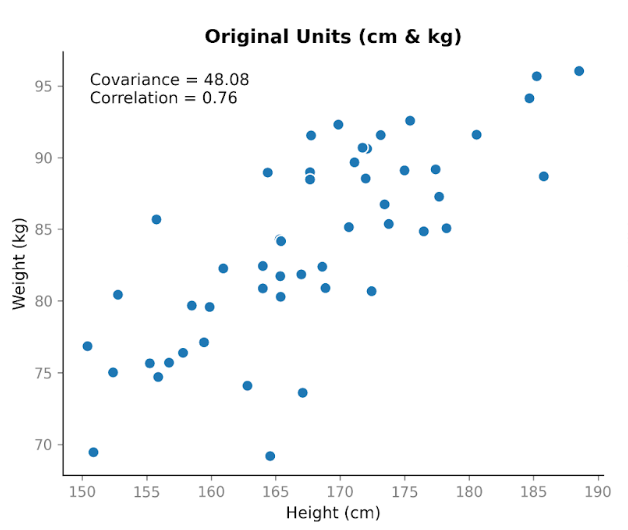
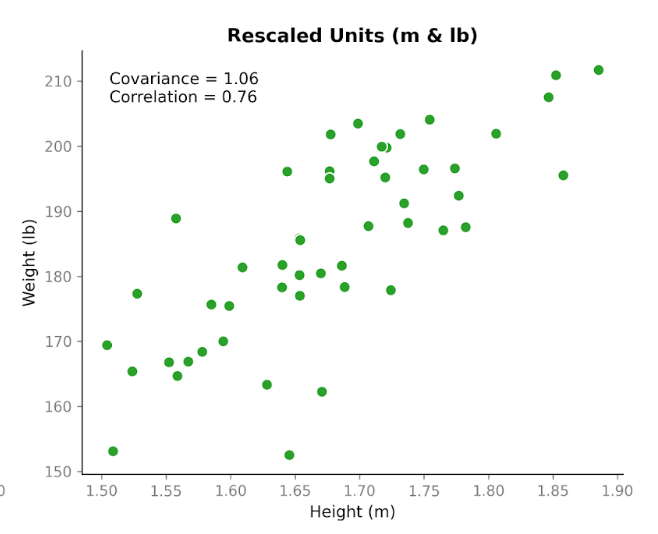
To pokazuje ważną cechę kowariancji: oddaje kierunek, ale jej wielkość zależy od skali. Jeśli rozciągniemy lub skurczymy jedną ze zmiennych, zmieniając jednostki, kowariancja rozciągnie się lub skurczy wraz z nią.
Spójrzmy teraz na korelację dla tych samych danych przed i po zmianie jednostek. Korelacja przy centymetrach i kilogramach wynosi 0,76. Po przeliczeniu na metry i funty nadal wynosi 0,76.
W odróżnieniu od kowariancji, korelacja koryguje zmienność każdej zmiennej, zanim zmierzy relację między nimi. Dzięki tej korekcie wartość nie zmienia się przy zmianie jednostek. Koncentruje się wyłącznie na tym, jak ściśle punkty podążają za wzorcem liniowym i czy nachylenie jest dodatnie, czy ujemne.
Ten prosty przykład podkreśla główną różnicę: kowariancja odzwierciedla zarówno kierunek, jak i skalę, podczas gdy korelacja odzwierciedla siłę zależności niezależnie od skali. W praktyce oznacza to, że korelacja jest bardziej wiarygodna przy porównywaniu zależności między zmiennymi mierzonymi w różnych skalach, natomiast kowariancja jest istotniejsza tam, gdzie znaczenie ma wielkość zmienności, np. w modelowaniu.
Jak omówiliśmy, kowariancja mówi nam, czy dwie zmienne poruszają się w tym samym kierunku, ale jej wielkość trudno zinterpretować.
Główny problem polega na tym, że kowariancja zależy od skali zmiennych, a nie wyłącznie od ich zależności. Jeśli wartości jednej lub obu zmiennych są większe lub bardziej rozproszone, kowariancja także będzie mieć tendencję do większych wartości.
Ta wrażliwość wynika z dwóch źródeł. Pierwsze to jednostki danych. Zmiana jednostek zmienia kowariancję. Pomiar dochodu w dolarach vs. w tysiącach dolarów da bardzo różne wartości kowariancji, choć relacja pozostaje identyczna.
Drugie źródło to poziom zmienności zmiennej. Nawet przy tych samych jednostkach, zbiór o szerszym zakresie lub większym rozproszeniu zwykle da większą kowariancję niż bardziej zwarty zbiór o tej samej zależności. Duża kowariancja nie musi więc oznaczać silnej relacji — może jedynie odzwierciedlać większe skale lub większą zmienność danych.
Z powodu tej wrażliwości na skalę, kowariancja jest często używana wewnętrznie, np. do dopasowywania modeli, zamiast być raportowana bezpośrednio.
Korelacja rozwiązuje wiele problemów interpretacyjnych kowariancji poprzez standaryzację relacji między zmiennymi. Ponieważ wartości korelacji zawsze mieszczą się między −1 a +1, ich wielkość jest natychmiast zrozumiała: wartości bliskie 1 lub −1 wskazują silne zależności liniowe, a wartości bliskie 0 — słabe lub brak zależności liniowej. Standaryzacja umożliwia też bezpośrednie porównania między zmiennymi lub zbiorami danych, co ułatwia komunikację i interpretację.
Te właściwości sprawiają, że korelacja jest szczególnie użyteczna w eksploracyjnej analizie danych, badaniu relacji między cechami, wykrywaniu redundancji lub wielokolinearności oraz w raportowaniu wyników. Macierze i mapy cieplne korelacji są też przydatnymi narzędziami pierwszego rozpoznania zbiorów danych.
Nie oznacza to jednak, że korelacja całkowicie zastępuje kowariancję. Ponieważ korelacja usuwa wpływ skali, odzwierciedla wyłącznie siłę zależności, a nie surową zmienność. W kontekście modelowania, takim jak analiza głównych składowych czy modele wielowymiarowe, oryginalna skala uchwycona przez kowariancję może być ważna dla zrozumienia struktury wariancji i zachowania algorytmów.
Dotychczas patrzyliśmy na kowariancję między parami zmiennych. Algebra liniowa pozwala rozszerzyć to podejście na cały zbiór danych naraz, układając dane w macierz.
W podstawowej macierzy danych każdy wiersz to obserwacja, a każda kolumna — zmienna. Aby badać relacje między zmiennymi, możemy najpierw wycentrować dane, odejmując od każdej wartości średnią z kolumny. Dzięki temu skupiamy się na odchyleniach od wartości typowych, a nie na wartościach bezwzględnych.
Pomnożenie wycentrowanej macierzy danych przez jej transpozycję daje strukturę, która uchwyca, jak zmienne współporuszają się. Ten iloczyn, po przeskalowaniu, to macierz kowariancji. Z perspektywy algebry liniowej macierz kowariancji podsumowuje, jak zmienność rozkłada się w wymiarach zbioru danych.
Takie spojrzenie wyjaśnia, dlaczego kowariancja tak często pojawia się w data science. Wiele algorytmów, w tym analiza głównych składowych (PCA) i inne techniki redukcji wymiarów, opiera się na tej macierzowej reprezentacji, aby rozumieć wzorce i strukturę danych. Koncepcyjnie macierz kowariancji stanowi mapę interakcji między wymiarami zbioru danych.
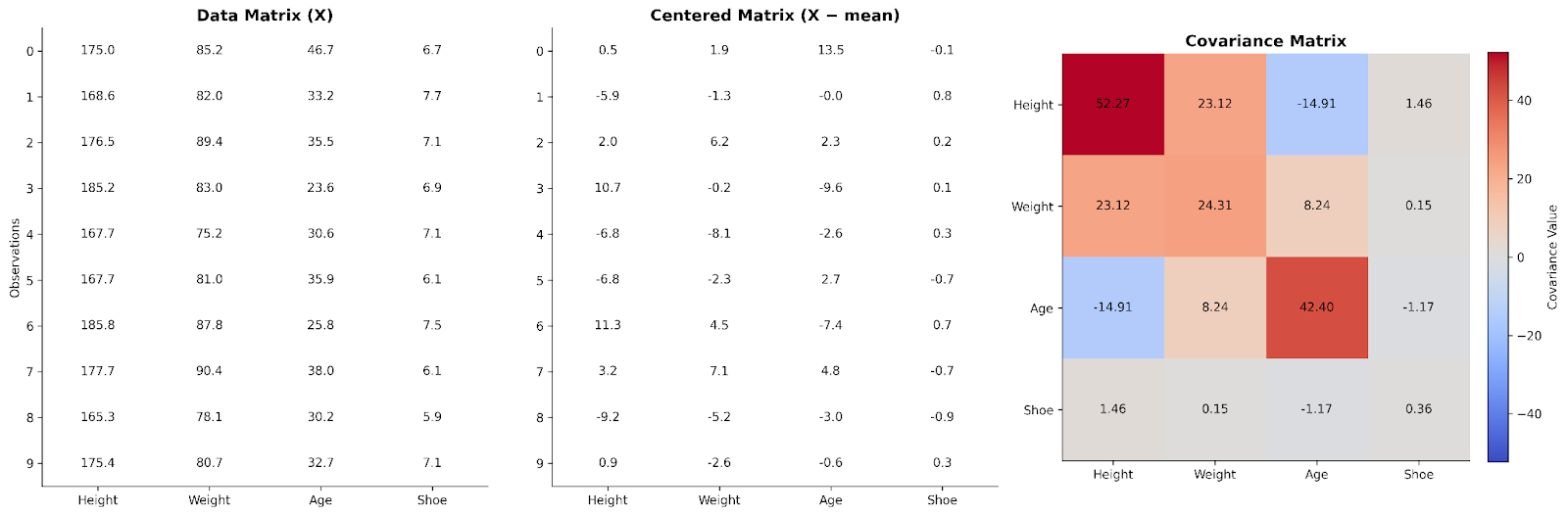
Widzimy tu dane dla czterech zmiennych ułożone w macierz danych. Następnie zostały wycentrowane i użyte do utworzenia macierzy kowariancji.
Jeśli chcą Państwo głębiej poznać algebrę liniową w data science, proszę zajrzeć na nasz kurs Linear Algebra for Data Science in R, który omawia podstawy potrzebne do zrozumienia podejść macierzowych, takich jak kowariancja.
Macierz kowariancji podsumowuje, jak zmienne współporuszają się w całym zbiorze danych. W praktyce badamy te relacje za pomocą macierzy kowariancji lub korelacji — w zależności od tego, czy chcemy zachować oryginalną skalę, czy też wyniki wystandaryzować.
Macierz kowariancji zawiera kowariancje dla wszystkich par zmiennych. Liczby na przekątnej pokazują wariancję w obrębie każdej zmiennej, a elementy poza przekątną odzwierciedlają, jak zmienne zmieniają się razem. Ponieważ kowariancja zachowuje oryginalną skalę i jednostki, macierz oddaje surową strukturę zmienności. To czyni ją szczególnie użyteczną w przepływach pracy modelowania i analizach wielowymiarowych.
Macierz korelacji z kolei standaryzuje te relacje. Każdy element na przekątnej równy jest 1, ponieważ każda zmienna jest doskonale skorelowana sama ze sobą. Wszystkie elementy poza przekątną mieszczą się między −1 a +1 i pokazują korelację między zmiennymi. Dzięki usunięciu efektów skali, macierze korelacji są łatwiejsze do interpretacji i pozwalają bezpośrednio porównywać zmienne. Są szczególnie przydatne w eksploracyjnej analizie danych i do szybkiej identyfikacji silnych lub słabych zależności liniowych między cechami.
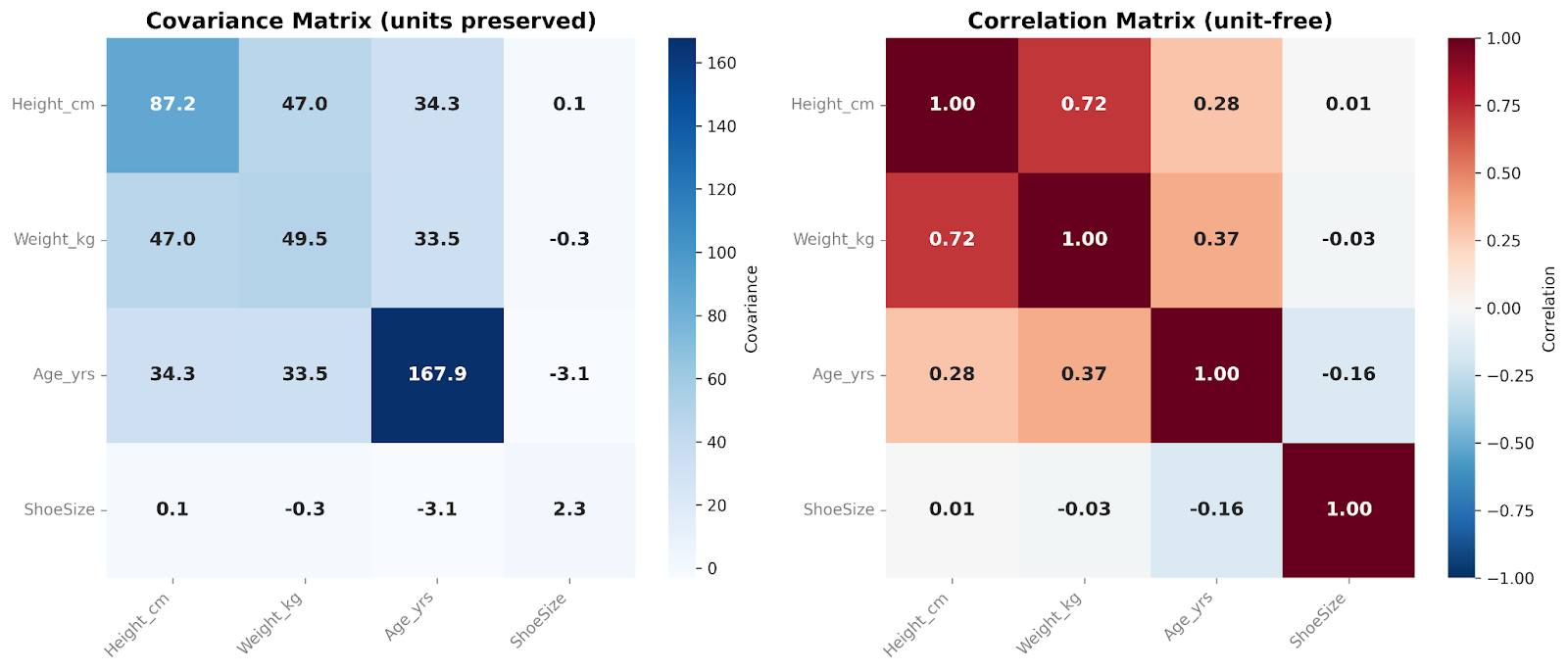
W tych macierzach porównujemy ze sobą cztery zmienne. Lubię dodawać nakładkę mapy cieplnej podczas prezentowania takich macierzy. Kolor każdej komórki pomaga na pierwszy rzut oka dostrzec względną wielkość wartości kowariancji lub korelacji.
Koncepcyjnie korelacja wynika z kowariancji poprzez standaryzację relacji między zmiennymi. Wystarczy podzielić kowariancję przez odchylenie standardowe każdej zmiennej. To skalowanie usuwa jednostki i wielkość zmiennych, dając standaryzowaną miarę zawsze mieszczącą się między −1 a +1. Ta transformacja wyjaśnia, dlaczego wartości korelacji są bezpośrednio porównywalne między różnymi zmiennymi lub zbiorami danych.
W praktyce przeliczanie kowariancji na korelację jest zautomatyzowane w większości programów statystycznych, więc analitycy rzadko robią to ręcznie. Zawsze jednak warto rozumieć, co oprogramowanie robi „pod maską”. Na przykład, zrozumienie, jak kowariancja zamieniana jest na korelację, wyjaśnia, dlaczego nie da się odwrócić tego przeliczenia (przynajmniej bez informacji o odchyleniu standardowym obu zmiennych). Korelacja nie zawiera już informacji o jednostkach ani wielkości potrzebnych do powrotu do kowariancji.
Kowariancja jest najprzydatniejsza, gdy skala i jednostki danych mają znaczenie lub gdy potrzebna jest surowa struktura zmienności danych. Jest powszechnie używana w modelowaniu wielowymiarowym, modelach probabilistycznych oraz przy konstruowaniu macierzy kowariancji dla metod opartych na algebrze liniowej. W tych kontekstach zachowanie oryginalnej zmienności pozwala algorytmom uchwycić prawdziwą strukturę danych i zrozumieć, jak wymiary współzmieniają się.
Korelacja natomiast lepiej nadaje się do interpretacji przez ludzi, porównań między zbiorami danych i analiz eksploracyjnych. Lubię używać tej miary w wizualizacjach, np. na mapach cieplnych, aby móc dostrzec i komunikować relacje od razu. Ponieważ korelacja standaryzuje zależność, jest też pomocna przy przygotowaniu danych do technik, w których ważne jest traktowanie wszystkich cech na porównywalnej skali.
Często obie miary pojawiają się w tym samym przepływie pracy. Macierze kowariancji stanowią matematyczną podstawę wielu technik wielowymiarowych, ponieważ zachowują oryginalną zmienność danych. Z kolei macierze korelacji są często używane na etapie eksploracji, aby zrozumieć strukturę zbioru danych przed modelowaniem.
Niektóre modele mogą korzystać z którejkolwiek miary, zależnie od celu. Rozważmy analizę głównych składowych (PCA). Gdy PCA wykonuje się na macierzy kowariancji, zmienne o większej wariancji naturalnie silniej wpływają na komponenty. Może to być pożądane, jeśli różnice w skali odzwierciedlają istotne różnice w zmienności. Na przykład analizując dzienne stopy zwrotu akcji, bardziej zmienna spółka może słusznie kształtować komponenty główne, ponieważ ta zmienność oddaje realne zachowanie rynku.
Użycie zamiast tego macierzy korelacji standaryzuje zmienne przed dekompozycją. Każda cecha trafia na tę samą skalę, więc żadna nie dominuje tylko dlatego, że ma większe jednostki lub szerszy zakres liczbowy. To podejście może być bardziej odpowiednie, gdy zmienne mierzone są w różnych jednostkach, takich jak wzrost (cm), masa (kg), ciśnienie krwi (mmHg) i cholesterol (mg/dL).
Żadne z podejść nie jest uniwersalnie lepsze. Właściwy wybór zależy od tego, czy różnice skali odzwierciedlają istotną strukturę, czy są jedynie artefaktem pomiaru.
Częstym nieporozumieniem jest przekonanie, że wysoka kowariancja automatycznie oznacza silną zależność. Jednak duże wartości kowariancji mogą po prostu odzwierciedlać skalę lub zmienność zmiennych, a nie siłę ich relacji. Jeśli chcą Państwo poznać siłę zależności, należy ją wystandaryzować, patrząc na korelację.
Zapewne słyszeli Państwo frazę „korelacja nie implikuje przyczynowości” już setki razy! A jednak to wciąż najpowszechniejsze nieporozumienie, z jakim się spotykam. Naturalne jest, że widząc silną korelację, zakładamy związek przyczynowy — to skrót myślowy, który pomagał przetrwać naszym przodkom. Jako praktycy danych musimy się jednak temu skrótowi oprzeć i pamiętać, że sama korelacja nie wystarcza do udowodnienia efektu przyczynowego. Korelacja mierzy współwystępowanie, a nie wpływ przyczynowy, a czynniki zewnętrzne mogą jednocześnie napędzać obie zmienne.
Inne bardzo częste nieporozumienie to traktowanie kowariancji i korelacji jako niemal tego samego. Nie są one jednak wymienne. Choć korelacja jest pochodną kowariancji, standaryzuje relację, stając się odrębną miarą, która nie zawsze nadaje się jako substytut kowariancji w obliczeniach.
Wreszcie pamiętajmy, że te statystyki oceniają wyłącznie zależności liniowe. Nieliniowe wzorce mogą istnieć nawet przy niskiej lub bliskiej zeru korelacji i kowariancji, więc poleganie wyłącznie na tych miarach może pominąć ważną strukturę danych. Zawsze zalecam narysować dane i obejrzeć je przed interpretacją miar statystycznych — to potrafi uratować analizę, gdy zależność jest wyraźnie nieliniowa.
Po pierwsze, zawsze proszę uwzględniać skalę pomiaru. Różnice w jednostkach lub zmienności mogą wpływać na surowe miary, takie jak kowariancja, dlatego ważne jest zrozumienie, co reprezentują liczby.
Po drugie, proszę określić, czego Państwo potrzebują od danych. Kowariancja jest najprzydatniejsza, gdy ważne jest zachowanie surowej zmienności — często w modelowaniu lub przy konstruowaniu macierzy kowariancji do analiz wielowymiarowych. W tych kontekstach wielkość zróżnicowania niesie istotną informację. Jeśli jednak surowa zmienność nie jest potrzebna, być może lepsza będzie standaryzacja i interpretowalność korelacji.
Po trzecie: zawsze, zawsze, zawsze proszę wykreślać dane i je oglądać! Oględziny wizualne pomagają ukierunkować analizę i uzupełniają podsumowania statystyczne. Do wykrywania wzorców par używać można wykresów rozrzutu, a do szybkiego oglądu wielu zmiennych naraz — macierzy.
Na koniec proszę pomyśleć o konsekwencjach dalszych etapów analizy. Wybór między surową miarą, jak kowariancja, a standaryzowaną, jak korelacja, wpłynie na wyniki modelowania i interpretacje. Proszę więc dopasować wybór do celów analitycznych.
Kowariancja i korelacja to blisko spokrewnione miary opisujące wspólne zmiany zmiennych, lecz służą różnym celom: kowariancja zachowuje oryginalną skalę, a korelacja standaryzuje wyniki na potrzeby porównań.
Jeśli chcą Państwo dowiedzieć się więcej o eksploracji danych, proszę zajrzeć do poradnika Exploratory Data Analysis w Pythonie. Aby nauczyć się, jak ocenić, czy korelacja rzeczywiście wskazuje przyczynowość, proszę sprawdzić kurs Hypothesis Testing in R.
Ucz się z DataCamp
course
course
course