
Kurs
Lineare Algebra für Data Science in R
4 Std.
21.2K
In der Datenanalyse wollen wir verstehen, wie Variablen miteinander zusammenhängen. Dabei bist du sicher schon auf zwei gängige statistische Kennzahlen gestoßen: Kovarianz und Korrelation. Beide klingen ähnlich und werden oft verwechselt. Doch worin unterscheiden sie sich, und wann setzt man welche ein?
Beide beschreiben, wie Variablen sich gemeinsam bewegen. Trotz der Ähnlichkeit beantworten Kovarianz und Korrelation jedoch leicht unterschiedliche Fragen und erfüllen dadurch verschiedene Aufgaben im Datenworkflow. Die Kovarianz erfasst die rohe gemeinsame Variabilität von Merkmalen, während die Korrelation diese Beziehung standardisiert und so vergleichbarer macht.
Schauen wir uns an, wie dieser feine Unterschied beeinflusst, welche Kennzahl wir in welcher Situation verwenden.
Die Kovarianz misst, wie zwei Variablen gemeinsam variieren. Sie zeigt, ob Anstiege der einen Variable typischerweise mit Anstiegen oder Abnahmen der anderen einhergehen. Es gibt drei Fälle:
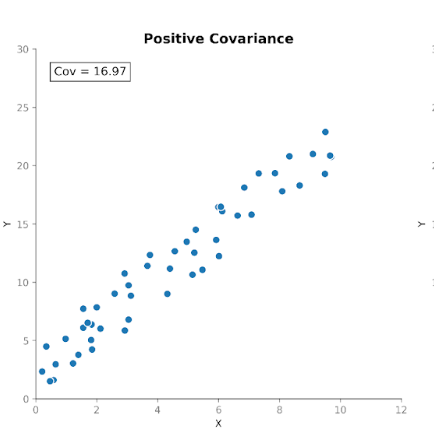
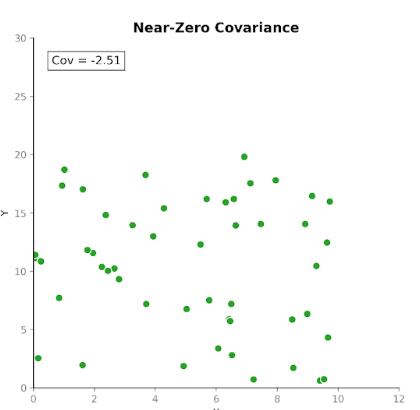
Damit eignet sich die Kovarianz gut, um zu erkennen, wie Variablen sich zueinander bewegen.
Die Richtung der Beziehung ist hilfreich, doch die Größe der Kovarianz ist schwer zu interpretieren. Sie hängt von den Maßeinheiten und der Skala der Variablen ab. Eine Umrechnung der Einheiten, etwa von Zentimetern auf Meter, kann die Kovarianz deutlich verändern, ohne die zugrunde liegende Beziehung zu beeinflussen.
Deshalb dient die Kovarianz häufiger als interner Rechenbaustein denn als eigenständige Kennzahl zur Beschreibung.
Die Korrelation misst sowohl die Richtung als auch die Stärke des Zusammenhangs zwischen zwei Variablen. Sie baut auf der Kovarianz auf, standardisiert jedoch deren Größe, sodass Einheiten keinen Einfluss mehr haben.
Korrelationswerte liegen immer im festen Bereich zwischen +1 (perfekt positiver Zusammenhang) und -1 (perfekt negativer Zusammenhang). Ein Wert von 0 zeigt an, dass kein linearer Zusammenhang besteht.
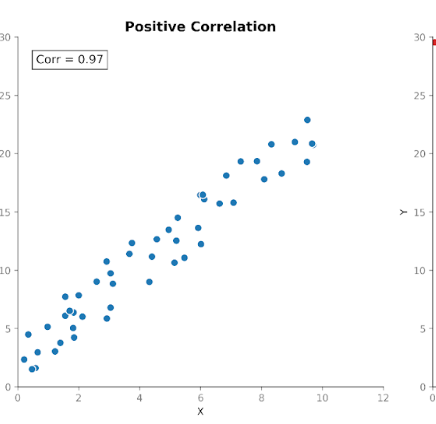
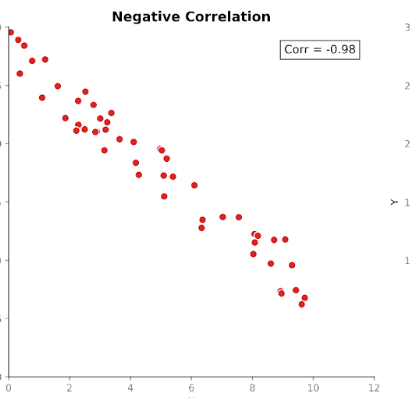
Diese Standardisierung macht die Korrelation leichter interpretierbar als die Kovarianz. Ein Wert von 0,8 signalisiert sofort einen starken Zusammenhang – unabhängig von den ursprünglichen Einheiten der Messung.
Zudem erlaubt die Standardisierung sinnvolle Vergleiche über Datensätze, Merkmale und Domänen hinweg. Darum wird die Korrelation so häufig in explorativen Analysen und bei der Merkmalsprüfung verwendet.
Kovarianz und Korrelation beschreiben verwandte Eigenschaften von Variablenbeziehungen, dienen jedoch unterschiedlichen Analysezwecken.
Praktisch betrachtet spiegelt die Kovarianz die rohe Mit-Variabilität wider, während die Korrelation dieselbe Beziehung in standardisierter Form ausdrückt. Dieses Verständnis hilft dir zu entscheiden, welche Kennzahl für deine Aufgabe besser geeignet ist.
|
Kovarianz |
Korrelation |
|
|
Misst |
Linearen Zusammenhang (nicht standardisiert) |
Linearen Zusammenhang (standardisiert) |
|
Skalensensitivität |
Skala durch Einheiten bestimmt |
Fester Bereich (−1 bis +1) |
|
Einheiten |
Mit Einheiten |
Einheitslos |
|
Interpretierbarkeit |
Größe schwer zu deuten |
Richtung und Stärke leicht zu deuten |
|
Vergleichbarkeit |
Begrenzt zwischen Datensätzen vergleichbar |
Direkt zwischen Datensätzen vergleichbar |
|
Typische Nutzung |
Modellierung und Matrixkonstruktion |
Exploration und Kommunikation |
|
Vorteil |
Erhält die Originalskskala |
Standardisiert für Vergleiche |
Angenommen, wir erheben Daten zu zwei Variablen: Körpergröße und Gewicht. Wir erwarten einen Zusammenhang, denn größere Menschen wiegen im Schnitt mehr. Tragen wir Größe in Zentimetern gegen Gewicht in Kilogramm auf, sehen wir einen klaren Aufwärtstrend: Mit zunehmender Größe nimmt tendenziell auch das Gewicht zu.
Berechnen wir die Kovarianz, erhalten wir einen positiven Wert: 48,08. Das Positive zeigt, dass sich beide Variablen in dieselbe Richtung bewegen. Liegt die Größe über dem Mittelwert, ist das Gewicht meist ebenfalls über dem Mittelwert.
Jetzt wird es spannend: Wir nehmen exakt dieselben Daten und ändern nur die Einheiten. Wir wandeln die Größe von Zentimetern in Meter und das Gewicht von Kilogramm in Pfund um. Die Personen haben sich nicht verändert. Die Beziehung hat sich nicht verändert. Das Muster im Scatterplot sieht gleich aus. Aber die neu berechnete Kovarianz lautet 1,06. Noch immer positiv, aber deutlich anders in der Größe. Und das Einzige, was wir geändert haben, sind die Einheiten.
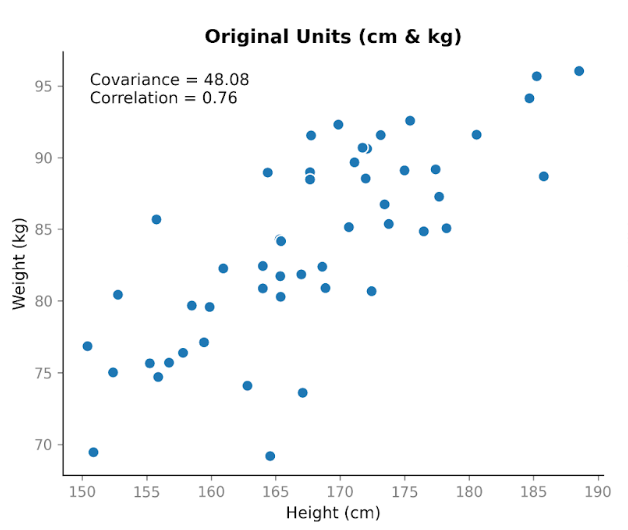
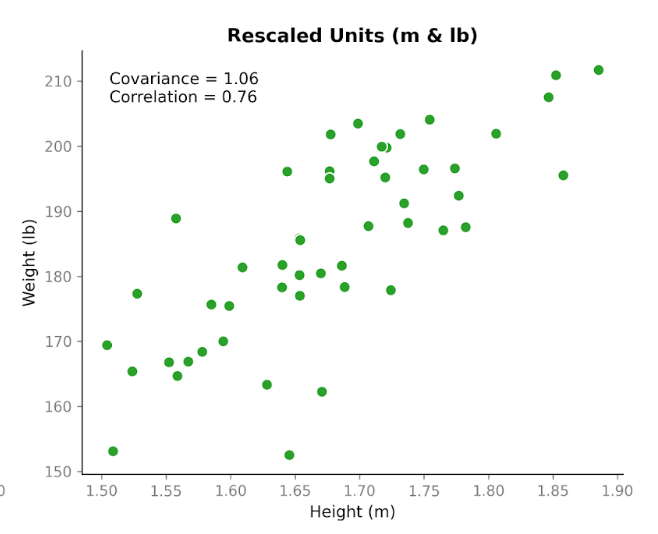
Das zeigt eine zentrale Eigenschaft der Kovarianz: Sie erfasst die Richtung, aber ihre Größe hängt von der Skala ab. Strecken oder stauchen wir eine Variable durch Einheitenänderung, folgt die Kovarianz diesem Effekt.
Betrachten wir nun die Korrelation mit denselben Daten vor und nach der Umrechnung. Mit Zentimetern und Kilogramm beträgt sie 0,76. Nach der Umrechnung in Meter und Pfund beträgt sie weiterhin 0,76.
Im Gegensatz zur Kovarianz korrigiert die Korrelation zunächst die Variabilität jeder Variable, bevor sie den Zusammenhang misst. Dadurch ändert sich der Wert nicht, wenn wir die Einheiten wechseln. Sie fokussiert nur darauf, wie eng die Punkte einem linearen Muster folgen und ob dieses nach oben oder unten geneigt ist.
Dieses einfache Beispiel macht den Hauptunterschied deutlich: Die Kovarianz spiegelt Richtung und Skala wider, die Korrelation die Stärke des Zusammenhangs unabhängig von der Skala. In der Praxis ist die Korrelation daher zuverlässiger, um Beziehungen über Variablen mit unterschiedlichen Skalen zu vergleichen, während die Kovarianz dort relevanter ist, wo die Größenordnung der Variabilität zählt – etwa in der Modellierung.
Wie besprochen zeigt die Kovarianz, ob zwei Variablen sich in dieselbe Richtung bewegen. Ihre Größe ist jedoch schwer zu interpretieren.
Der Hauptgrund: Die Kovarianz hängt von der Skala der Variablen ab, nicht nur von deren Beziehung. Sind die Werte einer oder beider Variablen größer oder stärker gestreut, fällt auch die Kovarianz tendenziell größer aus.
Diese Empfindlichkeit hat zwei Quellen. Erstens die Einheiten der Daten. Einheitenwechsel verändert die Kovarianz. Einkommen in Dollar versus in Tausend Dollar zu messen führt zu sehr unterschiedlichen Kovarianzen, obwohl der Zusammenhang identisch bleibt.
Zweitens die Höhe der Variabilität der Variable. Selbst bei gleichen Einheiten liefert ein Datensatz mit größerer Spannweite typischerweise eine höhere Kovarianz als ein engerer Datensatz mit demselben Grundzusammenhang. Eine große Kovarianz steht also nicht automatisch für eine starke Beziehung, sondern kann lediglich größere Skalen oder stärkere Streuung widerspiegeln.
Aufgrund dieser Skalenempfindlichkeit wird die Kovarianz oft intern verwendet, etwa beim Anpassen von Modellen, und seltener direkt berichtet.
Die Korrelation löst viele Interpretationsprobleme der Kovarianz, indem sie den Zusammenhang zwischen Variablen standardisiert. Da Korrelationswerte stets zwischen −1 und +1 liegen, ist die Größenordnung sofort verständlich: Werte nahe 1 oder −1 deuten auf starke lineare Beziehungen hin, Werte nahe 0 auf schwache oder keine lineare Beziehung. Diese Standardisierung ermöglicht direkte Vergleiche zwischen Variablen oder Datensätzen und macht Korrelation leichter zu kommunizieren und zu interpretieren.
Diese Eigenschaften machen die Korrelation besonders nützlich für die explorative Datenanalyse, das Prüfen von Merkmalsbeziehungen, das Erkennen von Redundanz oder Multikollinearität und für die Ergebnisberichterstattung. Korrelationsmatrizen und Heatmaps sind zudem hilfreiche Erstchecks bei der Datensichtung.
Allerdings ersetzt die Korrelation die Kovarianz nicht vollständig. Da sie Skaleneffekte entfernt, bildet sie nur die Stärke des Zusammenhangs ab, nicht die rohe Variabilität. In Modellierungskontexten wie der Hauptkomponentenanalyse oder multivariaten statistischen Modellen kann die durch die Kovarianz eingefangene Originalskskala wichtig sein, um die Varianzstruktur zu verstehen und das Verhalten von Algorithmen zu steuern.
Bisher haben wir die Kovarianz paarweise zwischen Variablen betrachtet. Die Lineare Algebra zeigt, wie sich dieser Gedanke auf den gesamten Datensatz skalieren lässt – indem wir die Daten in einer Matrix anordnen.
In einer Datenmatrix steht jede Zeile für eine Beobachtung und jede Spalte für eine Variable. Um Beziehungen zwischen Variablen zu verstehen, zentrieren wir die Daten zunächst, indem wir vom jeweiligen Spaltenwert den Spaltenmittelwert abziehen. So betrachten wir Abweichungen von typischen Werten statt Absolutwerten.
Multipliziert man die zentrierte Datenmatrix mit ihrer Transponierten, erhält man eine Struktur, die erfasst, wie Variablen gemeinsam variieren. Dieses Produkt ist – nach Skalierung – die Kovarianzmatrix. Aus Sicht der Linearen Algebra fasst sie zusammen, wie sich die Variabilität über die Dimensionen des Datensatzes verteilt.
So gedacht wird klar, warum die Kovarianz in der Data Science so häufig auftaucht. Viele Algorithmen, darunter die Hauptkomponentenanalyse (PCA) und andere Dimensionalitätsreduktionen, stützen sich auf diese Matrixdarstellung, um Muster und Strukturen in den Daten zu erkennen. Konzeptionell liefert die Kovarianzmatrix eine Karte, wie die Dimensionen eines Datensatzes interagieren.
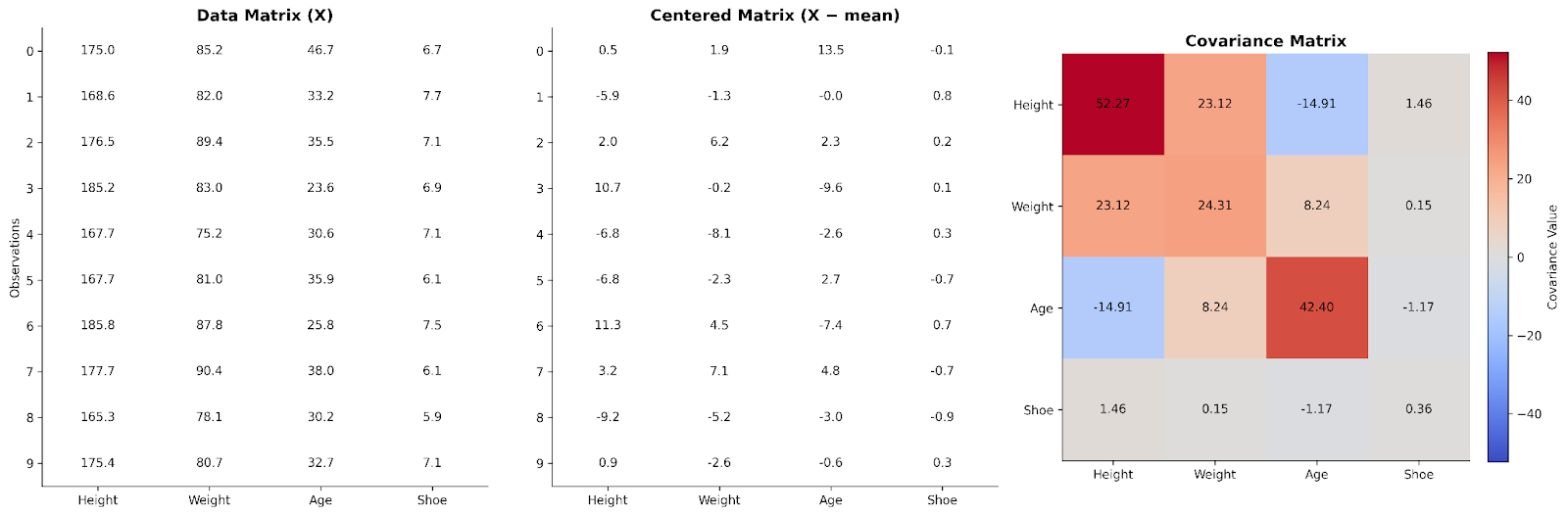
Hier sehen wir Daten für vier Variablen in einer Datenmatrix. Sie wird zentriert und zur Bildung einer Kovarianzmatrix verwendet.
Wenn du tiefer in Lineare Algebra für Data Science einsteigen möchtest, schau dir unseren Linear Algebra for Data Science in R Kurs an. Er vermittelt die Grundlagen, um matrixbasierte Ansätze wie die Kovarianz zu verstehen.
Die Kovarianzmatrix fasst zusammen, wie Variablen über einen gesamten Datensatz gemeinsam variieren. In der Praxis betrachten wir diese Zusammenhänge oft über Kovarianz- oder Korrelationsmatrizen – je nachdem, ob wir die Originalskala erhalten oder die Ergebnisse standardisieren möchten.
Eine Kovarianzmatrix enthält die Kovarianzen aller Variablenpaare. Die Diagonale zeigt die Varianz jeder Variable, die Nebendiagonalen zeigen, wie Variablen gemeinsam schwanken. Da die Kovarianz die ursprüngliche Skala und Einheiten erhält, bildet die Matrix die rohe Struktur der Variabilität ab. Das macht Kovarianzmatrizen besonders nützlich für Modellierungs-Workflows und multivariate Analysen.
Eine Korrelationsmatrix dagegen standardisiert diese Zusammenhänge. Jeder Diagonaleintrag ist 1, da jede Variable perfekt mit sich selbst korreliert. Alle Nebendiagonalen liegen zwischen −1 und +1 und zeigen die Korrelation zwischen Variablen. Durch die Entfernung von Skaleneffekten sind Korrelationsmatrizen für Menschen leichter zu interpretieren und erlauben direkte Vergleiche. Sie sind besonders nützlich in der explorativen Analyse und um starke oder schwache lineare Beziehungen zwischen Merkmalen schnell zu erkennen.
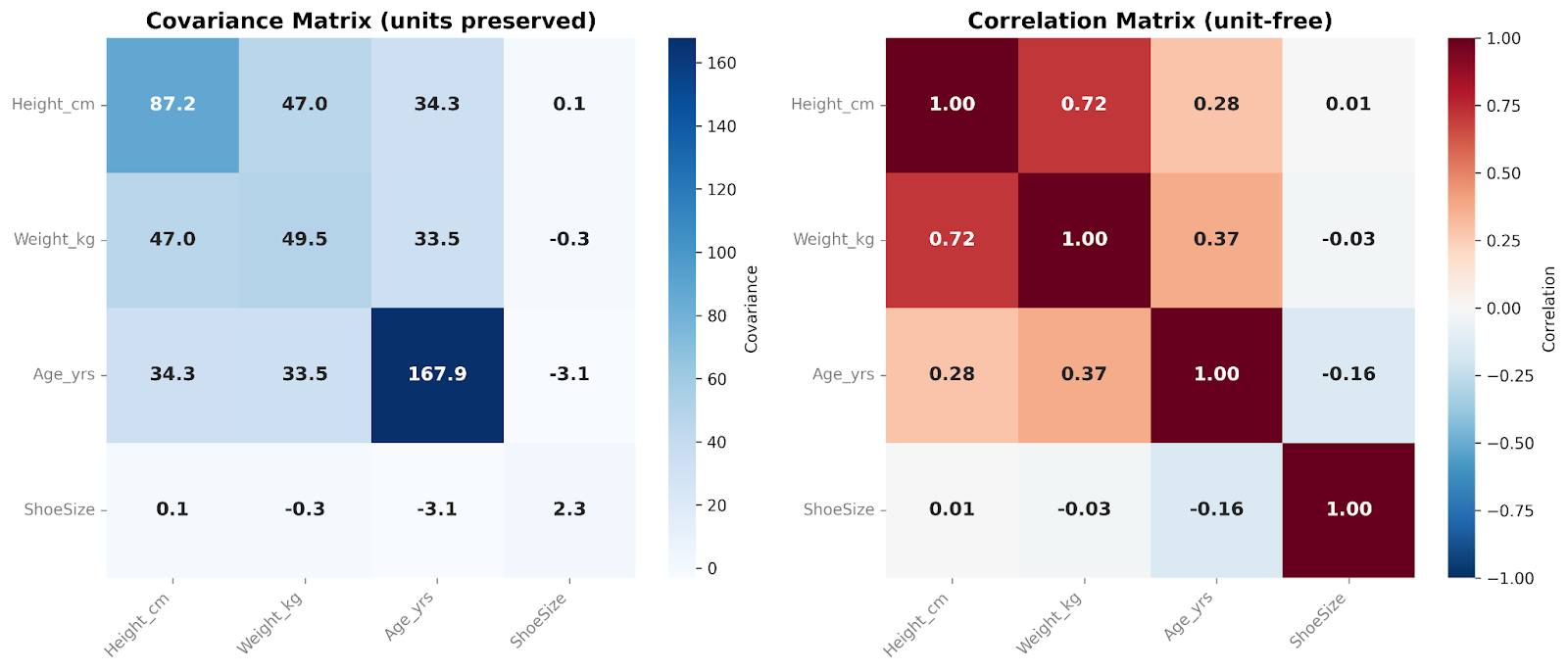
In diesen Matrizen vergleichen wir vier Variablen miteinander. Ich füge bei Präsentationen gern eine Heatmap-Überlagerung hinzu. Die Zellfarbe macht auf einen Blick die relative Größe der Kovarianz- oder Korrelationswerte sichtbar.
Konzeptionell entsteht die Korrelation aus der Kovarianz, indem der Zusammenhang zwischen Variablen standardisiert wird. Du teilst die Kovarianz einfach durch die Standardabweichung jeder Variable. Diese Skalierung entfernt Einheiten und Größenordnung und liefert ein standardisiertes Maß zwischen −1 und +1. Dadurch sind Korrelationswerte direkt über Variablen oder Datensätze hinweg vergleichbar.
In der Praxis übernehmen die meisten Statistiktools diese Umrechnung automatisch, sodass du sie selten manuell berechnen musst. Es ist jedoch wichtig zu verstehen, was das Tool im Hintergrund tut. Zum Beispiel erklärt das Verständnis der Umrechnung, warum du nicht in die andere Richtung konvertieren kannst (zumindest nicht ohne Informationen zur Standardabweichung beider Variablen). Die Korrelation enthält weder Einheiten noch Größeninformationen, die für die Rückrechnung zur Kovarianz nötig wären.
Die Kovarianz ist am nützlichsten, wenn Skala und Einheiten der Daten bedeutungsvoll sind oder wenn du die rohe Struktur der Variabilität brauchst. Sie wird häufig in multivariaten Modellen, probabilistischen Verfahren und beim Aufbau von Kovarianzmatrizen für linearalgebraische Methoden verwendet. In diesen Kontexten ermöglicht die Erhaltung der ursprünglichen Variabilität, dass Algorithmen die wahre Struktur der Daten erfassen und das gemeinsame Variieren der Dimensionen verstehen.
Die Korrelation eignet sich hingegen besser für menschliche Interpretation, Datensatzvergleiche und explorative Analysen. Ich nutze sie gern in Visualisierungen wie Heatmaps, um Zusammenhänge auf einen Blick zu sehen und zu vermitteln. Weil die Korrelation den Zusammenhang standardisiert, hilft sie auch bei der Vorbereitung für Verfahren, bei denen es wichtig ist, alle Features auf einer vergleichbaren Skala zu betrachten.
Oft tauchen beide Maße im selben Workflow auf. Kovarianzmatrizen bilden die mathematische Grundlage vieler multivariater Techniken, da sie die ursprüngliche Variabilität erhalten. Korrelationsmatrizen werden dagegen häufig in der Explorationsphase genutzt, um die Struktur des Datensatzes vor der Modellierung zu verstehen.
Manche Modelle können je nach Ziel mit beiden Statistiken arbeiten. Betrachte die Hauptkomponentenanalyse (PCA). Wird PCA auf einer Kovarianzmatrix durchgeführt, beeinflussen Variablen mit größerer Varianz die Komponenten stärker. Das kann sinnvoll sein, wenn Skalenunterschiede bedeutungsvolle Variabilität widerspiegeln. Analysierst du beispielsweise tägliche Aktienrenditen, kann ein volatilerer Titel die Hauptkomponenten angemessen prägen, weil diese Variabilität reales Marktverhalten abbildet.
Eine Korrelationsmatrix standardisiert dagegen die Variablen vor der Zerlegung. Jedes Feature liegt auf derselben Skala, sodass keine Variable dominiert, nur weil sie größere Einheiten oder einen weiteren Zahlenbereich hat. Das ist besonders passend, wenn Variablen in unterschiedlichen Einheiten gemessen werden, etwa Größe (cm), Gewicht (kg), Blutdruck (mmHg) und Cholesterin (mg/dL).
Keine der beiden Herangehensweisen ist pauschal besser. Entscheidend ist, ob Skalenunterschiede sinnvolle Struktur abbilden oder bloß Messartefakte sind.
Ein verbreitetes Missverständnis ist, dass eine hohe Kovarianz automatisch auf einen starken Zusammenhang hindeutet. Große Kovarianzwerte können jedoch schlicht die Skala oder Streuung der Variablen widerspiegeln, nicht die Stärke ihrer Beziehung. Willst du die Stärke beurteilen, musst du standardisieren – also auf die Korrelation schauen.
Du hast den Satz „Korrelation ist nicht Kausalität“ wahrscheinlich schon unzählige Male gehört – und doch ist es das häufigste Missverständnis. Es ist nachvollziehbar, aus einer starken Korrelation auf einen kausalen Zusammenhang zu schließen. Dieses mentale Abkürzen hat unsere Vorfahren über Jahrtausende geschützt. Als Data Professionals sollten wir dieser Abkürzung widerstehen und anerkennen, dass Korrelation allein keinen kausalen Effekt beweist. Sie misst Assoziation, nicht Verursachung; externe Faktoren können beide Variablen zugleich beeinflussen.
Ebenfalls sehr verbreitet ist die Annahme, Kovarianz und Korrelation seien im Grunde dasselbe. Das stimmt nicht. Zwar leitet sich die Korrelation aus der Kovarianz ab, sie standardisiert die Beziehung jedoch – und ist damit eine klar andere Kennzahl, die nicht immer als Ersatz für Kovarianz in Berechnungen taugt.
Schließlich ist wichtig: Beide Kennzahlen beurteilen nur lineare Beziehungen. Nichtlineare Muster können auch dann existieren, wenn Korrelation und Kovarianz niedrig oder nahe null sind. Sich allein auf diese Statistiken zu verlassen, kann wichtige Strukturen übersehen. Mein Rat: Plot deine Daten immer zuerst und schau sie dir an. Das kann dir viel Ärger ersparen, wenn ein offensichtlicher nichtlinearer Zusammenhang vorliegt.
Erstens: Berücksichtige immer die Skala deiner Messung. Unterschiede in Einheiten oder Streuung beeinflussen rohe Maße wie die Kovarianz. Verstehe also, wofür deine Zahlen stehen.
Zweitens: Kläre, was du von deinen Daten brauchst. Die Kovarianz ist am hilfreichsten, wenn die rohe Variabilität wichtig ist – etwa bei der Modellierung oder beim Aufbau von Kovarianzmatrizen für multivariate Analysen. In diesen Kontexten trägt die Größenordnung der Variation sinnvolle Information. Wenn du diese rohe Variabilität nicht benötigst, profitierst du wahrscheinlich von der Standardisierung und leichten Interpretierbarkeit der Korrelation.
Drittens: Plot deine Daten – wirklich immer! Visuelle Inspektion unterstützt die Analyse und ergänzt statistische Zusammenfassungen. Nutze Scatterplots, um Paarbeziehungen zu erkennen, oder Matrizen, um viele Variablen auf einen Blick zu überblicken.
Und zuletzt: Denke an die Auswirkungen deiner Wahl auf nachgelagerte Schritte. Ob du ein rohes Maß wie Kovarianz oder ein standardisiertes wie Korrelation nutzt, prägt Modellierergebnisse und Interpretationen. Richte deine Auswahl daher an deinen Analysezielen aus.
Kovarianz und Korrelation beschreiben beide, wie Variablen gemeinsam variieren, verfolgen aber unterschiedliche Zwecke: Die Kovarianz erhält die ursprüngliche Skala, die Korrelation standardisiert für den Vergleich.
Wenn du mehr über die Exploration deiner Daten erfahren möchtest, sieh dir das Python Exploratory Data Analysis Tutorial an. Und wenn du wissen willst, ob deine Korrelation wirklich auf Kausalität hinweist, schau dir Hypothesis Testing in R an.
Lerne mit DataCamp
Kurs
Kurs
Kurs
Blog
Blog
Nathaniel Taylor-Leach
4 Min.
Tutorial
Matt Crabtree
Tutorial
Laiba Siddiqui
Tutorial
Sejal Jaiswal

