course
Linear Algebra for Data Science in R
4 timmar
21K
Inom dataanalys försöker vi ständigt förstå hur variabler hänger ihop. Du har förmodligen stött på två statistiska mått som ofta används för detta: kovarians och korrelation. De låter lika och blandas ofta ihop. Men vad skiljer dem åt, och hur ska de användas?
Båda beskriver hur variabler rör sig tillsammans. Trots likheterna besvarar dock kovarians och korrelation något olika frågor och fyller därmed olika roller i dataflöden. Kovarians fångar den råa samvariationen mellan egenskaper, medan korrelation standardiserar relationen så att den blir lättare att jämföra.
Låt oss utforska hur denna subtila skillnad påverkar vilket mått vi använder i olika situationer.
Kovarians mäter hur två variabler rör sig tillsammans. Det visar om ökningar i en variabel tenderar att sammanfalla med ökningar eller minskningar i en annan. Det finns tre typer av kovarians:
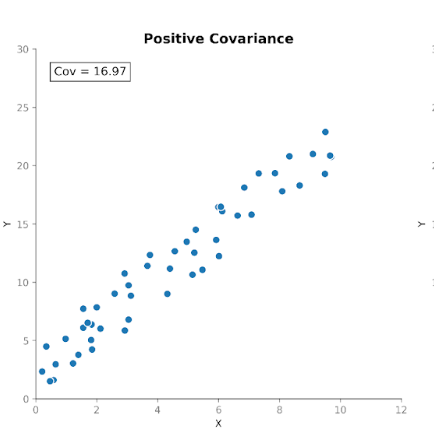
Detta gör kovarians användbart för att upptäcka hur variabler rör sig i förhållande till varandra.
Även om riktningen är värdefull är storleken på kovariansen inte lika enkel att tolka. Storleken beror på måttenheterna såväl som variablernas skala. Att byta enheter, till exempel från centimeter till meter, kan dramatiskt ändra kovariansens storlek utan att påverka den underliggande relationen.
Av denna anledning används kovarians oftare som en intern beräkningsbyggsten än som ett fristående sammanfattande mått.
Korrelation mäter både styrkan och riktningen i relationen mellan två variabler. Den bygger på kovarians genom att standardisera storleken så att enheter inte längre påverkar den.
Korrelationens värden ligger inom ett fast intervall mellan +1 (en perfekt positiv relation) och −1 (en perfekt negativ relation). Ett korrelationsvärde på 0 visar att det inte finns någon linjär relation.
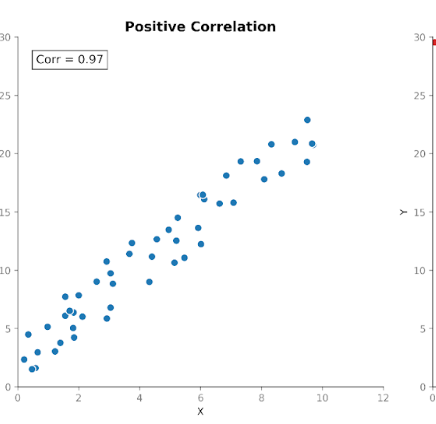
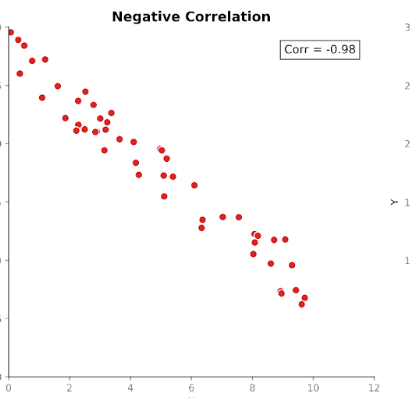
Denna standardiserade skala gör korrelation lättare att tolka än kovarians. Ser vi ett värde på 0,8 kan vi direkt förstå att det finns en stark relation mellan variablerna, oavsett vilka enheter som användes i den ursprungliga mätningen.
Standardiseringen möjliggör också meningsfulla jämförelser mellan dataset, egenskaper och domäner. Det är därför korrelation så ofta används i explorativ dataanalys och vid undersökning av variabler.
Kovarians och korrelation beskriver besläktade egenskaper hos variabelrelationer, men de fyller olika analytiska syften.
I praktiken speglar kovarians rå samvariabilitet, medan korrelation speglar samma relation i standardiserad form. Att förstå skillnaden hjälper dig att avgöra vilket mått som passar bäst för en given analytisk uppgift.
|
Kovarians |
Korrelation |
|
|
Mäter |
Linjär relation (icke-standardiserad) |
Linjär relation (standardiserad) |
|
Känslighet för skala |
Skala bestäms av enheter |
Fast intervall (−1 till +1) |
|
Enheter |
Har enheter |
Enhetslöst |
|
Tolkningsbarhet |
Storlek svår att tolka |
Riktning och storlek lätta att tolka |
|
Jämförbarhet |
Begränsad jämförbarhet mellan dataset |
Direkt jämförbar mellan dataset |
|
Vanlig användning |
Modellering och matrisuppbyggnad |
Utforskning och kommunikation |
|
Fördel |
Bevarar ursprunglig skala |
Standardiserar för jämförelse |
Anta att vi samlar in data om två variabler: längd och vikt. Vi förväntar oss att de är relaterade, eftersom längre personer i allmänhet väger mer. När vi plottar längd i centimeter mot vikt i kilogram ser vi en tydlig uppåtgående trend. När längden ökar tenderar vikten också att öka.
När vi beräknar kovariansen får vi ett positivt värde: 48,08. Att det är positivt visar att de två variablerna rör sig i samma riktning. När längden är över genomsnittet är vikten oftast också över genomsnittet.
Här blir det intressant. Låt oss ta exakt samma data och byta enheter. Vi konverterar längd från centimeter till meter och vikt från kilogram till pounds. Personerna har inte förändrats. Relationen har inte förändrats. Mönstret i spridningsdiagrammet ser likadant ut. Men när vi räknar om kovariansen blir talet annorlunda: 1,06. Det är fortfarande positivt, men storleken är mycket annorlunda. Och det enda vi ändrade var enheterna.
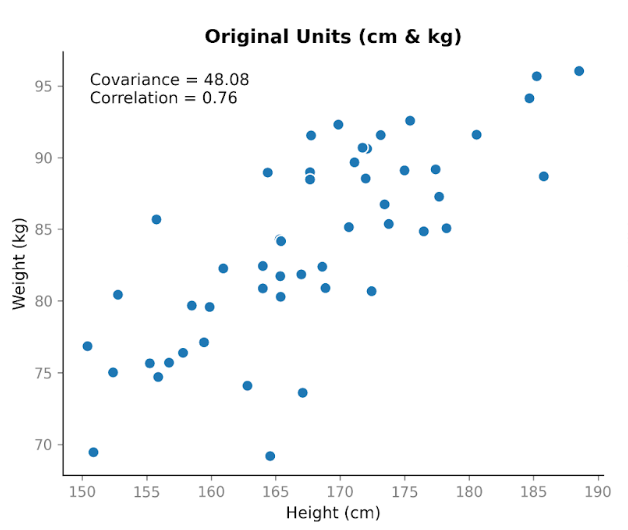
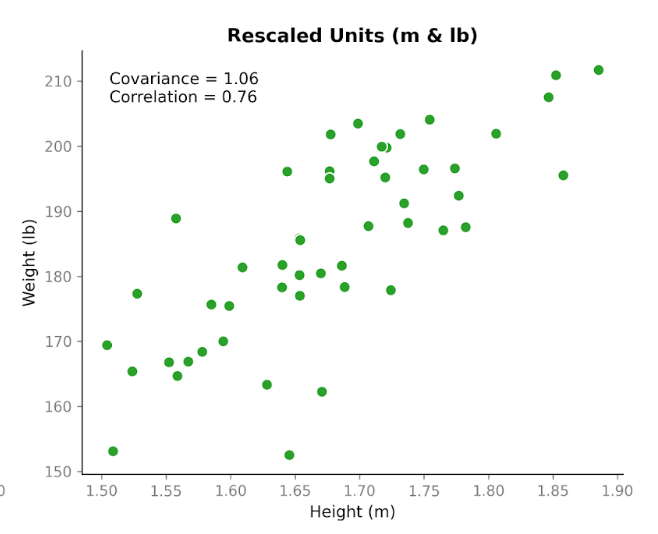
Detta visar en viktig egenskap hos kovarians: den fångar riktning, men storleken beror på skalan. Om vi sträcker ut eller krymper en av variablerna genom att byta enheter, förändras kovariansen på samma sätt.
Låt oss nu titta på korrelation med samma data före och efter enhetsbytet. Korrelationen med centimeter och kilogram är 0,76. Efter konvertering till meter och pounds är den fortfarande 0,76.
Till skillnad från kovarians justerar korrelation för variabiliteten i varje variabel innan relationen mellan dem mäts. Tack vare den justeringen förändras inte värdet när vi byter enheter. Det fokuserar enbart på hur tätt punkterna följer ett linjärt mönster och om mönstret lutar uppåt eller nedåt.
Detta enkla exempel belyser huvudskillnaden mellan dessa mått: kovarians återspeglar både riktning och skala, medan korrelation återspeglar relationsstyrka oberoende av skala. I praktiken innebär detta att korrelation är mer pålitligt för att jämföra relationer mellan variabler mätta på olika skalor, medan kovarians är mer relevant i sammanhang där variabilitetens storlek spelar roll, till exempel vid modellering.
Som vi har diskuterat visar kovarians om två variabler rör sig i samma riktning, men dess storlek är svår att tolka.
Huvudproblemet är att kovarians beror på variablernas skala, inte bara på deras relation. Om värdena i en eller båda variablerna är större eller mer utspridda tenderar kovariansen också att vara större.
Denna känslighet kommer från två källor. Den första är dataenheterna. Att byta enheter ändrar kovariansen. Att mäta inkomst i dollar jämfört med tusentals dollar ger mycket olika kovariansvärden, trots att relationen är identisk.
Den andra källan är mängden variabilitet i variabeln. Även när enheterna förblir desamma kommer ett dataset med ett större omfång eller större spridning vanligtvis att ge en större kovarians än ett snävare dataset med samma underliggande relation. En stor kovarians innebär inte nödvändigtvis en stark relation. Den kan helt enkelt återspegla större skalor eller större variabilitet i data.
På grund av denna skalkänslighet används kovarians ofta internt, till exempel vid anpassning av modeller, i stället för att rapporteras direkt.
Korrelation hanterar många av kovariansens tolkningsutmaningar genom att standardisera relationen mellan variabler. Eftersom korrelationsvärden alltid ligger mellan −1 och +1 är storleken omedelbart meningsfull: värden nära 1 eller −1 indikerar starka linjära relationer, medan värden nära 0 indikerar svaga eller inga linjära relationer. Denna standardisering möjliggör också direkta jämförelser mellan variabler eller dataset, vilket gör korrelation enklare att kommunicera och tolka.
Dessa egenskaper gör korrelation särskilt användbart för explorativ dataanalys, granskning av relationer mellan egenskaper, upptäckt av redundans eller multikollinearitet och för att rapportera resultat. Korrelationsmatriser och heatmaps är också användbara som förstahandsverktyg vid granskning av dataset.
Det betyder inte att korrelation är en fullständig ersättning för kovarians. Eftersom korrelation tar bort skaleffekter återspeglar den bara relationens styrka, inte den råa variabiliteten. I modelleringssammanhang, såsom principalkomponentanalys eller multivariata statistiska modeller, kan den ursprungliga skalan som fångas av kovarians vara viktig för att förstå variansstrukturen och styra algoritmers beteende.
Hittills har vi tittat på kovarians mellan variabler parvis. Linjär algebra visar hur vi kan skala upp idén till hela datasetet på en gång. Det gör vi genom att ordna våra data i en matris.
I en grundläggande datamatris representerar varje rad en observation och varje kolumn en variabel. För att förstå relationer mellan variabler kan vi först centrera data genom att subtrahera kolumnens medelvärde från varje värde. Detta steg gör att vi fokuserar på avvikelser från typiska värden snarare än absoluta värden.
Att multiplicera den centrerade datamatrisen med dess transponat ger en struktur som fångar hur variabler rör sig tillsammans. Denna produkt, efter skalning, är kovariansmatrisen. Ur ett linjäralgebraiskt perspektiv sammanfattar kovariansmatrisen hur variabilitet fördelas över datasetets dimensioner.
Att tänka på kovarians på detta sätt förklarar varför den dyker upp så ofta i data science. Många algoritmer, inklusive principalkomponentanalys (PCA) och andra metoder för dimensionsreduktion, förlitar sig på denna matrisrepresentation för att förstå mönster och struktur i data. Konceptuellt ger kovariansmatrisen en karta över hur datasetets olika dimensioner samverkar.
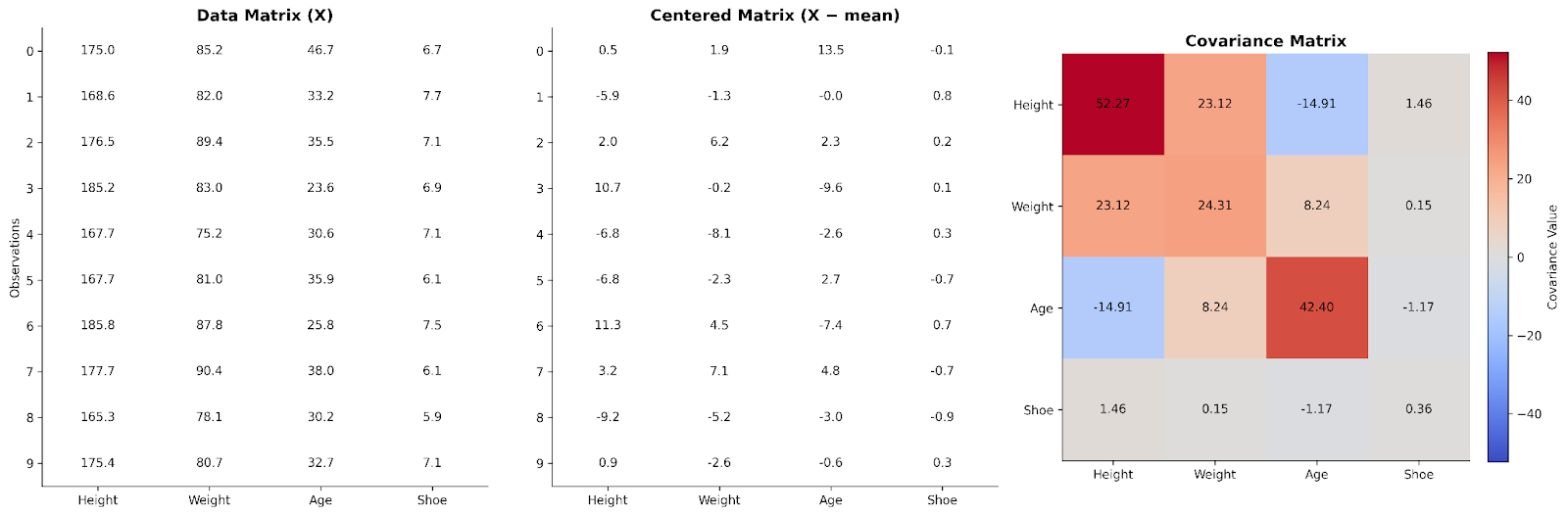
Här ser vi data för fyra variabler ordnade i en datamatris. Den centreras sedan och används för att skapa en kovariansmatris.
Om du vill fördjupa dig i linjär algebra för data science kan du kolla in vår Linear Algebra for Data Science in R-kurs, som täcker grunderna du behöver för att förstå matrisbaserade angreppssätt som kovarians.
Kovariansmatrisen sammanfattar hur variabler rör sig tillsammans i ett helt dataset. I praktiken undersöker vi ofta dessa relationer med antingen kovarians- eller korrelationsmatriser, beroende på om vi vill bevara den ursprungliga skalan eller standardisera resultaten.
En kovariansmatris innehåller kovarianserna mellan alla par av variabler. Diagonalen visar variansen inom varje variabel, medan elementen utanför diagonalen återspeglar hur variabler förändras tillsammans. Eftersom kovarians bevarar dataens ursprungliga skala och enheter fångar matrisen den råa variabilitetsstrukturen. Detta gör kovariansmatriser särskilt användbara i modelleringsflöden och multivariata analyser.
En korrelationsmatris, å andra sidan, standardiserar dessa relationer. Varje diagonalpost är 1, eftersom varje variabel korrelerar exakt med sig själv. Alla element utanför diagonalen ligger mellan −1 och +1 och visar korrelationen mellan variabler. Genom att ta bort skaleffekter blir korrelationsmatriser lättare för människor att tolka och möjliggör direkta jämförelser mellan variabler. De är särskilt användbara i explorativ dataanalys och för att snabbt identifiera starka eller svaga linjära relationer mellan egenskaper.
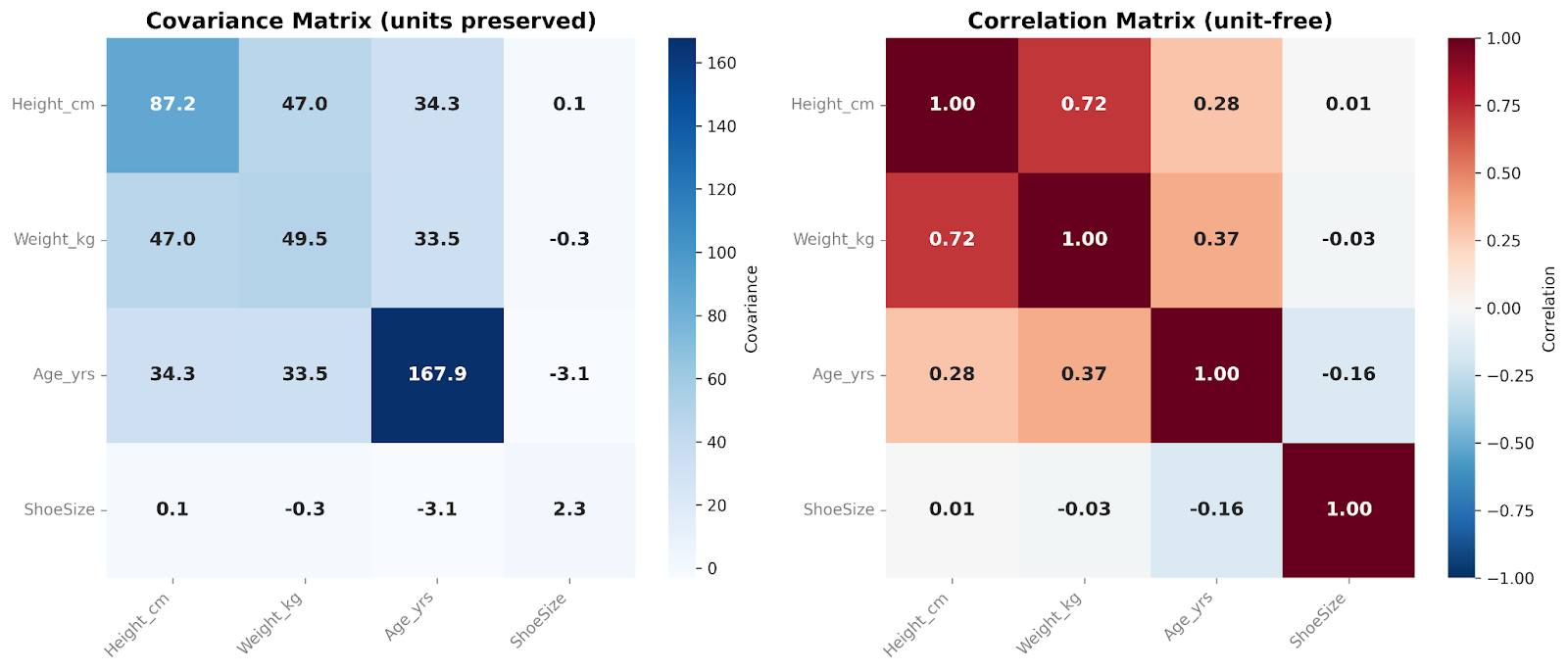
I dessa matriser jämför vi fyra variabler med varandra. Jag gillar att lägga till ett heatmap-överlägg när jag presenterar sådana matriser. Färgen i varje ruta hjälper oss att på ett ögonblick se den relativa storleken på kovarians- eller korrelationsvärdena.
Konceptuellt härleds korrelation från kovarians genom att standardisera relationen mellan variabler. Du delar helt enkelt kovariansen med standardavvikelsen för vardera variabeln. Denna skalning tar bort enheterna och storleken hos variablerna och ger ett standardiserat mått som alltid ligger mellan −1 och +1. Denna transformation är anledningen till att korrelationsvärden är direkt jämförbara mellan olika variabler eller dataset.
I praktiken görs konverteringen automatiskt i de flesta statistiska program, så analytiker behöver sällan räkna ut den manuellt. Det är dock alltid viktigt att förstå vad din mjukvara gör bakom kulisserna. Till exempel förklarar förståelsen för hur kovarians omvandlas till korrelation varför du inte kan konvertera i motsatt riktning (åtminstone inte utan information om standardavvikelsen för båda). Korrelationen innehåller inte längre de enheter eller den storleksinformation som krävs för att konvertera till kovarians.
Kovarians är mest användbar när dataens skala och enheter är meningsfulla eller när du behöver den råa strukturen i din datas variabilitet. Det används ofta i multivariat modellering, probabilistiska modeller och vid uppbyggnad av kovariansmatriser för linjäralgebraiskt baserade metoder. I dessa sammanhang gör bevarandet av den ursprungliga variabiliteten att algoritmer kan fånga den verkliga datastrukturen och förstå hur dimensioner varierar tillsammans.
Korrelation, däremot, lämpar sig bättre för mänsklig tolkning, jämförelser mellan dataset och explorativa analyser. Jag använder gärna detta mått i visualiseringar, såsom heatmaps, så att jag kan se och kommunicera relationerna på ett ögonblick. Eftersom korrelation standardiserar relationen är den också hjälpsam när du förbereder data för tekniker där det kan vara viktigt att behandla alla egenskaper på en jämförbar skala.
Ofta förekommer båda måtten i samma arbetsflöde. Kovariansmatriser utgör den matematiska grunden för många multivariata tekniker eftersom de behåller datans ursprungliga variabilitet. Korrelationsmatriser används å andra sidan ofta under de explorativa stegen för att förstå datasetets struktur innan modellering.
Vissa modeller kan använda endera måttet, beroende på målet. Ta principalkomponentanalys (PCA) som exempel. När PCA utförs på en kovariansmatris får variabler med större varians naturligt större inflytande på de resulterande komponenterna. Detta kan ibland vara önskvärt om skillnader i skala återspeglar meningsfulla skillnader i variabilitet. Om du till exempel analyserar dagliga aktieavkastningar kan en mer volatil aktie med rätta prägla principalkomponenterna, eftersom variabiliteten återspeglar verkligt marknadsbeteende.
Att använda en korrelationsmatris i stället standardiserar variablerna före dekomposition. Varje egenskap läggs på samma skala, så ingen variabel dominerar bara för att den har större enheter eller ett bredare numeriskt omfång. Detta tillvägagångssätt kan vara mer lämpligt när variabler mäts i olika enheter, såsom längd (cm), vikt (kg), blodtryck (mmHg) och kolesterol (mg/dL).
Inget av angreppssätten är generellt sett bättre. Det lämpliga valet beror på om skillnader i skala återspeglar meningsfull struktur eller bara är mätartefakter.
En vanlig missuppfattning är att en hög kovarians automatiskt innebär en stark relation. Stora kovariansvärden kan dock helt enkelt återspegla variablernas skala eller variabilitet snarare än styrkan i deras relation. Om du vill veta relationens styrka behöver du verkligen standardisera den genom att titta på korrelationen.
Du har förmodligen hört frasen “korrelation innebär inte kausalitet” nära nog en miljon gånger! Ändå är det troligen den vanligaste missuppfattningen jag stöter på. Det är förståeligt att se en stark korrelation och anta ett kausalt samband. Det är en genväg våra hjärnor har använt i årtusenden för att hålla våra förfäder vid liv. Men som datapratiker måste vi motstå denna hjärngenväg och inse att korrelation i sig inte räcker för att bevisa en kausal effekt. Korrelation mäter samvariation, inte kausalt inflytande, och externa faktorer kan driva båda variablerna samtidigt.
En annan mycket vanlig missuppfattning är att kovarians och korrelation i princip är samma sak. De är dock inte utbytbara. Även om korrelation härleds från kovarians standardiserar den relationen, vilket gör det till ett tydligt annorlunda mått som inte alltid är en lämplig ersättning för kovarians i beräkningar.
Slutligen är det viktigt att komma ihåg att dessa statistikmått endast utvärderar linjära relationer. Icke-linjära mönster kan finnas även när korrelation och kovarians är låg eller nära noll, så att förlita sig enbart på dessa mått kan göra att viktig struktur i data förbises. Jag rekommenderar alltid att du plottar dina data och tittar på dem innan du försöker tolka statistiska mått. Det kan verkligen rädda dig om det finns en uppenbar icke-linjär relation.
Börja alltid med att beakta din mätningens skala. Skillnader i enheter eller variabilitet kan påverka råa mått som kovarians, så det är viktigt att veta vad dina siffror representerar.
Avgör sedan vad du behöver från dina data. Kovarians är mest användbart när det är viktigt att bevara den råa variabiliteten. Detta är ofta fallet vid modellering eller när du konstruerar kovariansmatriser för multivariata analyser. I dessa sammanhang bär variationsstorleken meningsfull information. Men om du inte behöver den råa variabiliteten kan du föredra korrelationens standardisering och tolkningsbarhet.
För det tredje: plotta alltid, alltid, alltid dina data och titta på dem! Visuell inspektion kan vägleda dina analyser och kompletterar statistiska sammanfattningar. Du kan använda spridningsdiagram för att upptäcka parvisa mönster, eller matriser för att få en snabb översikt över många variabler samtidigt.
Slutligen, tänk på nedströmskonsekvenserna av dina val av mått. Att välja mellan ett rått mått som kovarians och ett standardiserat mått som korrelation kommer att påverka dina modelleringsresultat och tolkningar. Se därför till att ditt val ligger i linje med dina analytiska mål.
Kovarians och korrelation är närbesläktade mått som beskriver hur variabler rör sig tillsammans, men de tjänar olika syften: kovarians bevarar ursprunglig skala, medan korrelation standardiserar för jämförelse.
Om du vill lära dig mer om att utforska dina data, kolla in Python Exploratory Data Analysis Tutorial. För att lära dig hur du tar reda på om din korrelation verkligen visar kausalitet, kolla in Hypothesis Testing in R.
Lär dig med DataCamp
course
course
course