
Corso
Algebra lineare per la Data Science in R
4 h
21K
Nell’analisi dei dati cerchiamo continuamente di capire come le variabili si relazionano tra loro. Probabilmente ti sei imbattuto in due misure statistiche comunemente usate a questo scopo: covarianza e correlazione. Queste misure suonano simili e spesso vengono confuse. Ma qual è la differenza tra le due e come andrebbero usate?
Entrambe descrivono come le variabili si muovono insieme. Tuttavia, nonostante le somiglianze, covarianza e correlazione rispondono a domande leggermente diverse e quindi hanno ruoli differenti nei flussi di lavoro sui dati. La covarianza cattura la variabilità congiunta grezza tra le caratteristiche, mentre la correlazione standardizza quella relazione in modo che sia più facile da confrontare.
Vediamo come questa sottile differenza influisce sulla scelta della misura da usare nelle diverse circostanze.
La covarianza misura come due variabili si muovono insieme. Ci dice se gli aumenti di una variabile tendono a coincidere con aumenti o diminuzioni dell’altra. Esistono tre tipi di covarianza:
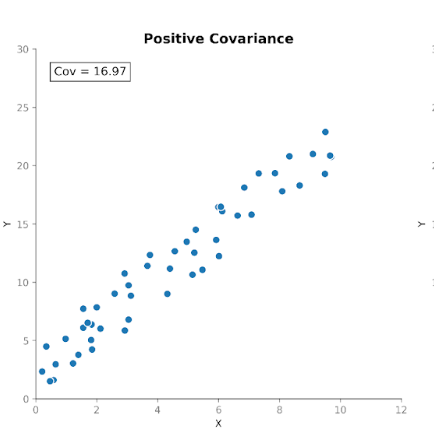
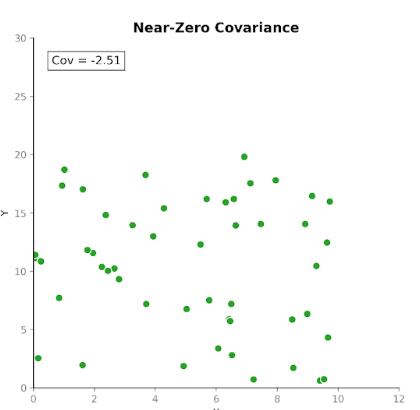
Questo rende la covarianza utile per rilevare come le variabili si muovono l’una rispetto all’altra.
Tuttavia, sebbene la direzione della relazione sia utile, interpretare la magnitudine della covarianza non è così immediato. La magnitudine dipende dalle unità di misura e dalla scala delle variabili. Convertire le unità, ad esempio da centimetri a metri, può cambiare drasticamente la magnitudine della covarianza senza influenzare la relazione sottostante.
Per questo motivo, la covarianza è usata più spesso come componente di calcolo interno che come statistica riassuntiva autonoma.
La correlazione misura l’intensità e la direzione della relazione tra due variabili. Si basa sulla covarianza standardizzandone la magnitudine, così che le unità non la influenzino più.
I valori di correlazione rientrano in un intervallo fisso tra +1 (relazione perfettamente positiva) e -1 (relazione perfettamente negativa). Un valore di correlazione pari a 0 indica assenza di relazione lineare.
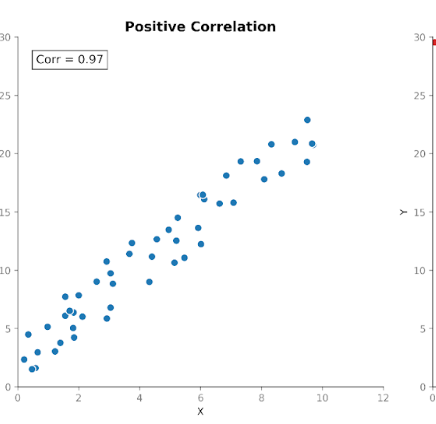
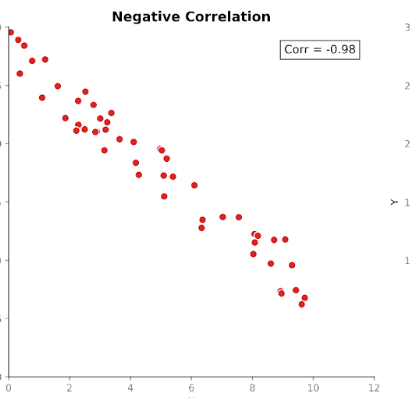
Questa scala standardizzata rende la correlazione più facile da interpretare rispetto alla covarianza. Se vediamo un valore di 0,8 possiamo capire subito che esiste una relazione forte tra le variabili, indipendentemente dalle unità usate nella misura originale.
Questa standardizzazione consente anche confronti significativi tra dataset, caratteristiche e domini. Ecco perché la correlazione è così comunemente usata nelle analisi esplorative dei dati e nelle indagini sulle feature.
Covarianza e correlazione descrivono proprietà correlate delle relazioni tra variabili, ma servono a scopi analitici diversi.
In termini pratici, la covarianza riflette la co-variabilità grezza, mentre la correlazione riflette la stessa relazione in forma standardizzata. Comprendere questa distinzione aiuta a stabilire quale misura si adatta meglio a un determinato compito analitico.
|
Covarianza |
Correlazione |
|
|
Misura |
Relazione lineare (non standardizzata) |
Relazione lineare (standardizzata) |
|
Sensibilità alla scala |
Scala dettata dalle unità |
Intervallo fisso (−1 a +1) |
|
Unità |
Ha unità |
Senza unità |
|
Interpretabilità |
Magnitudine difficile da interpretare |
Direzione e magnitudine facili da interpretare |
|
Confrontabilità |
Confrontabilità limitata tra dataset |
Direttamente confrontabile tra dataset |
|
Uso comune |
Modellazione e costruzione di matrici |
Esplorazione e comunicazione |
|
Vantaggio |
Preserva la scala originale |
Standardizza per il confronto |
Supponiamo di raccogliere dati su due variabili: altezza e peso. Ci aspettiamo che siano correlate, perché in generale le persone più alte tendono a pesare di più. Quando tracciamo l’altezza in centimetri rispetto al peso in chilogrammi, vediamo una chiara tendenza crescente. All’aumentare dell’altezza, tende ad aumentare anche il peso.
Calcolando la covarianza, otteniamo un valore positivo: 48,08. Il fatto che sia positivo ci dice che le due variabili si muovono nella stessa direzione. Quando l’altezza è sopra la media, di solito anche il peso è sopra la media.
Ed ecco la parte interessante. Prendiamo esattamente gli stessi dati e cambiamo le unità. Convertiamo l’altezza da centimetri a metri e il peso da chilogrammi a libbre. Le persone non sono cambiate. La relazione non è cambiata. Il pattern nello scatterplot appare lo stesso. Ma quando ricalcoliamo la covarianza, il numero è diverso: 1,06. È ancora positivo, ma la magnitudine è molto diversa. E l’unica cosa che abbiamo cambiato sono le unità.
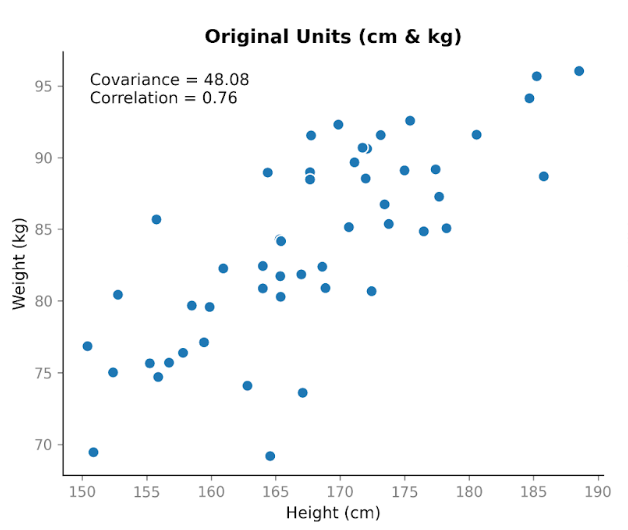
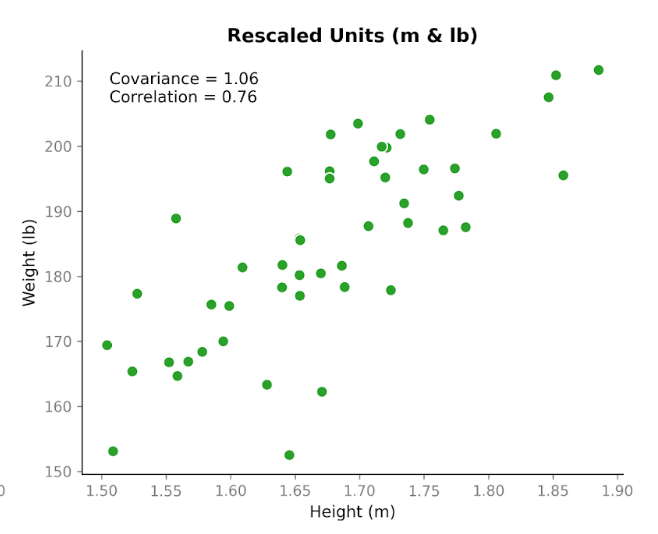
Questo mostra una proprietà importante della covarianza: cattura la direzione, ma la sua magnitudine dipende dalla scala. Se allunghiamo o riduciamo una delle variabili cambiando unità, la covarianza si allunga o si riduce anch’essa.
Ora guardiamo la correlazione usando gli stessi dati prima e dopo la conversione delle unità. La correlazione usando centimetri e chilogrammi è 0,76. Dopo aver convertito in metri e libbre, è ancora 0,76.
A differenza della covarianza, la correlazione corregge la variabilità di ciascuna variabile prima di misurare la relazione tra di esse. Grazie a tale correzione, il valore non cambia quando cambiamo unità. Si concentra solo su quanto strettamente i punti seguono un andamento lineare e se tale andamento è crescente o decrescente.
Questo semplice esempio evidenzia la differenza principale tra queste metriche: la covarianza riflette sia direzione sia scala, mentre la correlazione riflette l’intensità della relazione indipendentemente dalla scala. In pratica, ciò significa che la correlazione è più affidabile per confrontare relazioni tra variabili misurate su scale diverse, mentre la covarianza è più rilevante in contesti in cui la magnitudine della variabilità conta, come nella modellazione.
Come abbiamo discusso, la covarianza ci dice se due variabili si muovono nella stessa direzione, ma la sua magnitudine è difficile da interpretare.
Il problema principale è che la covarianza dipende dalla scala delle variabili, non solo dalla loro relazione. Se i valori di una o di entrambe le variabili sono più grandi o più dispersi, anche la covarianza tenderà a essere più grande.
Questa sensibilità deriva da due fonti. La prima sono le unità dei dati. Cambiare unità cambia la covarianza. Misurare il reddito in dollari rispetto a migliaia di dollari produce valori di covarianza molto diversi, anche se la relazione è identica.
La seconda fonte è la quantità di variabilità nella variabile. Anche quando le unità restano le stesse, un dataset con un intervallo più ampio o una maggiore dispersione produrrà tipicamente una covarianza più grande rispetto a un dataset più compatto con la stessa relazione sottostante. Una covarianza elevata non indica necessariamente una relazione forte. Può semplicemente riflettere scale più grandi o maggiore variabilità nei dati.
A causa di questa sensibilità alla scala, la covarianza è spesso usata internamente, ad esempio per l’adattamento dei modelli, invece di essere riportata direttamente.
La correlazione affronta molte delle difficoltà interpretative della covarianza standardizzando la relazione tra variabili. Poiché i valori di correlazione sono sempre compresi tra −1 e +1, la magnitudine è immediatamente significativa: valori vicini a 1 o −1 indicano relazioni lineari forti, mentre valori prossimi a 0 indicano relazioni lineari deboli o assenti. Questa standardizzazione consente anche confronti diretti tra variabili o dataset, rendendo la correlazione più facile da comunicare e interpretare.
Queste proprietà rendono la correlazione particolarmente utile per l’analisi esplorativa dei dati, l’ispezione delle relazioni tra feature, il rilevamento di ridondanze o multicollinearità e la comunicazione dei risultati. Le matrici di correlazione e le heatmap sono anche utili come strumenti di primo passaggio nell’esame dei dataset.
Detto questo, la correlazione non sostituisce completamente la covarianza. Poiché rimuove gli effetti di scala, riflette solo l’intensità della relazione, non la variabilità grezza. In contesti di modellazione, come l’analisi delle componenti principali o i modelli statistici multivariati, la scala originale catturata dalla covarianza può essere importante per comprendere la struttura della varianza e guidare il comportamento degli algoritmi.
Finora abbiamo osservato la covarianza tra variabili a coppie. L’algebra lineare ci mostra come estendere quest’idea all’intero dataset in una volta sola. Possiamo farlo disponendo i dati in una matrice.
In una matrice dei dati di base, ogni riga rappresenta un’osservazione e ogni colonna una variabile. Per comprendere le relazioni tra variabili, possiamo prima centrare i dati sottraendo a ciascun valore la media della colonna. Questo passaggio assicura che ci si concentri sulle deviazioni dai valori tipici piuttosto che sui valori assoluti.
Moltiplicare la matrice dei dati centrata per la sua trasposta produce una struttura che cattura come le variabili si muovono insieme. Questo prodotto, dopo la scalatura, è la matrice di covarianza. Dal punto di vista dell’algebra lineare, la matrice di covarianza riassume come la variabilità è distribuita lungo le dimensioni del dataset.
Pensare alla covarianza in questo modo aiuta a spiegare perché compare così spesso nella data science. Molti algoritmi, tra cui l’analisi delle componenti principali (PCA) e altre tecniche di riduzione della dimensionalità, si basano su questa rappresentazione matriciale per comprendere pattern e struttura nei dati. Concettualmente, la matrice di covarianza fornisce una mappa di come interagiscono le diverse dimensioni del dataset.
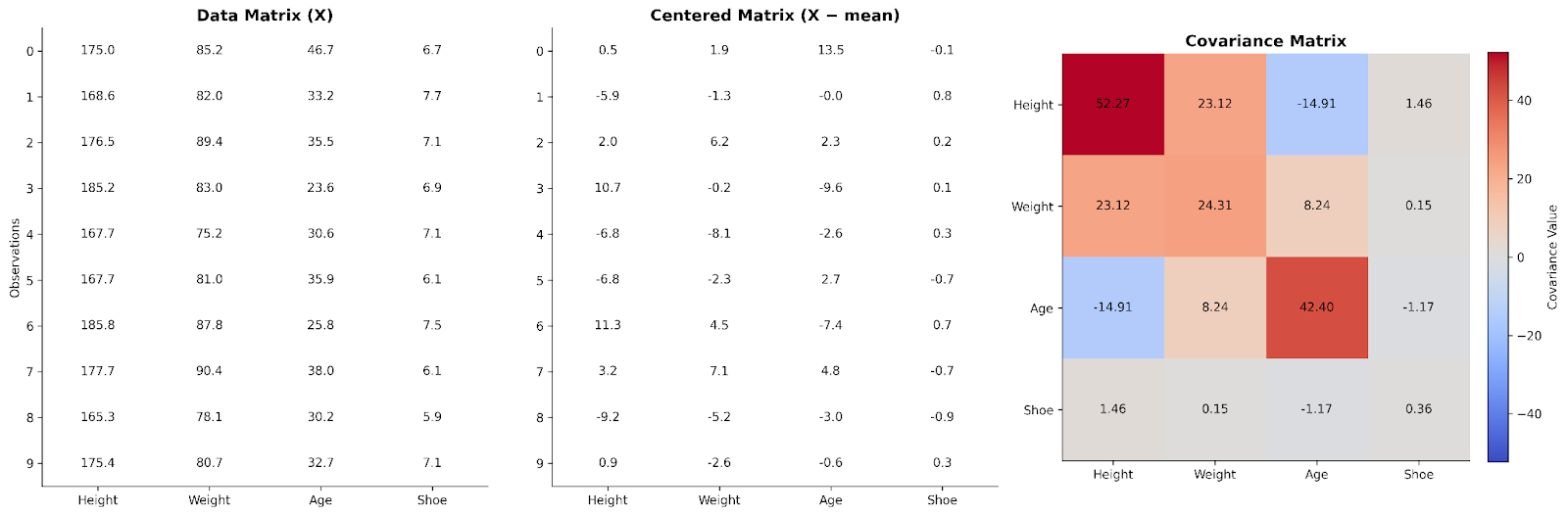
Qui vediamo i dati di quattro variabili disposti in una matrice dei dati. Vengono poi centrati e usati per creare una matrice di covarianza.
Se vuoi approfondire l’algebra lineare per la data science, dai un’occhiata al nostro corso Algebra lineare per la data science in R, che copre le basi necessarie per comprendere approcci basati su matrici come la covarianza.
La matrice di covarianza riassume come le variabili si muovono insieme in un intero dataset. In pratica, esaminiamo spesso queste relazioni usando matrici di covarianza o di correlazione, a seconda che vogliamo preservare la scala originale o standardizzare i risultati.
Una matrice di covarianza contiene le covarianze tra tutte le coppie di variabili. I numeri sulla diagonale mostrano la varianza all’interno di ciascuna variabile, mentre i numeri fuori diagonale riflettono come le variabili cambiano insieme. Poiché la covarianza preserva la scala e le unità originali dei dati, la matrice cattura la struttura grezza della variabilità. Ciò rende le matrici di covarianza particolarmente utili nei flussi di lavoro di modellazione e nelle analisi multivariate.
Una matrice di correlazione, invece, standardizza queste relazioni. Ogni voce diagonale è pari a 1, poiché ogni variabile è perfettamente correlata con sé stessa. Tutti i valori fuori diagonale sono compresi tra −1 e +1 e mostrano la correlazione tra variabili. Rimuovendo gli effetti di scala, le matrici di correlazione sono più facili da interpretare per gli esseri umani e permettono confronti diretti tra variabili. Sono particolarmente utili nell’analisi esplorativa dei dati e per identificare rapidamente relazioni lineari forti o deboli tra le feature.
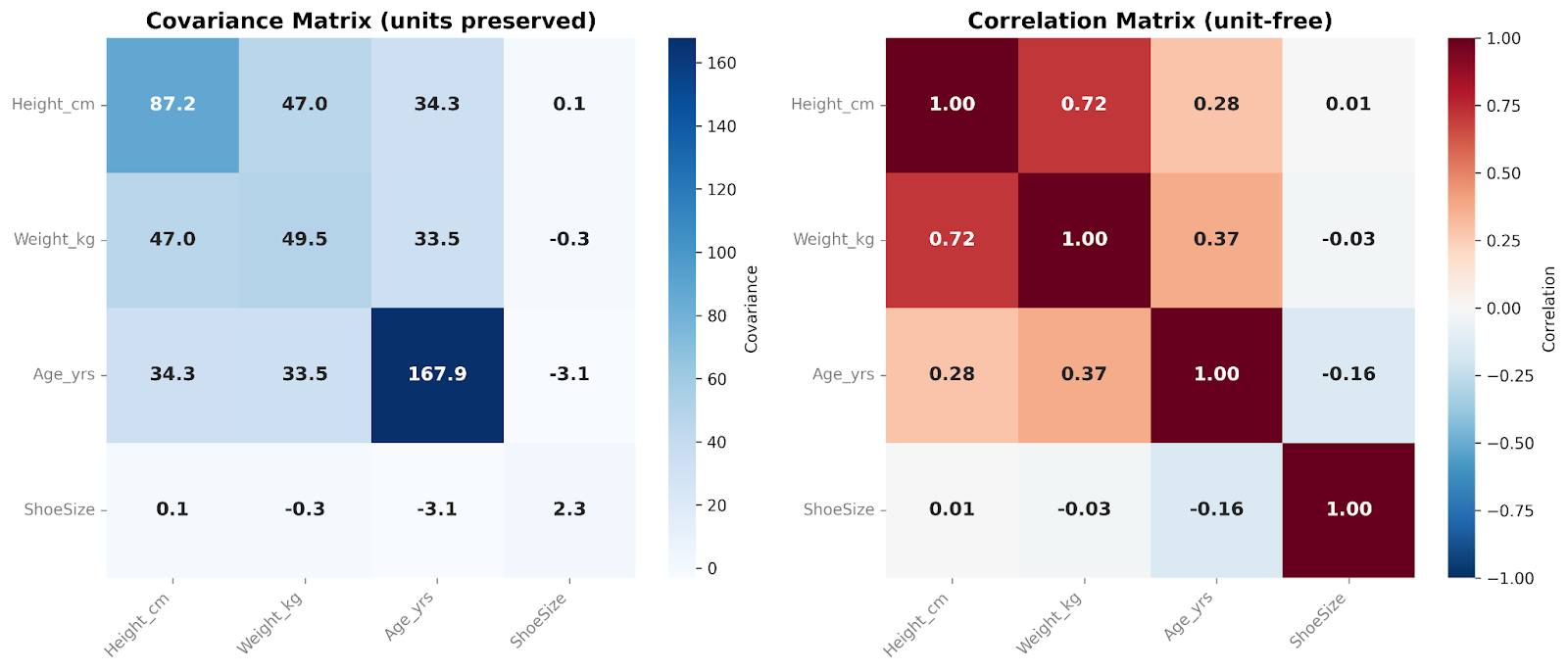
In queste matrici, confrontiamo quattro variabili tra loro. Mi piace aggiungere una heatmap come overlay quando presento queste matrici. Il colore di ciascuna cella ci aiuta a vedere, a colpo d’occhio, la magnitudine relativa dei valori di covarianza o correlazione.
Concettualmente, la correlazione deriva dalla covarianza standardizzando la relazione tra variabili. Basta dividere la covarianza per la deviazione standard di ciascuna variabile. Questa scalatura rimuove le unità e la magnitudine delle variabili, producendo una misura standardizzata che rientra sempre tra −1 e +1. Questa trasformazione è il motivo per cui i valori di correlazione sono direttamente confrontabili tra variabili o dataset diversi.
In pratica, la conversione da covarianza a correlazione è eseguita automaticamente nella maggior parte dei software statistici, quindi raramente gli analisti devono calcolarla manualmente. Tuttavia, è sempre importante capire cosa fa il software dietro le quinte. Ad esempio, comprendere come la covarianza viene convertita in correlazione spiega perché non puoi convertire nella direzione opposta (almeno non senza conoscere la deviazione standard di entrambe). La correlazione non contiene più le unità o le informazioni di magnitudine necessarie per riconvertire in covarianza.
La covarianza è più utile quando la scala e le unità dei dati sono significative o quando ti serve la struttura grezza della variabilità dei dati. È comunemente usata nella modellazione multivariata, nei modelli probabilistici e nella costruzione di matrici di covarianza per metodi basati sull’algebra lineare. In questi contesti, preservare la variabilità originale consente agli algoritmi di catturare la vera struttura dei dati e comprendere come le dimensioni variano insieme.
La correlazione, al contrario, è più adatta all’interpretazione umana, ai confronti tra dataset e alle analisi esplorative. Mi piace usare questa metrica nelle visualizzazioni, come le heatmap, per vedere e comunicare queste relazioni a colpo d’occhio. Poiché la correlazione standardizza la relazione, è anche utile nella preparazione dei dati per tecniche in cui può essere importante trattare tutte le feature su una scala confrontabile.
Spesso entrambe le misure compaiono nello stesso flusso di lavoro. Le matrici di covarianza costituiscono il fondamento matematico di molte tecniche multivariate perché mantengono la variabilità originale dei dati. Le matrici di correlazione, invece, sono usate frequentemente nelle fasi esplorative per comprendere la struttura del dataset prima della modellazione.
Alcuni modelli possono utilizzare entrambe le statistiche, a seconda dell’obiettivo. Considera la Principal Component Analysis (PCA). Quando la PCA è eseguita su una matrice di covarianza, le variabili con varianza maggiore esercitano naturalmente più influenza sulle componenti risultanti. Questo può essere talvolta desiderabile se le differenze di scala riflettono differenze significative di variabilità. Ad esempio, se stai analizzando i rendimenti giornalieri delle azioni, un titolo più volatile può giustamente influenzare le componenti principali perché tale variabilità riflette il reale comportamento del mercato.
Usare invece una matrice di correlazione standardizza le variabili prima della scomposizione. Ogni feature è posta sulla stessa scala, così nessuna variabile domina solo perché ha unità più grandi o un intervallo numerico più ampio. Questo approccio può essere più appropriato quando le variabili sono misurate in unità diverse, come altezza (cm), peso (kg), pressione sanguigna (mmHg) e colesterolo (mg/dL).
Nessun approccio è universalmente migliore. La scelta appropriata dipende dal fatto che le differenze di scala riflettano una struttura significativa o siano semplici artefatti di misura.
Un equivoco comune è che una covarianza alta indichi automaticamente una relazione forte. Tuttavia, valori elevati di covarianza possono semplicemente riflettere la scala o la variabilità delle variabili piuttosto che l’intensità della loro relazione. Se vuoi conoscere la forza della relazione, devi davvero standardizzarla osservando la correlazione.
Probabilmente avrai sentito la frase «la correlazione non implica causalità» un milione di volte! Eppure, è ancora probabilmente il fraintendimento più comune che incontro. È comprensibile guardare una forte correlazione e supporre che esista un legame causale. È una scorciatoia che il nostro cervello usa da millenni per tenere in vita i nostri antenati. Tuttavia, come professionisti dei dati, dobbiamo resistere a questa scorciatoia mentale e riconoscere che la sola correlazione non basta a dimostrare un effetto causale. La correlazione misura l’associazione, non l’influenza causale, e fattori esterni possono guidare simultaneamente entrambe le variabili.
Un altro equivoco molto comune è che covarianza e correlazione siano praticamente la stessa cosa. Tuttavia, non sono intercambiabili. Sebbene la correlazione derivi dalla covarianza, ne standardizza la relazione, rendendola una metrica decisamente diversa che non è sempre un sostituto adatto della covarianza nei calcoli.
Infine, è importante ricordare che queste statistiche valutano solo relazioni lineari. Pattern non lineari possono esistere anche quando correlazione e covarianza sono basse o prossime a zero, quindi affidarsi solo a queste statistiche può far trascurare una struttura importante nei dati. Raccomando sempre di tracciare i dati e osservarli prima di provare a interpretare le misure statistiche. Questo può davvero salvarti se c’è una relazione non lineare evidente.
Per prima cosa, considera sempre la scala della tua misurazione. Differenze di unità o di variabilità possono influenzare misure grezze come la covarianza, quindi è importante sapere che cosa rappresentano i tuoi numeri.
In secondo luogo, chiarisci cosa ti serve dai tuoi dati. La covarianza è più utile quando è importante preservare la variabilità grezza. Ciò accade spesso nella modellazione o quando si costruiscono matrici di covarianza per analisi multivariate. In questi contesti, la magnitudine della variazione porta informazioni significative. Ma se non ti serve quella variabilità grezza, potresti preferire la standardizzazione e l’interpretabilità della correlazione.
Terzo, sempre, sempre, sempre visualizza i tuoi dati e guardali! L’ispezione visiva può guidare le tue analisi e integrare i riepiloghi statistici. Puoi usare scatter plot per individuare pattern a coppie o matrici per avere una panoramica rapida di molte variabili in una volta.
Infine, pensa alle implicazioni a valle delle tue scelte di misurazione. Scegliere tra una misura grezza come la covarianza e una misura standardizzata come la correlazione influenzerà gli esiti della modellazione e le interpretazioni. Quindi assicurati che la tua scelta sia allineata ai tuoi obiettivi analitici.
Covarianza e correlazione sono misure strettamente correlate che descrivono come le variabili si muovono insieme, ma servono a scopi distinti: la covarianza preserva la scala originale, mentre la correlazione standardizza per il confronto.
Se vuoi approfondire l’esplorazione dei tuoi dati, dai un’occhiata al tutorial di Python per l’analisi esplorativa dei dati. Per capire come stabilire se la tua correlazione mostra davvero causalità, dai un’occhiata a Hypothesis Testing in R.
Impara con DataCamp
Corso
Corso
Corso
blog
Tim Lu
12 min
blog
Abid Ali Awan
10 min
blog
Abid Ali Awan
15 min

