
Curso
Álgebra Linear para Data Science em R
4 h
21.2K
Em análises de dados, estamos sempre tentando entender como as variáveis se relacionam entre si. Você provavelmente já esbarrou em duas medidas estatísticas muito usadas para isso: covariância e correlação. Elas soam parecidas e frequentemente geram confusão. Mas qual é a diferença entre elas e como devem ser usadas?
Ambas descrevem como as variáveis se movem juntas. Porém, apesar das semelhanças, covariância e correlação respondem a perguntas ligeiramente diferentes e, por isso, cumprem papéis distintos no fluxo de trabalho em dados. A covariância captura a variabilidade conjunta bruta entre os atributos, enquanto a correlação padroniza essa relação para facilitar a comparação.
Vamos explorar como essa diferença sutil influencia a escolha da melhor medida em cada contexto.
Covariância mede como duas variáveis se movem juntas. Ela indica se aumentos em uma variável tendem a coincidir com aumentos ou diminuições em outra. Existem três tipos de covariância:
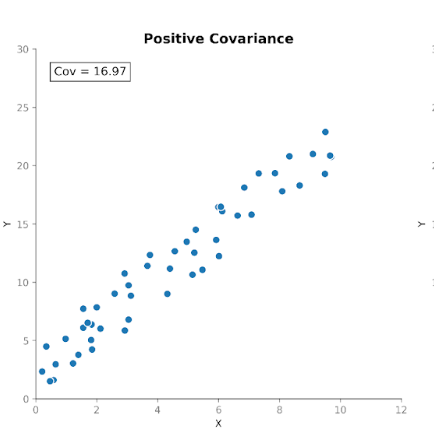
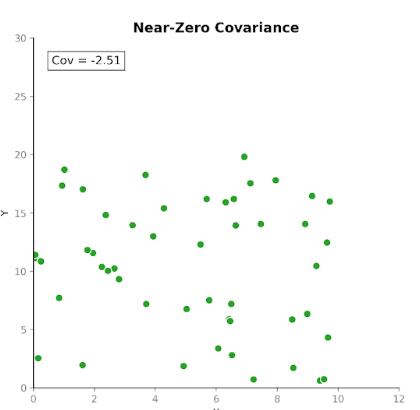
Isso torna a covariância útil para detectar como as variáveis se movem em relação umas às outras.
Porém, embora a direção da relação seja útil, interpretar a magnitude da covariância não é tão simples. A magnitude depende das unidades de medida e da escala das variáveis. Converter unidades, por exemplo, de centímetros para metros, pode alterar drasticamente a magnitude da covariância sem afetar a relação subjacente.
Por esse motivo, a covariância é mais usada como um componente interno de cálculo do que como uma estatística-resumo isolada.
Correlação mede a força e a direção da relação entre duas variáveis. Ela parte da covariância, mas padroniza a magnitude para que as unidades não a influenciem mais.
Os valores de correlação ficam em um intervalo fixo entre +1 (relação perfeitamente positiva) e -1 (relação perfeitamente negativa). Um valor de correlação igual a 0 indica ausência de relação linear.
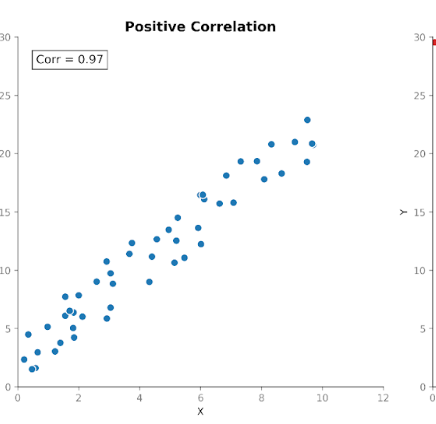
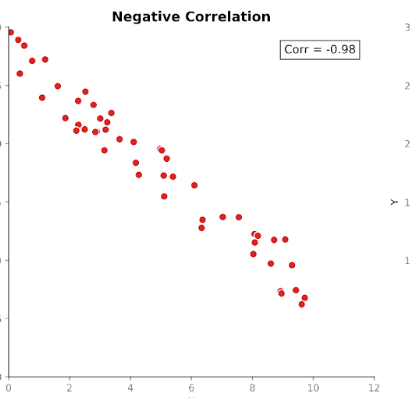
Essa escala padronizada torna a correlação mais fácil de interpretar do que a covariância. Se vemos um valor de 0,8, sabemos de imediato que existe uma relação forte entre as variáveis, independentemente das unidades usadas na medição original.
Essa padronização também permite comparações significativas entre conjuntos de dados, atributos e domínios. Por isso a correlação é tão usada em análises exploratórias e investigações de features.
Covariância e correlação descrevem propriedades relacionadas das relações entre variáveis, mas servem a propósitos analíticos distintos.
Na prática, a covariância reflete a co-variabilidade bruta, enquanto a correlação reflete essa mesma relação em forma padronizada. Entender essa distinção ajuda a escolher qual medida se encaixa melhor em cada tarefa analítica.
|
Covariância |
Correlação |
|
|
Mede |
Relação linear (não padronizada) |
Relação linear (padronizada) |
|
Sensibilidade à escala |
Escala ditada pelas unidades |
Intervalo fixo (−1 a +1) |
|
Unidades |
Possui unidades |
Sem unidade |
|
Interpretabilidade |
Magnitude difícil de interpretar |
Direção e magnitude fáceis de interpretar |
|
Comparabilidade |
Comparabilidade limitada entre datasets |
Comparável diretamente entre datasets |
|
Uso comum |
Modelagem e construção de matrizes |
Exploração e comunicação |
|
Vantagem |
Preserva a escala original |
Padroniza para comparação |
Suponha que coletamos dados de duas variáveis: altura e peso. Esperamos que estejam relacionadas, já que, em geral, pessoas mais altas tendem a pesar mais. Ao plotar altura em centímetros versus peso em quilogramas, vemos uma tendência de alta clara. À medida que a altura aumenta, o peso tende a aumentar também.
Ao calcular a covariância, obtemos um valor positivo: 48,08. O fato de ser positivo indica que as duas variáveis se movem na mesma direção. Quando a altura está acima da média, o peso geralmente também está acima da média.
Agora vem a parte interessante. Vamos pegar exatamente os mesmos dados e mudar as unidades. Converteremos a altura de centímetros para metros e o peso de quilogramas para libras. As pessoas não mudaram. A relação não mudou. O padrão no gráfico de dispersão parece o mesmo. Mas, quando recalculamos a covariância, o número é diferente: 1,06. Continua positivo, mas a magnitude é bem diferente. E a única coisa que mudamos foram as unidades.
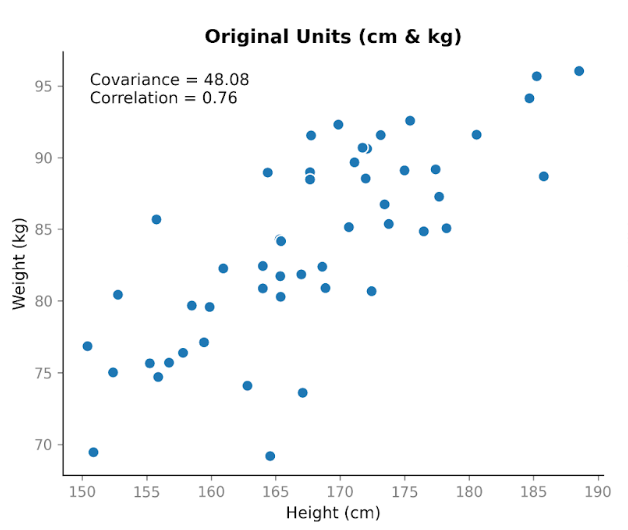
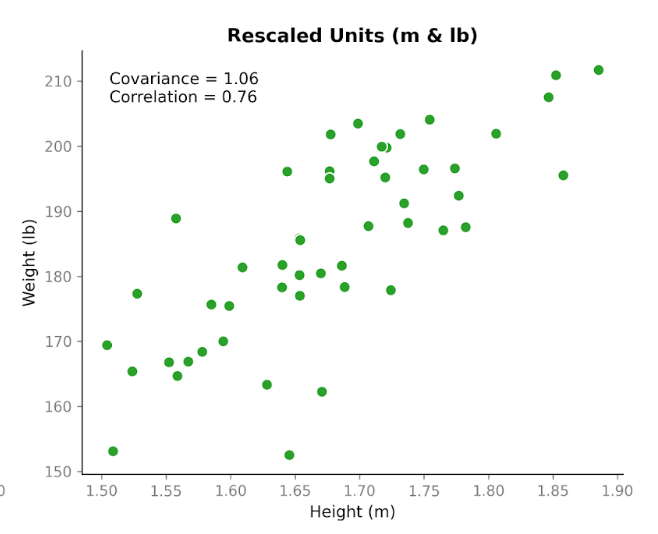
Isso evidencia uma propriedade importante da covariância: ela captura a direção, mas sua magnitude depende da escala. Se esticamos ou comprimimos uma das variáveis ao mudar as unidades, a covariância também se estica ou comprime.
Agora, vamos olhar a correlação usando os mesmos dados antes e depois da conversão de unidades. A correlação usando centímetros e quilogramas é 0,76. Depois de converter para metros e libras, continua 0,76.
Diferentemente da covariância, a correlação ajusta a variabilidade de cada variável antes de medir a relação entre elas. Por causa desse ajuste, o valor não muda quando trocamos as unidades. Ela foca apenas em quão bem os pontos seguem um padrão linear e se esse padrão tem inclinação positiva ou negativa.
Esse exemplo simples destaca a principal diferença entre as métricas: a covariância reflete direção e escala, enquanto a correlação reflete a força da relação independentemente da escala. Na prática, isso significa que a correlação é mais confiável para comparar relações entre variáveis medidas em escalas diferentes, enquanto a covariância é mais relevante em contextos em que a magnitude da variabilidade importa, como na modelagem.
Como vimos, a covariância indica se duas variáveis se movem na mesma direção, mas sua magnitude é difícil de interpretar.
O principal problema é que a covariância depende da escala das variáveis, não apenas da relação entre elas. Se os valores de uma ou ambas as variáveis são maiores ou mais dispersos, a covariância também tende a ser maior.
Essa sensibilidade vem de duas fontes. A primeira são as unidades dos dados. Mudar as unidades muda a covariância. Medir renda em reais versus milhares de reais produz valores de covariância muito diferentes, embora a relação seja idêntica.
A segunda fonte é a quantidade de variabilidade na variável. Mesmo mantendo as unidades, um conjunto de dados com faixa mais ampla ou maior dispersão tende a produzir uma covariância maior do que um conjunto mais concentrado com a mesma relação subjacente. Uma covariância alta não indica necessariamente uma relação forte. Ela pode simplesmente refletir escalas maiores ou maior variabilidade nos dados.
Por causa dessa sensibilidade à escala, a covariância costuma ser usada internamente, por exemplo no ajuste de modelos, em vez de ser reportada diretamente.
A correlação resolve muitos dos desafios de interpretabilidade da covariância ao padronizar a relação entre variáveis. Como os valores de correlação ficam sempre entre −1 e +1, a magnitude é imediatamente significativa: valores próximos de 1 ou −1 indicam relações lineares fortes, enquanto valores próximos de 0 indicam relação linear fraca ou inexistente. Essa padronização também permite comparação direta entre variáveis ou datasets, facilitando a comunicação e a interpretação.
Essas características tornam a correlação especialmente útil para análise exploratória de dados, inspeção de relações entre features, detecção de redundância ou multicolinearidade e comunicação de achados. Matrizes e heatmaps de correlação também são ótimas ferramentas de primeira passada ao examinar datasets.
Dito isso, a correlação não substitui totalmente a covariância. Como ela remove os efeitos de escala, reflete apenas a força da relação, não a variabilidade bruta. Em contextos de modelagem, como análise de componentes principais ou modelos estatísticos multivariados, a escala original capturada pela covariância pode ser importante para entender a estrutura de variância e orientar o comportamento dos algoritmos.
Até aqui, olhamos a covariância entre variáveis em pares. A álgebra linear mostra como escalar essa ideia para o dataset inteiro de uma vez. Fazemos isso organizando os dados em uma matriz.
Em uma matriz de dados básica, cada linha representa uma observação e cada coluna, uma variável. Para entender as relações entre variáveis, podemos primeiro centralizar os dados subtraindo a média da coluna de cada valor. Isso garante que foquemos nos desvios em relação aos valores típicos, e não nos valores absolutos.
Multiplicar a matriz de dados centralizada por sua transposta produz uma estrutura que captura como as variáveis se movem juntas. Esse produto, após o escalonamento, é a matriz de covariância. Do ponto de vista da álgebra linear, a matriz de covariância resume como a variabilidade se distribui pelas dimensões do dataset.
Pensar a covariância desse jeito ajuda a explicar por que ela aparece tanto em ciência de dados. Muitos algoritmos, incluindo análise de componentes principais (PCA) e outras técnicas de redução de dimensionalidade, dependem dessa representação matricial para entender padrões e estrutura nos dados. Conceitualmente, a matriz de covariância oferece um mapa de como as diferentes dimensões do dataset interagem.
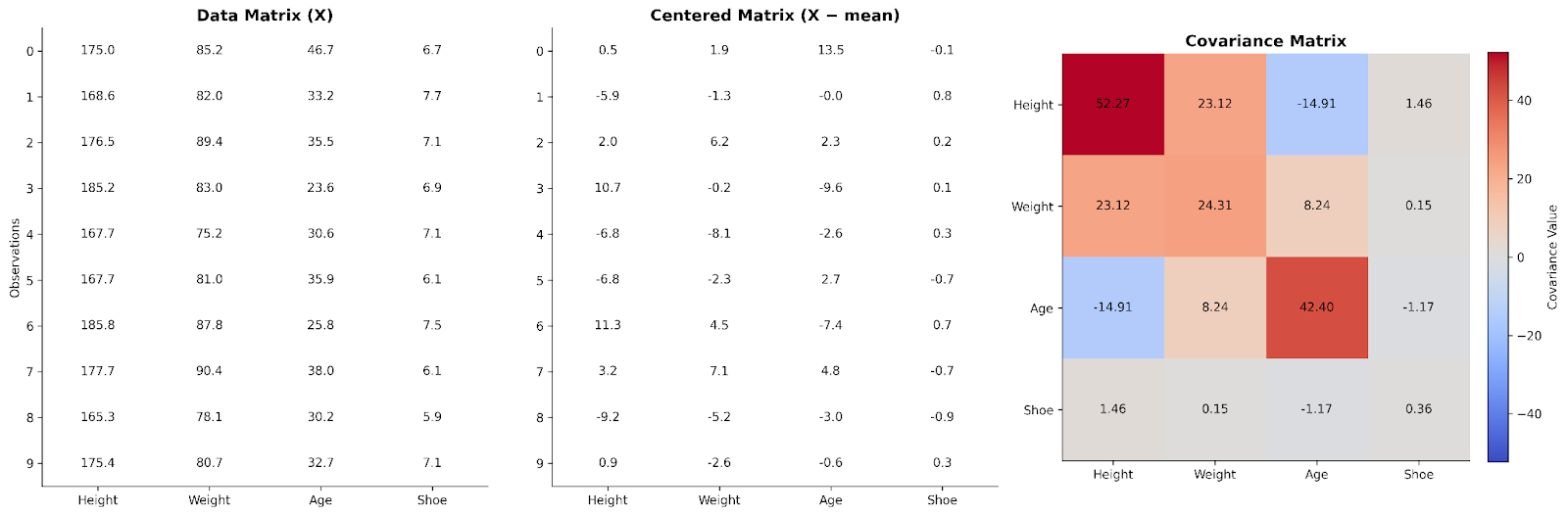
Aqui vemos dados de quatro variáveis organizados em uma matriz de dados. Em seguida, ela é centralizada e usada para formar uma matriz de covariância.
Se você quiser se aprofundar em álgebra linear para ciência de dados, confira nosso curso Linear Algebra for Data Science in R, que cobre as bases necessárias para entender abordagens baseadas em matrizes como a covariância.
A matriz de covariância resume como as variáveis se movem juntas em todo o dataset. Na prática, examinamos essas relações usando matrizes de covariância ou de correlação, dependendo se queremos preservar a escala original ou padronizar os resultados.
Uma matriz de covariância contém as covariâncias entre todos os pares de variáveis. Os números na diagonal mostram a variância dentro de cada variável, enquanto os valores fora da diagonal refletem como as variáveis variam em conjunto. Como a covariância preserva a escala e as unidades originais dos dados, a matriz captura a estrutura bruta da variabilidade. Isso torna as matrizes de covariância particularmente úteis em fluxos de trabalho de modelagem e análises multivariadas.
Já a matriz de correlação padroniza essas relações. Cada entrada da diagonal é igual a 1, já que toda variável se correlaciona perfeitamente consigo mesma. Todos os valores fora da diagonal ficam entre −1 e +1, mostrando a correlação entre as variáveis. Ao remover os efeitos de escala, as matrizes de correlação ficam mais fáceis de interpretar por humanos e permitem comparação direta entre variáveis. Elas são especialmente úteis na análise exploratória e para identificar rapidamente relações lineares fortes ou fracas entre features.
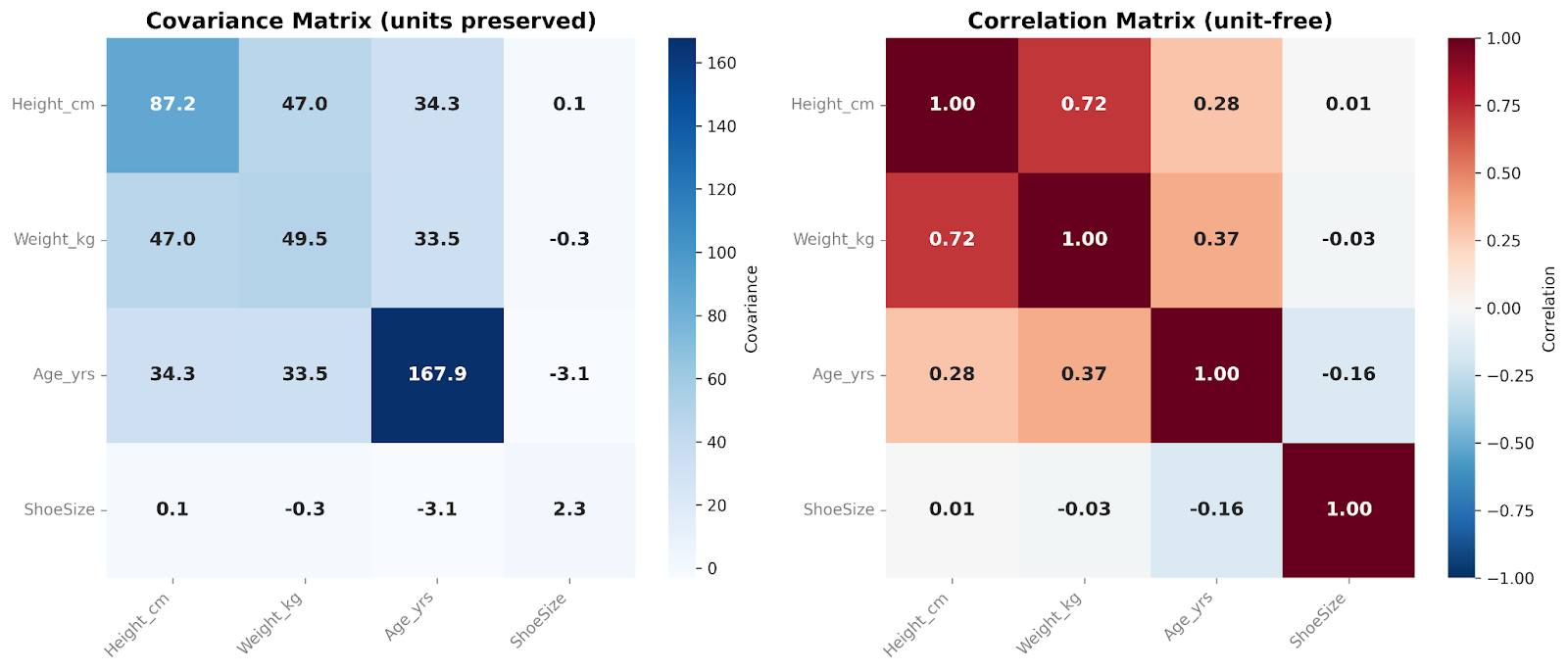
Nessas matrizes, comparamos quatro variáveis entre si. Eu gosto de adicionar um heatmap por cima ao apresentar essas matrizes. A cor de cada célula ajuda a ver, de relance, a magnitude relativa dos valores de covariância ou correlação.
Conceitualmente, a correlação é derivada da covariância pela padronização da relação entre variáveis. Basta dividir a covariância pelo desvio-padrão de cada variável. Esse escalonamento remove as unidades e a magnitude das variáveis, produzindo uma medida padronizada que sempre fica entre −1 e +1. Essa transformação explica por que os valores de correlação são diretamente comparáveis entre diferentes variáveis ou datasets.
Na prática, a conversão de covariância para correlação é feita automaticamente na maioria dos softwares estatísticos, então raramente é preciso calcular manualmente. Porém, é importante entender o que o software faz por trás dos panos. Por exemplo, entender como a covariância é convertida em correlação explica por que você não consegue converter no sentido oposto (pelo menos não sem a informação do desvio-padrão de ambas). A correlação não contém mais as unidades nem a magnitude necessárias para voltar à covariância.
A covariância é mais útil quando a escala e as unidades dos dados são significativas ou quando você precisa da estrutura bruta da variabilidade dos seus dados. Ela é comum em modelagem multivariada, modelos probabilísticos e na construção de matrizes de covariância para métodos baseados em álgebra linear. Nesses contextos, preservar a variabilidade original permite que os algoritmos capturem a verdadeira estrutura dos dados e entendam como as dimensões variam juntas.
Já a correlação é mais indicada para interpretação humana, comparações entre datasets e análises exploratórias. Eu gosto de usar essa métrica em visualizações, como heatmaps, para ver e comunicar essas relações de relance. Como a correlação padroniza a relação, ela também ajuda a preparar os dados para técnicas em que tratar todos os atributos em uma escala comparável pode ser importante.
Muitas vezes, as duas medidas aparecem no mesmo fluxo de trabalho. Matrizes de covariância formam a base matemática de muitas técnicas multivariadas porque retêm a variabilidade original dos dados. Matrizes de correlação, por sua vez, são usadas com frequência nas etapas exploratórias para entender a estrutura do dataset antes da modelagem.
Alguns modelos podem usar qualquer uma das estatísticas, dependendo do objetivo. Considere a análise de componentes principais (PCA). Quando a PCA é feita sobre uma matriz de covariância, variáveis com maior variância naturalmente exercem mais influência nos componentes resultantes. Isso pode ser desejável quando diferenças de escala refletem diferenças significativas de variabilidade. Por exemplo, ao analisar retornos diários de ações, um papel mais volátil pode influenciar adequadamente os componentes principais porque essa variabilidade reflete o comportamento real do mercado.
Usar uma matriz de correlação, por outro lado, padroniza as variáveis antes da decomposição. Cada feature fica na mesma escala, então nenhuma variável domina apenas por ter unidades maiores ou uma faixa numérica mais ampla. Essa abordagem pode ser mais adequada quando as variáveis são medidas em unidades diferentes, como altura (cm), peso (kg), pressão arterial (mmHg) e colesterol (mg/dL).
Nenhuma abordagem é universalmente melhor. A escolha adequada depende de as diferenças de escala refletirem uma estrutura significativa ou serem apenas artefatos de medição.
Um equívoco comum é achar que uma covariância alta indica automaticamente uma relação forte. No entanto, valores altos de covariância podem simplesmente refletir a escala ou a variabilidade das variáveis, e não a força da relação. Se você quer saber a força da relação, precisa padronizá-la olhando a correlação.
Você provavelmente já ouviu a frase "correlação não implica causalidade" um milhão de vezes! E, mesmo assim, ainda é o equívoco mais comum que encontro. É compreensível olhar uma correlação forte e supor um vínculo causal. É um atalho que nosso cérebro usa há milênios para manter nossos ancestrais vivos. Mas, como profissionais de dados, precisamos resistir a esse atalho mental e reconhecer que a correlação, sozinha, não é suficiente para provar efeito causal. Correlação mede associação, não influência causal, e fatores externos podem impulsionar ambas as variáveis simultaneamente.
Outro equívoco muito comum é que covariância e correlação são basicamente a mesma coisa. Não são intercambiáveis. Embora a correlação seja derivada da covariância, ela padroniza a relação, tornando-se uma métrica diferente que nem sempre substitui adequadamente a covariância em cálculos.
Por fim, é importante lembrar que essas estatísticas avaliam apenas relações lineares. Padrões não lineares podem existir mesmo quando a correlação e a covariância são baixas ou próximas de zero, então confiar apenas nessas estatísticas pode deixar passar estruturas importantes nos dados. Eu sempre recomendo plotar os dados e olhar para eles antes de interpretar as medidas estatísticas. Isso pode te salvar quando houver uma relação não linear evidente.
Primeiro, considere sempre a escala da sua medição. Diferenças de unidades ou de variabilidade podem afetar medidas brutas como a covariância, então é importante saber o que seus números representam.
Segundo, defina o que você precisa dos seus dados. A covariância é mais útil quando preservar a variabilidade bruta é importante. Isso é comum na modelagem ou na construção de matrizes de covariância para análises multivariadas. Nesses contextos, a magnitude da variação carrega informação valiosa. Mas, se você não precisa dessa variabilidade bruta, pode preferir a padronização e a interpretabilidade da correlação.
Terceiro: sempre, sempre, sempre plote seus dados e olhe para eles! A inspeção visual pode orientar suas análises e complementar os resumos estatísticos. Use gráficos de dispersão para identificar padrões em pares de variáveis ou matrizes para ter uma visão rápida de muitas variáveis ao mesmo tempo.
Por fim, reflita sobre os impactos a jusante das suas escolhas de medição. Optar por uma medida bruta como a covariância ou por uma medida padronizada como a correlação vai influenciar seus resultados e interpretações de modelagem. Garanta que sua seleção esteja alinhada com seus objetivos analíticos.
Covariância e correlação são medidas intimamente relacionadas que descrevem como as variáveis se movem juntas, mas têm propósitos distintos: a covariância preserva a escala original, enquanto a correlação padroniza para permitir comparação.
Se você quer aprender mais sobre como explorar seus dados, confira o Python Exploratory Data Analysis Tutorial. Para entender se a sua correlação realmente indica causalidade, confira o curso Hypothesis Testing in R.
Aprenda com a DataCamp
Curso
Curso
Curso
blog
Arun Nanda
15 min
blog
Austin Chia
8 min
blog
Matt Crabtree
15 min
Tutorial
Bex Tuychiev
Tutorial
Abid Ali Awan
Tutorial
Avinash Navlani


