
Cursus
Lineaire algebra voor data science in R
4 Hr
21K
In data-analyse proberen we voortdurend te begrijpen hoe variabelen zich tot elkaar verhouden. Je bent waarschijnlijk twee statistische maten tegengekomen die hiervoor vaak worden gebruikt: covariantie en correlatie. Deze maten klinken vergelijkbaar en worden vaak met elkaar verward. Maar wat is het verschil tussen beide, en hoe gebruik je ze?
Beide beschrijven hoe variabelen samen bewegen. Toch beantwoorden covariantie en correlatie, ondanks hun overeenkomsten, net iets andere vragen en spelen ze dus verschillende rollen in dataworkflows. Covariantie vangt de ruwe gezamenlijke variabiliteit tussen kenmerken, terwijl correlatie die relatie standaardiseert zodat hij makkelijker te vergelijken is.
Laten we bekijken hoe dit subtiele verschil bepaalt welke maat we in verschillende situaties gebruiken.
Covariantie meet hoe twee variabelen samen bewegen. Het vertelt ons of toenames in de ene variabele samenvallen met toenames of juist afnames in een andere. Er zijn drie typen covariantie:
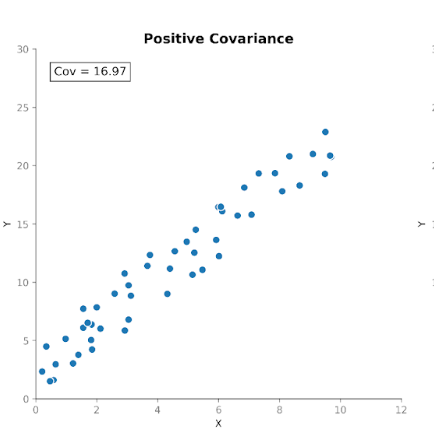
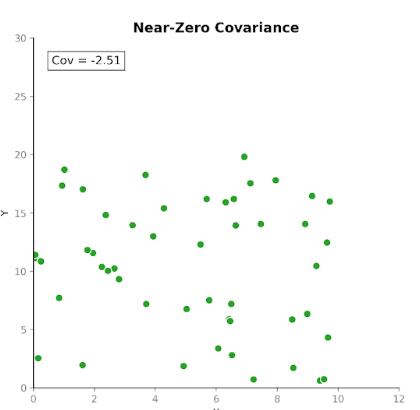
Dit maakt covariantie nuttig om te detecteren hoe variabelen zich ten opzichte van elkaar bewegen.
Hoewel de richting van de relatie nuttig is, is de grootte van de covariantie echter niet zo eenvoudig te interpreteren. De grootte hangt af van de meeteenheden en van de schaal van de variabelen. Het omzetten van eenheden, bijvoorbeeld van centimeters naar meters, kan de omvang van de covariantie drastisch veranderen zonder de onderliggende relatie te beïnvloeden.
Daarom wordt covariantie vaker gebruikt als interne rekenbouwsteen dan als op zichzelf staande samenvattende statistiek.
Correlatie meet zowel de sterkte als de richting van de relatie tussen twee variabelen. Het bouwt voort op covariantie door de grootte te standaardiseren zodat eenheden geen invloed meer hebben.
Correlatiewaarden vallen binnen een vast bereik tussen +1 (een perfect positieve relatie) en -1 (een perfect negatieve relatie). Een correlatiewaarde van 0 vertelt ons dat er geen lineaire relatie is.
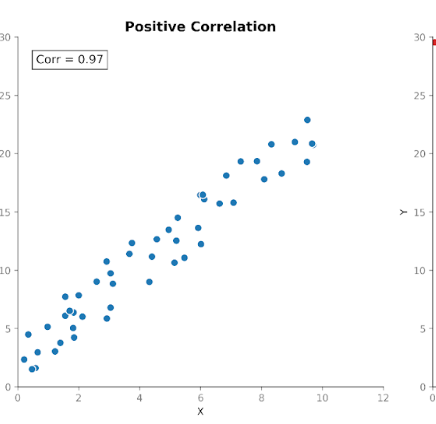
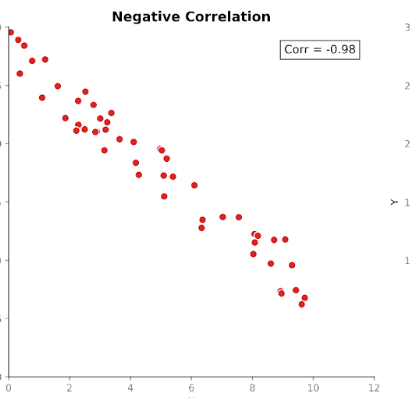
Deze gestandaardiseerde schaal maakt correlatie makkelijker te interpreteren dan covariantie. Als we een waarde van 0,8 zien, weten we meteen dat er een sterke relatie is tussen de variabelen, ongeacht welke eenheden in de oorspronkelijke meting zijn gebruikt.
Deze standaardisatie maakt ook zinvolle vergelijkingen mogelijk tussen datasets, kenmerken en domeinen. Daarom wordt correlatie zo vaak gebruikt in verkennende data-analyses en feature-onderzoeken.
Covariantie en correlatie beschrijven verwante eigenschappen van relaties tussen variabelen, maar ze dienen verschillende analytische doelen.
Praktisch gezien weerspiegelt covariantie ruwe co-variabiliteit, terwijl correlatie diezelfde relatie in gestandaardiseerde vorm weergeeft. Dit onderscheid begrijpen helpt te bepalen welke maat beter past bij een bepaalde analytische taak.
|
Covariantie |
Correlatie |
|
|
Meet |
Lineaire relatie (ongestandaardiseerd) |
Lineaire relatie (gestandaardiseerd) |
|
Gevoeligheid voor schaal |
Schaal bepaald door eenheden |
Vast bereik (−1 tot +1) |
|
Eenheden |
Heeft eenheden |
Zonder eenheid |
|
Interpretatie |
Grootte lastig te interpreteren |
Richting en grootte makkelijk te interpreteren |
|
Vergelijkbaarheid |
Beperkte vergelijkbaarheid tussen datasets |
Direct vergelijkbaar tussen datasets |
|
Gangbaar gebruik |
Modelleren en matrixconstructie |
Exploratie en communicatie |
|
Voordeel |
Behoudt oorspronkelijke schaal |
Standaardiseert voor vergelijking |
Stel, we verzamelen gegevens over twee variabelen: lengte en gewicht. We verwachten dat die gerelateerd zijn, omdat langere mensen over het algemeen meer wegen. Als we lengte in centimeters uitzetten tegen gewicht in kilogrammen, zien we een duidelijke opwaartse trend. Naarmate de lengte toeneemt, neemt het gewicht ook toe.
Als we de covariantie berekenen, krijgen we een positieve waarde: 48,08. Het feit dat die positief is, vertelt ons dat de twee variabelen in dezelfde richting bewegen. Als lengte boven het gemiddelde ligt, ligt gewicht meestal ook boven het gemiddelde.
Nu wordt het interessant. Laten we exact dezelfde data nemen en alleen de eenheden veranderen. We zetten lengte om van centimeters naar meters en gewicht van kilogrammen naar ponden. De mensen zijn niet veranderd. De relatie is niet veranderd. Het patroon in de scatterplot ziet er hetzelfde uit. Maar als we de covariantie opnieuw berekenen, is het getal anders: 1,06. Nog steeds positief, maar de grootte is heel anders. En het enige wat we veranderden, waren de eenheden.
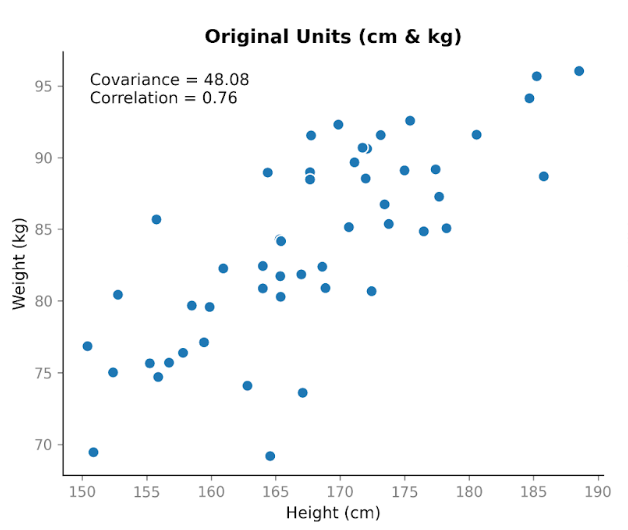
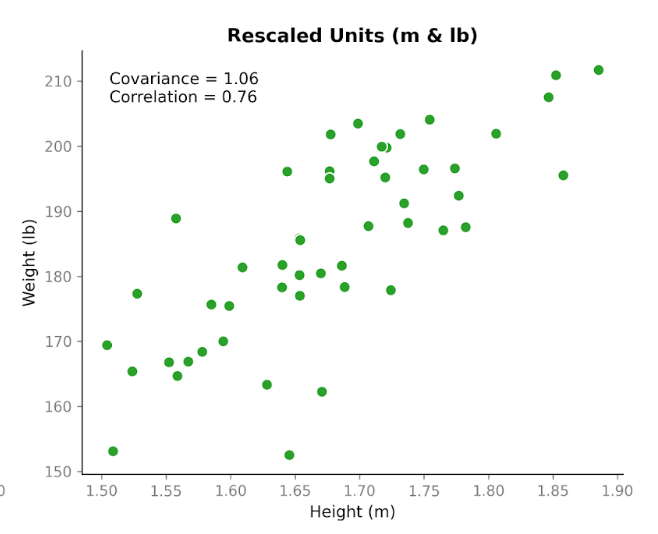
Dit laat een belangrijke eigenschap van covariantie zien: het vangt de richting, maar de grootte hangt af van de schaal. Als we een van de variabelen uitrekken of inkrimpen door de eenheden te veranderen, rekt of krimpt de covariantie mee.
Kijken we nu naar correlatie met dezelfde data vóór en na de eenheidsconversie. De correlatie met centimeters en kilogrammen is 0,76. Na omzetting naar meters en ponden is die nog steeds 0,76.
In tegenstelling tot covariantie, corrigeert correlatie eerst voor de variabiliteit in elke variabele voordat de relatie ertussen wordt gemeten. Door die aanpassing verandert de waarde niet wanneer we van eenheden wisselen. Ze richt zich alleen op hoe strak de punten een lineair patroon volgen en of dat patroon een stijgende of dalende helling heeft.
Dit eenvoudige voorbeeld benadrukt het belangrijkste verschil tussen deze maten: covariantie weerspiegelt zowel richting als schaal, terwijl correlatie de sterkte van de relatie weergeeft, onafhankelijk van schaal. In de praktijk betekent dit dat correlatie betrouwbaarder is om relaties te vergelijken tussen variabelen die op verschillende schalen zijn gemeten, terwijl covariantie relevanter is in contexten waarin de omvang van de variabiliteit ertoe doet, zoals bij modelleren.
Zoals we hebben besproken, vertelt covariantie ons of twee variabelen in dezelfde richting bewegen, maar de grootte is lastig te interpreteren.
Het belangrijkste probleem is dat covariantie afhangt van de schaal van de variabelen, niet alleen van hun relatie. Als de waarden van een of beide variabelen groter of sterker verspreid zijn, zal de covariantie ook de neiging hebben groter te zijn.
Deze gevoeligheid komt uit twee bronnen. De eerste zijn de eenheden van de data. Veranderen van eenheden verandert de covariantie. Inkomen meten in dollars versus in duizenden dollars levert heel verschillende covariantiewaarden op, ook al is de relatie identiek.
De tweede bron is de hoeveelheid variabiliteit in de variabele. Zelfs als de eenheden hetzelfde blijven, zal een dataset met een groter bereik of een grotere spreiding doorgaans een grotere covariantie opleveren dan een strakkere dataset met dezelfde onderliggende relatie. Een grote covariantie duidt niet per se op een sterke relatie. Het kan simpelweg grotere schalen of meer variabiliteit in de data weerspiegelen.
Vanwege deze gevoeligheid voor schaal wordt covariantie vaak intern gebruikt, bijvoorbeeld voor het fitten van modellen, in plaats van direct te worden gerapporteerd.
Correlatie pakt veel van de interpretatieproblemen van covariantie aan door de relatie tussen variabelen te standaardiseren. Omdat correlatiewaarden altijd tussen −1 en +1 liggen, is de grootte direct betekenisvol: waarden dicht bij 1 of −1 duiden op sterke lineaire relaties, terwijl waarden rond 0 op zwakke of geen lineaire relatie wijzen. Deze standaardisatie maakt ook directe vergelijking tussen variabelen of datasets mogelijk, waardoor correlatie eenvoudiger te communiceren en interpreteren is.
Deze eigenschappen maken correlatie bijzonder nuttig voor verkennende data-analyse, het inspecteren van relaties tussen features, het opsporen van redundantie of multicollineariteit, en het rapporteren van bevindingen. Correlatiematrices en heatmaps zijn ook nuttig als eerste hulpmiddel bij het verkennen van datasets.
Toch is correlatie geen volledige vervanging voor covariantie. Omdat correlatie de effecten van schaal verwijdert, weerspiegelt het alleen de sterkte van de relatie, niet de ruwe variabiliteit. In modelleercontexten, zoals principalecomponentenanalyse of multivariate statistische modellen, kan de oorspronkelijke schaal die door covariantie wordt vastgelegd belangrijk zijn om de variancestructuur te begrijpen en het gedrag van algoritmen te sturen.
Tot nu toe hebben we naar covariantie tussen variabelen paar voor paar gekeken. Lineaire algebra laat ons zien hoe we dat idee kunnen opschalen naar de hele dataset tegelijk. Dat kan door onze data in een matrix te plaatsen.
In een basisdatamatrix vertegenwoordigt elke rij een observatie en elke kolom een variabele. Om relaties tussen variabelen te begrijpen, kunnen we de data eerst centreren door van elke waarde het kolomgemiddelde af te trekken. Deze stap zorgt ervoor dat we focussen op afwijkingen van typische waarden in plaats van op absolute waarden.
Het vermenigvuldigen van de gecentreerde datamatrix met zijn transponeren levert een structuur op die vastlegt hoe variabelen samen bewegen. Dit product, na schaling, is de covariantiematrix. Vanuit lineair-algebraïsch perspectief vat de covariantiematrix samen hoe variabiliteit over de dimensies van de dataset is verdeeld.
Op deze manier over covariantie nadenken helpt te verklaren waarom het zo vaak voorkomt in data science. Veel algoritmen, waaronder principalecomponentenanalyse (PCA) en andere technieken voor dimensiereductie, steunen op deze matrixrepresentatie om patronen en structuur in de data te begrijpen. Conceptueel biedt de covariantiematrix een kaart van hoe verschillende dimensies van de dataset interageren.
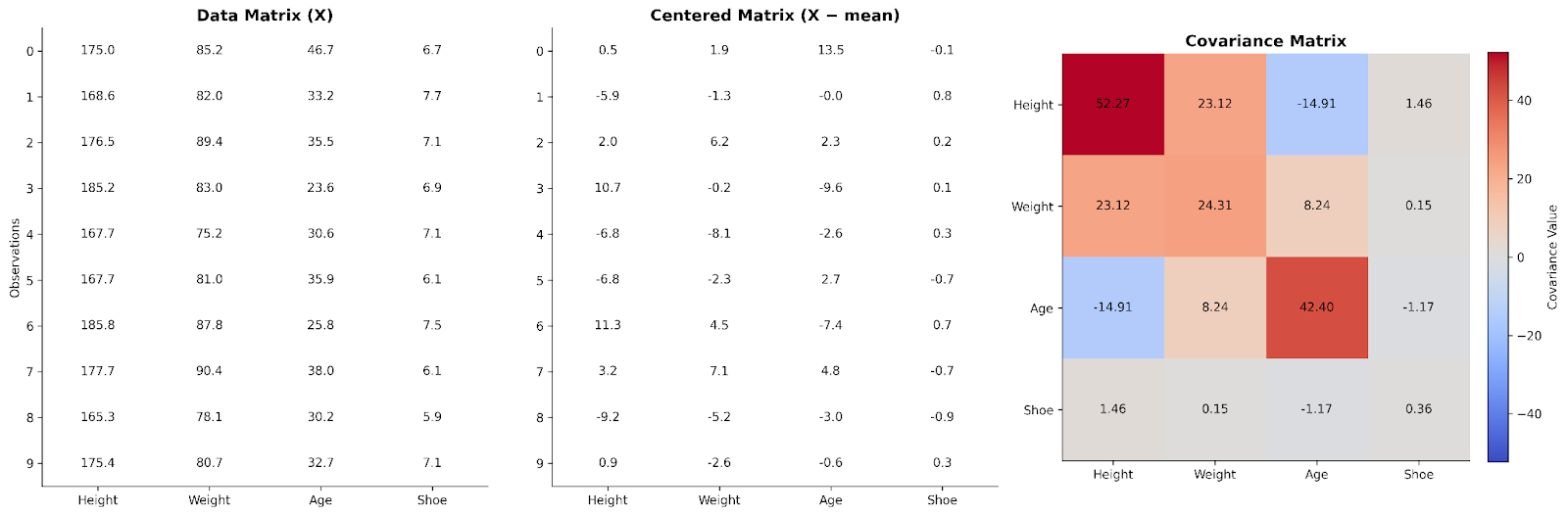
Hier zien we data voor vier variabelen in een datamatrix. Die wordt vervolgens gecentreerd en gebruikt om een covariantiematrix te maken.
Wil je dieper duiken in lineaire algebra voor data science? Bekijk dan onze Linear Algebra for Data Science in R-cursus, die de basis behandelt die je nodig hebt om matrixgebaseerde benaderingen zoals covariantie te begrijpen.
De covariantiematrix vat samen hoe variabelen samen bewegen over een hele dataset. In de praktijk onderzoeken we deze relaties vaak met covariantie- of correlatiematrices, afhankelijk van of we de oorspronkelijke schaal willen behouden of de resultaten willen standaardiseren.
Een covariantiematrix bevat de covarianties tussen alle paren van variabelen. De diagonaal toont de variantie binnen elke variabele, terwijl de niet-diagonale waarden laten zien hoe variabelen samen veranderen. Omdat covariantie de oorspronkelijke schaal en eenheden van de data behoudt, legt de matrix de ruwe structuur van variabiliteit vast. Dit maakt covariantiematrices bijzonder nuttig in modelleerworkflows en multivariate analyses.
Een correlatiematrix daarentegen standaardiseert deze relaties. Elke diagonaalwaarde is gelijk aan 1, omdat elke variabele perfect met zichzelf correleert. Alle niet-diagonale waarden liggen tussen −1 en +1 en tonen de correlatie tussen variabelen. Door schaaleffecten te verwijderen, zijn correlatiematrices voor mensen makkelijker te interpreteren en maken ze directe vergelijking tussen variabelen mogelijk. Ze zijn vooral handig in verkennende data-analyse en om snel sterke of zwakke lineaire relaties tussen features te identificeren.
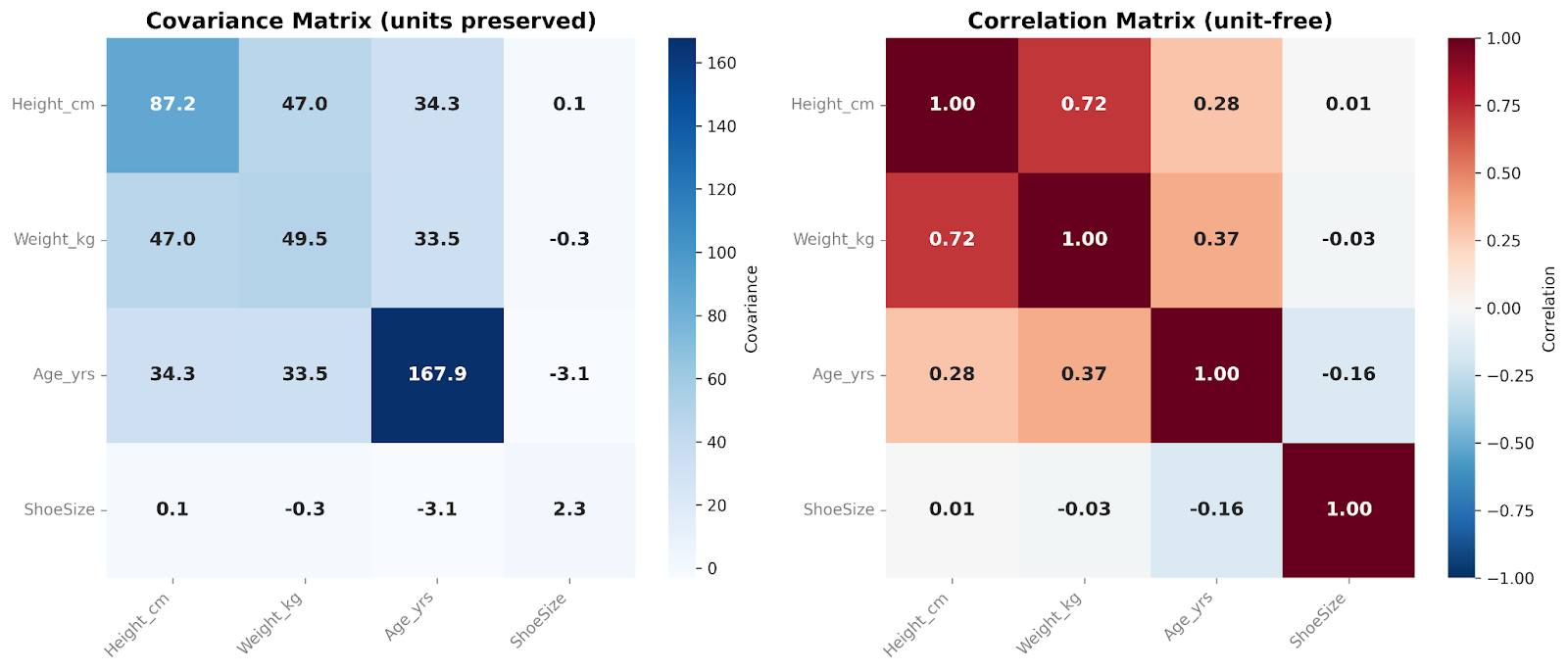
In deze matrices vergelijken we vier variabelen met elkaar. Ik voeg graag een heatmap-overlay toe wanneer ik deze matrices presenteer. De kleur van elke cel helpt ons in één oogopslag de relatieve grootte van de covariantie- of correlatiewaarden te zien.
Conceptueel is correlatie afgeleid van covariantie door de relatie tussen variabelen te standaardiseren. Je deelt eenvoudigweg de covariantie door de standaardafwijking van elke variabele. Deze schaling verwijdert de eenheden en de grootte van de variabelen, en levert een gestandaardiseerde maat op die altijd tussen −1 en +1 valt. Deze transformatie is de reden dat correlatiewaarden direct vergelijkbaar zijn tussen verschillende variabelen of datasets.
In de praktijk gebeurt het omzetten van covariantie naar correlatie automatisch in de meeste statistische software, dus analisten hoeven dit zelden handmatig te berekenen. Het is echter altijd belangrijk om te begrijpen wat je software achter de schermen doet. Zo verklaart het begrijpen van hoe covariantie wordt omgezet in correlatie waarom je niet in de omgekeerde richting kunt converteren (tenminste niet zonder informatie over de standaardafwijking van beide). Correlatie bevat niet langer de eenheden of de informatie over de grootte die nodig is om naar covariantie terug te rekenen.
Covariantie is het nuttigst wanneer de schaal en eenheden van de data betekenisvol zijn of wanneer je de ruwe structuur van de variabiliteit van je data nodig hebt. Het wordt vaak gebruikt in multivariaat modelleren, probabilistische modellen en bij het opbouwen van covariantiematrices voor lineair-algebragebaseerde methoden. In deze contexten stelt het behouden van de oorspronkelijke variabiliteit algoritmen in staat de echte structuur van de data vast te leggen en te begrijpen hoe dimensies samen variëren.
Correlatie daarentegen is beter geschikt voor menselijke interpretatie, vergelijkingen tussen datasets en verkennende analyses. Ik gebruik deze maat graag in visualisaties, zoals heatmaps, zodat ik deze relaties in één oogopslag kan zien en communiceren. Omdat correlatie de relatie standaardiseert, is het ook handig bij het voorbereiden van je data voor technieken waarbij het belangrijk kan zijn om alle features op een vergelijkbare schaal te behandelen.
Vaak komen beide maten in dezelfde workflow voor. Covariantiematrices vormen de wiskundige basis van veel multivariate technieken omdat ze de oorspronkelijke variabiliteit van de data behouden. Correlatiematrices worden daarentegen vaak gebruikt in de verkennende fase om de structuur van de dataset te begrijpen vóór het modelleren.
Sommige modellen kunnen beide statistieken gebruiken, afhankelijk van het doel. Neem principalecomponentenanalyse (PCA). Wanneer PCA wordt uitgevoerd op een covariantiematrix, hebben variabelen met een grotere variantie van nature meer invloed op de resulterende componenten. Dit kan soms wenselijk zijn als schaalverschillen betekenisvolle verschillen in variabiliteit weerspiegelen. Als je bijvoorbeeld dagelijkse aandelenrendementen analyseert, kan een volatieler aandeel de principale componenten terecht sterker bepalen omdat die variabiliteit echt marktgedrag weerspiegelt.
Een correlatiematrix gebruiken standaardiseert in plaats daarvan de variabelen vóór de ontbinding. Elke feature wordt op dezelfde schaal geplaatst, zodat geen enkele variabele domineert enkel omdat die grotere eenheden of een breder numeriek bereik heeft. Deze aanpak kan geschikter zijn wanneer variabelen in verschillende eenheden worden gemeten, zoals lengte (cm), gewicht (kg), bloeddruk (mmHg) en cholesterol (mg/dL).
Geen van beide benaderingen is universeel beter. De juiste keuze hangt ervan af of schaalverschillen betekenisvolle structuur weerspiegelen of simpelweg meetartefacten zijn.
Een veelvoorkomende misvatting is dat een hoge covariantie automatisch op een sterke relatie duidt. Grote covariantiewaarden kunnen echter simpelweg de schaal of variabiliteit van de variabelen weerspiegelen in plaats van de sterkte van hun relatie. Als je de sterkte van de relatie wilt weten, moet je die echt standaardiseren door naar de correlatie te kijken.
Je hebt de uitdrukking “correlatie impliceert geen causaliteit” waarschijnlijk al talloze keren gehoord! En toch is het nog steeds de meest voorkomende misvatting die ik tegenkom. Het is begrijpelijk om bij een sterke correlatie aan te nemen dat er een causaal verband is. Het is een snelkoppeling die onze hersenen al millennia gebruiken om onze voorouders in leven te houden. Maar als dataprofessionals moeten we deze mentale snelkoppeling weerstaan en erkennen dat correlatie op zichzelf niet genoeg is om een causaal effect te bewijzen. Correlatie meet associatie, geen causale invloed, en externe factoren kunnen beide variabelen tegelijk aansturen.
Een andere heel vaak voorkomende misvatting is dat covariantie en correlatie in wezen hetzelfde zijn. Ze zijn echter niet uitwisselbaar. Hoewel correlatie is afgeleid van covariantie, standaardiseert het de relatie, waardoor het een duidelijk andere maat is die niet altijd een geschikte vervanging is voor covariantie in berekeningen.
Tot slot is het belangrijk te onthouden dat deze statistieken alleen lineaire relaties evalueren. Niet-lineaire patronen kunnen bestaan, zelfs wanneer correlatie en covariantie laag of bijna nul zijn, dus alleen op deze statistieken vertrouwen kan belangrijke structuur in de data over het hoofd zien. Ik raad altijd aan om je data te plotten en ernaar te kijken voordat je statistische maten probeert te interpreteren. Dit kan je echt redden als er een overduidelijke niet-lineaire relatie is.
Denk om te beginnen altijd aan de schaal van je meting. Verschillen in eenheden of variabiliteit kunnen ruwe maten zoals covariantie beïnvloeden, dus het is belangrijk om te weten waar je getallen voor staan.
Bepaal vervolgens wat je uit je data nodig hebt. Covariantie is het nuttigst wanneer het behouden van de ruwe variabiliteit belangrijk is. Dit is vaak het geval bij modelleren of bij het opstellen van covariantiematrices voor multivariate analyses. In deze contexten draagt de omvang van variatie betekenisvolle informatie. Maar als je die ruwe variabiliteit niet nodig hebt, geef je misschien de voorkeur aan de standaardisatie en de interpretatiegemak van correlatie.
Ten derde: plot je data altijd, altijd, altijd en kijk ernaar! Visuele inspectie kan je analyses sturen en vult statistische samenvattingen aan. Je kunt scatterplots gebruiken om patronen per paar te spotten, of matrices om snel een overzicht van veel variabelen tegelijk te krijgen.
Denk ten slotte na over de gevolgen stroomafwaarts van je meetkeuzes. De keuze tussen een ruwe maat zoals covariantie en een gestandaardiseerde maat zoals correlatie zal je modelleeruitkomsten en interpretaties beïnvloeden. Zorg er dus voor dat je keuze aansluit bij je analytische doelen.
Covariantie en correlatie zijn nauw verwante maten die beschrijven hoe variabelen samen bewegen, maar ze hebben verschillende doelen: covariantie behoudt de oorspronkelijke schaal, terwijl correlatie standaardiseert voor vergelijking.
Wil je meer leren over het verkennen van je data, bekijk dan de Python Exploratory Data Analysis-tutorial. Wil je leren hoe je kunt achterhalen of je correlatie echt causaliteit aantoont, bekijk dan Hypothesetoetsen in R.
Leren met DataCamp
Cursus
Cursus
Cursus
blog
Adel Nehme
15 min
