
Cours
Algèbre linéaire pour la data science en R
4 h
21.2K
En analyse de données, nous cherchons en permanence à comprendre comment les variables se relient entre elles. Vous avez sans doute croisé deux mesures statistiques courantes pour cela : la covariance et la corrélation. Elles se ressemblent et sont souvent confondues. Mais quelle est la différence entre elles, et comment les utiliser à bon escient ?
Toutes deux décrivent la manière dont des variables évoluent conjointement. Malgré leurs similitudes, covariance et corrélation répondent à des questions légèrement différentes et jouent donc des rôles distincts dans les flux d'analyse. La covariance capture la variabilité conjointe brute entre des caractéristiques, tandis que la corrélation standardise cette relation pour la comparer plus facilement.
Voyons comment cette différence subtile conditionne le choix de la mesure selon les situations.
La covariance mesure la manière dont deux variables évoluent ensemble. Elle indique si les hausses de l'une coïncident plutôt avec des hausses ou des baisses de l'autre. On distingue trois types de covariance :
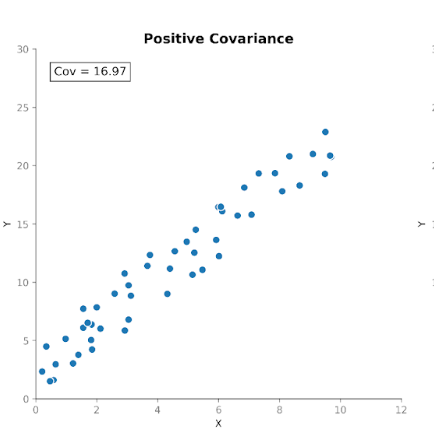
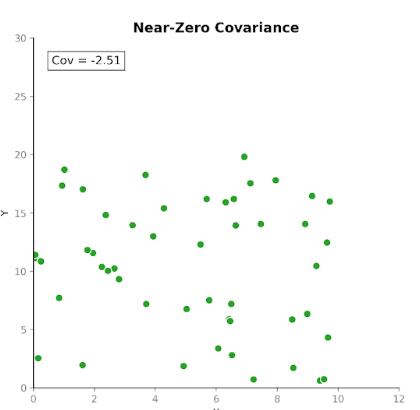
La covariance est utile pour détecter comment des variables évoluent l'une par rapport à l'autre.
Toutefois, si la direction de la relation est informative, l'interprétation de la magnitude de la covariance l'est beaucoup moins. Cette magnitude dépend des unités de mesure et de l'échelle des variables. Convertir des unités, par exemple de centimètres en mètres, peut modifier fortement la valeur de la covariance sans changer la relation sous-jacente.
Pour cette raison, la covariance est plus souvent utilisée comme brique de calcul interne que comme statistique synthétique autonome.
La corrélation mesure la force et la direction de la relation entre deux variables. Elle s'appuie sur la covariance en standardisant la magnitude, de sorte que les unités n'influencent plus la mesure.
Les valeurs de corrélation se situent toujours entre +1 (relation parfaitement positive) et −1 (relation parfaitement négative). Une valeur de 0 indique l'absence de relation linéaire.
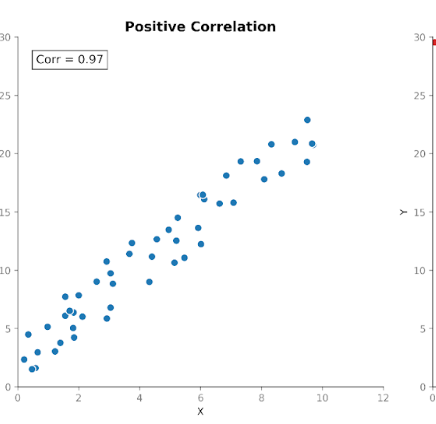
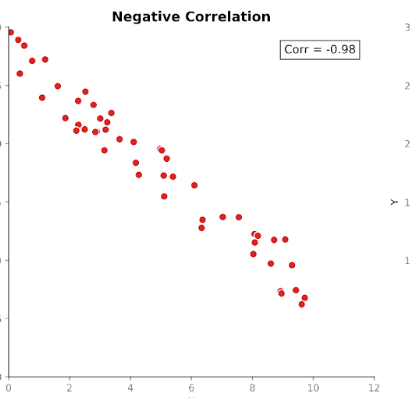
Cette échelle standardisée rend la corrélation plus facile à interpréter que la covariance. Si nous voyons une valeur de 0,8, nous savons immédiatement qu'il existe une relation forte entre les variables, quelles que soient les unités utilisées à l'origine.
Cette standardisation permet également des comparaisons pertinentes entre jeux de données, variables et domaines. C'est pourquoi la corrélation est si couramment employée dans l'analyse exploratoire et l'étude des variables.
Covariance et corrélation décrivent des propriétés liées des relations entre variables, mais leurs finalités analytiques diffèrent.
Concrètement, la covariance reflète la co-variabilité brute, tandis que la corrélation exprime cette même relation sous forme standardisée. Comprendre cette distinction aide à choisir la mesure la mieux adaptée à la tâche analytique.
|
Covariance |
Corrélation |
|
|
Mesure |
Relation linéaire (non standardisée) |
Relation linéaire (standardisée) |
|
Sensibilité à l'échelle |
Échelle dictée par les unités |
Plage fixe (−1 à +1) |
|
Unités |
Avec unités |
Sans unité |
|
Interprétabilité |
Magnitude difficile à interpréter |
Direction et magnitude faciles à interpréter |
|
Comparabilité |
Comparabilité limitée entre jeux de données |
Comparabilité directe entre jeux de données |
|
Usage courant |
Modélisation et construction de matrices |
Exploration et communication |
|
Atout |
Préserve l'échelle d'origine |
Standardise pour la comparaison |
Supposons que nous recueillions des données sur deux variables : taille et poids. On s'attend à ce qu'elles soient liées, puisque, en général, les personnes plus grandes pèsent davantage. En représentant la taille en centimètres en fonction du poids en kilogrammes, on observe une tendance nette à la hausse : quand la taille augmente, le poids a tendance à augmenter aussi.
En calculant la covariance, on obtient une valeur positive : 48,08. Le fait qu'elle soit positive indique que les deux variables évoluent dans le même sens. Quand la taille est au-dessus de la moyenne, le poids l'est généralement aussi.
Voici maintenant le point intéressant. Prenons exactement les mêmes données et changeons les unités. Convertissons la taille de centimètres en mètres et le poids de kilogrammes en livres. Les personnes n'ont pas changé. La relation non plus. Le nuage de points montre le même motif. Mais lorsque nous recalculons la covariance, le nombre est différent : 1,06. Il demeure positif, mais la magnitude a fortement changé. Et la seule chose que nous avons modifiée, ce sont les unités.
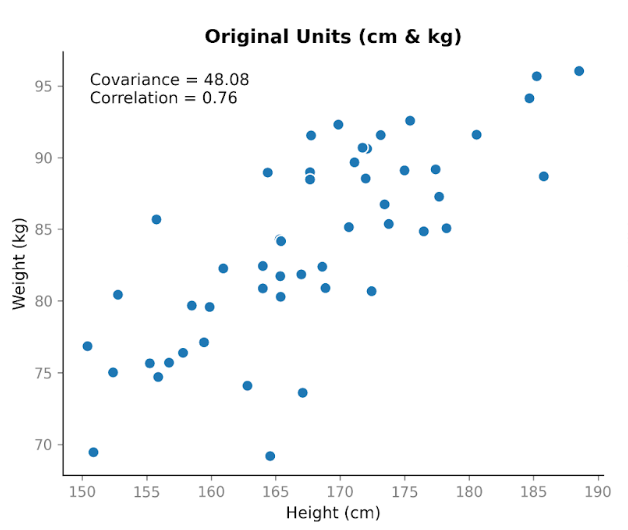
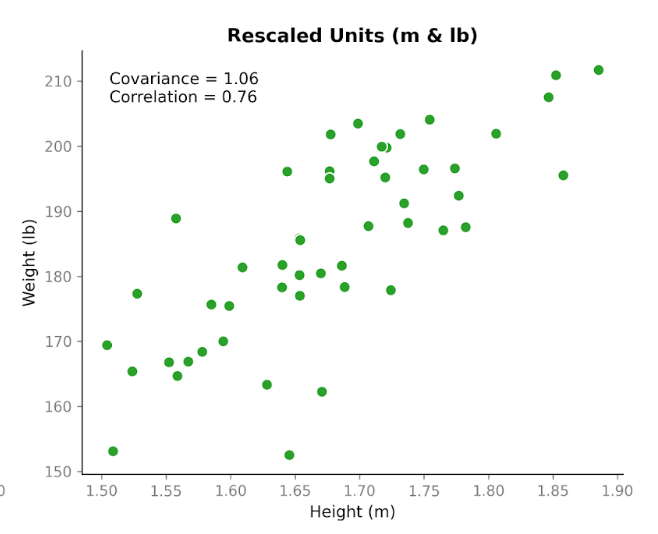
Cela illustre une propriété importante de la covariance : elle capture la direction, mais sa magnitude dépend de l'échelle. Si l'on étire ou compresse une variable en changeant d'unités, la covariance s'étire ou se compresse aussi.
Regardons maintenant la corrélation pour les mêmes données, avant et après conversion d'unités. La corrélation avec tailles en centimètres et poids en kilogrammes est de 0,76. Après conversion en mètres et en livres, elle est toujours de 0,76.
Contrairement à la covariance, la corrélation ajuste la variabilité de chaque variable avant de mesurer leur relation. Grâce à cet ajustement, la valeur ne change pas lorsque l'on modifie les unités. Elle se concentre uniquement sur la force de l'alignement linéaire et sur le sens de la pente (montante ou descendante).
Cet exemple simple met en évidence la différence majeure entre ces mesures : la covariance reflète à la fois la direction et l'échelle, tandis que la corrélation reflète la force de la relation indépendamment de l'échelle. En pratique, la corrélation est donc plus fiable pour comparer des relations entre variables mesurées sur des échelles différentes, tandis que la covariance est plus pertinente lorsque la magnitude de la variabilité compte, par exemple en modélisation.
Comme nous l'avons vu, la covariance indique si deux variables évoluent dans le même sens, mais sa magnitude est ardue à interpréter.
Le principal problème est que la covariance dépend de l'échelle des variables, et pas uniquement de leur relation. Si les valeurs d'une ou des deux variables sont plus grandes ou plus dispersées, la covariance tendra aussi à être plus élevée.
Cette sensibilité provient de deux sources. La première tient aux unités des données. Changer d'unités change la covariance. Mesurer un revenu en dollars plutôt qu'en milliers de dollars produit des valeurs de covariance très différentes, bien que la relation reste identique.
La seconde source concerne l'ampleur de la variabilité de la variable. Même avec des unités inchangées, un jeu de données plus étendu ou plus dispersé produira généralement une covariance plus élevée qu'un jeu plus resserré présentant la même relation sous-jacente. Une grande covariance n'indique pas nécessairement une relation forte : elle peut simplement refléter des échelles plus grandes ou une plus grande variabilité.
En raison de cette sensibilité à l'échelle, la covariance est souvent utilisée en interne, par exemple pour ajuster des modèles, plutôt que d'être communiquée telle quelle.
La corrélation résout bon nombre des difficultés d'interprétation de la covariance en standardisant la relation entre les variables. Comme elle est toujours comprise entre −1 et +1, sa magnitude est immédiatement parlante : des valeurs proches de 1 ou −1 indiquent des relations linéaires fortes, tandis que des valeurs proches de 0 signalent une relation faible ou inexistante. Cette standardisation permet aussi la comparaison directe entre variables ou jeux de données, ce qui facilite la communication et l'interprétation.
Ces propriétés rendent la corrélation particulièrement utile pour l'analyse exploratoire, l'examen des relations entre caractéristiques, la détection de redondances ou de multicolinéarité et la restitution des résultats. Les matrices de corrélation et les cartes thermiques sont aussi de bons outils de premier niveau pour explorer un jeu de données.
Cela dit, la corrélation ne remplace pas totalement la covariance. En supprimant l'effet d'échelle, elle ne conserve que la force de la relation, pas la variabilité brute. En modélisation, comme en analyse en composantes principales ou dans des modèles statistiques multivariés, l'échelle d'origine capturée par la covariance peut être cruciale pour comprendre la structure de variance et guider le comportement des algorithmes.
Jusqu'ici, nous avons examiné la covariance entre paires de variables. L'algèbre linéaire montre comment étendre ce raisonnement à l'ensemble du jeu de données. Pour cela, on organise les données en matrice.
Dans une matrice de données simple, chaque ligne représente une observation et chaque colonne une variable. Pour étudier les relations entre variables, on commence par centrer les données en soustrayant la moyenne de chaque colonne à ses valeurs. Cette étape permet de se focaliser sur les écarts aux valeurs typiques plutôt que sur les valeurs absolues.
Multiplier la matrice centrée par sa transposée produit une structure qui capture la manière dont les variables évoluent ensemble. Ce produit, après mise à l'échelle, est la matrice de covariance. D'un point de vue algèbre linéaire, elle résume la distribution de la variabilité à travers les dimensions du jeu de données.
Penser la covariance ainsi explique sa présence fréquente en data science. De nombreux algorithmes, dont l'analyse en composantes principales (PCA) et d'autres techniques de réduction de dimension, s'appuient sur cette représentation matricielle pour comprendre motifs et structure des données. Conceptuellement, la matrice de covariance fournit une cartographie des interactions entre dimensions du jeu de données.
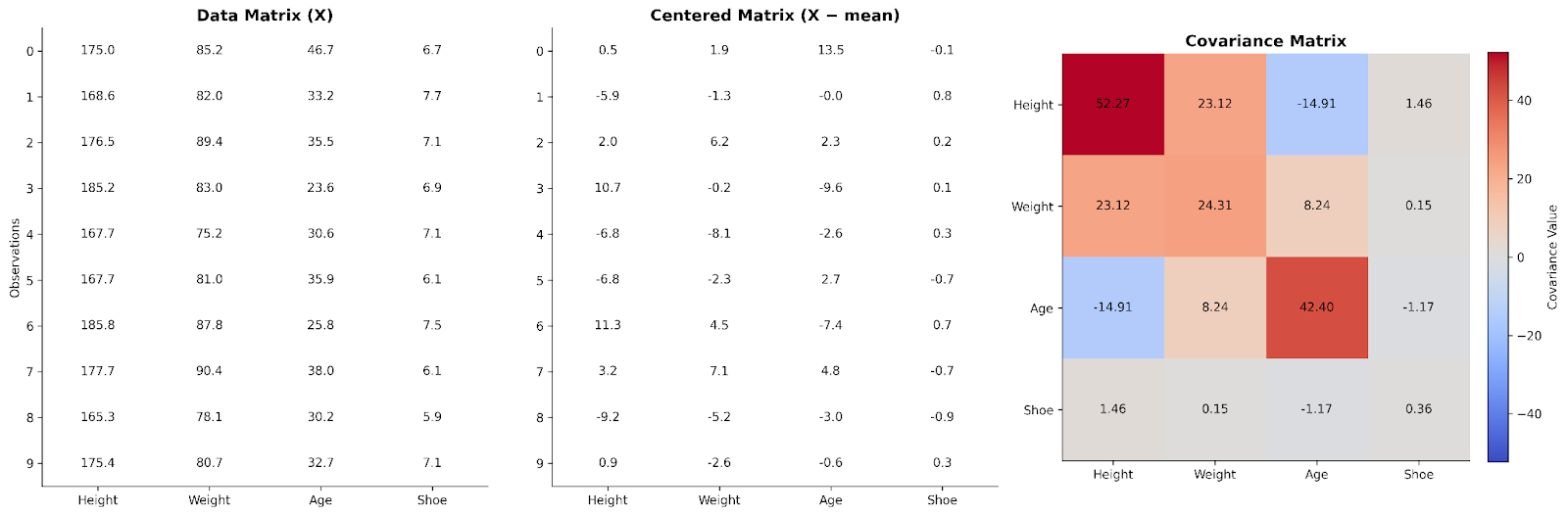
Ici, on voit des données pour quatre variables organisées en matrice de données. Elles sont ensuite centrées et utilisées pour construire une matrice de covariance.
Pour approfondir l'algèbre linéaire appliquée à la data science, découvrez notre cours Linear Algebra for Data Science in R, qui couvre les bases nécessaires pour comprendre les approches matricielles comme la covariance.
La matrice de covariance résume la manière dont les variables évoluent ensemble sur l'ensemble d'un jeu de données. En pratique, on étudie souvent ces relations via des matrices de covariance ou de corrélation, selon que l'on souhaite préserver l'échelle d'origine ou standardiser les résultats.
Une matrice de covariance contient les covariances entre toutes les paires de variables. Les éléments diagonaux indiquent la variance de chaque variable, tandis que les éléments hors diagonale reflètent leur coévolution. Comme la covariance préserve l'échelle et les unités des données, la matrice capture la structure brute de la variabilité. Elle est particulièrement utile en modélisation et en analyses multivariées.
Une matrice de corrélation, à l'inverse, standardise ces relations. Chaque terme diagonal vaut 1, puisqu'une variable est parfaitement corrélée avec elle-même. Tous les termes hors diagonale se situent entre −1 et +1 et indiquent la corrélation entre variables. En supprimant les effets d'échelle, les matrices de corrélation sont plus lisibles et permettent des comparaisons directes. Elles sont particulièrement utiles en analyse exploratoire pour repérer rapidement des relations linéaires fortes ou faibles entre caractéristiques.
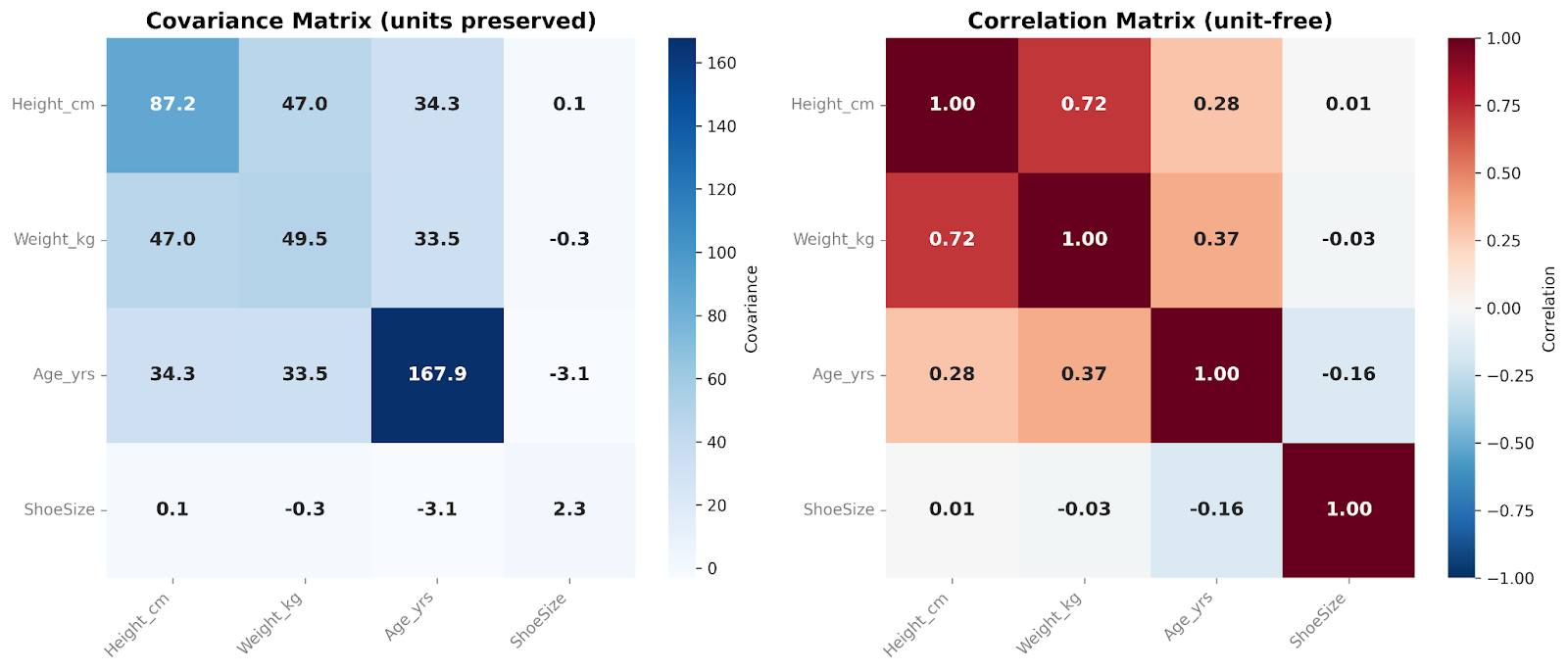
Dans ces matrices, nous comparons quatre variables entre elles. J'aime ajouter une surcouche de carte thermique lors de présentations. La couleur de chaque cellule permet de visualiser d'un coup d'œil l'ordre de grandeur relatif des valeurs de covariance ou de corrélation.
Conceptuellement, la corrélation est dérivée de la covariance en standardisant la relation entre variables. Il suffit de diviser la covariance par l'écart type de chaque variable. Cette mise à l'échelle supprime les unités et la magnitude des variables, produisant une mesure standardisée toujours comprise entre −1 et +1. C'est cette transformation qui rend les corrélations directement comparables entre différentes variables ou jeux de données.
En pratique, cette conversion est automatisée dans la plupart des logiciels statistiques, si bien que les analystes la calculent rarement à la main. Il reste toutefois important de comprendre ce que fait l'outil en coulisses. Par exemple, comprendre comment la covariance est convertie en corrélation explique pourquoi l'on ne peut pas convertir dans l'autre sens (du moins pas sans connaître les écarts types des deux variables). La corrélation ne contient plus les unités ni l'information de magnitude nécessaires pour revenir à la covariance.
La covariance est particulièrement utile lorsque l'échelle et les unités des données sont porteuses de sens, ou lorsque vous avez besoin de la structure brute de la variabilité. On l'emploie couramment en modélisation multivariée, dans les modèles probabilistes et pour construire des matrices de covariance pour des méthodes fondées sur l'algèbre linéaire. Dans ces contextes, préserver la variabilité d'origine permet aux algorithmes de capturer la véritable structure des données et de comprendre comment les dimensions varient conjointement.
La corrélation, à l'inverse, est mieux adaptée à l'interprétation humaine, aux comparaisons entre jeux de données et aux analyses exploratoires. J'aime utiliser cette mesure dans des visualisations, comme des cartes thermiques, pour voir et communiquer ces relations en un clin d'œil. Comme elle standardise la relation, elle est aussi utile pour préparer vos données à des techniques où il est important de mettre les variables sur une échelle comparable.
Souvent, les deux mesures coexistent dans un même flux. Les matrices de covariance constituent la base mathématique de nombreuses techniques multivariées, car elles conservent la variabilité d'origine. Les matrices de corrélation, quant à elles, sont fréquemment utilisées en phase exploratoire pour comprendre la structure du jeu de données avant la modélisation.
Certains modèles peuvent utiliser l'une ou l'autre statistique, selon l'objectif. Prenons la PCA. Lorsqu'elle est effectuée sur une matrice de covariance, les variables à forte variance influencent naturellement davantage les composantes. Cela peut être souhaitable si les différences d'échelle reflètent des différences de variabilité significatives. Par exemple, en analysant des rendements boursiers quotidiens, un titre plus volatil peut à juste titre façonner les composantes principales, car cette variabilité reflète un comportement de marché réel.
Utiliser à la place une matrice de corrélation standardise les variables avant la décomposition. Chaque caractéristique est placée sur la même échelle, de sorte qu'aucune ne domine simplement parce qu'elle a de plus grandes unités ou une plage numérique plus large. Cette approche est plus appropriée lorsque les variables sont mesurées dans des unités différentes, comme la taille (cm), le poids (kg), la pression artérielle (mmHg) et le cholestérol (mg/dL).
Aucune approche n'est universellement meilleure. Le choix pertinent dépend de la question de savoir si les différences d'échelle reflètent une structure significative ou ne sont que des artefacts de mesure.
Une idée reçue fréquente est qu'une covariance élevée indique automatiquement une relation forte. Or, de grandes valeurs de covariance peuvent simplement refléter l'échelle ou la variabilité des variables plutôt que la force de leur lien. Si vous souhaitez évaluer la force de la relation, il faut la standardiser en examinant la corrélation.
Vous avez probablement entendu l'expression « corrélation n'implique pas causalité » des centaines de fois ! Et pourtant, c'est sans doute l'idée reçue la plus courante. Il est tentant de voir une corrélation forte et d'en déduire une relation causale : c'est un raccourci que notre cerveau utilise depuis des millénaires. En tant que praticiens de la donnée, nous devons résister à ce biais et reconnaître que la corrélation seule ne prouve pas un effet causal. La corrélation mesure une association, pas une influence causale, et des facteurs externes peuvent piloter simultanément les deux variables.
Autre idée répandue : covariance et corrélation seraient quasiment identiques. Ce n'est pas le cas. Bien que la corrélation soit dérivée de la covariance, elle standardise la relation, ce qui en fait une mesure distincte qui ne remplace pas toujours la covariance dans les calculs.
Enfin, n'oubliez pas que ces statistiques n'évaluent que des relations linéaires. Des motifs non linéaires peuvent exister même lorsque covariance et corrélation sont faibles ou proches de zéro ; se fier uniquement à ces statistiques peut donc occulter des structures importantes. Je vous recommande toujours de tracer vos données et de les examiner avant d'interpréter des mesures statistiques. Cela peut vraiment vous éviter des pièges en présence de relations non linéaires évidentes.
Premièrement, considérez toujours l'échelle de mesure. Les différences d'unités ou de variabilité peuvent affecter les mesures brutes comme la covariance, il est donc essentiel de savoir ce que représentent vos chiffres.
Deuxièmement, clarifiez votre besoin. La covariance est la plus utile lorsque préserver la variabilité brute est important. C'est souvent le cas en modélisation ou lors de la construction de matrices de covariance pour des analyses multivariées. Dans ces contextes, la magnitude de la variation porte une information significative. Mais si vous n'avez pas besoin de cette variabilité brute, vous préférerez peut-être la standardisation et la lisibilité de la corrélation.
Troisièmement, tracez toujours, toujours, toujours vos données et regardez-les ! L'inspection visuelle peut guider vos analyses et compléter les résumés statistiques. Utilisez des nuages de points pour repérer des motifs par paires, ou des matrices pour obtenir un aperçu rapide de nombreuses variables à la fois.
Enfin, réfléchissez aux implications de vos choix de mesure pour la suite. Choisir entre une mesure brute comme la covariance et une mesure standardisée comme la corrélation influencera vos modèles et vos interprétations. Alignez donc votre sélection sur vos objectifs analytiques.
Covariance et corrélation sont deux mesures étroitement liées qui décrivent la coévolution de variables, mais elles servent des objectifs distincts : la covariance préserve l'échelle d'origine, tandis que la corrélation standardise pour faciliter la comparaison.
Si vous souhaitez aller plus loin dans l'exploration de vos données, consultez le tutoriel Python sur l'analyse exploratoire des données. Pour savoir si votre corrélation traduit réellement une causalité, découvrez le cours Hypothesis Testing in R.
Apprenez avec DataCamp
Cours
Cours
Cours
blog
Kurtis Pykes
15 min
Tutoriel
Samuel Shaibu
Tutoriel
Matt Crabtree
Tutoriel
Laiba Siddiqui
Tutoriel
Aditya Sharma
Tutoriel
Mark Pedigo

