course
Linear Algebra for Data Science in R
4 घंटा
21K
डेटा एनालिटिक्स में, हम हमेशा यह समझने की कोशिश करते हैं कि चर एक-दूसरे से कैसे संबंधित हैं। आप शायद इस उद्देश्य के लिए आमतौर पर इस्तेमाल की जाने वाली दो सांख्यिकीय मापों से परिचित होंगे: कोवैरीएंस और कोरिलेशन। ये माप सुनने में मिलते-जुलते हैं और अक्सर एक-दूसरे से भ्रमित कर दिए जाते हैं। लेकिन इनके बीच अंतर क्या है, और इन्हें कैसे उपयोग करना चाहिए?
दोनों बताते हैं कि चर साथ में कैसे बदलते हैं। हालांकि, समानताओं के बावजूद, कोवैरीएंस और कोरिलेशन थोड़े अलग प्रश्नों का उत्तर देते हैं और इसलिए डेटा वर्कफ़्लो में उनकी भूमिकाएँ भिन्न होती हैं। कोवैरीएंस फीचर्स के बीच कच्ची संयुक्त परिवर्तनशीलता को पकड़ता है, जबकि कोरिलेशन उस संबंध को मानकीकृत करता है ताकि उसकी तुलना आसानी से की जा सके।
आइए देखें कि यह सूक्ष्म अंतर अलग-अलग परिस्थितियों में किस माप का उपयोग करने पर कैसे असर डालता है।
कोवैरीएंस मापता है कि दो चर साथ में कैसे बदलते हैं। यह बताता है कि क्या एक चर में वृद्धि आमतौर पर दूसरे में वृद्धि या कमी के साथ होती है। कोवैरीएंस के तीन प्रकार होते हैं:
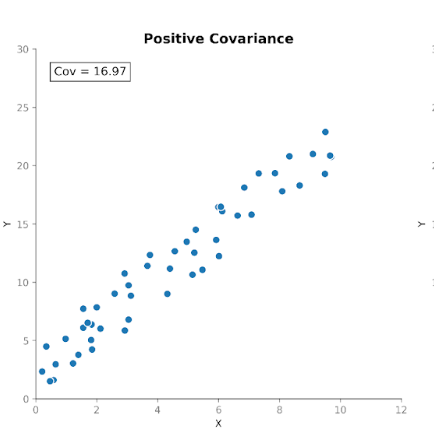
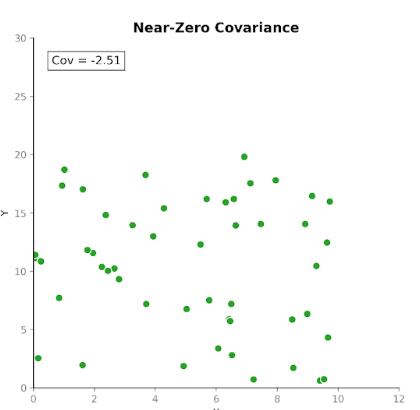
इससे कोवैरीएंस एक-दूसरे के सापेक्ष चरों की चाल पहचानने में उपयोगी बनता है।
हालांकि, संबंध की दिशा उपयोगी है, पर कोवैरीएंस के परिमाण की व्याख्या सीधी नहीं होती। परिमाण माप की इकाइयों और चरों के स्केल पर निर्भर करता है। इकाइयाँ बदलना, जैसे सेंटीमीटर से मीटर में, अंतर्निहित संबंध बदले बिना ही कोवैरीएंस का परिमाण नाटकीय रूप से बदल सकता है।
इसी कारण, कोवैरीएंस का अधिक उपयोग स्वतंत्र सार-सांख्यिकीय मान के बजाय एक आंतरिक संगणनात्मक निर्माण-खंड के रूप में होता है।
कोरिलेशन दो चरों के बीच संबंध की दिशा के साथ-साथ उसकी ताकत भी मापता है। यह परिमाण को मानकीकृत करके कोवैरीएंस पर आधारित होता है ताकि इकाइयाँ उस पर प्रभाव न डालें।
कोरिलेशन के मान एक निश्चित दायरे में होते हैं: +1 (संपूर्ण धनात्मक संबंध) से -1 (संपूर्ण ऋणात्मक संबंध) तक। 0 का मान बताता है कि कोई रैखिक संबंध नहीं है।
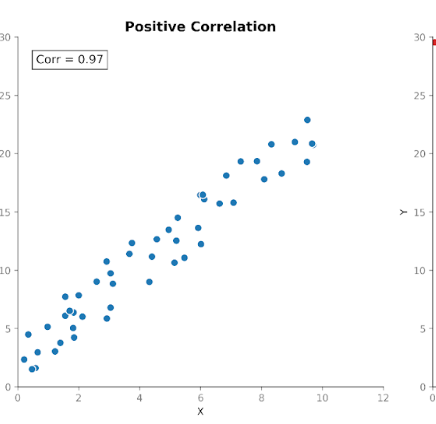
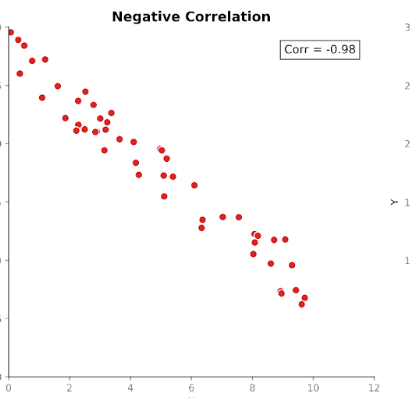
यह मानकीकृत पैमाना कोरिलेशन को कोवैरीएंस की तुलना में समझना आसान बनाता है। यदि हम 0.8 का मान देखें, तो हम तुरंत जान सकते हैं कि चरों के बीच एक मजबूत संबंध है, भले ही मूल मापन में किन इकाइयों का उपयोग किया गया हो।
यह मानकीकरण अलग-अलग डेटासेट्स, फीचर्स और डोमेन्स में सार्थक तुलना की भी अनुमति देता है। यही कारण है कि अन्वेषणात्मक डेटा विश्लेषण और फीचर जाँच में कोरिलेशन का व्यापक उपयोग होता है।
कोवैरीएंस और कोरिलेशन चरों के संबंधों के संबंधित गुणों का वर्णन करते हैं, पर उनके विश्लेषणात्मक उद्देश्य अलग होते हैं।
व्यावहारिक रूप से, कोवैरीएंस कच्ची सह-परिवर्तनशीलता को दर्शाता है, जबकि कोरिलेशन उसी संबंध को मानकीकृत रूप में दर्शाता है। यह भेद समझना यह तय करने में मदद करता है कि किसी विश्लेषणात्मक कार्य के लिए कौन-सा माप अधिक उपयुक्त है।
|
कोवैरीएंस |
कोरिलेशन |
|
|
क्या मापता है |
रैखिक संबंध (अमानकीकृत) |
रैखिक संबंध (मानकीकृत) |
|
स्केल के प्रति संवेदनशीलता |
पैमाना इकाइयों से निर्धारित |
निश्चित दायरा (−1 से +1) |
|
इकाइयाँ |
इकाइयाँ होती हैं |
इकाई-रहित |
|
व्याख्येयता |
परिमाण समझना कठिन |
दिशा और परिमाण समझना आसान |
|
तुलनात्मकता |
डेटासेट्स के बीच सीमित तुलना |
डेटासेट्स के बीच प्रत्यक्ष तुलना |
|
सामान्य उपयोग |
मॉडलिंग और मैट्रिक्स निर्माण |
अन्वेषण और संप्रेषण |
|
लाभ |
मूल पैमाना संरक्षित रखता है |
तुलना हेतु मानकीकरण करता है |
मान लें कि हम दो चरों पर डेटा इकट्ठा करते हैं: लंबाई और वज़न। हमें इनके संबंधित होने की उम्मीद है, क्योंकि आम तौर पर लंबे लोग अधिक वज़न रखते हैं। जब हम सेंटीमीटर में लंबाई को किलोग्राम में वज़न के साथ प्लॉट करते हैं, तो एक स्पष्ट ऊपर की ओर रुझान दिखता है। जैसे-जैसे लंबाई बढ़ती है, वज़न भी बढ़ने लगता है।
जब हम कोवैरीएंस की गणना करते हैं, तो एक धनात्मक मान मिलता है: 48.08। इसका धनात्मक होना बताता है कि दोनों चर एक ही दिशा में चलते हैं। जब लंबाई औसत से ऊपर होती है, तो वज़न भी सामान्यतः औसत से ऊपर होता है।
अब यहीं यह रोचक हो जाता है। आइए वही डेटा लें और इकाइयाँ बदल दें। हम लंबाई को सेंटीमीटर से मीटर में, और वज़न को किलोग्राम से पाउंड में बदल देंगे। लोग नहीं बदले। संबंध नहीं बदला। स्कैटरप्लॉट में पैटर्न वैसा ही दिखता है। लेकिन जब हम कोवैरीएंस को फिर से गणना करते हैं, तो संख्या अलग होती है: 1.06। यह अभी भी धनात्मक है, पर परिमाण बहुत अलग है। और हमने बदला केवल इकाइयों को ही।
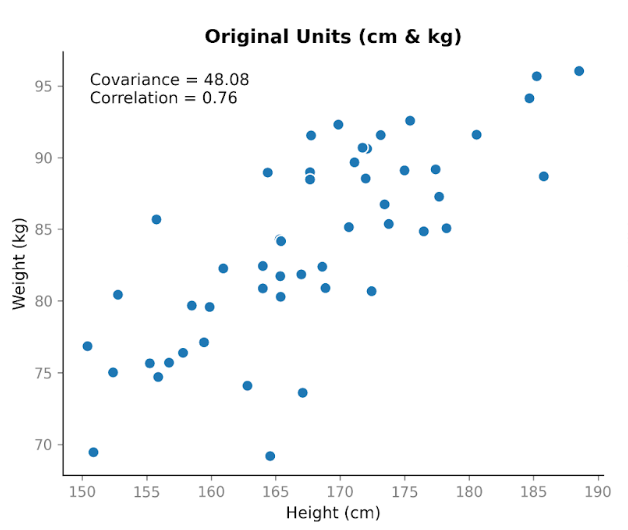
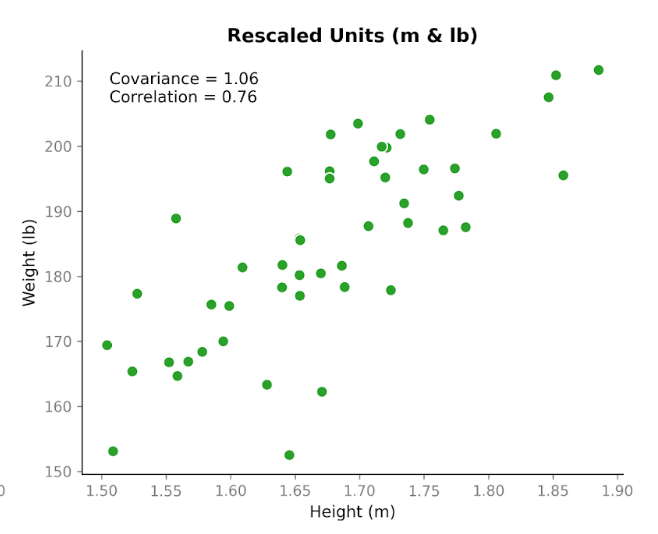
यह कोवैरीएंस के एक महत्वपूर्ण गुण को दर्शाता है: यह दिशा को पकड़ता है, पर इसका परिमाण स्केल पर निर्भर होता है। यदि हम इकाइयाँ बदलकर किसी चर को फैलाएँ या सिकोड़ें, तो कोवैरीएंस भी उसी अनुपात में फैलता या सिकुड़ता है।
अब, आइए उसी डेटा पर इकाइयाँ बदलने से पहले और बाद में कोरिलेशन देखें। सेंटीमीटर और किलोग्राम का उपयोग करते हुए कोरिलेशन 0.76 है। मीटर और पाउंड में बदलने के बाद भी यह 0.76 ही रहता है।
कोवैरीएंस के विपरीत, कोरिलेशन संबंध को मापने से पहले प्रत्येक चर की परिवर्तनशीलता के लिए समायोजन करता है। इसी समायोजन के कारण, इकाइयाँ बदलने पर मान नहीं बदलता। यह केवल इस पर ध्यान देता है कि बिंदु कितनी कसकर किसी रैखिक पैटर्न का अनुसरण करते हैं और वह पैटर्न ऊपर की ओर है या नीचे की ओर।
यह सरल उदाहरण इन मेट्रिक्स के मुख्य अंतर को उजागर करता है: कोवैरीएंस दिशा और स्केल दोनों को दर्शाता है, जबकि कोरिलेशन स्केल से स्वतंत्र रूप से संबंध की ताकत को दर्शाता है। व्यवहार में, इसका अर्थ है कि अलग-अलग स्केल पर मापे गए चरों के बीच संबंधों की तुलना के लिए कोरिलेशन अधिक विश्वसनीय है, जबकि जहाँ परिवर्तनशीलता के परिमाण का महत्व है, जैसे मॉडलिंग में, वहाँ कोवैरीएंस अधिक प्रासंगिक है।
जैसा कि हमने चर्चा की, कोवैरीएंस बताता है कि दो चर एक ही दिशा में चलते हैं या नहीं, पर इसका परिमाण समझना कठिन होता है।
मुख्य समस्या यह है कि कोवैरीएंस केवल संबंध पर ही नहीं, बल्कि चरों के स्केल पर भी निर्भर करता है। यदि एक या दोनों चरों के मान बड़े हैं या अधिक फैले हुए हैं, तो कोवैरीएंस भी बड़े होने की प्रवृत्ति दिखाएगा।
यह संवेदनशीलता दो स्रोतों से आती है। पहला है डेटा की इकाइयाँ। इकाइयाँ बदलने से कोवैरीएंस बदल जाता है। आय को डॉलर में बनाम हजार डॉलर में मापना बहुत अलग कोवैरीएंस मान देता है, जबकि संबंध समान रहता है।
दूसरा स्रोत है चर में परिवर्तनशीलता की मात्रा। इकाइयाँ समान रहने पर भी, व्यापक दायरे या अधिक फैलाव वाले डेटासेट में, समान अंतर्निहित संबंध के साथ भी, आमतौर पर तंग डेटासेट की तुलना में बड़ा कोवैरीएंस प्राप्त होता है। बड़ा कोवैरीएंस जरूरी नहीं कि मजबूत संबंध को दर्शाए। यह केवल बड़े पैमानों या डेटा में अधिक परिवर्तनशीलता को भी दर्शा सकता है।
स्केल के प्रति इस संवेदनशीलता के कारण, कोवैरीएंस का उपयोग अक्सर आंतरिक रूप से, जैसे मॉडल फिटिंग में, सीधे रिपोर्ट करने के बजाय किया जाता है।
कोरिलेशन चरों के बीच संबंध को मानकीकृत करके कोवैरीएंस की व्याख्या संबंधी कई चुनौतियों का समाधान करता है। क्योंकि कोरिलेशन के मान हमेशा −1 और +1 के बीच होते हैं, परिमाण तुरंत बोधगम्य होता है: 1 या −1 के निकट मान मजबूत रैखिक संबंध दिखाते हैं, जबकि 0 के आसपास के मान कमजोर या नगण्य रैखिक संबंध का संकेत देते हैं। यह मानकीकरण चरों या डेटासेट्स के बीच प्रत्यक्ष तुलना की अनुमति देता है, जिससे कोरिलेशन को संप्रेषित और समझना आसान हो जाता है।
ये गुण कोरिलेशन को अन्वेषणात्मक डेटा विश्लेषण, फीचर्स के बीच संबंधों की जाँच, अनावश्यकता या मल्टिकॉलीनियरिटी का पता लगाने और निष्कर्षों की रिपोर्टिंग के लिए विशेष रूप से उपयोगी बनाते हैं। डेटासेट्स की जाँच करते समय कोरिलेशन मैट्रिस और हीटमैप्स प्रथम-दृष्टि उपकरण के रूप में भी उपयोगी होते हैं।
यह कहा जाना चाहिए कि कोरिलेशन, कोवैरीएंस का पूर्ण विकल्प नहीं है। क्योंकि कोरिलेशन स्केल के प्रभावों को हटा देता है, यह केवल संबंध की ताकत को दर्शाता है, कच्ची परिवर्तनशीलता को नहीं। मॉडलिंग संदर्भों में, जैसे प्रिंसिपल कंपोनेंट एनालिसिस या बहुविविध सांख्यिकीय मॉडल, कोवैरीएंस द्वारा पकड़ा गया मूल पैमाना वैरिएंस संरचना को समझने और एल्गोरिदम के व्यवहार को निर्देशित करने के लिए महत्वपूर्ण हो सकता है।
अब तक, हमने चरों के बीच कोवैरीएंस को एक समय में एक जोड़ी के रूप में देखा है। रैखिक बीजगणित हमें दिखाता है कि इस विचार को एक साथ पूरे डेटासेट तक कैसे बढ़ाएँ। हम अपने डेटा को एक मैट्रिक्स में व्यवस्थित करके ऐसा कर सकते हैं।
एक बुनियादी डेटा मैट्रिक्स में, प्रत्येक पंक्ति एक प्रेक्षण का प्रतिनिधित्व करती है, और प्रत्येक स्तंभ एक चर का। चरों के बीच संबंधों को समझने के लिए, हम पहले डेटा को सेंटर कर सकते हैं—अर्थात प्रत्येक मान से स्तंभ का औसत घटा सकते हैं। यह चरण सुनिश्चित करता है कि हम निरपेक्ष मानों के बजाय विशिष्ट मानों से विचलनों पर ध्यान केंद्रित कर रहे हैं।
सेंटर किए गए डेटा मैट्रिक्स को उसके ट्रांसपोज़ से गुणा करना ऐसी संरचना बनाता है जो यह पकड़ती है कि चर साथ में कैसे बदलते हैं। इस गुणनफल को स्केल करने के बाद जो प्राप्त होता है, वही कोवैरीएंस मैट्रिक्स है। रैखिक बीजगणित के दृष्टिकोण से, कोवैरीएंस मैट्रिक्स यह संक्षेपित करता है कि डेटासेट के आयामों में परिवर्तनशीलता कैसे वितरित है।
इस तरह कोवैरीएंस के बारे में सोचना यह समझाने में मदद करता है कि यह डेटा साइंस में इतनी बार क्यों दिखता है। कई एल्गोरिदम, जिनमें प्रिंसिपल कंपोनेंट एनालिसिस (PCA) और अन्य डायमेंशनलिटी रिडक्शन तकनीकें शामिल हैं, डेटा में पैटर्न और संरचना समझने के लिए इसी मैट्रिक्स अभ्यावेदन पर निर्भर करते हैं। वैचारिक रूप से, कोवैरीएंस मैट्रिक्स यह नक्शा प्रदान करता है कि डेटासेट के विभिन्न आयाम कैसे परस्पर क्रिया करते हैं।
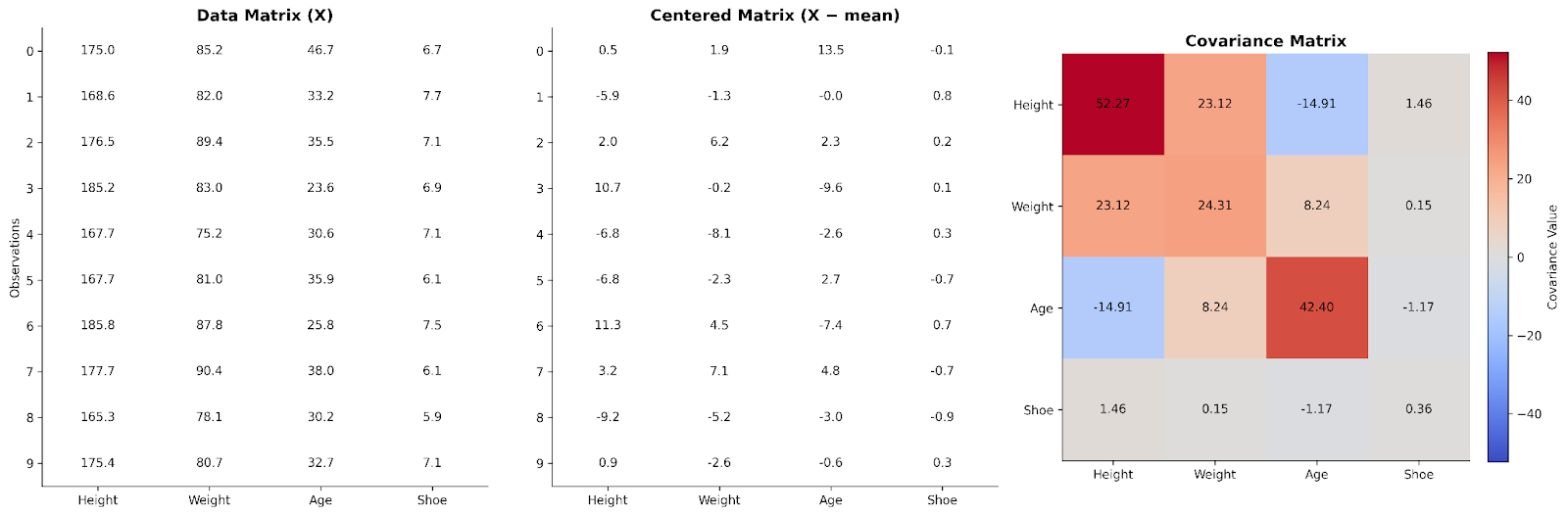
यहाँ हम चार चरों का डेटा एक डेटा मैट्रिक्स में व्यवस्थित देखते हैं। फिर इसे सेंटर किया गया है और एक कोवैरीएंस मैट्रिक्स बनाने में उपयोग किया गया है।
यदि आप डेटा साइंस के लिए रैखिक बीजगणित में गहराई से जाना चाहते हैं, तो हमारा Linear Algebra for Data Science in R कोर्स देखें, जो कोवैरीएंस जैसी मैट्रिक्स-आधारित पद्धतियों को समझने के लिए आवश्यक आधार तैयार करता है।
कोवैरीएंस मैट्रिक्स पूरे डेटासेट में चरों के साथ-साथ बदलने के तरीके का सार प्रस्तुत करता है। व्यवहार में, हम अक्सर इन संबंधों की जाँच कोवैरीएंस या कोरिलेशन मैट्रिसेस के माध्यम से करते हैं, यह इस पर निर्भर करता है कि हम मूल पैमाने को संरक्षित रखना चाहते हैं या परिणामों को मानकीकृत करना चाहते हैं।
कोवैरीएंस मैट्रिक्स में सभी युग्मों के बीच कोवैरीएंस शामिल होता है। विकर्ण (डायगोनल) संख्याएँ प्रत्येक चर के भीतर का वैरिएंस दिखाती हैं, जबकि ऑफ-डायगोनल संख्याएँ यह दर्शाती हैं कि चर साथ में कैसे बदलते हैं। क्योंकि कोवैरीएंस डेटा के मूल पैमाने और इकाइयों को संरक्षित रखता है, मैट्रिक्स परिवर्तनशीलता की कच्ची संरचना को पकड़ता है। यह कोवैरीएंस मैट्रिसेस को मॉडलिंग वर्कफ़्लोज़ और बहुविविध विश्लेषणों में विशेष रूप से उपयोगी बनाता है।
कोरिलेशन मैट्रिक्स, दूसरी ओर, इन संबंधों को मानकीकृत करता है। प्रत्येक डायगोनल प्रविष्टि 1 के बराबर होती है, क्योंकि हर चर स्वयं के साथ पूरी तरह सहसंबद्ध होता है। सभी ऑफ-डायगोनल मान −1 और +1 के बीच होते हैं, जो चरों के बीच सहसंबंध दिखाते हैं। स्केल के प्रभावों को हटाकर, कोरिलेशन मैट्रिसेस मनुष्यों द्वारा अधिक आसानी से व्याख्यायित की जा सकती हैं और चरों के बीच प्रत्यक्ष तुलना की अनुमति देती हैं। ये अन्वेषणात्मक डेटा विश्लेषण में और फीचर्स के बीच मजबूत या कमजोर रैखिक संबंधों की त्वरित पहचान के लिए विशेष रूप से उपयोगी हैं।
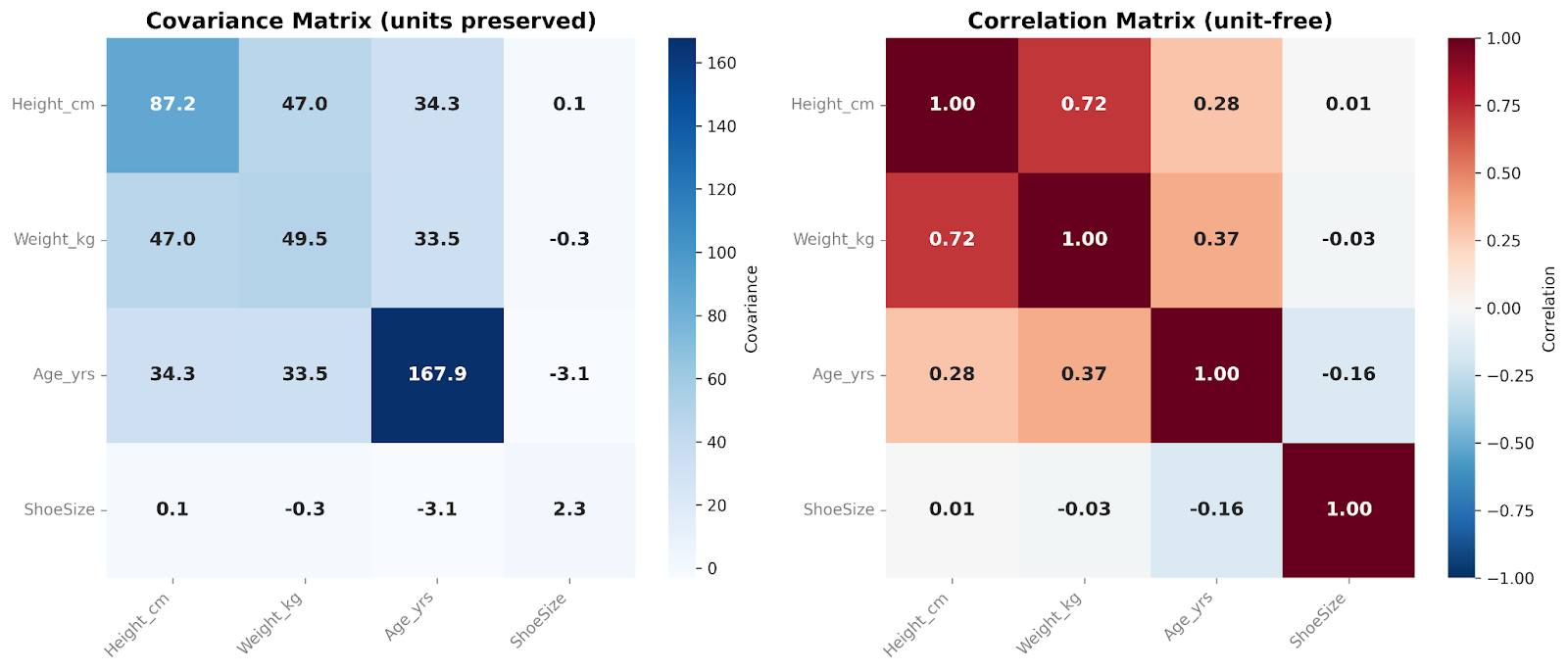
इन मैट्रिसेस में, हम चार चरों की एक-दूसरे से तुलना कर रहे हैं। मैं प्रस्तुत करते समय इन मैट्रिसेस पर हीटमैप ओवरले जोड़ना पसंद करता/करती हूँ। प्रत्येक सेल का रंग हमें एक नज़र में कोवैरीएंस या कोरिलेशन मानों के सापेक्ष परिमाण को देखने में मदद करता है।
वैचारिक रूप से, कोरिलेशन चरों के बीच संबंध को मानकीकृत करके कोवैरीएंस से व्युत्पन्न होता है। आप बस कोवैरीएंस को प्रत्येक चर के मानक विचलन से भाग दे देते हैं। यह स्केलिंग इकाइयों और चरों के परिमाण को हटा देती है, जिससे एक मानकीकृत माप मिलता है जो हमेशा −1 और +1 के बीच आता है। यही रूपांतरण कारण है कि कोरिलेशन मान अलग-अलग चरों या डेटासेट्स के बीच प्रत्यक्ष रूप से तुलनीय होते हैं।
व्यवहार में, अधिकांश सांख्यिकीय सॉफ़्टवेयर में कोवैरीएंस को कोरिलेशन में बदलना स्वतः हो जाता है, इसलिए विश्लेषकों को शायद ही कभी इसे हाथ से गणना करनी पड़ती है। फिर भी, यह समझना हमेशा महत्वपूर्ण है कि आपका सॉफ़्टवेयर पृष्ठभूमि में क्या कर रहा है। उदाहरण के लिए, यह समझना कि कोवैरीएंस को कोरिलेशन में कैसे बदला जाता है, यह भी समझाता है कि आप विपरीत दिशा में क्यों नहीं बदल सकते (कम-से-कम तब तक नहीं जब तक दोनों के मानक विचलन की जानकारी न हो)। कोरिलैशन में अब वे इकाइयाँ या परिमाण संबंधी जानकारी नहीं रहती जो कोवैरीएंस में वापस बदलने के लिए आवश्यक है।
जब डेटा का पैमाना और इकाइयाँ अर्थपूर्ण हों, या जब आपको अपने डेटा की परिवर्तनशीलता की कच्ची संरचना चाहिए, तब कोवैरीएंस सबसे उपयोगी होता है। इसका उपयोग सामान्यतः बहुविविध मॉडलिंग, प्रायिकतामूलक मॉडलों, और रैखिक बीजगणित-आधारित विधियों के लिए कोवैरीएंस मैट्रिक्स के निर्माण में किया जाता है। इन संदर्भों में, मूल परिवर्तनशीलता को संरक्षित रखने से एल्गोरिदम को डेटा की वास्तविक संरचना पकड़ने और यह समझने में मदद मिलती है कि आयाम साथ में कैसे बदलते हैं।
इसके विपरीत, कोरिलेशन मानव व्याख्या, डेटासेट्स के बीच तुलना, और अन्वेषणात्मक विश्लेषणों के लिए अधिक उपयुक्त है। मैं इस मेट्रिक का उपयोग दृश्याकृतियों में करना पसंद करता/करती हूँ, जैसे हीटमैप्स, ताकि इन संबंधों को एक नज़र में देखा और संप्रेषित किया जा सके। क्योंकि कोरिलेशन संबंध को मानकीकृत करता है, यह उन तकनीकों के लिए डेटा तैयार करने में भी सहायक होता है जहाँ सभी फीचर्स को तुलनीय स्केल पर रखना महत्वपूर्ण हो सकता है।
अक्सर, दोनों माप एक ही वर्कफ़्लो में दिखाई देते हैं। कोवैरीएंस मैट्रिसेस कई बहुविविध तकनीकों की गणितीय आधारशिला बनती हैं क्योंकि वे डेटा की मूल परिवर्तनशीलता बनाए रखती हैं। दूसरी ओर, कोरिलेशन मैट्रिसेस का उपयोग अक्सर मॉडलिंग से पहले डेटासेट की संरचना समझने के लिए अन्वेषण चरणों के दौरान किया जाता है।
कुछ मॉडल लक्ष्य पर निर्भर करते हुए किसी भी सांख्यिकीय मान का उपयोग कर सकते हैं। उदाहरण के लिए प्रिंसिपल कंपोनेंट एनालिसिस (PCA) पर विचार करें। जब PCA कोवैरीएंस मैट्रिक्स पर किया जाता है, तो अधिक वैरिएंस वाले चर स्वाभाविक रूप से परिणामी कंपोनेंट्स पर अधिक प्रभाव डालते हैं। यदि स्केल के अंतर परिवर्तनशीलता में अर्थपूर्ण अंतर दर्शाते हैं, तो यह कभी-कभी वांछनीय होता है। उदाहरण के लिए, यदि आप दैनिक स्टॉक रिटर्न का विश्लेषण कर रहे हैं, तो अधिक अस्थिर शेयर उपयुक्त रूप से प्रिंसिपल कंपोनेंट्स को आकार दे सकता है क्योंकि वह परिवर्तनशीलता वास्तविक बाजार व्यवहार को दर्शाती है।
इसके बजाय कोरिलेशन मैट्रिक्स का उपयोग करने से विघटन (डिकंपोज़िशन) से पहले चरों का मानकीकरण हो जाता है। प्रत्येक फीचर को एक ही स्केल पर रखा जाता है, इसलिए केवल बड़े यूनिट्स या व्यापक संख्यात्मक रेंज होने के कारण कोई चर हावी नहीं होता। यह तरीका तब अधिक उपयुक्त हो सकता है जब चरों को अलग-अलग इकाइयों में मापा गया हो, जैसे लंबाई (सेमी), वज़न (किग्रा), रक्तचाप (mmHg), और कोलेस्ट्रॉल (mg/dL)।
कोई भी तरीका सर्वत्र श्रेष्ठ नहीं है। उपयुक्त चयन इस पर निर्भर करता है कि क्या स्केल के अंतर अर्थपूर्ण संरचना दर्शाते हैं या केवल मापन के उपफल हैं।
एक आम भ्रांति यह है कि उच्च कोवैरीएंस अपने-आप एक मजबूत संबंध को दर्शाता है। हालांकि, बड़े कोवैरीएंस मान चरों के स्केल या परिवर्तनशीलता को ही दर्शा सकते हैं, न कि उनके संबंध की ताकत को। यदि आप संबंध की ताकत जानना चाहते हैं, तो आपको कोरिलेशन देखकर उसे मानकीकृत रूप में देखना चाहिए।
आपने शायद यह वाक्यांश “कोरिलेशन कार्य-कारण (causation) को सिद्ध नहीं करता” लाखों बार सुना होगा! फिर भी, यह शायद सबसे आम भ्रांति है जिससे मैं सामना करता/करती हूँ। एक मजबूत कोरिलेशन देखकर एक कारणात्मक कड़ी मान लेना समझ में आता है—यह वह शॉर्टकट है जिसका हमारा मस्तिष्क सहस्राब्दियों से हमारे पूर्वजों को सुरक्षित रखने के लिए उपयोग करता आया है। हालांकि, डेटा प्रैक्टिशनर्स के रूप में, हमें इस मानसिक शॉर्टकट का विरोध करना चाहिए और मानना चाहिए कि केवल कोरिलेशन किसी कारणात्मक प्रभाव को सिद्ध करने के लिए पर्याप्त नहीं है। कोरिलेशन सह-संबद्धता को मापता है, कारणात्मक प्रभाव को नहीं, और बाह्य कारक दोनों चरों को एक साथ प्रभावित कर सकते हैं।
एक और बहुत आम भ्रांति यह है कि कोवैरीएंस और कोरिलेशन मूलतः एक ही चीज़ हैं। हालांकि, वे एक-दूसरे के स्थान पर प्रयोज्य नहीं हैं। जबकि कोरिलेशन कोवैरीएंस से व्युत्पन्न होता है, यह संबंध को मानकीकृत करता है, जिससे यह एक अलग मेट्रिक बन जाता है जो गणनाओं में हमेशा कोवैरीएंस का उपयुक्त विकल्प नहीं होता।
अंत में, यह याद रखना महत्वपूर्ण है कि ये सांख्यिकीय मान केवल रैखिक संबंधों का आकलन करते हैं। जब कोरिलेशन और कोवैरीएंस कम या शून्य के निकट हों, तब भी अरेखीय पैटर्न मौजूद हो सकते हैं, इसलिए केवल इन पर निर्भर रहने से डेटा की महत्वपूर्ण संरचना अनदेखी हो सकती है। मैं हमेशा सलाह देता/देती हूँ कि आप अपने डेटा को प्लॉट करें और पहले उसे देखें। यदि कोई स्पष्ट अरेखीय संबंध हो, तो यह सच में आपकी मदद कर सकता है।
पहला, हमेशा अपने मापन के पैमाने पर विचार करें। इकाइयों या परिवर्तनशीलता में अंतर, कोवैरीएंस जैसे कच्चे मापों को प्रभावित कर सकते हैं, इसलिए यह जानना महत्वपूर्ण है कि आपके अंक क्या दर्शाते हैं।
दूसरा, यह तय करें कि आपको अपने डेटा से क्या चाहिए। जब कच्ची परिवर्तनशीलता को संरक्षित रखना महत्वपूर्ण होता है, तो कोवैरीएंस सबसे उपयोगी होता है। यह अक्सर मॉडलिंग या बहुविविध विश्लेषणों के लिए कोवैरीएंस मैट्रिसेस का निर्माण करते समय होता है। इन संदर्भों में, परिवर्तन के परिमाण में अर्थपूर्ण जानकारी होती है। पर यदि आपको वह कच्ची परिवर्तनशीलता आवश्यक नहीं है, तो आप कोरिलेशन के मानकीकरण और व्याख्येयता को प्राथमिकता दे सकते हैं।
तीसरा, हमेशा, हमेशा, हमेशा अपना डेटा प्लॉट करें और उसे देखें! दृश्य निरीक्षण आपकी विश्लेषण को दिशा दे सकता है और सांख्यिकीय सारांशों को पूरक करता है। आप युग्म-स्तरीय पैटर्न पहचानने के लिए स्कैटर प्लॉट्स का उपयोग कर सकते हैं, या कई चरों का त्वरित अवलोकन पाने के लिए मैट्रिसेस का।
अंत में, अपने मापन विकल्पों के डाउनस्ट्रीम प्रभावों के बारे में सोचें। कोवैरीएंस जैसे कच्चे माप और कोरिलेशन जैसे मानकीकृत माप के बीच चयन आपके मॉडलिंग परिणामों और व्याख्याओं को प्रभावित करेगा। इसलिए सुनिश्चित करें कि आपका चयन आपके विश्लेषणात्मक लक्ष्यों के अनुरूप है।
कोवैरीएंस और कोरिलेशन निकट से जुड़े माप हैं जो बताते हैं कि चर साथ में कैसे बदलते हैं, फिर भी उनके उद्देश्य भिन्न हैं: कोवैरीएंस मूल पैमाना संरक्षित रखता है, जबकि कोरिलेशन तुलना के लिए मानकीकरण करता है।
यदि आप अपने डेटा का अन्वेषण करना और सीखना चाहते हैं, तो देखें Python Exploratory Data Analysis Tutorial। यह जानने के लिए कि आपकी कोरिलेशन सच में कार्य-कारण दर्शाती है या नहीं, देखें Hypothesis Testing in R।
DataCamp के साथ सीखें
course
course
course