
Curso
Álgebra lineal para data science en R
4 h
21.2K
En analítica de datos, siempre intentamos entender cómo se relacionan unas variables con otras. Seguramente te hayas topado con dos medidas estadísticas muy usadas con este fin: la covarianza y la correlación. Suenan parecido y a menudo se confunden. Pero, ¿en qué se diferencian y cómo deberías usarlas?
Ambas describen cómo se mueven juntas las variables. Sin embargo, pese a sus similitudes, covarianza y correlación responden a preguntas ligeramente distintas y cumplen papeles diferentes en los flujos de trabajo con datos. La covarianza capta la variabilidad conjunta en bruto entre variables, mientras que la correlación estandariza esa relación para que sea más fácil de comparar.
Vamos a ver cómo esta diferencia sutil afecta a la medida que conviene usar en cada situación.
La covarianza mide cómo se mueven juntas dos variables. Nos indica si los aumentos en una variable tienden a coincidir con aumentos o descensos en la otra. Hay tres tipos de covarianza:
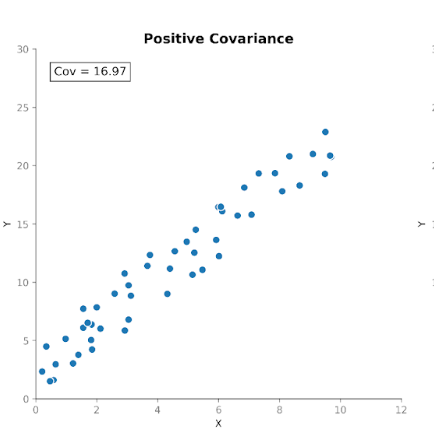
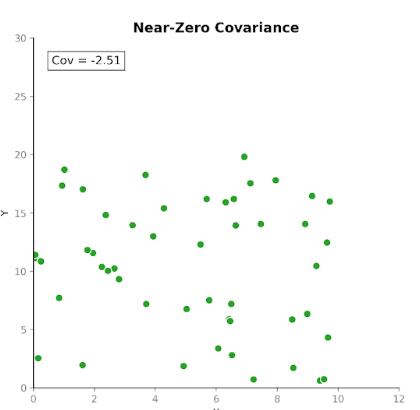
Esto hace que la covarianza sea útil para detectar cómo se mueven las variables entre sí.
Ahora bien, aunque la dirección de la relación es informativa, interpretar la magnitud de la covarianza no es tan sencillo. Su magnitud depende de las unidades de medida y de la escala de las variables. Cambiar las unidades, por ejemplo de centímetros a metros, puede modificar drásticamente la magnitud de la covarianza sin alterar la relación subyacente.
Por este motivo, la covarianza se usa más como un bloque de construcción computacional interno que como estadístico resumen independiente.
La correlación mide la fuerza y la dirección de la relación entre dos variables. Parte de la covarianza, pero estandariza la magnitud para que las unidades dejen de influir.
Los valores de correlación están acotados entre +1 (relación perfectamente positiva) y -1 (relación perfectamente negativa). Un valor de 0 indica que no hay relación lineal.
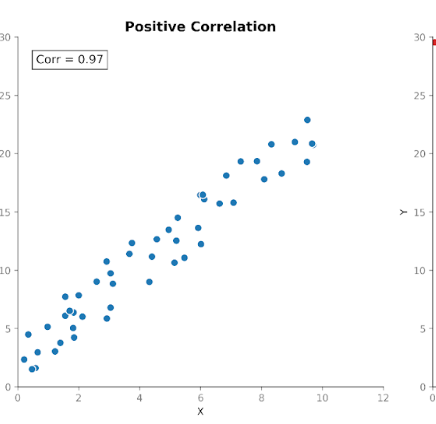
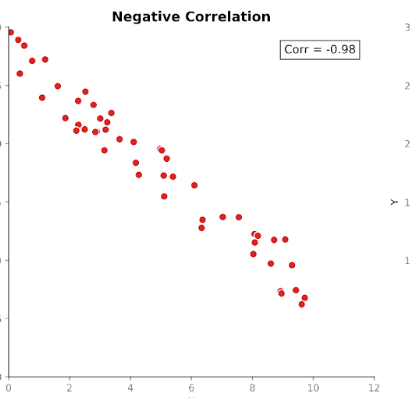
Esta escala estandarizada hace que la correlación sea más fácil de interpretar que la covarianza. Si vemos un 0,8, sabemos de inmediato que existe una relación fuerte entre las variables, independientemente de las unidades usadas en la medición original.
Esta estandarización también permite comparaciones significativas entre conjuntos de datos, variables y dominios. Por eso la correlación se usa tanto en el análisis exploratorio y en la investigación de variables.
Covarianza y correlación describen propiedades relacionadas de las relaciones entre variables, pero sirven a propósitos analíticos distintos.
En términos prácticos, la covarianza refleja la co-variabilidad en bruto, mientras que la correlación refleja esa misma relación en forma estandarizada. Entender esta distinción ayuda a decidir qué medida encaja mejor con cada tarea analítica.
|
Covarianza |
Correlación |
|
|
Mide |
Relación lineal (no estandarizada) |
Relación lineal (estandarizada) |
|
Sensibilidad a la escala |
Escala dictada por las unidades |
Rango fijo (−1 a +1) |
|
Unidades |
Tiene unidades |
Sin unidades |
|
Interpretabilidad |
La magnitud es difícil de interpretar |
Dirección y magnitud fáciles de interpretar |
|
Comparabilidad |
Comparabilidad limitada entre datasets |
Directamente comparable entre datasets |
|
Uso habitual |
Modelado y construcción de matrices |
Exploración y comunicación |
|
Ventaja |
Conserva la escala original |
Estandariza para comparar |
Supongamos que recopilamos datos de dos variables: altura y peso. Esperamos que estén relacionadas, porque en general las personas más altas tienden a pesar más. Si representamos la altura en centímetros frente al peso en kilogramos, vemos una clara tendencia ascendente. A medida que aumenta la altura, el peso también suele aumentar.
Al calcular la covarianza, obtenemos un valor positivo: 48,08. Que sea positivo nos indica que ambas variables se mueven en la misma dirección. Cuando la altura está por encima de la media, el peso normalmente también lo está.
Aquí viene lo interesante. Tomemos exactamente los mismos datos y cambiemos las unidades. Convertimos la altura de centímetros a metros y el peso de kilogramos a libras. Las personas no han cambiado. La relación no ha cambiado. El patrón en el diagrama de dispersión es el mismo. Pero al recalcular la covarianza, el número es diferente: 1,06. Sigue siendo positiva, pero la magnitud es muy distinta. Y lo único que hemos cambiado son las unidades.
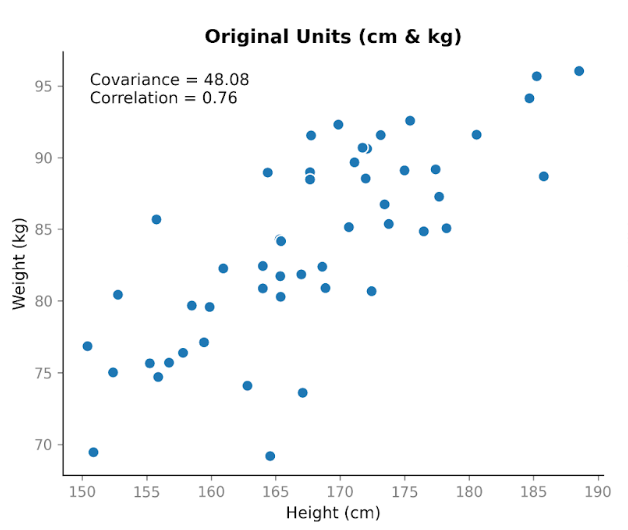
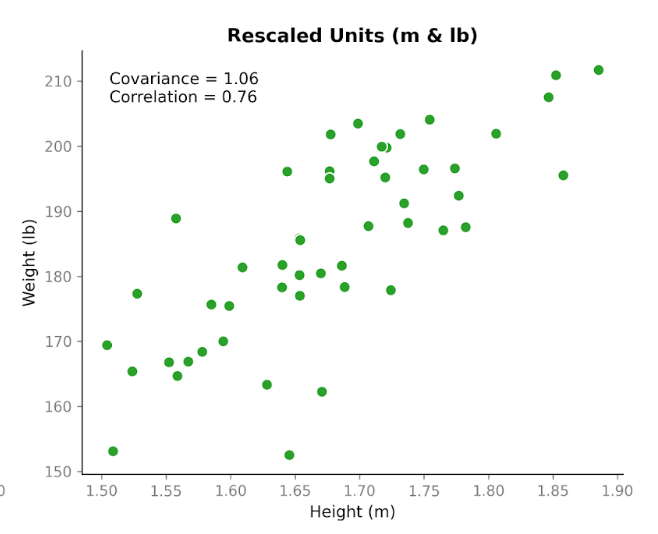
Esto muestra una propiedad importante de la covarianza: capta la dirección, pero su magnitud depende de la escala. Si estiramos o comprimimos una de las variables al cambiar las unidades, la covarianza también se estira o se comprime.
Ahora veamos la correlación con los mismos datos antes y después del cambio de unidades. La correlación usando centímetros y kilogramos es 0,76. Tras convertir a metros y libras, sigue siendo 0,76.
A diferencia de la covarianza, la correlación ajusta la variabilidad de cada variable antes de medir la relación entre ellas. Gracias a ese ajuste, el valor no cambia al cambiar de unidades. Se centra únicamente en lo ajustados que están los puntos a un patrón lineal y en si la pendiente es ascendente o descendente.
Este sencillo ejemplo resalta la diferencia principal entre ambas métricas: la covarianza refleja dirección y escala, mientras que la correlación refleja la fuerza de la relación independientemente de la escala. En la práctica, esto significa que la correlación es más fiable para comparar relaciones entre variables medidas en escalas distintas, mientras que la covarianza es más pertinente cuando la magnitud de la variabilidad importa, como en el modelado.
Como hemos comentado, la covarianza nos dice si dos variables se mueven en la misma dirección, pero su magnitud es difícil de interpretar.
El problema principal es que la covarianza depende de la escala de las variables, no solo de su relación. Si los valores de una o ambas variables son mayores o están más dispersos, la covarianza también tenderá a ser mayor.
Esta sensibilidad proviene de dos fuentes. La primera son las unidades de los datos. Cambiar de unidades cambia la covarianza. Medir ingresos en dólares frente a miles de dólares produce covarianzas muy distintas, aunque la relación sea idéntica.
La segunda fuente es la cantidad de variabilidad de la variable. Incluso manteniendo las mismas unidades, un conjunto de datos con un rango más amplio o mayor dispersión suele producir una covarianza mayor que otro más compacto con la misma relación subyacente. Una covarianza elevada no indica necesariamente una relación fuerte; puede reflejar simplemente escalas mayores o más variabilidad en los datos.
Por esta sensibilidad a la escala, la covarianza suele usarse de forma interna, por ejemplo para ajustar modelos, en lugar de comunicarse directamente.
La correlación resuelve muchos de los problemas de interpretabilidad de la covarianza al estandarizar la relación entre variables. Como los valores de correlación siempre van de −1 a +1, su magnitud es inmediatamente significativa: valores cercanos a 1 o −1 indican relaciones lineales fuertes, mientras que valores próximos a 0 indican relaciones lineales débiles o inexistentes. Esta estandarización también permite comparar directamente variables o datasets, lo que facilita comunicar e interpretar resultados.
Estas propiedades hacen que la correlación sea especialmente útil en el análisis exploratorio, para inspeccionar relaciones entre variables, detectar redundancias o multicolinealidad y presentar hallazgos. Las matrices de correlación y los mapas de calor también son buenas herramientas de primera pasada al examinar datasets.
Dicho esto, la correlación no sustituye por completo a la covarianza. Al eliminar los efectos de la escala, solo refleja la fortaleza de la relación, no la variabilidad en bruto. En contextos de modelado, como el análisis de componentes principales o los modelos estadísticos multivariantes, la escala original que capta la covarianza puede ser importante para entender la estructura de varianzas y guiar el comportamiento de los algoritmos.
Hasta ahora hemos visto la covarianza entre variables por parejas. El álgebra lineal nos muestra cómo escalar esa idea a todo el conjunto de datos a la vez. Podemos hacerlo organizando los datos en una matriz.
En una matriz de datos básica, cada fila representa una observación y cada columna una variable. Para entender las relaciones entre variables, primero podemos centrar los datos restando a cada valor la media de su columna. Este paso garantiza que nos centramos en las desviaciones respecto a los valores típicos y no en los valores absolutos.
Multiplicar la matriz centrada por su transpuesta produce una estructura que capta cómo se mueven juntas las variables. Este producto, tras escalarlo, es la matriz de covarianzas. Desde la perspectiva del álgebra lineal, la matriz de covarianzas resume cómo se distribuye la variabilidad a lo largo de las dimensiones del dataset.
Pensar en la covarianza de este modo ayuda a explicar por qué aparece tan a menudo en ciencia de datos. Muchos algoritmos, incluido el análisis de componentes principales (PCA) y otras técnicas de reducción de dimensionalidad, dependen de esta representación matricial para entender patrones y estructura en los datos. Conceptualmente, la matriz de covarianzas ofrece un mapa de cómo interactúan las distintas dimensiones del conjunto de datos.
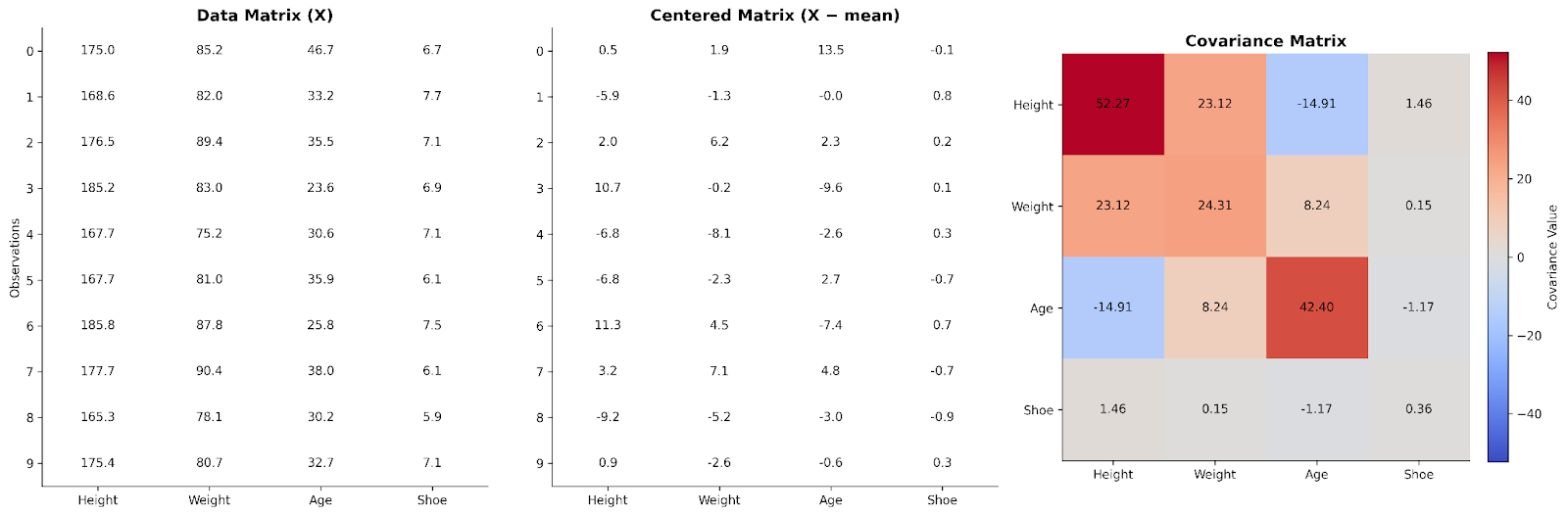
Aquí vemos datos de cuatro variables organizados en una matriz. Después se centran y se usan para crear una matriz de covarianzas.
Si quieres profundizar en álgebra lineal para ciencia de datos, echa un vistazo a nuestro curso Linear Algebra for Data Science in R, que cubre las bases necesarias para entender enfoques matriciales como la covarianza.
La matriz de covarianzas resume cómo se mueven juntas las variables en todo un dataset. En la práctica, solemos examinar estas relaciones usando matrices de covarianza o de correlación, según queramos conservar la escala original o estandarizar los resultados.
Una matriz de covarianzas contiene las covarianzas entre todos los pares de variables. Los números de la diagonal muestran la varianza de cada variable, y los fuera de la diagonal reflejan cómo cambian juntas. Como la covarianza conserva la escala y las unidades originales de los datos, la matriz captura la estructura de variabilidad en bruto. Esto las hace especialmente útiles en flujos de modelado y análisis multivariante.
Una matriz de correlaciones, en cambio, estandariza estas relaciones. Cada entrada de la diagonal es 1, ya que cada variable se correlaciona exactamente consigo misma. Todos los valores fuera de la diagonal están entre −1 y +1 y muestran la correlación entre variables. Al eliminar los efectos de la escala, las matrices de correlación son más fáciles de interpretar y permiten comparar variables directamente. Son especialmente útiles en análisis exploratorios y para identificar rápidamente relaciones lineales fuertes o débiles entre variables.
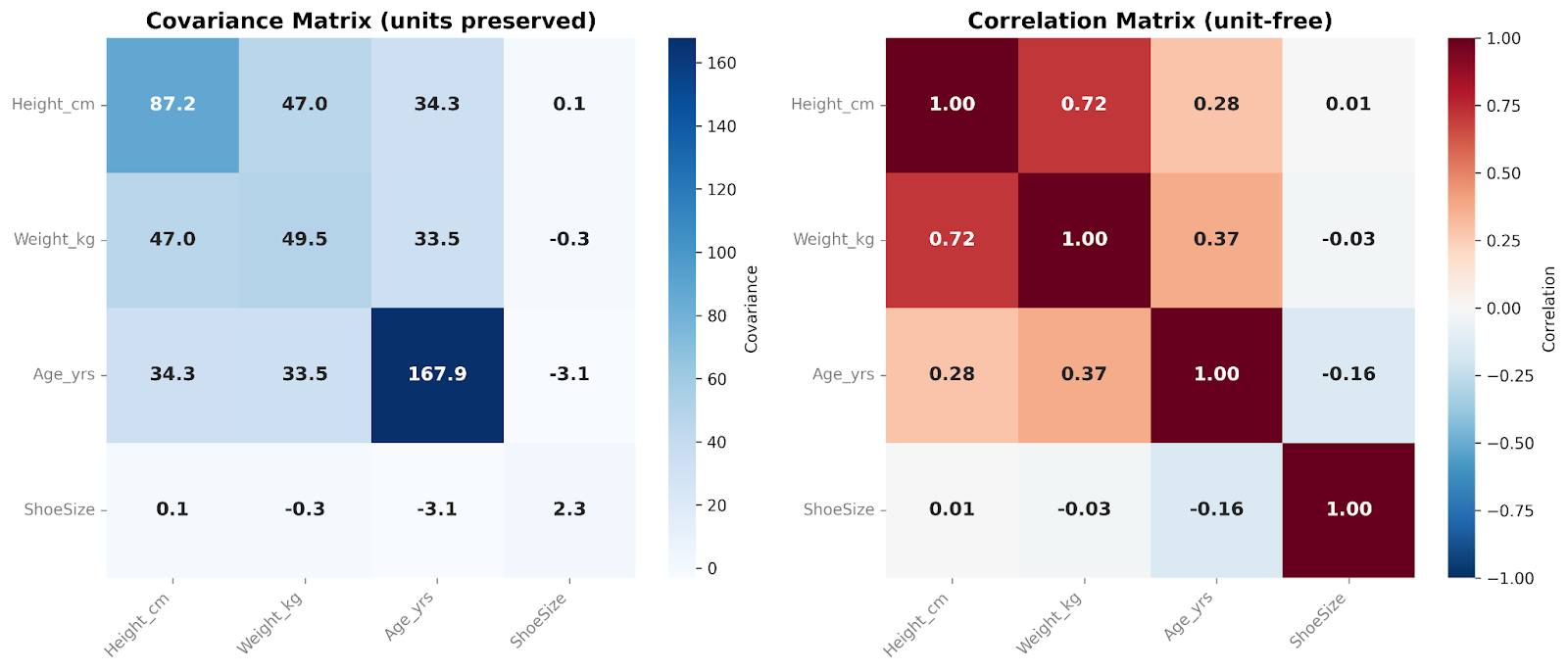
En estas matrices, comparamos cuatro variables entre sí. Me gusta añadir un mapa de calor cuando presento estas matrices. El color de cada celda nos ayuda a ver, de un vistazo, la magnitud relativa de los valores de covarianza o correlación.
Conceptualmente, la correlación se deriva de la covarianza al estandarizar la relación entre variables. Basta con dividir la covarianza por la desviación estándar de cada variable. Este escalado elimina las unidades y la magnitud de las variables, produciendo una medida estandarizada que siempre cae entre −1 y +1. Esta transformación explica por qué los valores de correlación son directamente comparables entre variables o datasets distintos.
En la práctica, la conversión de covarianza a correlación la hacen automáticamente la mayoría de softwares estadísticos, por lo que rara vez es necesario calcularla a mano. Aun así, siempre es importante entender qué hace tu software por detrás. Por ejemplo, comprender cómo se convierte la covarianza en correlación explica por qué no puedes convertir en la dirección opuesta (al menos no sin la desviación estándar de ambas). La correlación ya no contiene las unidades ni la información de magnitud necesarias para volver a la covarianza.
La covarianza es más útil cuando la escala y las unidades de los datos son significativas o cuando necesitas la estructura en bruto de la variabilidad. Se usa habitualmente en modelado multivariante, modelos probabilísticos y en la construcción de matrices de covarianzas para métodos basados en álgebra lineal. En estos contextos, conservar la variabilidad original permite que los algoritmos capten la estructura real de los datos y entiendan cómo varían conjuntamente las dimensiones.
La correlación, en cambio, se adapta mejor a la interpretación humana, a las comparaciones entre datasets y a los análisis exploratorios. Me gusta usar esta métrica en visualizaciones, como mapas de calor, para ver y comunicar estas relaciones de un vistazo. Como la correlación estandariza la relación, también ayuda a preparar los datos para técnicas en las que puede ser importante tratar todas las variables en una escala comparable.
A menudo, ambas medidas aparecen en el mismo flujo de trabajo. Las matrices de covarianzas forman la base matemática de muchas técnicas multivariantes porque conservan la variabilidad original de los datos. Las matrices de correlación, por su parte, se usan con frecuencia en las fases exploratorias para entender la estructura del dataset antes de modelar.
Algunos modelos pueden usar una u otra estadística, según el objetivo. Pensemos en el análisis de componentes principales (PCA). Cuando el PCA se realiza sobre una matriz de covarianzas, las variables con mayor varianza influyen más en los componentes resultantes. Esto puede ser deseable si las diferencias de escala reflejan diferencias significativas en la variabilidad. Por ejemplo, si analizas rendimientos bursátiles diarios, una acción más volátil puede influir apropiadamente en los componentes principales porque esa variabilidad refleja el comportamiento real del mercado.
Usar una matriz de correlaciones, en cambio, estandariza las variables antes de la descomposición. Cada variable queda en la misma escala, de modo que ninguna domina solo por tener unidades más grandes o un rango numérico más amplio. Este enfoque puede ser más adecuado cuando las variables se miden en unidades distintas, como altura (cm), peso (kg), presión arterial (mmHg) y colesterol (mg/dL).
Ningún enfoque es universalmente mejor. La elección adecuada depende de si las diferencias de escala reflejan estructura significativa o son simples artefactos de medición.
Un error común es pensar que una covarianza alta indica automáticamente una relación fuerte. Sin embargo, valores elevados pueden reflejar simplemente la escala o la variabilidad de las variables, no la fuerza de su relación. Si quieres conocer la fuerza de la relación, necesitas estandarizarla mirando la correlación.
Seguro que has oído la frase «correlación no implica causalidad» mil veces. Y aun así, sigue siendo el malentendido más común que me encuentro. Es comprensible ver una correlación fuerte y asumir un vínculo causal. Es un atajo que nuestro cerebro usa desde hace milenios. Sin embargo, como profesionales de datos, debemos resistir ese atajo mental y recordar que la correlación por sí sola no basta para demostrar un efecto causal. La correlación mide asociación, no influencia causal, y factores externos pueden impulsar ambas variables a la vez.
Otra idea muy común es que covarianza y correlación son básicamente lo mismo. No lo son y no son intercambiables. Aunque la correlación se derive de la covarianza, la estandariza, convirtiéndola en una métrica distinta que no siempre sustituye de forma adecuada a la covarianza en cálculos.
Por último, recuerda que estas estadísticas solo evalúan relaciones lineales. Pueden existir patrones no lineales incluso cuando la correlación y la covarianza son bajas o cercanas a cero, así que confiar únicamente en estas medidas puede hacerte pasar por alto estructuras importantes en los datos. Siempre te recomiendo que representes los datos y los mires antes de interpretar estadísticos. Te puede salvar si hay una relación no lineal evidente.
Primero, ten siempre en cuenta la escala de tu medición. Las diferencias en unidades o variabilidad pueden afectar a medidas en bruto como la covarianza, así que es importante saber qué representan tus números.
Segundo, define qué necesitas de tus datos. La covarianza es más útil cuando es importante conservar la variabilidad en bruto. Suele ser el caso en modelado o al construir matrices de covarianzas para análisis multivariantes. En estos contextos, la magnitud de la variación contiene información valiosa. Pero si no necesitas esa variabilidad en bruto, quizá prefieras la estandarización y la interpretabilidad de la correlación.
Tercero: ¡siempre, siempre, siempre representa tus datos y míralos! La inspección visual puede guiar tu análisis y complementa los resúmenes estadísticos. Usa diagramas de dispersión para detectar patrones por pares o matrices para obtener una visión rápida de muchas variables a la vez.
Por último, piensa en las implicaciones aguas abajo de tu elección de medida. Elegir entre una medida en bruto como la covarianza y una estandarizada como la correlación influirá en los resultados del modelado y en tus interpretaciones. Asegúrate de alinear tu elección con tus objetivos analíticos.
La covarianza y la correlación son medidas estrechamente relacionadas que describen cómo se mueven juntas las variables, pero sirven a fines distintos: la covarianza conserva la escala original y la correlación estandariza para comparar.
Si te interesa aprender más sobre cómo explorar tus datos, echa un vistazo al Python Exploratory Data Analysis Tutorial. Para aprender a determinar si tu correlación realmente refleja causalidad, consulta Hypothesis Testing in R.
Aprende con DataCamp
Curso
Curso
Curso
blog
Arun Nanda
15 min
Tutorial
Arunn Thevapalan
Tutorial
Bex Tuychiev
Tutorial
Avinash Navlani
Tutorial
Kurtis Pykes
Tutorial
Abid Ali Awan
