Track
Młodszy Inżynier Danych w SQL
30 godz.
Tradycyjna hurtownia danych jest wdrażana on‑premise, zwykle wymagając wysokich kosztów początkowych, wykwalifikowanego zespołu do jej utrzymania oraz odpowiedniego planowania, by sprostać rosnącemu zapotrzebowaniu z powodu sztywnej natury skalowania zasobów w tradycyjnych centrach danych.
Chmurowa hurtownia danych, przeciwnie, jest zarządzana i hostowana przez dostawcę usług chmurowych. Przykłady to Google BigQuery, Amazon Redshift i Snowflake.
Zwykle chmurowa hurtownia danych ma kilka przewag nad tradycyjnymi:
Przykład bazy wierszowej:

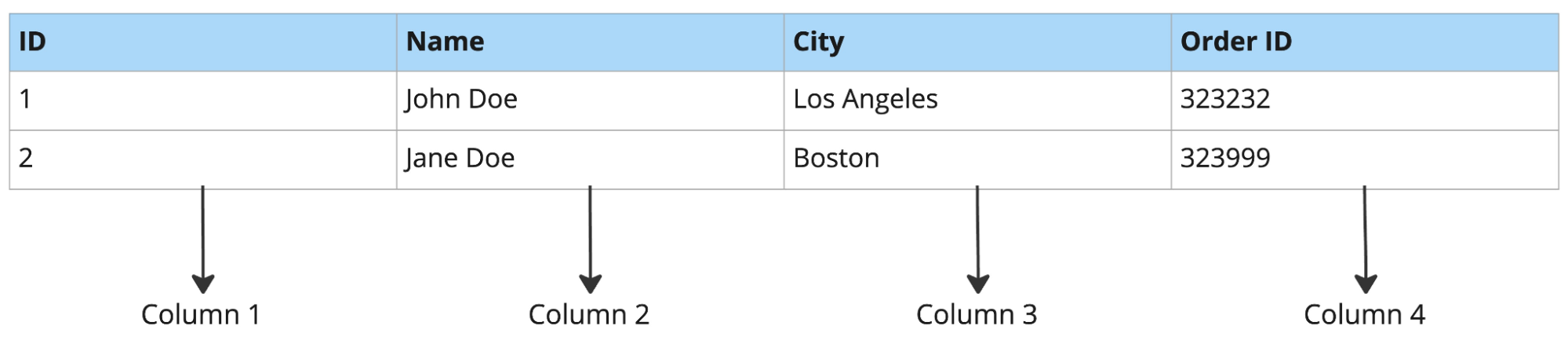
Przykład bazy kolumnowej:
Bazy wierszowe świetnie się sprawdzają przy odczytach pełnych wierszy, wstawianiu rekordów i aktualizacjach. Gorzej radzą sobie jednak z obciążeniami analitycznymi.
Na przykład, jeśli zapytasz o trzy kolumny z tabeli liczącej 50 kolumn, baza wierszowa i tak odczyta wszystkie 50 kolumn dla każdego wiersza. Baza kolumnowa odczyta tylko te trzy, których potrzebujesz, co jest dużo szybsze dla analiz, takich jak prognozowanie popytu czy ad‑hocowe raportowanie.
Bazy wierszowe są zazwyczaj dobrze dopasowane do przetwarzania transakcyjnego online (OLTP), a bazy kolumnowe do przetwarzania analitycznego online (OLAP).
Podsumowanie porównania:
|
Baza wierszowa |
Baza kolumnowa |
||||||
|
Sposób przechowywania |
Wg wierszy |
Wg kolumn |
|||||
|
Pobieranie danych |
Pełne rekordy |
Właściwe kolumny |
|||||
|
Typowe zastosowanie |
OLTP |
OLAP |
|||||
|
Szybkie operacje |
Wstawianie, aktualizacje, odczyty |
Zapytania na potrzeby raportowania |
|||||
|
Ładowanie danych |
Zwykle rekord po rekordzie |
Zwykle wsadowo |
|||||
|
Popularne opcje |
Postgres, MySQL, Oracle, Microsoft SQL Server |
Snowflake, Google BigQuery, Amazon Redshift |
|||||
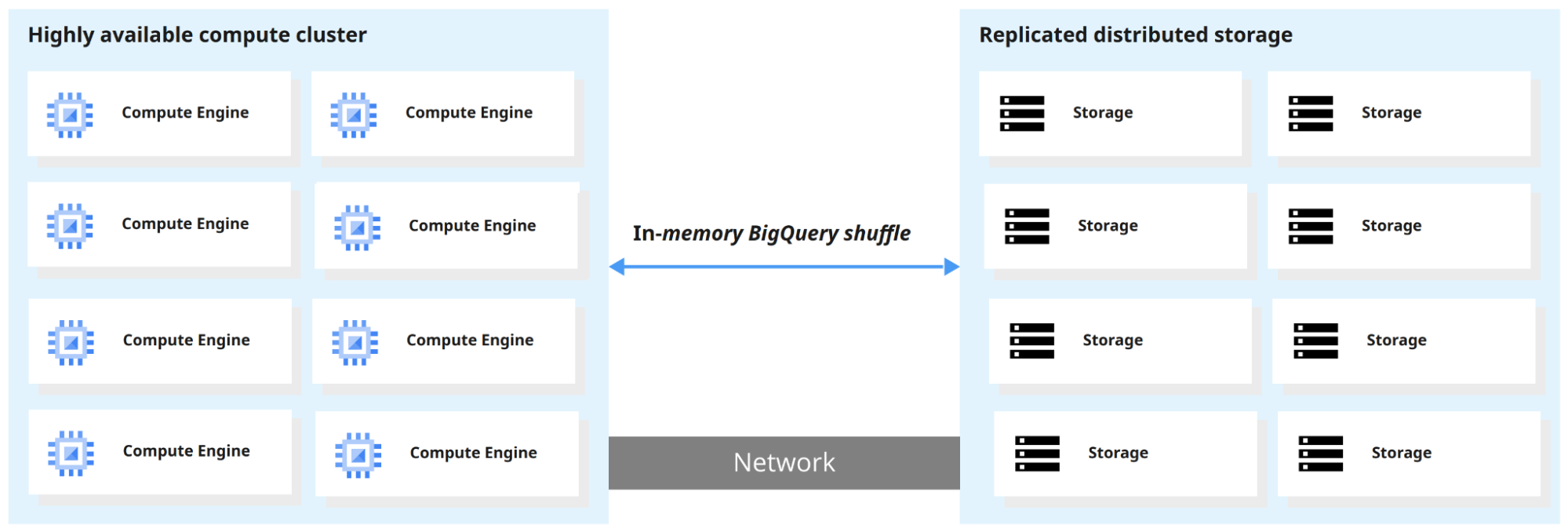
BigQuery oddziela silnik obliczeniowy od warstwy przechowywania, więc każda z nich może skalować się niezależnie. Efekt: możesz zapytywać terabajty danych w sekundy i petabajty w minuty.
Gdy BigQuery uruchamia zapytanie, silnik zapytań rozdziela pracę równolegle, skanując odpowiednie tabele w warstwie przechowywania, scalając wyniki i zwracając finalny zbiór danych.
Od premiery BigQuery Google dodał szereg funkcji, które wykraczają poza tradycyjną hurtownię danych:
Sandbox BigQuery pozwala wypróbować BigQuery bez podawania karty kredytowej czy tworzenia konta rozliczeniowego. W tej sekcji pokażę, jak uzyskać dostęp do BigQuery i skonfigurować pierwszy projekt, korzystając z sandboxa.
Do BigQuery możesz przejść przez Google Cloud Console. Musisz zalogować się kontem Google (lub je utworzyć). Po zalogowaniu powinien pojawić się ekran powitalny:
BigQuery znajdziesz w lewym pasku menu. Kliknięcie przeniesie cię do poniższego ekranu:
Aby użyć sandboxa BigQuery, najpierw utwórz projekt, klikając „Select Project”.
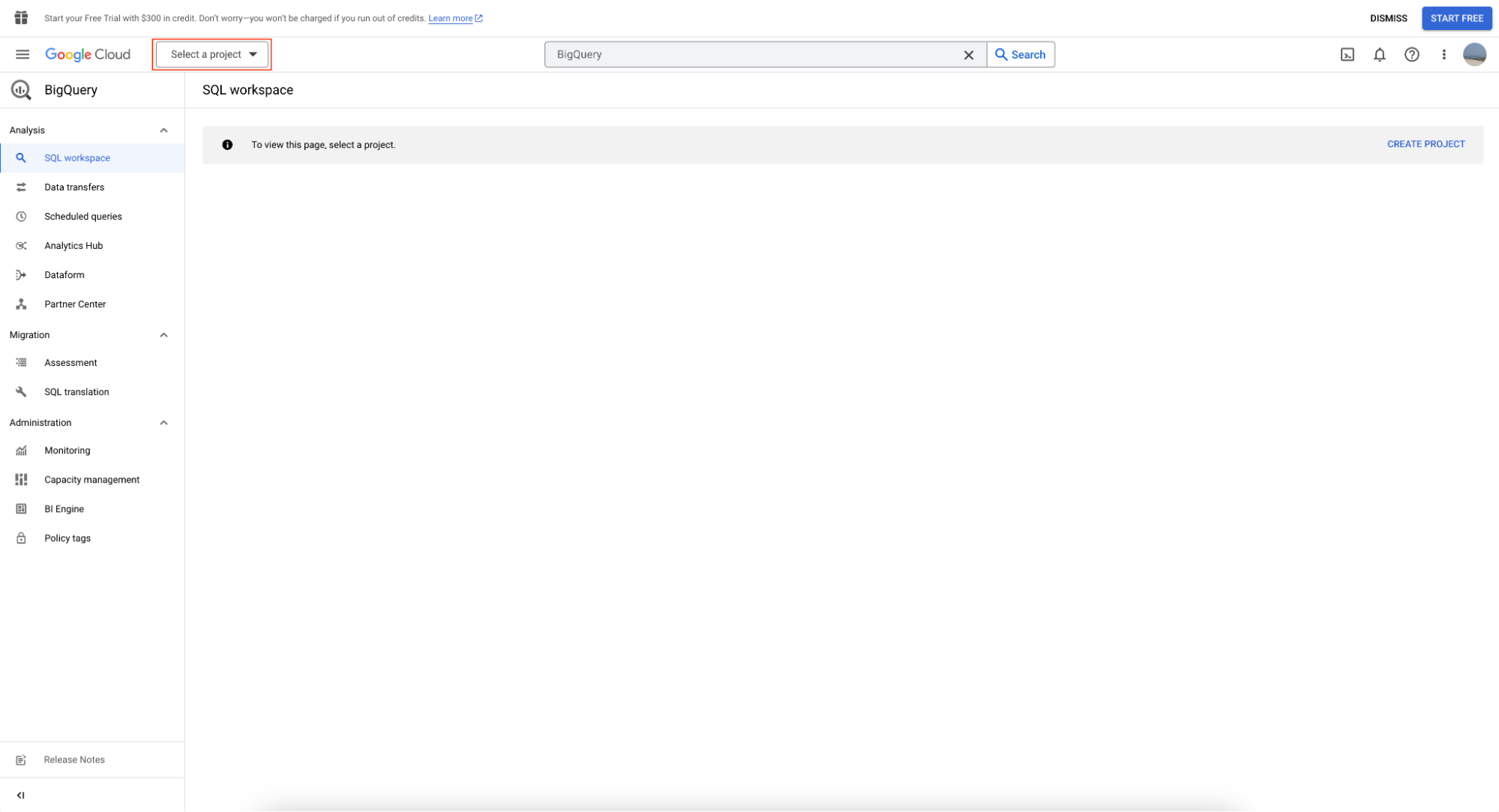
Następnie kliknij „New Project”:
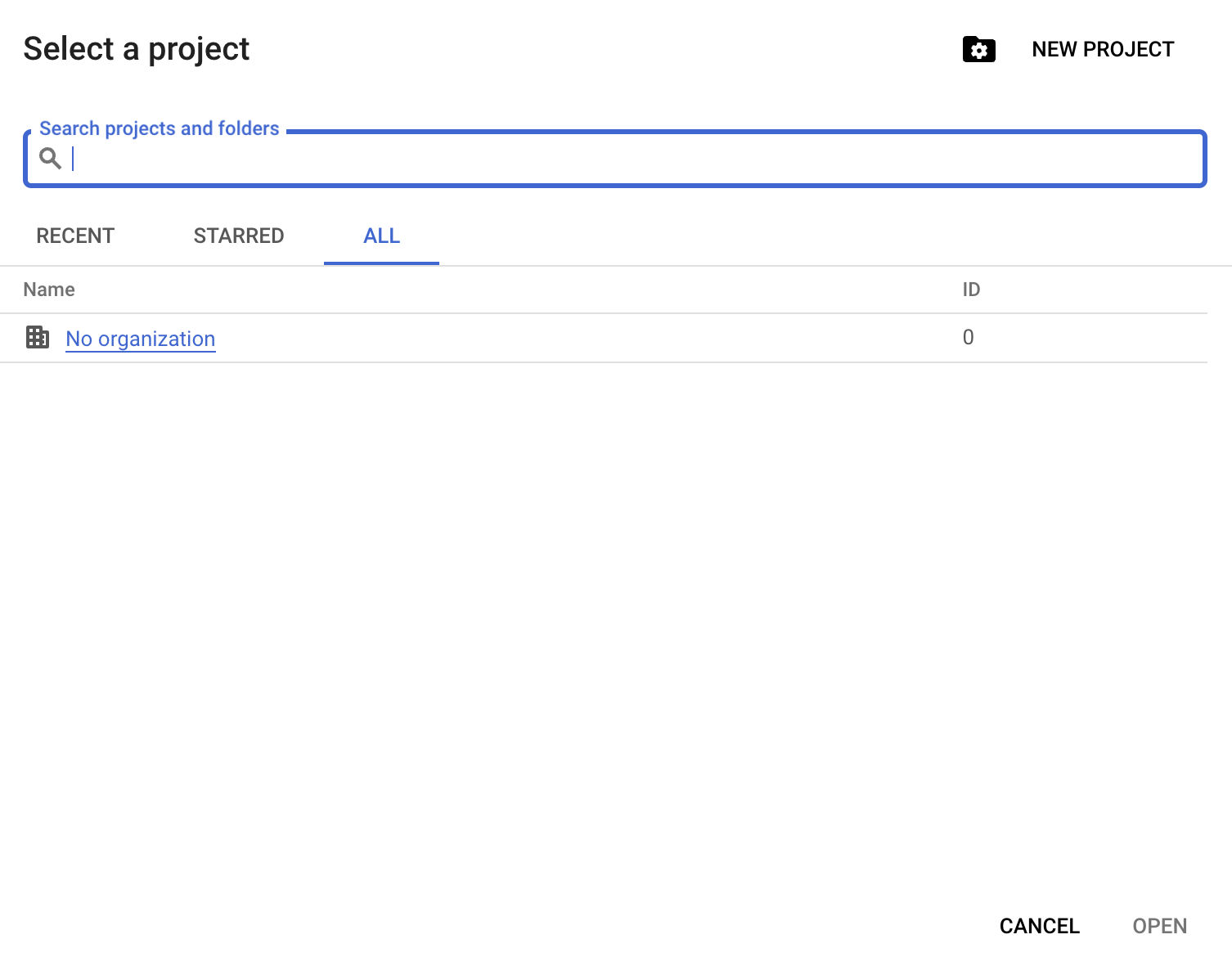
Musisz podać nazwę projektu; w tym przewodniku używamy datacamp-guide-project

Na stronie BigQuery pojawi się teraz informacja o sandboxie, co oznacza, że pomyślnie włączyłeś sandbox BigQuery.

Po włączeniu sandboxa BigQuery możesz używać nowego projektu do ładowania danych i wykonywania zapytań, a także do zapytań na publicznych zbiorach danych Google.
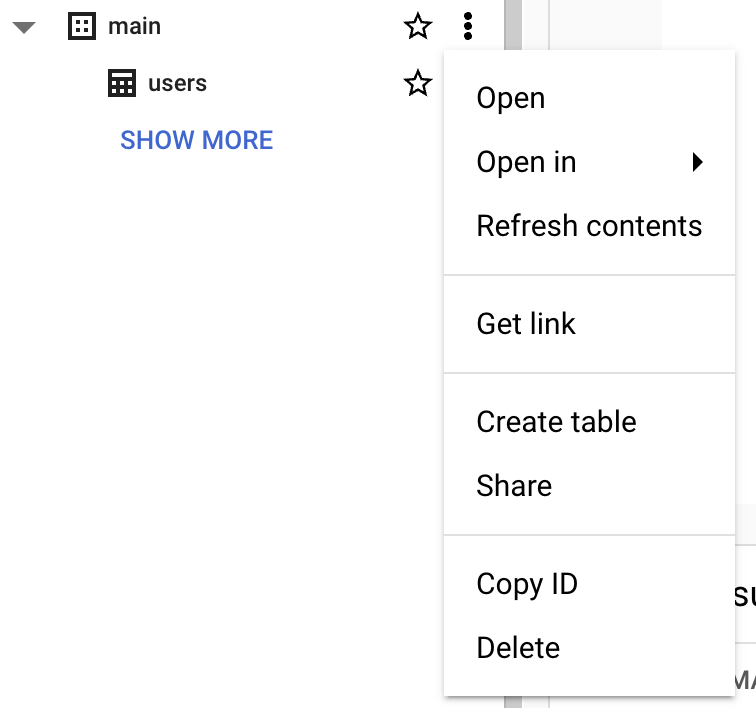
Zanim utworzysz tabelę, musisz utworzyć zbiór danych w nowym projekcie. Zbiór danych to kontener najwyższego poziomu używany do organizacji i kontroli dostępu do zestawu tabel i widoków. Aby utworzyć zbiór danych, kliknij ikonę „Actions” przy projekcie:
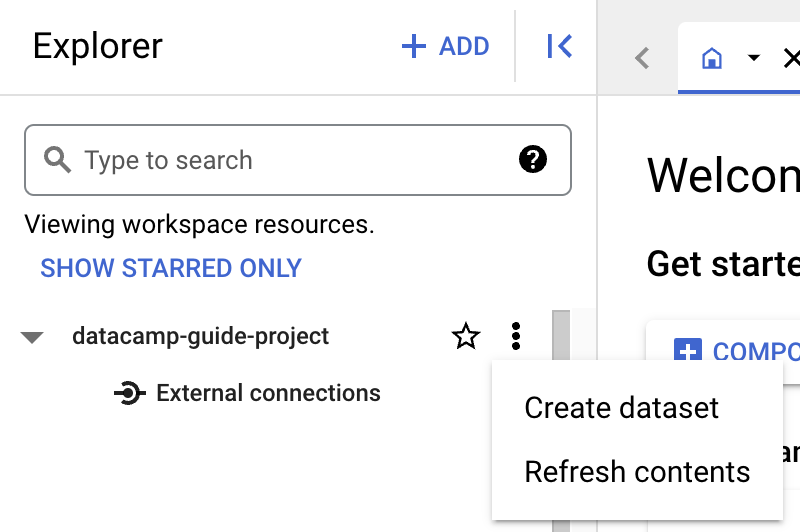
Na potrzeby tego przewodnika wypełnimy „Dataset ID” wartością „main”.
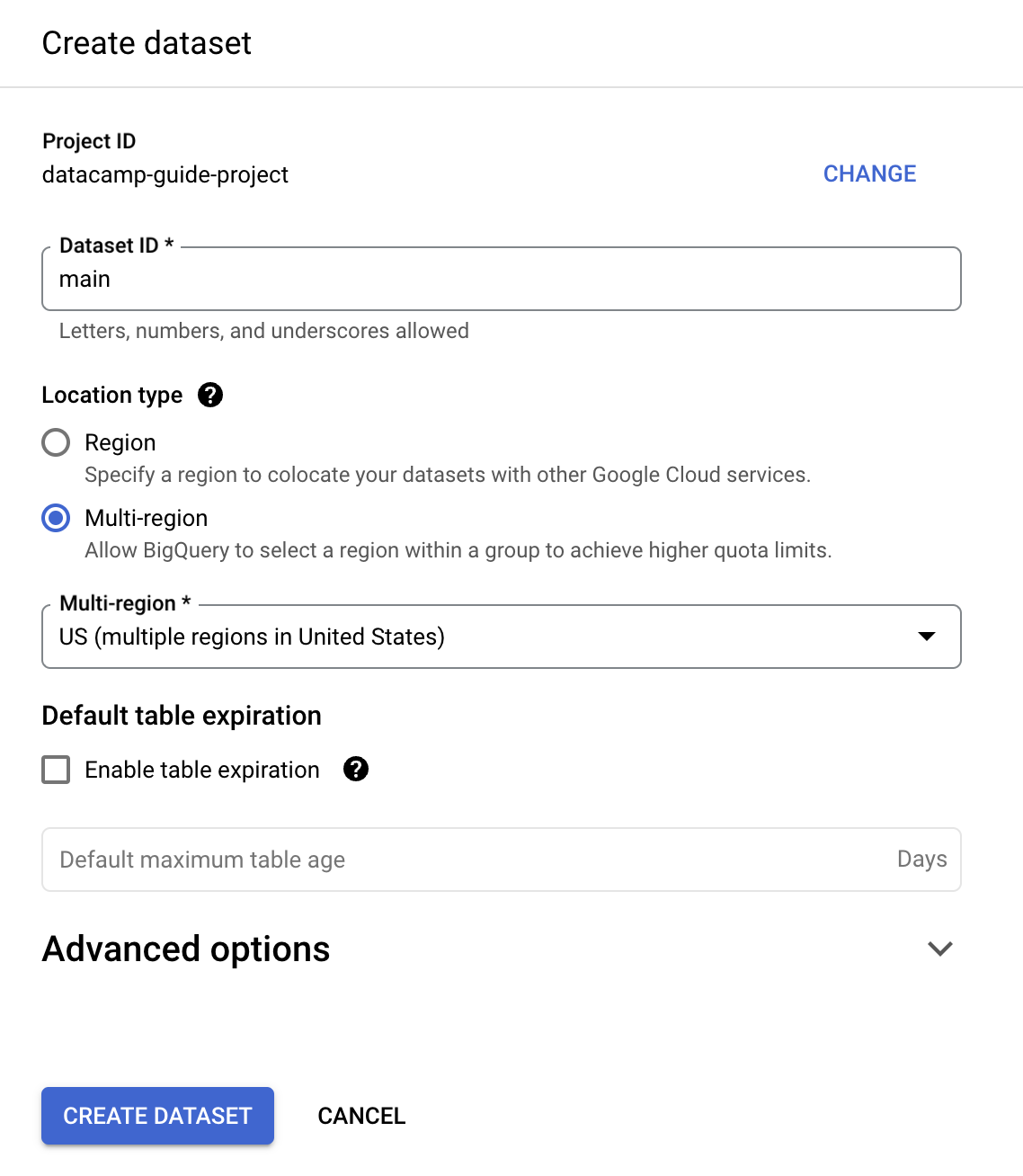
Możesz utworzyć tabelę przy użyciu SQL. BigQuery używa GoogleSQL, który jest zgodny z ANSI.
CREATE TABLE datacamp-guide-project.main.users (
id INT64 NOT NULL,
first_name STRING NOT NULL,
middle_name STRING,
last_name STRING NOT NULL,
active_account BOOL NOT NULL
);Możesz też użyć interfejsu BigQuery Console:
Uwaga: W środowisku sandbox nie da się wstawiać danych. Jeśli chcesz to wypróbować, musisz włączyć darmowy okres próbny. Kolejne sekcje skupiają się na zapytaniach do publicznych zbiorów danych udostępnianych w Google Cloud.
Aby wykonać zapytanie do publicznego zbioru danych, postępuj według kroków poniżej:
1. Kliknij „Add” obok Explorer.

2. Następnie wybierz zbiór danych.
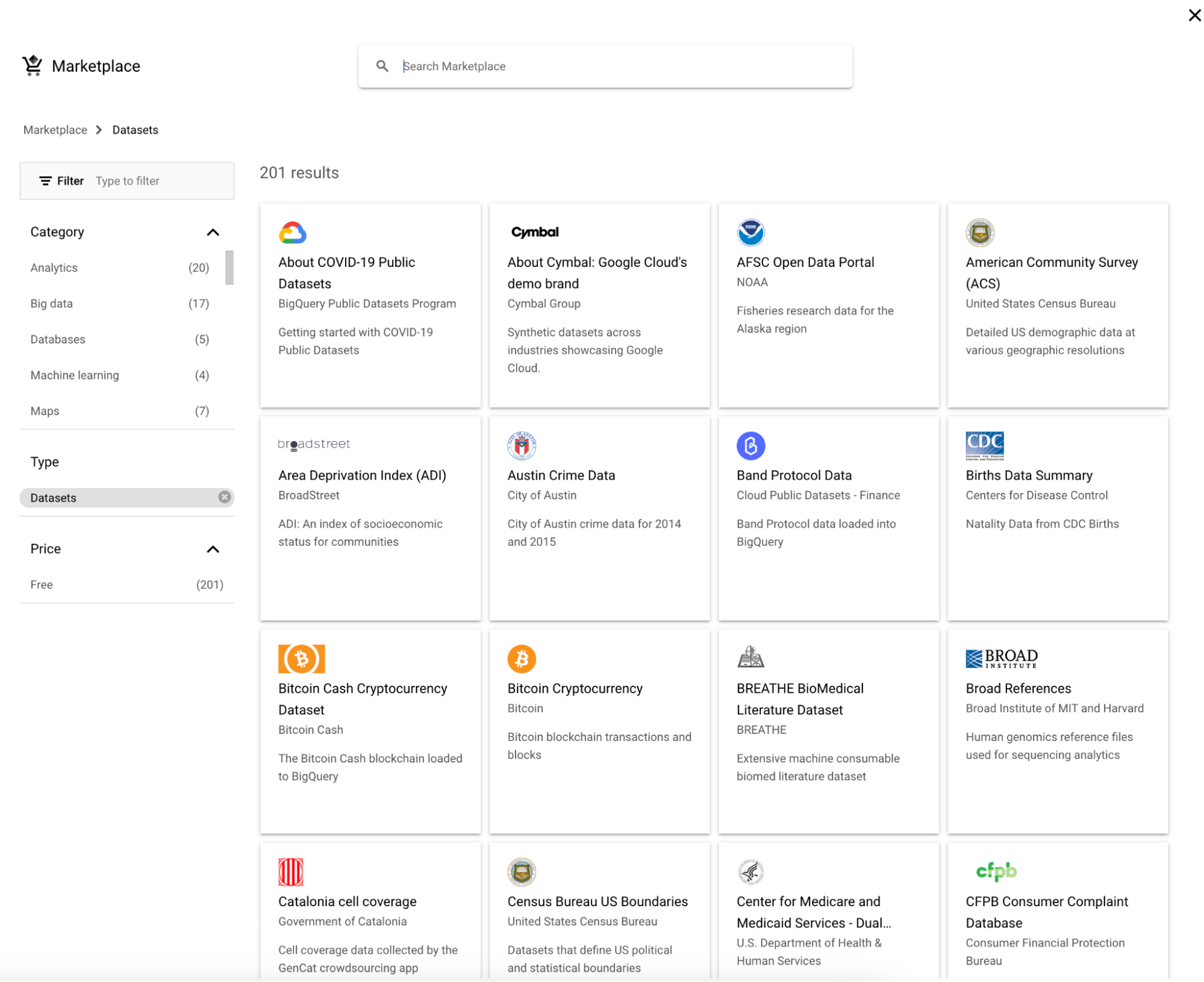
3. Wyszukaj „Google Trends” i wybierz Google Trends, a potem kliknij przycisk „View dataset”.

4. bigquery-public-data pojawi się z długą listą zbiorów danych. Oznacz bigquery-public-data gwiazdką, aby było „przyklejone” w eksploratorze
Użyjemy tabeli top_terms:

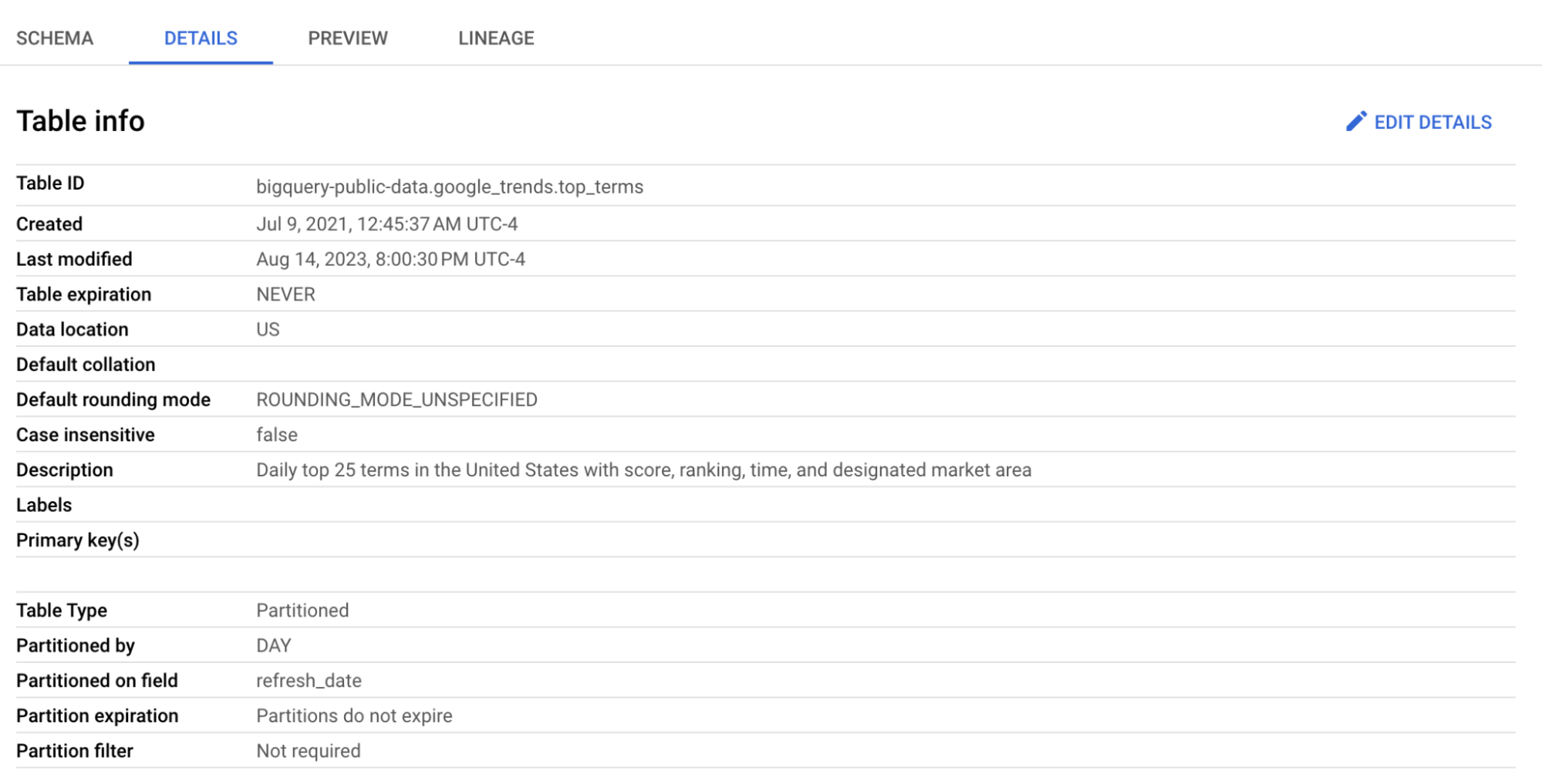
Kliknij tabelę top_terms, aby ją otworzyć, i przejrzyj zakładki Details oraz Preview, by dowiedzieć się więcej o danych w top_terms.
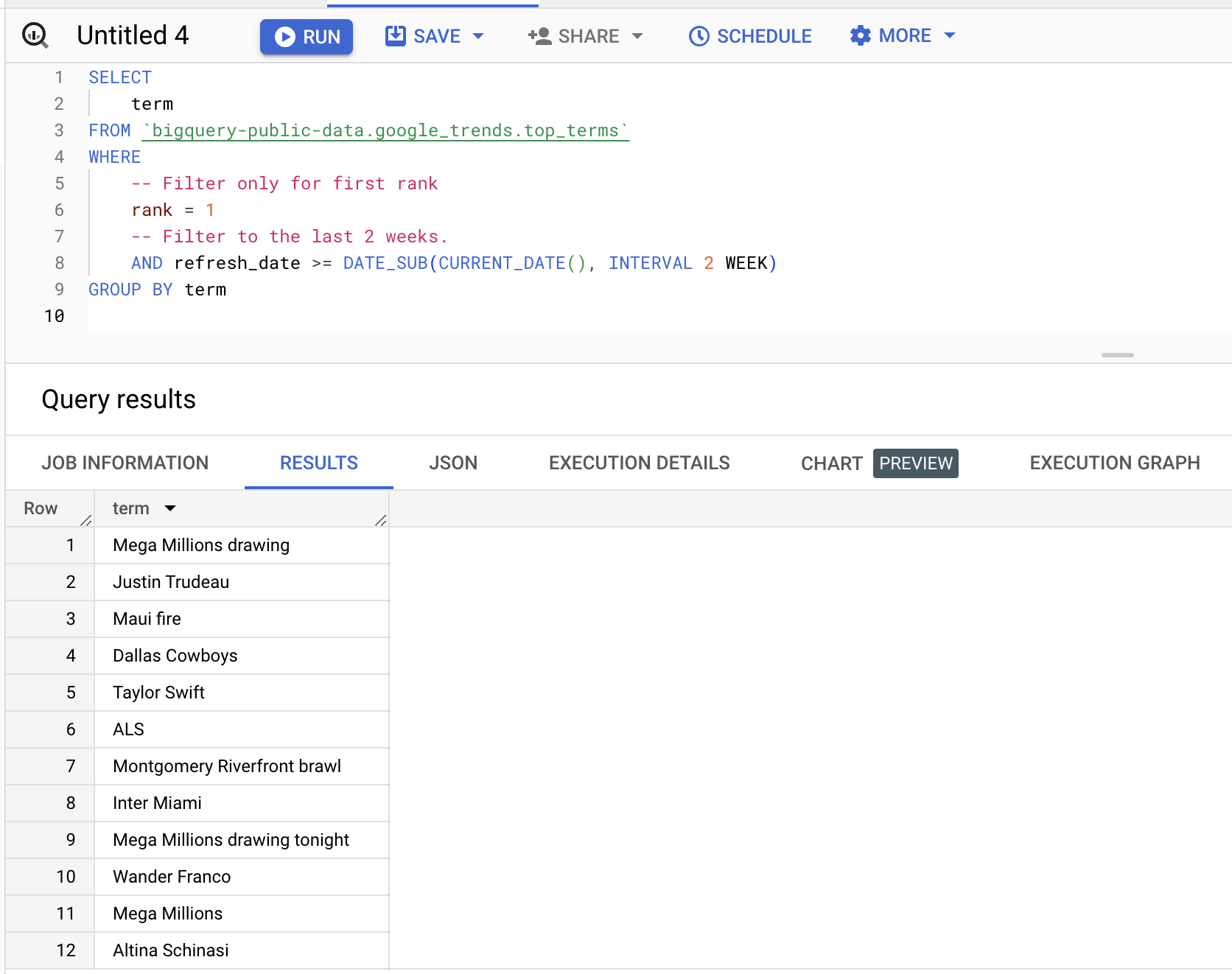
Możesz zapytać ten zbiór; poniżej przykład pobrania haseł, które zajęły pierwszą pozycję w ciągu ostatnich dwóch tygodni:
SELECT
term
FROM
bigquery-public-data.google_trends.top_terms
WHERE
rank = 1
AND refresh_date >= DATE_SUB(CURRENT_DATE(), INTERVAL 2 WEEK)
GROUP BY
termWyniki (będą się różnić):
Cennik BigQuery ma dwa główne składniki: obliczenia (przetwarzanie zapytań) i przechowywanie.
| Składnik | Darmowy pakiet | Cena płatna |
|---|---|---|
| Zapytania on-demand | 1 TiB miesięcznie | $6.25 za TiB |
| Przechowywanie (aktywne) | 10 GiB | $0.02 za GiB/miesiąc |
| Przechowywanie (długoterminowe) | 10 GiB | $0.01 za GiB/miesiąc |
| Wstawienia strumieniowe | N/D | $0.05 za 200 MB |
Dla zespołów o przewidywalnych obciążeniach BigQuery oferuje też ceny ryczałtowe poprzez rezerwacje mocy (BigQuery Editions). Sprawdź oficjalną stronę cennika, by poznać aktualne stawki.
BigQuery to jeden z najłatwiejszych punktów wejścia do hurtowni danych w chmurze. Sandbox daje ci bezpieczne środowisko do eksperymentów, a 1 TiB darmowych zapytań miesięcznie oznacza, że możesz eksplorować publiczne zbiory danych bez żadnych kosztów. Gdy będziesz potrzebować więcej, darmowy okres próbny Google Cloud zapewnia 300 USD w kredytach.
Jeśli chcesz rozwinąć to, czego się tu nauczyłeś, polecam kurs Introduction to BigQuery na DataCamp, który obejmuje optymalizację zapytań i pracę z większymi zbiorami danych. Szerszy obraz inżynierii danych daje ścieżka Data Engineer in Python, która obejmuje cały pipeline od ingestii po hurtownię.
Możesz też sprawdzić, jak BigQuery wypada na tle alternatyw w naszych porównaniach BigQuery vs Redshift i BigQuery vs Snowflake, albo przygotować się do rozmów kwalifikacyjnych dzięki przewodnikowi BigQuery interview questions.
Zacznij z inżynierią danych już dziś!
Track
course
course