
Lernpfad
Associate Data Engineer in SQL
30 Std.
Ein traditionelles Data Warehouse wird on-premises betrieben. Das erfordert meist hohe Anfangsinvestitionen, ein erfahrenes Team für Betrieb und Wartung sowie sorgfältige Kapazitätsplanung, weil sich Rechenzentrumsressourcen nur starr skalieren lassen.
Ein Cloud-Data-Warehouse wird dagegen von einem Cloud-Anbieter gehostet und gemanagt. Beispiele sind Google BigQuery, Amazon Redshift und Snowflake.
In der Regel bieten Cloud-Data-Warehouses mehrere Vorteile gegenüber traditionellen Data Warehouses:
Beispiel einer zeilenorientierten Datenbank:

Beispiel einer spaltenorientierten Datenbank:
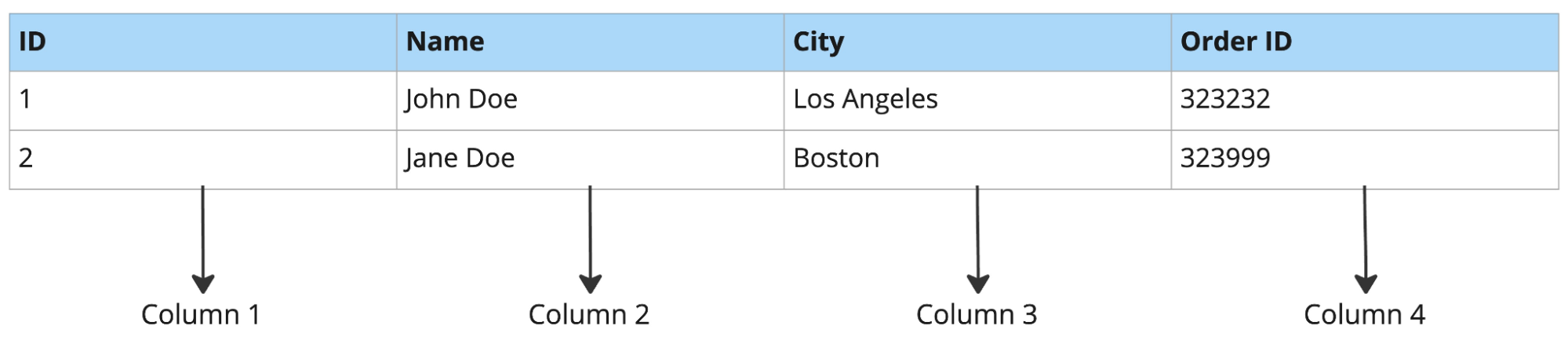
Zeilenorientierte Datenbanken sind gut für vollständige Zeilenabfragen, Inserts und Updates. Bei analytischen Workloads geraten sie jedoch ins Hintertreffen.
Wenn du zum Beispiel drei Spalten aus einer Tabelle mit 50 Spalten abfragst, liest eine zeilenorientierte Datenbank trotzdem alle 50 Spalten jeder Zeile. Eine spaltenorientierte Datenbank liest nur die drei benötigten Spalten – deutlich schneller für Analysen wie Produktprognosen oder Ad-hoc-Reporting.
Zeilenorientierte Datenbanken eignen sich typischerweise für Online Transaction Processing (OLTP), spaltenorientierte für Online Analytical Processing (OLAP).
Zusammenfassung des Vergleichs:
|
Zeilenorientierte Datenbank |
Spaltenorientierte Datenbank |
||||||
|
Speicherung |
Nach Zeile |
Nach Spalte |
|||||
|
Datenabruf |
Vollständige Datensätze |
Relevante Spalten |
|||||
|
Typische Anwendung |
OLTP |
OLAP |
|||||
|
Schnelle Operationen |
Insert, Updates, Lookups |
Abfragen für Reporting |
|||||
|
Daten laden |
Meistens Datensatz für Datensatz |
Meistens im Batch |
|||||
|
Beliebte Optionen |
Postgres, MySQL, Oracle, Microsoft SQL Server |
Snowflake, Google BigQuery, Amazon Redshift |
|||||
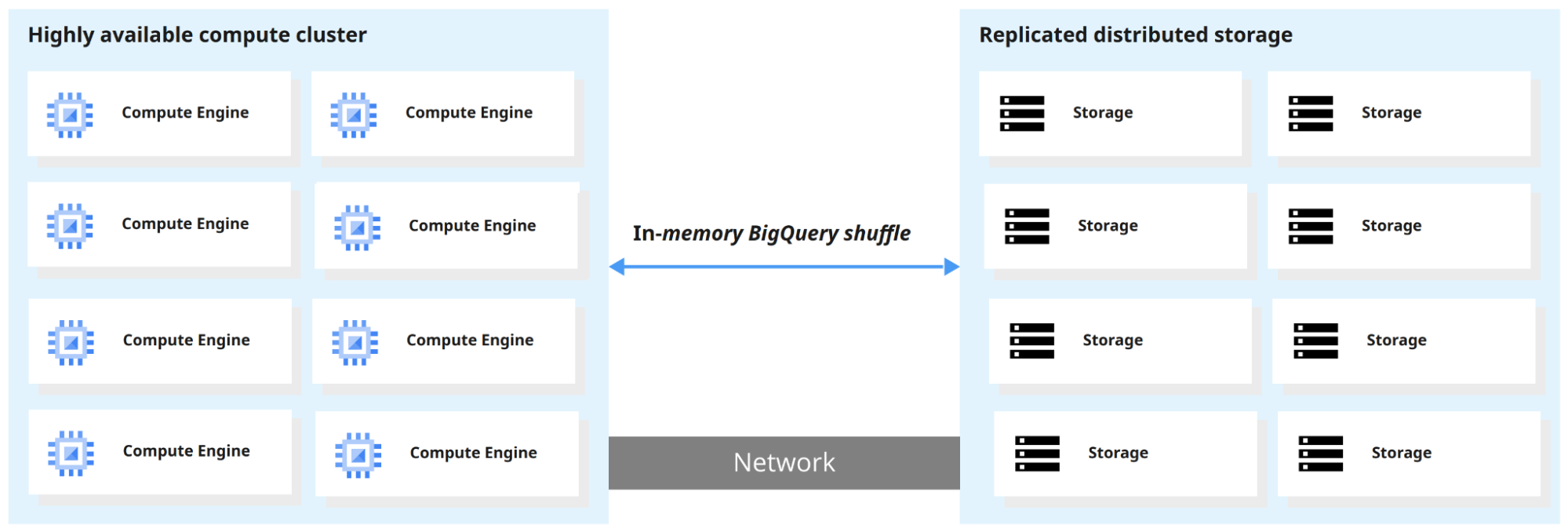
BigQuery trennt Rechenleistung und Speicher, sodass beides unabhängig skaliert. Das Ergebnis: Terabytes in Sekunden, Petabytes in Minuten abfragen.
Wenn BigQuery eine Abfrage ausführt, verteilt die Query Engine die Arbeit parallel, scannt die relevanten Tabellen im Storage, führt die Ergebnisse zusammen und liefert den finalen Datensatz zurück.
Seit dem Start von BigQuery hat Google zahlreiche Funktionen ergänzt, die über ein klassisches Data Warehouse hinausgehen:
Mit der BigQuery-Sandbox kannst du BigQuery ohne Kreditkarte oder Abrechnungskonto testen. In diesem Abschnitt zeige ich dir, wie du auf BigQuery zugreifst und mit der Sandbox dein erstes Projekt anlegst.
Du erreichst BigQuery über die Google Cloud Console. Melde dich mit einem Google-Konto an (oder erstelle eines). Nach dem Login erscheint ein Willkommensbildschirm:
Du findest BigQuery in der linken Seitenleiste. Ein Klick führt dich zu folgendem Bildschirm:
Um die BigQuery-Sandbox zu nutzen, lege zunächst ein Projekt an, indem du auf „Select Project“ klickst.
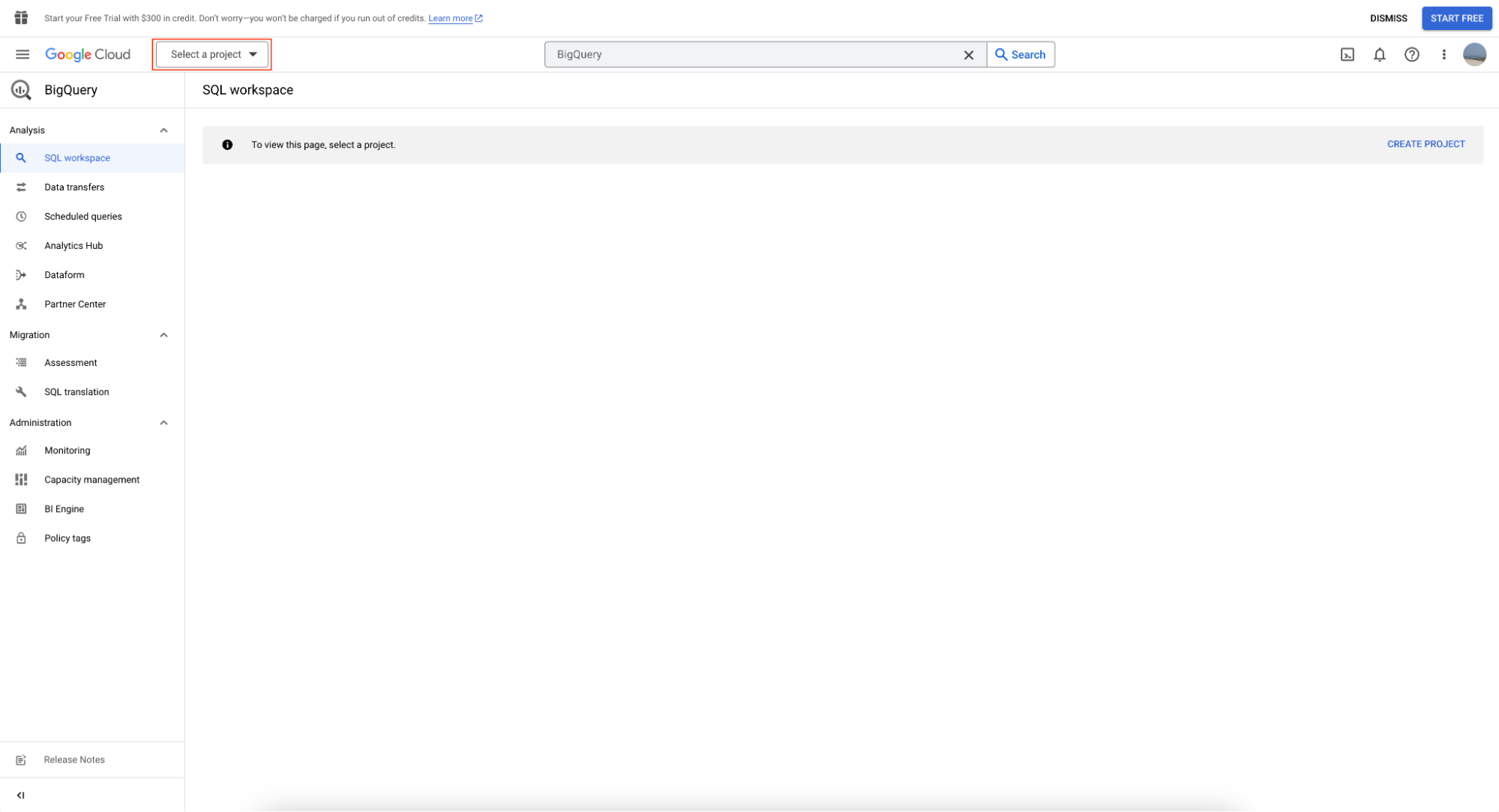
Klicke anschließend auf „New Project“:
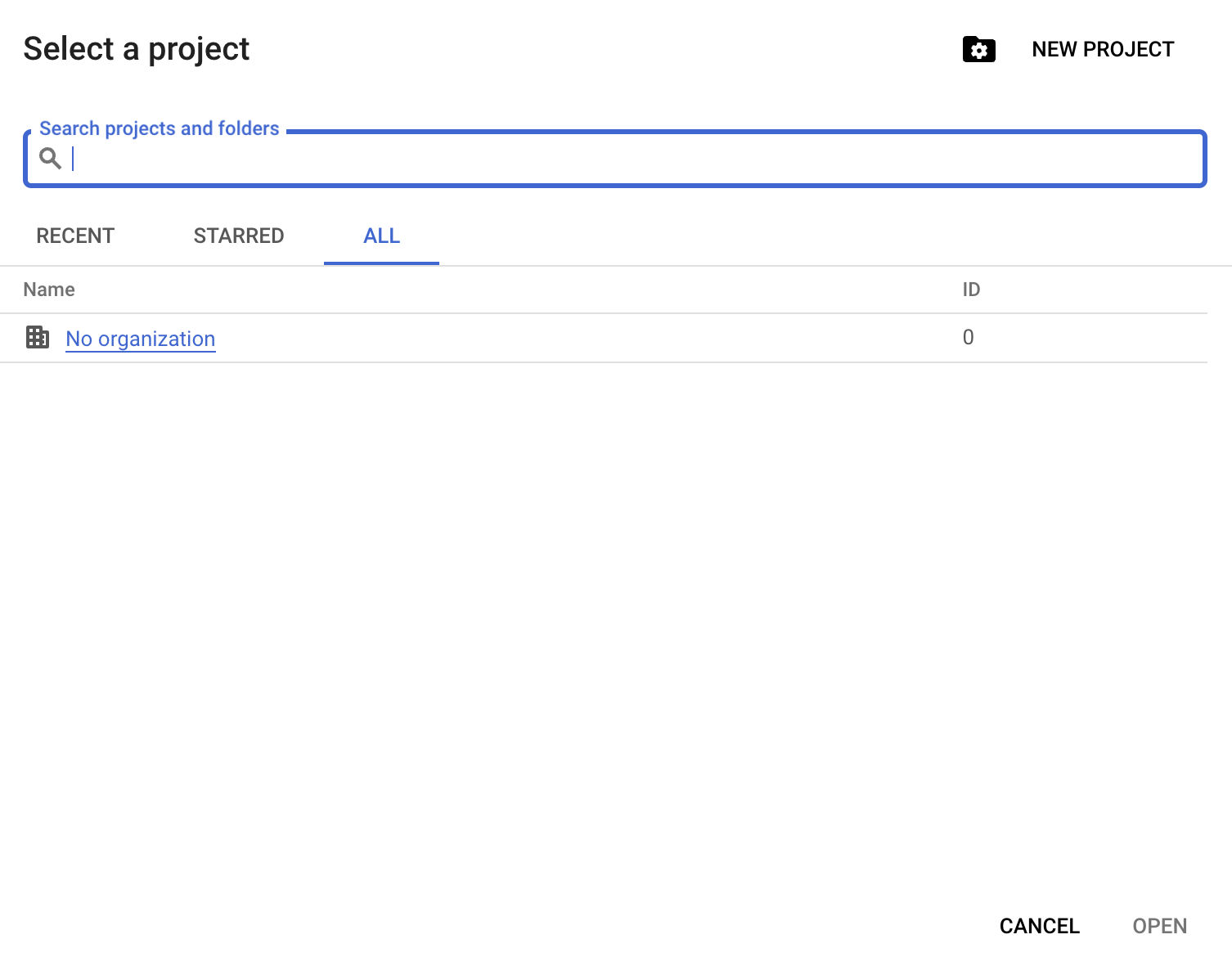
Vergib einen Projektnamen; in diesem Guide verwenden wir datacamp-guide-project.

Auf der BigQuery-Seite erscheint nun ein Sandbox-Hinweis – die BigQuery-Sandbox ist erfolgreich aktiviert.

Mit aktivierter BigQuery-Sandbox kannst du in deinem neuen Projekt Daten laden und abfragen sowie die öffentlichen Google-Datensätze nutzen.
Bevor du eine Tabelle anlegst, musst du in deinem Projekt ein Dataset erstellen. Ein Dataset ist ein Container auf oberster Ebene, mit dem du Tabellen und Views organisierst und deren Zugriff steuerst. Klicke zum Erstellen eines Datasets auf das „Actions“-Symbol deines Projekts:
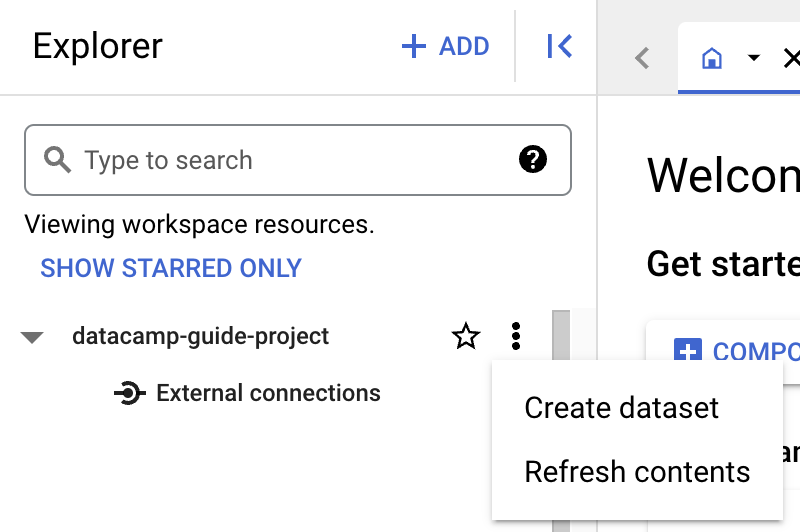
Für dieses Beispiel füllen wir „Dataset ID“ mit „main“.
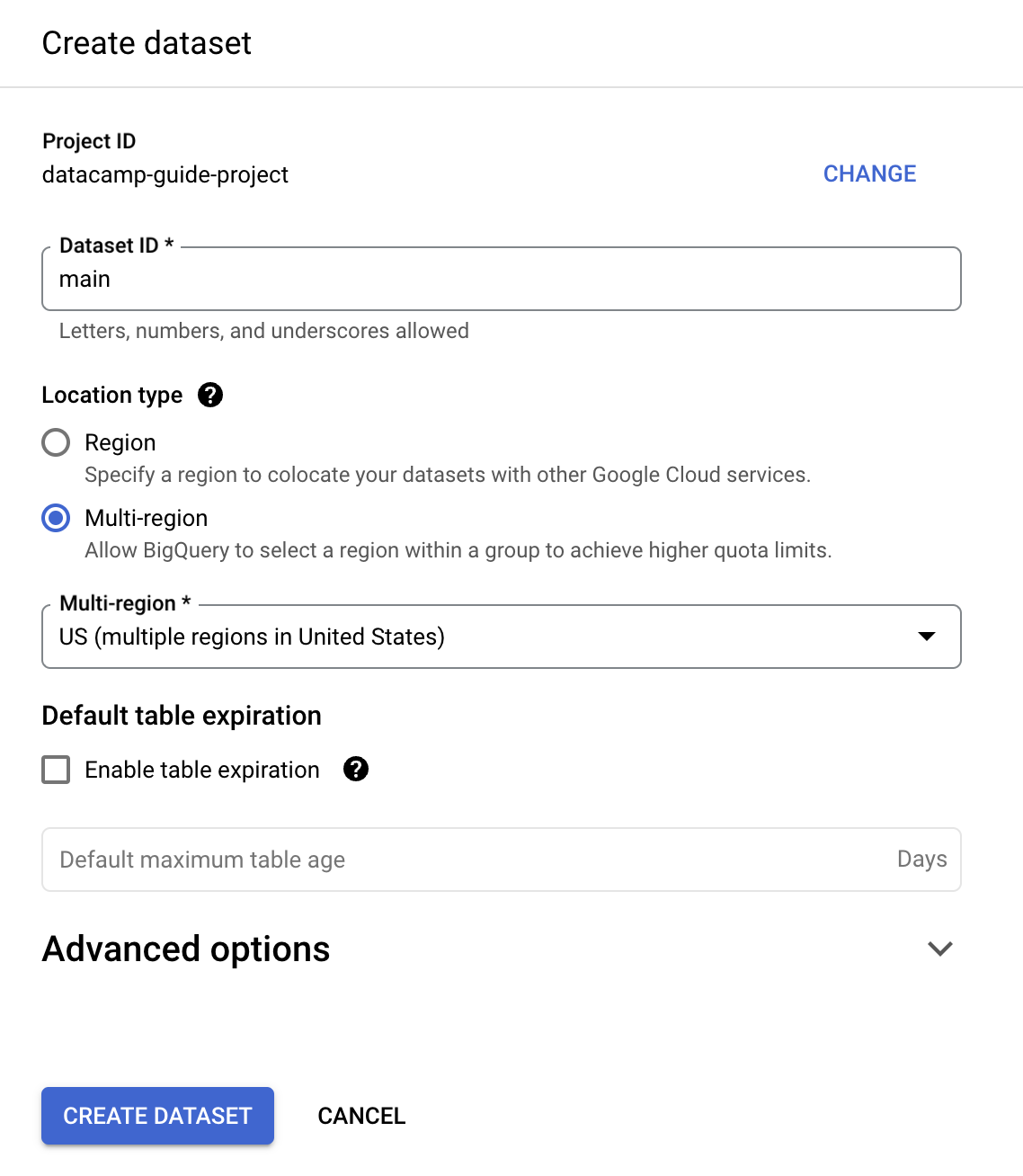
Du kannst eine Tabelle per SQL erstellen. BigQuery verwendet GoogleSQL, das ANSI-konform ist.
CREATE TABLE datacamp-guide-project.main.users (
id INT64 NOT NULL,
first_name STRING NOT NULL,
middle_name STRING,
last_name STRING NOT NULL,
active_account BOOL NOT NULL
);Alternativ nutzt du die Oberfläche der BigQuery-Konsole:
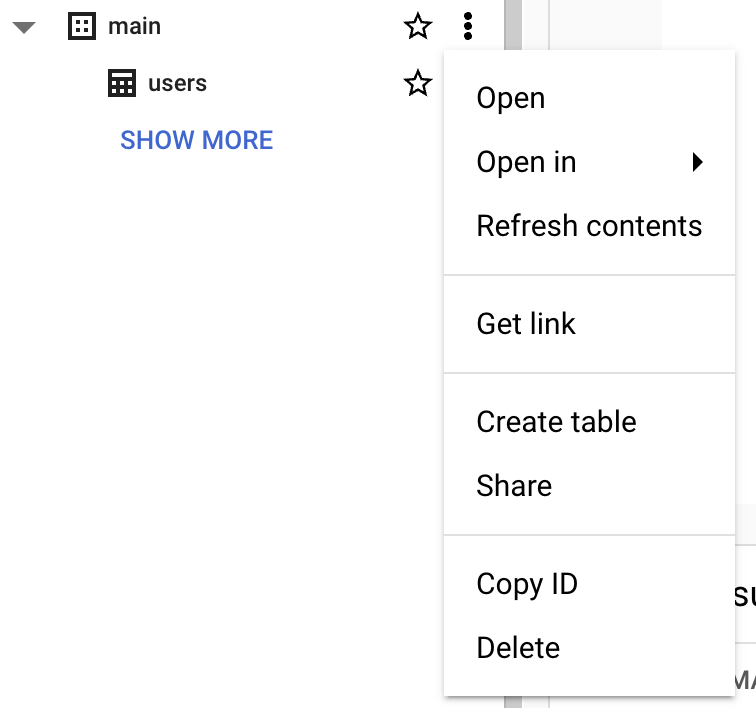
Hinweis: In der Sandbox kannst du keine Daten einfügen. Wenn du Inserts testen möchtest, aktiviere die kostenlose Testversion. Die nächsten Abschnitte konzentrieren sich auf Abfragen öffentlicher Datensätze, die Teil von Google Cloud sind.
So fragst du einen öffentlichen Datensatz ab:
1. Klicke neben Explorer auf „Add“.

2. Wähle anschließend ein Dataset aus.
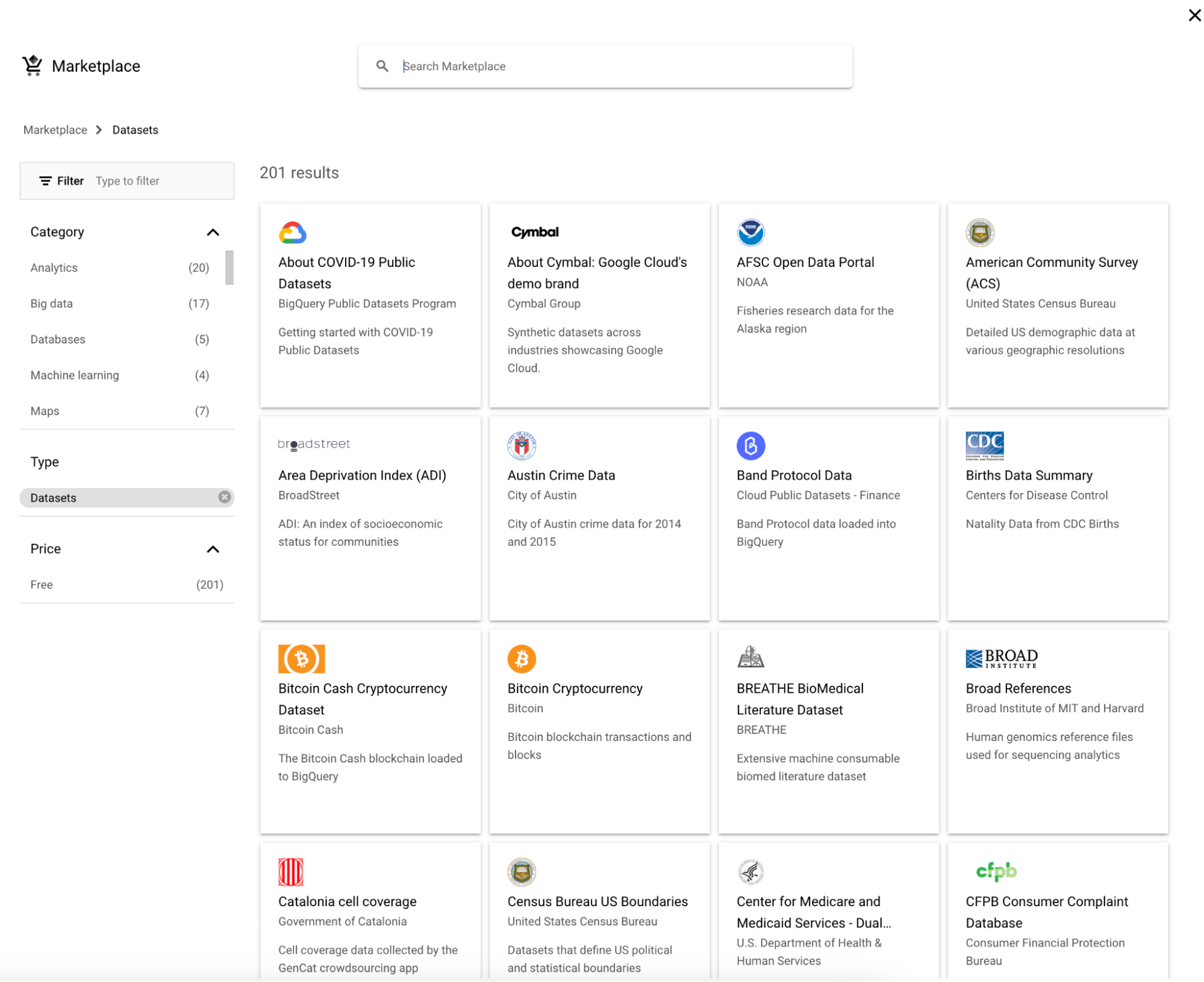
3. Suche nach „Google Trends“ und wähle Google Trends. Klicke dann auf „View dataset“.

4. bigquery-public-data erscheint mit einer langen Liste an Datasets. Setze bigquery-public-data als Favorit (Stern), damit es im Explorer „kleben bleibt“.
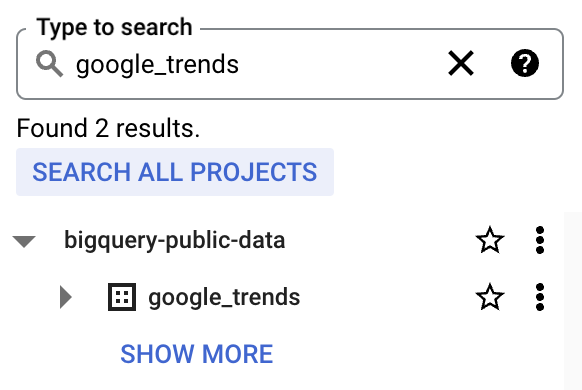
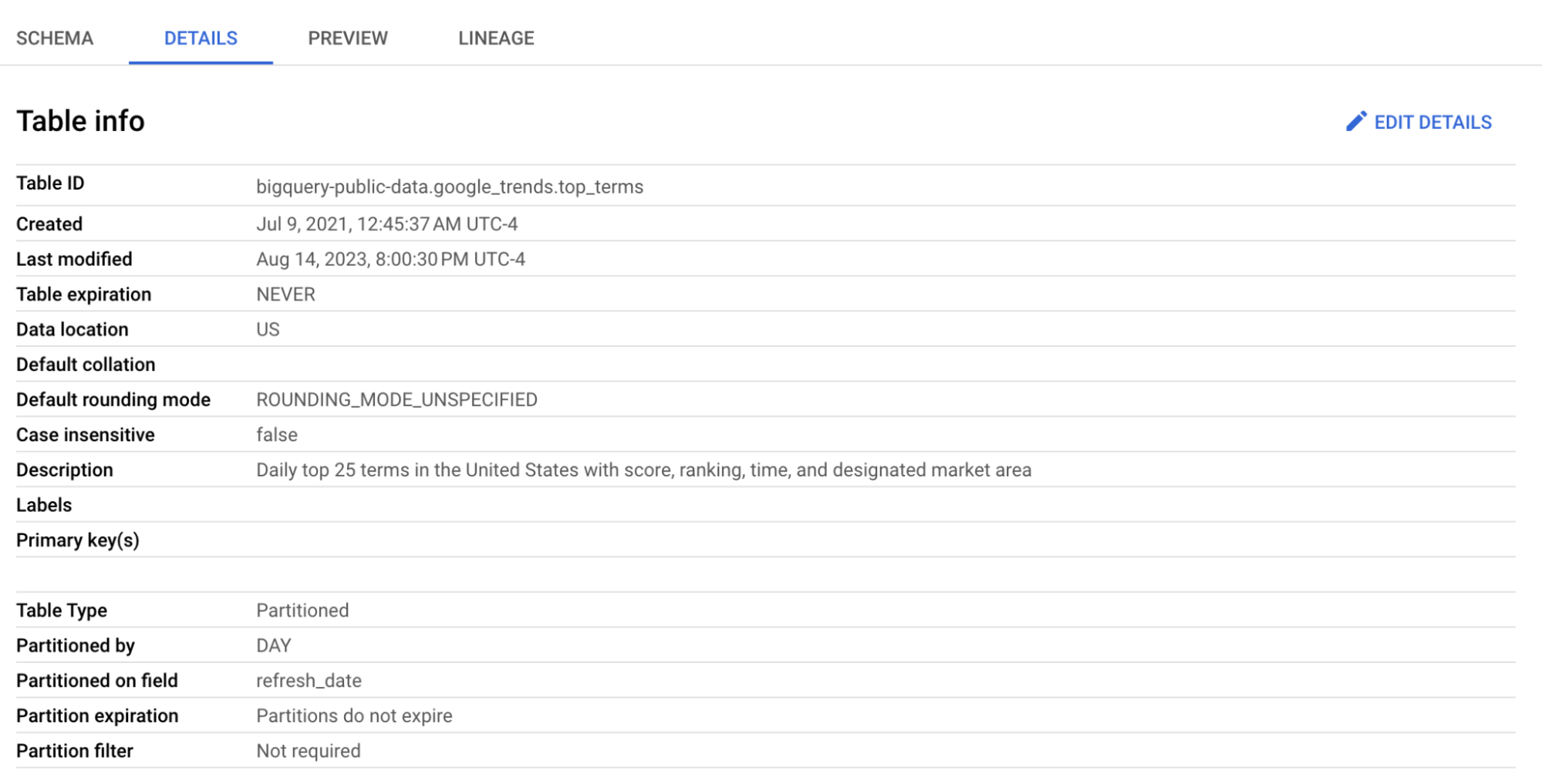
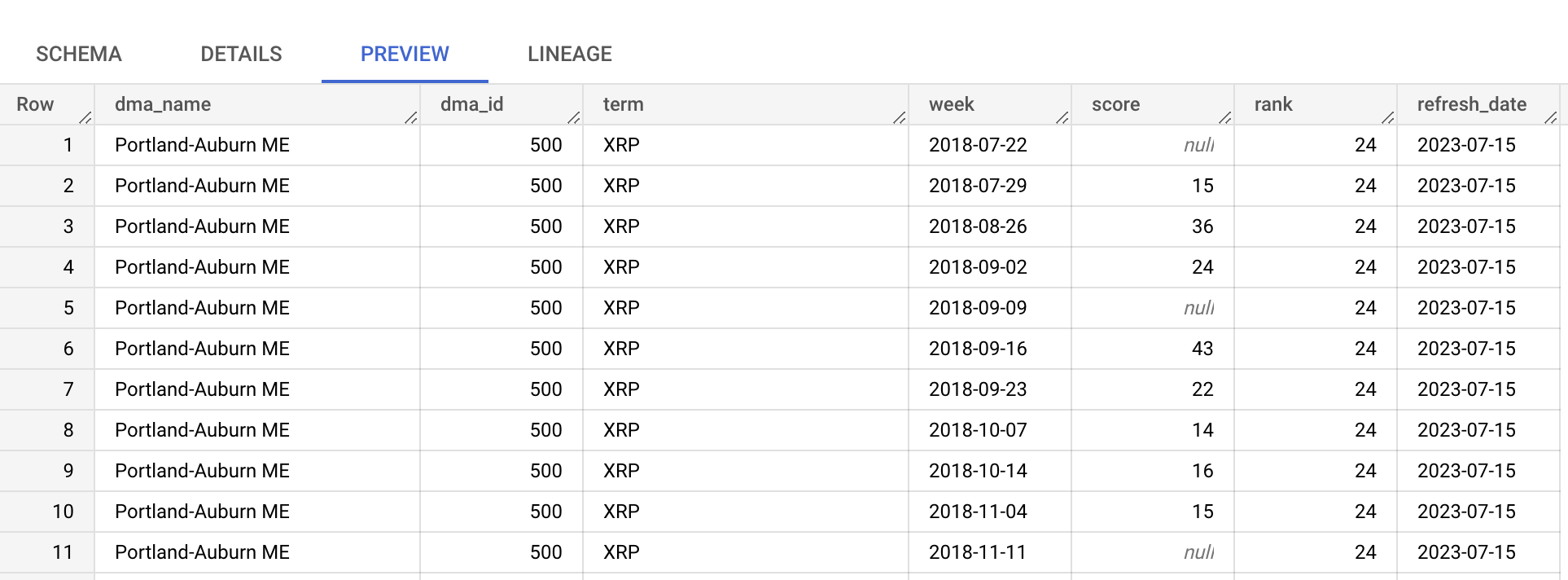
Wir verwenden die Tabelle top_terms:

Klicke auf die Tabelle top_terms, und sieh dir Details und Vorschau an, um mehr über die Daten in top_terms zu erfahren.
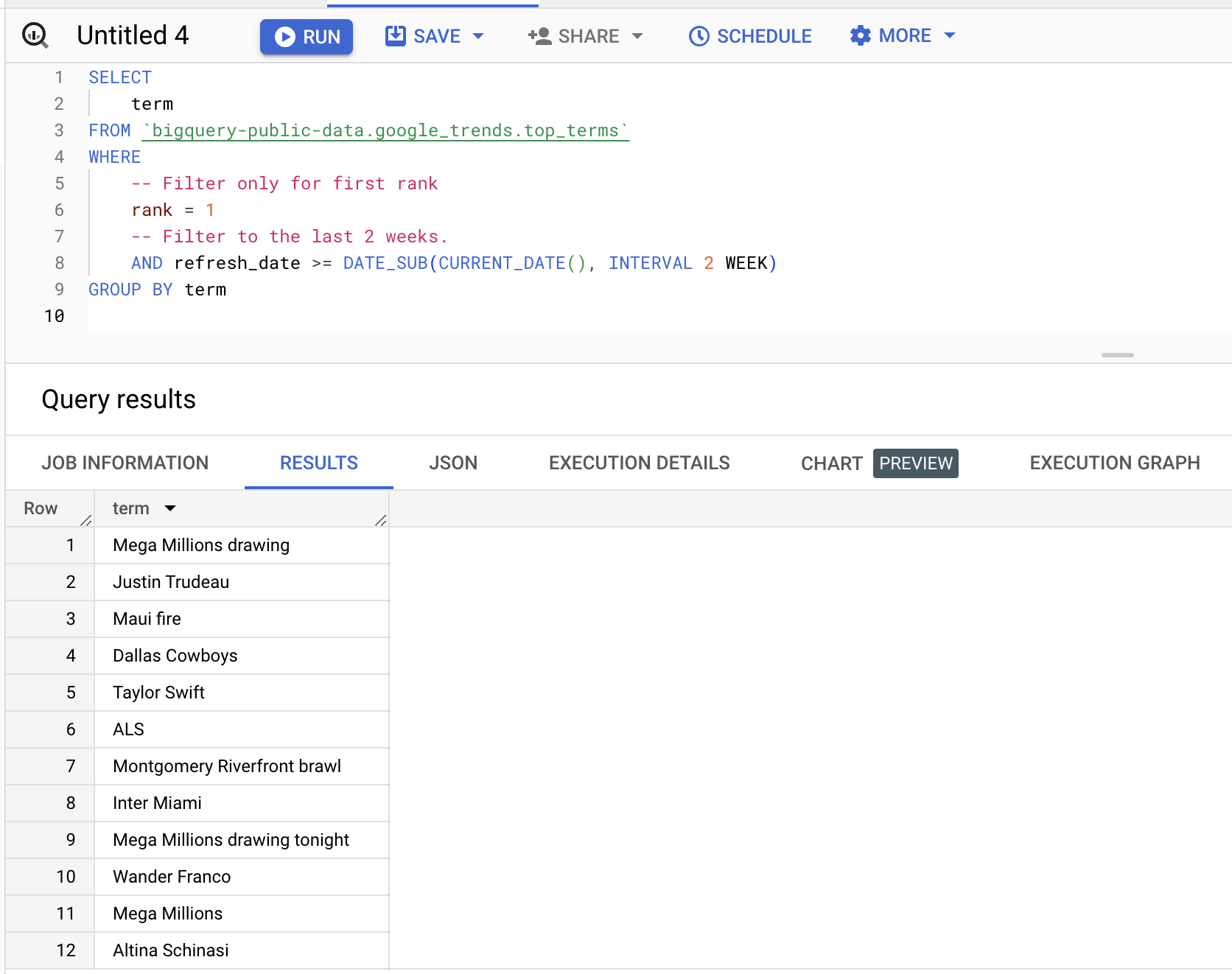
Du kannst den Datensatz abfragen, zum Beispiel so, um Begriffe zu holen, die in den letzten zwei Wochen auf Platz eins standen:
SELECT
term
FROM
bigquery-public-data.google_trends.top_terms
WHERE
rank = 1
AND refresh_date >= DATE_SUB(CURRENT_DATE(), INTERVAL 2 WEEK)
GROUP BY
termErgebnisse (variieren):
Die BigQuery-Preisstruktur hat zwei Hauptkomponenten: Compute (Query-Verarbeitung) und Storage.
| Komponente | Kostenloses Kontingent | Bezahlmodell |
|---|---|---|
| On-Demand-Abfragen | 1 TiB pro Monat | $6.25 pro TiB |
| Storage (aktiv) | 10 GiB | $0.02 pro GiB/Monat |
| Storage (Langzeit) | 10 GiB | $0.01 pro GiB/Monat |
| Streaming-Inserts | k. A. | $0.05 pro 200 MB |
Für Teams mit gut planbaren Workloads bietet BigQuery zudem Pauschalpreise über Kapazitätsreservierungen (BigQuery Editions). Die aktuellen Tarife findest du auf der offiziellen Preisseite.
BigQuery ist einer der leichtesten Einstiege ins Cloud-Data-Warehousing. Die Sandbox bietet dir eine risikofreie Umgebung zum Experimentieren, und mit 1 TiB kostenlosen Abfragen pro Monat kannst du öffentliche Datensätze erkunden, ohne Geld auszugeben. Wenn du mehr brauchst, stellt die kostenlose Google-Cloud-Testversion 300 $ Guthaben bereit.
Wenn du das hier Gelernte vertiefen willst, empfehle ich den Kurs Introduction to BigQuery auf DataCamp. Er behandelt Query-Optimierung und die Arbeit mit größeren Datensätzen. Für einen breiteren Blick auf Data Engineering deckt der Data Engineer in Python-Lernpfad die gesamte Pipeline von Ingestion bis Warehousing ab.
Außerdem kannst du in unseren Vergleichen BigQuery vs Redshift und BigQuery vs Snowflake sehen, wie sich BigQuery gegenüber Alternativen schlägt, oder dich mit unserem Guide zu BigQuery-Interviewfragen auf Bewerbungsgespräche vorbereiten.
Starte noch heute mit Data Engineering!
Lernpfad
Kurs
Kurs
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
4 Min.
Tutorial
Sejal Jaiswal
Tutorial
Javier Canales Luna
Tutorial
Matt Crabtree

