Tracks
アソシエイトデータエンジニア SQLで
30時間
従来型のデータウェアハウスはオンプレミスに展開され、通常は高額な初期コスト、運用管理に長けたチーム、そして従来のデータセンターにおける硬直的なリソーススケーリングに起因する需要増への入念な計画が必要です。
一方、クラウド・データウェアハウスはクラウドサービスプロバイダーによって管理・ホスティングされます。例として、Google BigQuery、Amazon Redshift、Snowflakeがあります。
一般に、クラウド・データウェアハウスには従来型に比べて次のような利点があります。
行指向データベースの例:

列指向データベースの例:
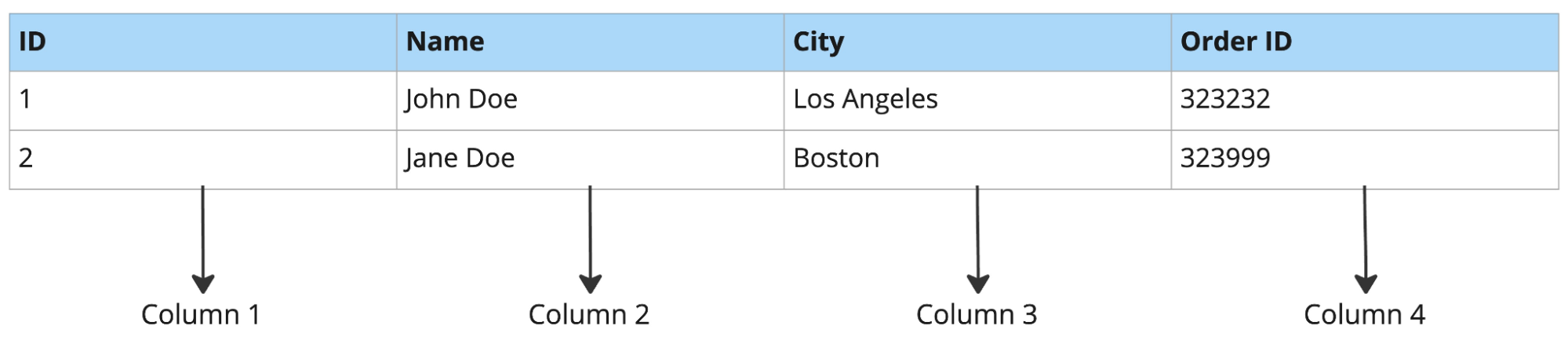
行指向データベースは、行全体のルックアップ、レコードの挿入、更新といった操作に適していますが、分析ワークロードは不得手です。
たとえば、50列のテーブルから3列だけを取得する場合でも、行指向データベースは各行について50列すべてを読み込みます。列指向データベースであれば必要な3列だけを読み込むため、製品の需要予測やアドホックなレポーティングなどの分析ではるかに高速です。
行指向データベースは一般にオンライン・トランザクション処理(OLTP)に適し、列指向データベースはオンライン分析処理(OLAP)に適しています。
比較のまとめ:
|
行指向データベース |
列指向データベース |
||||||
|
ストレージ |
行単位 |
列単位 |
|||||
|
データ取得 |
レコード全体 |
関連する列 |
|||||
|
典型的な用途 |
OLTP |
OLAP |
|||||
|
高速な操作 |
挿入、更新、ルックアップ |
レポート用途のクエリ |
|||||
|
データのロード |
通常は1レコードずつ |
通常はバッチで |
|||||
|
代表的な選択肢 |
Postgres、MySQL、Oracle、Microsoft SQL Server |
Snowflake、Google BigQuery、Amazon Redshift |
|||||
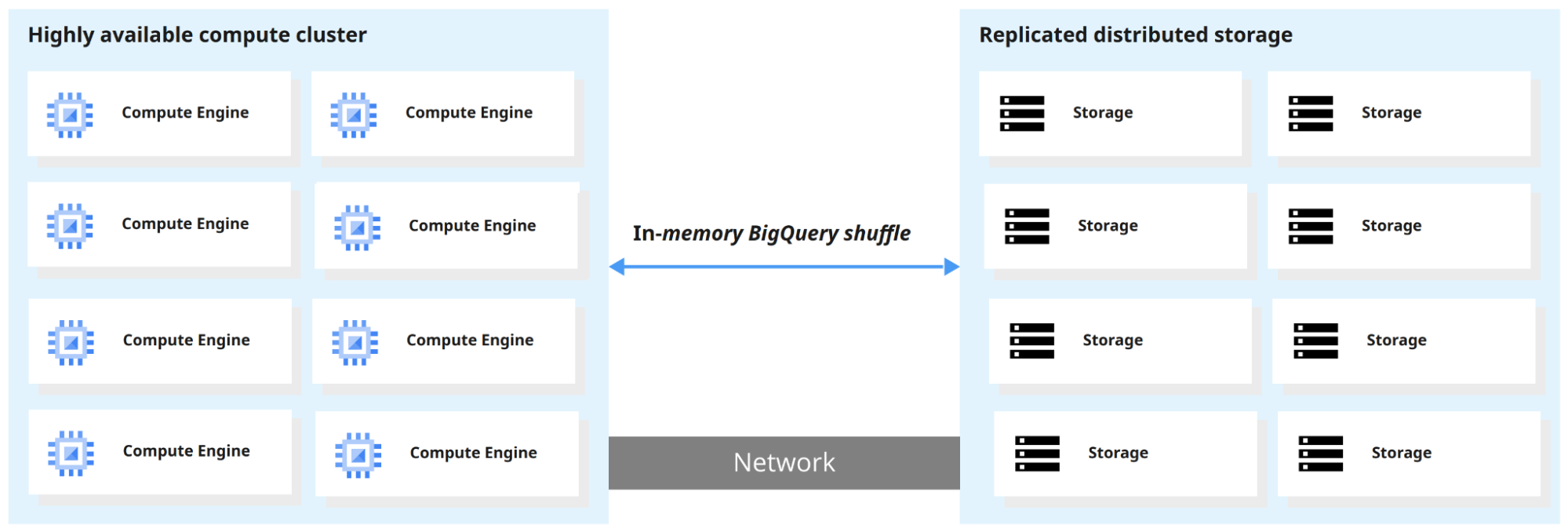
BigQueryはコンピュートエンジンとストレージを分離しており、それぞれを独立してスケールできます。結果として、テラバイト級のデータを数秒で、ペタバイト級のデータを数分でクエリできます。
BigQueryがクエリを実行すると、クエリエンジンが処理を並列に分散し、ストレージ内の該当テーブルをスキャンして結果をマージし、最終的なデータセットを返します。
BigQueryの登場以降、Googleは従来のデータウェアハウスの枠を超える多くの機能を追加してきました。
BigQueryサンドボックスを使えば、クレジットカードや請求アカウントを用意しなくてもBigQueryを試せます。ここでは、サンドボックスを使ってBigQueryへアクセスし、最初のプロジェクトを設定する手順を説明します。
BigQueryにはGoogle Cloud Consoleからアクセスできます。Googleアカウントでログイン(または作成)してください。ログインすると、ウェルカム画面が表示されます。
左側のメニューにBigQueryがあります。クリックすると次の画面に移動します。
BigQueryサンドボックスを利用するには、まず「Select Project」をクリックしてプロジェクトを作成します。
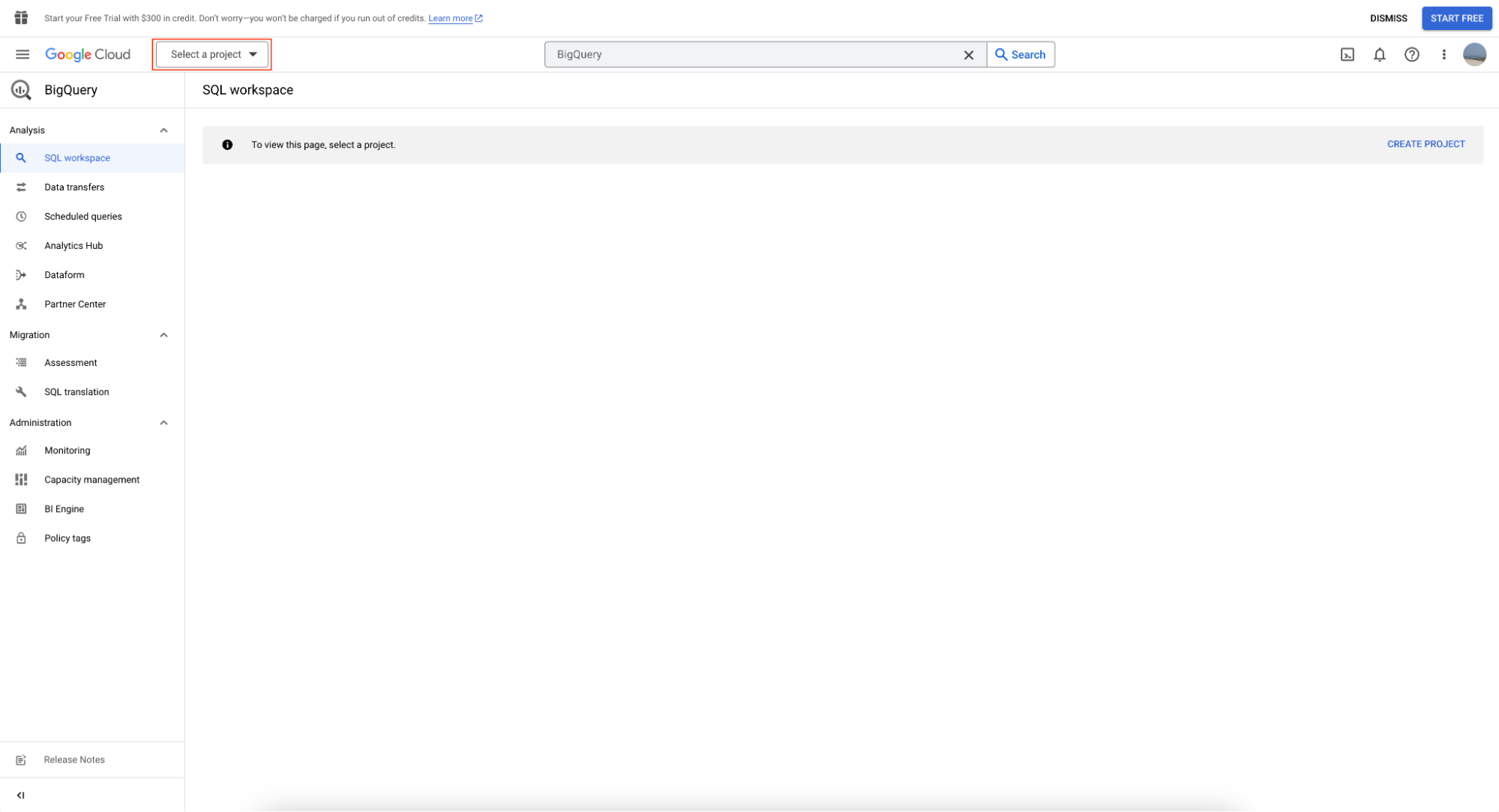
続いて「New Project」をクリックします。
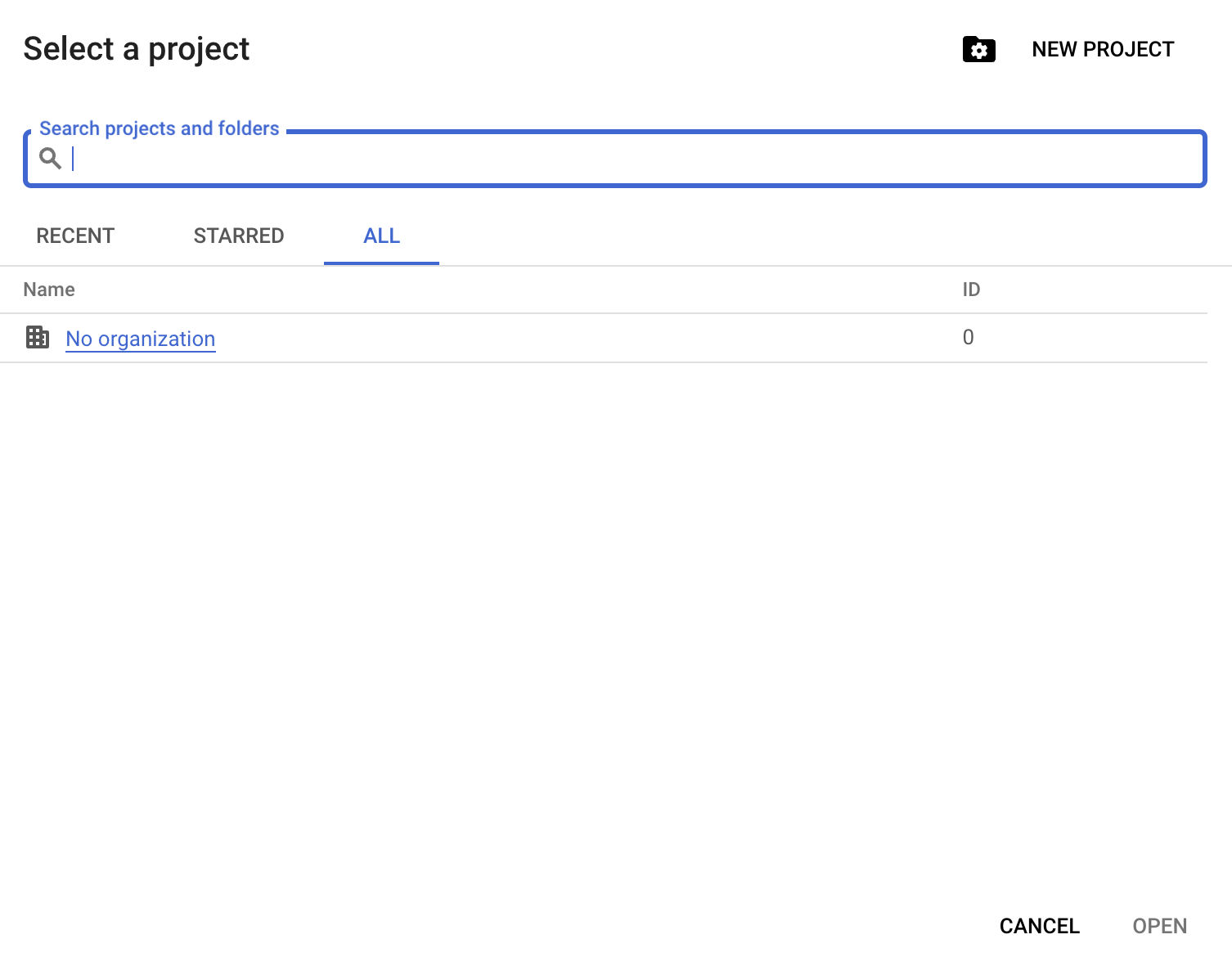
プロジェクト名を指定します。このガイドではdatacamp-guide-projectを使用します。

BigQueryのページにサンドボックスに関する案内が表示され、BigQueryサンドボックスが有効になったことを確認できます。

サンドボックスが有効になったら、新しいプロジェクトでデータの読み込みやクエリができるほか、Googleの公開データセットにもクエリできます。
テーブルを作成する前に、新しいプロジェクトにデータセットを作成する必要があります。データセットは、テーブルやビューの集合を整理しアクセス制御するための最上位コンテナです。作成するには、プロジェクトの「Actions」アイコンをクリックします。
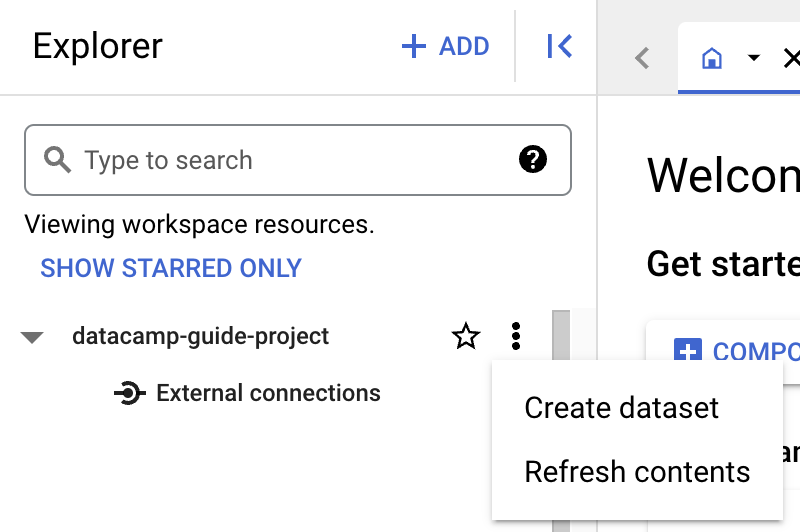
このガイドでは「Dataset ID」に「main」と入力します。
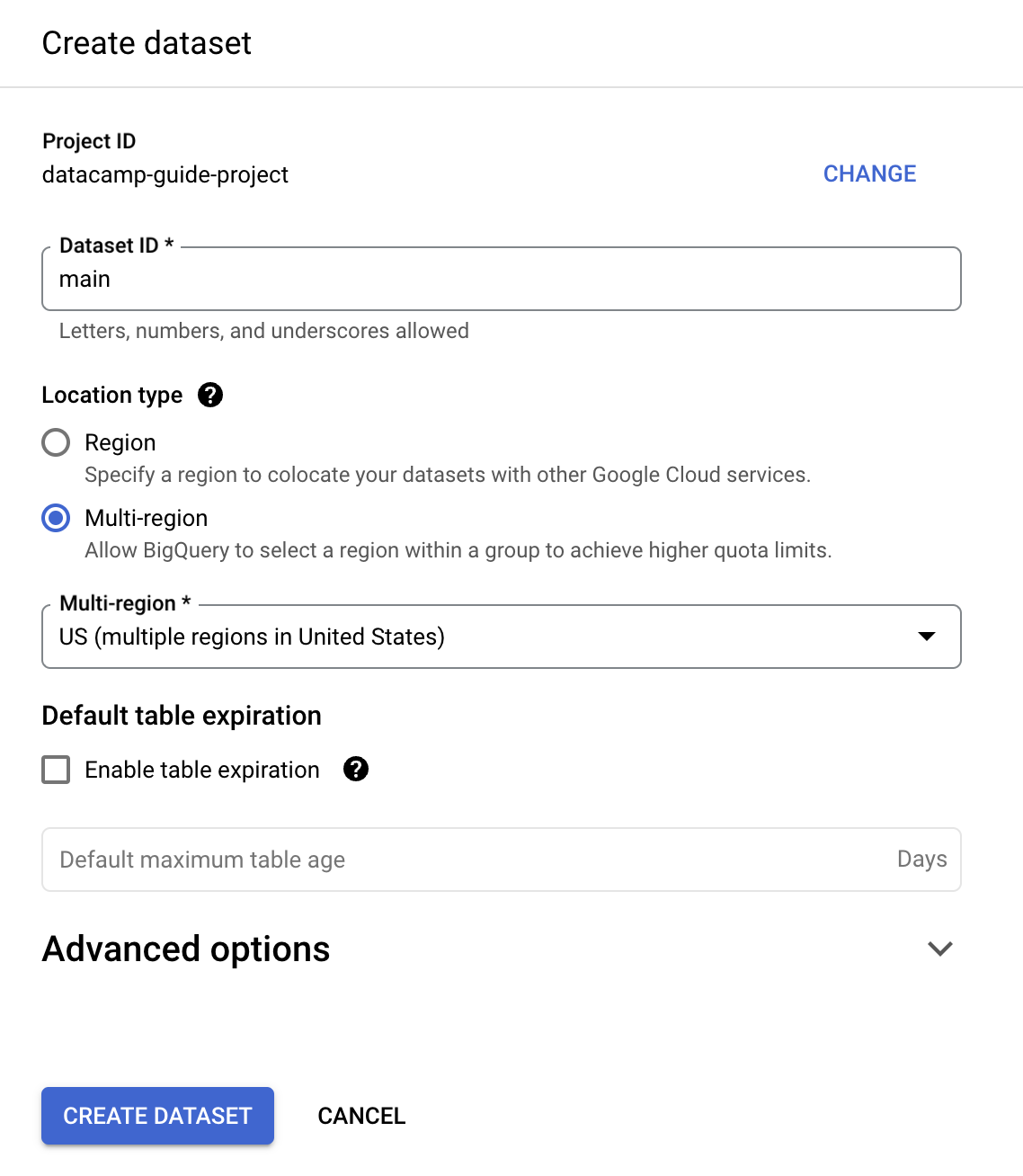
テーブルはSQLで作成できます。BigQueryはANSI準拠のGoogleSQLを使用します。
CREATE TABLE datacamp-guide-project.main.users (
id INT64 NOT NULL,
first_name STRING NOT NULL,
middle_name STRING,
last_name STRING NOT NULL,
active_account BOOL NOT NULL
);BigQueryコンソールのインターフェースから作成することも可能です。
注意:サンドボックス環境ではデータの挿入はできません。挿入を試す場合は無料トライアルを有効化してください。次のセクションでは、Google Cloudの一部として提供される公開データセットへのクエリに焦点を当てます。
公開データセットにクエリするには、以下の手順に従ってください。
1. Explorerの横にある「Add」をクリックします。

2. データセットを選択します。
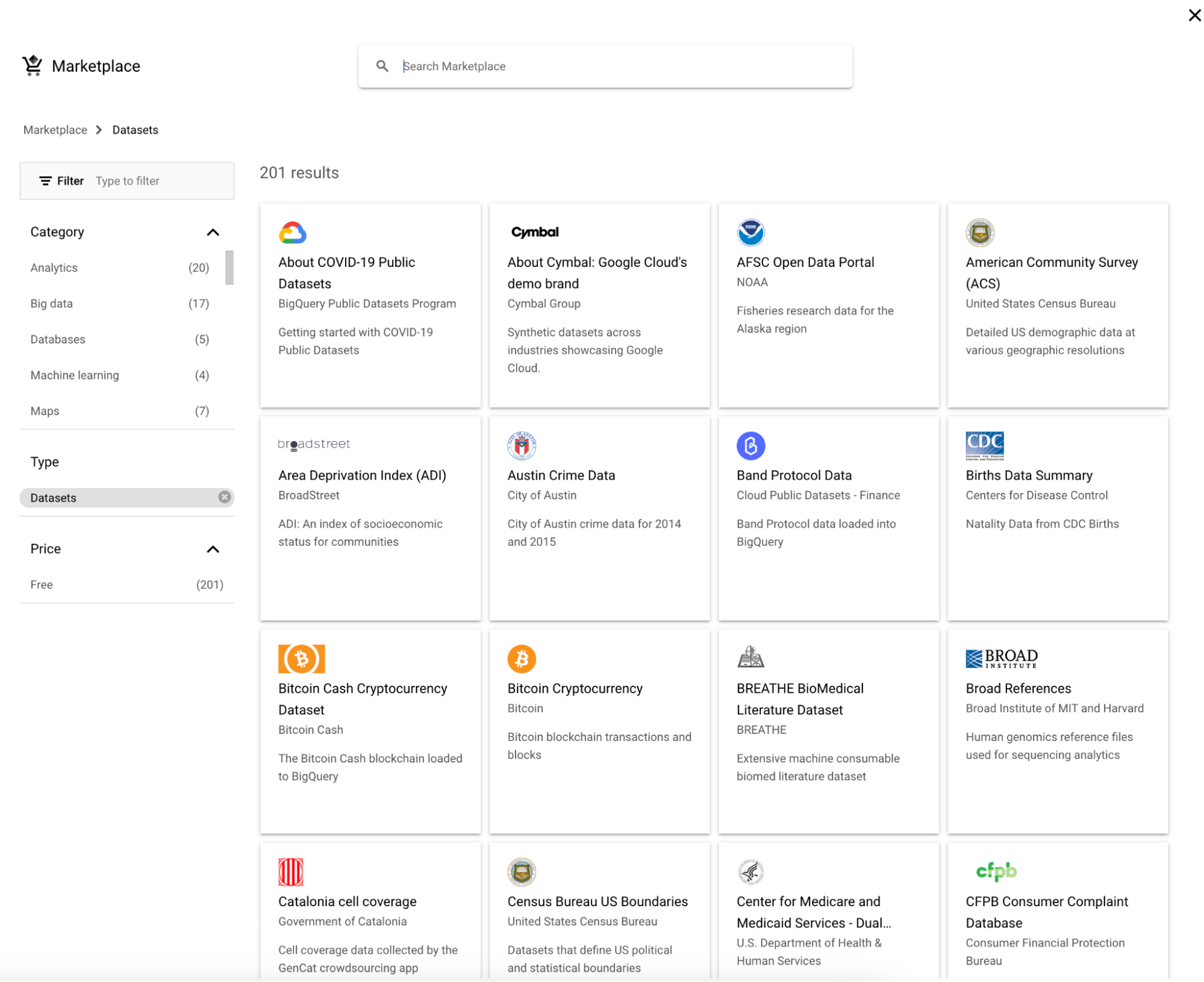
3. 「Google Trends」を検索し、Google Trendsを選択して「View dataset」ボタンをクリックします。

4. bigquery-public-dataに、多数のデータセットが一覧表示されます。bigquery-public-dataにスターを付け、Explorerで常に表示されるようにします。
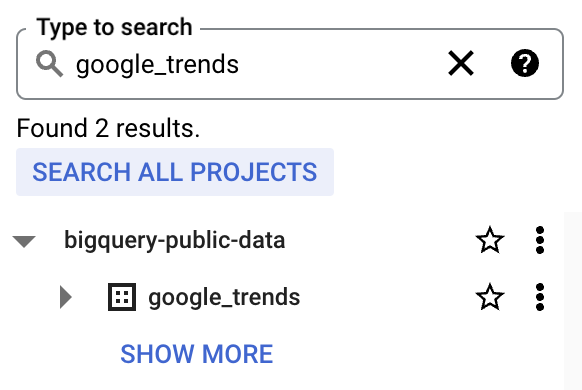
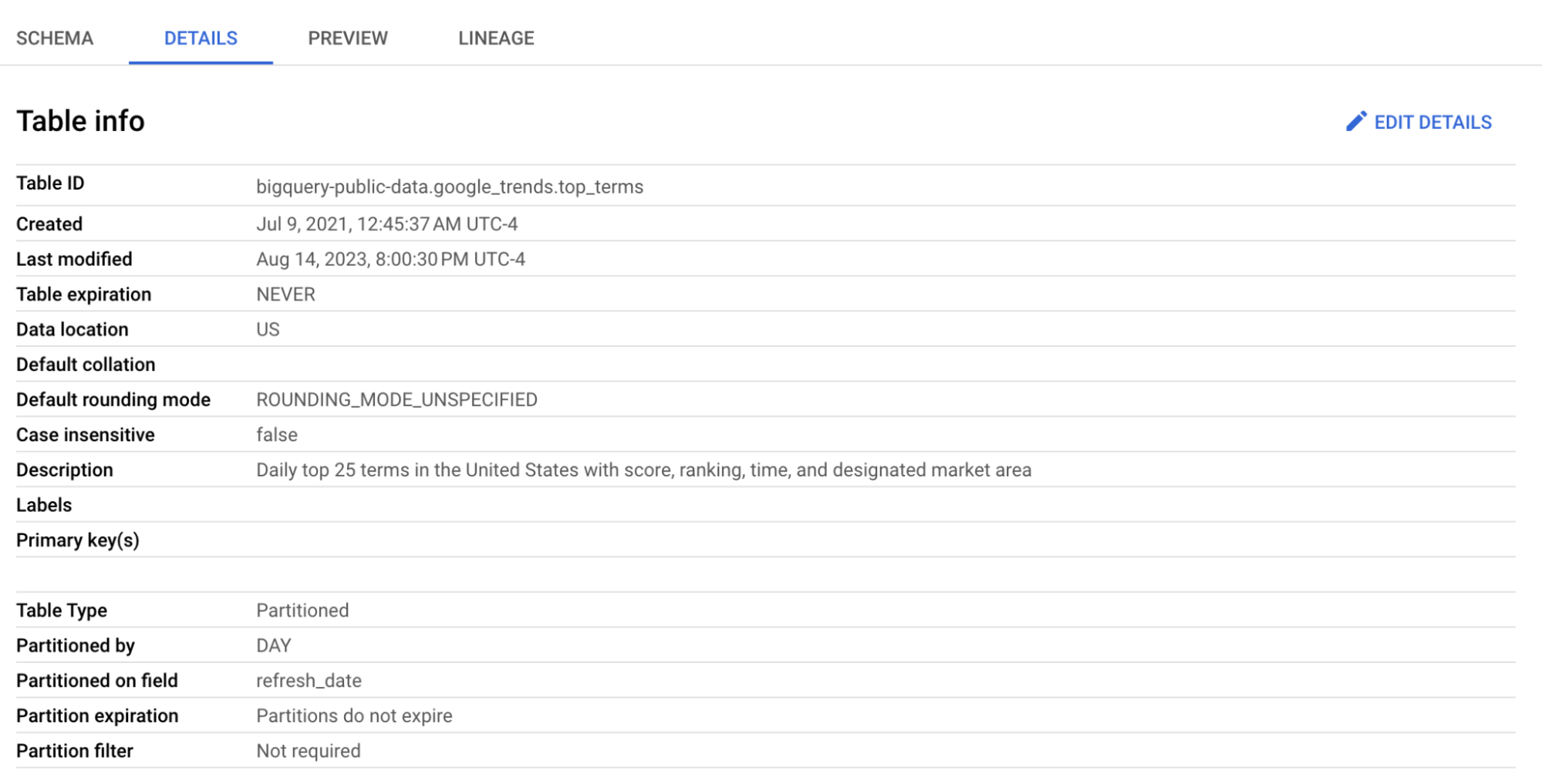
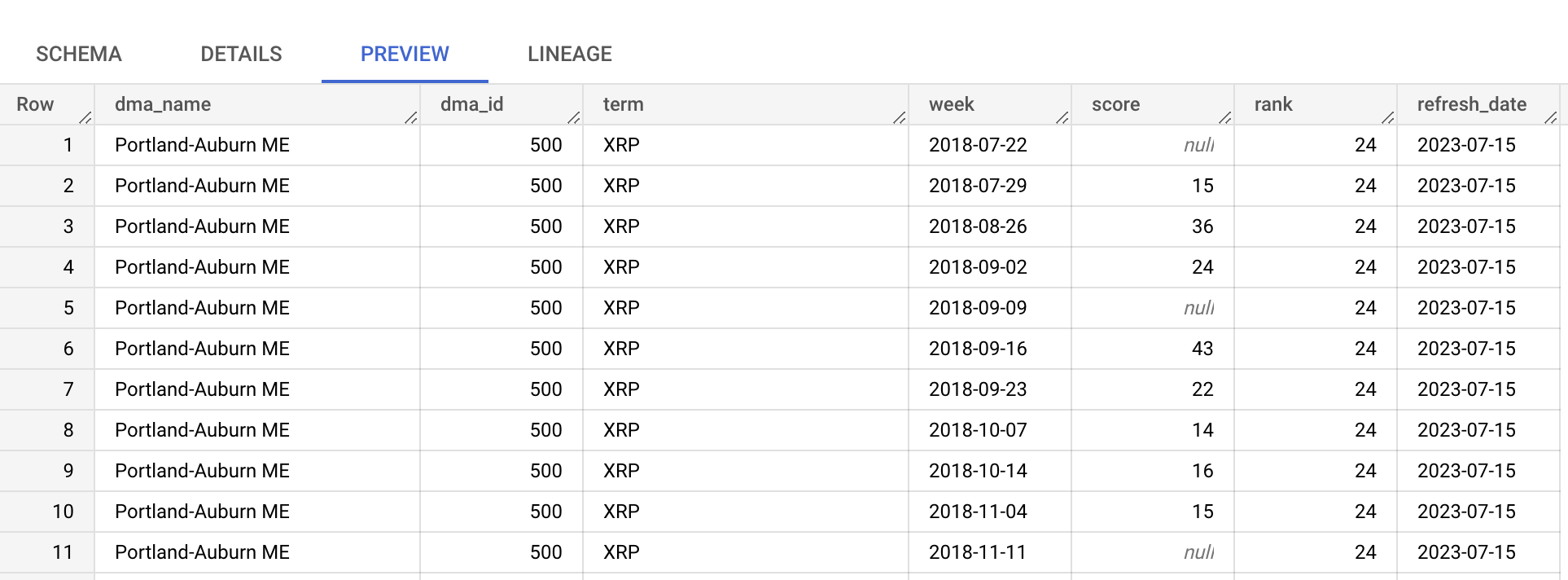
ここではtop_termsテーブルを使用します。

top_termsテーブルをクリックして開き、DetailsとPreviewタブを確認してtop_termsのデータについて理解を深めましょう。
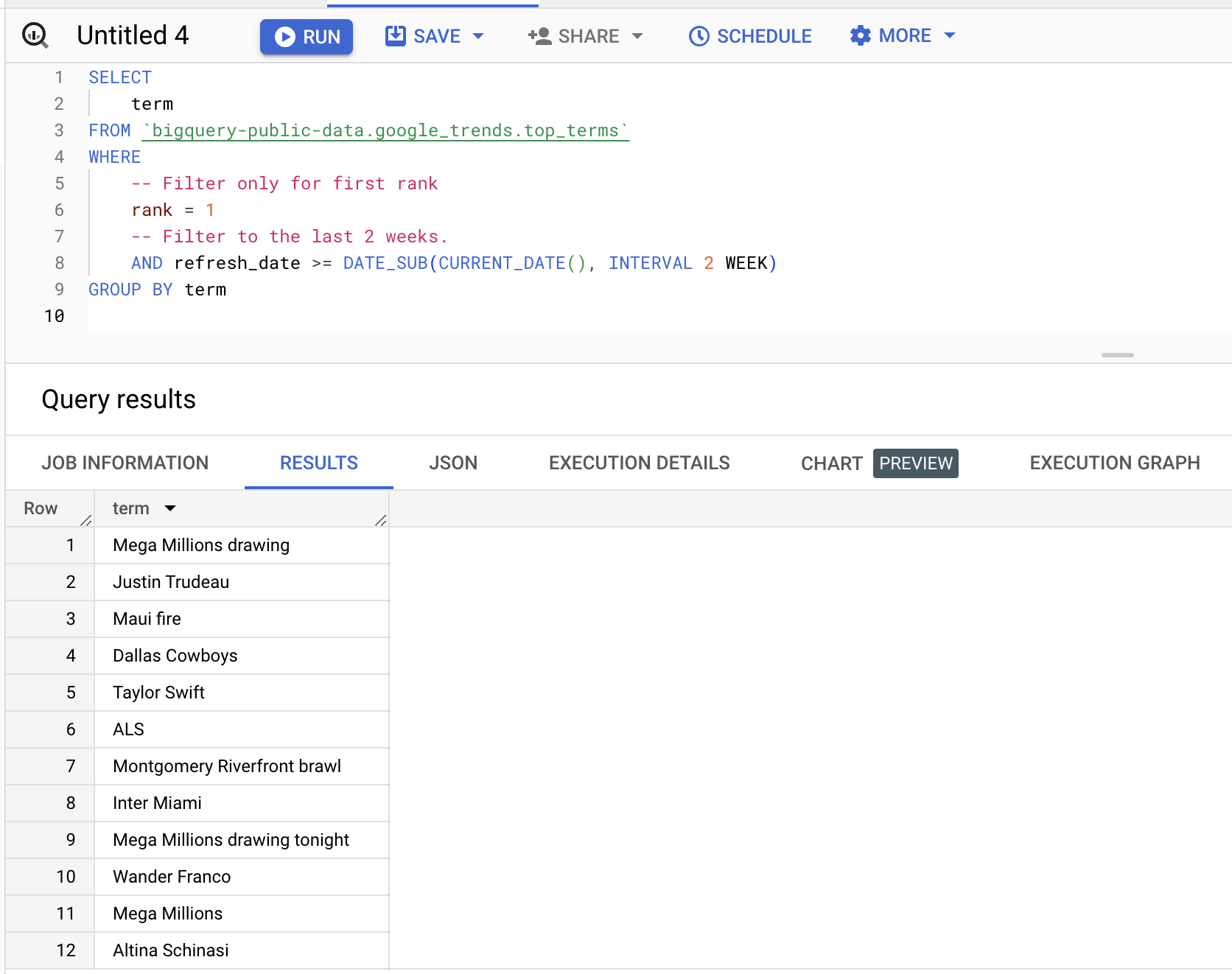
次の例のように、直近2週間で1位にランクインした用語を取得するクエリを実行できます。
SELECT
term
FROM
bigquery-public-data.google_trends.top_terms
WHERE
rank = 1
AND refresh_date >= DATE_SUB(CURRENT_DATE(), INTERVAL 2 WEEK)
GROUP BY
term結果(内容は変動します):
BigQueryの料金は大きく2つの要素で構成されます。コンピュート(クエリ処理)とストレージです。
| コンポーネント | 無料枠 | 有料料金 |
|---|---|---|
| オンデマンドクエリ | 月あたり1 TiB | TiBあたり$6.25 |
| ストレージ(アクティブ) | 10 GiB | GiB/月あたり$0.02 |
| ストレージ(長期) | 10 GiB | GiB/月あたり$0.01 |
| ストリーミング挿入 | N/A | 200 MBあたり$0.05 |
ワークロードが予測可能なチーム向けに、BigQueryはキャパシティ予約(BigQuery Editions)による定額課金も提供しています。最新の料金は公式の料金ページを確認してください。
BigQueryは、クラウド・データウェアハウスへの最もアクセスしやすい入り口の一つです。サンドボックスによりリスクなく試せ、月1 TiBの無料クエリ枠で公開データセットをコストゼロで探索できます。さらに必要になった場合は、Google Cloudの無料トライアルで$300分のクレジットが提供されます。
ここで学んだ内容をさらに発展させたい場合は、DataCampのIntroduction to BigQueryコースがおすすめです。クエリ最適化や大規模データセットの扱いを取り上げています。より広いデータエンジニアリングの観点では、Data Engineer in Pythonトラックで、データの取り込みからウェアハウジングまでの全体像を学べます。
また、BigQueryとRedshiftの比較、BigQueryとSnowflakeの比較、面接対策としてBigQueryの面接質問ガイドも参考にしてください。
今日からデータエンジニアリングを始めよう!
Tracks
Courses
Courses