
programa
Ingeniero de Datos Asociado en SQL
30 h
Un data warehouse tradicional se despliega on‑premise, normalmente con altos costes iniciales, un equipo experto para gestionarlo y una planificación rigurosa para crecer con la demanda debido a la rigidez al escalar recursos en centros de datos tradicionales.
Un data warehouse en la nube, en cambio, lo gestiona y aloja un proveedor de servicios cloud. Algunos ejemplos son Google BigQuery, Amazon Redshift y Snowflake.
Por lo general, un data warehouse en la nube ofrece varias ventajas frente a los tradicionales:
Ejemplo de base de datos orientada a filas:

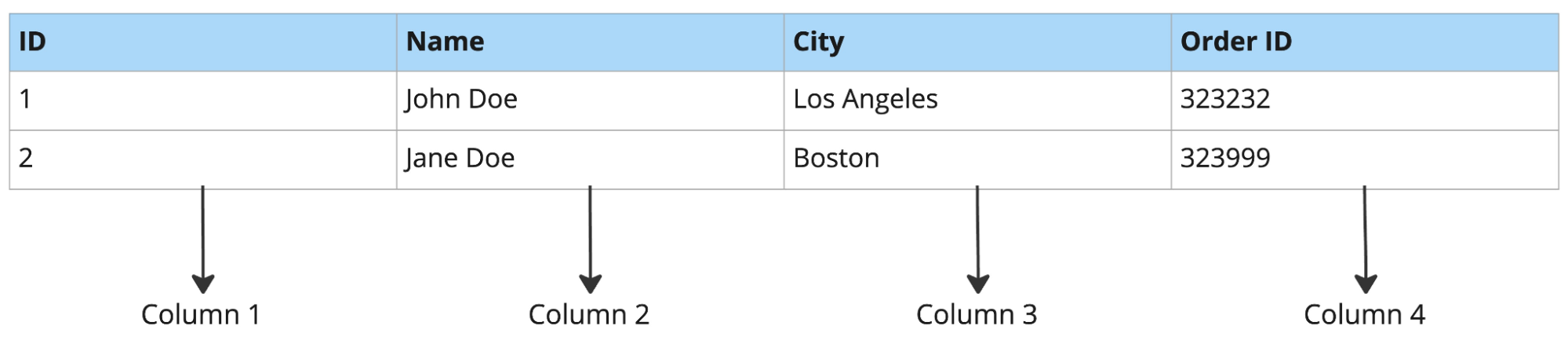
Ejemplo de base de datos orientada a columnas:
Las bases de datos orientadas a filas funcionan muy bien para búsquedas de filas completas, inserciones y actualizaciones. Pero se resienten con cargas analíticas.
Por ejemplo, si consultas tres columnas de una tabla con 50, una base de datos orientada a filas sigue leyendo las 50 columnas de cada fila. Una base orientada a columnas lee solo las tres que necesitas, lo que es mucho más rápido para analítica como previsión de productos o reporting ad‑hoc.
Las bases orientadas a filas suelen ser adecuadas para el procesamiento de transacciones en línea (OLTP) y las orientadas a columnas para el procesamiento analítico en línea (OLAP).
Resumen de la comparación:
|
Base orientada a filas |
Base orientada a columnas |
||||||
|
Almacenamiento |
Por fila |
Por columna |
|||||
|
Recuperación de datos |
Registros completos |
Columnas relevantes |
|||||
|
Aplicación típica |
OLTP |
OLAP |
|||||
|
Operaciones rápidas |
Inserciones, actualizaciones, búsquedas |
Consultas para reporting |
|||||
|
Carga de datos |
Normalmente registro a registro |
Normalmente por lotes |
|||||
|
Opciones populares |
Postgres, MySQL, Oracle, Microsoft SQL Server |
Snowflake, Google BigQuery, Amazon Redshift |
|||||
BigQuery separa el motor de cómputo del almacenamiento, de modo que cada uno puede escalar por separado. Resultado: puedes consultar terabytes en segundos y petabytes en minutos.
Cuando BigQuery ejecuta una consulta, el motor distribuye el trabajo en paralelo, escanea las tablas relevantes en almacenamiento, combina los resultados y devuelve el conjunto final de datos.
Desde su lanzamiento, Google ha añadido varias funciones que llevan BigQuery más allá de un data warehouse tradicional:
El sandbox de BigQuery te permite probar BigQuery sin tarjeta de crédito ni cuenta de facturación. En esta sección te explico cómo acceder a BigQuery y configurar tu primer proyecto usando el sandbox.
Puedes acceder a BigQuery desde la Google Cloud Console. Tendrás que iniciar sesión con una cuenta de Google (o crear una). Una vez dentro, verás una pantalla de bienvenida:
Encontrarás BigQuery en el menú de la izquierda. Al hacer clic, irás a la siguiente pantalla:
Para usar el sandbox de BigQuery, primero crea un proyecto haciendo clic en «Select Project».
Después, haz clic en «New Project»:
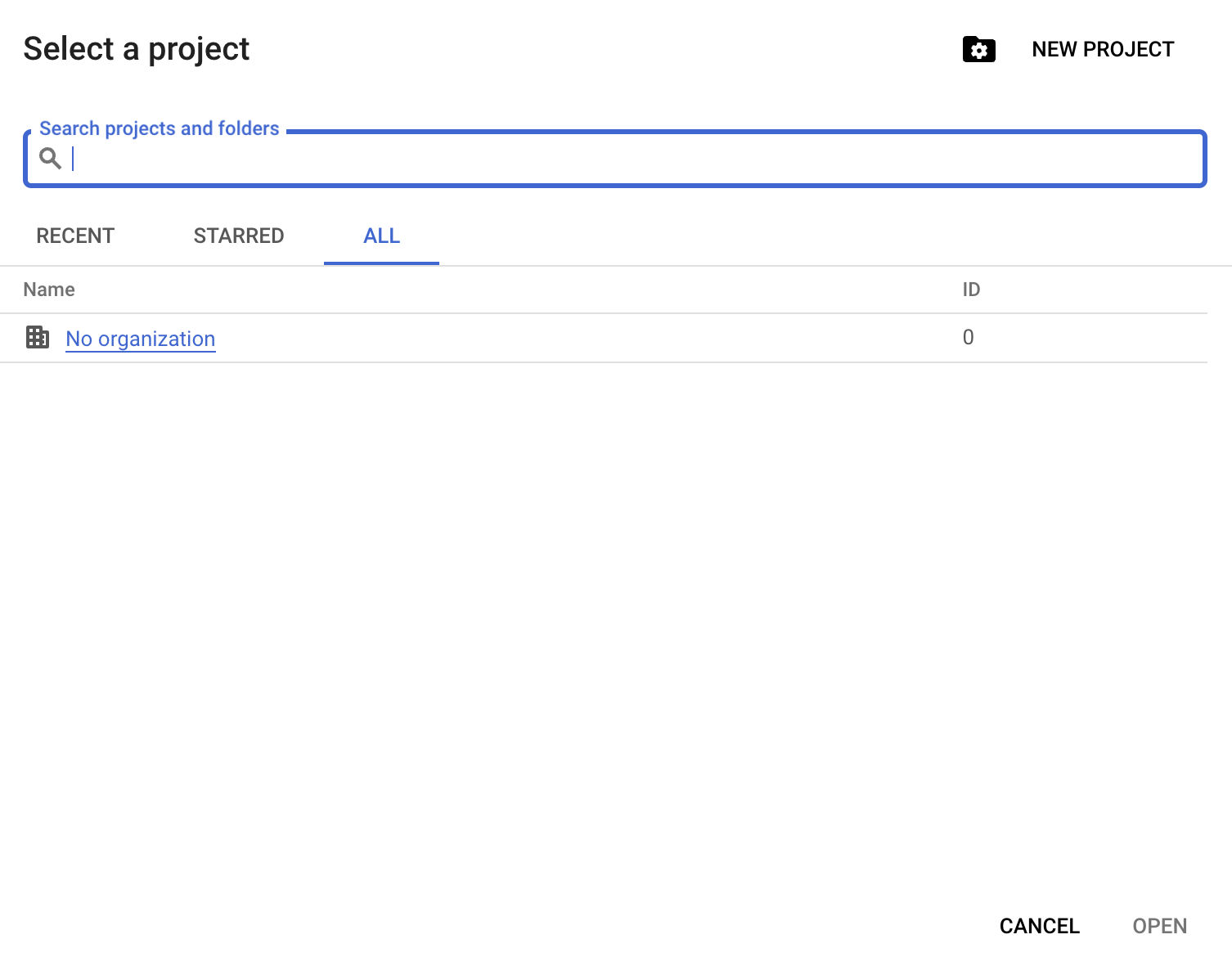
Tendrás que indicar un nombre de proyecto; para esta guía usamos datacamp-guide-project

Ahora verás un aviso del sandbox en la página de BigQuery que confirma que has activado correctamente el sandbox de BigQuery.

Con el sandbox de BigQuery activado, ya puedes usar tu nuevo proyecto para cargar y consultar datos, así como para consultar datasets públicos de Google.
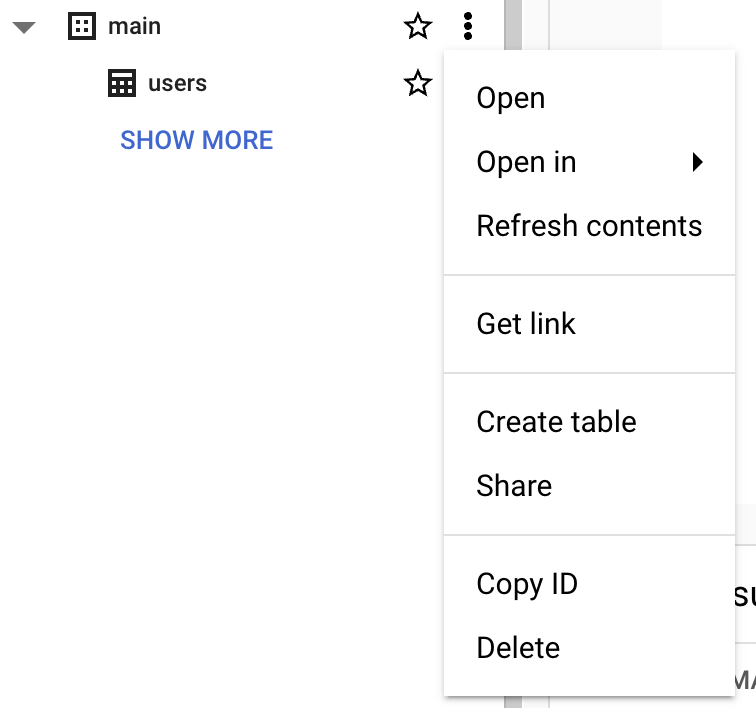
Antes de crear una tabla, necesitas crear un dataset en tu nuevo proyecto. Un dataset es un contenedor de nivel superior que se usa para organizar y controlar el acceso a un conjunto de tablas y vistas. Para crearlo, haz clic en el icono «Actions» del proyecto:
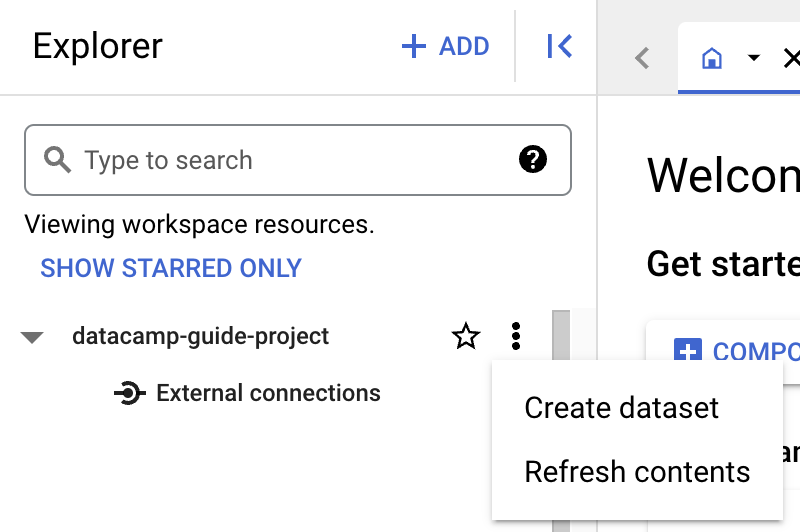
Para esta guía, rellenaremos «Dataset ID» con «main».
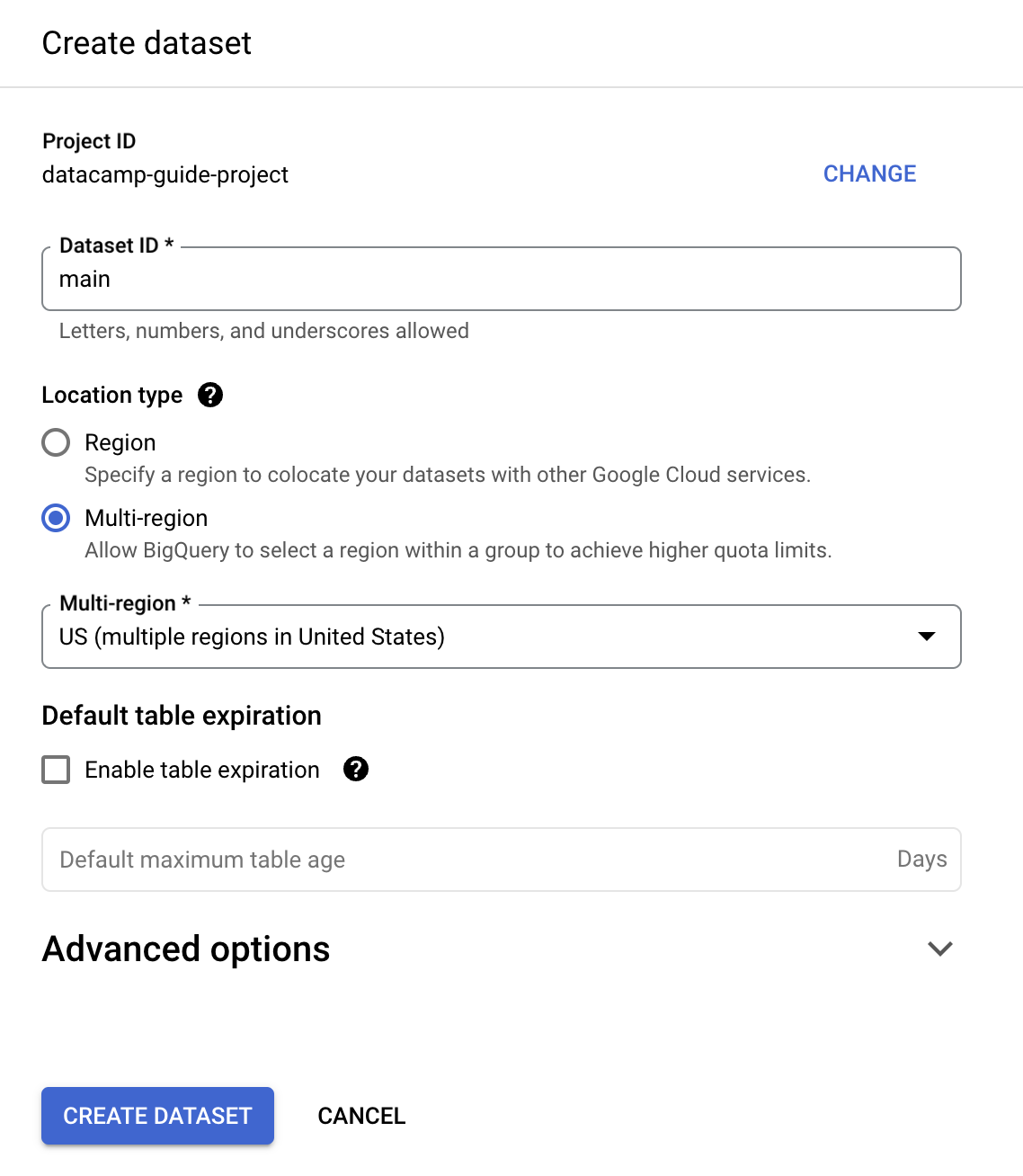
Puedes crear una tabla con SQL. BigQuery usa GoogleSQL, compatible con ANSI.
CREATE TABLE datacamp-guide-project.main.users (
id INT64 NOT NULL,
first_name STRING NOT NULL,
middle_name STRING,
last_name STRING NOT NULL,
active_account BOOL NOT NULL
);También puedes usar la interfaz de la consola de BigQuery:
Nota: No es posible insertar datos en el entorno de sandbox. Si quieres probar inserciones, debes activar la prueba gratuita. Las siguientes secciones se centran en consultar los datasets públicos que ofrece Google Cloud.
Para consultar un dataset público, sigue estos pasos:
1. Haz clic en «Add» junto a Explorer.

2. Luego, elige un dataset.
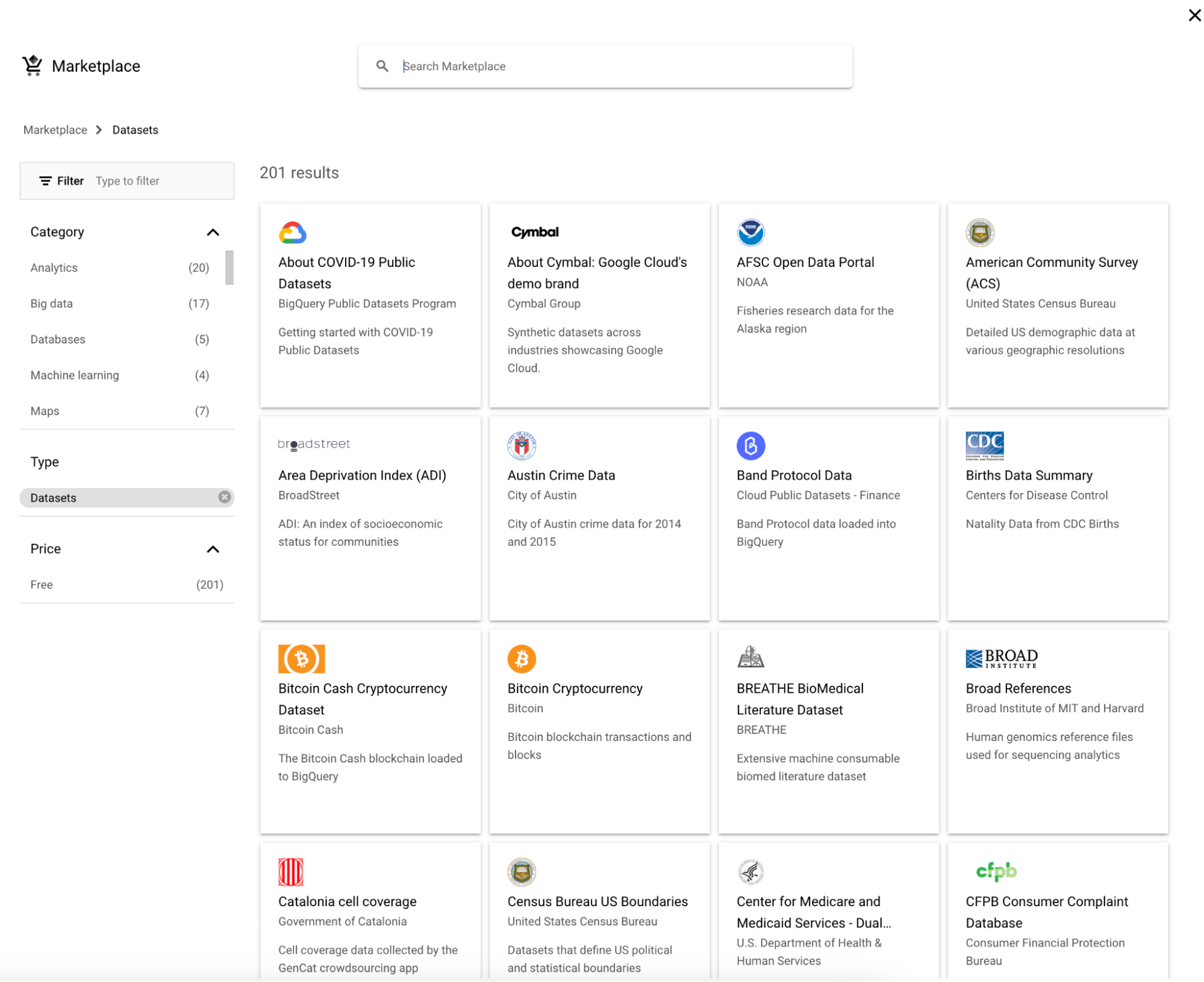
3. Busca «Google Trends» y elige Google Trends, y luego haz clic en el botón «View dataset».

4. bigquery-public-data aparecerá con una larga lista de datasets. Pon una estrella a bigquery-public-data para que quede «fijo» en el explorador
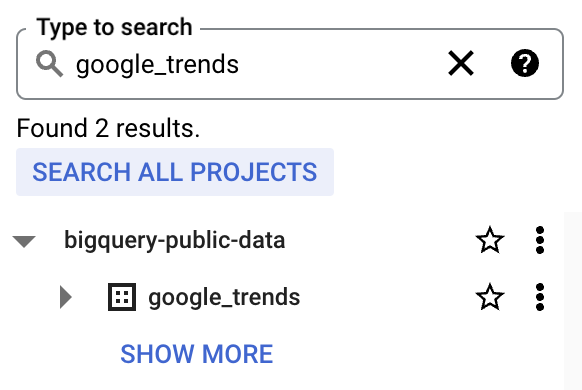
Usaremos la tabla top_terms:

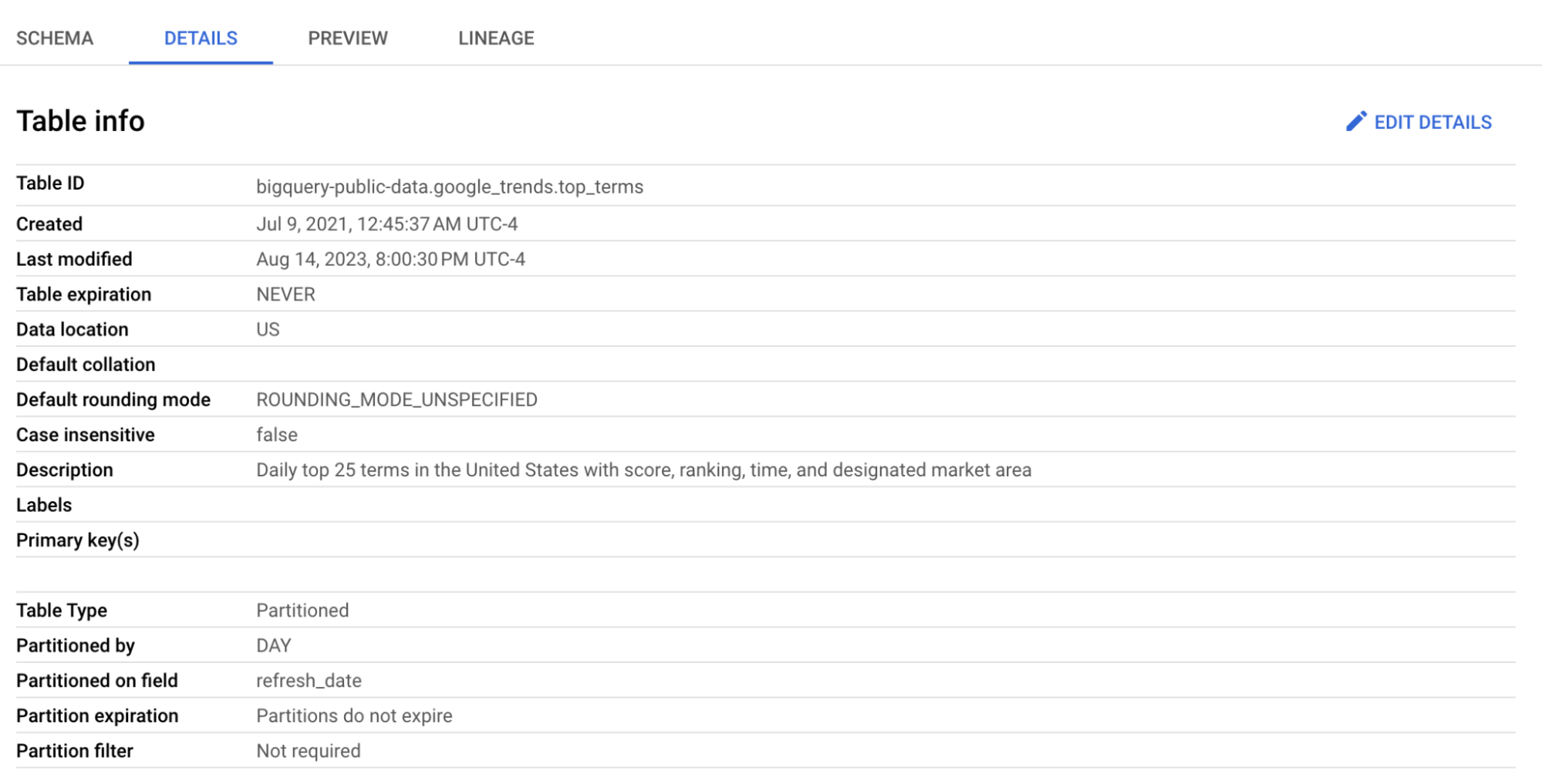
Haz clic en la tabla top_terms para abrirla y revisa las pestañas Details y Preview para conocer mejor los datos de top_terms.
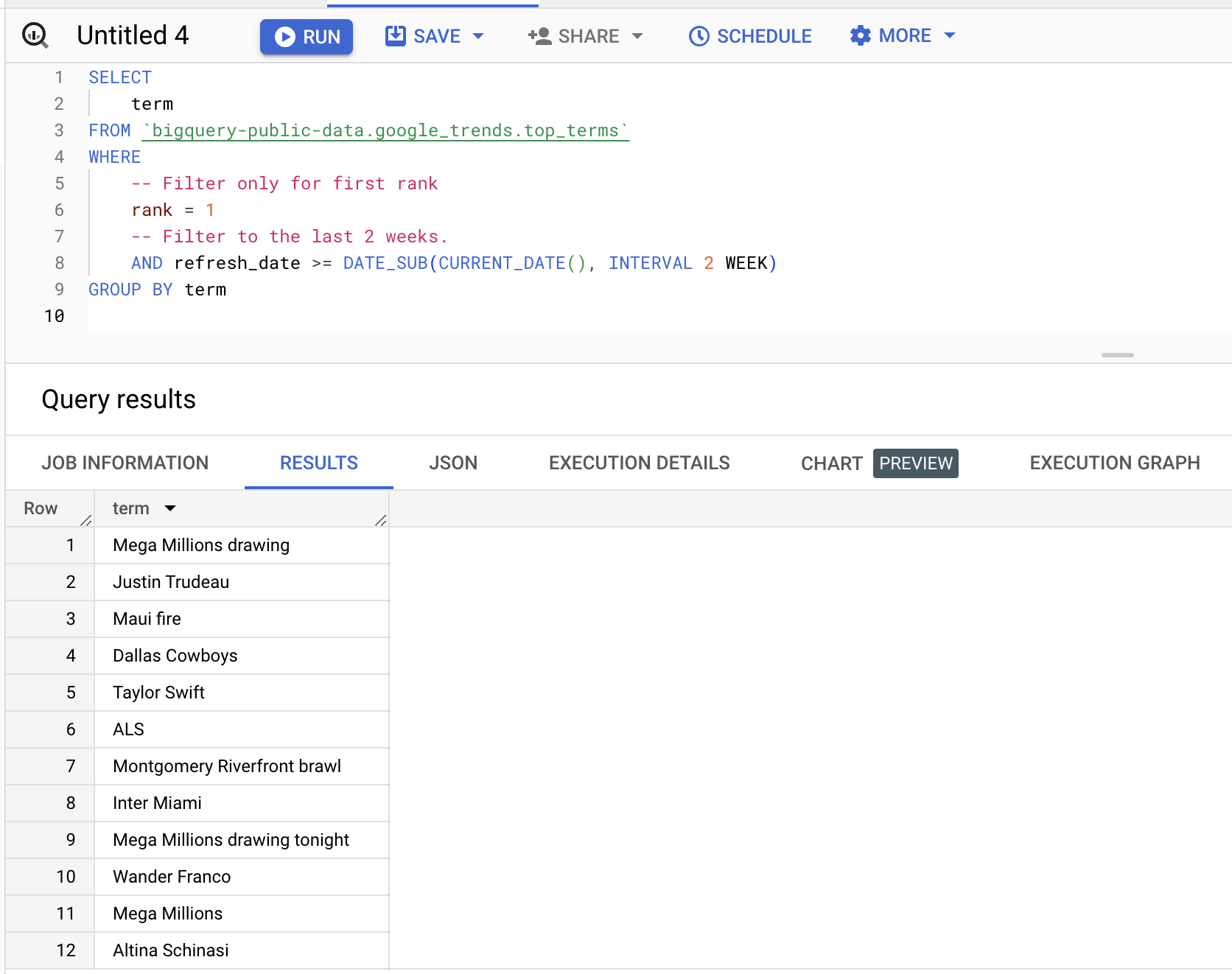
Puedes consultar el dataset; por ejemplo, para obtener los términos que han ocupado la primera posición en las dos últimas semanas:
SELECT
term
FROM
bigquery-public-data.google_trends.top_terms
WHERE
rank = 1
AND refresh_date >= DATE_SUB(CURRENT_DATE(), INTERVAL 2 WEEK)
GROUP BY
termResultados (variarán):
La tarificación de BigQuery tiene dos componentes principales: cómputo (procesamiento de consultas) y almacenamiento.
| Componente | Gratuito | Precio |
|---|---|---|
| Consultas bajo demanda | 1 TiB al mes | 6,25 $ por TiB |
| Almacenamiento (activo) | 10 GiB | 0,02 $ por GiB/mes |
| Almacenamiento (a largo plazo) | 10 GiB | 0,01 $ por GiB/mes |
| Inserciones en streaming | N/D | 0,05 $ por 200 MB |
Para equipos con cargas de trabajo predecibles, BigQuery también ofrece precio fijo mediante reservas de capacidad (BigQuery Editions). Consulta la página oficial de precios para ver las tarifas actuales.
BigQuery es una de las puertas de entrada más accesibles al data warehousing en la nube. El sandbox te da un entorno sin riesgo para experimentar, y el 1 TiB de consultas gratuitas al mes te permite explorar datasets públicos sin gastar nada. Cuando necesites más, la prueba gratuita de Google Cloud incluye 300 $ en créditos.
Si quieres seguir aprendiendo, te recomiendo el curso Introduction to BigQuery en DataCamp, que cubre optimización de consultas y trabajo con datasets más grandes. Para una visión más amplia de data engineering, el itinerario Data Engineer in Python abarca todo el pipeline, desde la ingesta hasta el warehousing.
También puedes comparar BigQuery con alternativas en nuestras guías BigQuery vs Redshift y BigQuery vs Snowflake, o prepararte para entrevistas con nuestra guía de preguntas de entrevista sobre BigQuery.
¡Empieza hoy con data engineering!
programa
Curso
Curso
blog
Tim Lu
12 min
Tutorial
DataCamp Team
Tutorial
Joleen Bothma
Tutorial
Tim Lu
Tutorial
Sejal Jaiswal
Tutorial
Joleen Bothma