Track
एसोसिएट डेटा इंजीनियर में SQL
30 घंटा
एक पारंपरिक डेटा वेयरहाउस ऑन-प्रिमाइसेज़ डिप्लॉय होता है, जिसमें आमतौर पर भारी प्रारंभिक लागत, उसे मैनेज करने के लिए कुशल टीम, और पारंपरिक डेटा सेंटर की कठोर संसाधन स्केलिंग के कारण बढ़ती मांग को पूरा करने के लिए उचित योजना की जरूरत होती है।
इसके विपरीत, क्लाउड डेटा वेयरहाउस क्लाउड सेवा प्रदाता द्वारा होस्ट और प्रबंधित किया जाता है। उदाहरणों में Google BigQuery, Amazon Redshift, और Snowflake शामिल हैं।
आमतौर पर, क्लाउड डेटा वेयरहाउस के पारंपरिक विकल्पों पर कई फायदे होते हैं:
रो-ओरिएंटेड डेटाबेस का उदाहरण:

कॉलम-ओरिएंटेड डेटाबेस का उदाहरण:
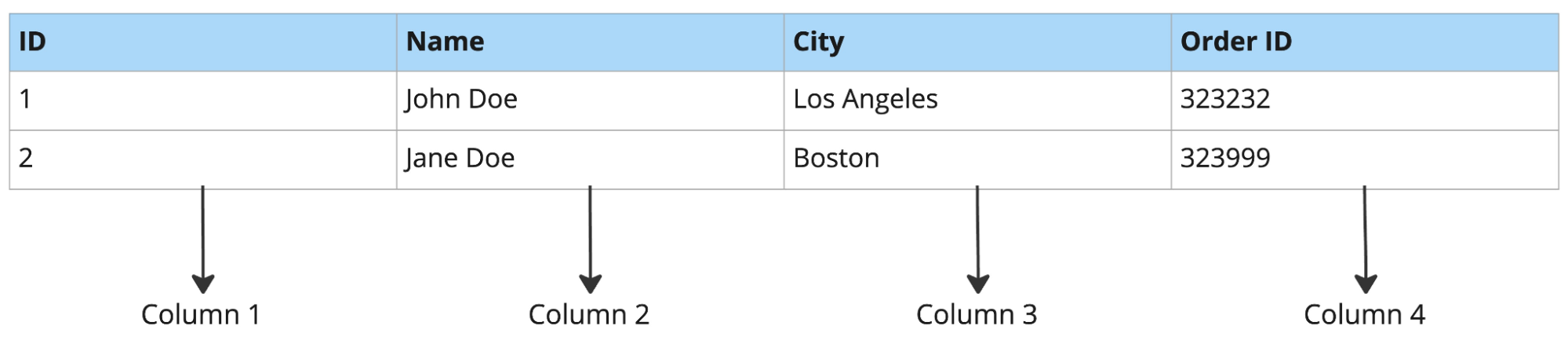
रो-ओरिएंटेड डेटाबेस पूर्ण पंक्ति लुकअप, रिकॉर्ड इंसर्शन और अपडेट के लिए अच्छा काम करते हैं। लेकिन वे विश्लेषणात्मक वर्कलोड में संघर्ष करते हैं।
उदाहरण के लिए, यदि आप 50-कालम की टेबल से तीन कॉलम क्वेरी करते हैं, तो रो-ओरिएंटेड डेटाबेस हर रो के सभी 50 कॉलम पढ़ता है। कॉलम-ओरिएंटेड डेटाबेस केवल वही तीन कॉलम पढ़ता है जिनकी आपको जरूरत है, जो प्रोडक्ट फ़ोरकास्टिंग या ऐड-हॉक रिपोर्टिंग जैसी एनालिटिक्स के लिए कहीं तेज़ है।
रो-ओरिएंटेड डेटाबेस आमतौर पर ऑनलाइन ट्रांजैक्शन प्रोसेसिंग (OLTP) के लिए उपयुक्त होते हैं, जबकि कॉलम-ओरिएंटेड डेटाबेस ऑनलाइन एनालिटिकल प्रोसेसिंग (OLAP) के लिए।
तुलना का सारांश:
|
रो-ओरिएंटेड डेटाबेस |
कॉलम-ओरिएंटेड डेटाबेस |
||||||
|
स्टोरेज |
रो के हिसाब से |
कॉलम के हिसाब से |
|||||
|
डेटा पुनर्प्राप्ति |
पूर्ण रिकॉर्ड |
प्रासंगिक कॉलम |
|||||
|
सामान्य उपयोग |
OLTP |
OLAP |
|||||
|
तेज़ ऑपरेशन |
इंसर्शन, अपडेट, लुकअप |
रिपोर्टिंग हेतु क्वेरी |
|||||
|
डेटा लोड |
आमतौर पर एक बार में एक रिकॉर्ड |
आमतौर पर बैच में |
|||||
|
लोकप्रिय विकल्प |
Postgres, MySQL, Oracle, Microsoft SQL Server |
Snowflake, Google BigQuery, Amazon Redshift |
|||||
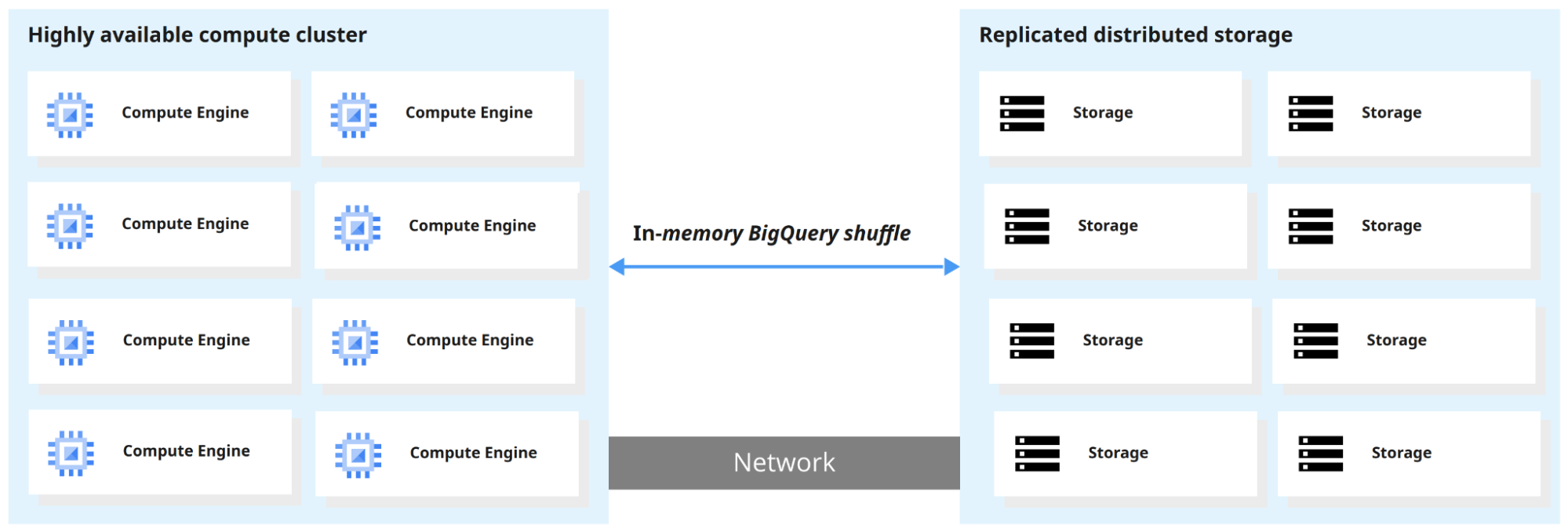
BigQuery अपने कंप्यूट इंजन को स्टोरेज से अलग करता है, ताकि दोनों स्वतंत्र रूप से स्केल हो सकें। नतीजा: आप कुछ सेकंड में टेराबाइट्स और कुछ मिनटों में पेटाबाइट्स डेटा पर क्वेरी चला सकते हैं।
जब BigQuery कोई क्वेरी चलाता है, तो क्वेरी इंजन काम को समानांतर में वितरित करता है, स्टोरेज में प्रासंगिक टेबल स्कैन करता है, परिणामों को मर्ज करता है और अंतिम डेटा सेट लौटाता है।
लॉन्च के बाद से, Google ने BigQuery में कई ऐसी सुविधाएँ जोड़ी हैं जो इसे पारंपरिक डेटा वेयरहाउस से आगे ले जाती हैं:
BigQuery सैंडबॉक्स आपको बिना क्रेडिट कार्ड दिए या बिलिंग अकाउंट बनाए BigQuery आज़माने देता है। इस सेक्शन में, मैं बताऊँगा कि BigQuery तक कैसे पहुँचा जाए और सैंडबॉक्स का उपयोग करके अपना पहला प्रोजेक्ट कैसे सेटअप किया जाए।
BigQuery तक आप Google Cloud Console के माध्यम से पहुँच सकते हैं। आपको किसी Google अकाउंट से लॉग इन करना होगा (या एक बनाना होगा)। लॉग इन होने पर एक वेलकम स्क्रीन दिखाई देगी:
आप BigQuery को बाएँ मेनू बार में पा सकते हैं। इस पर क्लिक करने से आप नीचे दिखाए गए स्क्रीन पर पहुँचेंगे:
BigQuery सैंडबॉक्स का उपयोग करने के लिए, पहले ‘Select Project’ पर क्लिक कर के एक प्रोजेक्ट बनाएँ।
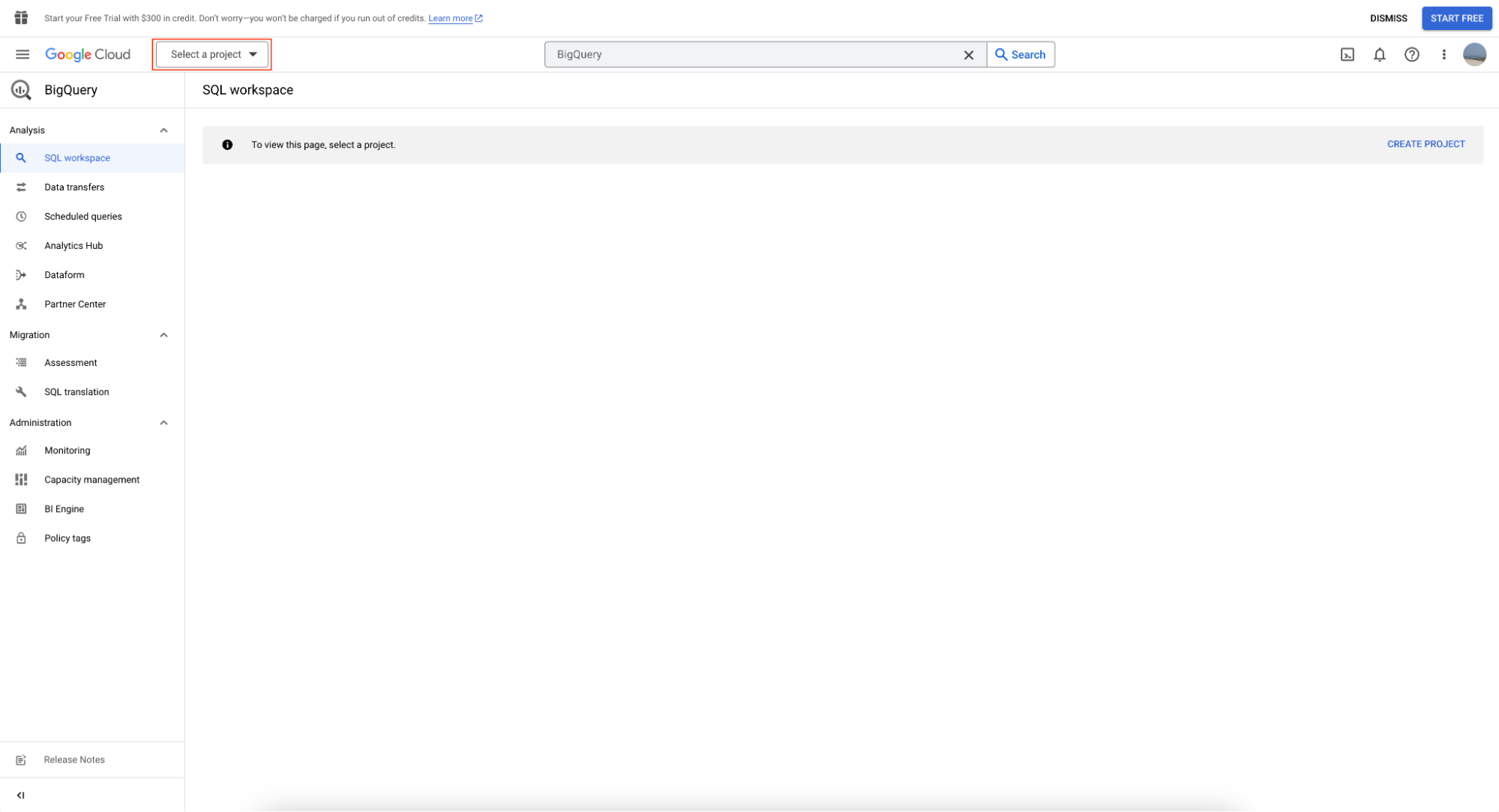
इसके बाद ‘New Project’ पर क्लिक करें:
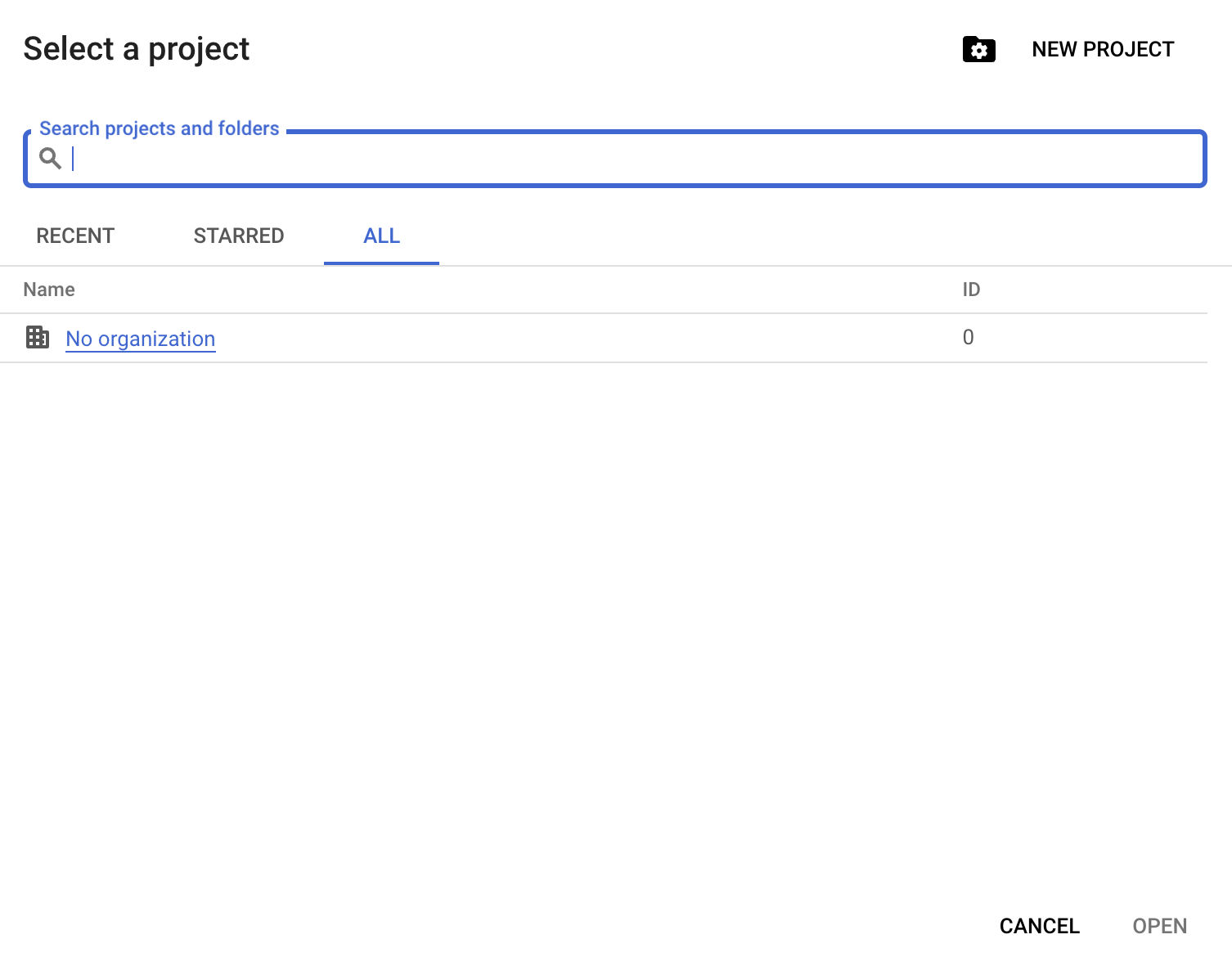
आपको एक प्रोजेक्ट नाम देना होगा; इस गाइड में हम datacamp-guide-project का उपयोग कर रहे हैं

अब BigQuery पेज पर सैंडबॉक्स नोटिस प्रदर्शित होगा, जो दिखाता है कि आपने सफलतापूर्वक BigQuery सैंडबॉक्स सक्षम कर दिया है।

BigQuery सैंडबॉक्स सक्षम होने के साथ, आप अपने नए प्रोजेक्ट का उपयोग डेटा लोड करने और क्वेरी चलाने के साथ-साथ Google के सार्वजनिक डेटासेट पर क्वेरी करने के लिए कर सकते हैं।
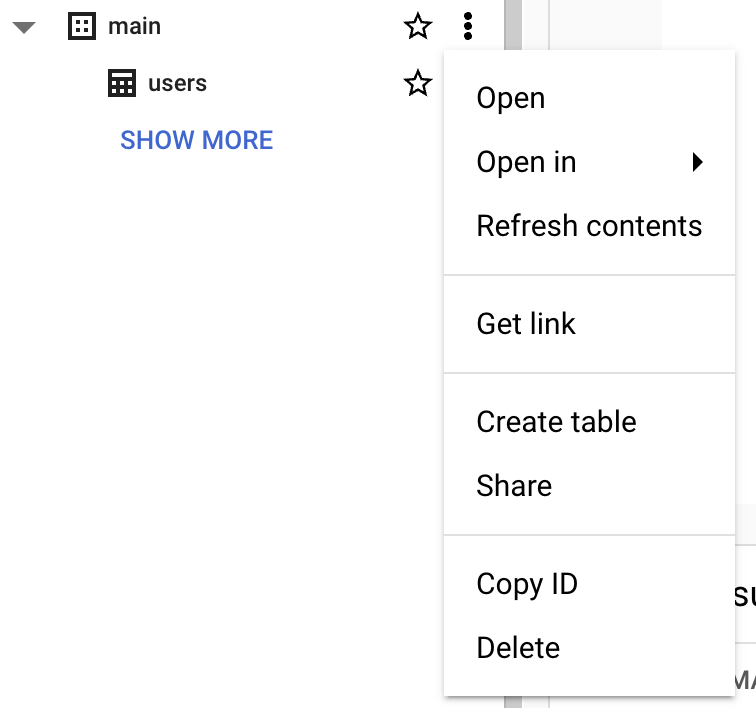
टेबल बनाने से पहले, आपको अपने नए प्रोजेक्ट में एक डेटासेट बनाना होगा। डेटासेट एक टॉप-लेवल कंटेनर होता है जिसका उपयोग टेबल और व्यूज़ के सेट को व्यवस्थित करने और उनकी एक्सेस कंट्रोल के लिए किया जाता है। डेटासेट बनाने के लिए, प्रोजेक्ट के ‘Actions’ आइकन पर क्लिक करें:
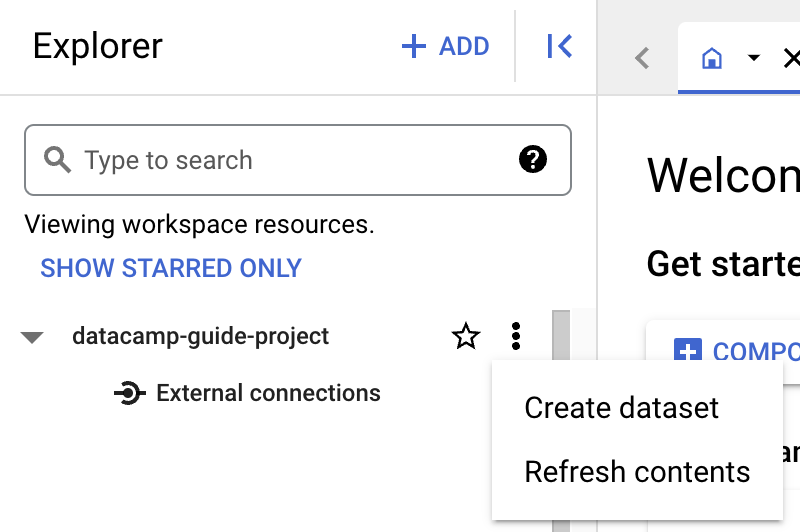
इस गाइड के उद्देश्य से, हम ‘Dataset ID’ में ‘main’ भरेंगे।
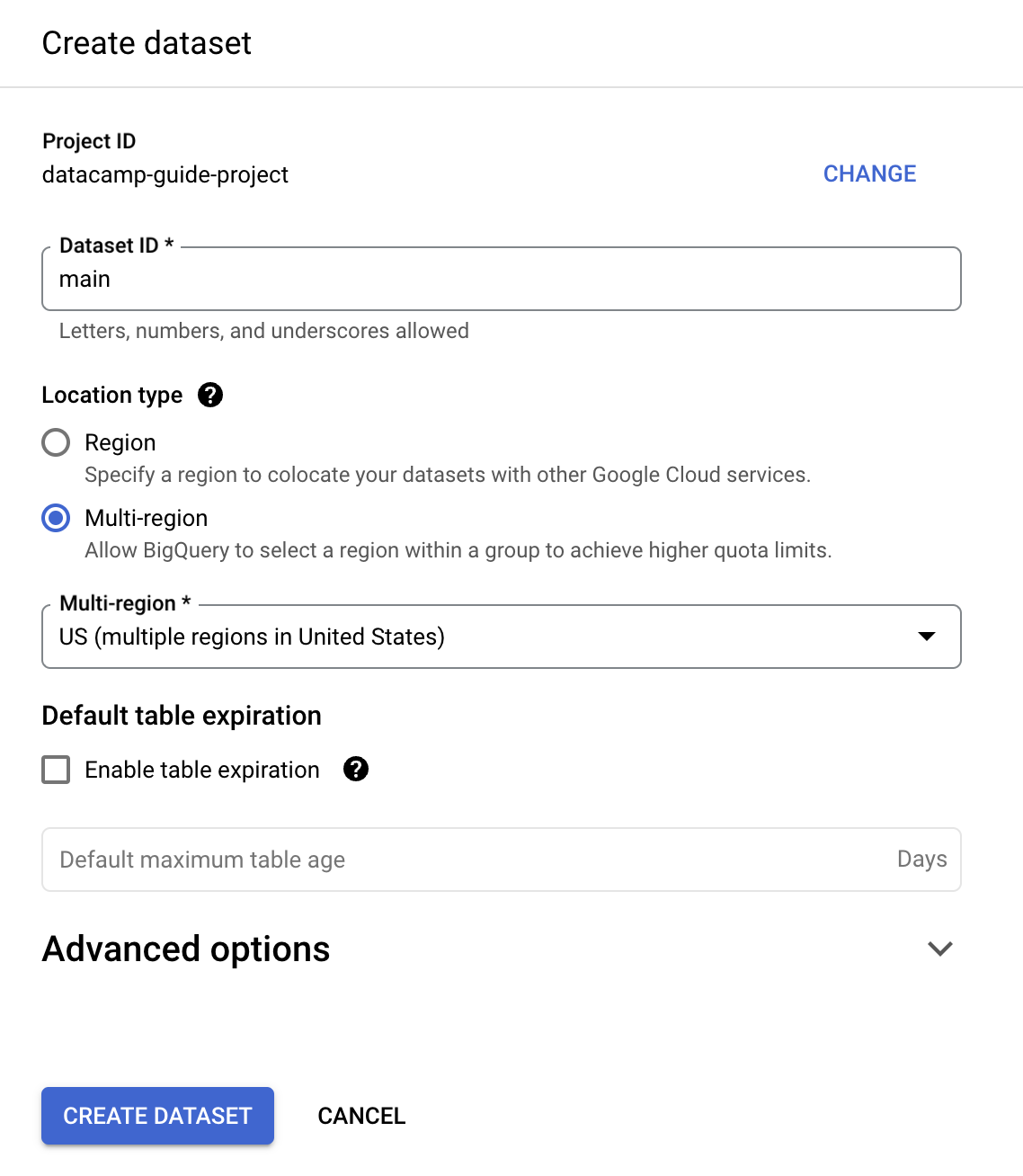
आप SQL का उपयोग करके टेबल बना सकते हैं। BigQuery GoogleSQL का उपयोग करता है, जो ANSI अनुरूप है।
CREATE TABLE datacamp-guide-project.main.users (
id INT64 NOT NULL,
first_name STRING NOT NULL,
middle_name STRING,
last_name STRING NOT NULL,
active_account BOOL NOT NULL
);आप BigQuery कंसोल इंटरफेस का भी उपयोग कर सकते हैं:
नोट: सैंडबॉक्स वातावरण में डेटा इंसर्ट करना संभव नहीं है। यदि आप डेटा इंसर्ट करना आज़माना चाहते हैं, तो आपको फ्री ट्रायल सक्षम करना होगा। अगली धाराएँ Google Cloud के हिस्से के रूप में उपलब्ध सार्वजनिक डेटासेट पर क्वेरी करने पर केंद्रित हैं।
किसी सार्वजनिक डेटासेट पर क्वेरी करने के लिए नीचे दिए चरणों का पालन करें:
1. Explorer के बगल में ‘Add’ पर क्लिक करें।

2. फिर, एक डेटासेट चुनें।
3. ‘Google Trends’ खोजें और Google Trends चुनें, फिर ‘View dataset’ बटन पर क्लिक करें।

4. bigquery-public-data लंबे डेटासेट सूची के साथ दिखाई देगा। bigquery-public-data को स्टार करें ताकि यह एक्सप्लोरर में “चिपका” रहे
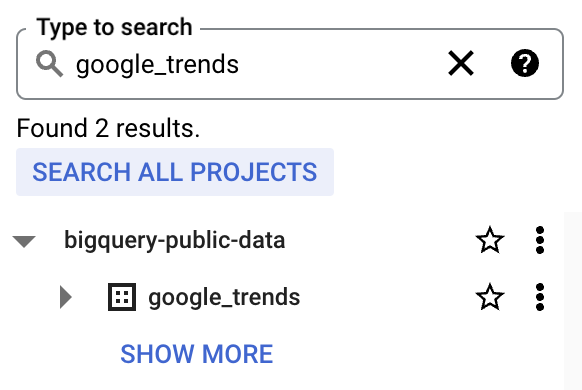
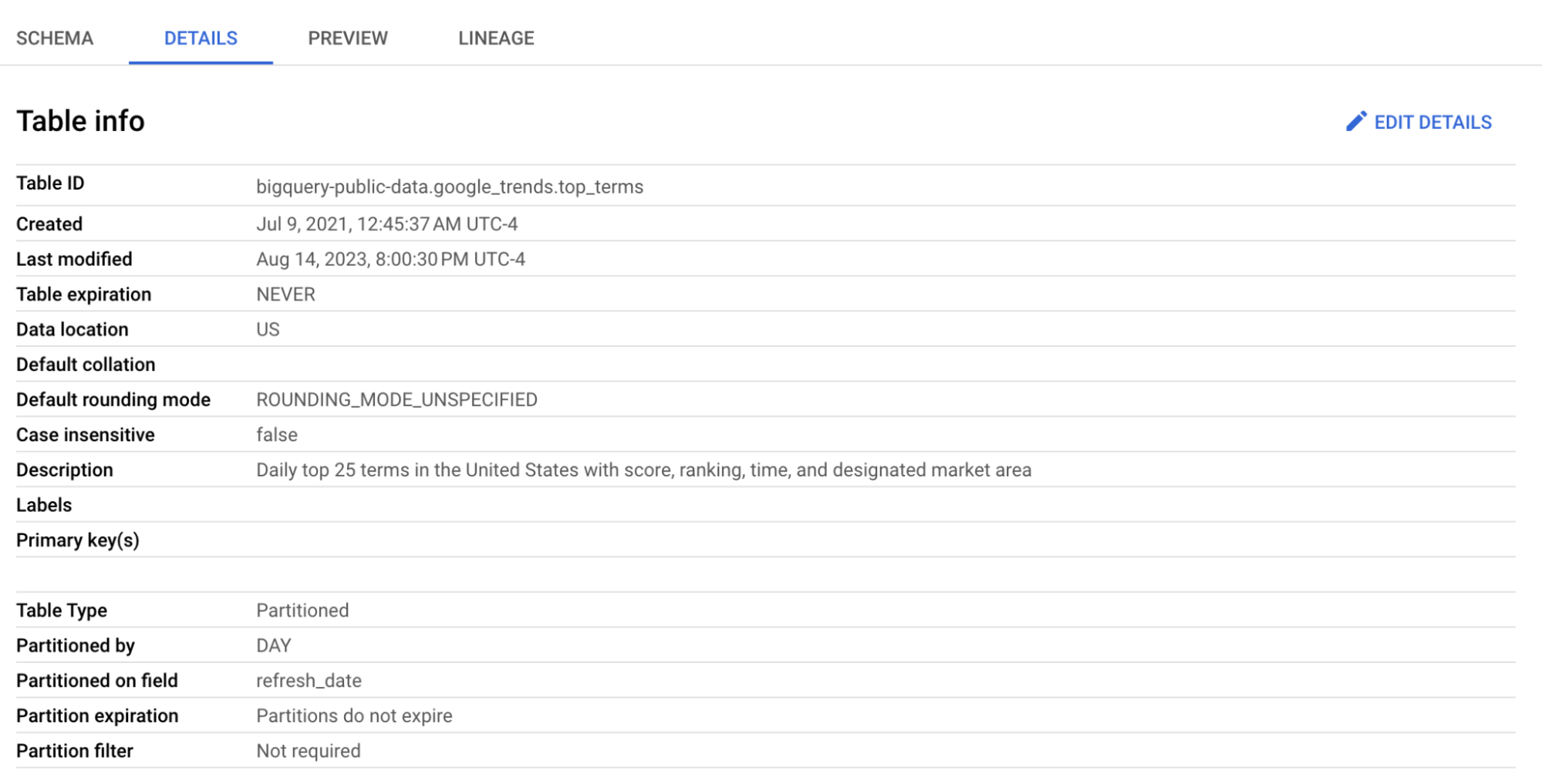
हम top_terms टेबल का उपयोग करेंगे:

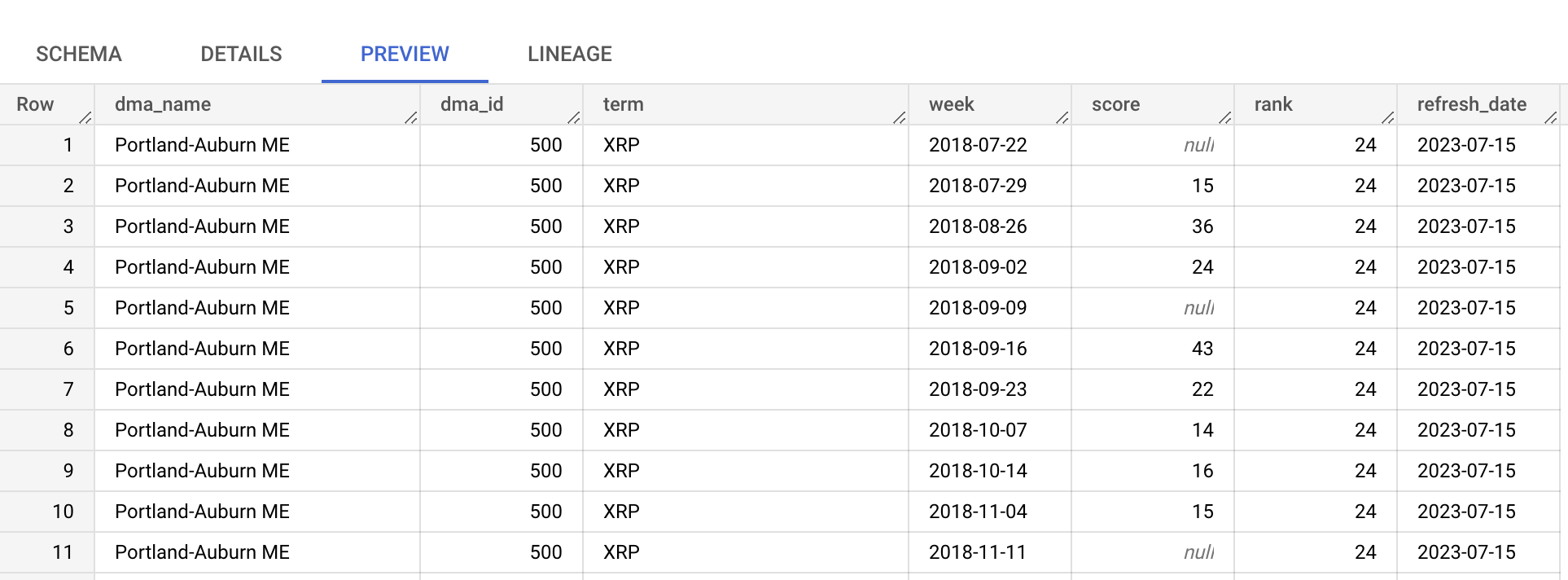
top_terms टेबल पर क्लिक करके उसे खोलें, और Details तथा Preview टैब देखें ताकि top_terms डेटा के बारे में अधिक जान सकें।
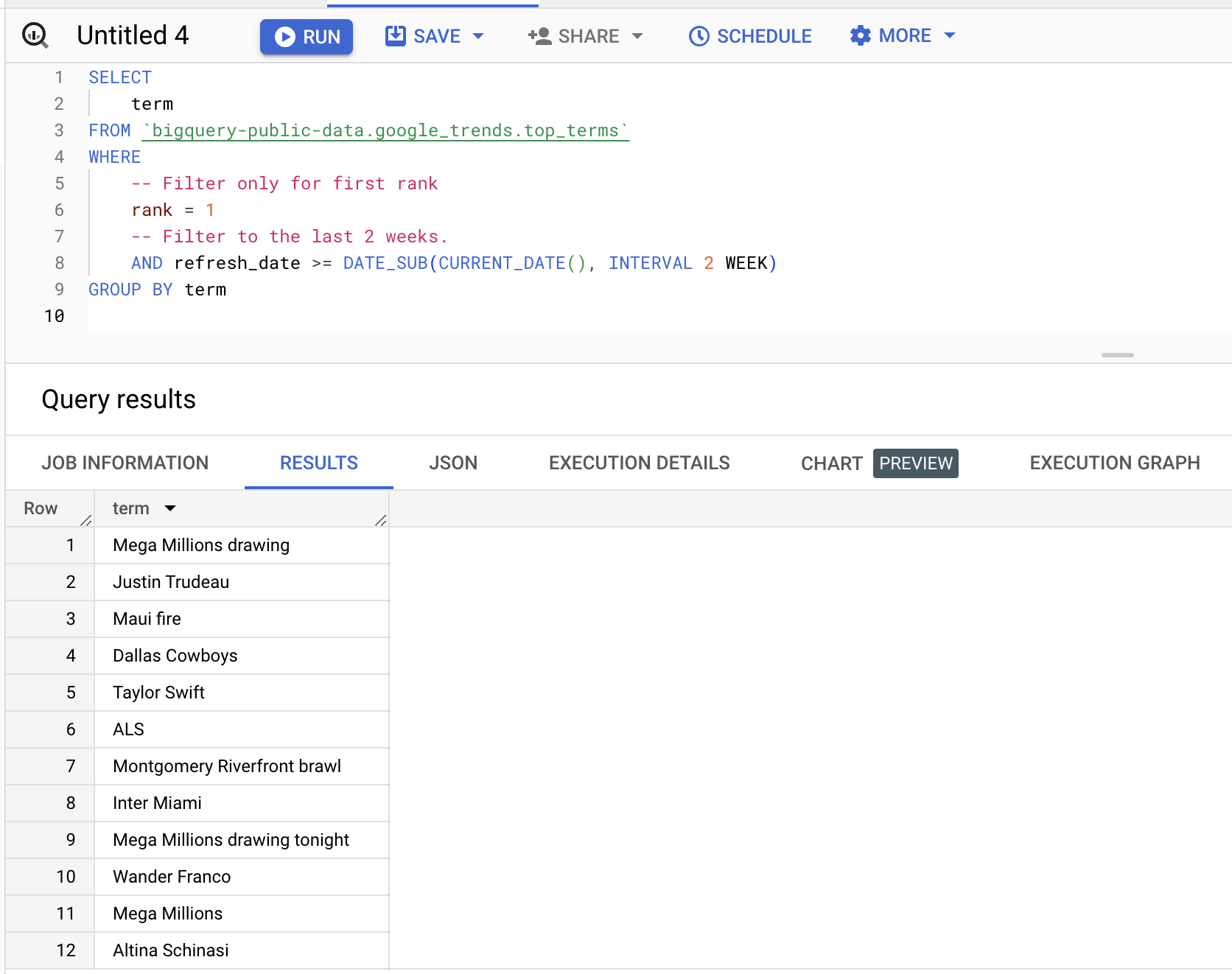
आप डेटासेट पर क्वेरी चला सकते हैं, नीचे पिछले दो हफ्तों में पहले स्थान पर रैंक किए गए शब्दों को प्राप्त करने का उदाहरण है:
SELECT
term
FROM
bigquery-public-data.google_trends.top_terms
WHERE
rank = 1
AND refresh_date >= DATE_SUB(CURRENT_DATE(), INTERVAL 2 WEEK)
GROUP BY
termनतीजे (बदल सकते हैं):
BigQuery की कीमत के दो मुख्य घटक हैं: कंप्यूट (क्वेरी प्रोसेसिंग) और स्टोरेज।
| घटक | फ्री टियर | पेड प्राइसिंग |
|---|---|---|
| ऑन-डिमांड क्वेरी | 1 TiB प्रति माह | $6.25 प्रति TiB |
| स्टोरेज (सक्रिय) | 10 GiB | $0.02 प्रति GiB/माह |
| स्टोरेज (लंबी अवधि) | 10 GiB | $0.01 प्रति GiB/माह |
| स्ट्रीमिंग इंसर्ट | N/A | $0.05 प्रति 200 MB |
जिन टीमों के वर्कलोड अनुमानित हैं, उनके लिए BigQuery क्षमता आरक्षण (BigQuery Editions) के माध्यम से फ्लैट-रेट प्राइसिंग भी प्रदान करता है। मौजूदा दरों के लिए आधिकारिक प्राइसिंग पेज देखें।
BigQuery क्लाउड डेटा वेयरहाउसिंग में प्रवेश के सबसे सुलभ तरीकों में से एक है। सैंडबॉक्स आपको बिना जोखिम के प्रयोग करने का वातावरण देता है, और प्रति माह 1 TiB फ्री क्वेरी का अर्थ है कि आप सार्वजनिक डेटासेट बिना कोई खर्च किए एक्सप्लोर कर सकते हैं। जब आपको अधिक की आवश्यकता हो, तो Google Cloud का फ्री ट्रायल $300 के क्रेडिट देता है।
यदि आप यहाँ सीखी बातों पर आगे निर्माण करना चाहते हैं, तो मैं DataCamp का Introduction to BigQuery कोर्स सुझाता हूँ, जो क्वेरी ऑप्टिमाइज़ेशन और बड़े डेटासेट के साथ काम करना कवर करता है। डेटा इंजीनियरिंग का व्यापक दृष्टिकोण पाने के लिए, Data Engineer in Python ट्रैक इन्गेशन से वेयरहाउसिंग तक की पूरी पाइपलाइन कवर करता है।
आप हमारे BigQuery बनाम Redshift और BigQuery बनाम Snowflake तुलना भी देख सकते हैं, या हमारे BigQuery इंटरव्यू प्रश्न गाइड से इंटरव्यू की तैयारी कर सकते हैं।
आज ही डेटा इंजीनियरिंग शुरू करें!
Track
course
course