
Cursus
Ingénieur de données associé en SQL
30 h
Un entrepôt de données traditionnel est déployé on-premise, avec généralement des coûts initiaux élevés, une équipe expérimentée pour le gérer et une planification rigoureuse pour absorber la montée en charge, en raison de la rigidité du dimensionnement des ressources en datacenter.
À l’inverse, un entrepôt de données cloud est géré et hébergé par un fournisseur de services cloud. Parmi les exemples : Google BigQuery, Amazon Redshift et Snowflake.
En général, un entrepôt de données cloud présente plusieurs avantages par rapport aux entrepôts traditionnels :
Exemple de base orientée lignes :

Exemple de base orientée colonnes :
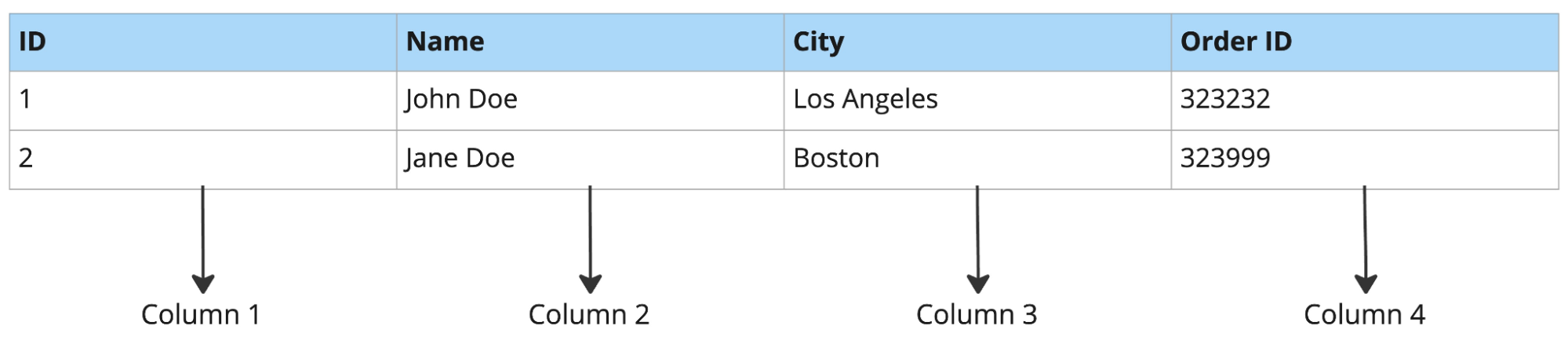
Les bases orientées lignes excellent pour récupérer des enregistrements complets, insérer des lignes et effectuer des mises à jour. En revanche, elles peinent face aux charges analytiques.
Par exemple, si vous interrogez trois colonnes d’une table qui en comporte 50, une base orientée lignes lit malgré tout les 50 colonnes pour chaque ligne. Une base orientée colonnes ne lit que les trois colonnes nécessaires, ce qui est bien plus rapide pour l’analytique, comme la prévision produit ou le reporting ad hoc.
Les bases orientées lignes conviennent généralement au traitement des transactions en ligne (OLTP), tandis que les bases orientées colonnes sont adaptées à l’analyse en ligne (OLAP).
Résumé de la comparaison :
|
Base orientée lignes |
Base orientée colonnes |
||||||
|
Stockage |
Par ligne |
Par colonne |
|||||
|
Récupération des données |
Enregistrements complets |
Colonnes pertinentes |
|||||
|
Application typique |
OLTP |
OLAP |
|||||
|
Opérations rapides |
Insertion, mises à jour, recherches |
Requêtes pour le reporting |
|||||
|
Chargement des données |
Généralement enregistrements unitaires |
Généralement par lot |
|||||
|
Options populaires |
Postgres, MySQL, Oracle, Microsoft SQL Server |
Snowflake, Google BigQuery, Amazon Redshift |
|||||
BigQuery sépare le moteur de calcul du stockage, ce qui permet à chacun de monter en charge indépendamment. Résultat : vous pouvez interroger des téraoctets de données en quelques secondes et des pétaoctets en quelques minutes.
Lors de l’exécution d’une requête, le moteur de BigQuery distribue le travail en parallèle, parcourt les tables pertinentes en stockage, fusionne les résultats et renvoie l’ensemble final de données.
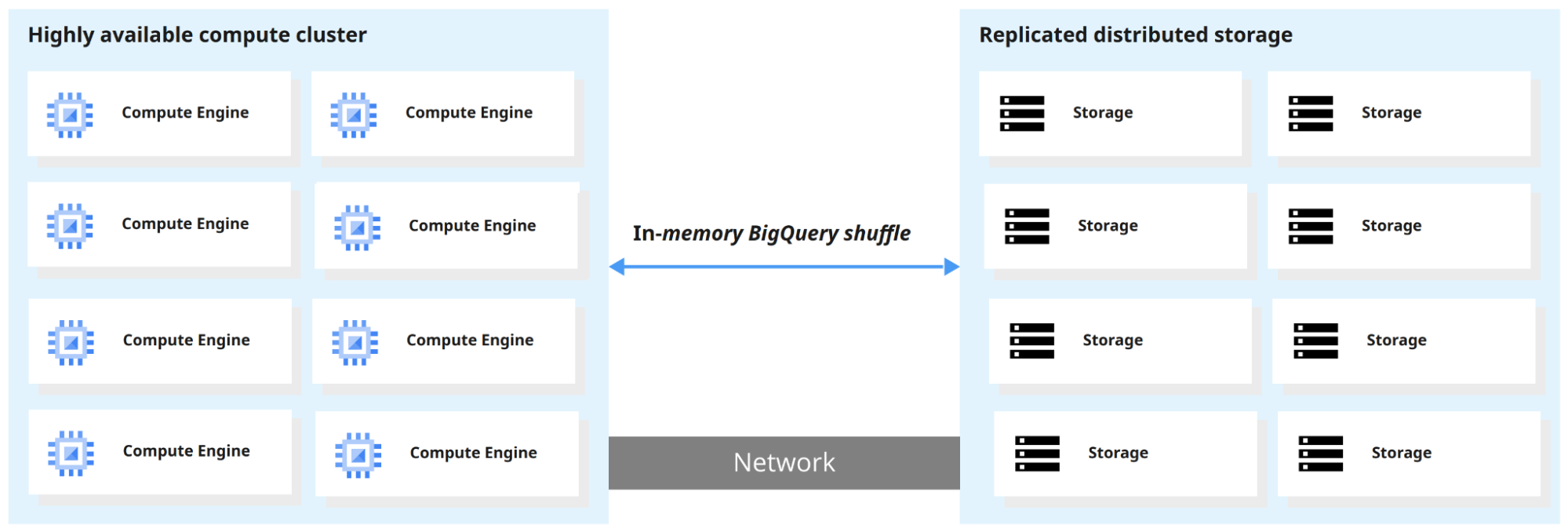
Depuis son lancement, Google a ajouté plusieurs fonctionnalités qui étendent BigQuery au-delà d’un entrepôt de données classique :
La sandbox BigQuery vous permet d’essayer BigQuery sans renseigner de carte bancaire ni créer de compte de facturation. Dans cette section, je vous explique comment accéder à BigQuery et configurer votre premier projet avec la sandbox.
BigQuery est accessible via la console Google Cloud. Vous devrez vous connecter avec un compte Google (ou en créer un). Une fois connecté, un écran de bienvenue s’affiche :
Vous trouverez BigQuery dans le menu de gauche. En cliquant, vous arrivez sur l’écran ci-dessous :
Pour utiliser la sandbox BigQuery, commencez par créer un projet en cliquant sur « Select Project ».
Puis cliquez sur « New Project » :
Vous devez fournir un nom de projet ; pour ce guide, nous utilisons datacamp-guide-project

Un message de sandbox s’affiche désormais sur la page BigQuery, confirmant que la sandbox a bien été activée.

Avec la sandbox BigQuery activée, vous pouvez utiliser votre nouveau projet pour charger et interroger des données, ainsi que pour interroger les jeux de données publics de Google.
Avant de créer une table, vous devez créer un dataset dans votre nouveau projet. Un dataset est un conteneur de premier niveau utilisé pour organiser et contrôler l’accès à un ensemble de tables et de vues. Pour créer un dataset, cliquez sur l’icône « Actions » du projet :
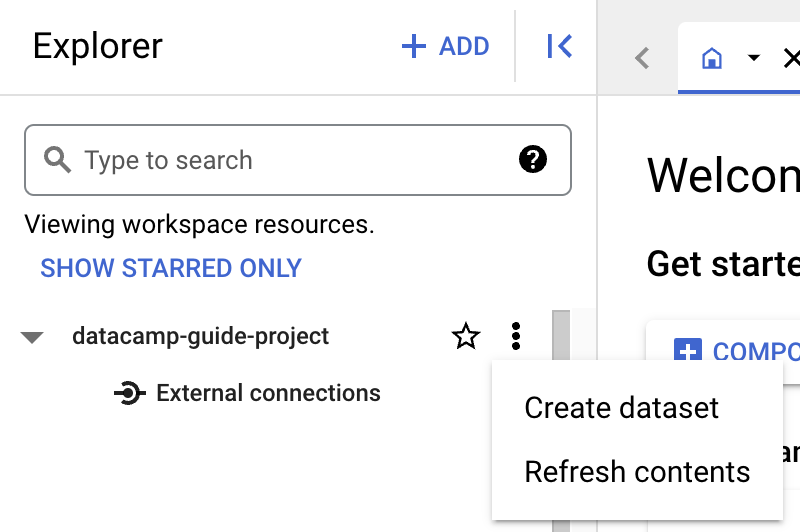
Pour les besoins de ce guide, renseignez « Dataset ID » avec « main ».
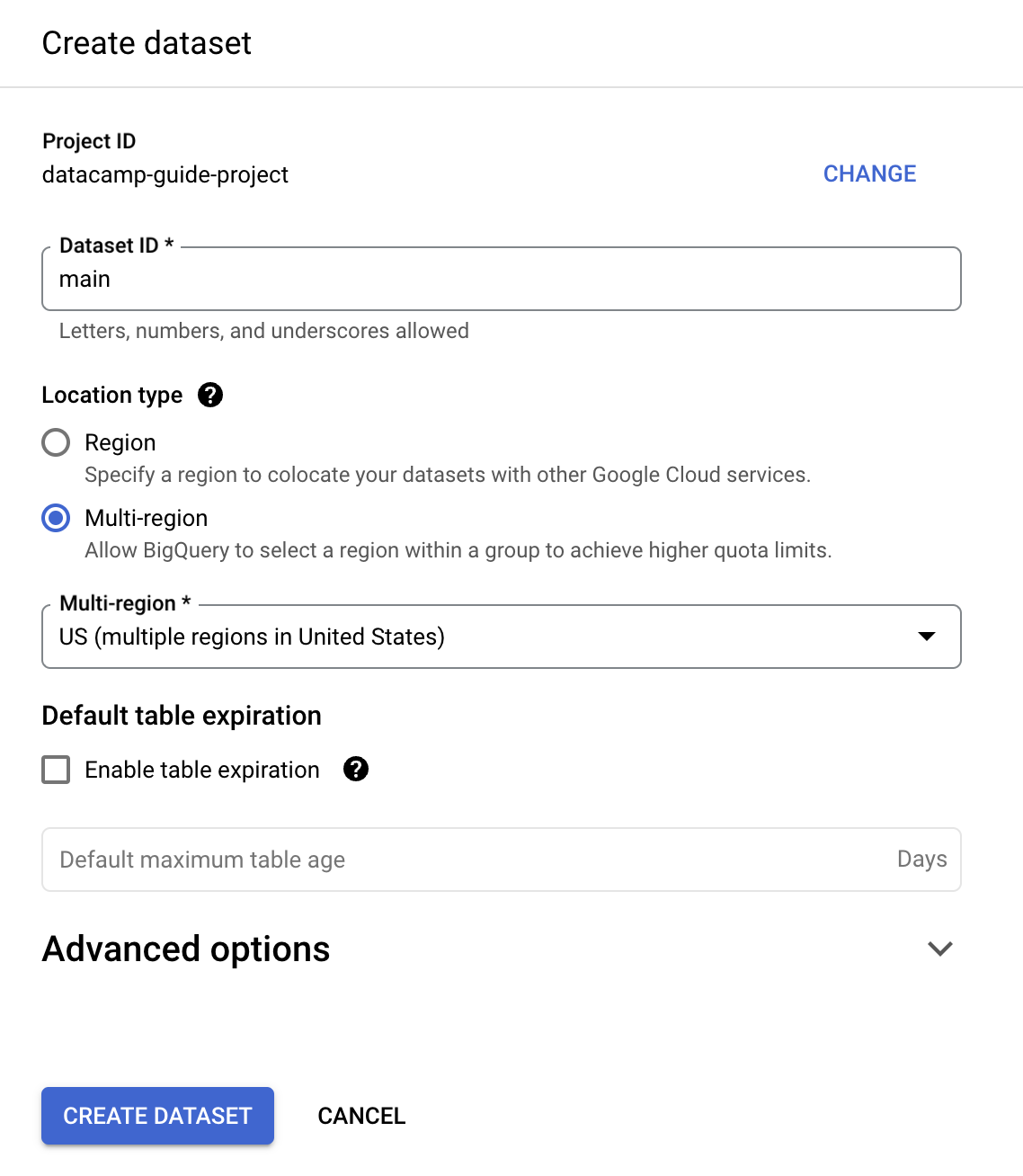
Vous pouvez créer une table en SQL. BigQuery utilise GoogleSQL, conforme à la norme ANSI.
CREATE TABLE datacamp-guide-project.main.users (
id INT64 NOT NULL,
first_name STRING NOT NULL,
middle_name STRING,
last_name STRING NOT NULL,
active_account BOOL NOT NULL
);Vous pouvez aussi utiliser l’interface de la console BigQuery :
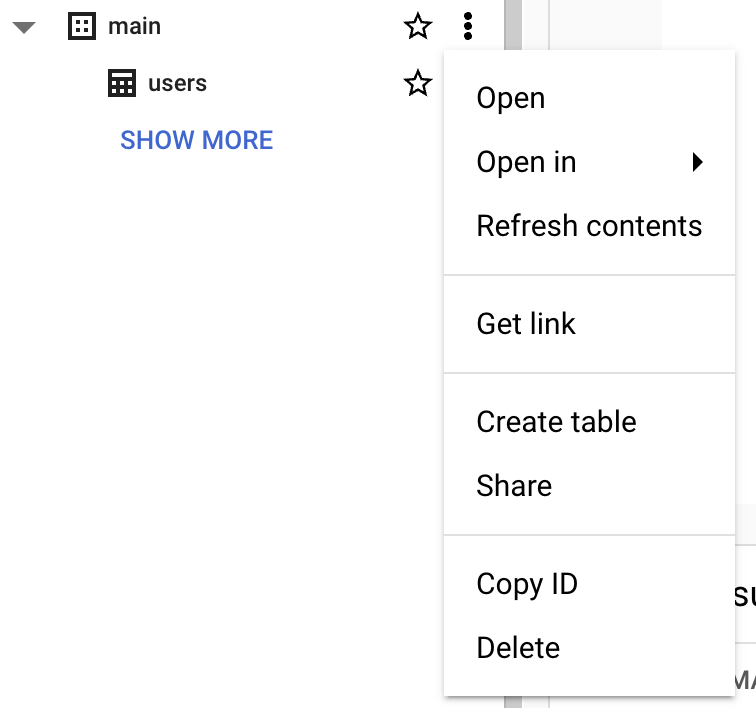
Remarque : il n’est pas possible d’insérer des données dans l’environnement sandbox. Si vous souhaitez essayer l’insertion de données, vous devez activer l’essai gratuit. Les sections suivantes se concentrent sur l’interrogation des jeux de données publics proposés dans Google Cloud.
Pour interroger un jeu de données public, suivez les étapes ci-dessous :
1. Cliquez sur « Add » à côté d’Explorer.

2. Choisissez ensuite un jeu de données.
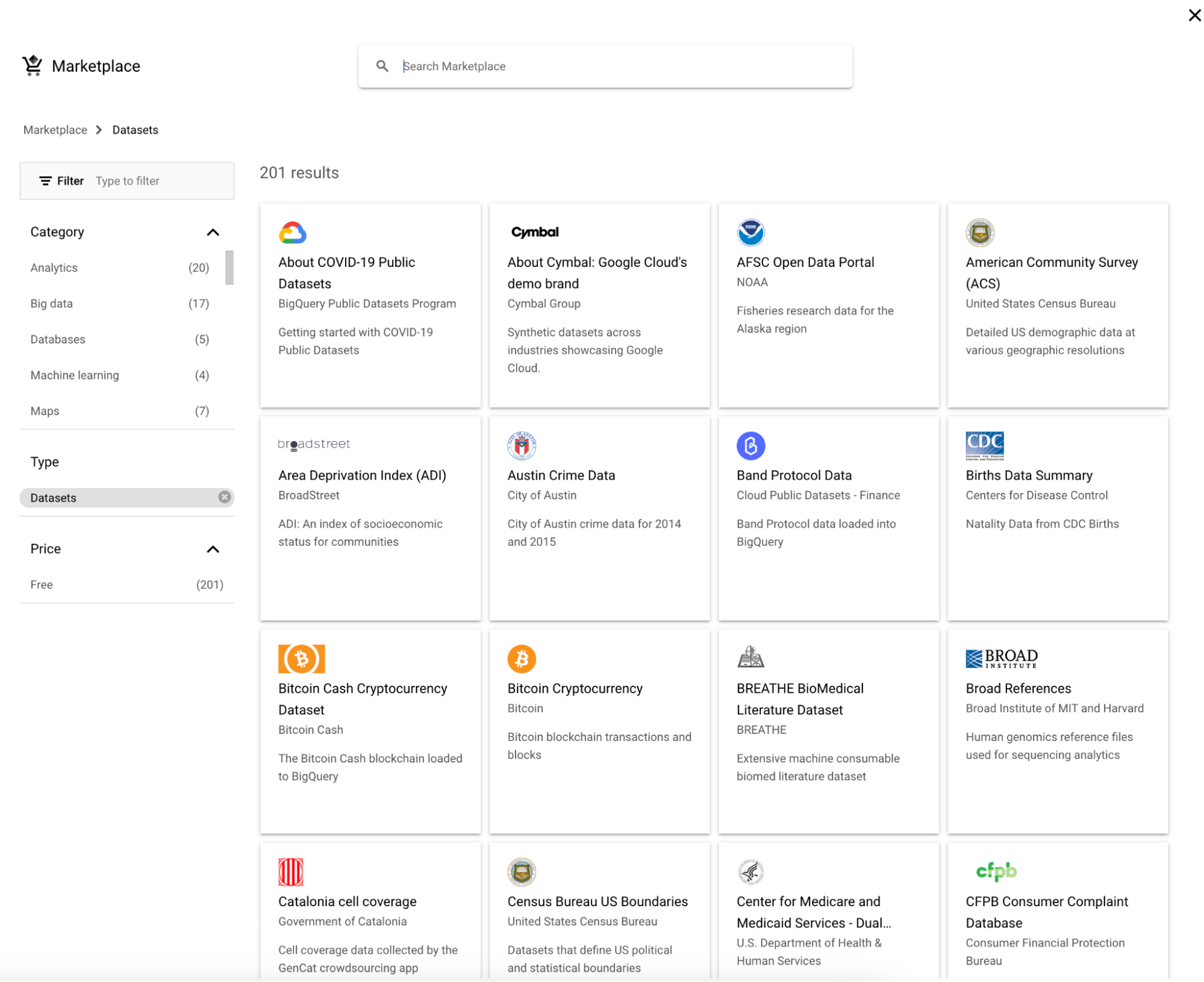
3. Recherchez « Google Trends » et sélectionnez Google Trends, puis cliquez sur le bouton « View dataset ».

4. bigquery-public-data apparaît avec une longue liste de jeux de données. Ajoutez bigquery-public-data aux favoris (étoile) pour qu’il reste épinglé dans l’explorateur
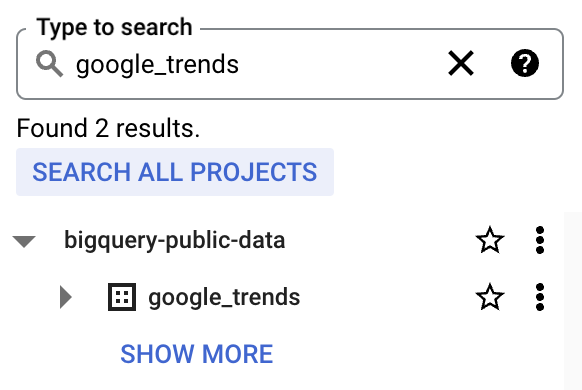
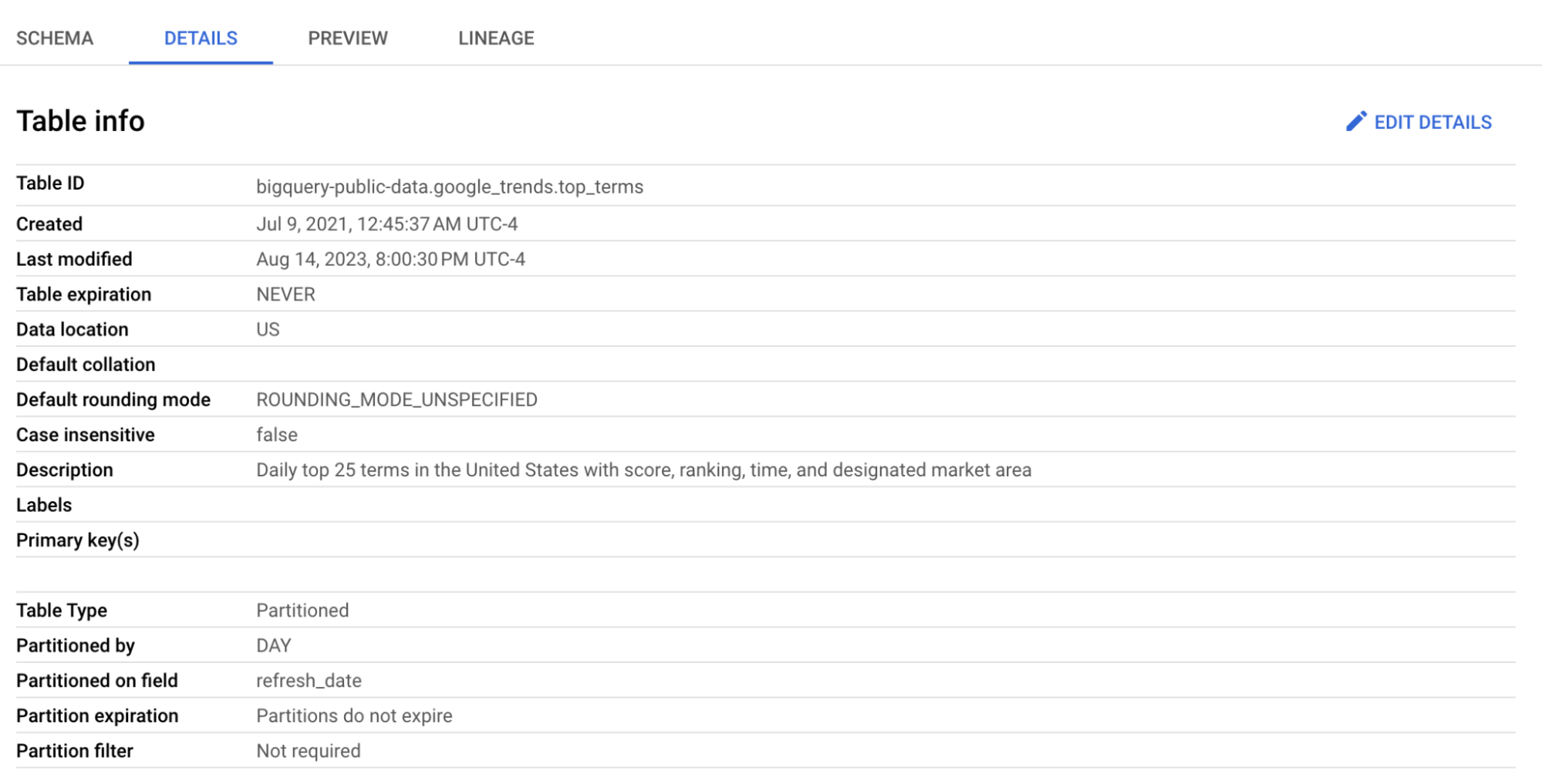
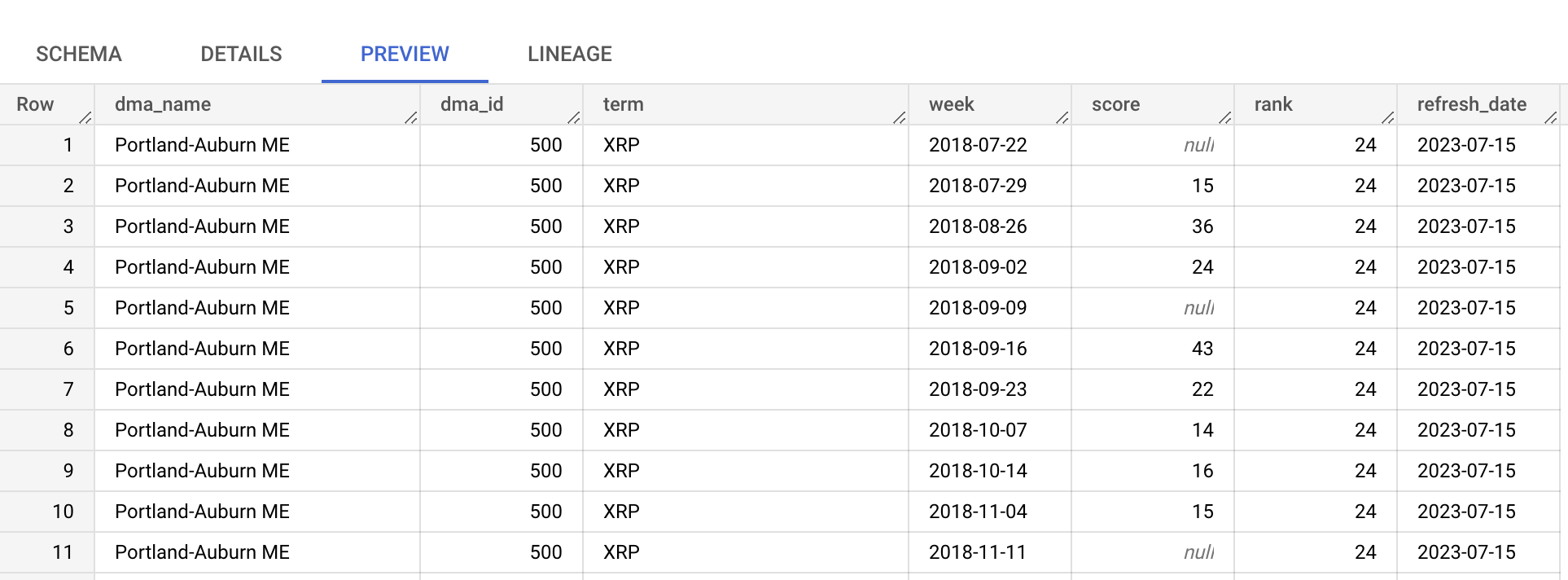
Nous allons utiliser la table top_terms :

Cliquez sur la table top_terms pour l’ouvrir, puis consultez les onglets Details et Preview afin d’en savoir plus sur les données de top_terms.
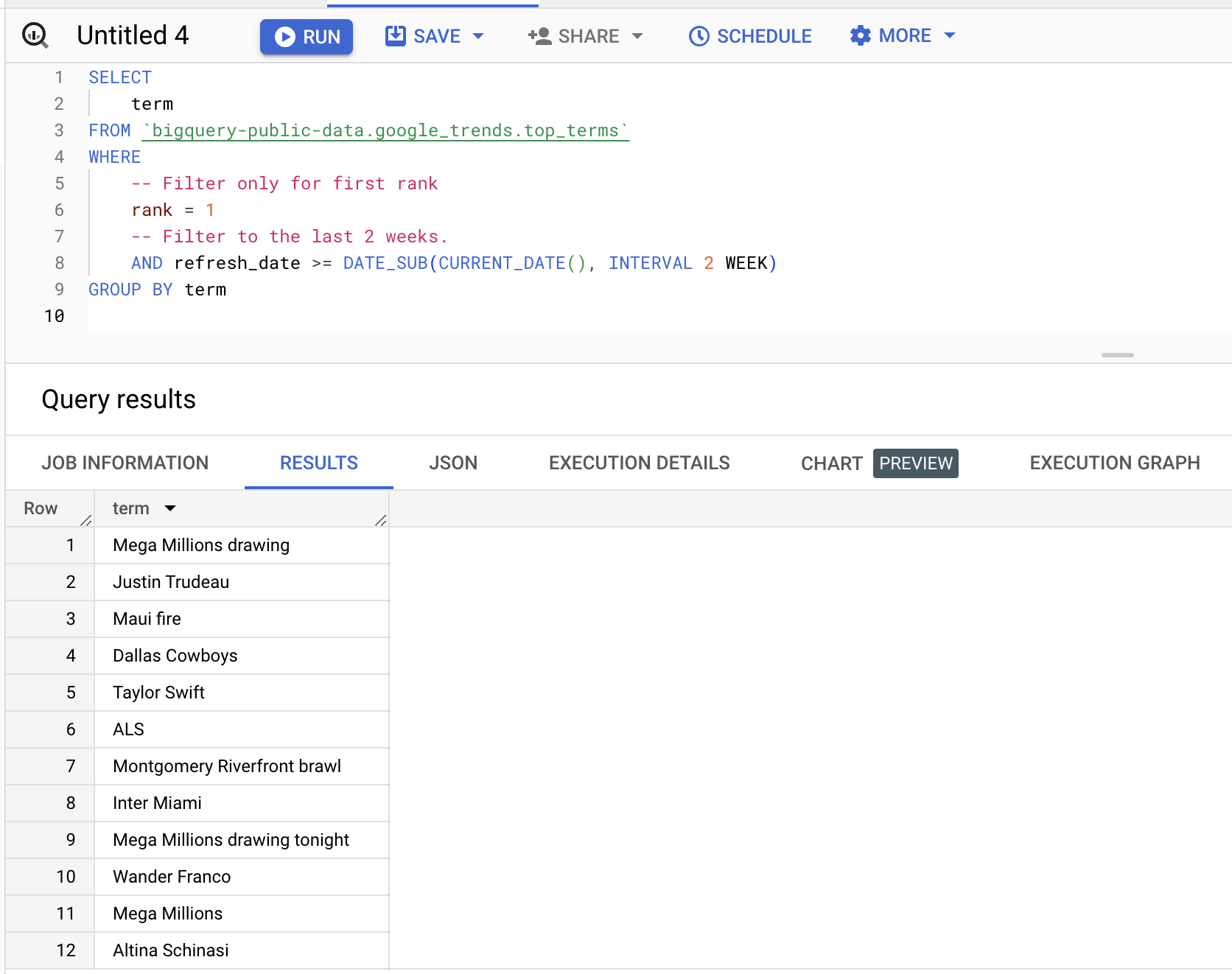
Vous pouvez interroger le dataset ; par exemple, pour récupérer les termes classés en première position au cours des deux dernières semaines :
SELECT
term
FROM
bigquery-public-data.google_trends.top_terms
WHERE
rank = 1
AND refresh_date >= DATE_SUB(CURRENT_DATE(), INTERVAL 2 WEEK)
GROUP BY
termRésultats (variables) :
La tarification de BigQuery repose sur deux composantes principales : le calcul (exécution des requêtes) et le stockage.
| Composante | Offre gratuite | Tarification payante |
|---|---|---|
| Requêtes à la demande | 1 TiB par mois | 6,25 $ par TiB |
| Stockage (actif) | 10 GiB | 0,02 $ par GiB/mois |
| Stockage (long terme) | 10 GiB | 0,01 $ par GiB/mois |
| Insertions en streaming | N/A | 0,05 $ par 200 Mo |
Pour les équipes aux charges prévisibles, BigQuery propose aussi une tarification forfaitaire via des réservations de capacité (BigQuery Editions). Consultez la page de tarification officielle pour les tarifs à jour.
BigQuery est l’un des points d’entrée les plus accessibles vers l’entreposage de données dans le cloud. La sandbox offre un environnement sans risque pour expérimenter, et l’allocation gratuite de 1 TiB de requêtes par mois vous permet d’explorer des jeux de données publics sans rien dépenser. Quand vous aurez besoin de plus, l’essai gratuit de Google Cloud offre 300 $ de crédits.
Pour approfondir ce que vous avez appris ici, je vous recommande le cours Introduction to BigQuery sur DataCamp, qui couvre l’optimisation des requêtes et la manipulation de jeux de données plus volumineux. Pour une vision plus large du data engineering, le parcours Data Engineer in Python couvre l’ensemble du pipeline, de l’ingestion à l’entreposage.
Vous pouvez aussi comparer BigQuery à d’autres solutions dans nos analyses BigQuery vs Redshift et BigQuery vs Snowflake, ou vous préparer aux entretiens avec notre guide BigQuery interview questions.
Commencez le data engineering dès aujourd’hui !
Cursus
Cours
Cours
blog
Kurtis Pykes
15 min
Tutoriel
Sejal Jaiswal
Tutoriel
Matt Crabtree
Tutoriel
Tutoriel
Samuel Shaibu

