
Programma
Ingegnere dei dati associato in SQL
30 h
Un data warehouse tradizionale è distribuito on-premise, richiede in genere alti costi iniziali, un team qualificato per gestirlo e un’adeguata pianificazione per soddisfare la domanda crescente, a causa della natura rigida dello scaling delle risorse nei data center tradizionali.
Un data warehouse cloud, invece, è gestito e ospitato da un provider di servizi cloud. Esempi sono Google BigQuery, Amazon Redshift e Snowflake.
In genere, un data warehouse cloud presenta diversi vantaggi rispetto a quelli tradizionali:
Esempio di database orientato alle righe:

Esempio di database orientato alle colonne:
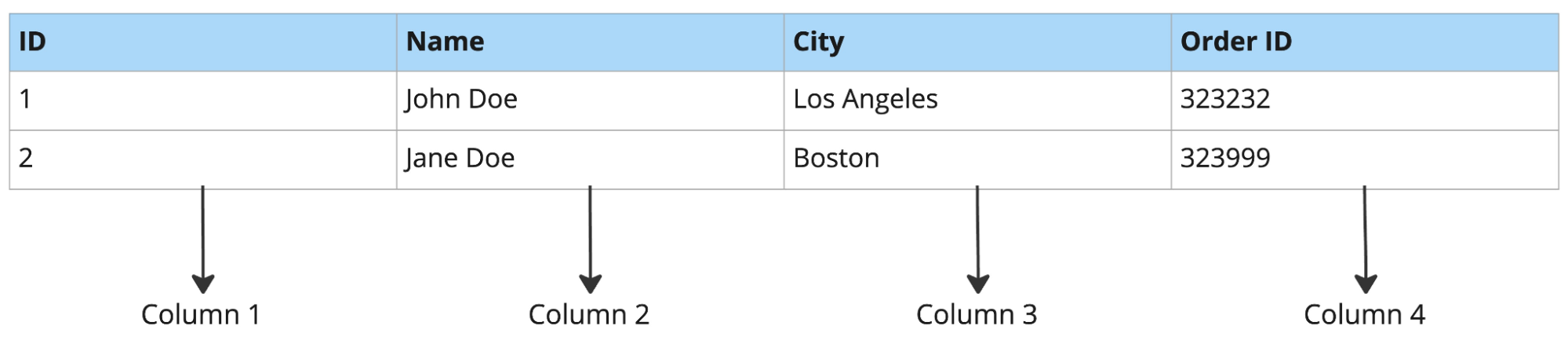
I database orientati alle righe funzionano bene per recuperi completi di righe, inserimenti di record e aggiornamenti. Ma faticano con i carichi di lavoro analitici.
Per esempio, se interroghi tre colonne da una tabella con 50 colonne, un database orientato alle righe leggerà comunque tutte e 50 le colonne per ogni riga. Un database orientato alle colonne legge solo le tre colonne di cui hai bisogno, risultando molto più veloce per analisi come il forecasting dei prodotti o reportistica ad hoc.
I database orientati alle righe sono in genere adatti all’online transaction processing (OLTP), mentre quelli orientati alle colonne all’online analytical processing (OLAP).
Riepilogo del confronto:
|
Database orientato alle righe |
Database orientato alle colonne |
||||||
|
Archiviazione |
Per riga |
Per colonna |
|||||
|
Recupero dati |
Record completi |
Colonne rilevanti |
|||||
|
Applicazione tipica |
OLTP |
OLAP |
|||||
|
Operazioni veloci |
Inserimenti, aggiornamenti, look-up |
Query a fini di reportistica |
|||||
|
Caricamento dati |
Tipicamente un record alla volta |
Tipicamente in batch |
|||||
|
Opzioni popolari |
Postgres, MySQL, Oracle, Microsoft SQL Server |
Snowflake, Google BigQuery, Amazon Redshift |
|||||
BigQuery separa il motore di calcolo dallo storage, così ciascuno può scalare in modo indipendente. Risultato: puoi interrogare terabyte di dati in pochi secondi e petabyte in minuti.
Quando BigQuery esegue una query, il motore di query distribuisce il lavoro in parallelo, scansiona le tabelle rilevanti nello storage, unisce i risultati e restituisce il dataset finale.
Dall’introduzione di BigQuery, Google ha aggiunto diverse funzionalità che lo estendono oltre un data warehouse tradizionale:
La sandbox di BigQuery ti permette di provarlo senza fornire una carta di credito o creare un account di fatturazione. In questa sezione ti mostrerò come accedere a BigQuery e configurare il tuo primo progetto usando la sandbox.
Puoi accedere a BigQuery tramite la Google Cloud Console. Dovrai accedere con un account Google (o crearne uno). Una volta effettuato l’accesso, dovrebbe comparire una schermata di benvenuto:
Puoi trovare BigQuery nella barra del menu a sinistra. Facendo clic verrai portato alla schermata seguente:
Per usare la sandbox di BigQuery, crea prima un progetto facendo clic su "Select Project".
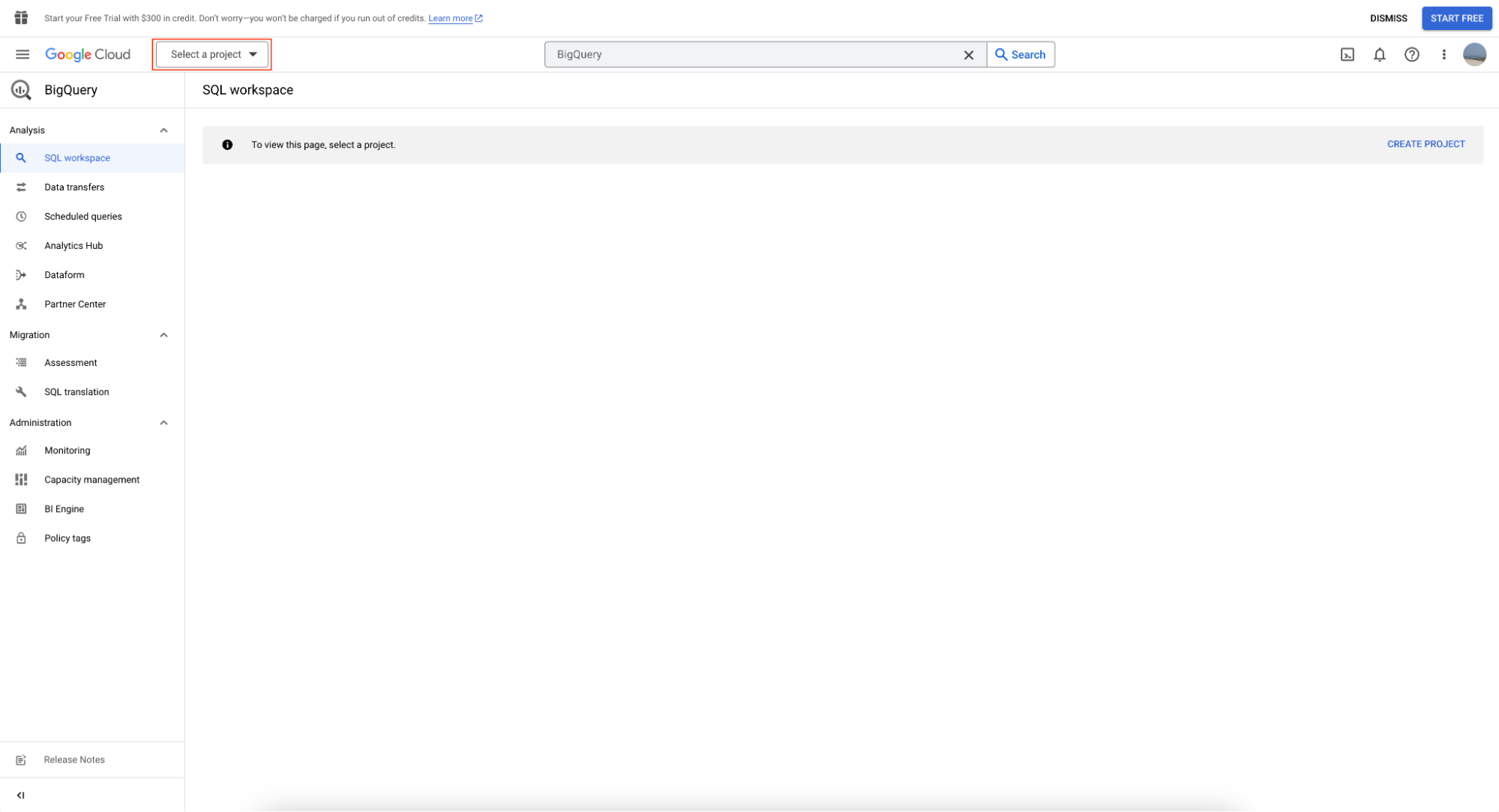
Poi fai clic su "New Project":
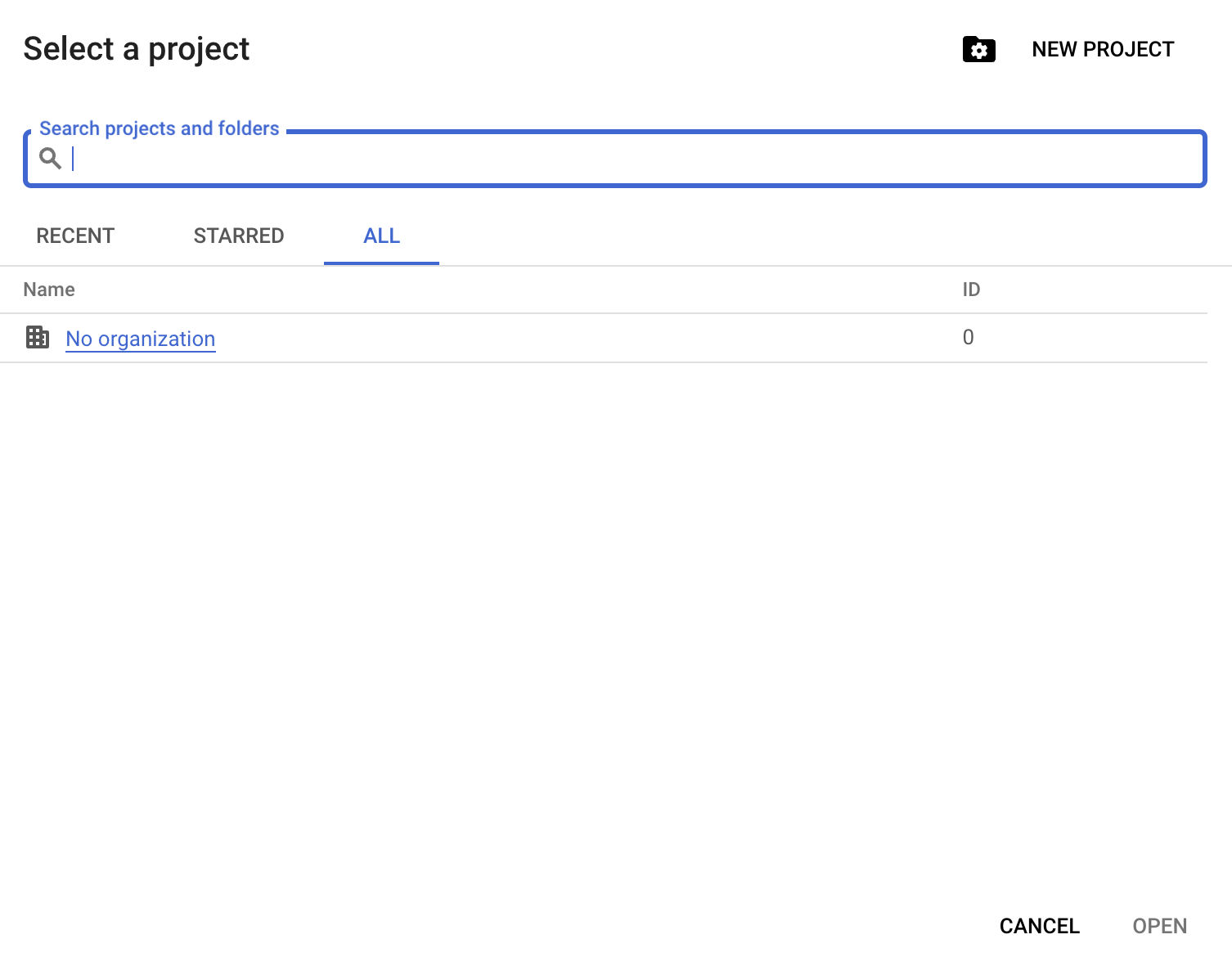
Dovrai fornire un nome per il progetto; per questa guida usiamo datacamp-guide-project

Ora nella pagina di BigQuery viene visualizzato un avviso della sandbox, che indica che hai abilitato correttamente la sandbox di BigQuery.

Con la sandbox di BigQuery abilitata, puoi usare il tuo nuovo progetto per caricare dati e fare query, oltre a interrogare i dataset pubblici di Google.
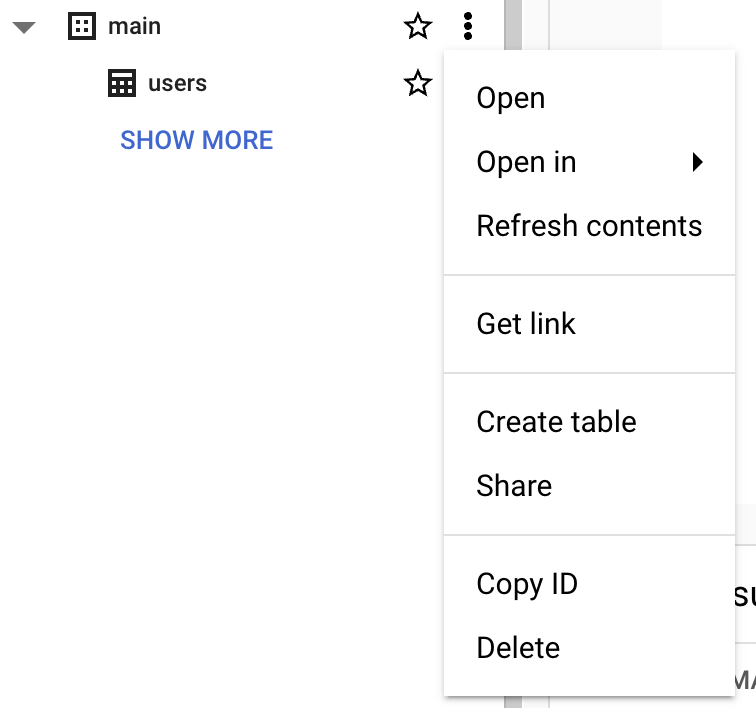
Prima di creare una tabella, devi creare un dataset nel tuo nuovo progetto. Un dataset è un contenitore di primo livello usato per organizzare e controllare l’accesso a un insieme di tabelle e viste. Per creare un dataset, fai clic sull’icona "Actions" del progetto:
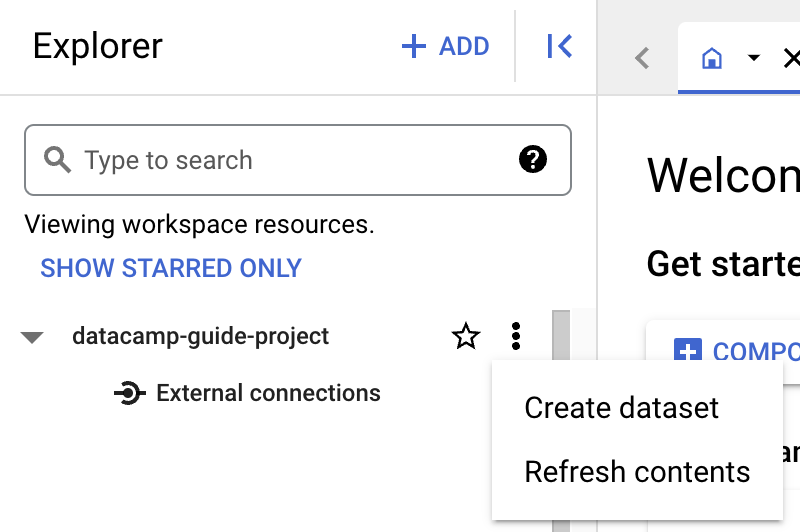
Per questa guida, inseriremo "Dataset ID" con "main".
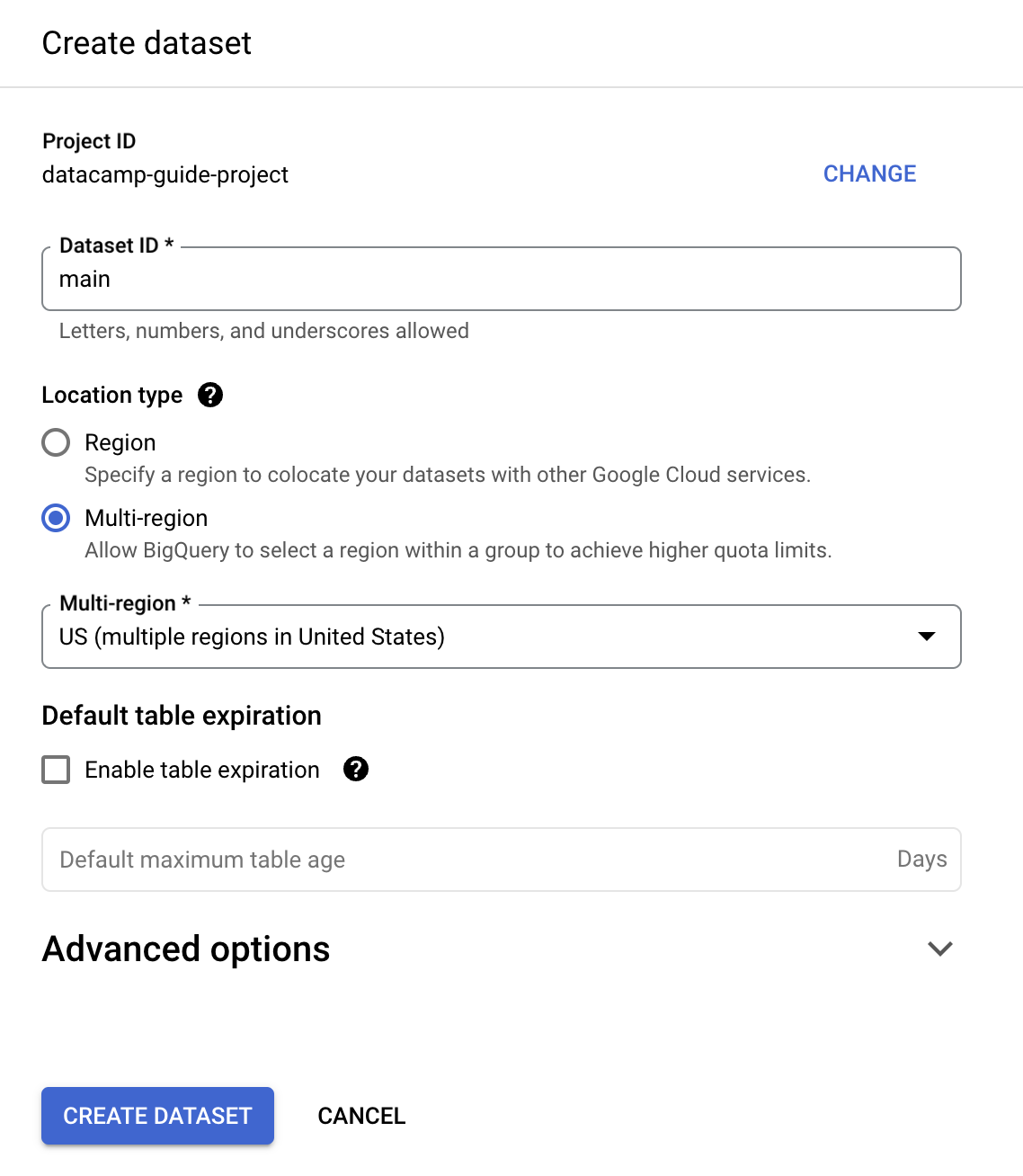
Puoi creare una tabella usando SQL. BigQuery usa GoogleSQL, conforme allo standard ANSI.
CREATE TABLE datacamp-guide-project.main.users (
id INT64 NOT NULL,
first_name STRING NOT NULL,
middle_name STRING,
last_name STRING NOT NULL,
active_account BOOL NOT NULL
);Puoi anche usare l’interfaccia della Console BigQuery:
Nota: Non è possibile inserire dati mentre si è in ambiente sandbox. Se vuoi provare a inserire dati, devi abilitare la prova gratuita. Le prossime sezioni si concentrano sull’interrogazione dei dataset pubblici forniti nell’ambito di Google Cloud.
Per interrogare un dataset pubblico, segui questi passaggi:
1. Clicca su "Add" accanto a Explorer.

2. Poi scegli un dataset.
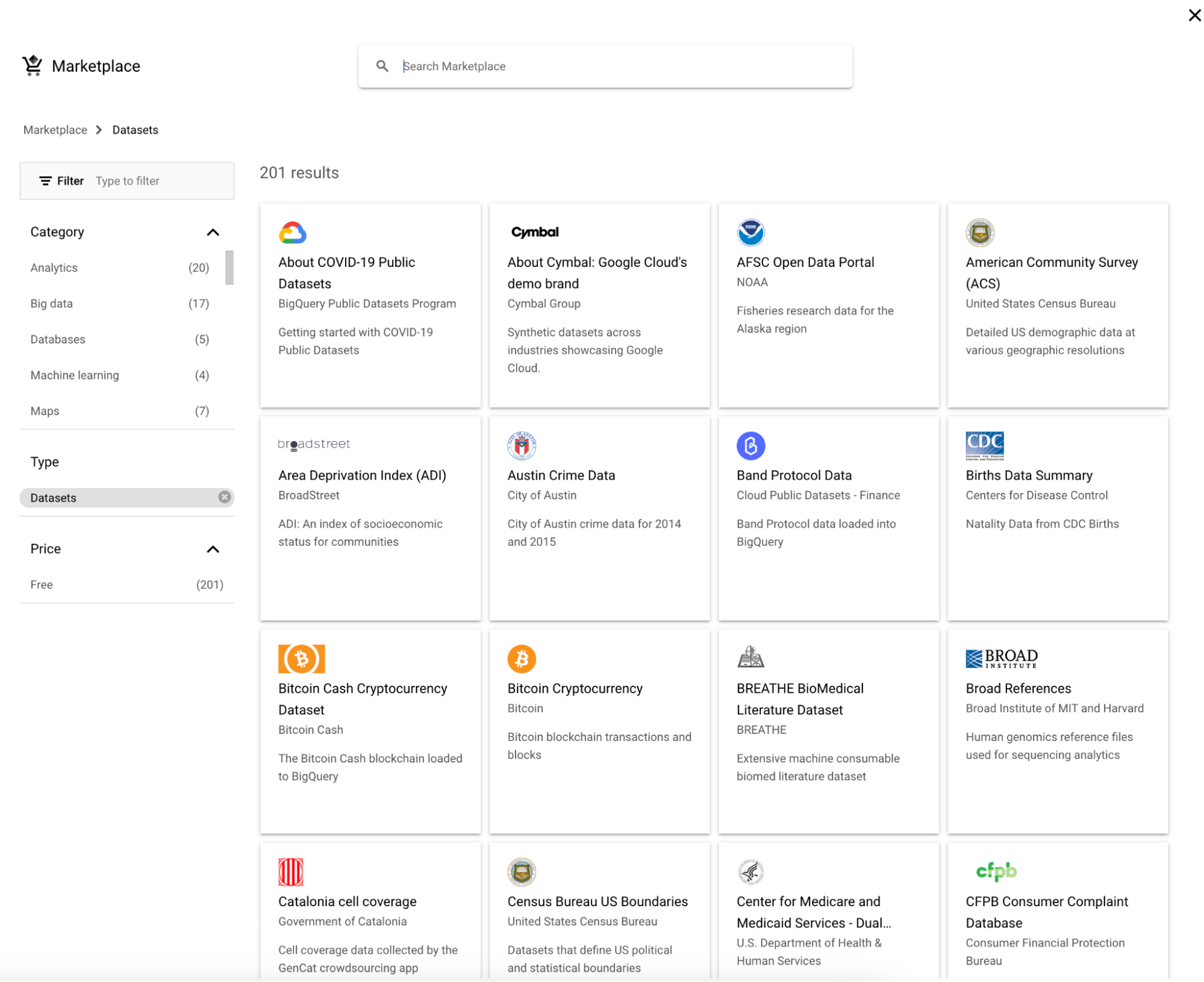
3. Cerca "Google Trends" e seleziona Google Trends, quindi fai clic sul pulsante "View dataset".

4. bigquery-public-data comparirà con un lungo elenco di dataset. Aggiungi bigquery-public-data ai preferiti (stella) così rimane "fisso" nell’explorer
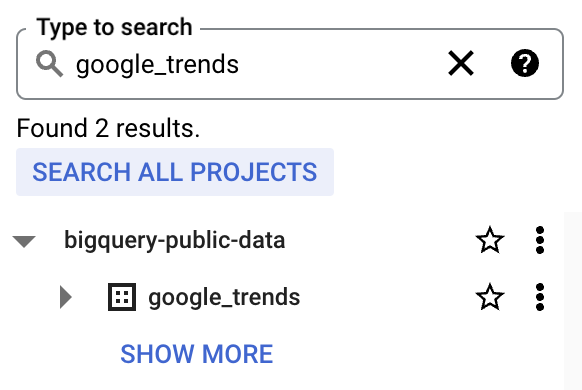
Useremo la tabella top_terms:

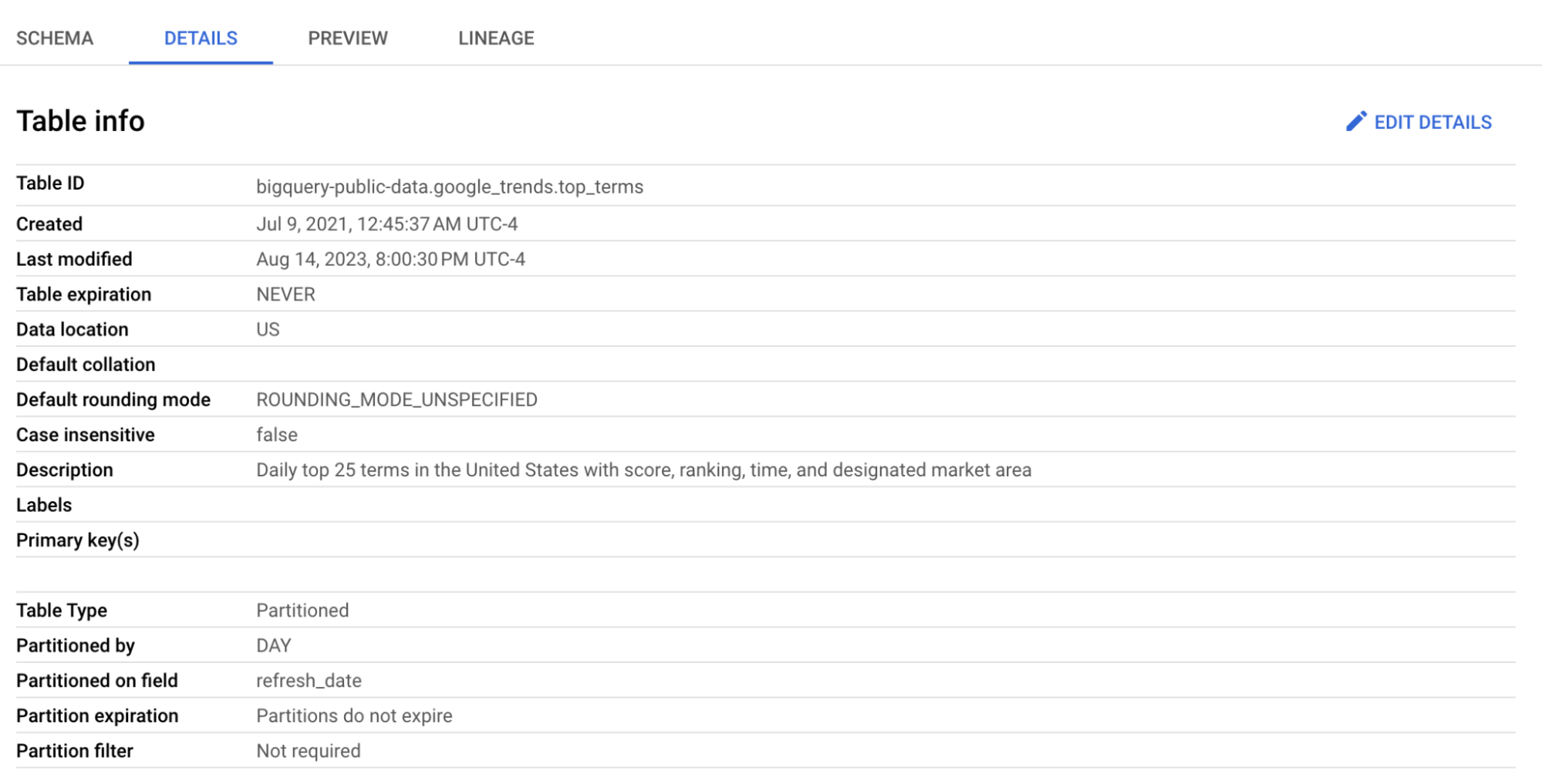
Clicca sulla tabella top_terms per aprirla e ispeziona le schede Details e Preview per saperne di più sui dati di top_terms.
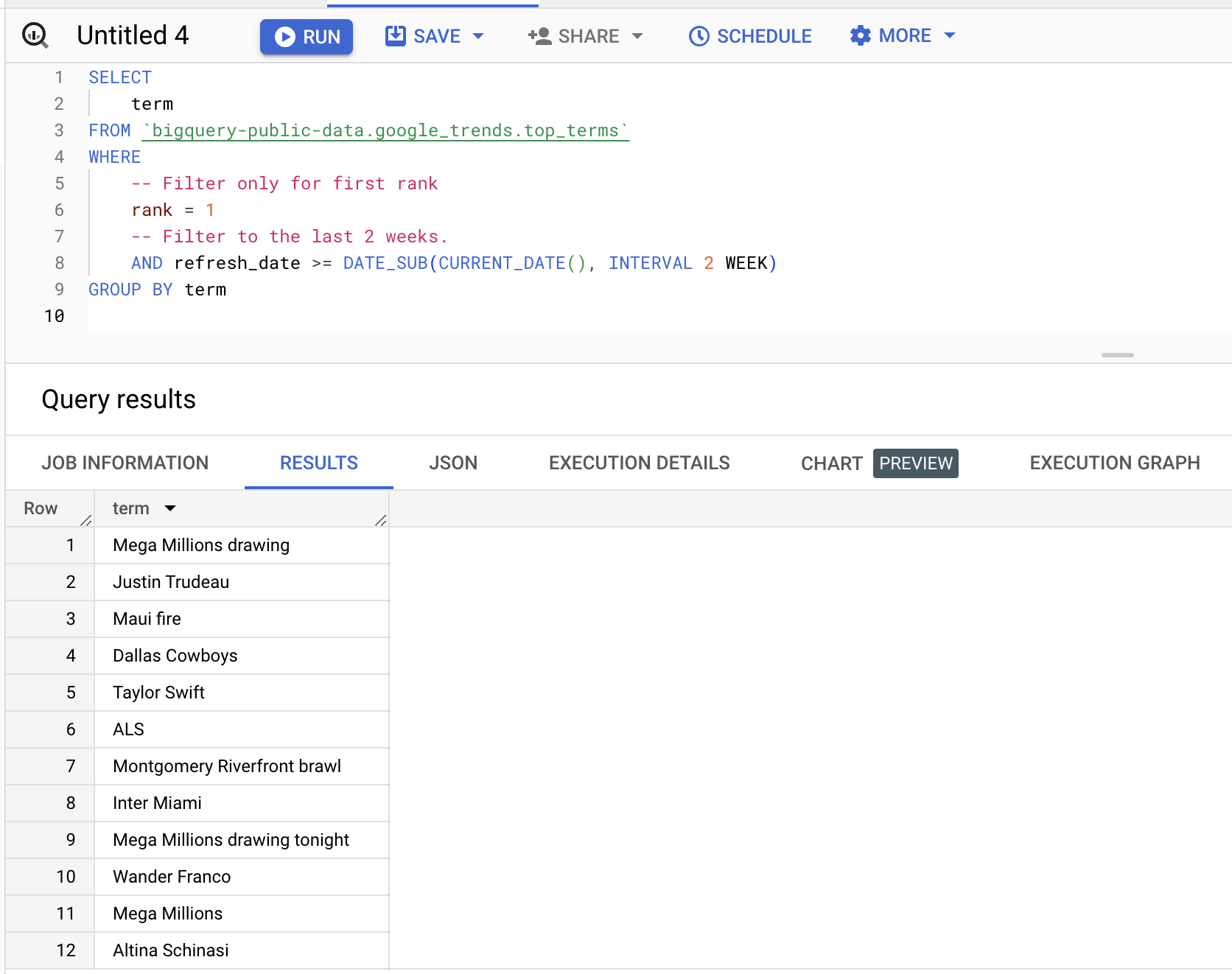
Puoi interrogare il dataset; ecco un esempio per recuperare i termini che hanno raggiunto la prima posizione nelle ultime due settimane:
SELECT
term
FROM
bigquery-public-data.google_trends.top_terms
WHERE
rank = 1
AND refresh_date >= DATE_SUB(CURRENT_DATE(), INTERVAL 2 WEEK)
GROUP BY
termRisultati (variano):
La tariffazione di BigQuery ha due componenti principali: compute (elaborazione delle query) e storage.
| Componente | Livello gratuito | Prezzo a pagamento |
|---|---|---|
| Query on-demand | 1 TiB al mese | $6.25 per TiB |
| Storage (attivo) | 10 GiB | $0.02 per GiB/mese |
| Storage (a lungo termine) | 10 GiB | $0.01 per GiB/mese |
| Streaming insert | N/D | $0.05 per 200 MB |
Per i team con carichi di lavoro prevedibili, BigQuery offre anche prezzi flat tramite prenotazioni di capacità (BigQuery Editions). Controlla la pagina ufficiale dei prezzi per le tariffe aggiornate.
BigQuery è uno dei punti di ingresso più accessibili al data warehousing nel cloud. La sandbox ti offre un ambiente senza rischi per sperimentare e 1 TiB di query gratuite al mese significa che puoi esplorare i dataset pubblici senza spendere nulla. Quando ti serve di più, la prova gratuita di Google Cloud fornisce 300 $ di crediti.
Se vuoi consolidare quanto hai imparato qui, ti consiglio il corso Introduction to BigQuery su DataCamp, che tratta l’ottimizzazione delle query e la gestione di dataset più grandi. Per una panoramica più ampia del data engineering, il percorso Data Engineer in Python copre l’intera pipeline, dall’ingestione al warehousing.
Puoi anche esplorare come BigQuery si confronta con le alternative nei nostri confronti BigQuery vs Redshift e BigQuery vs Snowflake, oppure prepararti ai colloqui con la nostra guida alle domande di colloquio su BigQuery.
Inizia oggi con il Data Engineering!
Programma
Corso
Corso
blog
Tim Lu
12 min
blog
Abid Ali Awan
10 min
blog
Abid Ali Awan
15 min

