Tracks
วิศวกรข้อมูลระดับต้น ใน SQL
30 ชม.
คลังข้อมูลแบบดั้งเดิมติดตั้งภายในองค์กร มักมีค่าใช้จ่ายเริ่มต้นสูง ต้องใช้ทีมงานที่มีทักษะเพื่อดูแล และต้องวางแผนอย่างรอบคอบเพื่อรองรับความต้องการที่เพิ่มขึ้น เนื่องจากการปรับสเกลทรัพยากรของดาต้าเซ็นเตอร์แบบเดิมทำได้ยาก
ส่วนคลังข้อมูลบนคลาวด์จะได้รับการดูแลและโฮสต์โดยผู้ให้บริการคลาวด์ ตัวอย่างเช่น Google BigQuery, Amazon Redshift และ Snowflake
โดยทั่วไป คลังข้อมูลบนคลาวด์มีข้อดีหลายประการเมื่อเทียบกับคลังข้อมูลแบบดั้งเดิม:
ตัวอย่างฐานข้อมูลแบบแถว:

ตัวอย่างฐานข้อมูลแบบคอลัมน์:
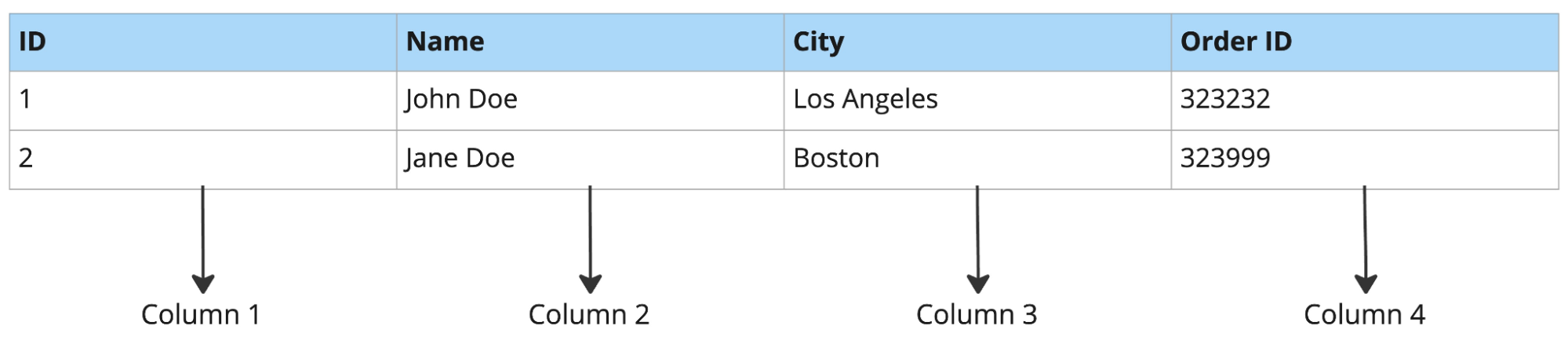
ฐานข้อมูลแบบแววเหมาะกับการดึงข้อมูลทั้งแถว การแทรกระเบียน และการอัปเดต แต่ไม่ถนัดงานวิเคราะห์
ตัวอย่างเช่น หากคิวรี 3 คอลัมน์จากตารางที่มี 50 คอลัมน์ ฐานข้อมูลแบบแถวยังคงต้องอ่านทั้ง 50 คอลัมน์ของทุกแถว ขณะที่ฐานข้อมูลแบบคอลัมน์จะอ่านเฉพาะ 3 คอลัมน์ที่ต้องการ ซึ่งเร็วกว่าอย่างมากสำหรับงานวิเคราะห์ เช่น การพยากรณ์สินค้า หรือรายงานเฉพาะกิจ
ฐานข้อมูลแบบแถวโดยทั่วไปเหมาะกับการประมวลผลธุรกรรมออนไลน์ (OLTP) ส่วนฐานข้อมูลแบบคอลัมน์เหมาะกับการประมวลผลเชิงวิเคราะห์ออนไลน์ (OLAP)
สรุปการเปรียบเทียบ:
|
ฐานข้อมูลแบบแถว |
ฐานข้อมูลแบบคอลัมน์ |
||||||
|
การจัดเก็บ |
ตามแถว |
ตามคอลัมน์ |
|||||
|
การดึงข้อมูล |
ระเบียนครบถ้วน |
คอลัมน์ที่เกี่ยวข้อง |
|||||
|
การใช้งานทั่วไป |
OLTP |
OLAP |
|||||
|
การดำเนินการที่เร็ว |
แทรก อัปเดต ค้นหา |
คิวรีเพื่อรายงาน |
|||||
|
การโหลดข้อมูล |
มักโหลดครั้งละหนึ่งระเบียน |
มักโหลดแบบแบตช์ |
|||||
|
ตัวเลือกยอดนิยม |
Postgres, MySQL, Oracle, Microsoft SQL Server |
Snowflake, Google BigQuery, Amazon Redshift |
|||||
BigQuery แยกเอนจินประมวลผลออกจากที่เก็บข้อมูล ทำให้ปรับสเกลแยกกันได้ ผลลัพธ์คือสามารถคิวรีข้อมูลระดับเทราไบต์ได้ภายในไม่กี่วินาที และระดับเพตะไบต์ภายในไม่กี่นาที
เมื่อ BigQuery รันคิวรี เอนจินคิวรีจะแจกจ่ายงานแบบขนาน สแกนตารางที่เกี่ยวข้องในสตอเรจ รวมผลลัพธ์ และส่งคืนชุดข้อมูลสุดท้าย
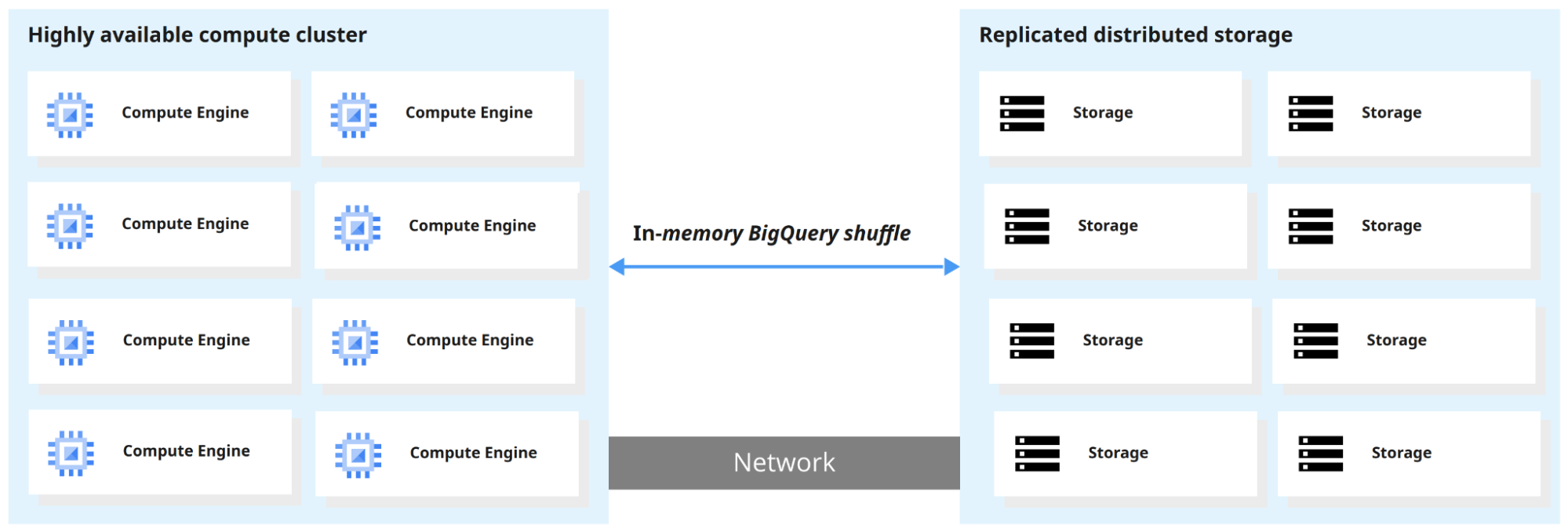
ตั้งแต่เปิดตัว Google ได้เพิ่มคุณสมบัติหลายอย่างที่ขยายขีดความสามารถเกินกว่าคลังข้อมูลแบบดั้งเดิม:
BigQuery sandbox ช่วยให้ทดลองใช้ BigQuery ได้โดยไม่ต้องใส่บัตรเครดิตหรือสร้างบัญชีเรียกเก็บเงิน ในส่วนนี้ ผมจะแนะนำวิธีเข้าถึง BigQuery และตั้งค่าโปรเจกต์แรกด้วย sandbox
เข้าถึง BigQuery ได้ผ่าน Google Cloud Console ต้องลงชื่อเข้าใช้ด้วยบัญชี Google (หรือสร้างบัญชีใหม่) เมื่อเข้าสู่ระบบแล้ว หน้าจอต้อนรับจะปรากฏขึ้น:
สามารถค้นหา BigQuery ได้จากแถบเมนูด้านซ้าย คลิกแล้วจะเข้าสู่หน้าจอต่อไปนี้:
หากต้องการใช้ BigQuery sandbox ให้สร้างโปรเจกต์ก่อนโดยคลิกที่ ‘Select Project’
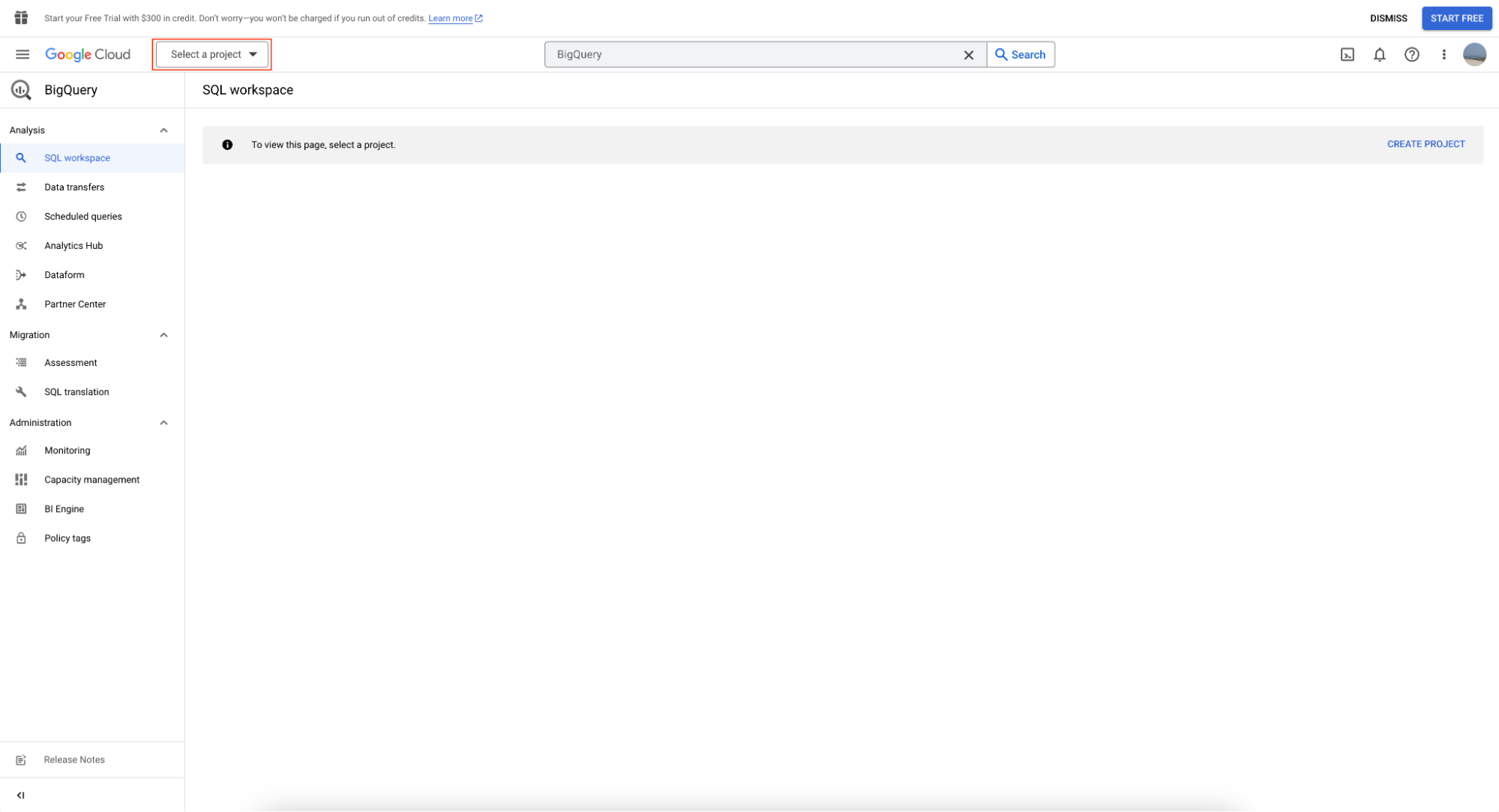
จากนั้นคลิก ‘New Project’:
ต้องระบุชื่อโปรเจกต์ สำหรับคู่มือนี้ เราใช้ datacamp-guide-project

ขณะนี้จะแสดงประกาศ sandbox บนหน้า BigQuery แสดงว่าเปิดใช้ BigQuery sandbox สำเร็จแล้ว

เมื่อเปิดใช้ BigQuery sandbox แล้ว สามารถใช้โปรเจกต์ใหม่เพื่อโหลดข้อมูลและคิวรี รวมถึงคิวรีชุดข้อมูลสาธารณะของ Google ได้
ก่อนสร้างตาราง ต้องสร้าง dataset ในโปรเจกต์ใหม่ก่อน Dataset เป็นคอนเทนเนอร์ระดับบนสุดสำหรับจัดระเบียบและควบคุมการเข้าถึงชุดของตารางและมุมมอง หากต้องการสร้าง dataset ให้คลิกไอคอน ‘Actions’ ของโปรเจกต์:
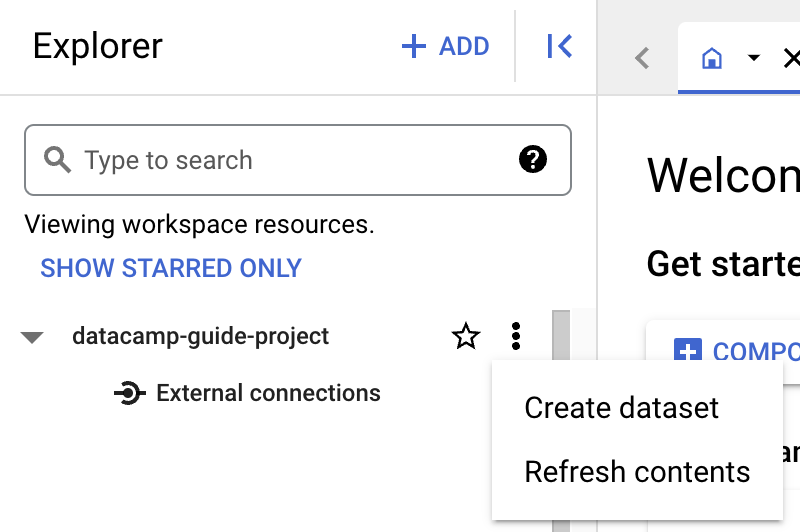
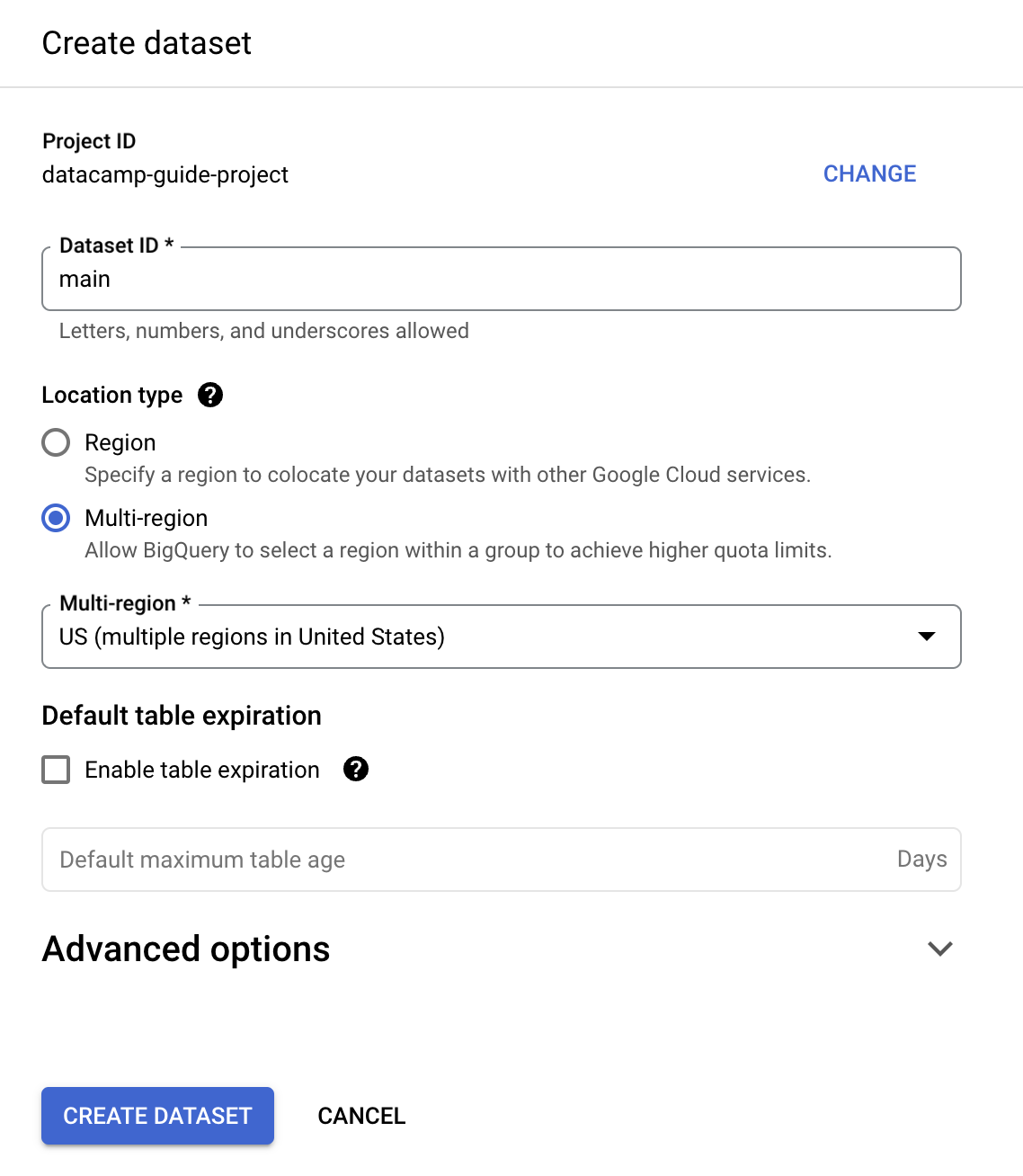
ในคู่มือนี้ เราจะกรอก ‘Dataset ID’ เป็น ‘main’
สามารถสร้างตารางด้วย SQL ได้ BigQuery ใช้ GoogleSQL ซึ่งสอดคล้องตาม ANSI
CREATE TABLE datacamp-guide-project.main.users (
id INT64 NOT NULL,
first_name STRING NOT NULL,
middle_name STRING,
last_name STRING NOT NULL,
active_account BOOL NOT NULL
);หรือจะใช้ส่วนติดต่อผู้ใช้ของ BigQuery Console ก็ได้:
หมายเหตุ: ไม่สามารถแทรกข้อมูลในสภาพแวดล้อม sandbox ได้ หากต้องการลองแทรกข้อมูล ต้องเปิดใช้งานช่วงทดลองใช้งานฟรี ส่วนถัดไปจะเน้นการคิวรีชุดข้อมูลสาธารณะที่มีให้ใน Google Cloud
หากต้องการคิวรีชุดข้อมูลสาธารณะ ให้ทำตามขั้นตอนด้านล่าง:
1. คลิก ‘Add’ ข้าง Explorer

2. จากนั้นเลือกชุดข้อมูล
3. ค้นหา ‘Google Trends’ แล้วเลือก Google Trends จากนั้นคลิกปุ่ม ‘View dataset’

4. bigquery-public-data จะปรากฏพร้อมรายการชุดข้อมูลยาว ๆ ให้ติดดาว bigquery-public-data เพื่อให้ “ปักหมุด” ใน Explorer
เราจะใช้ตาราง top_terms:

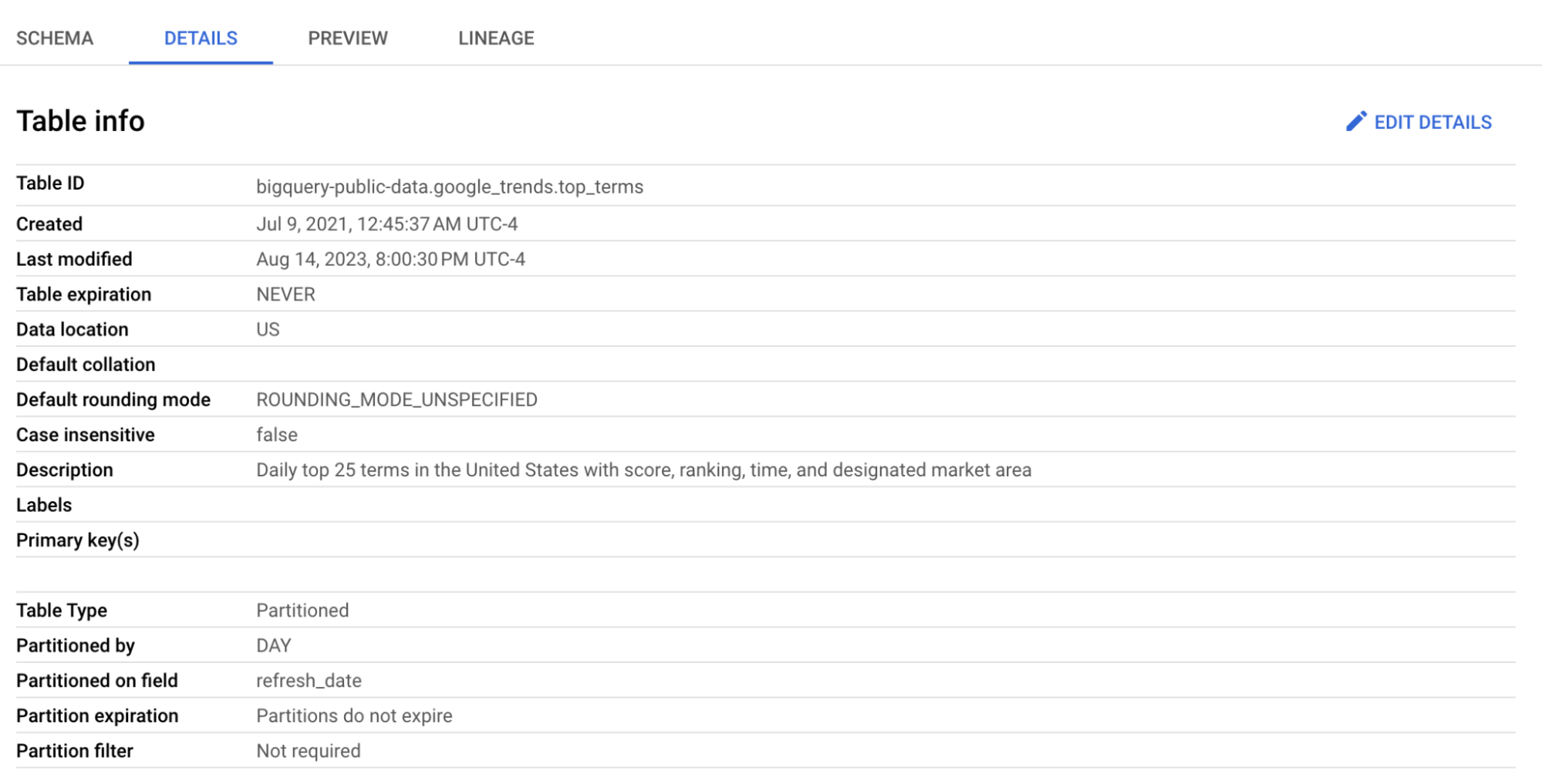
คลิกที่ตาราง top_terms เพื่อเปิด และตรวจดูแท็บ Details และ Preview เพื่อเรียนรู้เพิ่มเติมเกี่ยวกับข้อมูลใน top_terms
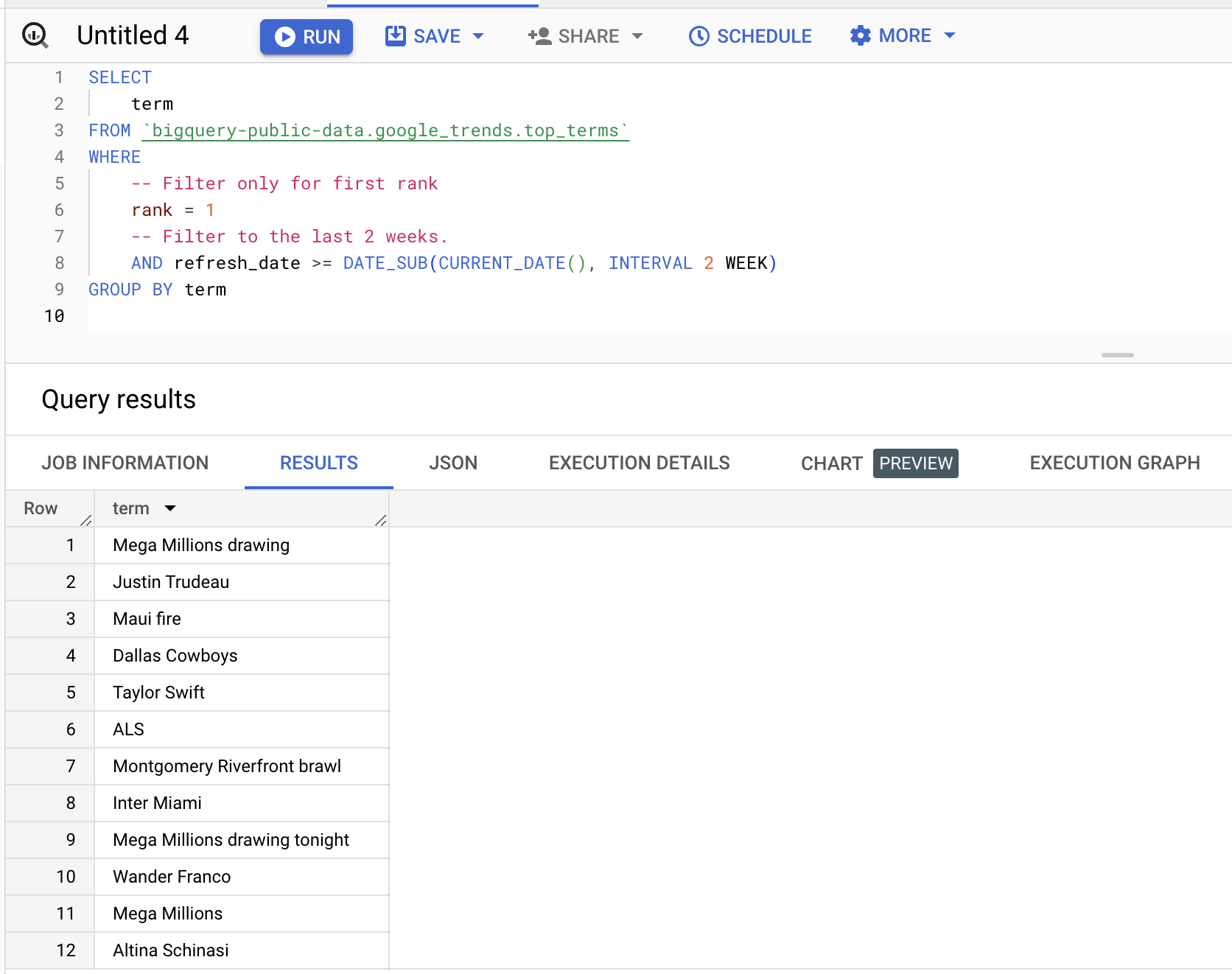
สามารถคิวรีชุดข้อมูลได้ ตัวอย่างด้านล่างดึงคำค้นที่ติดอันดับหนึ่งในช่วงสองสัปดาห์ที่ผ่านมา:
SELECT
term
FROM
bigquery-public-data.google_trends.top_terms
WHERE
rank = 1
AND refresh_date >= DATE_SUB(CURRENT_DATE(), INTERVAL 2 WEEK)
GROUP BY
termผลลัพธ์ (อาจแตกต่างกัน):
โครงสร้างราคาของ BigQuery มีสองส่วนหลัก: การประมวลผลคิวรี และที่จัดเก็บข้อมูล
| องค์ประกอบ | โควต้าฟรี | ราคาที่ต้องชำระ |
|---|---|---|
| คิวรีแบบ On-demand | 1 TiB ต่อเดือน | $6.25 ต่อ TiB |
| ที่จัดเก็บ (แบบใช้งาน) | 10 GiB | $0.02 ต่อ GiB/เดือน |
| ที่จัดเก็บ (ระยะยาว) | 10 GiB | $0.01 ต่อ GiB/เดือน |
| การแทรกแบบสตรีมมิง | N/A | $0.05 ต่อ 200 MB |
สำหรับทีมที่มีภาระงานคาดการณ์ได้ BigQuery มีราคาแบบเหมาจ่ายผ่านการจองขีดความสามารถ (BigQuery Editions) ตรวจสอบอัตราปัจจุบันได้ที่ หน้าอัตราค่าบริการอย่างเป็นทางการ
BigQuery เป็นหนึ่งในจุดเริ่มต้นที่เข้าถึงได้มากที่สุดสำหรับคลังข้อมูลบนคลาวด์ Sandbox ให้สภาพแวดล้อมที่ปราศจากความเสี่ยงสำหรับการทดลองใช้งาน และโควตาคิวรีฟรี 1 TiB ต่อเดือนช่วยให้สำรวจชุดข้อมูลสาธารณะได้โดยไม่ต้องเสียค่าใช้จ่าย เมื่อถึงเวลาต้องการมากขึ้น ช่วงทดลองใช้งานฟรีของ Google Cloud มีเครดิตให้ $300
หากต้องการต่อยอดจากที่เรียนรู้ ที่แนะนำคือคอร์ส Introduction to BigQuery บน DataCamp ซึ่งครอบคลุมการปรับแต่งคิวรีและการทำงานกับชุดข้อมูลขนาดใหญ่ สำหรับมุมมองกว้างด้านวิศวกรรมข้อมูล เส้นทาง Data Engineer in Python ครอบคลุมตั้งแต่การรับเข้าข้อมูลจนถึงคลังข้อมูล
ยังสามารถสำรวจการเปรียบเทียบ BigQuery กับทางเลือกอื่นได้ในบทความ BigQuery vs Redshift และ BigQuery vs Snowflake หรือเตรียมตัวสัมภาษณ์ด้วย คู่คำถามสัมภาษณ์ BigQuery
เริ่มต้นเส้นทางวิศวกรรมข้อมูลวันนี้!
Tracks
Courses
Courses