Programa
Fundamentos de machine learning Em Python
16 h
Neste tutorial, aprenderemos sobre o DeepChecks e como usá-lo para realizar validação de dados e testes de machine learning. Também usaremos o GitHub Actions para automatizar o teste do modelo e salvar os resultados como artefatos.
À medida que progredirmos, aprenderemos sobre os testes de machine learning e o DeepChecks, executaremos o conjunto de integridade de dados do DeepChecks e geraremos um relatório abrangente. Também geraremos relatórios de teste de machine learning executando um conjunto de avaliação de modelo, aprenderemos a executar um único teste em vez de um conjunto completo, automatizaremos nosso fluxo de trabalho de teste usando o GitHub Actions e salvaremos o relatório de teste de machine learning como um artefato do GitHub.

Imagem do autor
O teste de aprendizado de máquina é um processo crítico que envolve a avaliação e a validação do desempenho dos modelos de aprendizado de máquina para garantir sua imparcialidade, precisão e robustez. Não se trata apenas de precisão e desempenho do modelo. Temos que analisar as tendências do modelo, os falsos positivos, os falsos negativos, várias métricas de desempenho, o rendimento do modelo e o alinhamento do modelo com a ética da IA.
O processo de teste inclui vários tipos de avaliações, como validação de dados, validação cruzada, pontuação F1, matriz de confusão, desvio de previsão, desvio de dados e teste de robustez, cada um projetado para verificar diferentes aspectos do desempenho e da confiabilidade do modelo.
Também dividimos nosso conjunto de dados em três partes para que possamos avaliar o modelo durante o processo de treinamento e após o processo de treinamento em um conjunto de dados não visto.
O teste de machine learning é uma parte essencial dos aplicativos de IA, e automatizá-lo junto com o treinamento de modelos nos dará sistemas de IA confiáveis que funcionam para as pessoas.
Se você é novo no machine learning e deseja aprender o básico, faça o curso Fundamentos de machine learning com o programa de habilidades Python. Este curso ensinará a você os fundamentos do machine learning com Python, começando com o aprendizado supervisionado usando a biblioteca scikit-learn.
DeepChecks é um pacote Python de código aberto projetado para facilitar o teste e a validação abrangentes de modelos e dados de machine learning. Ele oferece uma ampla gama de verificações integradas para identificar problemas relacionados ao desempenho do modelo, à distribuição de dados, à integridade dos dados e muito mais. O DeepChecks inclui funcionalidades para validação contínua, garantindo que os modelos permaneçam confiáveis e eficazes à medida que são implantados e usados em cenários do mundo real.
Começaremos instalando o pacote Python usando o comando pip.
%pip install deepchecks --upgrade -qPara este tutorial, estamos usando o Dados de empréstimo dos conjuntos de dados do DataCamp. Ele consiste em 9578 linhas e informações sobre a estrutura do empréstimo, o mutuário e se o empréstimo foi pago integralmente.
Carregue o arquivo CSV usando o Pandas e exiba as 5 primeiras linhas.
import pandas as pd
loan_data = pd.read_csv("loan_data.csv")
loan_data.head()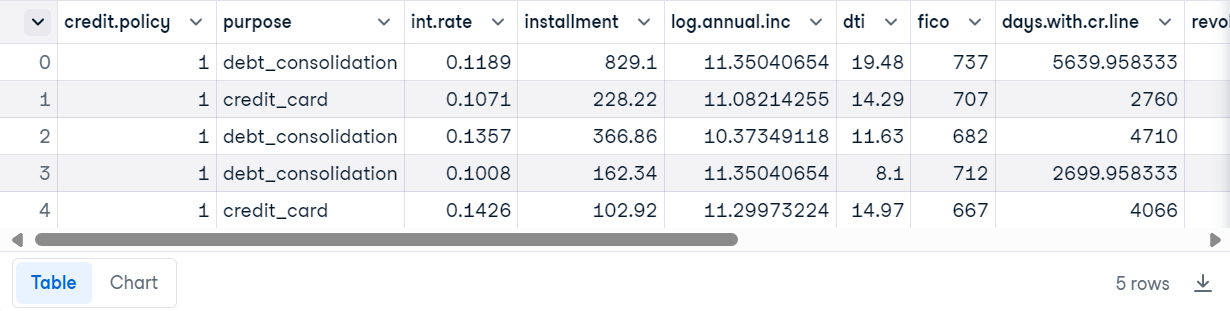
Crie o conjunto de dados DeepChecks usando o conjunto de dados de empréstimo, o nome da coluna de rótulo e o nome do recurso categórico.
from sklearn.model_selection import train_test_split
from deepchecks.tabular import Dataset
label_col = 'not.fully.paid'
deep_loan_data = Dataset(loan_data, label=label_col, cat_features=["purpose"])Usaremos um conjunto de integridade de dados para dados tabulares. A suíte executará todos os testes de forma autônoma e gerará um relatório interativo com os resultados.
Para isso, importaremos o conjunto de integridade de dados, o iniciaremos e, em seguida, executaremos o conjunto fornecendo a ele os dados de empréstimo do DeepChecks. Por fim, exibiremos os resultados.
from deepchecks.tabular.suites import data_integrity
integ_suite = data_integrity()
suite_result = integ_suite.run(deep_loan_data)
suite_result.show()Observação: Estamos usando o DataLab como ambiente de desenvolvimento. O uso do ipywidgets foi desativado, impedindo-o de exibir os resultados. Em vez disso, utilizaremos a função "show_in_iframe" para exibir o resultado como um iframe. Os resultados serão os mesmos em todos os níveis.
suite_result.show_in_iframe()Nosso relatório de integridade de dados inclui resultados de testes sobre:
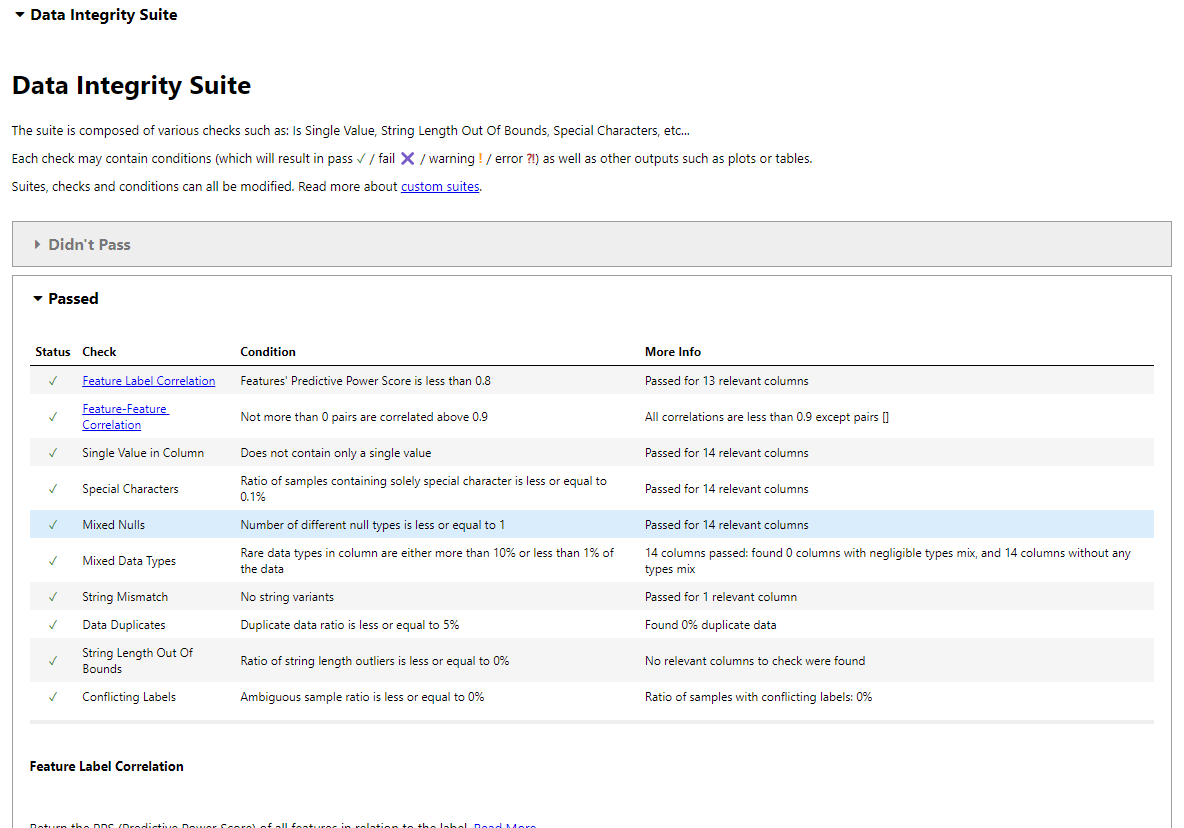
Resultados do teste de integridade de dados no Jupyter Notebook.
Você pode até mesmo salvar os resultados como um arquivo HTML e compartilhá-lo com seus colegas.
suite_result.save_as_html()'output.html'Executar todo o conjunto de dados em um grande conjunto de dados não é uma maneira eficiente, pois levará muito tempo para gerar os resultados. Em vez disso, você pode executar alguns testes individuais que sejam relevantes para seus dados e gerar um relatório por conta própria.
Para executar um único teste, importe as verificações tabulares, inicialize a verificação e execute-a com os dados do DeepCheck Loan. Depois disso, exiba os valores em vez de gerar um relatório interativo usando a função results.value.
from deepchecks.tabular.checks import IsSingleValue, DataDuplicates
result = IsSingleValue().run(deep_loan_data)
result.valueComo você pode ver, ele exibe o número de valores exclusivos presentes em cada coluna.
{'credit.policy': 2,
'purpose': 7,
'int.rate': 249,
'installment': 4788,
'log.annual.inc': 1987,
'dti': 2529,
'fico': 44,
'days.with.cr.line': 2687,
'revol.bal': 7869,
'revol.util': 1035,
'inq.last.6mths': 28,
'delinq.2yrs': 11,
'pub.rec': 6,
'not.fully.paid': 2}Vamos tentar verificar amostras duplicadas em nossos dados.
result = DataDuplicates().run(deep_loan_data)
result.valueNão temos nenhuma duplicata em nosso conjunto de dados.
0.0Nesta seção, reuniremos vários modelos e os treinaremos no conjunto de dados de carga processada. Em seguida, para gerar um relatório de teste de modelo, executaremos um conjunto de avaliação de modelo nos conjuntos de dados de treinamento e teste.
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import VotingClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.preprocessing import LabelEncoder
# Train test split
df_train, df_test = train_test_split(loan_data, stratify=loan_data[label_col], random_state=0)
# Encode the 'purpose' column
label_encoder = LabelEncoder()
df_train['purpose'] = label_encoder.fit_transform(df_train['purpose'])
df_test['purpose'] = label_encoder.fit_transform(df_test['purpose'])
# Define models
model_1 = LogisticRegression(random_state=1, max_iter=10000)
model_2 = RandomForestClassifier(n_estimators=50, random_state=1)
model_3 = GaussianNB()
# Create the VotingClassifier
clf_model = VotingClassifier(
estimators=[('lr', model_1), ('rf', model_2), ('svc', model_3)],
voting='soft'
)
# Train the model
clf_model.fit(df_train.drop(label_col, axis=1), df_train[label_col])
Executaremos o conjunto de avaliação do modelo DeepChecks para avaliar o desempenho do modelo.
from deepchecks.tabular.suites import model_evaluation
deep_train = Dataset(df_train, label=label_col, cat_features=[])
deep_test = Dataset(df_test, label=label_col, cat_features=[])
evaluation_suite = model_evaluation()
suite_result = evaluation_suite.run(deep_train, deep_test, clf_model)
suite_result.show_in_iframe()Nosso relatório de avaliação de modelos inclui resultados de testes em:

to_json(). suite_result.to_json()Assim como na validação de dados, você pode executar um único teste de machine learning. No nosso caso, executaremos o desvio de rótulo na divisão de treinamento e teste para verificar se nossos rótulos mudaram com o tempo.
from deepchecks.tabular.checks import LabelDrift
check = LabelDrift()
result = check.run(deep_train, deep_test)
result.valueNão foi detectado nenhum desvio nos dados.
{'Drift score': 0.0, 'Method': "Cramer's V"}Se você estiver com dificuldades para executar os conjuntos de validação de dados e avaliação de modelos, consulte o espaço de trabalho do DataLab em Se você tiver dificuldades em executar os conjuntos de validação de dados e avaliação de modelos, consulte o espaço de trabalho do DataLab em.
Se você estiver interessado em testes "manuais" de machine learning, siga o guia Experimentação de machine learning para saber como estruturar, registrar e analisar seus experimentos de machine learning usando Weights & Biases.
Vamos automatizar a validação de dados, o treinamento do modelo e a fase de avaliação do modelo com o GitHub Actions e salvar os resultados como um arquivo zip.
A automação dos testes de machine learning é parte integrante do pipeline de MLOps. Para saber mais sobre isso, você pode fazer o curso Fundamentos de MLOps programa de habilidades. Nesta série de cursos, você aprenderá sobre os princípios fundamentais para colocar os modelos de machine learning em produção e monitorá-los para oferecer valor comercial.
$ cd C:\Repository\GitHub\
$ git clone https://github.com/kingabzpro/Automating-Machine-Learning-Testing.git
$ cd .\Automating-Machine-Learning-Testing\
$ mkdir data
$ mv -v ".Downloads\loan_data.csv" ".\Automating-Machine-Learning-Testing\data"
$ code -r data_validation.pyimport pandas as pd
from deepchecks.tabular import Dataset
from deepchecks.tabular.suites import data_integrity
# Load the loan data from a CSV file
loan_data = pd.read_csv("data/loan_data.csv")
# Define the label column
label_col = "not.fully.paid"
# Create a Deepchecks Dataset object with the loan data
deep_loan_data = Dataset(loan_data, label=label_col, cat_features=["purpose"])
# Initialize the data integrity suite
integ_suite = data_integrity()
# Run the data integrity suite on the dataset
suite_result = integ_suite.run(deep_loan_data)
# Save the results of the data integrity suite as an HTML file
suite_result.save_as_html("results/data_validation.html")$ code -r train_validation.pyimport pandas as pd
from sklearn.ensemble import RandomForestClassifier, VotingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import GaussianNB
from sklearn.preprocessing import LabelEncoder, StandardScaler
from deepchecks.tabular import Dataset
from deepchecks.tabular.suites import model_evaluation
# Load the loan data from a CSV file
loan_data = pd.read_csv("data/loan_data.csv")
# Define the label column
label_col = "not.fully.paid"
# Train test split
df_train, df_test = train_test_split(
loan_data, stratify=loan_data[label_col], random_state=0
)
# Encode the 'purpose' column
label_encoder = LabelEncoder()
df_train["purpose"] = label_encoder.fit_transform(df_train["purpose"])
df_test["purpose"] = label_encoder.transform(df_test["purpose"])
# Standardize the features
scaler = StandardScaler()
df_train[df_train.columns.difference([label_col])] = scaler.fit_transform(df_train[df_train.columns.difference([label_col])])
df_test[df_test.columns.difference([label_col])] = scaler.transform(df_test[df_test.columns.difference([label_col])])
# Define models
model_1 = LogisticRegression(random_state=1, max_iter=10000)
model_2 = RandomForestClassifier(n_estimators=50, random_state=1)
model_3 = GaussianNB()
# Create the VotingClassifier
clf_model = VotingClassifier(
estimators=[("lr", model_1), ("rf", model_2), ("gnb", model_3)], voting="soft"
)
# Train the model
clf_model.fit(df_train.drop(label_col, axis=1), df_train[label_col])
# Calculate the accuracy score using the .score function
accuracy = clf_model.score(df_test.drop(label_col, axis=1), df_test[label_col])
# Print the accuracy score
print(f"Accuracy: {accuracy:.2f}")
# Create Deepchecks datasets
deep_train = Dataset(df_train, label=label_col, cat_features=["purpose"])
deep_test = Dataset(df_test, label=label_col, cat_features=["purpose"])
# Run the evaluation suite
evaluation_suite = model_evaluation()
suite_result = evaluation_suite.run(deep_train, deep_test, clf_model)
# Save the results as HTML
suite_result.save_as_html("results/model_validation.html")Se você for novo no GitHub Actions, conclua o tutorial "GitHub Actions e MakeFile: A Hands-on Introduction" antes de iniciar o processo de automação. Este tutorial fornecerá uma compreensão detalhada de como o GitHub Actions funciona com exemplos de código.
$ git add .
$ git commit -m "Data and Validation files"
$ git push
main.yml do fluxo de trabalho. Copie e cole o código a seguir. O código abaixo primeiro configurará o ambiente e instalará o pacote DeepChecks. Depois disso, ele criará a pasta, executará a validação de dados e a avaliação do modelo e salvará os resultados como um artefato do GitHub.name: Model Training and Validation
on:
push:
branches: [ main ]
pull_request:
branches: [ main ]
jobs:
build:
runs-on: ubuntu-latest
steps:
- name: Checkout Repository
uses: actions/checkout@v4
- name: Set up Python 3.10
uses: actions/setup-python@v5
with:
python-version: '3.10'
- name: Install dependencies
run: |
python -m pip install --upgrade pip
pip install deepchecks
- name: Create a folder
run: |
mkdir -p results
- name: Validate Data
run: |
python data_validation.py
- name: Validate Model Performance
run: |
python train_validation.py
- name: Archive Deepchecks Results
uses: actions/upload-artifact@v4
if: always()
with:
name: deepchecks results
path: results/*_validation.html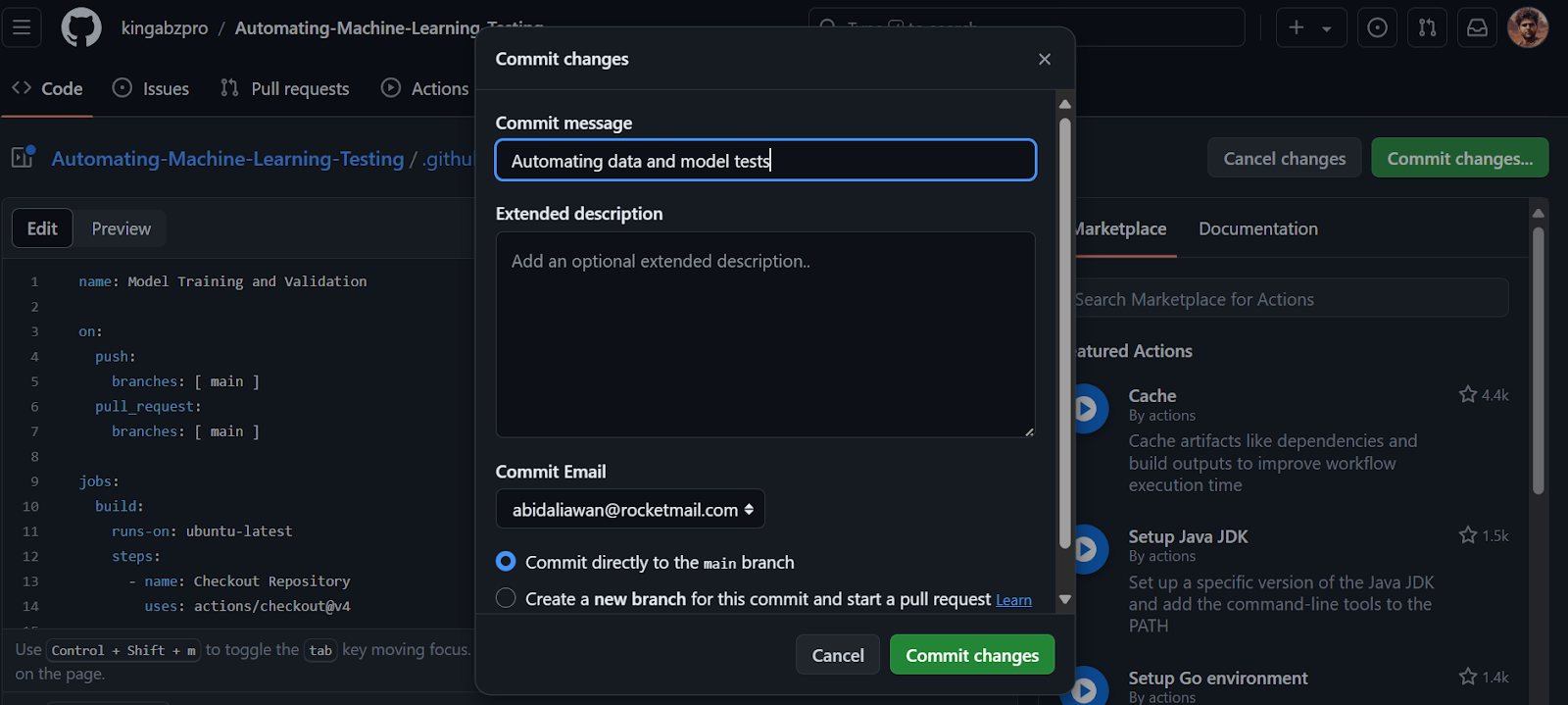
Ao confirmar as alterações na ramificação principal, a execução do fluxo de trabalho será iniciada. Para visualizar o registro de execução, navegue até a guia "Ações" e clique na execução atual do fluxo de trabalho associada à mensagem de confirmação.
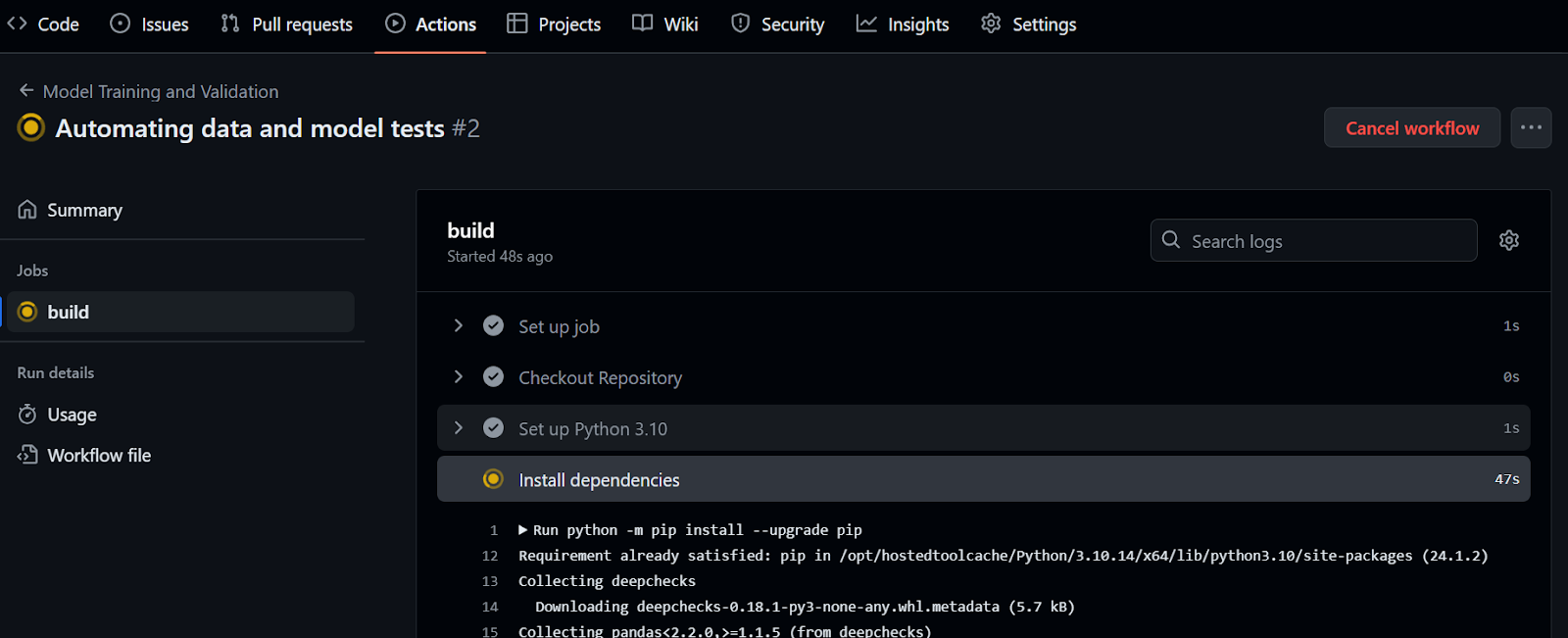
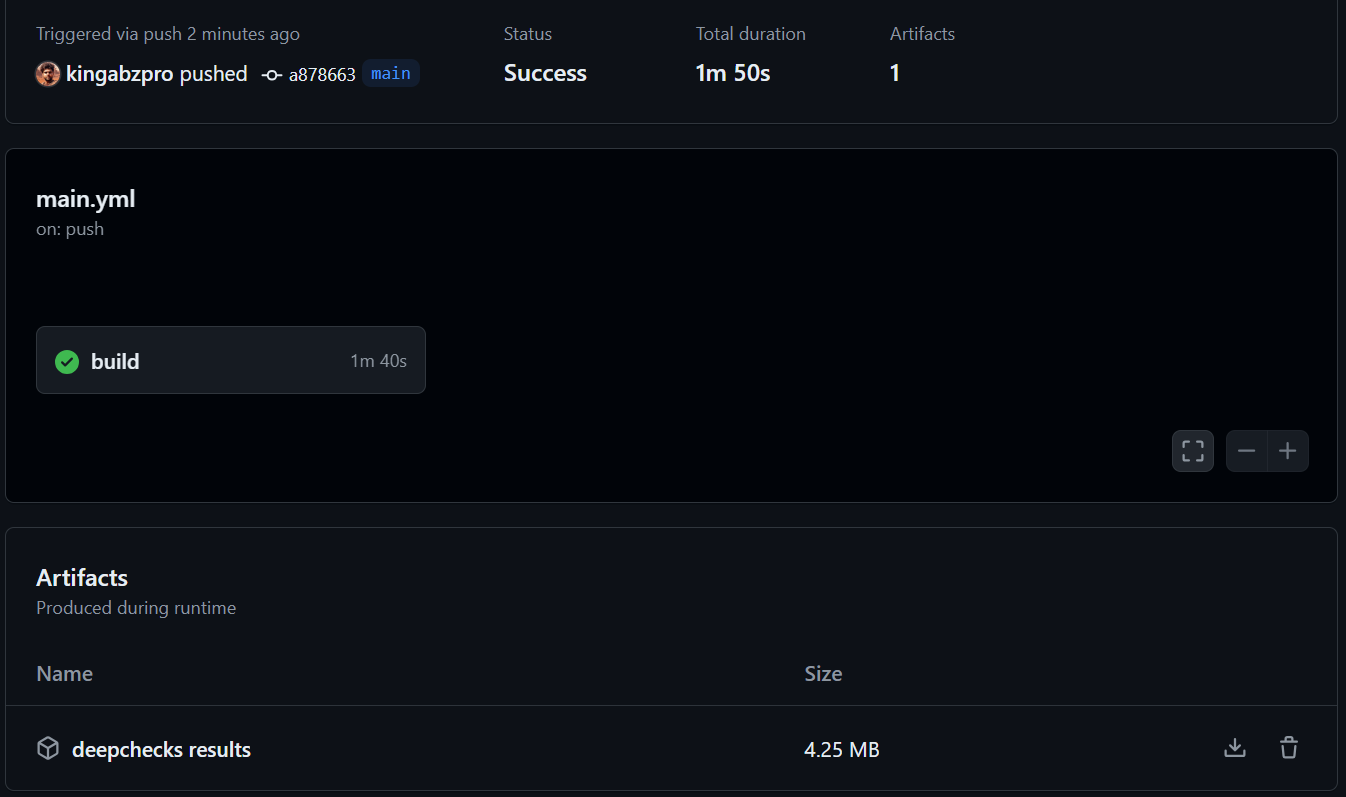
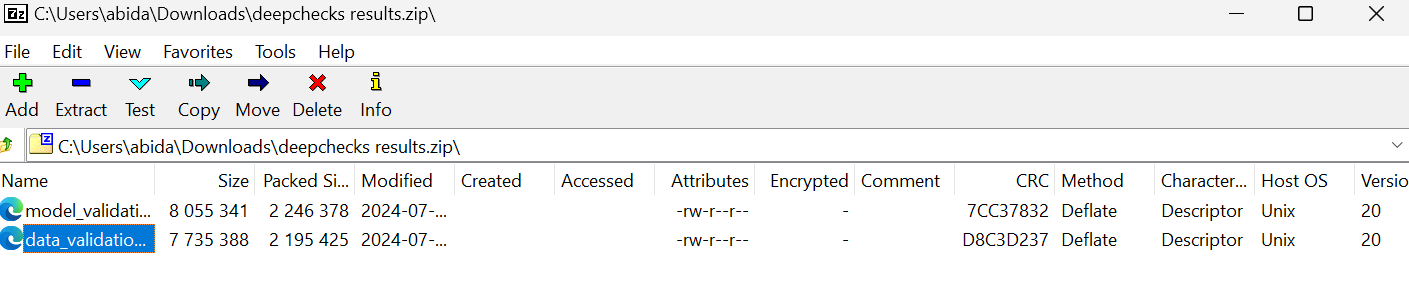
Dê uma olhada em kingabzpro/Automating-Machine-Learning-Testing no repositório GitHub como um guia. Ele contém dados, código Python, arquivos de fluxo de trabalho e outros arquivos necessários para que você possa executar testes totalmente automatizados.
Para automatizar todo o pipeline de machine learning, você precisa ter conhecimento de vários processos e ferramentas. Para saber mais sobre isso, considere fazer um curso de Implantação e ciclo de vida do MLOps do MLOps. Este curso explora as estruturas modernas de MLOps, com foco no ciclo de vida e na implementação de modelos de machine learning.
Ao automatizar o processo de teste, os desenvolvedores podem validar de forma rápida e eficiente a precisão e a robustez dos modelos em relação a conjuntos de dados grandes e complexos. Os testes automatizados ajudam a identificar problemas antecipadamente, como inconsistências de dados, desvios de dados e vieses de modelos, que podem não ser aparentes por meio de testes manuais. Isso economiza tempo e aumenta a capacidade do modelo de fazer previsões justas e precisas.
Neste tutorial, aprendemos sobre testes de machine learning e como usar o DeepChecks para validação de dados e testes de machine learning. Também automatizamos os testes de dados e modelos e salvamos os resultados como artefatos usando o GitHub Actions.
Se você gostou do tutorial e está interessado em iniciar uma carreira em machine learning, considere a possibilidade de se inscrever no curso Cientista de Machine Learning com Python programa de carreira. Conclua todos os cursos em 3 meses para adquirir as habilidades que você precisa para um emprego como cientista de machine learning.
Principais cursos de machine learning
Programa
Programa
Curso
blog
Austin Chia
blog
Abid Ali Awan
5 min
Tutorial
Zoumana Keita
Tutorial
Zoumana Keita


