Curso
Introdução a funções em Python
3 h
466.7K
Os aplicativos Python, especialmente aqueles que lidam com grandes conjuntos de dados ou cálculos complexos, podem consumir memória excessiva, levando a lentidão, falhas ou erros de falta de memória. A criação de perfil de memória é uma técnica que permite que você analise o uso de memória do seu código Python, identifique vazamentos de memória e gargalos e otimize o consumo de memória para melhorar o desempenho e a estabilidade.
Neste tutorial, exploraremos a criação de perfil de memória, as ferramentas disponíveis e exemplos práticos de como você pode usar essas ferramentas para criar um perfil do seu código Python.
O perfil de memória é a técnica de monitorar e avaliar a utilização da memória de um programa durante a execução. Esse método ajuda os desenvolvedores a encontrar vazamentos de memória, otimizar a utilização da memória e compreender os padrões de consumo de memória de seus programas. A criação de perfis de memória é fundamental para evitar que os aplicativos usem mais memória do que o necessário e causem lentidão no desempenho ou falhas.
A criação de perfis de memória oferece várias vantagens importantes que são essenciais para manter aplicativos eficientes e robustos:
Vamos explorar várias ferramentas populares de criação de perfil de memória, detalhando seus recursos, instalação e uso. Especificamente, examinaremos ferramentas como memory_profiler para análise de memória linha por linha, tracemalloc para obter e comparar instantâneos de memória e objgraph para visualizar relações entre objetos.
memory_profiler é uma ferramenta poderosa em Python que fornece informações detalhadas sobre o uso de memória do seu código. Ele funciona fornecendo um detalhamento granular, linha por linha, do uso da memória, o que é útil para identificar as linhas exatas de código responsáveis pelo alto consumo de memória. Ao compreender o uso da memória nesse nível de detalhe, os desenvolvedores podem tomar decisões informadas sobre onde concentrar seus esforços de otimização.
Para instalar o memory_profiler e os pacotes adicionais necessários, siga estas etapas:
O comando a seguir instala o pacote memory_profiler:
pip install memory_profilerSe quiser visualizar o uso da memória com gráficos, você pode instalar o matplotlib executando:
pip install matplotlibPara usar o site memory_profiler, siga estas etapas:
Decoramos as funções que desejamos definir como perfil.
Abra seu script Python em um editor de texto ou IDE.
Importe o decorador de perfil de memory_profiler e aplique-o às funções que você deseja criar um perfil.
Aqui está um exemplo de script:
from memory_profiler import profile
@profile
def allocate_memory():
# Allocate a list with a range of numbers
a = [i for i in range(10000)]
# Allocate another list with squares of numbers
b = [i ** 2 for i in range(10000)]
return a, b
if __name__ == "__main__":
allocate_memory()Eu importo o decorador de perfil do pacote memory_profiler aqui. Esse decorador nos ajudará a monitorar o uso da memória da função decorada.
from memory_profiler import profileAplico o decorador @profile à função allocate_memory(). Isso significa que, quando o allocate_memory() for executado, o memory_profiler rastreará o uso da memória e fornecerá um relatório detalhado.
@profileDentro da função allocate_memory(), crio duas listas. A primeira lista contém números de 0 a 9999; a segunda lista contém os quadrados dos números de 0 a 9999.
a = [i for i in range(10000)] # List of numbers from 0 to 9999
b = [i**2 for i in range(10000)] # List of squares of numbers from 0 to 9999O bloco a seguir garante que a função allocate_memory() seja chamada somente quando o script for executado diretamente, e não quando for importado como um módulo. Quando você executar esse script, memory_profiler exibirá o uso da memória da função allocate_memory(), permitindo que você veja quanta memória é usada durante a criação das duas listas, a e b.
if __name__ == "__main__":
allocate_memory()No terminal ou no prompt de comando, navegue até o diretório em que o script está localizado. Execute seu script com a opção -m memory_profiler.
-m memory_profiler your_script.py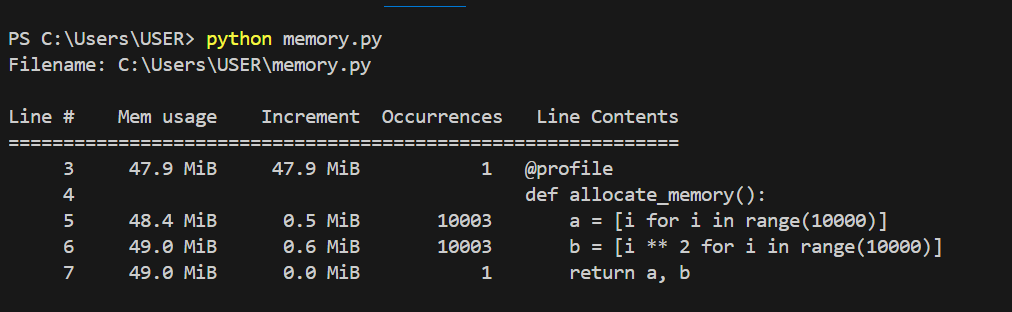
Uso de memória para cada linha de código. Imagem do autor.
No gráfico acima, podemos ver o uso de memória de cada linha de código e os incrementos para cada linha de código. O gráfico abaixo mostra como cada linha usa a memória em mais detalhes e como ela aumenta a cada iteração.
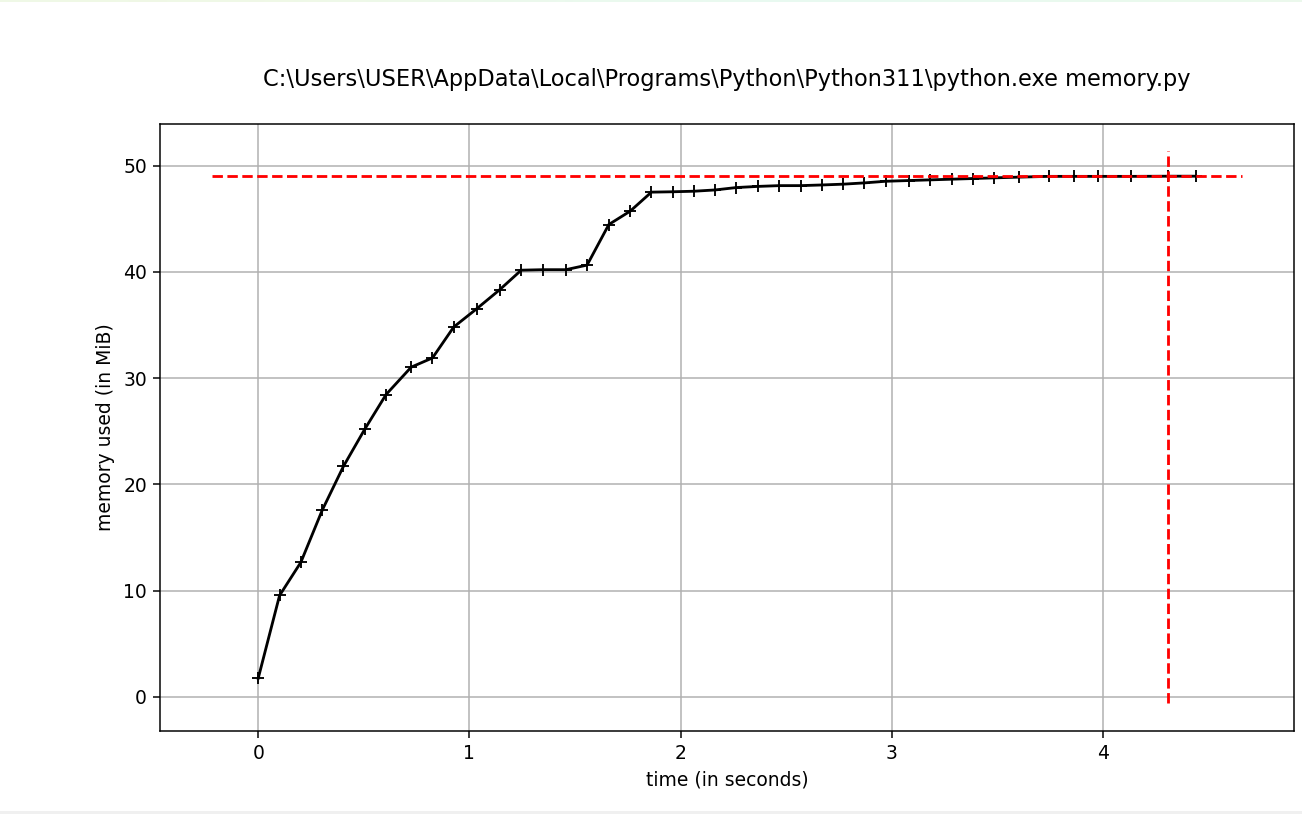
Uso da memória ao longo do tempo. Imagem do autor.
tracemalloc é um poderoso módulo interno do Python que rastreia as alocações e desalocações de memória. Entender como seu aplicativo usa a memória é fundamental para otimizar o desempenho e identificar vazamentos de memória. O Tracemalloc oferece uma interface fácil de usar para capturar e analisar instantâneos de uso de memória, o que o torna uma ferramenta inestimável para qualquer desenvolvedor Python.
Vamos examinar como o site tracemalloc tira instantâneos do uso da memória, compara esses instantâneos para identificar vazamentos de memória e, em seguida, analisa os principais consumidores de memória
tracemalloc permite que você tire instantâneos do uso da memória em pontos específicos do seu programa. Um instantâneo captura o estado das alocações de memória, fornecendo uma visão detalhada de onde a memória é usada.
Veja como você pode tirar um instantâneo com tracemalloc:
import tracemalloc
# Start tracing memory allocations
tracemalloc.start()
# Code block for which memory usage is to be tracked
def allocate_memory():
a = [i for i in range(10000)] # List of numbers from 0 to 9999
b = [i**2 for i in range(10000)] # List of squares of numbers from 0 to 9999
return a, b
# Keep the allocated lists in scope
allocated_lists = allocate_memory()
# Take a snapshot
snapshot = tracemalloc.take_snapshot()
# Stop tracing memory allocations
tracemalloc.stop()
# Analyze the snapshot to see memory usage
top_stats = snapshot.statistics('lineno')
# Write the memory usage data to a text file
with open('memory_usage.txt', 'w') as f:
f.write("[ Top 10 memory consumers ]\n")
for stat in top_stats[:10]:
f.write(f"{stat}\n")
# Detailed traceback for the top memory consumer
f.write("\n[ Detailed traceback for the top memory consumer ]\n")
for stat in top_stats[:1]:
f.write('\n'.join(stat.traceback.format()) + '\n')
print("Memory usage details saved to 'memory_usage.txt'")Eu programei e examinei o uso da memória em meu aplicativo Python usando o módulo tracemalloc. Ao tirar um instantâneo das alocações de memória e observar os principais consumidores de memória, determinei quais seções do meu código usavam mais memória. Em seguida, coloco essa análise em um arquivo de texto para leitura e referência adicionais.
Um dos recursos mais avançados do tracemalloc é a capacidade de comparar instantâneos obtidos em diferentes pontos do programa para identificar vazamentos de memória. Ao analisar as diferenças entre os instantâneos, você pode identificar onde a memória adicional está sendo alocada e não liberada.
Veja como você pode comparar instantâneos:
import tracemalloc
# Start tracing memory allocations
tracemalloc.start()
# Function to allocate memory
def allocate_memory():
a = [i for i in range(10000)] # List of numbers from 0 to 9999
b = [i**2 for i in range(10000)] # List of squares of numbers from 0 to 9999
return a, b
# Initial memory usage snapshot
snapshot1 = tracemalloc.take_snapshot()
# Perform memory allocations
allocated_lists = allocate_memory()
# Memory usage snapshot after allocations
snapshot2 = tracemalloc.take_snapshot()
# Further memory allocations (simulate more work to find potential leaks)
allocated_lists += allocate_memory()
# Memory usage snapshot after additional allocations
snapshot3 = tracemalloc.take_snapshot()
# Stop tracing memory allocations
tracemalloc.stop()
# Compare the snapshots
stats1_vs_2 = snapshot2.compare_to(snapshot1, 'lineno')
stats2_vs_3 = snapshot3.compare_to(snapshot2, 'lineno')
# Save the comparison results to a text file
with open('memory_leak_analysis.txt', 'w') as f:
f.write("[ Memory usage increase from snapshot 1 to snapshot 2 ]\n")
for stat in stats1_vs_2[:10]:
f.write(f"{stat}\n")
f.write("\n[ Memory usage increase from snapshot 2 to snapshot 3 ]\n")
for stat in stats2_vs_3[:10]:
f.write(f"{stat}\n")
# Detailed traceback for the top memory consumers
f.write("\n[ Detailed traceback for the top memory consumers ]\n")
for stat in stats2_vs_3[:1]:
f.write('\n'.join(stat.traceback.format()) + '\n')
print("Memory leak analysis saved to 'memory_leak_analysis.txt'")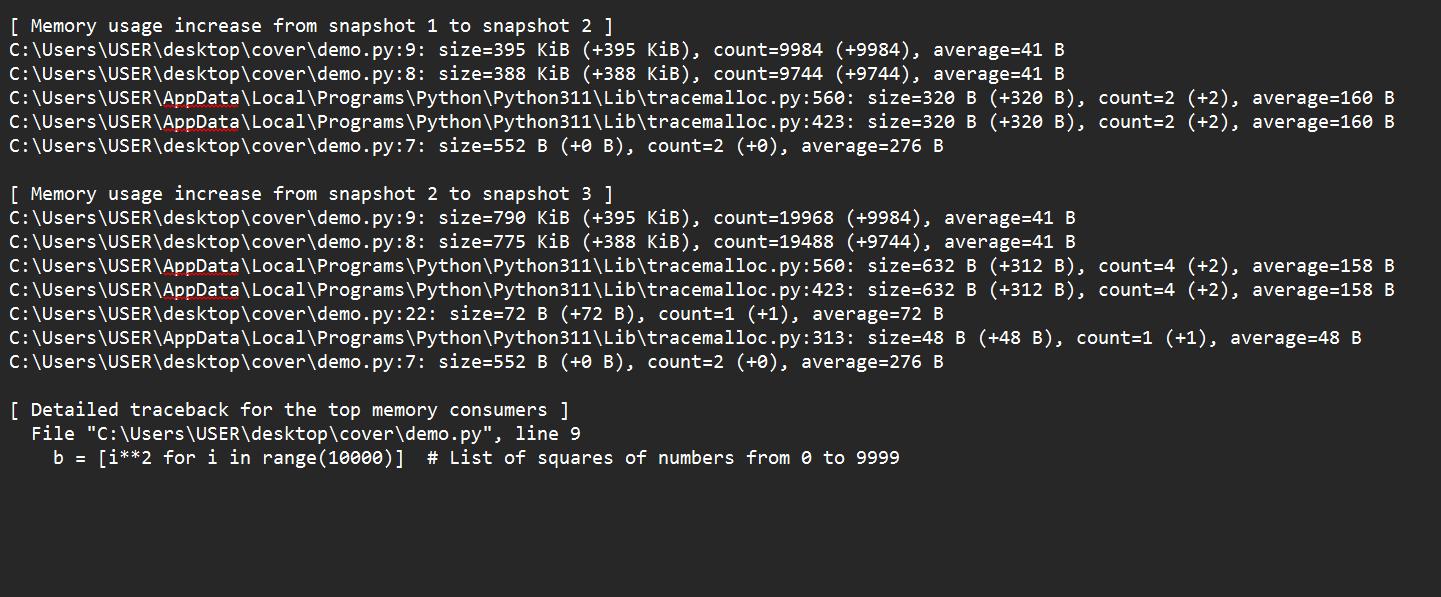
Passando do instantâneo 1 para o instantâneo 2, vemos que o estabelecimento das listas a e b foi a principal causa de um pico no uso da memória. Passando donapshot 2 para o snapshot 3, também vemos que mais alocações das listas a e b aumentaram a utilização da memória.
Ao comparar esses instantâneos, descobrimos que a principal causa do aumento do uso da memória é a alocação recorrente de listas grandes. Essas alocações podem indicar um vazamento de memória se não forem necessárias em aplicativos do mundo real. Um rastreamento abrangente pode identificar as linhas de código exatas que causam essas alocações.
tracemalloc também oferece ferramentas para analisar os principais consumidores de memória do seu aplicativo. Isso pode ajudar você a se concentrar na otimização das partes do seu código que usam mais memória.
Veja como você pode analisar os principais consumidores de memória:
import tracemalloc
# Start tracing memory allocations
tracemalloc.start()
# Code block for which memory usage is to be tracked
def allocate_memory():
a = [i for i in range(10000)]
b = [i**2 for i in range(10000)]
allocate_memory()
# Take a snapshot
snapshot = tracemalloc.take_snapshot()
# Analyze top memory consumers
top_stats = snapshot.statistics('lineno')
print("[ Top 10 memory consumers ]")
for stat in top_stats[:10]:
print(stat)
# Stop tracing memory allocations
tracemalloc.stop()Neste exemplo, depois de tirar um instantâneo, eu uso snapshot. Estatísticas ('lineno') para obter estatísticas sobre o uso da memória agrupadas por número de linha. Essa saída ajuda você a identificar rapidamente quais partes do seu código consomem mais memória, permitindo que você direcione essas áreas para otimização.
Objgraph é uma biblioteca Python projetada para ajudar os desenvolvedores a visualizar e analisar referências a objetos em seu código. Ele fornece ferramentas para criar gráficos visuais que mostram como os objetos na memória fazem referência uns aos outros. Essa visualização é útil para que você compreenda a estrutura e os relacionamentos dentro do programa, identifique vazamentos de memória e otimize o uso da memória.
Primeiro, vamos instalar a biblioteca objgraph. Você pode instalá-lo usando o pip:
pip install objgraphobjgraphobjgraph oferece vários recursos essenciais para a criação e a visualização de perfis de memória:
objgraph, você pode criar representações visuais de objetos e suas referências. Isso ajuda você a entender como os objetos estão interconectados, tornando a depuração e a otimização do código mais acessíveis.Vamos nos aprofundar em alguns exemplos para você ver como o objgraph pode ser usado na prática.
Exemplo 1: Geração de um gráfico de referência de objeto
Suponhamos que você tenha uma classe simples e crie algumas instâncias:
class Node:
def __init__(self, value):
self.value = value
self.children = []
# Create some nodes
node1 = Node(1)
node2 = Node(2)
node3 = Node(3)
# Establish relationships
node1.children.append(node2)
node2.children.append(node3)
import Objgraph
# Generate a graph of object references
objgraph.show_refs([node1], filename='object_refs.png')Neste exemplo, definimos uma classe Node e criamos instâncias de nós com relacionamentos. A função objgraph.show_refs() gera um gráfico visual das referências de objeto a partir de node1 e o salva como object_refs.png. Esse gráfico nos ajuda a entender como os nós estão interconectados.
Exemplo 2: Detecção de referências circulares
Para detectar referências circulares, podemos usar a função objgraph.find_backref_chain():
# Create a circular reference
node 3.children.append(node1)
# Detect circular references
chain = objgraph.find_backref_chain(node1, objgraph.is_proper_module)
objgraph.show_chain(chain, filename='circular_refs.png')Aqui, criamos uma referência circular adicionando o nó1 aos filhos do nó3. A função objgraph.find_backref_chain() detecta essa referência circular e objgraph.show_chain a visualiza, salvando o resultado como circular_refs.png.
Exemplo 3: Análise de tipos e tamanhos de objetos
Para analisar os tipos e tamanhos dos objetos, podemos usar objgraph.show_most_common_types e objgraph.by_type:
# Show the most common object types
objgraph.show_most_common_types()
# Get the details of a specific object type
objs = objgraph.by_type('Node')
objgraph.show_refs(objs[:3], refcounts=True, filename='node_details.png')Neste exemplo, objgraph.show_most_common_types exibe os tipos de objetos mais comuns atualmente na memória. A função objgraph.by_type() recupera todas as instâncias da classe Node e visualizamos suas referências, inclusive as contagens de referência, gerando outro gráfico salvo como node_details.png.
Vamos agora dar uma olhada em várias técnicas para usar as ferramentas de criação de perfil de memória de forma eficaz. Vamos nos concentrar na criação de perfis de funções específicas, no controle do uso geral da memória e na visualização de gráficos de objetos.
Você pode direcionar funções específicas com memory_profiler ou tracemalloc.
memory_profilermemory_profiler oferece uma maneira simples de monitorar o consumo de memória linha por linha em suas funções, ajudando você a identificar as áreas em que o uso de memória pode ser reduzido.
from memory_profiler import profile
@profile
def allocate_memory():
a = [i for i in range(10000)]
b = [i ** 2 for i in range(10000)]
return a, b
if __name__ == "__main__":
allocate_memory()tracemallocimport tracemalloc
tracemalloc.start()
def allocate_memory():
a = [i for i in range(10000)]
b = [i ** 2 for i in range(10000)]
return a, b
allocate_memory()
snapshot = tracemalloc.take_snapshot()
top_stats = snapshot.statistics('lineno')
for stat in top_stats[:10]:
print(stat)Para monitorar o uso total de memória do nosso programa ao longo do tempo, podemos usar o módulo tracemalloc integrado. Veja como podemos rastrear o uso geral da memória e interpretar os resultados para identificar tendências.
Etapas para usar tracemalloc
Nós beçamos inicializando o rastreamento de memória no início do nosso script.
import tracemalloc
tracemalloc.start()Em seguida, executamos nosso código executando as seções do nosso código que queremos monitorar.
def run_heavy_computation():
a = [i for i in range(10000)]
b = [i**2 for i in range(10000)]
return a, b
run_heavy_computation()Nóstiramos instantâneos do uso da memória. Isso nos permite capturar o estado das alocações de memória em diferentes pontos.
snapshot1 = tracemalloc.take_snapshot()
run_heavy_computation()
snapshot2 = tracemalloc.take_snapshot()Por fim, nós comparamos os instantâneos para entender os padrões de uso da memória e detectar vazamentos.
stats = snapshot2.compare_to(snapshot1, 'lineno')
for stat in stats[:10]:
print(stat)Exemplo
import tracemalloc
# Start tracing memory allocations
tracemalloc.start()
# Function to run heavy computation
def run_heavy_computation():
a = [i for i in range(10000)]
b = [i**2 for i in range(10000)]
return a, b
# Initial memory usage snapshot
snapshot1 = tracemalloc.take_snapshot()
# Perform memory allocations
run_heavy_computation()
# Memory usage snapshot after allocations
snapshot2 = tracemalloc.take_snapshot()
# Compare the snapshots
stats = snapshot2.compare_to(snapshot1, 'lineno')
# Print the top memory-consuming lines of code
print("[ Top 10 memory consumers ]")
for stat in stats[:10]:
print(stat)
# Stop tracing memory allocations
tracemalloc.stop()Aqui estão algumas dicas para ajudar você a entender os dados de criação de perfil:
Usando a biblioteca objgraph, podemos criar visualizações de relacionamentos de objetos. Isso nos ajuda a analisar o uso da memória, detectar vazamentos e entender a vida útil dos objetos.
Aqui está o processo passo a passo para você visualizar gráficos de objetos. Primeiro, geraremos um gráfico de referência de objeto; depois, detectaremos referências circulares; por fim, analisaremos os gráficos.
import objgraph
class Node:
def __init__(self, value):
self.value = value
self.children = []
# Create some nodes and establish relationships
node1 = Node(1)
node2 = Node(2)
node3 = Node(3)
node1.children.append(node2)
node2.children.append(node3)
# Generate a graph of object references
objgraph.show_refs([node1], filename='object_refs.png')# Create a circular reference
node3.children.append(node1)
# Detect circular references
chain = objgraph.find_backref_chain(node1, objgraph.is_proper_module)
objgraph.show_chain(chain, filename='circular_refs.png')# Show the most common object types
objgraph.show_most_common_types()
# Get details of a specific object type
nodes = objgraph.by_type('Node')
objgraph.show_refs(nodes[:3], refcounts=True, filename='node_details.png')Exemplo
import objgraph
class Node:
def __init__(self, value):
self.value = value
self.children = []
# Create some nodes and establish relationships
node1 = Node(1)
node2 = Node(2)
node3 = Node(3)
node1.children.append(node2)
node2.children.append(node3)
# Generate a graph of object references
objgraph.show_refs([node1], filename='object_refs.png')
# Create a circular reference
node3.children.append(node1)
# Detect circular references
chain = objgraph.find_backref_chain(node1, objgraph.is_proper_module)
objgraph.show_chain(chain, filename='circular_refs.png')
# Show the most common object types
objgraph.show_most_common_types()
# Get details of a specific object type
nodes = objgraph.by_type('Node')
objgraph.show_refs(nodes[:3], refcounts=True, filename='node_details.png')Como etapa final, analisamos os gráficos. Consideramos as seguintes etapas em ordem:
Aqui estão algumas dicas importantes e práticas recomendadas para ajudar você a obter o máximo de seus esforços de criação de perfis:
Neste tutorial, exploramos ferramentas e técnicas essenciais para que você entenda e otimize o uso da memória em seus aplicativos Python. Essas técnicas incluem memory_profiler, que oferece uma maneira direta de monitorar o consumo de memória linha por linha dentro da sua função, e objgraph, que oferece recursos avançados de visualização, permitindo que você analise as relações entre objetos, detecte referências circulares e entenda a estrutura do uso da memória.
A integração de ferramentas de criação de perfil de memória ao seu fluxo de trabalho de desenvolvimento permite que você obtenha insights valiosos sobre como o seu código gerencia a memória, ajuda a tomar decisões de otimização informadas e a melhorar o desempenho e a confiabilidade gerais dos aplicativos. Independentemente de você estar trabalhando em pequenos scripts ou em sistemas de grande escala, a criação de perfis de memória é uma prática essencial para qualquer desenvolvedor Python que queira escrever um código eficiente e robusto.
Para aprofundar sua compreensão e suas habilidades em criação de perfil de memória e escrita de código eficiente, considere fazer o curso Writing Efficient Code in Python. Além disso, nosso curso de programação Python oferece uma visão geral abrangente das práticas recomendadas e técnicas avançadas para ajudar você a se tornar um desenvolvedor proficiente.
Aprenda Python com a DataCamp
Curso
Curso
Curso
blog
Javier Canales Luna
13 min
Tutorial
Satyam Tripathi
Tutorial
Aditya Sharma
Tutorial
Abid Ali Awan
Tutorial
Kevin Babitz


